

20846eeabdd231ea4bd7b873705819a6.ppt
- Количество слайдов: 89
 Interactive Information Extraction and Social Network Analysis Andrew Mc. Callum Information Extraction and Synthesis Laboratory UMass Amherst
Interactive Information Extraction and Social Network Analysis Andrew Mc. Callum Information Extraction and Synthesis Laboratory UMass Amherst
 Motivation • Capture confidence of records in extracted database First Name Last Name Confidence Bill Gates 0. 96 Bill banks 0. 43 • Alerts data mining to possible errors in database 9
Motivation • Capture confidence of records in extracted database First Name Last Name Confidence Bill Gates 0. 96 Bill banks 0. 43 • Alerts data mining to possible errors in database 9
![Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Finite State Lattice y t-1](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-3.jpg "Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Finite State Lattice y t-1") Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Finite State Lattice y t-1 yt y t+1 y t+2 output sequence y t+3 ORG OTHER. . . PERSON Lattice of FSM states TITLE observations x t -1 said x t Arden x t +1 Bement x t +2 NSF x t +3 Director … input sequence 10
Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Finite State Lattice y t-1 yt y t+1 y t+2 output sequence y t+3 ORG OTHER. . . PERSON Lattice of FSM states TITLE observations x t -1 said x t Arden x t +1 Bement x t +2 NSF x t +3 Director … input sequence 10
![Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Constrained Forward-Backward y t-1 yt](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-4.jpg "Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Constrained Forward-Backward y t-1 yt") Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Constrained Forward-Backward y t-1 yt y t+1 y t+2 output sequence y t+3 ORG OTHER. . . PERSON Lattice of FSM states TITLE observations x t -1 said x t Arden x t +1 Bement x t +2 NSF x t +3 Director … input sequence 11
Confidence Estimation in Linear-chain CRFs [Culotta, Mc. Callum 2004] Constrained Forward-Backward y t-1 yt y t+1 y t+2 output sequence y t+3 ORG OTHER. . . PERSON Lattice of FSM states TITLE observations x t -1 said x t Arden x t +1 Bement x t +2 NSF x t +3 Director … input sequence 11
 Forward-Backward Confidence Estimation improves accuracy/coverage our forward-backward confidence l optima traditional token-wise confidence no use of confidence 12
Forward-Backward Confidence Estimation improves accuracy/coverage our forward-backward confidence l optima traditional token-wise confidence no use of confidence 12
 Application of Confidence Estimation u Interactive Information Extraction: – To correct predictions, direct user to least confident field 13
Application of Confidence Estimation u Interactive Information Extraction: – To correct predictions, direct user to least confident field 13
 Interactive Information Extraction u u u IE algorithm calculates confidence scores UI uses confidence scores to alert user to possible errors IE algorithm takes corrections into account and propagates correction to other fields 14
Interactive Information Extraction u u u IE algorithm calculates confidence scores UI uses confidence scores to alert user to possible errors IE algorithm takes corrections into account and propagates correction to other fields 14
 User Correction u User Corrects a field, e. g. dragging Stanley to the First Name field x 1 x 2 x 3 x 4 Stanley 100 Charles y 3 y 4 x 5 First Name Last Name Address Line Charles y 1 y 2 Street y 5 15
User Correction u User Corrects a field, e. g. dragging Stanley to the First Name field x 1 x 2 x 3 x 4 Stanley 100 Charles y 3 y 4 x 5 First Name Last Name Address Line Charles y 1 y 2 Street y 5 15
 Remove Paths u User Corrects a field, e. g. dragging Stanley to the First Name field x 1 x 2 x 3 x 4 Stanley 100 Charles y 3 y 4 x 5 First Name Last Name Address Line Charles y 1 y 2 Street y 5 16
Remove Paths u User Corrects a field, e. g. dragging Stanley to the First Name field x 1 x 2 x 3 x 4 Stanley 100 Charles y 3 y 4 x 5 First Name Last Name Address Line Charles y 1 y 2 Street y 5 16
 Constrained Viterbi u Viterbi algorithm is constrained to pass through the designated state. x 1 x 2 Charles Stanley x 3 x 4 x 5 First Name Last Name Address Line y 1 y 2 100 Charles y 3 y 4 Street y 5 Adjacent field changed: Correction Propagation 17
Constrained Viterbi u Viterbi algorithm is constrained to pass through the designated state. x 1 x 2 Charles Stanley x 3 x 4 x 5 First Name Last Name Address Line y 1 y 2 100 Charles y 3 y 4 Street y 5 Adjacent field changed: Correction Propagation 17
 Constrained Viterbi u u After fixing least confident field, constrained Viterbi automatically reduces error by another 23%. Recent work reduces annotation effort further – simplifies annotation to multiple-choice First Name A) B) Last Name City Bill Gates Redmond WA Bill Gates Redmond 18
Constrained Viterbi u u After fixing least confident field, constrained Viterbi automatically reduces error by another 23%. Recent work reduces annotation effort further – simplifies annotation to multiple-choice First Name A) B) Last Name City Bill Gates Redmond WA Bill Gates Redmond 18
 User feedback “in the wild” as labeling Labeling for Classification Labeling for Extraction Seminar: How to Organize your Life by Jane Smith, Stevenson & Smith Mezzanine Level, Papadapoulos Sq 3: 30 pm Thursday March 31 In this seminar we will learn how to use CALO to. . . Seminar announcement Todo request Other Easy: Often found in user interfaces e. g. CALO IRIS, Apple Mail Click, drag, adjust, label, . . . Painful: Difficult even for paid labelers Complex tools 19
User feedback “in the wild” as labeling Labeling for Classification Labeling for Extraction Seminar: How to Organize your Life by Jane Smith, Stevenson & Smith Mezzanine Level, Papadapoulos Sq 3: 30 pm Thursday March 31 In this seminar we will learn how to use CALO to. . . Seminar announcement Todo request Other Easy: Often found in user interfaces e. g. CALO IRIS, Apple Mail Click, drag, adjust, label, . . . Painful: Difficult even for paid labelers Complex tools 19
![Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-13.jpg "Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information") Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information Extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. user corrects labels, not segmentations 20
Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information Extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. user corrects labels, not segmentations 20
![Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-14.jpg "Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information") Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. user corrects labels, not segmentations 21
Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. user corrects labels, not segmentations 21
![Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-15.jpg "Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information") Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. 29% percent reduction in user actions needed to train 22
Multiple-choice Annotation for Learning Extractors “in the wild” [Culotta, Mc. Callum 2005] Task: Information extraction. Fields: NAME COMPANY ADDRESS (and others) Jane Smith , Stevenson & Smith , Mezzanine Level, Papadopoulos Sq. Interface presents top hypothesized segmentations Jane Smith , Stevenson & Smith Mezzanine Level , Papadopoulos Sq. 29% percent reduction in user actions needed to train 22
![Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Emailed seminar](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-16.jpg "Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Emailed seminar") Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Emailed seminar ann’mt entities Email English words GRAND CHALLENGES FOR MACHINE LEARNING 60 k words training. Jaime Carbonell School of Computer Science Carnegie Mellon University 3: 30 pm 7500 Wean Hall Machine learning has evolved from obscurity in the 1970 s into a vibrant and popular discipline in artificial intelligence during the 1980 s and 1990 s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e. g. analogy, explanation-based learning), learning theory (e. g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on. Too little labeled training data. 24
Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Emailed seminar ann’mt entities Email English words GRAND CHALLENGES FOR MACHINE LEARNING 60 k words training. Jaime Carbonell School of Computer Science Carnegie Mellon University 3: 30 pm 7500 Wean Hall Machine learning has evolved from obscurity in the 1970 s into a vibrant and popular discipline in artificial intelligence during the 1980 s and 1990 s. As a result of its success and growth, machine learning is evolving into a collection of related disciplines: inductive concept acquisition, analytic learning in problem solving (e. g. analogy, explanation-based learning), learning theory (e. g. PAC learning), genetic algorithms, connectionist learning, hybrid systems, and so on. Too little labeled training data. 24
![Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Train on](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-17.jpg "Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Train on") Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Train on “related” task with more data. Newswire named entities Newswire English words 200 k words training. CRICKET MILLNS SIGNS FOR BOLAND CAPE TOWN 1996 -08 -22 South African provincial side Boland said on Thursday they had signed Leicestershire fast bowler David Millns on a one year contract. Millns, who toured Australia with England A in 1992, replaces former England all-rounder Phillip De. Freitas as Boland's overseas professional. 25
Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Train on “related” task with more data. Newswire named entities Newswire English words 200 k words training. CRICKET MILLNS SIGNS FOR BOLAND CAPE TOWN 1996 -08 -22 South African provincial side Boland said on Thursday they had signed Leicestershire fast bowler David Millns on a one year contract. Millns, who toured Australia with England A in 1992, replaces former England all-rounder Phillip De. Freitas as Boland's overseas professional. 25
![Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] At test](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-18.jpg "Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] At test") Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] At test time, label email with newswire NEs. . . Newswire named entities Email English words 26
Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] At test time, label email with newswire NEs. . . Newswire named entities Email English words 26
![Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] …then use](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-19.jpg "Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] …then use") Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] …then use these labels as features for final task Emailed seminar ann’mt entities Newswire named entities Email English words 27
Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] …then use these labels as features for final task Emailed seminar ann’mt entities Newswire named entities Email English words 27
![Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Use joint](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-20.jpg "Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Use joint") Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Use joint inference at test time. Seminar Announcement entities Newswire named entities English words An alternative to hierarchical Bayes. Needn’t know anything about parameterization of subtask. Accuracy No transfer < Cascaded Transfer < Joint Inference Transfer 28
Piecewise Training in Factorial CRFs for Transfer Learning [Sutton, Mc. Callum, 2005] Use joint inference at test time. Seminar Announcement entities Newswire named entities English words An alternative to hierarchical Bayes. Needn’t know anything about parameterization of subtask. Accuracy No transfer < Cascaded Transfer < Joint Inference Transfer 28
