54b7f1ad2f1747901d7b756099bb9919.ppt
- Количество слайдов: 40


 Computational Cluster Facilities Xiaohui CECS Department University of Louisville")
Introduction of Cluster and (KBRIN) Computational Cluster Facilities Xiaohui CECS Department University of Louisville X 0 cui 001@uofl. edu 09/03/2003

Introduction to Cluster Technology What is a Beowulf ? Kentucky Biomedical Research Infrastructure Network MPI Programming on KBRIN cluster

People always wants to have faster computer • Normal users – Play game faster – Play music better, watch movies better • Science and Engineer – Solving larger and more complex science and engineering problems using computer modeling, simulation and analysis

How to make a computer faster? • Make a faster chip! – reduce feature size – better architecture, better memory subsystem • VLIW , Super scalar, vector support, DSP instruction (MMX, 3 DNow) • SDRAM, NVRAM • Uni-processor speed is still limited by speed of light • Alternate technologies – Optical – Bio – Molecular

How to make a computer faster? • Using multiple processors to solve a single problem – Divide problem into many small pieces – Distributed these small problems to be solved by multiple processors simultaneously • This technique is called Parallel Processing

Parallel computer • Parallel computer is a special computer with – High Speed I/O , Large memory, multiple processing units, fast communication network • Every modern supercomputer is also a parallel computer CPU CPU High Speed Network

Fastest Supercomputer in the world • Intel ASCI Red at Sandia National Laboratory • 9216 Pentium Processors • 2. 3 Teraflops performance

But Supercomputer will cost you 100 millions, how to get enough money to buy one? • Using PC Cluster is a low cost solution to this problem

Introduction to Cluster Technology • A Cluster system is – Parallel multi-computer built from high-end PCs and conventional high-speed network.

Why cluster computing? • Scalability – Build small system first, grow it later. • Low-cost – Hardware based on COTS model (Component off-the-shelf) – Software based on freeware from research community • Easier to maintain • Vendor independent

Different kinds of PC cluster • High Performance Computing Cluster • Load Balancing • High Availability

The Beginning • Thomas Sterling and Donald Becker CESDIS, Goddard Space Flight Center, Greenbelt, MD • Summer 1994: built an experimental cluster • Called their cluster Beowulf • 16 x 486 DX 4, 100 MHz processors • 16 MB of RAM each, 256 MB in total • Channel bonded Ethernet (2 x 10 Mbps) • Not that different from our Beowulf

Current Beowulfs • Faster processors, faster interconnect, but the idea remains the same • Cluster database: http: //clusters. top 500. org/db/Query. php 3 • Super cluster: 2300 processors, 11 TFLOPS peak
")
What is a Beowulf ? • Runs a free operating system (not Wolfpack, MSCS) • Connected by high speed interconnect • Compute nodes are dedicated (not Network of Workstations)

Why Beowulf? • It’s cheap! • Our Beowulf, 32 processors, 32 GB RAM: $50, 000 • The IBM SP 2 cluster cost many millions • Everything in a Beowulf is open-source and open standard - easier to manage/upgrade

Essential Components of a Beowulf • Processors • AMD and Intel • Memory • DDR RAM • RDRAM • Interconnect • Fast Ethernet • Gigabit Ethernet • Myrinet • Software

Free cluster OS and management software • OS • Linux • Free. BSD • Cluster Management • Oscar: http: //oscar. sourceforge. net/ • Rocks: http: //rocks. npaci. edu • MOSIX: http: //www. mosix. org/

DIY Cluster

White Box Desktop n Cheap n n n Expandable n n n 4 -6 PCI slots 3 -5 disk drives Low density n n 2. 8 GHz Pentium 4 for $1000 Very low margins 16 processor in on rack (on shelves) Quality n 90 - 365 day warrantees

Commercial designed Cluster

Brand Name Servers n Expensive n n High density n n Up to double equivalent desktop hardware Rack mountable 64 processors in one rack Blades Quality n 3 year warrantee n n Throw away machine when out of warrantee Good thermal design

Minimum Components Power Local Hard Drive Ethernet x 86 server

Cluster Advantages • Error isolation: separate address space limits contamination of error • Repair: Easier to replace a machine without bringing down the system than in an shared memory multiprocessor • Scale: easier to expand the system without bringing down the application that runs on top of the cluster • Cost: Large scale machine has low volume => fewer machines to spread development costs vs. leverage high volume off-the-shelf switches and computers • Amazon, AOL, Google, Hotmail, Inktomi, Web. TV, and Yahoo rely on clusters of PCs to provide services used by millions of people every day

Cluster Drawbacks • Cost of administering a cluster of N machines ~ administering N independent machines vs. cost of administering a shared address space N processors multiprocessor ~ administering 1 big machine • Clusters usually connected using I/O bus, whereas multiprocessors usually connected on memory bus • Cluster of N machines has N independent memories and N copies of OS, but a shared address multi-processor allows 1 program to use almost all memory

