545e6d32079b808687fbff272c7e7b4e.ppt
- Количество слайдов: 138



Introduction to Bioinformatics Monday, November 17, 2008 Jonathan Pevsner pevsner@jhmi. edu Bioinformatics M. E: 800. 707
 Huang huangchengran@gmail. com")
Teaching assistants! Bethany Drehman bethfoxglove@gmail. com Cheng Ran (Lisa) Huang huangchengran@gmail. com

Who is taking this course? • People with very diverse backgrounds in biology • Some people with backgrounds in computer science and biostatistics • Most people (will) have a favorite gene, protein, or disease

What are the goals of the course? • To provide an introduction to bioinformatics with a focus on the National Center for Biotechnology Information (NCBI) and EBI • To focus on the analysis of DNA, RNA and proteins • To introduce you to the analysis of genomes • To combine theory and practice to help you solve research problems

Themes throughout the course Textbooks Web sites Literature references Gene/protein families Computer labs

Textbook The course textbook has no required textbook. I wrote Bioinformatics and Functional Genomics (Wiley, 2003). The seven lectures in this course correspond closely to chapters. An electronic version is available on the Welch Library website. A few copies will be available on reserve at Welch Library, and the library has six more copies. I recommend several other bioinformatics texts: Baxevanis and Ouellette David Mount Durbin et al.

Visit http: //www. welch. jhu. edu Search for: “bioinformatics” in “ebook titles”

Visit http: //www. welch. jhu. edu Search for: “bioinformatics” in “ebook titles”

Web sites The course website is reached via moodle: http: //pevsnerlab. kennedykrieger. org/moodle (or Google “moodle bioinformatics”) --This site contains the powerpoints for each lecture. including color and black & white versions --The weekly quizzes are here --You can ask questions via the forum The textbook website is: http: //www. bioinfbook. org This has powerpoints, URLs, etc. organized by chapter
. They")
Literature references You are encouraged to read original source articles (posted on moodle). They will enhance your understanding of the material. Readings are optional but recommended.

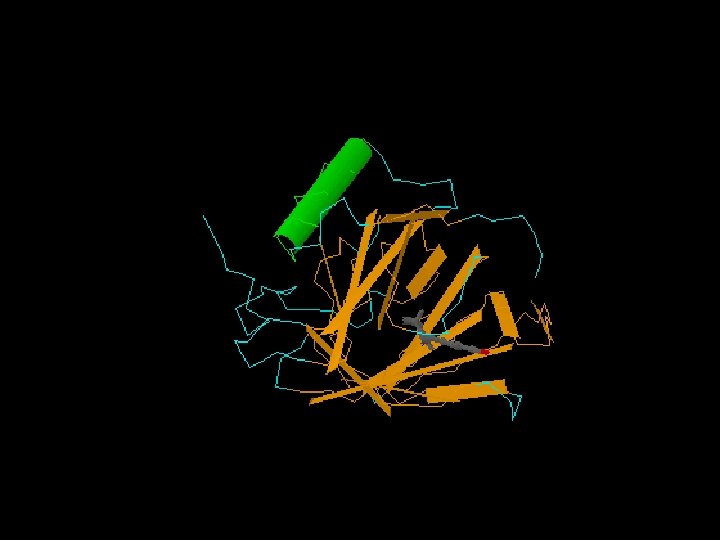
Themes throughout the course: gene/protein families We will use beta globin and retinol-binding protein 4 (RBP 4) as model genes/proteins throughout the course. Globins including hemoglobin and myoglobin carry oxygen. RBP 4 is a member of the lipocalin family. It is a small, abundant carrier protein. We will study globins and lipocalins in a variety of contexts including --sequence alignment --gene expression --protein structure --phylogeny --homologs in various species

Computer labs There are three computer labs. I STRONGLY encourage you to bring a laptop to class. Also, the seven weekly quizzes function as a computer lab: to solve the questions, you may need to go to a website and use databases or software.
. Quizzes are taken at the")
Grading 60% moodle quizzes (best six out of seven). Quizzes are taken at the moodle website, and are due one week after the relevant lecture 40% final exam Tuesday, January 12 (in class). Closed book, cumulative, no computer, short answer / multiple choice. Past exams will be made available ahead of time.

Google “moodle bioinformatics” to get here; Click “Introduction to Bioinformatics” to sign in; The enrollment key is…

Outline for the course 1. Accessing information about DNA and proteins Nov. 17 2. Pairwise alignment Nov. 24 3. BLAST Dec. 1 LAB #1 of 3 Dec. 1 4. Multiple sequence alignment Dec. 8 5. Molecular phylogeny and evolution Dec. 15 LAB #2 of 3 Dec. 15 6. Proteomics Dec. 22 7. Gene expression: microarrays Jan. 5 LAB #3 of 3 Final exam Jan. 5 Jan. 12

Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Four ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction

What is bioinformatics? • Interface of biology and computers • Analysis of proteins, genes and genomes using computer algorithms and computer databases • Genomics is the analysis of genomes. The tools of bioinformatics are used to make sense of the billions of base pairs of DNA that are sequenced by genomics projects.

