

7c09536167fdbcc2087c0498acaa3eb2.ppt
- Количество слайдов: 51
 Prof. Dragomir R. Radev radev@umich. edu") Information Retrieval (1) Prof. Dragomir R. Radev radev@umich. edu
Information Retrieval (1) Prof. Dragomir R. Radev radev@umich. edu
 IR WINTER 2010 … 1. Introduction … …
IR WINTER 2010 … 1. Introduction … …
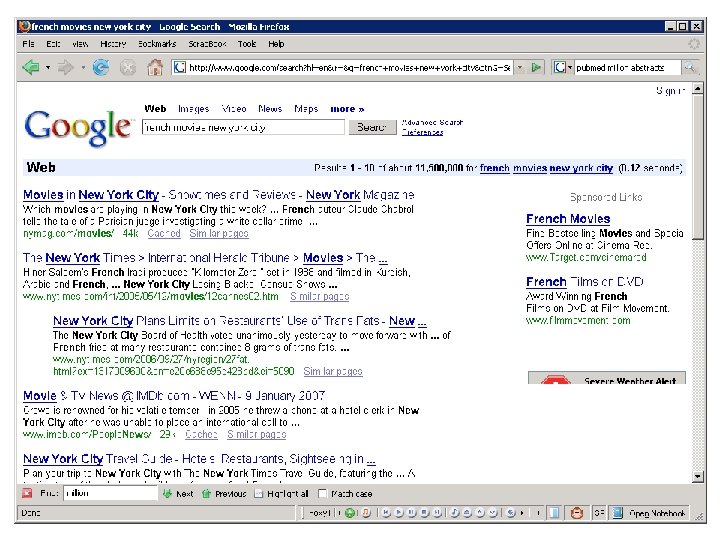
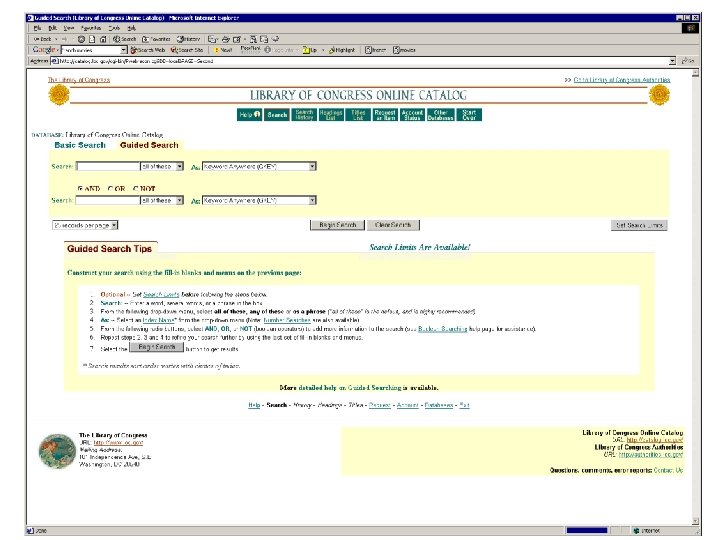
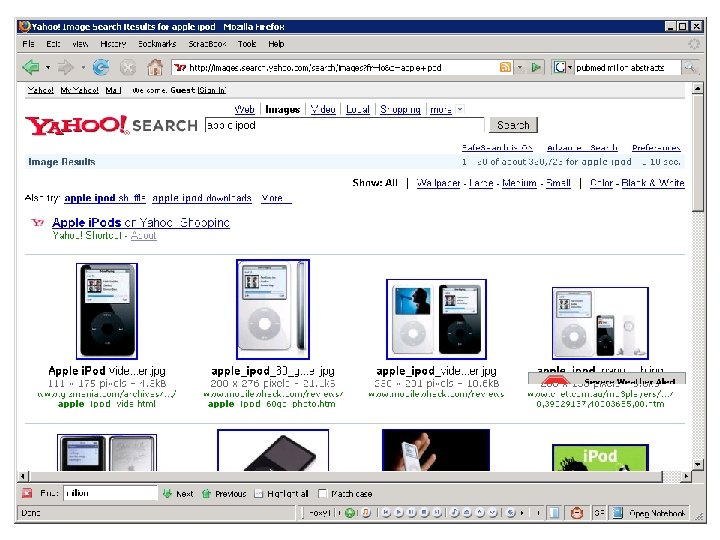
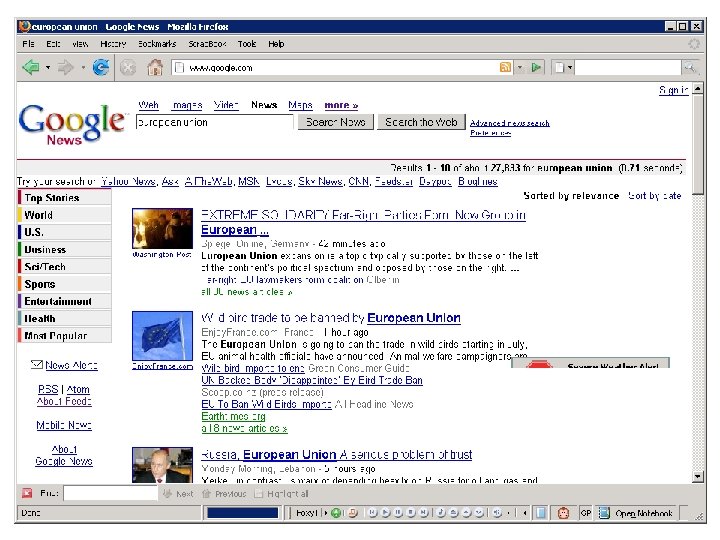
. Search by keyword, title, author, etc.") Examples of search engines • Conventional (library catalog). Search by keyword, title, author, etc. • Text-based (Lexis-Nexis, Google, Yahoo!). Search by keywords. Limited search using queries in natural language. • Multimedia (QBIC, Web. Seek, Sa. Fe) Search by visual appearance (shapes, colors, … ). • Question answering systems (Ask, NSIR, Answerbus) Search in (restricted) natural language • Clustering systems (Vivísimo, Clusty) • Research systems (Lemur, Nutch)
Examples of search engines • Conventional (library catalog). Search by keyword, title, author, etc. • Text-based (Lexis-Nexis, Google, Yahoo!). Search by keywords. Limited search using queries in natural language. • Multimedia (QBIC, Web. Seek, Sa. Fe) Search by visual appearance (shapes, colors, … ). • Question answering systems (Ask, NSIR, Answerbus) Search in (restricted) natural language • Clustering systems (Vivísimo, Clusty) • Research systems (Lemur, Nutch)
 What does it take to build a search engine? • • • Decide what to index Collect it Index it (efficiently) Keep the index up to date Provide user-friendly query facilities
What does it take to build a search engine? • • • Decide what to index Collect it Index it (efficiently) Keep the index up to date Provide user-friendly query facilities
 What else? • Understand the structure of the web for efficient crawling • Understand user information needs • Preprocess text and other unstructured data • Cluster data • Classify data • Evaluate performance
What else? • Understand the structure of the web for efficient crawling • Understand user information needs • Preprocess text and other unstructured data • Cluster data • Classify data • Evaluate performance
