2120ee7675c1b7b5a7c68351bc8c9076.ppt
- Количество слайдов: 29



Infrastructure Strategies for Success Behind the University of Florida's Sakai Implementation Chris Cuevas, Systems Administrator (airwalk@ufl. edu) Martin Smith, Systems Administrator (smithmb@ufl. edu)

What is a. . . Design pattern "A general reusable solution to a commonly occurring problem. " [1] http: //en. wikipedia. org/wiki/Design_pattern_%28 computer_science%29 12 th Sakai Conference – Los Angeles, California – June 14 -16

Patterns for… Change control, build promotion, deployment 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Baseline set of artifacts for a change • What do we consider a complete build? o Version number o Readme file o Change log o SQL scripts o Sakai 'binary' distribution • Reduce ambiguity, recovery time, and improves the chance of catching errors early 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: build promotion process • All changes are load tested and functionally tested against monitoring scripts (i. e. our test cluster is the same size as our prod cluster, and it is monitored like prod) • All changes require a full two weeks of testing time, a go/no-go decision at least 4 days before (this allows us to announce the change), and at least a 2 hour maintenance window 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Maintenance for a new build • During a deployment/build promotion, we have two strategies: o Rolling restart: Quiesce nodes, upgrade them, and reintroduce them o Full outage: Stop all nodes, upgrade in chunks, apply any SQL, and start them all • Session replication is key here for seamless upgrades (and with Sakai, we don't have it). 12 th Sakai Conference – Los Angeles, California – June 14 -16
 12 th Sakai Conference – Los Angeles,")
Patterns for… Other Software (OS/DB/etc patches, updates) 12 th Sakai Conference – Los Angeles, California – June 14 -16

Patterns: Other updates • High risk packages are identified, only updated by those who know the application best • All others packages are updated (at least) quarterly • Database patches are done best-effort (for now) • Rarely, infrastructure-wide changes will affect a particular service worse than others • We reserve a weekly maintenance window • Least well understood at this time 12 th Sakai Conference – Los Angeles, California – June 14 -16

Patterns for… Traffic Management 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Application stack • User Traffic dispatching o Sticky TCP traffic to Apache httpd frontends based on perceived health o Cookie based route from httpd to tomcat, with ability to select a node o Both of these fail to failover session information well • We’re considering a design pattern where we combine the httpd+tomcat stack and do full NAT dispatching so that we can get more change flexibility • Compare other architectures 12 th Sakai Conference – Los Angeles, California – June 14 -16

Current cluster layout 12 th Sakai Conference – Los Angeles, California – June 14 -16

Current cluster layout as two sites 12 th Sakai Conference – Los Angeles, California – June 14 -16

Site-local dispatching 12 th Sakai Conference – Los Angeles, California – June 14 -16

Combining more of the stack 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Resource clustering • • • Database failover is automatic now with Oracle & JDBC File tier still doesn't do failover in any nice way Application+web tier no longer complex dependencies (All state for a user lives on a single server now) Split presence across two sites for database (dataguard), file storage (emc celerra), app/web tier (vmware) 12 th Sakai Conference – Los Angeles, California – June 14 -16

Patterns for… Monitoring and logging 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: System health checks • Overall: o Fully synthetic login to Sakai o Cluster checks on Apache and Tomcat (more than X out of Y servers in the cluster in a bad state) o Wget? • Individual server checks for web, app, db tiers o Database connection pool o Clock, SNMP, Ping, Disk o Java processes, Apache configtest o AJP and Web response time and status codes o Replication health, available storage growth 12 th Sakai Conference – Los Angeles, California – June 14 -16
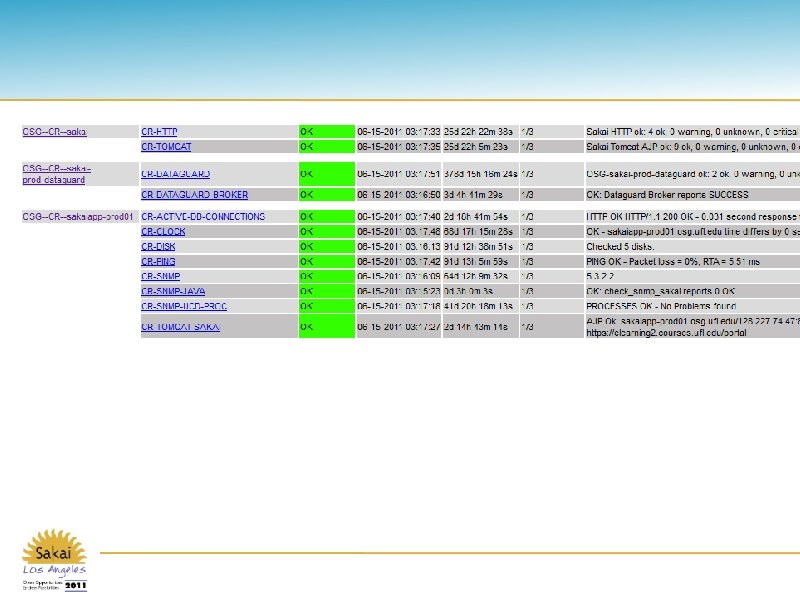