On bioinformatics “Science is about building causal relations between natural phenomena (for instance, between a mutation in a gene and a disease). The development of instruments to increase our capacity to observe natural phenomena has, therefore, played a crucial role in the development of science - the microscope being the paradigmatic example in biology. With the human genome, the natural world takes an unprecedented turn: it is better described as a sequence of symbols. Besides high-throughput machines such as sequencers and DNA chip readers, the computer and the associated software becomes the instrument to observe it, and the discipline of bioinformatics flourishes. ”
 and the phenomena observed")
On bioinformatics “However, as the separation between us (the observers) and the phenomena observed increases (from organism to cell to genome, for instance), instruments may capture phenomena only indirectly, through the footprints they leave. Instruments therefore need to be calibrated: the distance between the reality and the observation (through the instrument) needs to be accounted for. This issue of Genome Biology is about calibrating instruments to observe gene sequences; more specifically, computer programs to identify human genes in the sequence of the human genome. ” Martin Reese and Roderic Guigó, Genome Biology 2006 7(Suppl I): S 1, introducing EGASP, the Encyclopedia of DNA Elements (ENCODE) Genome Annotation Assessment Project

bioinformatics medical informatics Tool-users public health informatics Tool-makers algorithms databases infrastructure

Three perspectives on bioinformatics The cell The organism The tree of life Page 4

DNA RNA protein phenotype Page 5

Time of development Body region, physiology, pharmacology, pathology Page 5
 Science 276: 734 Page 6")
After Pace NR (1997) Science 276: 734 Page 6

DNA RNA protein phenotype
 Base pairs of DNA (billions) Growth of Gen. Bank 1982 1986 1990")
Sequences (millions) Base pairs of DNA (billions) Growth of Gen. Bank 1982 1986 1990 1994 Year 1998 2002 Fig. 2. 1 Page 17
 250 200 150 100 50 0 1982")
Number of sequences in Gen. Bank (millions) 250 200 150 100 50 0 1982 1987 1992 1997 2002 2007 Base pairs of DNA in Gen. Bank (billions) Base pairs in Gen. Bank + WGS (billions) Growth of Gen. Bank + Whole Genome Shotgun (1982 -November 2008)

Central dogma of molecular biology DNA genome RNA transcriptome protein proteome Central dogma of bioinformatics and genomics

DNA genomic DNA databases RNA c. DNA ESTs Uni. Gene protein phenotype protein sequence databases Fig. 2. 2 Page 20

There are three major public DNA databases EMBL Gen. Bank DDBJ The underlying raw DNA sequences are identical Page 16

There are three major public DNA databases EMBL Housed at EBI European Bioinformatics Institute Gen. Bank DDBJ Housed at NCBI National Center for Biotechnology Information Housed in Japan Page 16

The Trace Archive at NCBI contains over 2 billion traces 11/08

Taxonomy at NCBI: ~200, 000 species are represented in Gen. Bank 11/08 http: //www. ncbi. nlm. nih. gov/Taxonomy/txstat. cgi

The most sequenced organisms in Gen. Bank Homo sapiens Mus musculus Rattus norvegicus Bos taurus Zea mays Sus scrofa Danio rerio Oryza sativa (japonica) Strongylocentrotus purpurata Nicotiana tabacum Updated 11 -6 -08 Gen. Bank release 168. 0 Excluding WGS, organelles, metagenomics 13. 1 billion bases 8. 4 b 6. 1 b 5. 2 b 4. 6 b 3. 0 b 1. 5 b 1. 4 b 1. 1 b Table 2 -2 Page 18
 www. ncbi. nlm. nih. gov Page 24")
National Center for Biotechnology Information (NCBI) www. ncbi. nlm. nih. gov Page 24

www. ncbi. nlm. nih. gov Fig. 2. 5 Page 25

Fig. 2. 5 Page 25

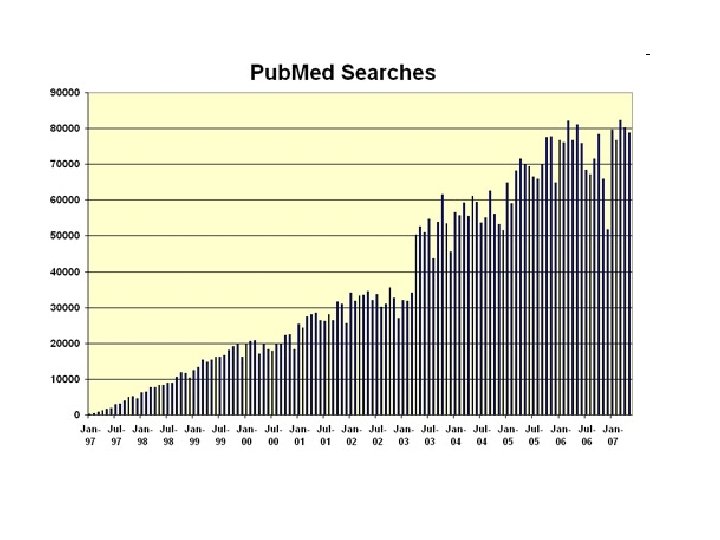
Pub. Med is… • National Library of Medicine's search service • 16 million citations in MEDLINE • links to participating online journals • Pub. Med tutorial (via “Education” on side bar) Page 24

Entrez integrates… • the scientific literature; • DNA and protein sequence databases; • 3 D protein structure data; • population study data sets; • assemblies of complete genomes Page 24

