

8-Информационный поиск.pptx
- Количество слайдов: 61
 Информационный поиск
Информационный поиск
 Информационный поиск • Информационный поиск – это отрасль знания, которая занимается представлением, хранением и доступом к информационным ресурсам. • Информационный ресурс – это любой материальный объект, который фиксирует какие-либо знания и может быть включен в определенное собрание.
Информационный поиск • Информационный поиск – это отрасль знания, которая занимается представлением, хранением и доступом к информационным ресурсам. • Информационный ресурс – это любой материальный объект, который фиксирует какие-либо знания и может быть включен в определенное собрание.
, • графические (чертежи,") Виды информационных ресурсов По форме различают: • текстовые (книги, журналы, рукописи), • графические (чертежи, схемы, графики, планы, карты, диаграммы), • аудиовизуальные (звукозаписи, видеозаписи, фильмы) информационные ресурсы
Виды информационных ресурсов По форме различают: • текстовые (книги, журналы, рукописи), • графические (чертежи, схемы, графики, планы, карты, диаграммы), • аудиовизуальные (звукозаписи, видеозаписи, фильмы) информационные ресурсы
 Документ в задаче ИП: • Содержательно законченный текстовый информационный ресурс • Уникальный идентификатор. • Метаданные – это структурированная информация о документе, например, библиографические сведения, информация о качестве документа, отзывы других пользователей. • Суррогаты - представление документа в виде заголовка, имени автора, аннотации, ключевых слов и т. д.
Документ в задаче ИП: • Содержательно законченный текстовый информационный ресурс • Уникальный идентификатор. • Метаданные – это структурированная информация о документе, например, библиографические сведения, информация о качестве документа, отзывы других пользователей. • Суррогаты - представление документа в виде заголовка, имени автора, аннотации, ключевых слов и т. д.
 Цель – удовлетворение информационной потребности • Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.
Цель – удовлетворение информационной потребности • Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.
 Поисковая потребность «То ли мне хочется музыки и цветов, то ли зарезать кого-нибудь. » ( «Обыкновенное чудо» ) • Необходимо представить свою информационную потребность в виде некоторого выражения, которое может быть воспринято поисковой системой.
Поисковая потребность «То ли мне хочется музыки и цветов, то ли зарезать кого-нибудь. » ( «Обыкновенное чудо» ) • Необходимо представить свою информационную потребность в виде некоторого выражения, которое может быть воспринято поисковой системой.
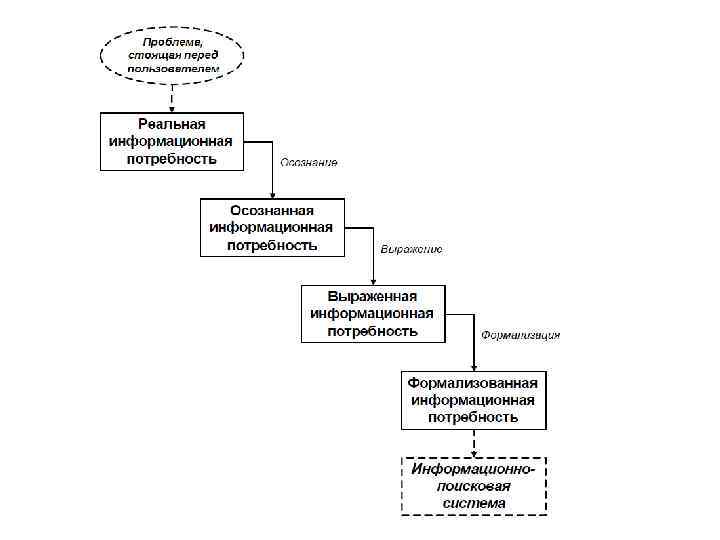
 Схема ИП
Схема ИП
 Этапы представления ИП: • реальная ИП –потребность в некоторой новой информации при решении стоящей перед пользователем задачи; • выраженная ИП – результат описания осознанной информационной потребности с помощью естественного языка; • формализованная ИП – это результат представления выраженной потребности средствами формального поискового языка ИПС.
Этапы представления ИП: • реальная ИП –потребность в некоторой новой информации при решении стоящей перед пользователем задачи; • выраженная ИП – результат описания осознанной информационной потребности с помощью естественного языка; • формализованная ИП – это результат представления выраженной потребности средствами формального поискового языка ИПС.
