

Доклад кригинг.ppt
- Количество слайдов: 70
 Интерполяция • Интерполяция - это восстановление функции в промежуточной точке по известным её значениям в соседних точках, эти точки Хi и Yi, i=0, 1, 2, …, n называют узлами интерполяции, а функцию – интерполирующей или интерполянтом.
Интерполяция • Интерполяция - это восстановление функции в промежуточной точке по известным её значениям в соседних точках, эти точки Хi и Yi, i=0, 1, 2, …, n называют узлами интерполяции, а функцию – интерполирующей или интерполянтом.
 Все методы интерполяции делятся на 2 группы: детерминированные • геостатистические.
Все методы интерполяции делятся на 2 группы: детерминированные • геостатистические.
 • Геостатистические методы базируются на математических и на статистических функциях, которые могут быть использованы для построения поверхностей и оценки точности прогнозов. • Методы детерминированной интерполяции создают поверхности из измеренных точек, основываясь или на степени схожести (обратные взвешенные расстояния), или уровне сглаживания (радиальные базисные функции). • Детерминированные методы для интерполяции используют математические функции (зависимости).
• Геостатистические методы базируются на математических и на статистических функциях, которые могут быть использованы для построения поверхностей и оценки точности прогнозов. • Методы детерминированной интерполяции создают поверхности из измеренных точек, основываясь или на степени схожести (обратные взвешенные расстояния), или уровне сглаживания (радиальные базисные функции). • Детерминированные методы для интерполяции используют математические функции (зависимости).
 Группы детерминированных методов • Локальные методы вычисляют проинтерполированные значения на основании измеренных точек в пределах окрестностей, которые являются меньшими пространственными областями внутри большей изучаемой территории. • Глобальные методы вычисляют проинтерполированн ые значения на основании всего набора данных
Группы детерминированных методов • Локальные методы вычисляют проинтерполированные значения на основании измеренных точек в пределах окрестностей, которые являются меньшими пространственными областями внутри большей изучаемой территории. • Глобальные методы вычисляют проинтерполированн ые значения на основании всего набора данных
 Классы методов построения • Методы построения сеточных функций, реализованные в пакете Surfer, можно разбить на два класса: интерполирующие и сглаживающие.
Классы методов построения • Методы построения сеточных функций, реализованные в пакете Surfer, можно разбить на два класса: интерполирующие и сглаживающие.
 • Метод интерполяции, который вычисляет значение идентичное измеренному в опорном местоположении, называется жестким интерполятором • Обратные взвешенные расстояния и радиальные базисные функции • Нежесткий интерполятор вычисляет значение, которое отличается от измеренного. Последний можно использовать с целью избежать возникновения острых вершин или углублений на выходной поверхности. • глобальный полином, локальный полином, интерполяция ядра с барьерами и интерполяция диффузии с барьерами
• Метод интерполяции, который вычисляет значение идентичное измеренному в опорном местоположении, называется жестким интерполятором • Обратные взвешенные расстояния и радиальные базисные функции • Нежесткий интерполятор вычисляет значение, которое отличается от измеренного. Последний можно использовать с целью избежать возникновения острых вершин или углублений на выходной поверхности. • глобальный полином, локальный полином, интерполяция ядра с барьерами и интерполяция диффузии с барьерами
 Сглаживающие методы • Используются в тех случаях, когда экспериментальные данные измерены в узлах сетки не точно, а с некоторой погрешностью. Сглаживающие методы не присваивают весов равных единице, даже тем значениям, которые совпадают с узлами сетки.
Сглаживающие методы • Используются в тех случаях, когда экспериментальные данные измерены в узлах сетки не точно, а с некоторой погрешностью. Сглаживающие методы не присваивают весов равных единице, даже тем значениям, которые совпадают с узлами сетки.
,") В пакете Surfer интерполяторами являются: • Метод обратных расстояний (Inverse Distance to a Power), если не задан сглаживающий параметр; • Метод Криге (Kriging), если не задан параметр Nugget Effect; • Метод радиальных базисных функций (Radial Basis Functions), если не задан параметр RI; • Метод Шепарда (Shepard’s method), если не задан сглаживающий параметр; • Триангуляция с линейной интерполяцией (Triangulation with linear Interpolation).
В пакете Surfer интерполяторами являются: • Метод обратных расстояний (Inverse Distance to a Power), если не задан сглаживающий параметр; • Метод Криге (Kriging), если не задан параметр Nugget Effect; • Метод радиальных базисных функций (Radial Basis Functions), если не задан параметр RI; • Метод Шепарда (Shepard’s method), если не задан сглаживающий параметр; • Триангуляция с линейной интерполяцией (Triangulation with linear Interpolation).
