

1db767667f976ef26e8f16b8ab8d4a98.ppt
- Количество слайдов: 102
 Introducing Corpus Linguistics Dr. Gloria Cappelli A/A 2006/2007 – University of Pisa
Introducing Corpus Linguistics Dr. Gloria Cappelli A/A 2006/2007 – University of Pisa
 What is a CORPUS? “A corpus is a collection of pieces of language that are selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language” (Sinclair 1996)
What is a CORPUS? “A corpus is a collection of pieces of language that are selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language” (Sinclair 1996)
![What is a CORPUS? “[…] the term corpus as used in modern linguistics can](https://present5.com/presentation/1db767667f976ef26e8f16b8ab8d4a98/image-3.jpg "What is a CORPUS? “[…] the term corpus as used in modern linguistics can") What is a CORPUS? “[…] the term corpus as used in modern linguistics can best be defined as a collection of sampled texts, written or spoken, in machinereadable form which may be annotated with various forms of linguistic information” (Mc. Enery, Xiao and Tono 2006)
What is a CORPUS? “[…] the term corpus as used in modern linguistics can best be defined as a collection of sampled texts, written or spoken, in machinereadable form which may be annotated with various forms of linguistic information” (Mc. Enery, Xiao and Tono 2006)
 Key concepts re. Corpora: • Machine-readable texts • Authentic texts • Sampled texts • Representative of a particular language or language variety
Key concepts re. Corpora: • Machine-readable texts • Authentic texts • Sampled texts • Representative of a particular language or language variety
 Is Corpus Linguistics a new approach to the study of language? The expression Corpus Linguistics first appeared in the early 80 s. Corpus-based language study, however has a substantial history.
Is Corpus Linguistics a new approach to the study of language? The expression Corpus Linguistics first appeared in the early 80 s. Corpus-based language study, however has a substantial history.
 • Structuralists (Sapir,") Corpus-based language study In the “pre-Chomskyan era”: • Field linguists (Boas) • Structuralists (Sapir, Newman, Bloomfield, Pike, etc. ) “Corpora” where few paper slips with data. “Shoebox Corpora”: Non-representative. Corpus-based only in that the methodology was empirical and based on observable data.
Corpus-based language study In the “pre-Chomskyan era”: • Field linguists (Boas) • Structuralists (Sapir, Newman, Bloomfield, Pike, etc. ) “Corpora” where few paper slips with data. “Shoebox Corpora”: Non-representative. Corpus-based only in that the methodology was empirical and based on observable data.
 accused the (contemporary) corpus methodology, by reason") The 50 s: the “protests” Chomsky (1962) accused the (contemporary) corpus methodology, by reason of the skewedness of corpora. Non-representative, time consuming, competence vs. performance, Ilanguage vs. E-language Corpora were marginalized.
The 50 s: the “protests” Chomsky (1962) accused the (contemporary) corpus methodology, by reason of the skewedness of corpora. Non-representative, time consuming, competence vs. performance, Ilanguage vs. E-language Corpora were marginalized.
 The revolutionary 60 s With the advances in computer technology the exploitation of massive corpora became feasible. Brown Corpus Brown University Standard Corpus of American Present-day English
The revolutionary 60 s With the advances in computer technology the exploitation of massive corpora became feasible. Brown Corpus Brown University Standard Corpus of American Present-day English
 The 80 s: the boom From the 80 s onwards the number and size of corpora and corpus based studies have increased dramatically. Corpora have revolutionized almost all branches of linguistics.
The 80 s: the boom From the 80 s onwards the number and size of corpora and corpus based studies have increased dramatically. Corpora have revolutionized almost all branches of linguistics.
 A few remarks… Computers… … allow us to speed up the processing of data. … avoid human bias in data analysis … allow the enrichment of data with metadata
A few remarks… Computers… … allow us to speed up the processing of data. … avoid human bias in data analysis … allow the enrichment of data with metadata
 Intuition vs. Corpus Intuition should be applied with caution: • Influence of dialect, sociolect, idiolect… • No universal agreement on (degree of) acceptability • Informants monitor their use of language (non-spontaneous) • Introspection is not observable
Intuition vs. Corpus Intuition should be applied with caution: • Influence of dialect, sociolect, idiolect… • No universal agreement on (degree of) acceptability • Informants monitor their use of language (non-spontaneous) • Introspection is not observable
 Intuition vs. Corpus • Corpus-based approach draws upon authentic or real texts • Computer-based analysis can retrieve differences that intuition alone cannot perceive • Reliable quantitative data
Intuition vs. Corpus • Corpus-based approach draws upon authentic or real texts • Computer-based analysis can retrieve differences that intuition alone cannot perceive • Reliable quantitative data
 Should we dismiss intuition then? Not at all! The key to using corpus data is to find the balance between the use of corpus data and the use of one’s own intuition.
Should we dismiss intuition then? Not at all! The key to using corpus data is to find the balance between the use of corpus data and the use of one’s own intuition.
 Should we dismiss intuition then? Not all research questions can be addressed by the corpus-based approach. Corpus-based approach and intuition -based approach ARE NOT MUTUALLY EXCLUSIVE
Should we dismiss intuition then? Not all research questions can be addressed by the corpus-based approach. Corpus-based approach and intuition -based approach ARE NOT MUTUALLY EXCLUSIVE
![Leech (1991: 14) writes… “[…] Neither the corpus linguist of the 1950 s, who](https://present5.com/presentation/1db767667f976ef26e8f16b8ab8d4a98/image-15.jpg "Leech (1991: 14) writes… “[…] Neither the corpus linguist of the 1950 s, who") Leech (1991: 14) writes… “[…] Neither the corpus linguist of the 1950 s, who rejected intuition, nor the general linguist of the 1960 s, who rejected corpus data, was able to achieve the interaction of data coverage and the insight that characterise the many successful corpus analyses of recent years”.
Leech (1991: 14) writes… “[…] Neither the corpus linguist of the 1950 s, who rejected intuition, nor the general linguist of the 1960 s, who rejected corpus data, was able to achieve the interaction of data coverage and the insight that characterise the many successful corpus analyses of recent years”.
 Is CL a methodology or a theory? No universal agreement. CL is a METHODOLOGY and not an independent branch of linguistics such as semantics, pragmatics, syntax, etc. CL can be employed to explore almost any area of linguistic research.
Is CL a methodology or a theory? No universal agreement. CL is a METHODOLOGY and not an independent branch of linguistics such as semantics, pragmatics, syntax, etc. CL can be employed to explore almost any area of linguistic research.
 Corpus-based or Corpusdriven approaches? Corpus-based approaches are used to “expound, test or exemplify theories and descriptions that were formulated before large corpora became available to inform language study” (Tognini-Bonelli 2001: 65). Therefore, corpus-based linguists are not strictly committed to corpus data and they would discard “inconvenient evidence” by insulation, standardisation and instantiation (i. e. via corpus annotation).