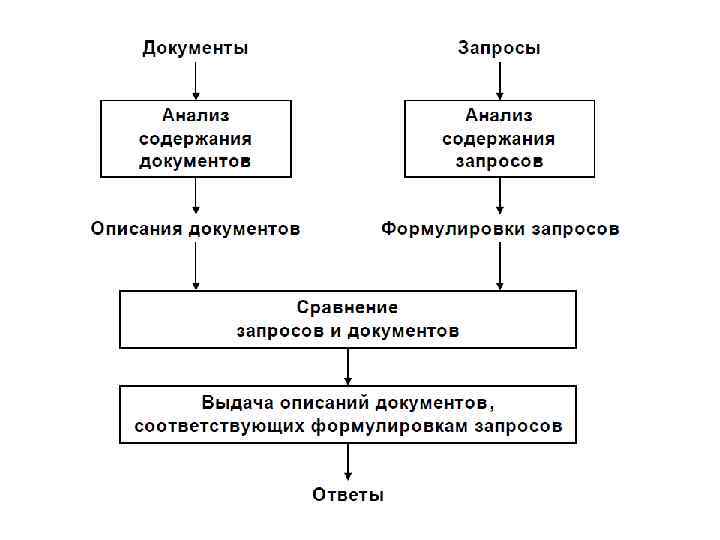
 Общая схема процесса поиска • Использование специальных тематических каталогов и реализуется в классификационных ИПС. Для поиска документа в этом случае используются его название, выходные данные, тематика и другие реквизиты. • Поисковые машины - словарные ИПС, использует для поиска словари, составленные из терминов, описывающих содержание индексированных документов, с которыми работают программные средства, называемые поисковыми машинами.
Общая схема процесса поиска • Использование специальных тематических каталогов и реализуется в классификационных ИПС. Для поиска документа в этом случае используются его название, выходные данные, тематика и другие реквизиты. • Поисковые машины - словарные ИПС, использует для поиска словари, составленные из терминов, описывающих содержание индексированных документов, с которыми работают программные средства, называемые поисковыми машинами.
 Первая поисковая машина • Первой поисковой системой для Всемирной паутины был «Wandex» 1993 • Мэтью Грэем (Matthew Gray) Массачусетский технологический институт
Первая поисковая машина • Первой поисковой системой для Всемирной паутины был «Wandex» 1993 • Мэтью Грэем (Matthew Gray) Массачусетский технологический институт
 «Путеводитель Джерри по Всемирной Паутине» • В январе 1994 года аспиранты Стэнфордского университета Дэвид Файло (англ. David Filo) и Джерри Янг (англ. Jerry Yang) создали веб-сайт, который стал первым каталогом. • 4 по посещаемости
«Путеводитель Джерри по Всемирной Паутине» • В январе 1994 года аспиранты Стэнфордского университета Дэвид Файло (англ. David Filo) и Джерри Янг (англ. Jerry Yang) создали веб-сайт, который стал первым каталогом. • 4 по посещаемости
 По данным Net Applications, в январе 2011 года использование поисковых систем распределялось следующим образом: • • • Google — 84, 65 %; Yahoo! — 6, 69 %; Baidu — 3, 39 %; Bing — 3, 29 %; Ask — 0, 56 %; AOL — 0, 42 %.
По данным Net Applications, в январе 2011 года использование поисковых систем распределялось следующим образом: • • • Google — 84, 65 %; Yahoo! — 6, 69 %; Baidu — 3, 39 %; Bing — 3, 29 %; Ask — 0, 56 %; AOL — 0, 42 %.
 информационной потребности и формулировка информационного") Поиск информации состоит из четырех этапов: • определение (уточнение) информационной потребности и формулировка информационного запроса; • определение совокупности возможных держателей информационных массивов (источников); • извлечение информации из выявленных информационных массивов; • ознакомление с полученной информацией и оценка результатов поиска.
Поиск информации состоит из четырех этапов: • определение (уточнение) информационной потребности и формулировка информационного запроса; • определение совокупности возможных держателей информационных массивов (источников); • извлечение информации из выявленных информационных массивов; • ознакомление с полученной информацией и оценка результатов поиска.
 Характеристики качества поиска - релевантность • ИП, сформулированная на информационнопоисковом языке, называется запросом. • Степень соответствия ответов поисковой системы запросу пользователя, а значит, и его информационной потребности, называется релевантностью.
Характеристики качества поиска - релевантность • ИП, сформулированная на информационнопоисковом языке, называется запросом. • Степень соответствия ответов поисковой системы запросу пользователя, а значит, и его информационной потребности, называется релевантностью.