 В пакете Surfer сглаживающими методами являются: • Метод обратных расстояний (Inverse Distance to a Power), если задан сглаживающий параметр; • Метод Kriging, если задан параметр Nugget Effect; • Метод минимальной кривизны (Minimum Curvature); • Метод полиномиальной регрессии (Polynomial Regression); • Метод Radial Basis Functions, если задан параметр RI; • Метод Shepard's Method, если задан сглаживающий параметр.
В пакете Surfer сглаживающими методами являются: • Метод обратных расстояний (Inverse Distance to a Power), если задан сглаживающий параметр; • Метод Kriging, если задан параметр Nugget Effect; • Метод минимальной кривизны (Minimum Curvature); • Метод полиномиальной регрессии (Polynomial Regression); • Метод Radial Basis Functions, если задан параметр RI; • Метод Shepard's Method, если задан сглаживающий параметр.
 Краткое описание методов
Краткое описание методов
 Метод обратных расстояний • The inverse distance method uses a "simple" distance weighted averaging method to calculate grid node values. It does not extrapolate values beyond those found in the data file, but it tends to draw circles or bulls-eyes around each data point. • Является достаточно быстрым, но имеет тенденцию генерировать структуры вокруг точек наблюдений с высокими значениями функции.
Метод обратных расстояний • The inverse distance method uses a "simple" distance weighted averaging method to calculate grid node values. It does not extrapolate values beyond those found in the data file, but it tends to draw circles or bulls-eyes around each data point. • Является достаточно быстрым, но имеет тенденцию генерировать структуры вокруг точек наблюдений с высокими значениями функции.
 Кригинг • • The kriging method uses trends in the map to extrapolate into areas of no data, sometimes resulting in minimum and maximum Z values in the grid that are beyond the values in the data file. This could be acceptable in a structure map or topography map, but not in an isopach map where the extrapolation produces negative thickness values. На множествах большого размера он работает достаточно медленно.
Кригинг • • The kriging method uses trends in the map to extrapolate into areas of no data, sometimes resulting in minimum and maximum Z values in the grid that are beyond the values in the data file. This could be acceptable in a structure map or topography map, but not in an isopach map where the extrapolation produces negative thickness values. На множествах большого размера он работает достаточно медленно.
 Метод минимальной кривизны • The minimum curvature method attempts to fit a surface to all the data values using an iterative approach. One drawback to this method is a tendency to "blow up", or extrapolate extremely large or small values, in areas of no data. Minimum curvature can extrapolate values beyond your data’s Z range. • Генерирует гладкие поверхности и для большинства множеств экспериментальных данных работает достаточно быстро.
Метод минимальной кривизны • The minimum curvature method attempts to fit a surface to all the data values using an iterative approach. One drawback to this method is a tendency to "blow up", or extrapolate extremely large or small values, in areas of no data. Minimum curvature can extrapolate values beyond your data’s Z range. • Генерирует гладкие поверхности и для большинства множеств экспериментальных данных работает достаточно быстро.
 Метод ближайшего соседа • The nearest neighbor method uses the nearest point to assign a value to a grid node. It is useful for converting regularly spaced (or almost regularly spaced) XYZ data files into grid files. This method does not extrapolate Z grid values beyond the range of the data. • Всем ближайшим соседям присваивается определённый вес, для всех остальных точек вес равен 0
Метод ближайшего соседа • The nearest neighbor method uses the nearest point to assign a value to a grid node. It is useful for converting regularly spaced (or almost regularly spaced) XYZ data files into grid files. This method does not extrapolate Z grid values beyond the range of the data. • Всем ближайшим соседям присваивается определённый вес, для всех остальных точек вес равен 0
 Метод естественного соседа • The natural neighbor gridding method uses a weighted average of the neighboring observations. This method generates good contours from data sets containing dense data in some areas and sparse data in other areas. It does not generate data in areas without data and does not extrapolate Z grid values beyond the range of the data.
Метод естественного соседа • The natural neighbor gridding method uses a weighted average of the neighboring observations. This method generates good contours from data sets containing dense data in some areas and sparse data in other areas. It does not generate data in areas without data and does not extrapolate Z grid values beyond the range of the data.
 Метод Шеппарда • The modified Shepard's method attempts to combine the inverse distance method with a spline smoothing algorithm. It tends to accentuate the bulls-eye effect of the inverse distance method. It can extrapolate values beyond your data’s Z range. • Подобен методу обратных расстояний, но как правило, не генерирует структуры типа "бычий глаз", особенно когда задан сглаживающий параметр.