 Goals of the course • • • • Understand how search engines work Understand the limits of existing search technology Learn to appreciate the sheer size of the Web Learn to wrote code for text indexing and retrieval Learn about the state of the art in IR research Learn to analyze textual and semi-structured data sets Learn to appreciate the diversity of texts on the Web Learn to evaluate information retrieval Learn about standardized document collections Learn about text similarity measures Learn about semantic dimensionality reduction Learn about the idiosyncracies of hyperlinked document collections Learn about web crawling Learn to use existing software Understand the dynamics of the Web by building appropriate mathematical models Build working systems that assist users in finding useful information on the Web
Goals of the course • • • • Understand how search engines work Understand the limits of existing search technology Learn to appreciate the sheer size of the Web Learn to wrote code for text indexing and retrieval Learn about the state of the art in IR research Learn to analyze textual and semi-structured data sets Learn to appreciate the diversity of texts on the Web Learn to evaluate information retrieval Learn about standardized document collections Learn about text similarity measures Learn about semantic dimensionality reduction Learn about the idiosyncracies of hyperlinked document collections Learn about web crawling Learn to use existing software Understand the dynamics of the Web by building appropriate mathematical models Build working systems that assist users in finding useful information on the Web
 Course logistics • • Fridays 2: 10 -4: 55 PM Office hours: TBA URL: http: //clair. si. umich. edu/si 650 Instructor: Dragomir Radev Email: radev@umich. edu Instructor: Qiaozhu Mei Email: qmei@umich. edu
Course logistics • • Fridays 2: 10 -4: 55 PM Office hours: TBA URL: http: //clair. si. umich. edu/si 650 Instructor: Dragomir Radev Email: radev@umich. edu Instructor: Qiaozhu Mei Email: qmei@umich. edu
 Course outline • Classic document retrieval: storing, indexing, retrieval. • Web retrieval: crawling, query processing. • Text and web mining: classification, clustering. • Network analysis: random graph models, centrality, diameter and clustering coefficient.
Course outline • Classic document retrieval: storing, indexing, retrieval. • Web retrieval: crawling, query processing. • Text and web mining: classification, clustering. • Network analysis: random graph models, centrality, diameter and clustering coefficient.