 Виды релевантности • Пертинентность – степень соответствия информации из документа и реальной ИП пользователя. Это истинная и наиболее трудноопределимая релевантность. • Тематическая релевантность – степень близости тематики (область интересов пользователя) ИП и найденного документа. • Ситуационная релевантность – полезность информационного ресурса для задачи, решаемой пользователем, с точки зрения временных затрат, способа взаимодействия пользователя с системой и т. п. • Системная релевантность – характеризует степень близости между формализованной ИП (запросом) и найденным документом.
Виды релевантности • Пертинентность – степень соответствия информации из документа и реальной ИП пользователя. Это истинная и наиболее трудноопределимая релевантность. • Тематическая релевантность – степень близости тематики (область интересов пользователя) ИП и найденного документа. • Ситуационная релевантность – полезность информационного ресурса для задачи, решаемой пользователем, с точки зрения временных затрат, способа взаимодействия пользователя с системой и т. п. • Системная релевантность – характеризует степень близости между формализованной ИП (запросом) и найденным документом.
 Виды релевантности • Системная релевантность вычисляется без участия пользователя. • Один и тот же документ может быть релевантным согласно одному определению релевантности и нерелевантным согласно другому. • Документ, релевантный алгоритмически, может оказаться непертинентным. ( «мышь» , «ключ» )
Виды релевантности • Системная релевантность вычисляется без участия пользователя. • Один и тот же документ может быть релевантным согласно одному определению релевантности и нерелевантным согласно другому. • Документ, релевантный алгоритмически, может оказаться непертинентным. ( «мышь» , «ключ» )
 Характеристики качества поиска • Полнота: отношение количества найденных релевантных ко всем релевантным • Точность: Отношение количества найденных релевантных ко всем найденным
Характеристики качества поиска • Полнота: отношение количества найденных релевантных ко всем релевантным • Точность: Отношение количества найденных релевантных ко всем найденным
 Полнотекстовый индекс - инвертированные файлы • Первые версии программ полнотекстового поиска предполагали сканирование всего содержимого всех документов в поиске заданного слова или фразы. • Заранее сформированный для поиска так называемый полнотекстовый индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются.
Полнотекстовый индекс - инвертированные файлы • Первые версии программ полнотекстового поиска предполагали сканирование всего содержимого всех документов в поиске заданного слова или фразы. • Заранее сформированный для поиска так называемый полнотекстовый индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются.
 • Пьесы Шекспира: в каких встречаются слова") Sec. 1. 1 Неструктурированные данные (1680 г) • Пьесы Шекспира: в каких встречаются слова Brutus AND Caesar but NOT Calpurnia? • Решение: просмотреть все пьесы, найти все, где встречаются слова Brutus и Caesar, затем убрать из списка те, в которых есть слово Calpurnia • Почему плохо? – Медленно (для больших наборов данных) – NOT Calpurnia нетривиальный поиск – Другие операции (напр. , найти Romans near countrymen) невозможны – Ранжировать поиск (найти наилучший результат) 21
Sec. 1. 1 Неструктурированные данные (1680 г) • Пьесы Шекспира: в каких встречаются слова Brutus AND Caesar but NOT Calpurnia? • Решение: просмотреть все пьесы, найти все, где встречаются слова Brutus и Caesar, затем убрать из списка те, в которых есть слово Calpurnia • Почему плохо? – Медленно (для больших наборов данных) – NOT Calpurnia нетривиальный поиск – Другие операции (напр. , найти Romans near countrymen) невозможны – Ранжировать поиск (найти наилучший результат) 21
 Матрица инцидентности термин - документ Brutus AND Caesar BUT NOT Calpurnia Sec. 1. 1 1 если пьеса содержит слово, 0 в другом случае
Матрица инцидентности термин - документ Brutus AND Caesar BUT NOT Calpurnia Sec. 1. 1 1 если пьеса содержит слово, 0 в другом случае
 Sec. 1. 1 Вектор инцидентности • Итак, у нас есть вектор 0/1 для каждого терма. • Ответ на запрос: найти вектор для Brutus, Caesar and Calpurnia (инвертированный) побитовое AND. • 110100 AND 110111 AND 101111 = 100100. 23