 A Conditional Random Field for Discriminatively-trained Finite-state String Edit Distance Andrew Mc. Callum Kedar Bellare Fernando Pereira Thanks to Charles Sutton, Xuerui Wang and Mikhail Bilenko for helpful discussions. 30
A Conditional Random Field for Discriminatively-trained Finite-state String Edit Distance Andrew Mc. Callum Kedar Bellare Fernando Pereira Thanks to Charles Sutton, Xuerui Wang and Mikhail Bilenko for helpful discussions. 30
 String Edit Distance u Distance between sequences x and y: – “cost” of lowest-cost sequence of edit operations that transform string x into y. 31
String Edit Distance u Distance between sequences x and y: – “cost” of lowest-cost sequence of edit operations that transform string x into y. 31
 String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication Apex International Hotel Grassmarket Street Apex Internat’l Grasmarket Street Records are duplicates of the same hotel? 32
String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication Apex International Hotel Grassmarket Street Apex Internat’l Grasmarket Street Records are duplicates of the same hotel? 32
 String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences AGCTCTTACGATAGAGGACTCCAGA AGGTCTTACCAAAGAGGACTTCAGA 33
String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences AGCTCTTACGATAGAGGACTCCAGA AGGTCTTACCAAAGAGGACTTCAGA 33
 String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences – Machine Translation Il a achete une pomme He bought an apple 34
String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences – Machine Translation Il a achete une pomme He bought an apple 34
 String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences – Machine Translation – Textual Entailment He bought a new car last night He purchased a brand new automobile yesterday evening 35
String Edit Distance u Distance between sequences x and y: – u “cost” of lowest-cost sequence of edit operations that transform string x into y. Applications – Database Record Deduplication – Biological Sequences – Machine Translation – Textual Entailment He bought a new car last night He purchased a brand new automobile yesterday evening 35
 Levenshtein Distance Edit operations Align two strings copy insert delete subst x 1 = x 2 = [1966] Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another (cost 0) (cost 1) William W. Cohon Willleam Cohen Will iam_W. _Cohon copy subst copy delete copy subst insert copy operation cost copy Lowest cost alignment Willleam _Cohen 0000111000010 Total cost = 6 = Levenshtein Distance 36
Levenshtein Distance Edit operations Align two strings copy insert delete subst x 1 = x 2 = [1966] Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another (cost 0) (cost 1) William W. Cohon Willleam Cohen Will iam_W. _Cohon copy subst copy delete copy subst insert copy operation cost copy Lowest cost alignment Willleam _Cohen 0000111000010 Total cost = 6 = Levenshtein Distance 36
 = score") Levenshtein Distance Edit operations copy insert delete subst Dynamic program D(i, j) = score of best alignment from x 1. . . xi to y 1. . . yj. D(i-1, j-1) + (xi≠yj ) D(i, j) = min D(i-1, j) + 1 D(i, j-1) + 1 Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another Willleam 012345678 W 101234567 i 210123456 l 321012345 l 432101234 i 543211234 a 654322224 m 765433332 (cost 0) (cost 1) insert subst total cost = distance 37
Levenshtein Distance Edit operations copy insert delete subst Dynamic program D(i, j) = score of best alignment from x 1. . . xi to y 1. . . yj. D(i-1, j-1) + (xi≠yj ) D(i, j) = min D(i-1, j) + 1 D(i, j-1) + 1 Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another Willleam 012345678 W 101234567 i 210123456 l 321012345 l 432101234 i 543211234 a 654322224 m 765433332 (cost 0) (cost 1) insert subst total cost = distance 37
 Levenshtein Distance with Markov Dependencies Edit operations copy insert delete Cost after a Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another repeated delete is cheaper cids 0000 1 12 1 1 1 2 subst 1111 Learn these costs from training data subst copy delete insert Willleam 012345678 W 101234567 i 210123456 l 321012345 l 432101234 i 543211234 a 654322224 m 765433332 3 D DP table 38
Levenshtein Distance with Markov Dependencies Edit operations copy insert delete Cost after a Copy a character from x to y Insert a character into y Delete a character from y Substitute one character for another repeated delete is cheaper cids 0000 1 12 1 1 1 2 subst 1111 Learn these costs from training data subst copy delete insert Willleam 012345678 W 101234567 i 210123456 l 321012345 l 432101234 i 543211234 a 654322224 m 765433332 3 D DP table 38
 Essentially a Pair-HMM, generating a edit/state/alignment-sequence and two strings string") Ristad & Yianilos (1997) Essentially a Pair-HMM, generating a edit/state/alignment-sequence and two strings string 1 copy subst 7 8 8 9 10 11 12 13 14 copy delete copy 6 7 8 9 10 11 12 13 14 15 16 copy Willleam subst 1 2 3 4 5 6 insert copy 1 2 3 4 4 5 copy string 2 Will iam_W. _Cohon copy alignment x 1 a. i 1 a. e a. i 2 x 2 _Cohen complete data likelihood Match score = Given training set of matching string pairs, objective fn is incomplete data likelihood (sum over all alignments consistent with x 1 and x 2) Learn via EM: Expectation step: Calculate likelihood of alignment paths Maximization step: Make those paths more likely. 39
Ristad & Yianilos (1997) Essentially a Pair-HMM, generating a edit/state/alignment-sequence and two strings string 1 copy subst 7 8 8 9 10 11 12 13 14 copy delete copy 6 7 8 9 10 11 12 13 14 15 16 copy Willleam subst 1 2 3 4 5 6 insert copy 1 2 3 4 4 5 copy string 2 Will iam_W. _Cohon copy alignment x 1 a. i 1 a. e a. i 2 x 2 _Cohen complete data likelihood Match score = Given training set of matching string pairs, objective fn is incomplete data likelihood (sum over all alignments consistent with x 1 and x 2) Learn via EM: Expectation step: Calculate likelihood of alignment paths Maximization step: Make those paths more likely. 39