Entrez is a search and retrieval system that integrates NCBI databases Page 24

BLAST is… • Basic Local Alignment Search Tool • NCBI's sequence similarity search tool • supports analysis of DNA and protein databases • 100, 000 searches per day Page 25

OMIM is… • Online Mendelian Inheritance in Man • catalog of human genes and genetic disorders • created by Dr. Victor Mc. Kusick; led by Dr. Ada Hamosh at JHMI Page 25

Books is… • searchable resource of on-line books Page 26

Tax. Browser is… • browser for the major divisions of living organisms (archaea, bacteria, eukaryota, viruses) • taxonomy information such as genetic codes • molecular data on extinct organisms Page 26
 • biopolymer structures obtained from the")
Structure site includes… • Molecular Modelling Database (MMDB) • biopolymer structures obtained from the Protein Data Bank (PDB) • Cn 3 D (a 3 D-structure viewer) • vector alignment search tool (VAST) Page 26

Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Five ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction
 that")
Accession numbers are labels for sequences NCBI includes databases (such as Gen. Bank) that contain information on DNA, RNA, or protein sequences. You may want to acquire information beginning with a query such as the name of a protein of interest, or the raw nucleotides comprising a DNA sequence of interest. DNA sequences and other molecular data are tagged with accession numbers that are used to identify a sequence or other record relevant to molecular data. Page 26

What is an accession number? An accession number is label that used to identify a sequence. It is a string of letters and/or numbers that corresponds to a molecular sequence. Examples (all for retinol-binding protein, RBP 4): X 02775 NT_030059 Rs 7079946 Gen. Bank genomic DNA sequence Genomic contig db. SNP (single nucleotide polymorphism) DNA N 91759. 1 NM_006744 An expressed sequence tag (1 of 170) Ref. Seq DNA sequence (from a transcript) RNA NP_007635 AAC 02945 Q 28369 1 KT 7 Ref. Seq protein Gen. Bank protein Swiss. Prot protein Protein Data Bank structure record protein Page 27
![Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-52.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq")
Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq [2] Uni. Gene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] Ex. PASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 27
![5 ways to access protein and DNA sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-53.jpg "5 ways to access protein and DNA sequences [1] Entrez Gene with Ref. Seq")
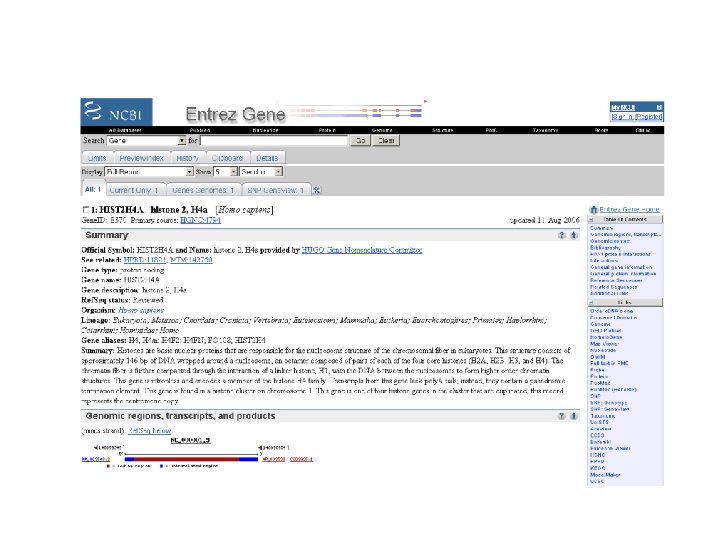
5 ways to access protein and DNA sequences [1] Entrez Gene with Ref. Seq Entrez Gene is a great starting point: it collects key information on each gene/protein from major databases. It covers all major organisms. Ref. Seq provides a curated, optimal accession number for each DNA (NM_006744) or protein (NP_007635) Page 27

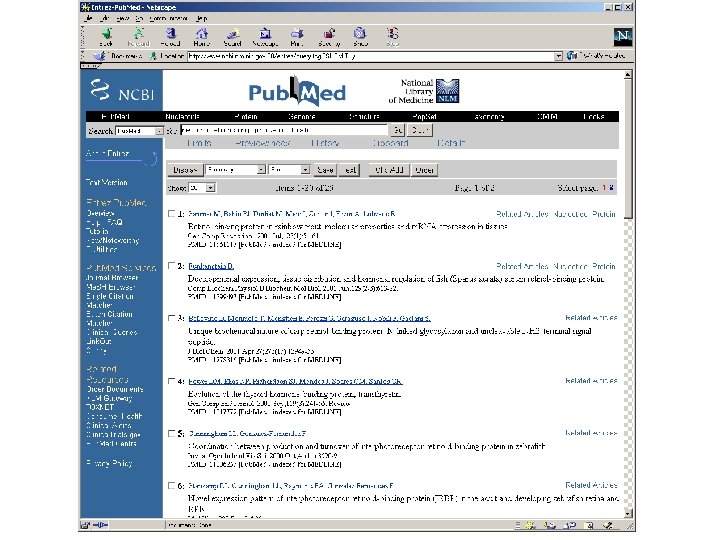
From the NCBI home page, type “beta globin” and hit “Go” revised 11/08 Fig. 2. 7 Page 29