 Syllabus • • • Introduction. Queries and Documents. Models of Information retrieval. The Boolean model. The Vector model. Document preprocessing. Tokenization. Stemming. The Porter algorithm. Storing, indexing and searching text. Inverted indexes. Word distributions. The Zipf distribution. The Benford distribution. Heap's law. TF*IDF. Vector space similarity and ranking. Retrievaluation. Precision and Recall. F-measure. Reference collections. The TREC conferences. Automated indexing/labeling. Compression and coding. Optimal codes. String matching. Approximate matching. Query expansion. Relevance feedback. Text classification. Naive Bayes. Feature selection. Decision trees.
Syllabus • • • Introduction. Queries and Documents. Models of Information retrieval. The Boolean model. The Vector model. Document preprocessing. Tokenization. Stemming. The Porter algorithm. Storing, indexing and searching text. Inverted indexes. Word distributions. The Zipf distribution. The Benford distribution. Heap's law. TF*IDF. Vector space similarity and ranking. Retrievaluation. Precision and Recall. F-measure. Reference collections. The TREC conferences. Automated indexing/labeling. Compression and coding. Optimal codes. String matching. Approximate matching. Query expansion. Relevance feedback. Text classification. Naive Bayes. Feature selection. Decision trees.
 Syllabus • • • Linear classifiers. k-nearest neighbors. Perceptron. Kernel methods. Maximum-margin classifiers. Support vector machines. Semi-supervised learning. Lexical semantics and Wordnet. Latent semantic indexing. Singular value decomposition. Vector space clustering. k-means clustering. EM clustering. Random graph models. Properties of random graphs: clustering coefficient, betweenness, diameter, giant connected component, degree distribution. Social network analysis. Small worlds and scale-free networks. Power law distributions. Centrality. Graph-based methods. Harmonic functions. Random walks. Page. Rank. Hubs and authorities. Bipartite graphs. HITS. Models of the Web.
Syllabus • • • Linear classifiers. k-nearest neighbors. Perceptron. Kernel methods. Maximum-margin classifiers. Support vector machines. Semi-supervised learning. Lexical semantics and Wordnet. Latent semantic indexing. Singular value decomposition. Vector space clustering. k-means clustering. EM clustering. Random graph models. Properties of random graphs: clustering coefficient, betweenness, diameter, giant connected component, degree distribution. Social network analysis. Small worlds and scale-free networks. Power law distributions. Centrality. Graph-based methods. Harmonic functions. Random walks. Page. Rank. Hubs and authorities. Bipartite graphs. HITS. Models of the Web.