 Ristad & Yianilos Regrets u Limited features of input strings Examine only single character pair at a time – Difficult to use upcoming string context, lexicons, . . . – Example: “Senator John Green” “John Green” – u Limited edit operations Difficult to generate arbitrary jumps in both strings – Example: “UMass” “University of Massachusetts”. – u Trained only on positive match data Doesn’t include information-rich “near misses” – Example: “ACM SIGIR” ≠ “ACM SIGCHI” – So, consider model trained by conditional probability 40
Ristad & Yianilos Regrets u Limited features of input strings Examine only single character pair at a time – Difficult to use upcoming string context, lexicons, . . . – Example: “Senator John Green” “John Green” – u Limited edit operations Difficult to generate arbitrary jumps in both strings – Example: “UMass” “University of Massachusetts”. – u Trained only on positive match data Doesn’t include information-rich “near misses” – Example: “ACM SIGIR” ≠ “ACM SIGCHI” – So, consider model trained by conditional probability 40
 Models u We prefer a model that is trained to maximize") Conditional Probability (Sequence) Models u We prefer a model that is trained to maximize a conditional probability rather than joint probability: P(y|x) instead of P(y, x): – Can examine features, but not responsible for generating them. – Don’t have to explicitly model their dependencies. 41
Conditional Probability (Sequence) Models u We prefer a model that is trained to maximize a conditional probability rather than joint probability: P(y|x) instead of P(y, x): – Can examine features, but not responsible for generating them. – Don’t have to explicitly model their dependencies. 41
![Linear-chain ^ From HMMs to Conditional Random Fields [Lafferty, Mc. Callum, Pereira 2001] yt-1](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-33.jpg "Linear-chain ^ From HMMs to Conditional Random Fields [Lafferty, Mc. Callum, Pereira 2001] yt-1") Linear-chain ^ From HMMs to Conditional Random Fields [Lafferty, Mc. Callum, Pereira 2001] yt-1 Joint xt-1 yt xt yt+1. . . xt+1 . . . Conditional yt-1 xt-1 yt xt yt+1. . . xt+1 . . . where Set parameters by maximum likelihood, using optimization method on L. (A super-special case of Conditional Random Fields. ) Wide-spread interest, positive experimental results in many applications. Noun phrase, Named entity [HLT’ 03], [Co. NLL’ 03] Protein structure prediction [ICML’ 04] IE from Bioinformatics text [Bioinformatics ‘ 04], … Asian word segmentation [COLING’ 04], [ACL’ 04] IE from Research papers [HTL’ 04] 42 Object classification in images [CVPR ‘ 04]
Linear-chain ^ From HMMs to Conditional Random Fields [Lafferty, Mc. Callum, Pereira 2001] yt-1 Joint xt-1 yt xt yt+1. . . xt+1 . . . Conditional yt-1 xt-1 yt xt yt+1. . . xt+1 . . . where Set parameters by maximum likelihood, using optimization method on L. (A super-special case of Conditional Random Fields. ) Wide-spread interest, positive experimental results in many applications. Noun phrase, Named entity [HLT’ 03], [Co. NLL’ 03] Protein structure prediction [ICML’ 04] IE from Bioinformatics text [Bioinformatics ‘ 04], … Asian word segmentation [COLING’ 04], [ACL’ 04] IE from Research papers [HTL’ 04] 42 Object classification in images [CVPR ‘ 04]
 CRF String Edit Distance string 1 copy subst 7 8 8 9 10 11 12 13 14 copy delete copy 6 7 8 9 10 11 12 13 14 15 16 copy Willleam subst 1 2 3 4 5 6 insert copy 1 2 3 4 4 5 copy string 2 Will iam_W. _Cohon copy alignment x 1 a. i 1 a. e a. i 2 x 2 _Cohen joint complete data likelihood conditional complete data likelihood Want to train from set of string pairs, each labeled one of {match, non-match} match non-match “William W. Cohon” “Bruce D’Ambrosio” “Tommi Jaakkola” “Stuart Russell” “Tom Deitterich” “Willlleam Cohen” “Bruce Croft” “Tommi Jakola” “Stuart Russel” “Tom Dean” 44
CRF String Edit Distance string 1 copy subst 7 8 8 9 10 11 12 13 14 copy delete copy 6 7 8 9 10 11 12 13 14 15 16 copy Willleam subst 1 2 3 4 5 6 insert copy 1 2 3 4 4 5 copy string 2 Will iam_W. _Cohon copy alignment x 1 a. i 1 a. e a. i 2 x 2 _Cohen joint complete data likelihood conditional complete data likelihood Want to train from set of string pairs, each labeled one of {match, non-match} match non-match “William W. Cohon” “Bruce D’Ambrosio” “Tommi Jaakkola” “Stuart Russell” “Tom Deitterich” “Willlleam Cohen” “Bruce Croft” “Tommi Jakola” “Stuart Russel” “Tom Dean” 44
 CRF String Edit Distance FSM subst copy delete insert 45
CRF String Edit Distance FSM subst copy delete insert 45
 CRF String Edit Distance FSM conditional incomplete data likelihood subst copy match m=1 delete insert subst copy Start non-match m=0 delete insert 46
CRF String Edit Distance FSM conditional incomplete data likelihood subst copy match m=1 delete insert subst copy Start non-match m=0 delete insert 46
 CRF String Edit Distance FSM x 1 = “Tommi Jaakkola” x 2 = “Tommi Jakola” subst copy match m=1 delete copy 0. 8 insert subst Probability summed over all alignments in match states Start non-match m=0 delete Probability summed over all alignments in non-match states 0. 2 insert 47
CRF String Edit Distance FSM x 1 = “Tommi Jaakkola” x 2 = “Tommi Jakola” subst copy match m=1 delete copy 0. 8 insert subst Probability summed over all alignments in match states Start non-match m=0 delete Probability summed over all alignments in non-match states 0. 2 insert 47
 CRF String Edit Distance FSM x 1 = “Tom Dietterich” x 2 = “Tom Dean” subst copy match m=1 delete copy 0. 1 insert subst Probability summed over all alignments in match states Start non-match m=0 delete Probability summed over all alignments in non-match states 0. 9 insert 48
CRF String Edit Distance FSM x 1 = “Tom Dietterich” x 2 = “Tom Dean” subst copy match m=1 delete copy 0. 1 insert subst Probability summed over all alignments in match states Start non-match m=0 delete Probability summed over all alignments in non-match states 0. 9 insert 48
 Parameter Estimation Given training set of string pairs and match/non-match labels, objective fn is the incomplete log likelihood The complete log likelihood Expectation Maximization u E-step: Estimate distribution over alignments, , using current parameters u M-step: Change parameters to maximize the complete (penalized) log likelihood, with an iterative quasi-Newton method (BFGS) This is “conditional EM”, but avoid complexities of [Jebara 1998], because no need to solve M-step in closed form. 49