Sec. 1. 1 Вектор инцидентности • Итак, у нас есть вектор 0/1 для каждого терма. • Ответ на запрос: найти вектор для Brutus, Caesar and Calpurnia (инвертированный) побитовое AND. • 110100 AND 110111 AND 101111 = 100100. 23
 Sec. 1. 1 Ответ на запрос • Antony and Cleopatra, Act III, Scene ii Agrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus, When Antony found Julius Caesar dead, He cried almost to roaring; and he wept When at Philippi he found Brutus slain. • Hamlet, Act III, Scene ii Lord Polonius: I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. 24
Sec. 1. 1 Ответ на запрос • Antony and Cleopatra, Act III, Scene ii Agrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus, When Antony found Julius Caesar dead, He cried almost to roaring; and he wept When at Philippi he found Brutus slain. • Hamlet, Act III, Scene ii Lord Polonius: I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. 24
 Sec. 1. 1 Базовые положения информационного поиска • Коллекции: заданный набор документов • Цель: Найти документы, содержащие информацию, релевантную запрашиваемой пользователем, и помочь пользователю выполнить задачу. 25
Sec. 1. 1 Базовые положения информационного поиска • Коллекции: заданный набор документов • Цель: Найти документы, содержащие информацию, релевантную запрашиваемой пользователем, и помочь пользователю выполнить задачу. 25
 Sec. 1. 1 Большие коллекции • Рассмотрим N = 1 миллион документов, в каждом около 1000 слов. • Примерно 6 bytes/слово, включая пробелы и пунктуацию – 6 GB данных в документах. • Пусть M = 500 K различных термов в текстах. 26
Sec. 1. 1 Большие коллекции • Рассмотрим N = 1 миллион документов, в каждом около 1000 слов. • Примерно 6 bytes/слово, включая пробелы и пунктуацию – 6 GB данных в документах. • Пусть M = 500 K различных термов в текстах. 26
 Sec. 1. 1 Невозможно построить матрицу • 500 K x 1 M – в матрице будет полтриллиона 0 -й and 1 -ц. Почему? • Но не более миллиарда 1 -ц. – Матрица, в основном, нулевая. • Какое представление будет лучше? – Записывать только 1 -цы. 27
Sec. 1. 1 Невозможно построить матрицу • 500 K x 1 M – в матрице будет полтриллиона 0 -й and 1 -ц. Почему? • Но не более миллиарда 1 -ц. – Матрица, в основном, нулевая. • Какое представление будет лучше? – Записывать только 1 -цы. 27
 Sec. 1. 2 Инвертированный индекс • Для каждого терма t мы храним список документов, которые содержат слово t. – Идентифицируем каждый документ с помощью doc. ID, например, последовательный номер • Можно ли использовать массивы заданной длины? Brutus 1 Caesar 1 Calpurnia 2 2 2 31 4 11 31 45 173 4 5 6 16 174 57 132 54 101 Что произойдет, если слово Caesar будет добавлено в документ 14? 28
Sec. 1. 2 Инвертированный индекс • Для каждого терма t мы храним список документов, которые содержат слово t. – Идентифицируем каждый документ с помощью doc. ID, например, последовательный номер • Можно ли использовать массивы заданной длины? Brutus 1 Caesar 1 Calpurnia 2 2 2 31 4 11 31 45 173 4 5 6 16 174 57 132 54 101 Что произойдет, если слово Caesar будет добавлено в документ 14? 28
 Sec. 1. 2 Инвертированный индекс • Нам нужны списки записей переменной длины – На диске используется однонаправленные списки словопозиций (Doc. ID + координата термина) – В памяти можно использовать списки или массивы переменной длины Запись • Некоторые компромиссы в размере / легкость вставки Brutus 1 Caesar 1 Calpurnia 2 2 2 31 4 11 31 45 173 4 5 6 16 174 57 132 54 101 Записи Словарь Отсортированы по doc. ID 29
Sec. 1. 2 Инвертированный индекс • Нам нужны списки записей переменной длины – На диске используется однонаправленные списки словопозиций (Doc. ID + координата термина) – В памяти можно использовать списки или массивы переменной длины Запись • Некоторые компромиссы в размере / легкость вставки Brutus 1 Caesar 1 Calpurnia 2 2 2 31 4 11 31 45 173 4 5 6 16 174 57 132 54 101 Записи Словарь Отсортированы по doc. ID 29
 Sec. 1. 2 Построение индекса: сортировка • Сортировка по термам – И затем по doc. ID Суть построения индекса
Sec. 1. 2 Построение индекса: сортировка • Сортировка по термам – И затем по doc. ID Суть построения индекса