 Syllabus • • Crawling the web. Webometrics. Measuring the size of the web. The Bow-tiemethod. Hypertext retrieval. Web-based IR. Document closures. Focused crawling. Question answering Burstiness. Self-triggerability Information extraction Adversarial IR. Human behavior on the web. Text summarization POSSIBLE TOPICS • • • Discovering communities, spectral clustering Semi-supervised retrieval Natural language processing. XML retrieval. Text tiling. Human behavior on the web.
Syllabus • • Crawling the web. Webometrics. Measuring the size of the web. The Bow-tiemethod. Hypertext retrieval. Web-based IR. Document closures. Focused crawling. Question answering Burstiness. Self-triggerability Information extraction Adversarial IR. Human behavior on the web. Text summarization POSSIBLE TOPICS • • • Discovering communities, spectral clustering Semi-supervised retrieval Natural language processing. XML retrieval. Text tiling. Human behavior on the web.
 Readings • required: Information Retrieval by Manning, Schuetze, and Raghavan (http: //wwwcsli. stanford. edu/~schuetze/information-retrievalbook. html), freely available, hard copy for sale • optional: Modeling the Internet and the Web: Probabilistic Methods and Algorithms by Pierre Baldi, Paolo Frasconi, Padhraic Smyth, Wiley, 2003, ISBN: 0 -470 -84906 -1 (http: //ibook. ics. uci. edu). • papers from SIGIR, WWW and journals (to be announced in class).
Readings • required: Information Retrieval by Manning, Schuetze, and Raghavan (http: //wwwcsli. stanford. edu/~schuetze/information-retrievalbook. html), freely available, hard copy for sale • optional: Modeling the Internet and the Web: Probabilistic Methods and Algorithms by Pierre Baldi, Paolo Frasconi, Padhraic Smyth, Wiley, 2003, ISBN: 0 -470 -84906 -1 (http: //ibook. ics. uci. edu). • papers from SIGIR, WWW and journals (to be announced in class).
 Prerequisites • Linear algebra: vectors and matrices. • Calculus: Finding extrema of functions. • Probabilities: random variables, discrete and continuous distributions, Bayes theorem. • Programming: experience with at least one webaware programming language such as Perl (highly recommended) or Java in a UNIX environment. • Required CS account
Prerequisites • Linear algebra: vectors and matrices. • Calculus: Finding extrema of functions. • Probabilities: random variables, discrete and continuous distributions, Bayes theorem. • Programming: experience with at least one webaware programming language such as Perl (highly recommended) or Java in a UNIX environment. • Required CS account
 – Some of them will be in Perl.") Course requirements • Three assignments (30%) – Some of them will be in Perl. The rest can be done in any appropriate language. All will involve some data analysis and evaluation • Final project (30%) – Research paper or software system. • Class participation (10%) • Final exam (30%)
Course requirements • Three assignments (30%) – Some of them will be in Perl. The rest can be done in any appropriate language. All will involve some data analysis and evaluation • Final project (30%) – Research paper or software system. • Class participation (10%) • Final exam (30%)
 Final project format • Research paper - using the SIGIR format. Students will be in charge of problem formulation, literature survey, hypothesis formulation, experimental design, implementation, and possibly submission to a conference like SIGIR or WWW. • Software system - develop a working system or API. Students will be responsible for identifying a niche problem, implementing it and deploying it, either on the Web or as an open-source downloadable tool. The system can be either stand alone or an extension to an existing one.
Final project format • Research paper - using the SIGIR format. Students will be in charge of problem formulation, literature survey, hypothesis formulation, experimental design, implementation, and possibly submission to a conference like SIGIR or WWW. • Software system - develop a working system or API. Students will be responsible for identifying a niche problem, implementing it and deploying it, either on the Web or as an open-source downloadable tool. The system can be either stand alone or an extension to an existing one.