Метод Шеппарда • The modified Shepard's method attempts to combine the inverse distance method with a spline smoothing algorithm. It tends to accentuate the bulls-eye effect of the inverse distance method. It can extrapolate values beyond your data’s Z range. • Подобен методу обратных расстояний, но как правило, не генерирует структуры типа "бычий глаз", особенно когда задан сглаживающий параметр.
 Триангуляция с линейной интерполяцией • The triangulation with linear interpolation method computes a unique set of triangles from the data points, and uses linear interpolation within each triangle for the calculation of the grid nodes. It tends to produce angular contours for small data sets, but it can often handle difficult situations, such as man-made features like terraces and pits. This method does not extrapolate Z values beyond the range of data.
Триангуляция с линейной интерполяцией • The triangulation with linear interpolation method computes a unique set of triangles from the data points, and uses linear interpolation within each triangle for the calculation of the grid nodes. It tends to produce angular contours for small data sets, but it can often handle difficult situations, such as man-made features like terraces and pits. This method does not extrapolate Z values beyond the range of data.
 • The local polynomial gridding method is most applicable to data sets that are locally smooth (i. e. relatively smooth surfaces within the search neighborhoods).
• The local polynomial gridding method is most applicable to data sets that are locally smooth (i. e. relatively smooth surfaces within the search neighborhoods).
 • The polynomial regression • The moving average is most method processes the data so applicable to large and very that underlying large-scale large data sets (e. g. >1000 trends and patterns are shown. data points). It extracts This is used for trend surface intermediate-scale trends and analysis. This method can variations from large noisy data extrapolate grid values beyond sets. This gridding method is a your data’s Z range. reasonable alternative to Nearest Neighbor for • Используется для выделения generating grids from large, больших трендов и структур. regularly spaced data sets. Работает очень быстро для множеств любого размера, но не является точным интерполяционным методом, поскольку сгенерированная поверхность не проходит через экспериментальные точки
• The polynomial regression • The moving average is most method processes the data so applicable to large and very that underlying large-scale large data sets (e. g. >1000 trends and patterns are shown. data points). It extracts This is used for trend surface intermediate-scale trends and analysis. This method can variations from large noisy data extrapolate grid values beyond sets. This gridding method is a your data’s Z range. reasonable alternative to Nearest Neighbor for • Используется для выделения generating grids from large, больших трендов и структур. regularly spaced data sets. Работает очень быстро для множеств любого размера, но не является точным интерполяционным методом, поскольку сгенерированная поверхность не проходит через экспериментальные точки
 Кригинг - это • Кригинг - это метод интерполяции, использующий статистические параметры для более точного построения поверхностей, кубов и карт, выполняющий две группы задач: • количественное определение пространственной структуры данных и • создание прогноза.
Кригинг - это • Кригинг - это метод интерполяции, использующий статистические параметры для более точного построения поверхностей, кубов и карт, выполняющий две группы задач: • количественное определение пространственной структуры данных и • создание прогноза.
 Kriging Weighted linear estimates Kriging uses weighted linear estimates; i. e. combining known values to estimate an unknown value Z at a location Xo Influence of variogram Range on weights Range X 0 ? 1 Direction of major continuity Data with known values, Z(Xi) Value to be estimated, Z(X 0) 2 3 4 5 Lag distance Weighting factor decided by Variogram: • How close to location? • Preferred direction (anisotropy) Z (Xo) is not known, but we can still calculate the error variance because we know the statistic parameters; mean value, variance value and the
Kriging Weighted linear estimates Kriging uses weighted linear estimates; i. e. combining known values to estimate an unknown value Z at a location Xo Influence of variogram Range on weights Range X 0 ? 1 Direction of major continuity Data with known values, Z(Xi) Value to be estimated, Z(X 0) 2 3 4 5 Lag distance Weighting factor decided by Variogram: • How close to location? • Preferred direction (anisotropy) Z (Xo) is not known, but we can still calculate the error variance because we know the statistic parameters; mean value, variance value and the
 Кригинг
Кригинг
 Выдержка из книги Де. Мерс N. N. «Географические информационные системы Основы»
Выдержка из книги Де. Мерс N. N. «Географические информационные системы Основы»
 • При универсальном кригинге предполагается, что есть доминирующий тренд в данных, и его можно моделировать детерминистской функцией, полиномом. Этот полином извлекается из исходных измеренных точек, и автокорреляция моделируется из произвольных ошибок. После установки модели на произвольные ошибки и до прогнозирования, полином добавляется обратно к прогнозам, чтобы дать значимые результаты. Универсальный кригинг следует использовать, только если вы знаете, что в данных есть тренд, и можете дать научное обоснование для его описания.