revised Fig. 2. 7 Page 29
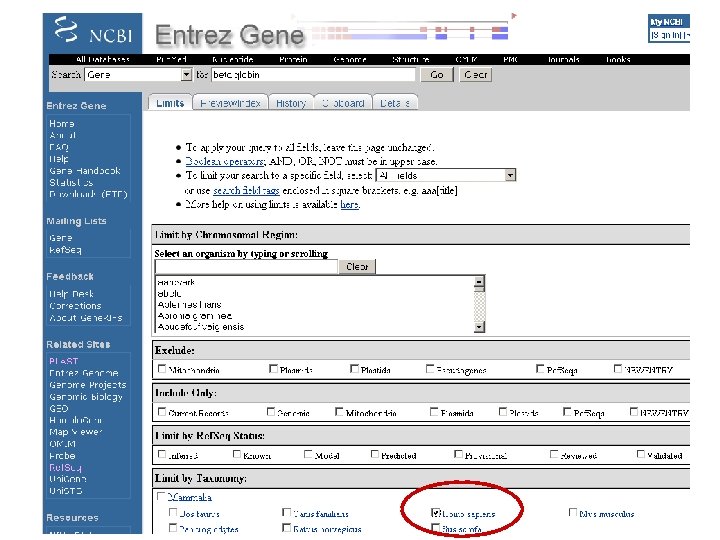

By applying limits, there are now fewer entries
 Note that links to many other HBB database entries")
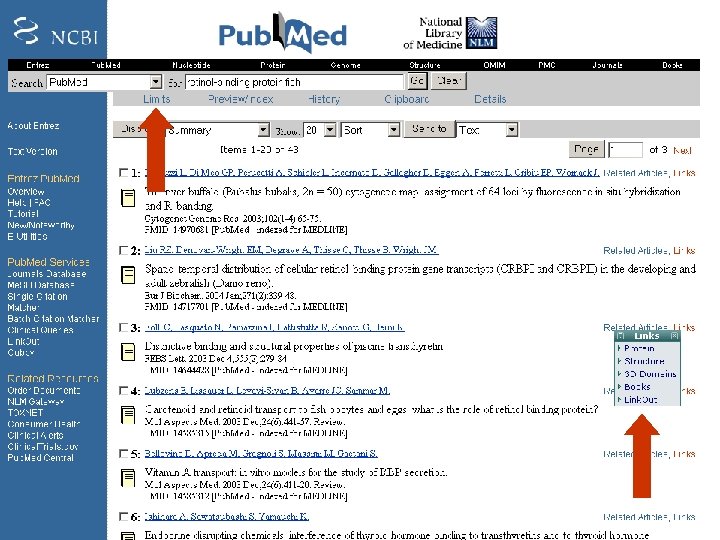
Entrez Gene (top of page) Note that links to many other HBB database entries are available revised Fig. 2. 8 Page 30
")
Entrez Gene (middle of page)
")
Entrez Gene (middle of page, continued)
: Ref. Seqs")
Entrez Gene (bottom of page): Ref. Seqs
: non-Ref. Seq accessions")
Entrez Gene (bottom of page): non-Ref. Seq accessions

Fig. 2. 9 Page 32

Fig. 2. 9 Page 32

Fig. 2. 9 Page 32

FASTA format: versatile, compact with >one header line followed by a string of nucleotides or amino acids in the single letter code Fig. 2. 10 Page 32

What is an accession number? An accession number is label that used to identify a sequence. It is a string of letters and/or numbers that corresponds to a molecular sequence. Examples: X 02775 NT_030059 Rs 7079946 Gen. Bank genomic DNA sequence Genomic contig db. SNP (single nucleotide polymorphism) DNA N 91759. 1 NM_006744 An expressed sequence tag (1 of hundreds) Ref. Seq DNA sequence (from a transcript) RNA NP_007635 AAC 02945 Q 28369 1 KT 7 Ref. Seq protein Gen. Bank protein Swiss. Prot protein Protein Data Bank structure record protein Page 27

NCBI’s important Ref. Seq project: best representative sequences Ref. Seq (accessible via the main page of NCBI) provides an expertly curated accession number that corresponds to the most stable, agreed-upon “reference” version of a sequence. Ref. Seq identifiers include the following formats: Complete genome Complete chromosome Genomic contig m. RNA (DNA format) Protein NC_###### NT_###### NM_###### e. g. NM_006744 NP_###### e. g. NP_006735 Page 29 -30

NCBI’s Ref. Seq project: accession for genomic, m. RNA, protein sequences Accession AC_123456 AP_123456 NC_123456 NG_123456 NM_123456789 NP_123456789 NR_123456 NT_123456 NW_123456 NZ_ABCD 12345678 XM_123456 XP_123456 XR_123456 YP_123456 ZP_12345678 Molecule Genomic Protein Genomic m. RNA Protein RNA Genomic m. RNA Protein Method Mixed Mixed Curation Mixed Automated Automated Auto. & Curated Automated Note Alternate complete genomic Protein products; alternate Complete genomic molecules Incomplete genomic regions Transcript products; m. RNA Transcript products; 9 -digit Protein products; 9 -digit Non-coding transcripts Genomic assemblies Whole genome shotgun data Transcript products Protein products
![Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-71.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq")
Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq [2] Uni. Gene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] Ex. PASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31
 Uni. Gene Fig. 2. 3 Page 23")
DNA RNA protein complementary DNA (c. DNA) Uni. Gene Fig. 2. 3 Page 23