Corpus-based or Corpusdriven approaches? Corpus-based approaches are used to “expound, test or exemplify theories and descriptions that were formulated before large corpora became available to inform language study” (Tognini-Bonelli 2001: 65). Therefore, corpus-based linguists are not strictly committed to corpus data and they would discard “inconvenient evidence” by insulation, standardisation and instantiation (i. e. via corpus annotation).
 Corpus-based or Corpusdriven approaches? Corpus-driven linguists are “strictly committed to the integrity of the data as a whole”. Theoretical statements are fully consistent with, and reflect directly, the evidence provided by the corpus. (Tognini-Bonelli 2001: 84 -85).
Corpus-based or Corpusdriven approaches? Corpus-driven linguists are “strictly committed to the integrity of the data as a whole”. Theoretical statements are fully consistent with, and reflect directly, the evidence provided by the corpus. (Tognini-Bonelli 2001: 84 -85).
 Corpus-based or Corpusdriven approaches? The distinction is overstated, they are 2 idealized extremes. 4 • • basic differences among the 2 approaches: Types of corpora used Attitudes towards theories and intuitions Focuses of research Paradigmatic claims
Corpus-based or Corpusdriven approaches? The distinction is overstated, they are 2 idealized extremes. 4 • • basic differences among the 2 approaches: Types of corpora used Attitudes towards theories and intuitions Focuses of research Paradigmatic claims
 C. B. Approaches C. D. Approaches • Corpus must be representative and balanced • Corpus will balance itself when it grows to be big enough (cumulative representativeness); • Size is not all-important; • Corpus must be very large; • Minimum frequency is used to exclude non-relevant results; • Corpus evidence is exploited fully, but this way the number of the combinations is enormous; • In favour of corpus annotation: CB approaches generally have existing theory as a starting point and correct and revise such theory in the light of corpus evidence; • Against corpus annotation (no preconceived theories) • Distinction between the different levels of language analysis. • No distinction between lexis, syntax, pragmatics, etc. There is only 1 level of language description: the functionally complete unit of meaning or language patterning
C. B. Approaches C. D. Approaches • Corpus must be representative and balanced • Corpus will balance itself when it grows to be big enough (cumulative representativeness); • Size is not all-important; • Corpus must be very large; • Minimum frequency is used to exclude non-relevant results; • Corpus evidence is exploited fully, but this way the number of the combinations is enormous; • In favour of corpus annotation: CB approaches generally have existing theory as a starting point and correct and revise such theory in the light of corpus evidence; • Against corpus annotation (no preconceived theories) • Distinction between the different levels of language analysis. • No distinction between lexis, syntax, pragmatics, etc. There is only 1 level of language description: the functionally complete unit of meaning or language patterning
 We will only refer to CORPUS-BASED APPROACHES A few key notions in Corpus Linguistics…
We will only refer to CORPUS-BASED APPROACHES A few key notions in Corpus Linguistics…
 Representativeness Essential feature of a corpus. Balance (the range of genres included in a corpus) and sampling (how the text chunks for each genre are selected) ensure representativeness.
Representativeness Essential feature of a corpus. Balance (the range of genres included in a corpus) and sampling (how the text chunks for each genre are selected) ensure representativeness.
 Representativeness A corpus is representative if… …the findings based on its contents cane be generalized to the said language variety (Leech 1991); …its samples include the full range of variability in a population (Biber 1993)
Representativeness A corpus is representative if… …the findings based on its contents cane be generalized to the said language variety (Leech 1991); …its samples include the full range of variability in a population (Biber 1993)
: if a corpus is not regularly updated,") Representativeness It changes over time (Hunston 2002): if a corpus is not regularly updated, it rapidly becomes unrepresentative.
Representativeness It changes over time (Hunston 2002): if a corpus is not regularly updated, it rapidly becomes unrepresentative.
:") Representativeness Criteria to select texts for a corpus: • External criteria (Biber’s situational perspective): defined situationally, e. g. genres, registers, text types, etc. • Internal criteria (Biber’s linguistic perspective): defined linguistically, taking into account the distribution of linguistic features. CIRCULAR – because a corpus is typically design to study linguistic distribution, so there is no point in analysing a corpus where distribution of linguistic features is predetermined.
Representativeness Criteria to select texts for a corpus: • External criteria (Biber’s situational perspective): defined situationally, e. g. genres, registers, text types, etc. • Internal criteria (Biber’s linguistic perspective): defined linguistically, taking into account the distribution of linguistic features. CIRCULAR – because a corpus is typically design to study linguistic distribution, so there is no point in analysing a corpus where distribution of linguistic features is predetermined.
: • General corpora") Representativeness 2 main types (for the range of text categories represented): • General corpora – a basis for an overall description of a language (variety); their r. depends on the sampling from a broad range of genres. • Specialized corpora – domain- or genre specific corpora; their r. can be measured by the degree of closure or saturation (lexical features).
Representativeness 2 main types (for the range of text categories represented): • General corpora – a basis for an overall description of a language (variety); their r. depends on the sampling from a broad range of genres. • Specialized corpora – domain- or genre specific corpora; their r. can be measured by the degree of closure or saturation (lexical features).
 Balance The range of text categories included in the corpus: The acceptable b. is determined by the intended uses. A balanced corpus covers a wide range of text categories which are supposed to be representative of the language (variety) under consideration.
Balance The range of text categories included in the corpus: The acceptable b. is determined by the intended uses. A balanced corpus covers a wide range of text categories which are supposed to be representative of the language (variety) under consideration.
 Balance There is no scientific measure for balance. It is more important for sample corpora than for monitor corpora
Balance There is no scientific measure for balance. It is more important for sample corpora than for monitor corpora
 Sampling A corpus is a sample of a given population A sample is representative if what we find for the sample holds for the general population Samples are scaled-down versions of a larger population
Sampling A corpus is a sample of a given population A sample is representative if what we find for the sample holds for the general population Samples are scaled-down versions of a larger population
 Sampling unit: for written text, a s. u. could be a book, periodical or newspaper. Population: the assembly of all sampling units; it can be defined in terms of language production, reception (demographic, sex, age, etc. ) or language as a product (category, genre of language data). Sampling frame: the list of sampling units
Sampling unit: for written text, a s. u. could be a book, periodical or newspaper. Population: the assembly of all sampling units; it can be defined in terms of language production, reception (demographic, sex, age, etc. ) or language as a product (category, genre of language data). Sampling frame: the list of sampling units
 Sampling techniques: • Simple random sampling: all sampling units within the sampling frame are numbered and the sample is chosen by use of a table or random numbers; rare features could not be accounted for. • Stratified random sampling: the population is divided in relatively homogeneous groups, i. e. the strata, and then these latter are sampled at random; never less representative than the former method.
Sampling techniques: • Simple random sampling: all sampling units within the sampling frame are numbered and the sample is chosen by use of a table or random numbers; rare features could not be accounted for. • Stratified random sampling: the population is divided in relatively homogeneous groups, i. e. the strata, and then these latter are sampled at random; never less representative than the former method.