• При универсальном кригинге предполагается, что есть доминирующий тренд в данных, и его можно моделировать детерминистской функцией, полиномом. Этот полином извлекается из исходных измеренных точек, и автокорреляция моделируется из произвольных ошибок. После установки модели на произвольные ошибки и до прогнозирования, полином добавляется обратно к прогнозам, чтобы дать значимые результаты. Универсальный кригинг следует использовать, только если вы знаете, что в данных есть тренд, и можете дать научное обоснование для его описания.
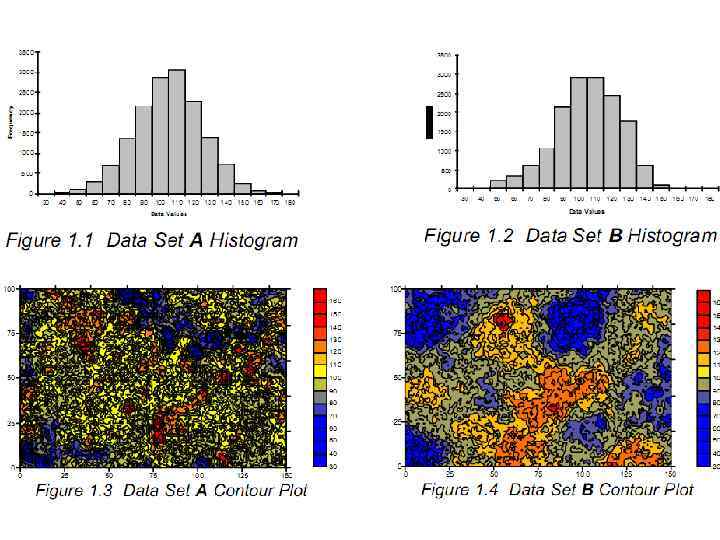
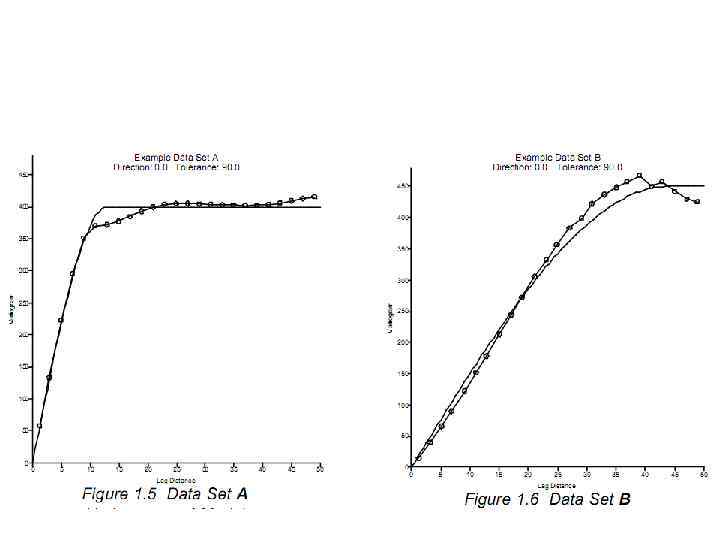
 Вариограммы
Вариограммы
 Метод обратных расстояний Кригинг
Метод обратных расстояний Кригинг
 =0 =
=0 =
 а
а





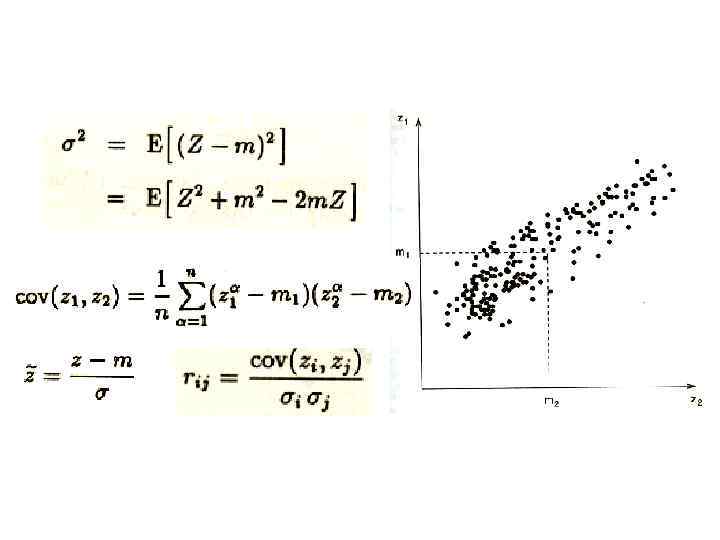
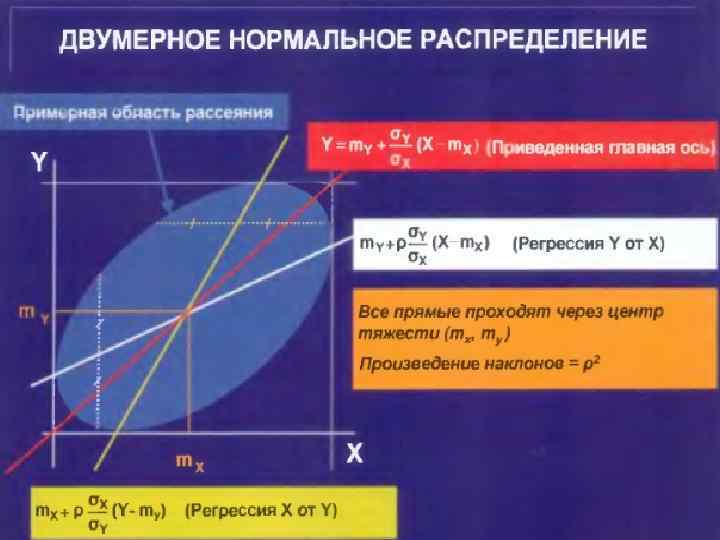
 Вариограмма – это • Вариограмма – это функция от одной переменной, статистически описывающая пространственную зависимость данных. γ( ) Функция разброса между точками Z(x, y) Значение параметра в точке (х, у) ε [ ] Математическое ожидание