Uni. Gene: unique genes via ESTs • Find Uni. Gene at NCBI: www. ncbi. nlm. nih. gov/Uni. Gene • Uni. Gene clusters contain many expressed sequence tags (ESTs), which are DNA sequences (typically 500 base pairs in length) corresponding to the m. RNA from an expressed gene. ESTs are sequenced from a complementary DNA (c. DNA) library. • Uni. Gene data come from many c. DNA libraries. Thus, when you look up a gene in Uni. Gene you get information on its abundance and its regional distribution. Pages 20 -21

Cluster sizes in Uni. Gene This is a gene with 1 EST associated; the cluster size is 1 Fig. 2. 3 Page 23

Cluster sizes in Uni. Gene This is a gene with 10 ESTs associated; the cluster size is 10
 Cluster size (ESTs) 1 2 3 -4 5")
Cluster sizes in Uni. Gene (human) Cluster size (ESTs) 1 2 3 -4 5 -8 9 -16 17 -32 500 -1000 -4000 -16, 000 -65, 000 Uni. Gene build 216, 11/08 Number of clusters 40, 300 18, 500 18, 000 13, 400 8, 100 5, 200 1, 900 940 74 8 16000: 70000[ESTC]

Uni. Gene: unique genes via ESTs Conclusion: Uni. Gene is a useful tool to look up information about expressed genes. Uni. Gene displays information about the abundance of a transcript (expressed gene), as well as its regional distribution of expression (e. g. brain vs. liver). We will discuss Uni. Gene further on January 5 (gene expression). Page 31
![Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-78.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq")
Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq [2] Uni. Gene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] Ex. PASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31

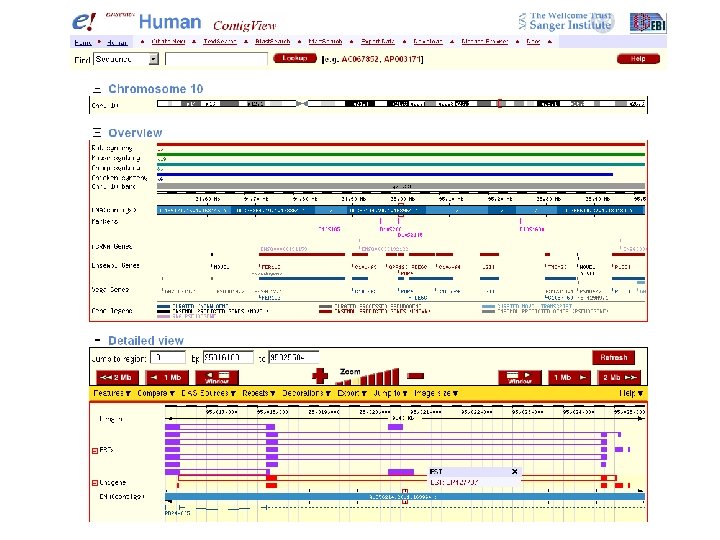
Ensembl to access protein and DNA sequences Try Ensembl at www. ensembl. org for a premier human genome web browser. We will encounter Ensembl as we study the human genome, BLAST, and other topics.

click human

enter RBP 4
![Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-83.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq")
Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq [2] Uni. Gene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] Ex. PASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33

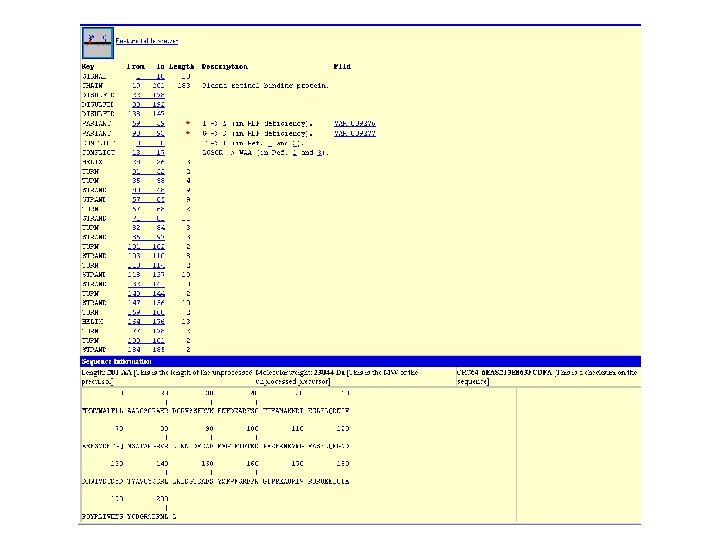
Ex. PASy to access protein and DNA sequences Ex. PASy sequence retrieval system (Ex. PASy = Expert Protein Analysis System) Visit http: //www. expasy. ch/ Page 33

Fig. 2. 11 Page 33
![Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-87.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq")
Five ways to access DNA and protein sequences [1] Entrez Gene with Ref. Seq [2] Uni. Gene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] Ex. PASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33
![[1] Visit http: //genome. ucsc. edu/, click Genome Browser [2] Choose organisms, enter query](https://present5.com/presentation/545e6d32079b808687fbff272c7e7b4e/image-88.jpg "[1] Visit http: //genome. ucsc. edu/, click Genome Browser [2] Choose organisms, enter query")
[1] Visit http: //genome. ucsc. edu/, click Genome Browser [2] Choose organisms, enter query (beta globin), hit submit