Parameter Estimation Given training set of string pairs and match/non-match labels, objective fn is the incomplete log likelihood The complete log likelihood Expectation Maximization u E-step: Estimate distribution over alignments, , using current parameters u M-step: Change parameters to maximize the complete (penalized) log likelihood, with an iterative quasi-Newton method (BFGS) This is “conditional EM”, but avoid complexities of [Jebara 1998], because no need to solve M-step in closed form. 49
 Efficient Training u u Dynamic programming table is 3 D; |x 1| = |x 2| = 100, |S| = 12, . . 120, 000 entries Use beam search during E-step [Pal, Sutton, Mc. Callum 2005] Unlike completely observed CRFs, objective function is not convex. Initialize parameters not at zero, but so as to yield a reasonable initial edit distance. 50
Efficient Training u u Dynamic programming table is 3 D; |x 1| = |x 2| = 100, |S| = 12, . . 120, 000 entries Use beam search during E-step [Pal, Sutton, Mc. Callum 2005] Unlike completely observed CRFs, objective function is not convex. Initialize parameters not at zero, but so as to yield a reasonable initial edit distance. 50
 What Alignments are Learned? x 1 = “Tommi Jaakkola” x 2 = “Tommi Jakola” Tommi Jaakkola subst copy match m=1 delete insert subst T o m m i J a k o l a copy Start non-match m=0 delete insert 51
What Alignments are Learned? x 1 = “Tommi Jaakkola” x 2 = “Tommi Jakola” Tommi Jaakkola subst copy match m=1 delete insert subst T o m m i J a k o l a copy Start non-match m=0 delete insert 51
 What Alignments are Learned? x 1 = “Bruce Croft” x 2 = “Tom Dean” subst copy match m=1 delete insert Start Bruce Croft subst copy non-match m=0 delete insert T o m D e a n 52
What Alignments are Learned? x 1 = “Bruce Croft” x 2 = “Tom Dean” subst copy match m=1 delete insert Start Bruce Croft subst copy non-match m=0 delete insert T o m D e a n 52
 What Alignments are Learned? x 1 = “Jaime Carbonell” x 2 = “Jamie Callan” subst copy match m=1 delete insert Start Jaime Carbonell subst copy non-match m=0 delete insert J a m i e C a l l a n 53
What Alignments are Learned? x 1 = “Jaime Carbonell” x 2 = “Jamie Callan” subst copy match m=1 delete insert Start Jaime Carbonell subst copy non-match m=0 delete insert J a m i e C a l l a n 53
 Summary of Advantages u Arbitrary features of the input strings Examine past, future context – Use lexicons, Word. Net – u Extremely flexible edit operations – u Single operation may make arbitrary jumps in both strings, of size determined by input features Discriminative Training – Maximize ability to predict match vs non-match 55
Summary of Advantages u Arbitrary features of the input strings Examine past, future context – Use lexicons, Word. Net – u Extremely flexible edit operations – u Single operation may make arbitrary jumps in both strings, of size determined by input features Discriminative Training – Maximize ability to predict match vs non-match 55
 Experimental Results: Data Sets u Restaurant name, Restaurant address 864 records, 112 matches – E. g. “Abe’s Bar & Grill, E. Main St” “Abe’s Grill, East Main Street” – u People names, UIS DB generator synthetic noise – E. g. “John Smith” – u vs “Snith, John” Cite. Seer Citations In four sections: Reason, Face, Reinforce, Constraint – E. g. “Rusell & Norvig, “Artificial Intelligence: A Modern. . . ” “Russell & Norvig, “Artificial Intelligence: An Intro. . . ” – 56
Experimental Results: Data Sets u Restaurant name, Restaurant address 864 records, 112 matches – E. g. “Abe’s Bar & Grill, E. Main St” “Abe’s Grill, East Main Street” – u People names, UIS DB generator synthetic noise – E. g. “John Smith” – u vs “Snith, John” Cite. Seer Citations In four sections: Reason, Face, Reinforce, Constraint – E. g. “Rusell & Norvig, “Artificial Intelligence: A Modern. . . ” “Russell & Norvig, “Artificial Intelligence: An Intro. . . ” – 56
 Experimental Results: Features u u u u same, different same-alphabetic, different alphbetic same-numeric, different-numeric punctuation 1, punctuation 2 alphabet-mismatch, numeric-mismatch end-of-1, end-of-2 same-next-character, different-next-character 57
Experimental Results: Features u u u u same, different same-alphabetic, different alphbetic same-numeric, different-numeric punctuation 1, punctuation 2 alphabet-mismatch, numeric-mismatch end-of-1, end-of-2 same-next-character, different-next-character 57
 Experimental Results: Edit Operations u u u u insert, delete, substitute/copy swap-two-characters skip-word-if-in-lexicon skip-parenthesized-words skip-any-word substitute-word-pairs-in-translation-lexicon skip-word-if-present-in-other-string 58
Experimental Results: Edit Operations u u u u insert, delete, substitute/copy swap-two-characters skip-word-if-in-lexicon skip-parenthesized-words skip-any-word substitute-word-pairs-in-translation-lexicon skip-word-if-present-in-other-string 58
![Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-48.jpg "Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance") Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance metric Restaurant name Restaurant address Cite. Seer Reason Face Reinf Constraint Levenshtein Learned Leven. Vector Learned Vector 0. 290 0. 354 0. 365 0. 433 0. 686 0. 712 0. 380 0. 532 0. 927 0. 938 0. 897 0. 924 0. 941 0. 923 0. 913 0. 952 0. 966 0. 922 0. 875 0. 893 0. 907 0. 903 0. 808 59
Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance metric Restaurant name Restaurant address Cite. Seer Reason Face Reinf Constraint Levenshtein Learned Leven. Vector Learned Vector 0. 290 0. 354 0. 365 0. 433 0. 686 0. 712 0. 380 0. 532 0. 927 0. 938 0. 897 0. 924 0. 941 0. 923 0. 913 0. 952 0. 966 0. 922 0. 875 0. 893 0. 907 0. 903 0. 808 59
![Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-49.jpg "Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance") Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance metric Restaurant name Restaurant address Cite. Seer Reason Face Reinf Constraint Levenshtein Learned Leven. Vector Learned Vector 0. 290 0. 354 0. 365 0. 433 0. 686 0. 712 0. 380 0. 532 0. 927 0. 938 0. 897 0. 924 0. 952 0. 966 0. 922 0. 875 0. 893 0. 907 0. 903 0. 808 0. 924 0. 941 0. 923 0. 913 CRF Edit Distance 0. 448 0. 783 0. 964 0. 918 0. 917 0. 976 60
Experimental Results [Bilenko & Mooney 2003] F 1 (average of precision and recall) Distance metric Restaurant name Restaurant address Cite. Seer Reason Face Reinf Constraint Levenshtein Learned Leven. Vector Learned Vector 0. 290 0. 354 0. 365 0. 433 0. 686 0. 712 0. 380 0. 532 0. 927 0. 938 0. 897 0. 924 0. 952 0. 966 0. 922 0. 875 0. 893 0. 907 0. 903 0. 808 0. 924 0. 941 0. 923 0. 913 CRF Edit Distance 0. 448 0. 783 0. 964 0. 918 0. 917 0. 976 60
 Experimental Results Data set: person names, with word-order noise added F 1 Without skip-if-present-in-other-string With skip-if-present-in-other-string 0. 856 0. 981 61
Experimental Results Data set: person names, with word-order noise added F 1 Without skip-if-present-in-other-string With skip-if-present-in-other-string 0. 856 0. 981 61
![Joint Co-reference Decisions, Discriminative Model [Culotta & Mc. Callum 2005] People Stuart Russell Y/N](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-51.jpg "Joint Co-reference Decisions, Discriminative Model [Culotta & Mc. Callum 2005] People Stuart Russell Y/N") Joint Co-reference Decisions, Discriminative Model [Culotta & Mc. Callum 2005] People Stuart Russell Y/N Y/N S. Russel 63
Joint Co-reference Decisions, Discriminative Model [Culotta & Mc. Callum 2005] People Stuart Russell Y/N Y/N S. Russel 63
 Co-reference for Multiple Entity Types People Stuart Russell Organizations University of California at Berkeley Y/N Stuart Russell Y/N Berkeley Y/N S. Russel [Culotta & Mc. Callum 2005] Y/N Berkeley 64
Co-reference for Multiple Entity Types People Stuart Russell Organizations University of California at Berkeley Y/N Stuart Russell Y/N Berkeley Y/N S. Russel [Culotta & Mc. Callum 2005] Y/N Berkeley 64
 Joint Co-reference of Multiple Entity Types People Stuart Russell Organizations University of California at Berkeley Y/N Stuart Russell Y/N Berkeley Y/N S. Russel [Culotta & Mc. Callum 2005] Y/N Reduces error by 22% Berkeley 65
Joint Co-reference of Multiple Entity Types People Stuart Russell Organizations University of California at Berkeley Y/N Stuart Russell Y/N Berkeley Y/N S. Russel [Culotta & Mc. Callum 2005] Y/N Reduces error by 22% Berkeley 65
 Social network from my email 68
Social network from my email 68
![Clustering words into topics with Latent Dirichlet Allocation [Blei, Ng, Jordan 2003] Generative Process:](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-55.jpg "Clustering words into topics with Latent Dirichlet Allocation [Blei, Ng, Jordan 2003] Generative Process:") Clustering words into topics with Latent Dirichlet Allocation [Blei, Ng, Jordan 2003] Generative Process: Example: For each document: Sample a distribution over topics, 70% Iraq war 30% US election For each word in doc Sample a topic, z Sample a word from the topic, w Iraq war “bombing” 69
Clustering words into topics with Latent Dirichlet Allocation [Blei, Ng, Jordan 2003] Generative Process: Example: For each document: Sample a distribution over topics, 70% Iraq war 30% US election For each word in doc Sample a topic, z Sample a word from the topic, w Iraq war “bombing” 69
 Example topics induced from a large collection of text JOB SCIENCE BALL FIELD STORY MIND DISEASE WATER WORK STUDY GAME MAGNETIC STORIES WORLD BACTERIA FISH JOBS SCIENTISTS TEAM MAGNET TELL DREAM DISEASES SEA CAREER SCIENTIFIC FOOTBALL WIRE CHARACTER DREAMS GERMS SWIM KNOWLEDGE BASEBALL EXPERIENCE NEEDLE THOUGHT CHARACTERS FEVER SWIMMING WORK PLAYERS EMPLOYMENT CURRENT AUTHOR IMAGINATION CAUSE POOL OPPORTUNITIES RESEARCH PLAY COIL READ MOMENT CAUSED LIKE WORKING CHEMISTRY FIELD POLES TOLD THOUGHTS SPREAD SHELL TRAINING TECHNOLOGY PLAYER IRON SETTING OWN VIRUSES SHARK SKILLS MANY BASKETBALL COMPASS TALES REAL INFECTION TANK CAREERS MATHEMATICS COACH LINES PLOT LIFE VIRUS SHELLS POSITIONS BIOLOGY PLAYED CORE TELLING IMAGINE MICROORGANISMS SHARKS FIND FIELD PLAYING ELECTRIC SHORT SENSE PERSON DIVING POSITION PHYSICS HIT DIRECTION INFECTIOUS DOLPHINS CONSCIOUSNESS FICTION FIELD LABORATORY TENNIS FORCE ACTION STRANGE COMMON SWAM OCCUPATIONS STUDIES TEAMS MAGNETS TRUE FEELING CAUSING LONG REQUIRE WORLD GAMES BE EVENTS WHOLE SMALLPOX SEAL OPPORTUNITY SPORTS MAGNETISM SCIENTIST TELLS BEING BODY DIVE EARN STUDYING BAT POLE TALE MIGHT INFECTIONS DOLPHIN ABLE SCIENCES TERRY INDUCED NOVEL HOPE CERTAIN UNDERWATER [Tennenbaum et al]
Example topics induced from a large collection of text JOB SCIENCE BALL FIELD STORY MIND DISEASE WATER WORK STUDY GAME MAGNETIC STORIES WORLD BACTERIA FISH JOBS SCIENTISTS TEAM MAGNET TELL DREAM DISEASES SEA CAREER SCIENTIFIC FOOTBALL WIRE CHARACTER DREAMS GERMS SWIM KNOWLEDGE BASEBALL EXPERIENCE NEEDLE THOUGHT CHARACTERS FEVER SWIMMING WORK PLAYERS EMPLOYMENT CURRENT AUTHOR IMAGINATION CAUSE POOL OPPORTUNITIES RESEARCH PLAY COIL READ MOMENT CAUSED LIKE WORKING CHEMISTRY FIELD POLES TOLD THOUGHTS SPREAD SHELL TRAINING TECHNOLOGY PLAYER IRON SETTING OWN VIRUSES SHARK SKILLS MANY BASKETBALL COMPASS TALES REAL INFECTION TANK CAREERS MATHEMATICS COACH LINES PLOT LIFE VIRUS SHELLS POSITIONS BIOLOGY PLAYED CORE TELLING IMAGINE MICROORGANISMS SHARKS FIND FIELD PLAYING ELECTRIC SHORT SENSE PERSON DIVING POSITION PHYSICS HIT DIRECTION INFECTIOUS DOLPHINS CONSCIOUSNESS FICTION FIELD LABORATORY TENNIS FORCE ACTION STRANGE COMMON SWAM OCCUPATIONS STUDIES TEAMS MAGNETS TRUE FEELING CAUSING LONG REQUIRE WORLD GAMES BE EVENTS WHOLE SMALLPOX SEAL OPPORTUNITY SPORTS MAGNETISM SCIENTIST TELLS BEING BODY DIVE EARN STUDYING BAT POLE TALE MIGHT INFECTIONS DOLPHIN ABLE SCIENCES TERRY INDUCED NOVEL HOPE CERTAIN UNDERWATER [Tennenbaum et al]