Вариограмма – это • Вариограмма – это функция от одной переменной, статистически описывающая пространственную зависимость данных. γ( ) Функция разброса между точками Z(x, y) Значение параметра в точке (х, у) ε [ ] Математическое ожидание
 Экспериментальная вариограмма
Экспериментальная вариограмма
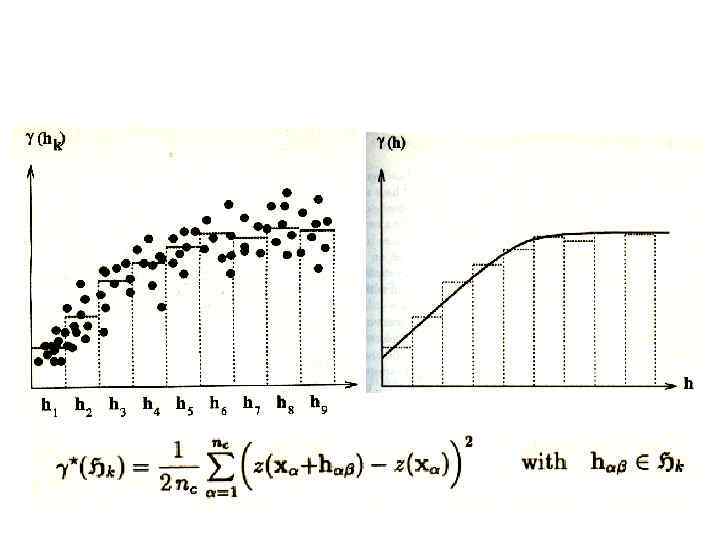
 Variance: A measure of how different members of a collection are from each other. Lag distance: Separation distance between points. Sill: Variance at the point where the summary plot flattens out to random similarity. Range: Correlation distance; distance beyond which data points no longer exhibit any statistical similarity. Variance Variogram Parameters Points - Sample variogram Line - Model variogram Sill Nugget Range 1 2 3 4 Separation 5 distance (lag) The Variogram can be calculated Nugget: Degree of dissimilarity at zero in 3 directions: distance. • Horizontal Major • Horizontal Minor • Vertical
Variance: A measure of how different members of a collection are from each other. Lag distance: Separation distance between points. Sill: Variance at the point where the summary plot flattens out to random