Example of how to access sequence data: HIV-1 pol There are many possible approaches. Begin at the main page of NCBI, and type an Entrez query: hiv-1 pol Page 34

11/08

Searching for HIV-1 pol: Following the “genome” link yields a manageable five results Page 34

Example of how to access sequence data: HIV-1 pol For the Entrez query: hiv-1 pol there about 80, 000 nucleotide or protein records (and >200, 000 records for a search for “hiv-1”), but these can easily be reduced in two easy steps: --specify the organism, e. g. hiv-1[organism] --limit the output to Ref. Seq! Page 34

over 200, 000 nucleotide entries for HIV-1 only 1 Ref. Seq

Examples of how to access sequence data: histone query for “histone” # results protein records Ref. Seq entries 21847 7544 Ref. Seq (limit to human) NOT deacetylase 1108 697 At this point, select a reasonable candidate (e. g. histone 2, H 4) and follow its link to Entrez Gene. There, you can confirm you have the right gene/protein. 8 -12 -06

Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Four ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction

Pub. Med at NCBI to find literature information

Pub. Med is the NCBI gateway to MEDLINE contains bibliographic citations and author abstracts from over 4, 600 journals published in the United States and in 70 foreign countries. It has >18 million records dating back to 1950 s. Updated 11 -08 Page 35

Me. SH is the acronym for "Medical Subject Headings. " Me. SH is the list of the vocabulary terms used for subject analysis of biomedical literature at NLM. Me. SH vocabulary is used for indexing journal articles for MEDLINE. The Me. SH controlled vocabulary imposes uniformity and consistency to the indexing of biomedical literature. Page 35
 Use boolean")
Pub. Med search strategies Try the tutorial (“education” on the left sidebar) Use boolean queries (capitalize AND, OR, NOT) lipocalin AND disease Try using “limits” Try “Links” to find Entrez information and external resources Obtain articles on-line via Welch Medical Library (and download pdf files): http: //www. welch. jhu. edu/ Page 35
 1 OR 2 1")
1 AND 2 1 2 lipocalin AND disease (60 results) 1 OR 2 1 2 lipocalin OR disease (1, 650, 000 results) 1 NOT 2 1 2 lipocalin NOT disease (530 results) Fig. 2. 12 Page 34

Article contents: “globin” is absent present Search result: “globin” is found true positive false positive (article does not discuss globins) “globin” is not found false negative (article discusses globins) true negative

Welch. Web is available at http: //www. welch. jhu. edu

Welch. Web is available at http: //www. welch. jhu. edu Welch Medical Library liasons to the basic sciences

November 24, 2008 Pairwise sequence alignment Jonathan Pevsner, Ph. D. Bioinformatics Johns Hopkins M. E: 440. 707

Outline: pairwise alignment • Overview and examples • Definitions: homologs, paralogs, orthologs • Assigning scores to aligned amino acids: Dayhoff’s PAM matrices • Alignment algorithms: Needleman-Wunsch, Smith-Waterman • Statistical significance of pairwise alignments
 Corticotropin A (pig) Oxytocin Vasopressin ala")
Pairwise alignments in the 1950 s b-corticotropin (sheep) Corticotropin A (pig) Oxytocin Vasopressin ala gly glu asp gly ala glu asp glu CYIQNCPLG CYFQNCPRG
 H. C. Watson")
globins: a- b- myoglobin Early example of sequence alignment: globins (1961) H. C. Watson and J. C. Kendrew, “Comparison Between the Amino-Acid Sequences of Sperm Whale Myoglobin and of Human Hæmoglobin. ” Nature 190: 670 -672, 1961.

Pairwise sequence alignment is the most fundamental operation of bioinformatics • It is used to decide if two proteins (or genes) are related structurally or functionally • It is used to identify domains or motifs that are shared between proteins • It is the basis of BLAST searching (next week) • It is used in the analysis of genomes

Pairwise alignment: protein sequences can be more informative than DNA • protein is more informative (20 vs 4 characters); many amino acids share related biophysical properties • codons are degenerate: changes in the third position often do not alter the amino acid that is specified • protein sequences offer a longer “look-back” time • DNA sequences can be translated into protein, and then used in pairwise alignments

Page 54

Pairwise alignment: protein sequences can be more informative than DNA • DNA can be translated into six potential proteins 5’ CAT CAA 5’ ATC AAC 5’ TCA ACT 5’ CATCAACTACAACTCCAAAGACACCCTTACACATCAACAAACCTACCCAC 3’ 3’ GTAGTTGATGTTGAGGTTTCTGTGGGAATGTGTAGTTGTTTGGATGGGTG 5’ 5’ GTG GGT 5’ TGG GTA 5’ GGG TAG