 Project ideas • • • • Build a question answering system. Build a language identification system. Social network analysis from the Web. Participate in the Netflix challenge. Query log analysis. Build models of Web evolution. Information diffusion in blogs or web. Author-topic models of web pages. Using the web for machine translation. Building evolving models of web documents. News recommendation system. Compress the text of Wikipedia (losslessly). Spelling correction using query logs. Automatic query expansion.
Project ideas • • • • Build a question answering system. Build a language identification system. Social network analysis from the Web. Participate in the Netflix challenge. Query log analysis. Build models of Web evolution. Information diffusion in blogs or web. Author-topic models of web pages. Using the web for machine translation. Building evolving models of web documents. News recommendation system. Compress the text of Wikipedia (losslessly). Spelling correction using query logs. Automatic query expansion.
 List of projects from the past • • • Document Closures for Indexing Tibet - Table Structure Recognition Library Ruby Blog Memetracker Sentence decomposition for more accurate information retrieval Extracting Social Networks from Live. Journal Google Suggest Programming Project (Java Swing Client and Lucene Back-End) Leveraging Social Networks for Organizing and Browsing Shared Photographs Media Bias and the Political Blogosphere Measuring Similarity between search queries Extracting Social Networks and Information about the people within them from Text LSI + dependency trees
List of projects from the past • • • Document Closures for Indexing Tibet - Table Structure Recognition Library Ruby Blog Memetracker Sentence decomposition for more accurate information retrieval Extracting Social Networks from Live. Journal Google Suggest Programming Project (Java Swing Client and Lucene Back-End) Leveraging Social Networks for Organizing and Browsing Shared Photographs Media Bias and the Political Blogosphere Measuring Similarity between search queries Extracting Social Networks and Information about the people within them from Text LSI + dependency trees
 Available corpora • • • • • Netflix challenge AOL query logs Bio papers AAN Email Generifs Web pages Political science corpus VAST del. icio. us SMS News data: aquaint, tdt, nantc, reuters, setimes, trec, tipster Europarl multilingual US congressional data DMOZ Pubmedcentral DUC/TAC • • • • • Timebank Wikipedia wt 2 g/wt 100 g dotgov RTE Paraphrases GENIA Generifs Hansards IMDB MTA/MTC nie cnnsumm Poliblog Sentiment xml epinions Enron
Available corpora • • • • • Netflix challenge AOL query logs Bio papers AAN Email Generifs Web pages Political science corpus VAST del. icio. us SMS News data: aquaint, tdt, nantc, reuters, setimes, trec, tipster Europarl multilingual US congressional data DMOZ Pubmedcentral DUC/TAC • • • • • Timebank Wikipedia wt 2 g/wt 100 g dotgov RTE Paraphrases GENIA Generifs Hansards IMDB MTA/MTC nie cnnsumm Poliblog Sentiment xml epinions Enron
 • Cornell") Related courses elsewhere • Stanford (Chris Manning, Prabhakar Raghavan, and Hinrich Schuetze) • Cornell (Jon Kleinberg) • CMU (Yiming Yang and Jamie Callan) • UMass (James Allan) • UTexas (Ray Mooney) • Illinois (Chengxiang Zhai) • Johns Hopkins (David Yarowsky) • For a long list of courses related to Search Engines, Natural Language Processing, Machine Learning look here: http: //tangra. si. umich. edu/clair/courses. html
Related courses elsewhere • Stanford (Chris Manning, Prabhakar Raghavan, and Hinrich Schuetze) • Cornell (Jon Kleinberg) • CMU (Yiming Yang and Jamie Callan) • UMass (James Allan) • UTexas (Ray Mooney) • Illinois (Chengxiang Zhai) • Johns Hopkins (David Yarowsky) • For a long list of courses related to Search Engines, Natural Language Processing, Machine Learning look here: http: //tangra. si. umich. edu/clair/courses. html
 IR WINTER 2010 … 2. Models of Information retrieval The Vector model The Boolean model … …
IR WINTER 2010 … 2. Models of Information retrieval The Vector model The Boolean model … …
 The web is really large • • • 100 B pages Dynamically generated content New pages get added all the time Technorati has 50 M+ blogs The size of the blogosphere doubles every 6 months • Yahoo deals with 12 TB of data per day (according to Ron Brachman)
The web is really large • • • 100 B pages Dynamically generated content New pages get added all the time Technorati has 50 M+ blogs The size of the blogosphere doubles every 6 months • Yahoo deals with 12 TB of data per day (according to Ron Brachman)