similarity. Range: Correlation distance; distance beyond which data points no longer exhibit any statistical similarity. Variance Variogram Parameters Points - Sample variogram Line - Model variogram Sill Nugget Range 1 2 3 4 Separation 5 distance (lag) The Variogram can be calculated Nugget: Degree of dissimilarity at zero in 3 directions: distance. • Horizontal Major • Horizontal Minor • Vertical
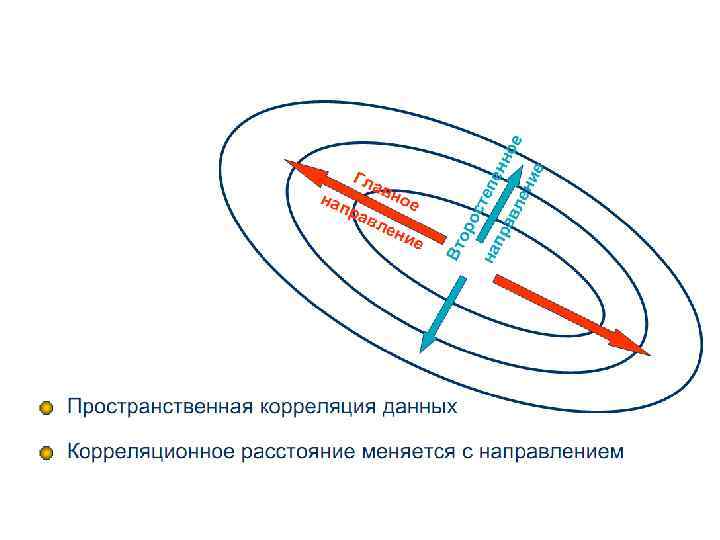
 Kriging Influence of the Variogram model parameters Nugget Variogram Range Azimuth Anisotropi c High (0. 99) Range: small Low (0. 1) Range: large Bad Anisotropi c Good
Kriging Influence of the Variogram model parameters Nugget Variogram Range Azimuth Anisotropi c High (0. 99) Range: small Low (0. 1) Range: large Bad Anisotropi c Good
 Радиус = 5000
Радиус = 5000
 • Радиус = 20000
• Радиус = 20000
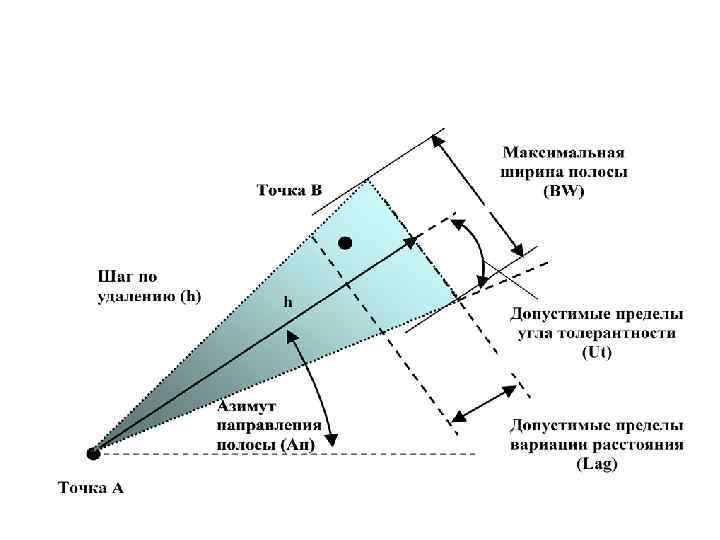
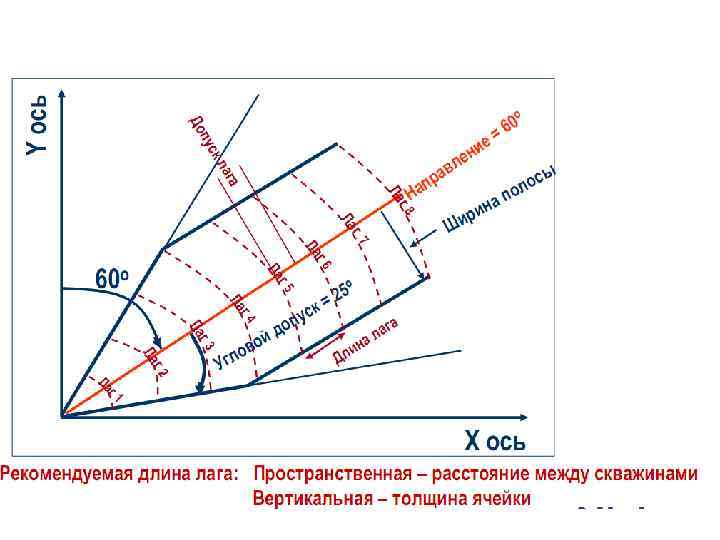
 Max Lag Distance is the maximum separation distance to be considered during variogram modeling.
Max Lag Distance is the maximum separation distance to be considered during variogram modeling.