 Sampling Sample size: • Full texts = no balance; peculiarity of individual texts may show through. • Text chunks are sufficient (e. g. 2000 running words): frequent linguistic features are stable in their distribution and hence short text chunks are sufficient for their study (Biber 1993). Text initial, middle and end samples must be balanced.
Sampling Sample size: • Full texts = no balance; peculiarity of individual texts may show through. • Text chunks are sufficient (e. g. 2000 running words): frequent linguistic features are stable in their distribution and hence short text chunks are sufficient for their study (Biber 1993). Text initial, middle and end samples must be balanced.
 Sampling Proportion and number of samples: The number of samples across text categories should be proportional to their frequencies and/or weights in the target population in order for the resulting corpus to be considered as representative
Sampling Proportion and number of samples: The number of samples across text categories should be proportional to their frequencies and/or weights in the target population in order for the resulting corpus to be considered as representative
 What matters is the Research Question! Question Claims of corpus representativeness and balance should be interpreted in relative terms as there is no objective way to balance a corpus or to measure its representativeness. Representativeness is a fluid concept: the research question that one has in mind when building a corpus determines what is an acceptable balance for the corpus one should use and whether it is suitably representative.
What matters is the Research Question! Question Claims of corpus representativeness and balance should be interpreted in relative terms as there is no objective way to balance a corpus or to measure its representativeness. Representativeness is a fluid concept: the research question that one has in mind when building a corpus determines what is an acceptable balance for the corpus one should use and whether it is suitably representative.
 Data collection Spoken data must be transcribed from audio recordings. Written text must be rendered machine-readable by keyboarding or OCR (Optical Character Recognition) scanning. Language data so collected form a RAW CORPUS.
Data collection Spoken data must be transcribed from audio recordings. Written text must be rendered machine-readable by keyboarding or OCR (Optical Character Recognition) scanning. Language data so collected form a RAW CORPUS.
 Corpus Mark-up System of standard codes inserted into a document stored in electronic form to provide information about the text itself and govern formatting, printing and other processes. Most widely used mark-up schemes: • TEI (Text Encoding Initiative) • CES (Corpus Encoding Standard)
Corpus Mark-up System of standard codes inserted into a document stored in electronic form to provide information about the text itself and govern formatting, printing and other processes. Most widely used mark-up schemes: • TEI (Text Encoding Initiative) • CES (Corpus Encoding Standard)
 Corpus Mark-up It is essential in corpus-building because… …sampled texts are out of context and it allows to recover contextual information …it provides more information than the file names alone (re. text types, sociolinguistic variables, textual information – structure) …it ads value to the corpus because it allows for a broader range of questions to be addressed …it allows to insert editorial comments during the corpus building process.
Corpus Mark-up It is essential in corpus-building because… …sampled texts are out of context and it allows to recover contextual information …it provides more information than the file names alone (re. text types, sociolinguistic variables, textual information – structure) …it ads value to the corpus because it allows for a broader range of questions to be addressed …it allows to insert editorial comments during the corpus building process.
 Corpus Mark-up Extra-textual and textual information must be kept separate from the corpus data. Examples: COCOA mark-up scheme A= author, attribute name WILLIAM SHAKESPEARE= attribute value
Corpus Mark-up Extra-textual and textual information must be kept separate from the corpus data. Examples: COCOA mark-up scheme A= author, attribute name WILLIAM SHAKESPEARE= attribute value
 TEI Mark-up Scheme Each individual text is a document consisting in a header and a body, in turn composed of different elements. Ex. in the header there are 4 main elements: • A file description
TEI Mark-up Scheme Each individual text is a document consisting in a header and a body, in turn composed of different elements. Ex. in the header there are 4 main elements: • A file description
 TEI Mark-up Scheme It can be expressed using a number of different formal languages. SGML (Standard Generalized Mark-up Language – used by the BNC) XML (Extensible Mark-up Language)
TEI Mark-up Scheme It can be expressed using a number of different formal languages. SGML (Standard Generalized Mark-up Language – used by the BNC) XML (Extensible Mark-up Language)
 CES Mark-up Scheme Designed specifically for the encoding of language corpora. • Document-wide mark-up (bibliographical descripion, encoding description, etc. ) • Gross structural mark-up (volume, chapter, paragraph, footnotes, etc. ; specifies recommended character sets) • Mark-up for subparagraph structures (sentence, quotations, words, abbreviations, etc. )
CES Mark-up Scheme Designed specifically for the encoding of language corpora. • Document-wide mark-up (bibliographical descripion, encoding description, etc. ) • Gross structural mark-up (volume, chapter, paragraph, footnotes, etc. ; specifies recommended character sets) • Mark-up for subparagraph structures (sentence, quotations, words, abbreviations, etc. )
 CES Mark-up Scheme It specifies a minimal encoding level that corpora must achieve to be considered standardized in terms of descriptive representation as well as general architecture. 3 levels of standardization designed to achieve the goal of universal document interchange: • Metalanguage level • Syntactic level • Semantic level
CES Mark-up Scheme It specifies a minimal encoding level that corpora must achieve to be considered standardized in terms of descriptive representation as well as general architecture. 3 levels of standardization designed to achieve the goal of universal document interchange: • Metalanguage level • Syntactic level • Semantic level
 Corpus Annotation Necessary in order to extract relevant information from corpora. “The process of adding […] interpretive, linguistic information to an electronic corpus of spoken and/or written language data” (Leech 1997)
Corpus Annotation Necessary in order to extract relevant information from corpora. “The process of adding […] interpretive, linguistic information to an electronic corpus of spoken and/or written language data” (Leech 1997)
 Annotation vs. Mark-up Corpus mark-up provides objective, verifiable information. Annotation is concerned with interpretive linguistic information.
Annotation vs. Mark-up Corpus mark-up provides objective, verifiable information. Annotation is concerned with interpretive linguistic information.
 The advantages of annotation 1. It makes extracting information easier, faster and enables human analysts to exploit and retrieve analyses of which they are not themselves capable.
The advantages of annotation 1. It makes extracting information easier, faster and enables human analysts to exploit and retrieve analyses of which they are not themselves capable.
 The advantages of annotation 2. Annotated corpora are reusable resources. 3. Annotated corpora are multifunctional: they can be annotated with a purpose and be reused with another.
The advantages of annotation 2. Annotated corpora are reusable resources. 3. Annotated corpora are multifunctional: they can be annotated with a purpose and be reused with another.
 The advantages of annotation 4. Corpus annotation records a linguistic analysis explicitly. 5. Corpus annotation provides a standard reference resource, a stable base of linguistic analyses, so that successive studies can be compared and contrasted on a common basis.
The advantages of annotation 4. Corpus annotation records a linguistic analysis explicitly. 5. Corpus annotation provides a standard reference resource, a stable base of linguistic analyses, so that successive studies can be compared and contrasted on a common basis.