 In what year did baseball become an offical sport? play") Sample queries (from Excite) In what year did baseball become an offical sport? play station codes. com birth control and depression government "Work. Ability I"+conference kitchen appliances where can I find a chines rosewood tiger electronics 58 Plymouth Fury How does the character Seyavash in Ferdowsi's Shahnameh exhibit characteristics of a hero? emeril Lagasse Hubble M. S Subalaksmi running
Sample queries (from Excite) In what year did baseball become an offical sport? play station codes. com birth control and depression government "Work. Ability I"+conference kitchen appliances where can I find a chines rosewood tiger electronics 58 Plymouth Fury How does the character Seyavash in Ferdowsi's Shahnameh exhibit characteristics of a hero? emeril Lagasse Hubble M. S Subalaksmi running
 Fun things to do with search engines • Googlewhack • Reduce document set size to 1 • Find query that will bring given URL in the top 10
Fun things to do with search engines • Googlewhack • Reduce document set size to 1 • Find query that will bring given URL in the top 10
 Key Terms Used in IR • QUERY: a representation of what the user is looking for - can be a list of words or a phrase. • DOCUMENT: an information entity that the user wants to retrieve • COLLECTION: a set of documents • INDEX: a representation of information that makes querying easier • TERM: word or concept that appears in a document or a query
Key Terms Used in IR • QUERY: a representation of what the user is looking for - can be a list of words or a phrase. • DOCUMENT: an information entity that the user wants to retrieve • COLLECTION: a set of documents • INDEX: a representation of information that makes querying easier • TERM: word or concept that appears in a document or a query
 Mappings and abstractions Reality Data Information need Query From Robert Korfhage’s book
Mappings and abstractions Reality Data Information need Query From Robert Korfhage’s book
 Documents • Not just printed paper • Can be records, pages, sites, images, people, movies • Document encoding (Unicode) • Document representation • Document preprocessing
Documents • Not just printed paper • Can be records, pages, sites, images, people, movies • Document encoding (Unicode) • Document representation • Document preprocessing
 • toley spies grames tolley spies games totally spies") Sample query sessions (from AOL) • toley spies grames tolley spies games totally spies games • tajmahal restaurant brooklyn ny taj mahal restaurant brooklyn ny 11209 • do you love me like you say lyrics marvin gaye M: /data 4/corpora/AOL-user-ct-collection
Sample query sessions (from AOL) • toley spies grames tolley spies games totally spies games • tajmahal restaurant brooklyn ny taj mahal restaurant brooklyn ny 11209 • do you love me like you say lyrics marvin gaye M: /data 4/corpora/AOL-user-ct-collection
 Characteristics of user queries • • Sessions: users revisit their queries. Very short queries: typically 2 words long. A large number of typos. A small number of popular queries. A long tail of infrequent ones. • Almost no use of advanced query operators with the exception of double quotes
Characteristics of user queries • • Sessions: users revisit their queries. Very short queries: typically 2 words long. A large number of typos. A small number of popular queries. A long tail of infrequent ones. • Almost no use of advanced query operators with the exception of double quotes
 Queries as documents • Advantages: – Mathematically easier to manage • Problems: – Different lengths – Syntactic differences – Repetitions of words (or lack thereof)
Queries as documents • Advantages: – Mathematically easier to manage • Problems: – Different lengths – Syntactic differences – Repetitions of words (or lack thereof)
 • Document-document matrix (n x n)") Document representations • Term-document matrix (m x n) • Document-document matrix (n x n) • Typical example in a medium-sized collection: 3, 000 documents (n) with 50, 000 terms (m) • Typical example on the Web: n=30, 000, m=1, 000 • Boolean vs. integer-valued matrices
Document representations • Term-document matrix (m x n) • Document-document matrix (n x n) • Typical example in a medium-sized collection: 3, 000 documents (n) with 50, 000 terms (m) • Typical example on the Web: n=30, 000, m=1, 000 • Boolean vs. integer-valued matrices
 Storage issues • Imagine a medium-sized collection with n=3, 000 and m=50, 000 • How large a term-document matrix will be needed? • Is there any way to do better? Any heuristic?