 Example topics induced from a large collection of text JOB SCIENCE BALL FIELD STORY MIND DISEASE WATER WORK STUDY GAME MAGNETIC STORIES WORLD BACTERIA FISH JOBS SCIENTISTS TEAM MAGNET TELL DREAM DISEASES SEA CAREER SCIENTIFIC FOOTBALL WIRE CHARACTER DREAMS GERMS SWIM KNOWLEDGE BASEBALL EXPERIENCE NEEDLE THOUGHT CHARACTERS FEVER SWIMMING WORK PLAYERS EMPLOYMENT CURRENT AUTHOR IMAGINATION CAUSE POOL OPPORTUNITIES RESEARCH PLAY COIL READ MOMENT CAUSED LIKE WORKING CHEMISTRY FIELD POLES TOLD THOUGHTS SPREAD SHELL TRAINING TECHNOLOGY PLAYER IRON SETTING OWN VIRUSES SHARK SKILLS MANY BASKETBALL COMPASS TALES REAL INFECTION TANK CAREERS MATHEMATICS COACH LINES PLOT LIFE VIRUS SHELLS POSITIONS BIOLOGY PLAYED CORE TELLING IMAGINE MICROORGANISMS SHARKS FIND FIELD PLAYING ELECTRIC SHORT SENSE PERSON DIVING POSITION PHYSICS HIT DIRECTION INFECTIOUS DOLPHINS CONSCIOUSNESS FICTION FIELD LABORATORY TENNIS FORCE ACTION STRANGE COMMON SWAM OCCUPATIONS STUDIES TEAMS MAGNETS TRUE FEELING CAUSING LONG REQUIRE WORLD GAMES BE EVENTS WHOLE SMALLPOX SEAL OPPORTUNITY SPORTS MAGNETISM SCIENTIST TELLS BEING BODY DIVE EARN STUDYING BAT POLE TALE MIGHT INFECTIONS DOLPHIN ABLE SCIENCES TERRY INDUCED NOVEL HOPE CERTAIN UNDERWATER [Tennenbaum et al]
Example topics induced from a large collection of text JOB SCIENCE BALL FIELD STORY MIND DISEASE WATER WORK STUDY GAME MAGNETIC STORIES WORLD BACTERIA FISH JOBS SCIENTISTS TEAM MAGNET TELL DREAM DISEASES SEA CAREER SCIENTIFIC FOOTBALL WIRE CHARACTER DREAMS GERMS SWIM KNOWLEDGE BASEBALL EXPERIENCE NEEDLE THOUGHT CHARACTERS FEVER SWIMMING WORK PLAYERS EMPLOYMENT CURRENT AUTHOR IMAGINATION CAUSE POOL OPPORTUNITIES RESEARCH PLAY COIL READ MOMENT CAUSED LIKE WORKING CHEMISTRY FIELD POLES TOLD THOUGHTS SPREAD SHELL TRAINING TECHNOLOGY PLAYER IRON SETTING OWN VIRUSES SHARK SKILLS MANY BASKETBALL COMPASS TALES REAL INFECTION TANK CAREERS MATHEMATICS COACH LINES PLOT LIFE VIRUS SHELLS POSITIONS BIOLOGY PLAYED CORE TELLING IMAGINE MICROORGANISMS SHARKS FIND FIELD PLAYING ELECTRIC SHORT SENSE PERSON DIVING POSITION PHYSICS HIT DIRECTION INFECTIOUS DOLPHINS CONSCIOUSNESS FICTION FIELD LABORATORY TENNIS FORCE ACTION STRANGE COMMON SWAM OCCUPATIONS STUDIES TEAMS MAGNETS TRUE FEELING CAUSING LONG REQUIRE WORLD GAMES BE EVENTS WHOLE SMALLPOX SEAL OPPORTUNITY SPORTS MAGNETISM SCIENTIST TELLS BEING BODY DIVE EARN STUDYING BAT POLE TALE MIGHT INFECTIONS DOLPHIN ABLE SCIENCES TERRY INDUCED NOVEL HOPE CERTAIN UNDERWATER [Tennenbaum et al]
 72") From LDA to Author-Recipient-Topic (ART) 72
From LDA to Author-Recipient-Topic (ART) 72
 Inference and Estimation Gibbs Sampling: - Easy to implement - Reasonably fast r 73
Inference and Estimation Gibbs Sampling: - Easy to implement - Reasonably fast r 73
 Outline a. Email, motivation a. ART Graphical Model. u u u Experimental Results – Enron Email (corpus) – Academic Email (one person) u RART: Roles for ART u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 74
Outline a. Email, motivation a. ART Graphical Model. u u u Experimental Results – Enron Email (corpus) – Academic Email (one person) u RART: Roles for ART u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 74
 Enron Email Corpus u u 250 k email messages 23 k people Date: Wed, 11 Apr 2001 06: 56: 00 -0700 (PDT) From: debra. perlingiere@enron. com To: steve. hooser@enron. com Subject: Enron/Trans. Alta. Contract dated Jan 1, 2001 Please see below. Katalin Kiss of Trans. Alta has requested an electronic copy of our final draft? Are you OK with this? If so, the only version I have is the original draft without revisions. DP Debra Perlingiere Enron North America Corp. Legal Department 1400 Smith Street, EB 3885 Houston, Texas 77002 dperlin@enron. com 75
Enron Email Corpus u u 250 k email messages 23 k people Date: Wed, 11 Apr 2001 06: 56: 00 -0700 (PDT) From: debra. perlingiere@enron. com To: steve. hooser@enron. com Subject: Enron/Trans. Alta. Contract dated Jan 1, 2001 Please see below. Katalin Kiss of Trans. Alta has requested an electronic copy of our final draft? Are you OK with this? If so, the only version I have is the original draft without revisions. DP Debra Perlingiere Enron North America Corp. Legal Department 1400 Smith Street, EB 3885 Houston, Texas 77002 dperlin@enron. com 75
 Topic names, by hand Topics, and prominent senders / receivers discovered by ART 76
Topic names, by hand Topics, and prominent senders / receivers discovered by ART 76
 Topics, and prominent sender/receivers discovered by ART Beck = “Chief Operations Officer” Dasovich = “Government Relations Executive” Shapiro = “Vice President of Regulatory Affairs” Steffes = “Vice President of Government Affairs” 77
Topics, and prominent sender/receivers discovered by ART Beck = “Chief Operations Officer” Dasovich = “Government Relations Executive” Shapiro = “Vice President of Regulatory Affairs” Steffes = “Vice President of Government Affairs” 77
 Comparing Role Discovery Traditional SNA ART Author-Topic distribution over authored topics connection strength (A, B) = distribution over recipients 78
Comparing Role Discovery Traditional SNA ART Author-Topic distribution over authored topics connection strength (A, B) = distribution over recipients 78
 Comparing Role Discovery Tracy Geaconne Dan Mc. Carty Traditional SNA ART Similar roles Different roles Author-Topic Different roles Geaconne = “Secretary” Mc. Carty = “Vice President” 79
Comparing Role Discovery Tracy Geaconne Dan Mc. Carty Traditional SNA ART Similar roles Different roles Author-Topic Different roles Geaconne = “Secretary” Mc. Carty = “Vice President” 79
 Comparing Role Discovery Tracy Geaconne Rod Hayslett Traditional SNA Different roles ART Not very similar Author-Topic Very similar Geaconne = “Secretary” Hayslett = “Vice President & CTO” 80
Comparing Role Discovery Tracy Geaconne Rod Hayslett Traditional SNA Different roles ART Not very similar Author-Topic Very similar Geaconne = “Secretary” Hayslett = “Vice President & CTO” 80
 Comparing Role Discovery Lynn Blair Kimberly Watson Traditional SNA Different roles ART Very similar Author-Topic Very different Blair = “Gas pipeline logistics” Watson = “Pipeline facilities planning” 81
Comparing Role Discovery Lynn Blair Kimberly Watson Traditional SNA Different roles ART Very similar Author-Topic Very different Blair = “Gas pipeline logistics” Watson = “Pipeline facilities planning” 81