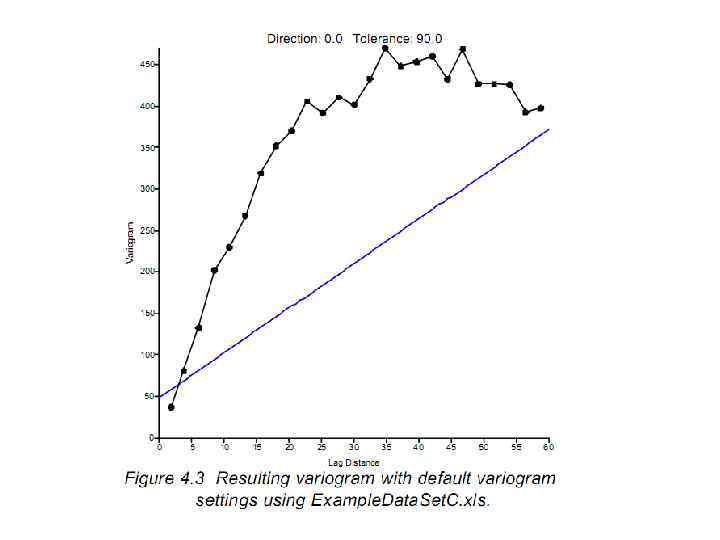
 Добавление вариограммы Petrel 2009
Добавление вариограммы Petrel 2009
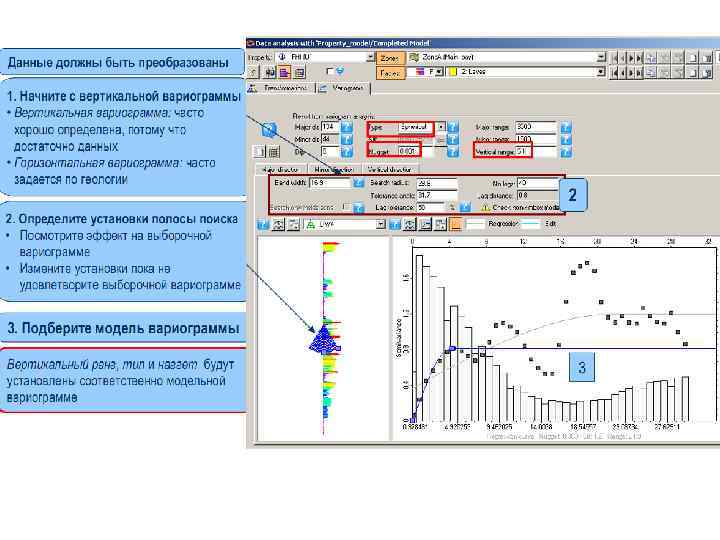
 • пример рассчитанной вариограммы по маркеру
• пример рассчитанной вариограммы по маркеру
 • Далее подбирается наиболее подходящая теоретическая непрерывная модель вариограмммы, параметрами которой являются интересующие нас характеристики ошибок.
• Далее подбирается наиболее подходящая теоретическая непрерывная модель вариограмммы, параметрами которой являются интересующие нас характеристики ошибок.
 Порог(С)") Экспоненциальная (Exponential) Порог(С)
Экспоненциальная (Exponential) Порог(С)
 • С помощью скаляров C , A , C 0 подбирают параметры модели: • Порог (С) – горизонтальная асимптота вариограммы; • Радиус(A) - значение аргумента, начиная с которого вариограмма примерно равна порогу (т. е. своей асимптоте); • Скачок (C 0) – величина скачка в нуле у вариограммы (значение вариограммы в нуле всегда равно нулю, а предел в нуле справа может быть положительным). Наличие скачка может объясняться, например, наличием в данных независимой некоррелированной случайной составляющей (например, ошибки измерений).
• С помощью скаляров C , A , C 0 подбирают параметры модели: • Порог (С) – горизонтальная асимптота вариограммы; • Радиус(A) - значение аргумента, начиная с которого вариограмма примерно равна порогу (т. е. своей асимптоте); • Скачок (C 0) – величина скачка в нуле у вариограммы (значение вариограммы в нуле всегда равно нулю, а предел в нуле справа может быть положительным). Наличие скачка может объясняться, например, наличием в данных независимой некоррелированной случайной составляющей (например, ошибки измерений).