 Criticisms to corpus annotation 1. Annotation produces cluttered corpora 2. Annotation imposes an analysis 3. Annotation overvalues corpora making them less accessible 4. Is annotation accurate and consistent?
Criticisms to corpus annotation 1. Annotation produces cluttered corpora 2. Annotation imposes an analysis 3. Annotation overvalues corpora making them less accessible 4. Is annotation accurate and consistent?
 How are corpora annotated? • Automatic annotation • Computer-assisted annotation • Manual annotation Sinclair (1992): the introduction of the human element in corpus annotation reduces consistency.
How are corpora annotated? • Automatic annotation • Computer-assisted annotation • Manual annotation Sinclair (1992): the introduction of the human element in corpus annotation reduces consistency.
 Types of annotation Different types of annotation can be carried out with different means. For some types automatic annotation is very accurate. Other types require post-editing, i. e. human correction.
Types of annotation Different types of annotation can be carried out with different means. For some types automatic annotation is very accurate. Other types require post-editing, i. e. human correction.
 Types of annotation Corpora can be annotated at different levels of linguistic analysis. • Phonological level – Syllable boundaries (phonetic/phonemic annotation) – Prosodic features (prosodic annotation)
Types of annotation Corpora can be annotated at different levels of linguistic analysis. • Phonological level – Syllable boundaries (phonetic/phonemic annotation) – Prosodic features (prosodic annotation)
") Types of annotation • Morphological level – Prefixes – Suffixes – Stems (morphological annotation)
Types of annotation • Morphological level – Prefixes – Suffixes – Stems (morphological annotation)
 – Lemmas") Types of annotation • Lexical level – Part of speech (POS Tagging) – Lemmas (lemmatization) – Semantic fields (semantic annotation) • Syntactic level – parsing – treebanking – bracketing
Types of annotation • Lexical level – Part of speech (POS Tagging) – Lemmas (lemmatization) – Semantic fields (semantic annotation) • Syntactic level – parsing – treebanking – bracketing
 – Speech acts") Types of annotation • Discourse level – Anaphoric relations (coreference annotation) – Speech acts (pragmatic annotation) – Stylistic features such as speech and thought in presentation (stylistic annotation).
Types of annotation • Discourse level – Anaphoric relations (coreference annotation) – Speech acts (pragmatic annotation) – Stylistic features such as speech and thought in presentation (stylistic annotation).
 POS Tagging POS is the most common type of annotation. Also known as grammatical tagging or morpho-syntactic annotation. It provides the basis of further forms of analysis such as parsing and semantic annotation. Many linguistic analyses, e. g. the collocates of a word depend heavily on POS tagging.
POS Tagging POS is the most common type of annotation. Also known as grammatical tagging or morpho-syntactic annotation. It provides the basis of further forms of analysis such as parsing and semantic annotation. Many linguistic analyses, e. g. the collocates of a word depend heavily on POS tagging.
 POS Tagging It can be performed automatically with taggers like CLAWS http: //www. comp. lancs. ac. uk/ucrel/claws/ You can try it for free online. Examples of tags: NN 1 (noun), VVZ (verb in the third person of the simple present tense), VVD (verb in the simple past form), ADJ 0 (adjective in the basic form), etc.
POS Tagging It can be performed automatically with taggers like CLAWS http: //www. comp. lancs. ac. uk/ucrel/claws/ You can try it for free online. Examples of tags: NN 1 (noun), VVZ (verb in the third person of the simple present tense), VVD (verb in the simple past form), ADJ 0 (adjective in the basic form), etc.
 – Multiwords (so that, inspite of) –") POS Tagging Problems: • Word segmentation (tokenization) – Multiwords (so that, inspite of) – Mergers (can’t, gonna) – Variably spelled compounds (noticeboard, notice-board, notice board)
POS Tagging Problems: • Word segmentation (tokenization) – Multiwords (so that, inspite of) – Mergers (can’t, gonna) – Variably spelled compounds (noticeboard, notice-board, notice board)
 Lemmatization Type of annotation that reduces the inflextional variants of words to their respective lexemes or lemmas as they appear in dictionary entries: Do, does, did, done, doing= DO Corpus, corpora= CORPUS Small capital letters are the convention.
Lemmatization Type of annotation that reduces the inflextional variants of words to their respective lexemes or lemmas as they appear in dictionary entries: Do, does, did, done, doing= DO Corpus, corpora= CORPUS Small capital letters are the convention.
 Lemmatization It is important in vocabulary studies and lexicography, e. g. in studying the distribution pattern of lexemes and improving dictionaries and computer lexicons. It can be automatically performed.
Lemmatization It is important in vocabulary studies and lexicography, e. g. in studying the distribution pattern of lexemes and improving dictionaries and computer lexicons. It can be automatically performed.
 Parsing Once a corpus is POS tagged, it is possible to bring these morphosyntactic categories into higher level syntactic relationships with one another, that is, to analyse the sentences in a corpus into their constituents. Parsing consists in bracketing. It can be automated but with a low precision rate.
Parsing Once a corpus is POS tagged, it is possible to bring these morphosyntactic categories into higher level syntactic relationships with one another, that is, to analyse the sentences in a corpus into their constituents. Parsing consists in bracketing. It can be automated but with a low precision rate.
 visited) (NP a (ADJP very nice) boy)))") Parsing Example: (S (NP (VP Mary) visited) (NP a (ADJP very nice) boy)))
Parsing Example: (S (NP (VP Mary) visited) (NP a (ADJP very nice) boy)))
 Semantic annotation It assigns codes indicating the semantic features of the semantic fields of the words in a text. It is knowledge-based so it needs to be manual most of the time. Two types: – One marks the semantic relationships between the constituents in a sentence – One marks the semantic features of words in a text
Semantic annotation It assigns codes indicating the semantic features of the semantic fields of the words in a text. It is knowledge-based so it needs to be manual most of the time. Two types: – One marks the semantic relationships between the constituents in a sentence – One marks the semantic features of words in a text
 Coreference annotation • Pronouns • Repetition • Substitution • Ellipsis Computer-assisted at best.
Coreference annotation • Pronouns • Repetition • Substitution • Ellipsis Computer-assisted at best.