Google company 2001 cluster reliability statistic • For 6000 PCs, 12000 HD, 200 EN switches • ~ 20 PCs will need to be rebooted/day • ~ 2 PCs/day hardware failure, or 2%-3% / year – 5% due to problems with motherboard, power supply, and connectors – 30% DRAM: bits change + errors in transmission (100 MHz) – 30% Disks fail – 30% Disks go very slow (10%-3% expected BW) • 200 EN switches, 2 -3 fail in 2 years
 Computational Cluster Facilities CECS Department Bioinformatics Laboratory KBRIN")
Kentucky Biomedical Research Infrastructure Network (KBRIN) Computational Cluster Facilities CECS Department Bioinformatics Laboratory KBRIN Computational Cluster Dahlem Supercomputer Laboratory KBRIN Supercomputer HP Laser Printer Dual AMD 2400 Workstation 2 GB memory (4) 70 GB hard drives 100 mb NIC Dual AMD 2400 2 GB memory 40 GB hard drive 1 gb NIC Dual AMD 2400 Workstation 2 GB memory 80 GB hard drive 100 mb and 1 gb NIC Web Srvr / Bkp master Dual AMD 2400 2 GB memory CD RW drive (4) 70 GB hard drives 100 mb and 1 gb NIC 100 mb Ethernet Gigabit Ethernet Dual AMD 2400 Workstation 2 GB memory 80 GB hard drive 100 mb and 1 gb NIC Master Backup System (16) Compute Nodes Dual AMD 2400 Workstation 2 GB memory 80 GB hard drive 100 mb and 1 gb NIC KBRIN Project Office KVM Switch Monitor, Keyboard Master Node Dual AMD 2400 2 GB memory CD RW drive (4) 70 GB hard drives 100 mb and 1 gb NIC 24 Port Gb Ethernet Switch 100 mb Ethernet Campus Ethernet Network Elb 4/1/2003

Programming a Cluster • Cluster power comes from parallel processing – Large task is decomposed to a set of small tasks – These tasks are executed by a set of processes on multiple nodes • Programming model based on Message Passing – These process communicate by exchanging message which consists of data and synchronization information
 – POSIX Threads – Java")
Programming environments • Threads (PCs, SMPs, NOW. . ) – POSIX Threads – Java Threads • MPI – http: //www-unix. mcs. anl. gov/mpich/ • PVM – http: //www. epm. ornl. gov/pvm/

MPI n n Message Passing Interface v 1. 1, v 2. 0 n Standard for high performance message passing on parallel machines n http: //www-unix. mcs. anl. gov/mpi/ Supports n GNU C, Fortran 77 n Intel C, Fortran 77, Fortran 90 n Portland Group C, C++, Fortran 77, Fortran 90 n Requires site license

PVM n Parallel Virtual Machines v 3. 4. 3 n Message passing interface for heterogeneous architectures n Supports over 60 variants of UNIX n Supports Windows NT n Resource control and meta computing n Fault tolerance n http: //www. csm. ornl. gov/pvm/

MPI Programming A 2 6 2 8 1 2 2 4 43 87 3 9 5 6 3 8 3 5 9 1 5 8 4 0 9 9 5 1 5 24 8 9 1 5 5 6 8 6 6 2 67 8 9 5 63 6 7 4 4 2 8 8 4 4 3 1 2 7 1 9 1 8 Sum(A)=?

MPI Programming 2 6 A 1 2 8 1 A 3 2 2 4 43 87 3 9 5 3 3 9 6 8 5 1 5 8 4 0 9 9 5 1 6 2 24 8 5 A 2 5 6 6 67 8 56 6 4 3 A 4 2 8 4 4 1 2 9 8 9 7 4 8 3 7 Sum(A 1, A 2, A 3, A 4)=? 1 9 1 8

MPI Programming Request Output Master Slaves

MPI Programming /* Algorithm for the master program */ initialize the array `items'. /* send data to the slaves */ for i = 0 to 3 Send items[25*i] to items[25*(i+1)-1] to slave Pi end for /* collect the results from the slaves */ for i = 0 to 3 Receive the result from slave Pi in result[i] end for /* calculate the final result */ sum = 0 for i = 0 to 3 sum = sum + result[i] end for print sum

MPI Programming /* Algorithm for the slave program */ Receive 25 elements from the master in some array say `items' /* calculate intermediate result */ sum = 0 for i = 0 to 24 sum = sum + items[i] end for send `sum' as the intermediate result to the master

Run MPI Program on the Cluster • MPI C compiler: mpicc • MPI job submit software: PBS • The PBS command used for submit MPI job: • Mkpbs • Qsub • Rps

Portable Batch System n Three standard components to PBS n MOM n Daemon on every node n Used for job launching and health reporting n Server n On the frontend only n Queue definition, and aggregation of node information n Scheduler n Policies for what job to run out of which queue at what time
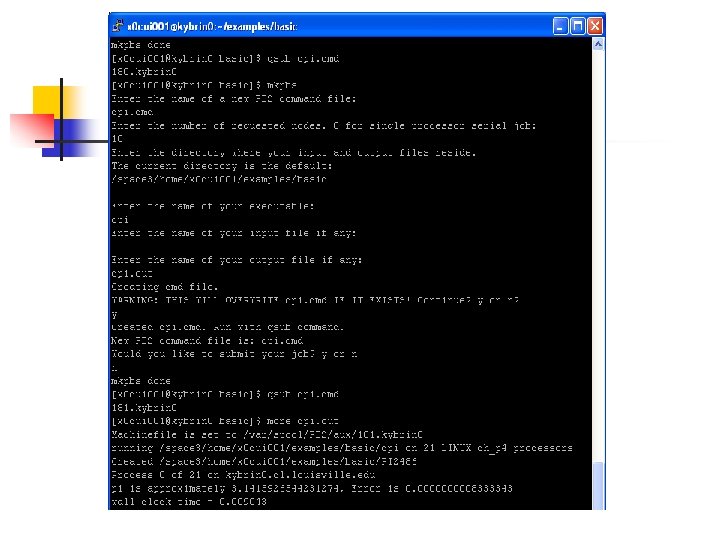

Connect cluster from your computer

Free X-windows Server on windows http: //www. cygwin. com/
54b7f1ad2f1747901d7b756099bb9919.ppt