") Сферическая (Spherical)
Сферическая (Spherical)
") Гауссова (Gaussian)
Гауссова (Gaussian)
") Кубическая (Cubic)
Кубическая (Cubic)
") Наггет-эффект ( Hole_Effect)
Наггет-эффект ( Hole_Effect)
") степенная (Power)
степенная (Power)
") логарифмическая (Cauchy)
логарифмическая (Cauchy)
") рационально-квадратическая (De-Vijs)
рационально-квадратическая (De-Vijs)
 Погрешности построений
Погрешности построений
 • Кригинг часто дает довольно точные оценки пропущенных значений, но эта точность обходится ценой времени и вычислительных ресурсов. Но даже при этом кригинг имеет еще одно преимущество перед другими методами интерполяции, - он не только дает интерполированные значения, но также и оценку возможной ошибки этих значений. Это может навести на мысль, что данный метод следует применять повсеместно, но увы. Когда мы имеем дело с большим уровнем локального шума из-за ошибок измерений или большие вариации высоты между отсчетами, в данном методе становится трудным построение кривой полудисперсии. А в таких условиях результаты кригинга будут не лучше, чем полученные другими методами.
• Кригинг часто дает довольно точные оценки пропущенных значений, но эта точность обходится ценой времени и вычислительных ресурсов. Но даже при этом кригинг имеет еще одно преимущество перед другими методами интерполяции, - он не только дает интерполированные значения, но также и оценку возможной ошибки этих значений. Это может навести на мысль, что данный метод следует применять повсеместно, но увы. Когда мы имеем дело с большим уровнем локального шума из-за ошибок измерений или большие вариации высоты между отсчетами, в данном методе становится трудным построение кривой полудисперсии. А в таких условиях результаты кригинга будут не лучше, чем полученные другими методами.
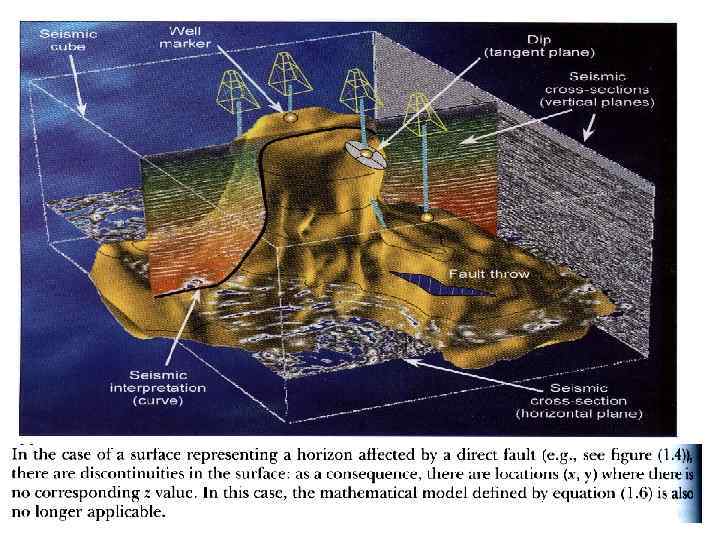

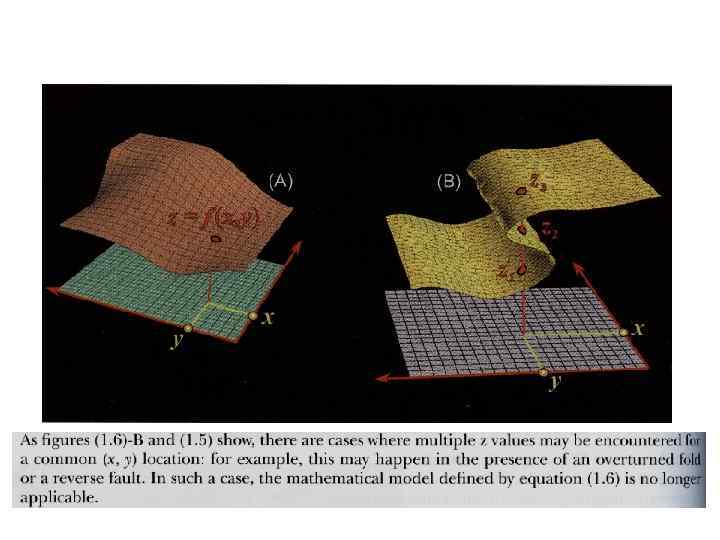
 «Краевой эффект» • При построении карт часто возможен «краевой эффект» , т. е. значения сеточных функций могут выходить за пределы интервала исходных данных, это происходит в тех областях карты, где значений нет, или они находятся на большом расстоянии друг от друга, например вдоль края карты.
«Краевой эффект» • При построении карт часто возможен «краевой эффект» , т. е. значения сеточных функций могут выходить за пределы интервала исходных данных, это происходит в тех областях карты, где значений нет, или они находятся на большом расстоянии друг от друга, например вдоль края карты.