 Pragmatic annotation • Speech/dialogue acts in domain-specific dialogue. The most coherent system is DRI (Discourse Representation Initiative). 3 layers of coding: – Segmentation (dividing dialogue in textual units, utterances) – Functional annotation (dialogue act annotation) – Utterance tags (applying utterance tags that characterize the role of the utterance as a dialogue act)
Pragmatic annotation • Speech/dialogue acts in domain-specific dialogue. The most coherent system is DRI (Discourse Representation Initiative). 3 layers of coding: – Segmentation (dividing dialogue in textual units, utterances) – Functional annotation (dialogue act annotation) – Utterance tags (applying utterance tags that characterize the role of the utterance as a dialogue act)
 – Information level") Pragmatic annotation Utterance tags: – Communicative status (intelligible, complete, etc. ) – Information level and status (indicating the semantic content of the utterance and how it relates to the task in question) – Forward-looking communicative function (utterances that may constrain or affect the discourse, e. g. assert, request, question and offer) – Backwarding-looking communicative function (utterances that relate to previous parts of the discourse, e. g. accept, backchannelling, answer)
Pragmatic annotation Utterance tags: – Communicative status (intelligible, complete, etc. ) – Information level and status (indicating the semantic content of the utterance and how it relates to the task in question) – Forward-looking communicative function (utterances that may constrain or affect the discourse, e. g. assert, request, question and offer) – Backwarding-looking communicative function (utterances that relate to previous parts of the discourse, e. g. accept, backchannelling, answer)
 Stylistic annotation It is particularly associated with stylistic features in literary texts. An example: the representation of people’s speech and thoughts, known as speech ad thought presentation (S&TP)
Stylistic annotation It is particularly associated with stylistic features in literary texts. An example: the representation of people’s speech and thoughts, known as speech ad thought presentation (S&TP)
 Other types of tagging • Error tagging • Problem-oriented annotation
Other types of tagging • Error tagging • Problem-oriented annotation
 Types of corpora • Multilingual • Monolingual
Types of corpora • Multilingual • Monolingual
: Canadian Hansard • Comparable corpora") Multilingual Corpora • Parallel corpora (source texts plus translations): Canadian Hansard • Comparable corpora (monolingual subcorpora designed using the sampling techniques): Aahrus corpus of contract law – Multilingual – Bilingual
Multilingual Corpora • Parallel corpora (source texts plus translations): Canadian Hansard • Comparable corpora (monolingual subcorpora designed using the sampling techniques): Aahrus corpus of contract law – Multilingual – Bilingual
 Multilingual Corpora Important resources for translation and contrastive studies. Multilingual corpora… • …give new insight into the language compared • …can be used to study language specific and universal features • …illuminate differences between source texts and translations • …can be used for a number of practical applications, in lexicography, language teaching, translation, etc.
Multilingual Corpora Important resources for translation and contrastive studies. Multilingual corpora… • …give new insight into the language compared • …can be used to study language specific and universal features • …illuminate differences between source texts and translations • …can be used for a number of practical applications, in lexicography, language teaching, translation, etc.
 Parallel Corpora • Bilingual vs. Multilingual • Unidirectional (from La to Lb or from Lb to Lc alone) vs. Bidirectional (from La to Lb and from Lb to La) vs. Multidirectional (from La to Lb, Lc etc. )
Parallel Corpora • Bilingual vs. Multilingual • Unidirectional (from La to Lb or from Lb to Lc alone) vs. Bidirectional (from La to Lb and from Lb to La) vs. Multidirectional (from La to Lb, Lc etc. )
 Comparable corpora A corpus containing components that are collected using the sampling techniques and similar balance and representativeness, e. g. the same proportions of the texts of the same genres in the same domains in a range of different languages in the sampling period.
Comparable corpora A corpus containing components that are collected using the sampling techniques and similar balance and representativeness, e. g. the same proportions of the texts of the same genres in the same domains in a range of different languages in the sampling period.
 Comparable vs. parallel corpora The sampling frame is essential for comparable corpora but not for parallel corpora because the texts are exact translations of each other.
Comparable vs. parallel corpora The sampling frame is essential for comparable corpora but not for parallel corpora because the texts are exact translations of each other.
 Corpus Alignment In order for us to be able to fully exploit parallel corpora, they need to be aligned. Different types of alignment: • Word-level alignment • Sentence-level alignment • Paragraph alignment
Corpus Alignment In order for us to be able to fully exploit parallel corpora, they need to be aligned. Different types of alignment: • Word-level alignment • Sentence-level alignment • Paragraph alignment
 • The American National") General Corpora • British National Corpus (100, 106, 008 words) • The American National Corpus • ICE-CUP
General Corpora • British National Corpus (100, 106, 008 words) • The American National Corpus • ICE-CUP
 Specialized Corpora • Guangzhou Petroleum English Corpus (411, 612 words of written English from the petrochemical domain) • HKUST Computer Science Corpus (1, 000 words of written English sampled from undergraduate textbooks in computer science. • CPSA (Corpus of Professional Spoken American English) • MICASE (1, 700, 000 words of English spoken in the academic domain)
Specialized Corpora • Guangzhou Petroleum English Corpus (411, 612 words of written English from the petrochemical domain) • HKUST Computer Science Corpus (1, 000 words of written English sampled from undergraduate textbooks in computer science. • CPSA (Corpus of Professional Spoken American English) • MICASE (1, 700, 000 words of English spoken in the academic domain)
 • LOB Corpus (Comparable") Written Corpora • BROWN Corpus (written texts, AE in 1961) • LOB Corpus (Comparable to BROWN Corpus, BE, early 1960 s) • FROWN Corpus (AE, Early 1990 s) • FLOB Corpus (BE, Early 1990’s)
Written Corpora • BROWN Corpus (written texts, AE in 1961) • LOB Corpus (Comparable to BROWN Corpus, BE, early 1960 s) • FROWN Corpus (AE, Early 1990 s) • FLOB Corpus (BE, Early 1990’s)
 • Lancaster/IBM Spoken English Corpus (SEC) • Cambridge") Spoken Corpora • London-Lund Corpus (LLC) • Lancaster/IBM Spoken English Corpus (SEC) • Cambridge and Nottingham Corpus of Discourse in English (CANCODE) • Santa Barbara Corpus of Spoken American English (SBCSAE) • Wellington Corpus of Spoken New Zealand English (WSC)
Spoken Corpora • London-Lund Corpus (LLC) • Lancaster/IBM Spoken English Corpus (SEC) • Cambridge and Nottingham Corpus of Discourse in English (CANCODE) • Santa Barbara Corpus of Spoken American English (SBCSAE) • Wellington Corpus of Spoken New Zealand English (WSC)
 Synchronic Corpora Useful to compare varieties of English. Texts date all to the same period. • Brown and Lob • Frown and Flob • International Corpus of English (ICE) (Texts produced after 1989) • BNC
Synchronic Corpora Useful to compare varieties of English. Texts date all to the same period. • Brown and Lob • Frown and Flob • International Corpus of English (ICE) (Texts produced after 1989) • BNC
 Diachronic Corpora Texts date to different periods in time. Ideal to study language change and history. • Brown/Frown • Lob/Flob • Helsinki Diachronic Corpus of English Texts (8 th-18 th century) • Archer Corpus – A representative Corpus of Historical English Registers (BE and AE, 1650 -1990).
Diachronic Corpora Texts date to different periods in time. Ideal to study language change and history. • Brown/Frown • Lob/Flob • Helsinki Diachronic Corpus of English Texts (8 th-18 th century) • Archer Corpus – A representative Corpus of Historical English Registers (BE and AE, 1650 -1990).