Pattern: Interventions • Fully automated functional test that authenticates and requests some course sites • Response time is as-important as success or failure • We’re hesitant to automatically restart application nodes, since session replication isn’t available – this would be a major interruption to our users 12 th Sakai Conference – Los Angeles, California – June 14 -16
")
Pattern: Collecting data • Collect the usual suspects • sakai events, automatic (? ) thread dumps to detect stuck processes, server-status results • Sakai health: . jsp file that dumps many data points (JVM memory, ehcache stats, database pools, etc) • Anything we can pull from the JVM or Sakai APIs, we’ll use that jsp file and collectd 12 th Sakai Conference – Los Angeles, California – June 14 -16
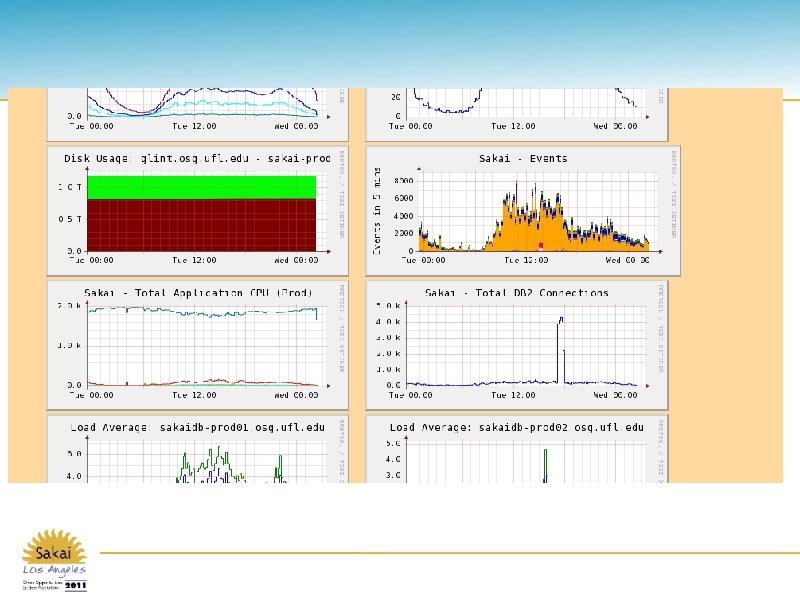

Pattern: Application responsiveness • Also known as, "Get close to the user" • Bug reports are aggregated using shared mailbox, send daily/weekly/yearly reports with buckets for browser, user, course site, tool, stack trace hash, etc • Redirection for 4 XX/5 XX http status codes as much as possible, with explanations • Timeouts for long-running activities, so make sure traffic isn’t waiting forever • Watch for AJP errors from specific application servers 12 th Sakai Conference – Los Angeles, California – June 14 -16

Summary of weekly Sakai bug reports for 2011 -06 -12: browser-id => count: Mac-Mozilla => 377 Win-Internet. Explorer => 356 Win-Mozilla => 194 Unknown. Browser => 33 empty => 12 service-version => count: [r 329] => 967 empty => 8 user => count: atorres 78 (Alina Torres) => 32 lisareeve (Lisa Jacobs) => 26 ziggy 41 (Stefan Katz) => 15 ngrosztenger (Nathalie Grosz-Tenger) => 14 agabriel 2450 (Gabriel Arguello) => 12 stack-trace-digest => count: 41 D 7 C 94702 B 20 B 270953 EBB 00 ECA 9 F 5 C 1388 A 393 => 180 DEB 88 C 2307 DA 572 C 9 C 1 EFE 1 E 8 E 17828 DC 29 A 7 C 00 => 154 A 600 DAE 1792 C 82 B 1472 C 9980 EED 8938 E 5 F 39 B 4 F 0 => 88 15963 E 2 F 2314286 E 1 BC 1 A 24 DF 953560 B 7845 BDCE => 33 042 CF 39 E 8 D 34570 CD 3 D 79152 B 757 A 090 AB 6 AB 39 F => 24 app-server => count: sakaiapp-prod 06. osg. ufl. edu => 154 sakaiapp-prod 02. osg. ufl. edu => 146 sakaiapp-prod 04. osg. ufl. edu => 118 sakaiapp-prod 05. osg. ufl. edu => 96 sakaiapp-prod 03. osg. ufl. edu => 83

Patterns for… Backup and recovery 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Backing up for DR • File tier is backed up every 4 hours, with a 2 week retention window • Database tier is backed up daily, with archived redo logs every 4 hours, and 2 week retention window 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Backing up user data • Hoping this comes from application-specific operations to backup and restore (and delete!) user specific data • Can't do a full restore of your files and database every time your user deletes a site by accident • Strive for reasonable windows of retention (e. g. hardware, software, application-level data) • This is supposedly coming in Sakai 2. x 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Multi-site replication • Database and file tier are both replicated to a 2 nd site, file tier is also redundant internally, some manual intervention still required there 12 th Sakai Conference – Los Angeles, California – June 14 -16

Pattern: Bringing production to test • We use ‘snapshot standby’ in Oracle RDBMS to take read consistent copies of production for reloading test and development copies • We use rsync to copy over the file storage tier • With our full set of build artifacts from earlier, we can always build a complete version of what's in prod 12 th Sakai Conference – Los Angeles, California – June 14 -16

Thank you! Questions? 12 th Sakai Conference – Los Angeles, California – June 14 -16
2120ee7675c1b7b5a7c68351bc8c9076.ppt