 Sec. 1. 3 Построенный индекс • Как мы обрабатываем запрос? • Какие виды запросов мы можем обработать? 35
Sec. 1. 3 Построенный индекс • Как мы обрабатываем запрос? • Какие виды запросов мы можем обработать? 35
 Sec. 1. 3 Булев поиск: точное совпадение • Метод Булева поиска может дать ответ на запрос, который является булевским выражением: – Запросы с использованием AND, OR и NOT для соединения термов запроса • Рассматриваем каждый документ как множество слов • Результат: документ удовлетворяет запросу или нет. – Самая простая модель для создания ИП-системы • Первичный инструмент поиска в течение последних 30 лет. • Множество поисковых систем до сих пор используют Булев поиск: – Email, library catalog, Mac OS X Spotlight 38
Sec. 1. 3 Булев поиск: точное совпадение • Метод Булева поиска может дать ответ на запрос, который является булевским выражением: – Запросы с использованием AND, OR и NOT для соединения термов запроса • Рассматриваем каждый документ как множество слов • Результат: документ удовлетворяет запросу или нет. – Самая простая модель для создания ИП-системы • Первичный инструмент поиска в течение последних 30 лет. • Множество поисковых систем до сих пор используют Булев поиск: – Email, library catalog, Mac OS X Spotlight 38
 Ранжирование результатов поиска • Булевские запросы говорят о соответствии/несоответствии документов. • Часто мы хотим ранжировать/группировать результаты – Нам нужна мера схожести между запросом и каждым документом. – Необходимо решить, как представлять пользователю документы: по одному или группами 41
Ранжирование результатов поиска • Булевские запросы говорят о соответствии/несоответствии документов. • Часто мы хотим ранжировать/группировать результаты – Нам нужна мера схожести между запросом и каждым документом. – Необходимо решить, как представлять пользователю документы: по одному или группами 41
 Кластеризация, классификация и ранжирование • Кластеризация: группировка документов на основании их содержимого. • Классификация: выбор разделов – при появлении нового документа определяем подходящий раздел. • Ранжирование: выбрать наилучший порядок в наборе документов 42
Кластеризация, классификация и ранжирование • Кластеризация: группировка документов на основании их содержимого. • Классификация: выбор разделов – при появлении нового документа определяем подходящий раздел. • Ранжирование: выбрать наилучший порядок в наборе документов 42
 В компьютерной лингвистике эмпирический закон Г. С. Хипса (H. S.") Закон Хипса (Heaps’ law) В компьютерной лингвистике эмпирический закон Г. С. Хипса (H. S. Heaps) связывает объем документа с объемом словаря уникальных слов, которые входят в этот документ. Казалось бы, словарь уникальных слов должен насыщаться, а его объем стабилизироваться при увеличении объемов текста. Оказывается, это не так! Для всех известных сегодня текстов в соответствии с законом Хипса, эти значения связаны соотношением: M(T)= T , где M - это объем словаря уникальных слов, составленный из текста, который состоит из T лексем, и – определенные эмпирически параметры. Для европейских языков принимает значение от 10 до 100, а - от 0. 4 до 0. 6.
Закон Хипса (Heaps’ law) В компьютерной лингвистике эмпирический закон Г. С. Хипса (H. S. Heaps) связывает объем документа с объемом словаря уникальных слов, которые входят в этот документ. Казалось бы, словарь уникальных слов должен насыщаться, а его объем стабилизироваться при увеличении объемов текста. Оказывается, это не так! Для всех известных сегодня текстов в соответствии с законом Хипса, эти значения связаны соотношением: M(T)= T , где M - это объем словаря уникальных слов, составленный из текста, который состоит из T лексем, и – определенные эмпирически параметры. Для европейских языков принимает значение от 10 до 100, а - от 0. 4 до 0. 6.
 Reuters-RCV 1 Пунктирная линия построена по методу наименьших квадратов log") Закон Хипса (Heaps’ law) Reuters-RCV 1 Пунктирная линия построена по методу наименьших квадратов log 10 M = 0. 49 ∗ log 10 T + 1. 64 Получаем: M = 101. 64 T 0. 49 k = 101. 64 ≈ 44 b = 0. 49.
Закон Хипса (Heaps’ law) Reuters-RCV 1 Пунктирная линия построена по методу наименьших квадратов log 10 M = 0. 49 ∗ log 10 T + 1. 64 Получаем: M = 101. 64 T 0. 49 k = 101. 64 ≈ 44 b = 0. 49.