") Learner/developmental Corpora Lstr or L 2 acquisition/L 1 acquired by children • CHILDES (DC) • International Corpus of Learner English – ICLE (LC) • Cambridge Learner Corpus (LC)
Learner/developmental Corpora Lstr or L 2 acquisition/L 1 acquired by children • CHILDES (DC) • International Corpus of Learner English – ICLE (LC) • Cambridge Learner Corpus (LC)
 Monitor Corpora Constantly supplemented with fresh material and keep increasing in size, though the proportion of text types included in the corpus remains constant. • Bank of English (Bo. E) • Global English Monitor Corpus • AVIATOR
Monitor Corpora Constantly supplemented with fresh material and keep increasing in size, though the proportion of text types included in the corpus remains constant. • Bank of English (Bo. E) • Global English Monitor Corpus • AVIATOR
 is a 100 million word collection of") The BNC The British National Corpus (BNC) is a 100 million word collection of samples of written and spoken language from a wide range of sources, designed to represent a wide cross-section of current British English, both spoken and written.
The BNC The British National Corpus (BNC) is a 100 million word collection of samples of written and spoken language from a wide range of sources, designed to represent a wide cross-section of current British English, both spoken and written.
 includes, for example, extracts from") The BNC The written part of the BNC (90%) includes, for example, extracts from regional and national newspapers, specialist periodicals and journals for all ages and interests, academic books and popular fiction, published and unpublished letters and memoranda, school and university essays, etc. The spoken part (10%) includes a large amount of unscripted informal conversation, recorded by volunteers selected from different age, region and social classes in a demographically balanced way, together with spoken language collected in all kinds of different contexts, ranging from formal business or government meetings to radio shows and phone-ins.
The BNC The written part of the BNC (90%) includes, for example, extracts from regional and national newspapers, specialist periodicals and journals for all ages and interests, academic books and popular fiction, published and unpublished letters and memoranda, school and university essays, etc. The spoken part (10%) includes a large amount of unscripted informal conversation, recorded by volunteers selected from different age, region and social classes in a demographically balanced way, together with spoken language collected in all kinds of different contexts, ranging from formal business or government meetings to radio shows and phone-ins.