Pairwise alignment: protein sequences can be more informative than DNA • Many times, DNA alignments are appropriate --to confirm the identity of a c. DNA --to study noncoding regions of DNA --to study DNA polymorphisms --example: Neanderthal vs modern human DNA Query: 181 catcaactacaactccaaagacacccttacacccactaggatatcaacaaacctacccac 240 |||||| |||||||||||||||| Sbjct: 189 catcaactgcaaccccaaagccacccct-cacccactaggatatcaacaaacctacccac 247
 b-lactoglobulin (P 02754) Page 42")
retinol-binding protein 4 (NP_006735) b-lactoglobulin (P 02754) Page 42

Outline: pairwise alignment • Overview and examples • Definitions: homologs, paralogs, orthologs • Assigning scores to aligned amino acids: Dayhoff’s PAM matrices • Alignment algorithms: Needleman-Wunsch, Smith-Waterman • Statistical significance of pairwise alignments

Definitions Pairwise alignment The process of lining up two sequences to achieve maximal levels of identity (and conservation, in the case of amino acid sequences) for the purpose of assessing the degree of similarity and the possibility of homology.

Definitions Homology Similarity attributed to descent from a common ancestor. Page 42

Definitions Homology Similarity attributed to descent from a common ancestor. Identity The extent to which two (nucleotide or amino acid) sequences are invariant. RBP: 26 glycodelin: 23 RVKENFDKARFSGTWYAMAKKDPEGLFLQDNIVA 59 + K++ + ++ GTW++MA + L + A QTKQDLELPKLAGTWHSMAMA-TNNISLMATLKA 55 Page 44

Definitions: two types of homology Orthologs Homologous sequences in different species that arose from a common ancestral gene during speciation; may or may not be responsible for a similar function. Paralogs Homologous sequences within a single species that arose by gene duplication. Page 43
 family in")
common carp zebrafish rainbow trout teleost Orthologs: members of a gene (protein) family in various organisms. This tree shows RBP orthologs. African clawed frog chicken human mouse rat horse pig cow rabbit 10 changes Page 43

apolipoprotein D retinol-binding protein 4 Complement component 8 Alpha-1 Microglobulin /bikunin Paralogs: members of a gene (protein) family within a species prostaglandin D 2 synthase progestagenassociated endometrial protein Odorant-binding protein 2 A neutrophil gelatinaseassociated lipocalin Lipocalin 1 10 changes Page 44


Pairwise alignment of retinol-binding protein 4 and b-lactoglobulin 1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |. . . | : . ||||. : | : 1. . . MKCLLLALALTCGAQALIVT. . QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR. LLNNWD. . VCADMVGTFTDTE 97 RBP : | | : : |. |. || |: || |. 45 ISLLDAQSAPLRV. YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV. . . QYSC 136 RBP || ||. | : . |||| |. . | 94 IPAVFKIDALNENKVL. . . . VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ. EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI. . . . 178 lactoglobulin Page 46

Definitions Similarity The extent to which nucleotide or protein sequences are related. It is based upon identity plus conservation. Identity The extent to which two sequences are invariant. Conservation Changes at a specific position of an amino acid or (less commonly, DNA) sequence that preserve the physicochemical properties of the original residue.

Pairwise alignment of retinol-binding protein and b-lactoglobulin 1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |. . . | : . ||||. : | : 1. . . MKCLLLALALTCGAQALIVT. . QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR. LLNNWD. . VCADMVGTFTDTE 97 RBP : | | : : |. |. || |: || |. 45 ISLLDAQSAPLRV. YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV. . . QYSC 136 RBP || ||. | : . |||| |. . | 94 IPAVFKIDALNENKVL. . . . VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin Identity (bar) 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ. EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI. . . . 178 lactoglobulin Page 46

Pairwise alignment of retinol-binding protein and b-lactoglobulin 1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |. . . | : . ||||. : | : 1. . . MKCLLLALALTCGAQALIVT. . QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR. LLNNWD. . VCADMVGTFTDTE 97 RBP : | | : : |. |. || |: || |. 45 ISLLDAQSAPLRV. YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV. . . QYSC 136 RBP || ||. | : . |||| |. . | 94 IPAVFKIDALNENKVL. . . . VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin Somewhat similar (one dot) Very similar (two dots) 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ. EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI. . . . 178 lactoglobulin Page 46

Definitions Pairwise alignment The process of lining up two sequences to achieve maximal levels of identity (and conservation, in the case of amino acid sequences) for the purpose of assessing the degree of similarity and the possibility of homology. Page 47

Pairwise alignment of retinol-binding protein and b-lactoglobulin 1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |. . . | : . ||||. : | : 1. . . MKCLLLALALTCGAQALIVT. . QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR. LLNNWD. . VCADMVGTFTDTE 97 RBP : | | : : |. |. || |: || |. 45 ISLLDAQSAPLRV. YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV. . . QYSC 136 RBP || ||. | : . |||| |. . | 94 IPAVFKIDALNENKVL. . . . VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ. EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI. . . . 178 lactoglobulin Internal gap Terminal gap Page 46

Gaps • Positions at which a letter is paired with a null are called gaps. • Gap scores are typically negative. • Since a single mutational event may cause the insertion or deletion of more than one residue, the presence of a gap is ascribed more significance than the length of the gap. • In BLAST, it is rarely necessary to change gap values from the default.