 Ранжированный поиск § До сих пор наши запросы были булевского типа. § Документ подходит или не подходит. § Хорошо для опытных пользователей, с точным пониманием, что и где они ищут. § Также удобно для приложений: приложения могут легко найти тысячи результатов. § Плохо для большинства пользователей § Большинство пользователей не могут написать булевы запросы. . . §. . . или они могут, но думают, что это слишком сложно. § Большинство пользователей не хотят получить тысячи результатов. 45
Ранжированный поиск § До сих пор наши запросы были булевского типа. § Документ подходит или не подходит. § Хорошо для опытных пользователей, с точным пониманием, что и где они ищут. § Также удобно для приложений: приложения могут легко найти тысячи результатов. § Плохо для большинства пользователей § Большинство пользователей не могут написать булевы запросы. . . §. . . или они могут, но думают, что это слишком сложно. § Большинство пользователей не хотят получить тысячи результатов. 45
 Запрос-документ оценка соответствия § Как оценить соответствие запроса и документа? § Начнем с запроса из одного термина. § Если документ не встречается в документе: результат должен быть 0. § Чем чаще термин запроса встречается в документе, тем выше должно быть соответствие. § У такого подхода есть альтернативы. 46 46
Запрос-документ оценка соответствия § Как оценить соответствие запроса и документа? § Начнем с запроса из одного термина. § Если документ не встречается в документе: результат должен быть 0. § Чем чаще термин запроса встречается в документе, тем выше должно быть соответствие. § У такого подхода есть альтернативы. 46 46
 Бинарная матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 1 1 1 0 1 1 1 1 0 0 0 0 1 1 Othello 0 1 1 0 0 1 1 Macbeth . . . 0 0 1 1 1 0 0 1 0 Каждый документ представлен бинарным вектором ∈ {0, 1}|V|. 47 47
Бинарная матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 1 1 1 0 1 1 1 1 0 0 0 0 1 1 Othello 0 1 1 0 0 1 1 Macbeth . . . 0 0 1 1 1 0 0 1 0 Каждый документ представлен бинарным вектором ∈ {0, 1}|V|. 47 47
 Матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 157 4 232 0 57 2 2 73 157 227 10 0 0 0 0 3 1 Othello 0 2 2 0 0 8 1 Macbeth . . . 0 0 1 0 0 5 1 1 0 0 8 5 Теперь каждый документ представлен числовым вектором ∈ N|V|. 48 48
Матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 157 4 232 0 57 2 2 73 157 227 10 0 0 0 0 3 1 Othello 0 2 2 0 0 8 1 Macbeth . . . 0 0 1 0 0 5 1 1 0 0 8 5 Теперь каждый документ представлен числовым вектором ∈ N|V|. 48 48
 «Мешок слов» § Мы не рассматриваем порядок слов в документе. § John is quicker than Mary is quicker than John представлены одинаково. § Эта модель называется мешком слов. § В некотором смысле, это шаг назад – позиционный индекс мог различать эти два документа. 49 49
«Мешок слов» § Мы не рассматриваем порядок слов в документе. § John is quicker than Mary is quicker than John представлены одинаково. § Эта модель называется мешком слов. § В некотором смысле, это шаг назад – позиционный индекс мог различать эти два документа. 49 49
 Частота терминов tf § Частотой терминов tft, d термина t в документе d называют количество появлений термина t в d. § Мы хотим использовать tf при вычислении схожести между запросом и документом. § Простая частота терминов не совсем то, что нам нужно: § Документ с tf = 10 появления термина более релевантный, чем документ с tf = 1 появления термина. § Но не в 10 раз релевантнее. § Релевантность возрастает не пропорционально частоте появления термина. 50 50
Частота терминов tf § Частотой терминов tft, d термина t в документе d называют количество появлений термина t в d. § Мы хотим использовать tf при вычислении схожести между запросом и документом. § Простая частота терминов не совсем то, что нам нужно: § Документ с tf = 10 появления термина более релевантный, чем документ с tf = 1 появления термина. § Но не в 10 раз релевантнее. § Релевантность возрастает не пропорционально частоте появления термина. 50 50
 Частотное взвешивание § Частотное взвешивание термина t в d определяется так § tft, d → wt, d : 0 → 0, 1 → 1, 2 → 1. 3, 10 → 2, 1000 → 4, etc. § Оценка для пары запрос-документ: сумма по всем терминам t для запроса q и d: tf -оценка(q, d) = t∈q∩d (1 + log tft, d ) § Оценка будет 0, если ни один из терминов запроса не встречается в документе. 51 51