 The BNC The corpus is encoded according to the Guidelines of the Text Encoding Initiative (TEI) to represent both the output from CLAWS (automatic part-of-speech tagger) and a variety of other structural properties of texts (e. g. headings, paragraphs, lists etc. ). Full classification, contextual and bibliographic information is also included with each text in the form of a TEI-conformant header.
The BNC The corpus is encoded according to the Guidelines of the Text Encoding Initiative (TEI) to represent both the output from CLAWS (automatic part-of-speech tagger) and a variety of other structural properties of texts (e. g. headings, paragraphs, lists etc. ). Full classification, contextual and bibliographic information is also included with each text in the form of a TEI-conformant header.
 What sort of corpus is the BNC? Monolingual: It deals with modern British English, not other languges used in Britain. However non-British English and foreign language words do occur in the corpus. Synchronic: It covers British English of the late twentieth century, rather than the historical development which produced it. General: It includes many different styles and varieties, and is not limited to any particular subject field, genre or register. In particular, it contains examples of both spoken and written language. Sample: For written sources, samples of 45, 000 words are taken from various parts of single-author texts. Shorter texts up to a maximum of 45, 000 words, or multi-author texts such as magazines and newspapers, are included in full. Sampling allows for a wider coverage of texts within the 100 million limit, and avoids over-representing idiosyncratic texts.
What sort of corpus is the BNC? Monolingual: It deals with modern British English, not other languges used in Britain. However non-British English and foreign language words do occur in the corpus. Synchronic: It covers British English of the late twentieth century, rather than the historical development which produced it. General: It includes many different styles and varieties, and is not limited to any particular subject field, genre or register. In particular, it contains examples of both spoken and written language. Sample: For written sources, samples of 45, 000 words are taken from various parts of single-author texts. Shorter texts up to a maximum of 45, 000 words, or multi-author texts such as magazines and newspapers, are included in full. Sampling allows for a wider coverage of texts within the 100 million limit, and avoids over-representing idiosyncratic texts.
 BNC and Sketchengine Sketch Engine is an excellent userinterface to query the BNC. Here are some screenshots.
BNC and Sketchengine Sketch Engine is an excellent userinterface to query the BNC. Here are some screenshots.
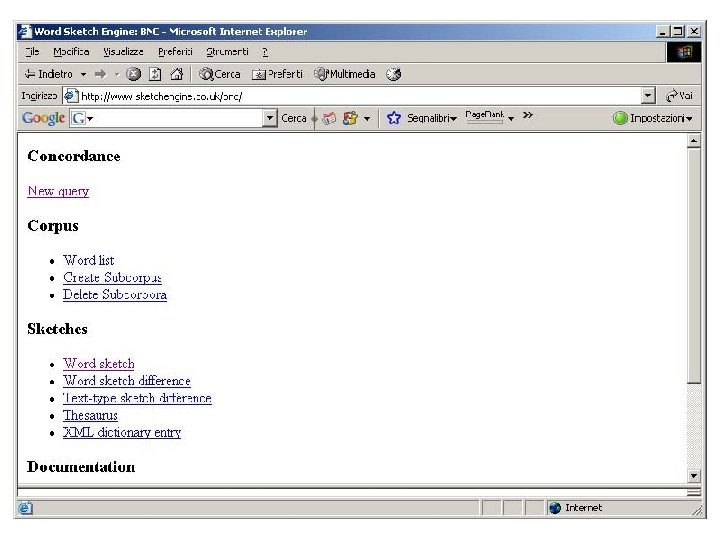
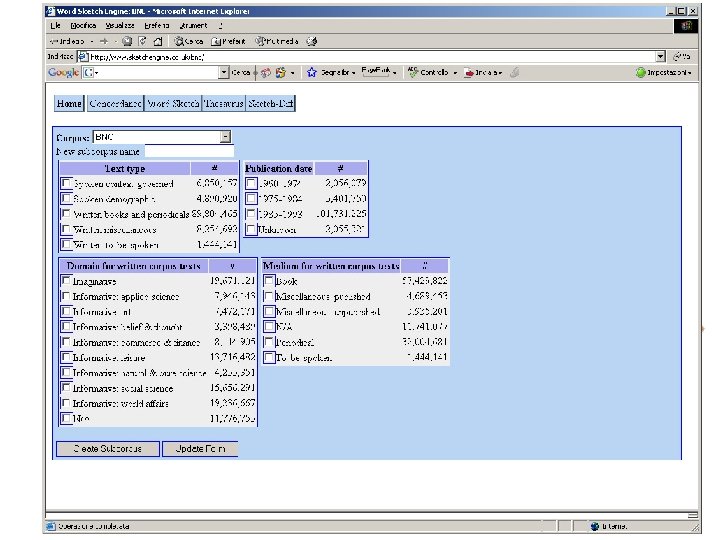