Storage issues • Imagine a medium-sized collection with n=3, 000 and m=50, 000 • How large a term-document matrix will be needed? • Is there any way to do better? Any heuristic?
 Inverted index • Instead of an incidence vector, use a posting table • CLEVELAND: D 1, D 2, D 6 • OHIO: D 1, D 5, D 6, D 7 • Use linked lists to be able to insert new document postings in order and to remove existing postings. • Keep everything sorted! This gives you a logarithmic improvement in access.
Inverted index • Instead of an incidence vector, use a posting table • CLEVELAND: D 1, D 2, D 6 • OHIO: D 1, D 5, D 6, D 7 • Use linked lists to be able to insert new document postings in order and to remove existing postings. • Keep everything sorted! This gives you a logarithmic improvement in access.
 – iterative merge of the two") Basic operations on inverted indexes • Conjunction (AND) – iterative merge of the two postings: O(x+y) • Disjunction (OR) – very similar • Negation (NOT) – can we still do it in O(x+y)? – Example: MICHIGAN AND NOT OHIO – Example: MICHIGAN OR NOT OHIO • Recursive operations • Optimization: start with the smallest sets
Basic operations on inverted indexes • Conjunction (AND) – iterative merge of the two postings: O(x+y) • Disjunction (OR) – very similar • Negation (NOT) – can we still do it in O(x+y)? – Example: MICHIGAN AND NOT OHIO – Example: MICHIGAN OR NOT OHIO • Recursive operations • Optimization: start with the smallest sets
 Major IR models • • • Boolean Vector Probabilistic Language modeling Fuzzy retrieval Latent semantic indexing
Major IR models • • • Boolean Vector Probabilistic Language modeling Fuzzy retrieval Latent semantic indexing
 The Boolean model Venn diagrams x D 1 w z y D 2
The Boolean model Venn diagrams x D 1 w z y D 2
 Boolean queries • Operators: AND, OR, NOT, parentheses • Example: – CLEVELAND NOT OHIO – (MICHIGAN AND INDIANA) OR (TEXAS AND OKLAHOMA) • Ambiguous uses of AND and OR in human language – Exclusive vs. inclusive OR – Restrictive operator: AND or OR?
Boolean queries • Operators: AND, OR, NOT, parentheses • Example: – CLEVELAND NOT OHIO – (MICHIGAN AND INDIANA) OR (TEXAS AND OKLAHOMA) • Ambiguous uses of AND and OR in human language – Exclusive vs. inclusive OR – Restrictive operator: AND or OR?
 = (NOT") Canonical forms of queries • De Morgan’s Laws: NOT (A AND B) = (NOT A) OR (NOT B) NOT (A OR B) = (NOT A) AND (NOT B) • Normal forms – Conjunctive normal form (CNF) – Disjunctive normal form (DNF) – Reference librarians prefer CNF - why?
Canonical forms of queries • De Morgan’s Laws: NOT (A AND B) = (NOT A) OR (NOT B) NOT (A OR B) = (NOT A) AND (NOT B) • Normal forms – Conjunctive normal form (CNF) – Disjunctive normal form (DNF) – Reference librarians prefer CNF - why?