Частотное взвешивание § Частотное взвешивание термина t в d определяется так § tft, d → wt, d : 0 → 0, 1 → 1, 2 → 1. 3, 10 → 2, 1000 → 4, etc. § Оценка для пары запрос-документ: сумма по всем терминам t для запроса q и d: tf -оценка(q, d) = t∈q∩d (1 + log tft, d ) § Оценка будет 0, если ни один из терминов запроса не встречается в документе. 51 51
 Частота в документе или частота в коллекции § Кроме частоты термина в документе. . . §. . . хотелось бы учитывать общую частоту термина в коллекции для взвешивания и ранжирования. 52 52
Частота в документе или частота в коллекции § Кроме частоты термина в документе. . . §. . . хотелось бы учитывать общую частоту термина в коллекции для взвешивания и ранжирования. 52 52
 Желаемый вес редких слов § Редкие термины более информативны, чем часто встречаемые. § Рассматривает термины запросы, которые редко встречаются в коллекции ( «эгоцентризм» – «существовать» ). § Документ, содержащий этот термин, скорее всего будет релевантным. § → Надо увеличить вес редких терминов. 53 53
Желаемый вес редких слов § Редкие термины более информативны, чем часто встречаемые. § Рассматривает термины запросы, которые редко встречаются в коллекции ( «эгоцентризм» – «существовать» ). § Документ, содержащий этот термин, скорее всего будет релевантным. § → Надо увеличить вес редких терминов. 53 53
 Желаемый вес частых слов § Частые термины менее информативны, чем редкие. § Рассмотрим термин в запрос, который часто встречается в коллекции (e. g. , хороший, увеличивать и кривая). § Документ, содержащий эти термины, более релевантен, чем документ, в котором этих терминов нет. . . §. . . но такие слова, как хороший, увеличивать и кривая не похожи на индикаторы релевантности. § → Для частых терминов мы хотим иметь положительный вес. . . §. . . но меньший, чем у редких терминов. 54 54
Желаемый вес частых слов § Частые термины менее информативны, чем редкие. § Рассмотрим термин в запрос, который часто встречается в коллекции (e. g. , хороший, увеличивать и кривая). § Документ, содержащий эти термины, более релевантен, чем документ, в котором этих терминов нет. . . §. . . но такие слова, как хороший, увеличивать и кривая не похожи на индикаторы релевантности. § → Для частых терминов мы хотим иметь положительный вес. . . §. . . но меньший, чем у редких терминов. 54 54
 Документная частота § Нужен большой вес для редких слов как эмансипация, дирижабль. § Нужен небольшой вес для частых слов как хороший, увеличивать и кривая. § Будем использовать документную частоту для вычисления соответствия. § Документная частота - это количество документов коллекции, в которых встречается термин. 55 55
Документная частота § Нужен большой вес для редких слов как эмансипация, дирижабль. § Нужен небольшой вес для частых слов как хороший, увеличивать и кривая. § Будем использовать документную частоту для вычисления соответствия. § Документная частота - это количество документов коллекции, в которых встречается термин. 55 55
 idf вес § dft - документная частота - это количество документов коллекции, в которых встречается термин t. § dft является обратной мерой информативности термина t. § Определим idf вес термина следующим образом: (N – количество документов в коллекции. ) § idft является мерой информативности термина. § [log N/dft ] вместо [N/dft ] чтобы «ослабить» idf § Можно использовать log и для частоты термина, и для документальной частоты. 56 56
idf вес § dft - документная частота - это количество документов коллекции, в которых встречается термин t. § dft является обратной мерой информативности термина t. § Определим idf вес термина следующим образом: (N – количество документов в коллекции. ) § idft является мерой информативности термина. § [log N/dft ] вместо [N/dft ] чтобы «ослабить» idf § Можно использовать log и для частоты термина, и для документальной частоты. 56 56
 Пример idf § Вычисляем idft по формуле: term calpurnia animal sunday fly under the dft 1 1000 10, 000 100, 000 1, 000 idft 6 4 3 2 1 0 57 57
Пример idf § Вычисляем idft по формуле: term calpurnia animal sunday fly under the dft 1 1000 10, 000 100, 000 1, 000 idft 6 4 3 2 1 0 57 57