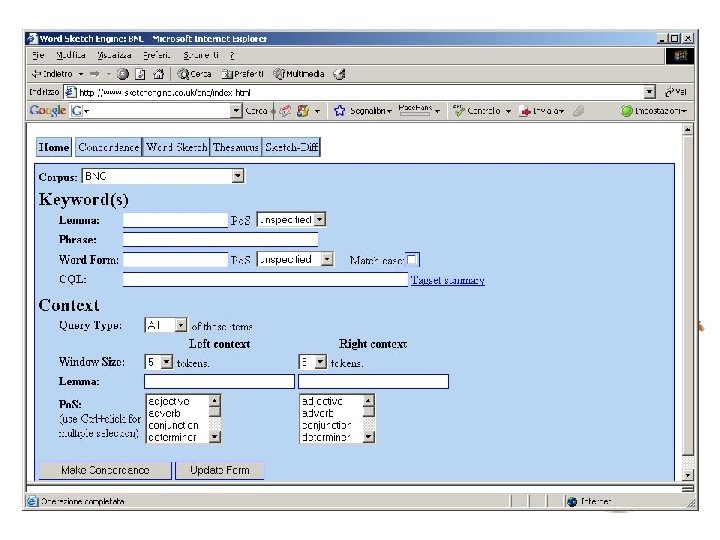
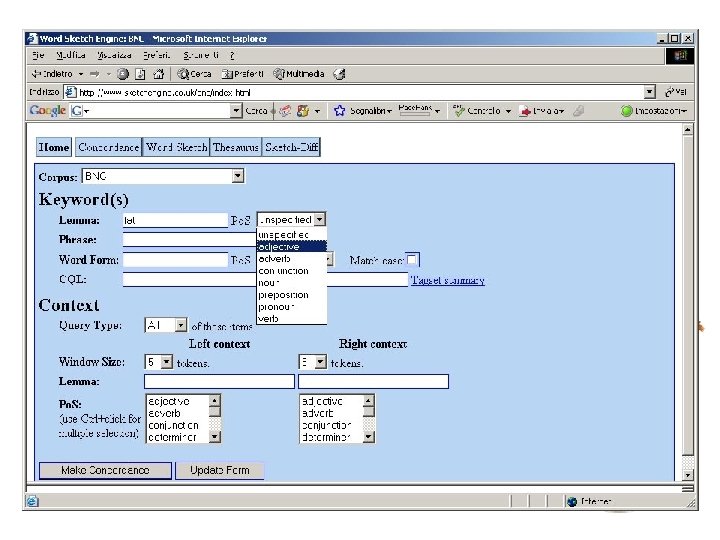
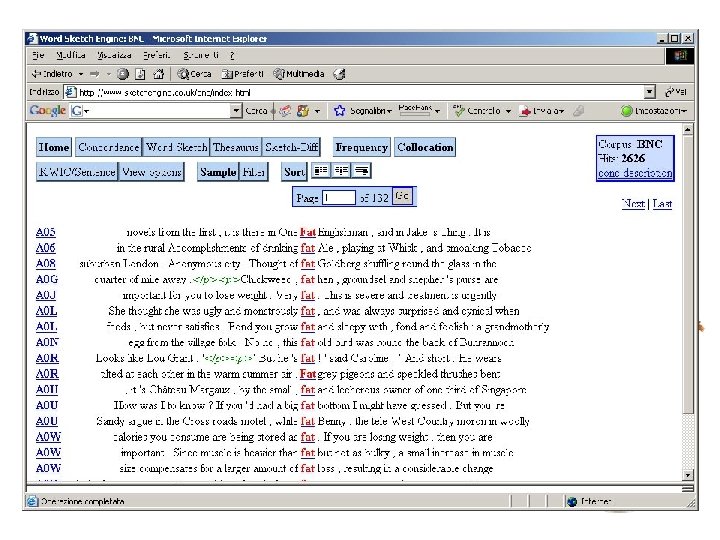
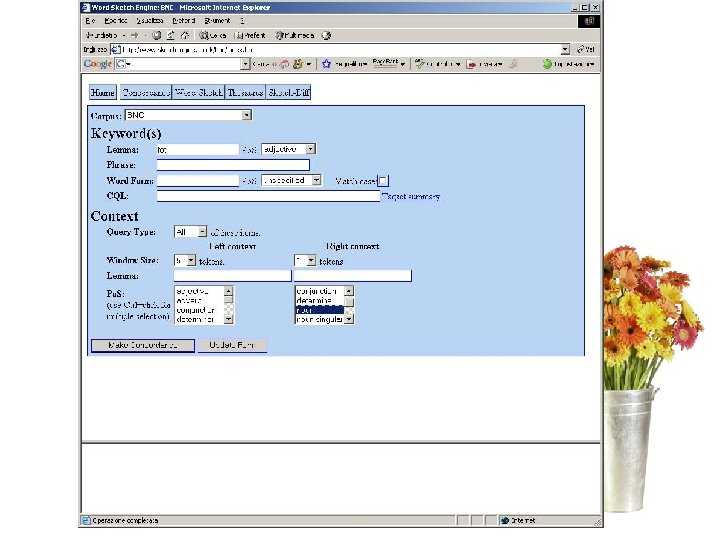
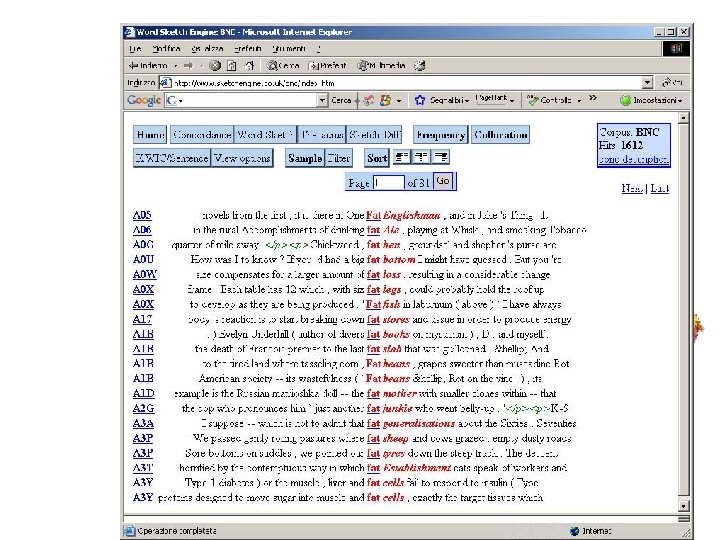
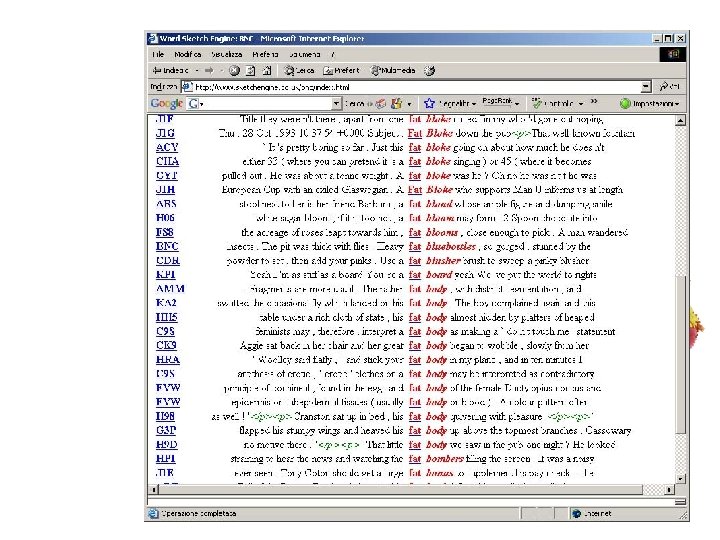
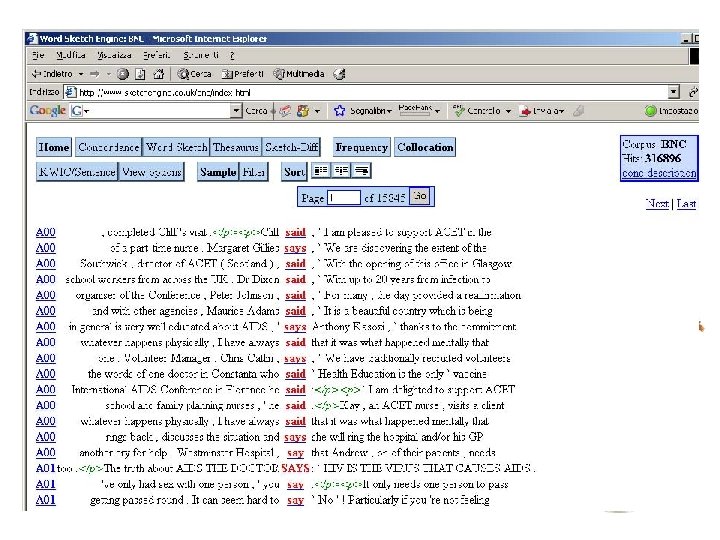
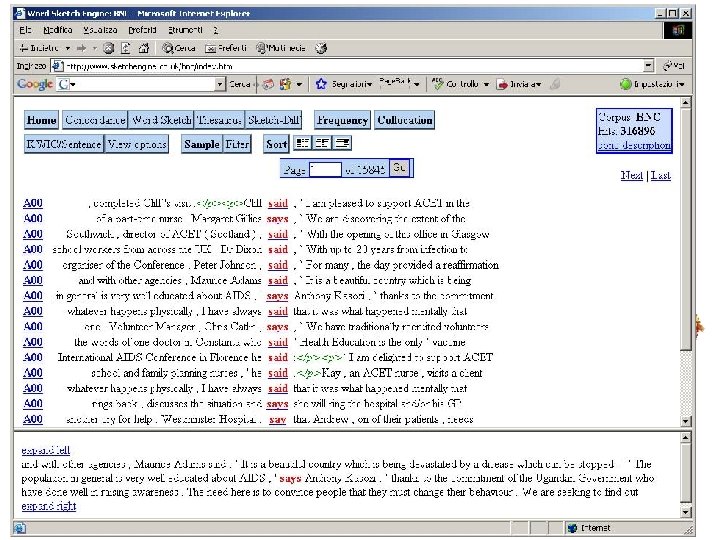
 An example of a POS-tagged text I've been giving some thought to the whole idea of writing a book as of late (I've also been giving some thought to winning the lottery, and we can all see where that's got me) and it came to me while showering the other night that if I were to ever write a book (which ain't gonna happen, but let's just say for the sake of argument) I would bill myself as the anti-Francis Mayes.
An example of a POS-tagged text I've been giving some thought to the whole idea of writing a book as of late (I've also been giving some thought to winning the lottery, and we can all see where that's got me) and it came to me while showering the other night that if I were to ever write a book (which ain't gonna happen, but let's just say for the sake of argument) I would bill myself as the anti-Francis Mayes.
 An example of a POS-tagged text I_PNP 've_VHB been_VBN giving_VVG some_DT 0 thought_NN 1 to_PRP the_AT 0 whole_AJ 0 idea_NN 1 of_PRF writing_VVG a_AT 0 book_NN 1 as_PRP 21 of_PRP 22 late_AJ 0 (_( I_PNP 've_VHB also_AV 0 been_VBN giving_VVG some_DT 0 thought_NN 1 to_PRP winning_VVG the_AT 0 lottery_NN 1 , _, and_CJC we_PNP can_VM 0 all_DT 0 see_VVI where_AVQ that_DT 0 's_VHZ got_VVN me_PNP )_) and_CJC it_PNP came_VVD to_PRP me_PNP while_CJS showering_VVG the_AT 0 other_AJ 0 night_NN 1 that_CJT if_CJS I_PNP were_VBD to_TO 0 ever_AV 0 write_VVI a_AT 0 book_NN 1 (_( which_DTQ ai_UNC n't_XX 0 gon_VVG na_TO 0 happen_VVI , _, but_CJC let_VM 021 's_VM 022 just_AV 0 say_VVI for_PRP the_AT 0 sake_NN 1 of_PRF argument_NN 1 )_) I_PNP would_VM 0 bill_NN 1 myself_PNX as_PRP the_AT 0 anti-Francis_AJ 0 Mayes_NP 0. _.
An example of a POS-tagged text I_PNP 've_VHB been_VBN giving_VVG some_DT 0 thought_NN 1 to_PRP the_AT 0 whole_AJ 0 idea_NN 1 of_PRF writing_VVG a_AT 0 book_NN 1 as_PRP 21 of_PRP 22 late_AJ 0 (_( I_PNP 've_VHB also_AV 0 been_VBN giving_VVG some_DT 0 thought_NN 1 to_PRP winning_VVG the_AT 0 lottery_NN 1 , _, and_CJC we_PNP can_VM 0 all_DT 0 see_VVI where_AVQ that_DT 0 's_VHZ got_VVN me_PNP )_) and_CJC it_PNP came_VVD to_PRP me_PNP while_CJS showering_VVG the_AT 0 other_AJ 0 night_NN 1 that_CJT if_CJS I_PNP were_VBD to_TO 0 ever_AV 0 write_VVI a_AT 0 book_NN 1 (_( which_DTQ ai_UNC n't_XX 0 gon_VVG na_TO 0 happen_VVI , _, but_CJC let_VM 021 's_VM 022 just_AV 0 say_VVI for_PRP the_AT 0 sake_NN 1 of_PRF argument_NN 1 )_) I_PNP would_VM 0 bill_NN 1 myself_PNX as_PRP the_AT 0 anti-Francis_AJ 0 Mayes_NP 0. _.