Pairwise alignment of retinol-binding protein and b-lactoglobulin 1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |. . . | : . ||||. : | : 1. . . MKCLLLALALTCGAQALIVT. . QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR. LLNNWD. . VCADMVGTFTDTE 97 RBP : | | : : |. |. || |: || |. 45 ISLLDAQSAPLRV. YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV. . . QYSC 136 RBP || ||. | : . |||| |. . | 94 IPAVFKIDALNENKVL. . . . VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ. EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI. . . . 178 lactoglobulin
 and rainbow trout (O. mykiss) 1.")
Pairwise alignment of retinol-binding protein from human (top) and rainbow trout (O. mykiss) 1. MKWVWALLLLA. AWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDP 48 : : || || ||. ||. . | : |||: . | ||||| 1 MLRICVALCALATCWA. . . QDCQVSNIQVMQNFDRSRYTGRWYAVAKKDP 47. . . 49 EGLFLQDNIVAEFSVDETGQMSATAKGRVRLLNNWDVCADMVGTFTDTED 98 |||| ||: |||||. ||| : ||||: . ||. | || | 48 VGLFLLDNVVAQFSVDESGKMTATAHGRVIILNNWEMCANMFGTFEDTPD 97. . . 99 PAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAVQYSCRLLNLDGTCADS 148 ||||||: ||| ||: || ||||||: : ||||| ||: ||||. . ||||| | 98 PAKFKMRYWGAASYLQTGNDDHWVIDTDYDNYAIHYSCREVDLDGTCLDG 147. . . 149 YSFVFSRDPNGLPPEAQKIVRQRQEELCLARQYRLIVHNGYCDGRSERNLL 199 |||: ||| || |||| : . . |: |. || : | |: |: 148 YSFIFSRHPTGLRPEDQKIVTDKKKEICFLGKYRRVGHTGFCESS. . . 192
 Origin")
Pairwise sequence alignment allows us to look back billions of years ago (BYA) Origin of life 4 Earliest fossils Origin of Eukaryote/ eukaryotes archaea 3 2 Fungi/animal Plant/animal 1 insects 0 Page 48

Multiple sequence alignment of glyceraldehyde 3 -phosphate dehydrogenases fly human plant bacterium yeast archaeon GAKKVIISAP GAKRVIISAP GAKKVVMTGP GAKKVVITAP GADKVLISAP SAD. APM. . F SKDNTPM. . F SS. TAPM. . F PKGDEPVKQL VCGVNLDAYK VMGVNHEKYD VVGVNEHTYQ VKGANFDKY. VMGVNEEKYT VYGVNHDEYD PDMKVVSNAS NSLKIISNAS PNMDIVSNAS AGQDIVSNAS SDLKIVSNAS GE. DVVSNAS CTTNCLAPLA CTTNCLAPLA CTTNSITPVA fly human plant bacterium yeast archaeon KVINDNFEIV KVIHDNFGIV KVVHEEFGIL KVINDNFGII KVINDAFGIE KVLDEEFGIN EGLMTTVHAT EGLMTTVHAI EGLMTTVHAT EGLMTTVHSL AGQLTTVHAY TATQKTVDGP TATQKTVDGP TGSQNLMDGP SGKLWRDGRG SMKDWRGGRG SHKDWRGGRT NGKP. RRRRA AAQNIIPAST ALQNIIPAST ASQNIIPSST ASGNIIPSST AAENIIPTST fly human plant bacterium yeast archaeon GAAKAVGKVI GAAKAVGKVL GAAQAATEVL PALNGKLTGM PELNGKLTGM PELQGKLTGM PELEGKLDGM AFRVPTPNVS AFRVPTANVS AFRVPTSNVS AFRVPTPNVS AFRVPTVDVS AIRVPVPNGS VVDLTVRLGK VVDLTCRLEK VVDLTVRLEK VVDLTVKLNK ITEFVVDLDD GASYDEIKAK PAKYDDIKKV GASYEDVKAA AATYEQIKAA ETTYDEIKKV DVTESDVNAA Page 49

Multiple sequence alignment of human lipocalin paralogs ~~~~~EIQDVSGTWYAMTVDREFPEMNLESVTPMTLTTL. GGNLEAKVTM LSFTLEEEDITGTWYAMVVDKDFPEDRRRKVSPVKVTALGGGNLEATFTF TKQDLELPKLAGTWHSMAMATNNISLMATLKAPLRVHITSEDNLEIVLHR VQENFDVNKYLGRWYEIEKIPTTFENGRCIQANYSLMENGNQELRADGTV VKENFDKARFSGTWYAMAKDPEGLFLQDNIVAEFSVDETGNWDVCADGTF LQQNFQDNQFQGKWYVVGLAGNAI. LREDKDPQKMYATIDKSYNVTSVLF VQPNFQQDKFLGRWFSAGLASNSSWLREKKAALSMCKSVDGGLNLTSTFL VQENFNISRIYGKWYNLAIGSTCPWMDRMTVSTLVLGEGEAEISMTSTRW PKANFDAQQFAGTWLLVAVGSACRFLQRAEATTLHVAPQGSTFRKLD. . . lipocalin 1 odorant-binding protein 2 a progestagen-assoc. endo. apolipoprotein D retinol-binding protein neutrophil gelatinase-ass. prostaglandin D 2 synthase alpha-1 -microglobulin complement component 8 Page 49
545e6d32079b808687fbff272c7e7b4e.ppt