 Evaluating Boolean queries • Incidence vectors: – CLEVELAND: 1100010 – OHIO: 1000111 • Examples: – CLEVELAND OHIO – CLEVELAND NOT OHIO – CLEVALAND OR OHIO
Evaluating Boolean queries • Incidence vectors: – CLEVELAND: 1100010 – OHIO: 1000111 • Examples: – CLEVELAND OHIO – CLEVELAND NOT OHIO – CLEVALAND OR OHIO
 Exercise • • D 1 = “computer information retrieval” D 2 = “computer retrieval” D 3 = “information” D 4 = “computer information” • Q 1 = “information AND retrieval” • Q 2 = “information AND NOT computer”
Exercise • • D 1 = “computer information retrieval” D 2 = “computer retrieval” D 3 = “information” D 4 = “computer information” • Q 1 = “information AND retrieval” • Q 2 = “information AND NOT computer”
 Exercise 0 1 Swift 2 Shakespeare 3 Shakespeare 4 Milton 5 Milton 6 Milton Shakespeare 7 Milton Shakespeare Swift 8 Chaucer 9 Chaucer 10 Chaucer Shakespeare 11 Chaucer Shakespeare 12 Chaucer Milton 13 Chaucer Milton 14 Chaucer Milton Shakespeare 15 Chaucer Milton Shakespeare Swift Swift ((chaucer OR milton) AND (NOT swift)) OR ((NOT chaucer) AND (swift OR shakespeare))
Exercise 0 1 Swift 2 Shakespeare 3 Shakespeare 4 Milton 5 Milton 6 Milton Shakespeare 7 Milton Shakespeare Swift 8 Chaucer 9 Chaucer 10 Chaucer Shakespeare 11 Chaucer Shakespeare 12 Chaucer Milton 13 Chaucer Milton 14 Chaucer Milton Shakespeare 15 Chaucer Milton Shakespeare Swift Swift ((chaucer OR milton) AND (NOT swift)) OR ((NOT chaucer) AND (swift OR shakespeare))
 How to deal with? • Multi-word phrases? • Document ranking?
How to deal with? • Multi-word phrases? • Document ranking?
 The Vector model Term 1 Doc 2 Term 3 Term 2 Doc 3
The Vector model Term 1 Doc 2 Term 3 Term 2 Doc 3
 Vector queries • Each document is represented as a vector • Non-efficient representation • Dimensional compatibility
Vector queries • Each document is represented as a vector • Non-efficient representation • Dimensional compatibility
 The matching process • Document space • Matching is done between a document and a query (or between two documents) • Distance vs. similarity measures. • Euclidean distance, Manhattan distance, Word overlap, Jaccard coefficient, etc.
The matching process • Document space • Matching is done between a document and a query (or between two documents) • Distance vs. similarity measures. • Euclidean distance, Manhattan distance, Word overlap, Jaccard coefficient, etc.
 (D, Q) = |X") Miscellaneous similarity measures • The Cosine measure (normalized dot product) (D, Q) = |X Y| = |X| * |Y| • The Jaccard coefficient |X Y| (D, Q) = |X Y| (di x qi) (di)2 * (qi)2
Miscellaneous similarity measures • The Cosine measure (normalized dot product) (D, Q) = |X Y| = |X| * |Y| • The Jaccard coefficient |X Y| (D, Q) = |X Y| (di x qi) (di)2 * (qi)2
 and (D 1, D") Exercise • Compute the cosine scores (D 1, D 2) and (D 1, D 3) for the documents: D 1 = <1, 3>, D 2 = <100, 300> and D 3 = <3, 1> • Compute the corresponding Euclidean distances, Manhattan distances, and Jaccard coefficients.
Exercise • Compute the cosine scores (D 1, D 2) and (D 1, D 3) for the documents: D 1 = <1, 3>, D 2 = <100, 300> and D 3 = <3, 1> • Compute the corresponding Euclidean distances, Manhattan distances, and Jaccard coefficients.
: MRS 1, MRS 2, MRS 5 (Zipf) • (2): MRS 7,") Readings • (1): MRS 1, MRS 2, MRS 5 (Zipf) • (2): MRS 7, MRS 8
Readings • (1): MRS 1, MRS 2, MRS 5 (Zipf) • (2): MRS 7, MRS 8