 Mc. Callum Email Corpus 2004 u u u January - October 2004 23 k email messages 825 people From: kate@cs. umass. edu Subject: NIPS and. . Date: June 14, 2004 2: 27: 41 PM EDT To: mccallum@cs. umass. edu There is pertinent stuff on the first yellow folder that is completed either travel or other things, so please sign that first folder anyway. Then, here is the reminder of the things I'm still waiting for: NIPS registration receipt. CALO registration receipt. Thanks, Kate 82
Mc. Callum Email Corpus 2004 u u u January - October 2004 23 k email messages 825 people From: kate@cs. umass. edu Subject: NIPS and. . Date: June 14, 2004 2: 27: 41 PM EDT To: mccallum@cs. umass. edu There is pertinent stuff on the first yellow folder that is completed either travel or other things, so please sign that first folder anyway. Then, here is the reminder of the things I'm still waiting for: NIPS registration receipt. CALO registration receipt. Thanks, Kate 82
 Mc. Callum Email Blockstructure 83
Mc. Callum Email Blockstructure 83
 Four most prominent topics in discussions with ____? 84
Four most prominent topics in discussions with ____? 84
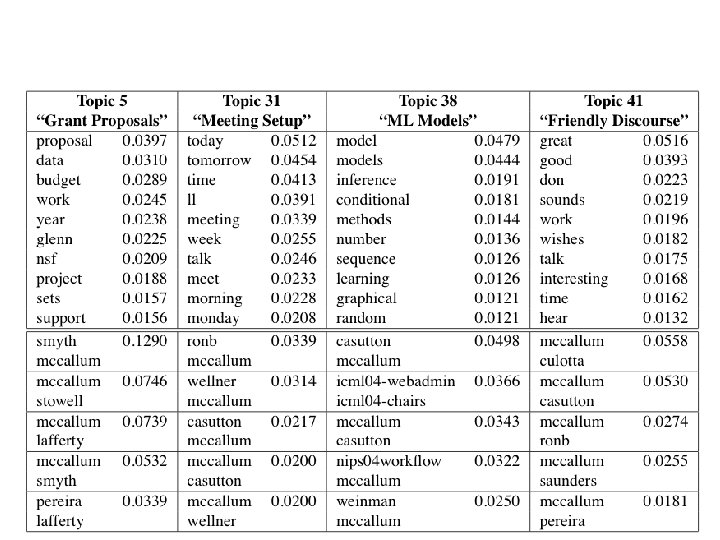
 Two most prominent topics in discussions with ____? 86
Two most prominent topics in discussions with ____? 86
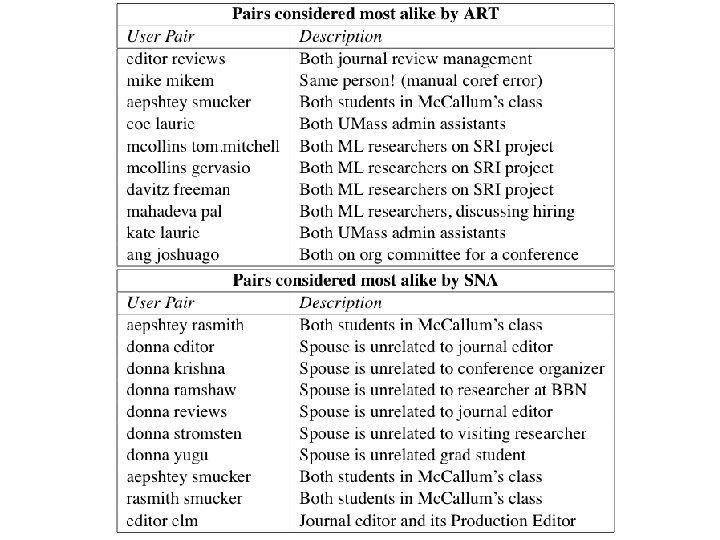
 Outline a. Email, motivation a. ART Graphical Model. a. Experimental Results u u u – Enron Email (corpus) – Academic Email (one person) u RART: Roles for ART u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 90
Outline a. Email, motivation a. ART Graphical Model. a. Experimental Results u u u – Enron Email (corpus) – Academic Email (one person) u RART: Roles for ART u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 90
 Role-Author-Recipient-Topic Models 91
Role-Author-Recipient-Topic Models 91
 Results with RART: People in “Role #3” in Academic Email u u u u olc gauthier irsystem allan valerie tech steve lead Linux sysadmin for CIIR group mailing list CIIR sysadmins mailing list for dept. sysadmins Prof. , chair of “computing committee” second Linux sysadmin mailing list for dept. hardware head of dept. I. T. support 92
Results with RART: People in “Role #3” in Academic Email u u u u olc gauthier irsystem allan valerie tech steve lead Linux sysadmin for CIIR group mailing list CIIR sysadmins mailing list for dept. sysadmins Prof. , chair of “computing committee” second Linux sysadmin mailing list for dept. hardware head of dept. I. T. support 92
 u u Role #3 Role #2 I. T. support") Roles for allan (James Allan) u u Role #3 Role #2 I. T. support Natural Language researcher Roles for pereira (Fernando Pereira) u u u Role #2 Role #4 Role #6 Role #10 Role #8 Natural Language researcher SRI CALO project participant Grant proposal writer Grant proposal coordinator Guests at Mc. Callum’s house 93
Roles for allan (James Allan) u u Role #3 Role #2 I. T. support Natural Language researcher Roles for pereira (Fernando Pereira) u u u Role #2 Role #4 Role #6 Role #10 Role #8 Natural Language researcher SRI CALO project participant Grant proposal writer Grant proposal coordinator Guests at Mc. Callum’s house 93
 Outline a. Email, motivation a. ART Graphical Model. a. Experimental Results u u u – Enron Email (corpus) – Academic Email (one person) a. RART: Roles for ART u u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 94
Outline a. Email, motivation a. ART Graphical Model. a. Experimental Results u u u – Enron Email (corpus) – Academic Email (one person) a. RART: Roles for ART u u Group-Topic Model – Experiments on voting data – Voting data from U. S. Senate and the U. N. 94
 ART & RART: Roles but not Groups Traditional SNA Block structured ART Not Author-Topic Not Enron Trans. Western Division 95
ART & RART: Roles but not Groups Traditional SNA Block structured ART Not Author-Topic Not Enron Trans. Western Division 95
 A Group Model: “Stochastic Blockstructures Model” 96
A Group Model: “Stochastic Blockstructures Model” 96
![Group-Topic Model [Wang, Mohanty, Mc. Callum 2005] 97](https://present5.com/presentation/20846eeabdd231ea4bd7b873705819a6/image-81.jpg "Group-Topic Model [Wang, Mohanty, Mc. Callum 2005] 97") Group-Topic Model [Wang, Mohanty, Mc. Callum 2005] 97
Group-Topic Model [Wang, Mohanty, Mc. Callum 2005] 97
 U. S. Senate Data sets u u u 3426 bills from 16 years of voting records from the U. S. Senate Yea / Nea / Abstain (absent) Each bill comes with an abstract (text describing the contents of the bill). 98
U. S. Senate Data sets u u u 3426 bills from 16 years of voting records from the U. S. Senate Yea / Nea / Abstain (absent) Each bill comes with an abstract (text describing the contents of the bill). 98
 Topics Discovered Traditional “Mixtures of Unigrams” Group. Topic Model 99
Topics Discovered Traditional “Mixtures of Unigrams” Group. Topic Model 99
 Groups Discovered Agreement Index Groups from topic Education + Domestic 100
Groups Discovered Agreement Index Groups from topic Education + Domestic 100
 votes with") Senators who change Coalition Dependent on Topic e. g. Senator Shelby (D-AL) votes with the Republicans on Economic with the Democrats on Education + Domestic with a small group of maverick Republicans on Social Security + Medicaid 101
Senators who change Coalition Dependent on Topic e. g. Senator Shelby (D-AL) votes with the Republicans on Economic with the Democrats on Education + Domestic with a small group of maverick Republicans on Social Security + Medicaid 101
 U. N. Data Set u u 931 U. N. Resolutions, voted on by 192 countries, from 1990 -2003. Yes / No / Abstain votes List of keywords summarizes the content of the resolution. Also experiments later with resolutions from 19602003 102
U. N. Data Set u u 931 U. N. Resolutions, voted on by 192 countries, from 1990 -2003. Yes / No / Abstain votes List of keywords summarizes the content of the resolution. Also experiments later with resolutions from 19602003 102
 Topics Discovered Traditional mixture of unigrams Group-Topic Model 103
Topics Discovered Traditional mixture of unigrams Group-Topic Model 103
 Groups Discovered 104
Groups Discovered 104
 Groups and Topics, Trends over Time 105
Groups and Topics, Trends over Time 105