 Эффект от idf для ранжирования §idf влияет на ранжирование документов для запросов, состоящих по крайней мере из двух терминов. §Например, для запроса “лента Мёбиуса”, idf увеличит соответствующий вес МЁБИУС и уменьшит соответствующий вес ЛЕНТА. §idf слабо влияет на ранжирование запросов из 1 термина. 58 58
Эффект от idf для ранжирования §idf влияет на ранжирование документов для запросов, состоящих по крайней мере из двух терминов. §Например, для запроса “лента Мёбиуса”, idf увеличит соответствующий вес МЁБИУС и уменьшит соответствующий вес ЛЕНТА. §idf слабо влияет на ранжирование запросов из 1 термина. 58 58
 Частота в коллекции vs. Документная частота слово INSURANCE TRY Частота в коллекции Документная частота 10440 10422 3997 8760 §Частота в коллекции термина t: количество включений термина t в коллекции §Документная частота термина t: количество документов, в которых встречается термин t §Что лучше для поиска терминов (и даст больший вес)? §Этот пример показывает, что df (и idf) лучше для взвешивания, чем cf (и “icf”). 59 59
Частота в коллекции vs. Документная частота слово INSURANCE TRY Частота в коллекции Документная частота 10440 10422 3997 8760 §Частота в коллекции термина t: количество включений термина t в коллекции §Документная частота термина t: количество документов, в которых встречается термин t §Что лучше для поиска терминов (и даст больший вес)? §Этот пример показывает, что df (и idf) лучше для взвешивания, чем cf (и “icf”). 59 59
 tf-idf взвешивание §tf-idf вес термина определяется его tf-весом и его idf- весом. §tf-вес §idf-вес §“-” в tf-idf не минус, а дефис! §tf. idf, tf x idf 60 60
tf-idf взвешивание §tf-idf вес термина определяется его tf-весом и его idf- весом. §tf-вес §idf-вес §“-” в tf-idf не минус, а дефис! §tf. idf, tf x idf 60 60
 Итог: tf-idf §Определим tf-idf вес для каждого термина t в каждом документе document d: §tf-idf вес. . . §. . . возрастает с ростом количества появлений термина в документе. (частота термина) §. . . возрастает с уменьшением количества появлений термина в коллекции. (обратная документная частота) 61 61
Итог: tf-idf §Определим tf-idf вес для каждого термина t в каждом документе document d: §tf-idf вес. . . §. . . возрастает с ростом количества появлений термина в документе. (частота термина) §. . . возрастает с уменьшением количества появлений термина в коллекции. (обратная документная частота) 61 61
 tft, d") Термины, документы, коллекции и частота Quantity Symbol Definition term frequency (частота термина) tft, d Количество появлений термина t в d document frequency dft Количество документов в коллекции, в которых есть t cft Общее количество появлений термина t в коллекции (документная частота) collection frequency (частота в коллекции) §Отношение между df и cf? §Отношение между tf и df? 62 62
Термины, документы, коллекции и частота Quantity Symbol Definition term frequency (частота термина) tft, d Количество появлений термина t в d document frequency dft Количество документов в коллекции, в которых есть t cft Общее количество появлений термина t в коллекции (документная частота) collection frequency (частота в коллекции) §Отношение между df и cf? §Отношение между tf и df? 62 62
 Бинарная матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 1 1 1 0 1 1 1 1 0 0 0 0 1 1 Othello 0 1 1 0 0 1 1 Macbeth . . . 0 0 1 1 1 0 0 1 0 Каждый документ представлен двоичным вектором ∈ {0, 1}|V|. 63 63
Бинарная матрица инциденции Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 1 1 1 0 1 1 1 1 0 0 0 0 1 1 Othello 0 1 1 0 0 1 1 Macbeth . . . 0 0 1 1 1 0 0 1 0 Каждый документ представлен двоичным вектором ∈ {0, 1}|V|. 63 63
 Числовая матрица Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 157 4 232 0 57 2 2 73 157 227 10 0 0 0 0 3 1 Othello 0 2 2 0 0 8 1 Macbeth . . . 0 0 1 0 0 5 1 1 0 0 8 5 Каждый документ представлен числовым вектором ∈ N|V|. 64 64
Числовая матрица Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 157 4 232 0 57 2 2 73 157 227 10 0 0 0 0 3 1 Othello 0 2 2 0 0 8 1 Macbeth . . . 0 0 1 0 0 5 1 1 0 0 8 5 Каждый документ представлен числовым вектором ∈ N|V|. 64 64
 Бинарная → числовая → взвешенная матрица Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 5. 25 1. 21 8. 59 0. 0 2. 85 1. 51 1. 37 3. 18 6. 10 2. 54 1. 54 0. 0 0. 0 1. 90 0. 11 0. 0 1. 51 0. 0 0. 12 4. 15 Othello Macbeth . . . 0. 0 0. 25 0. 0 5. 25 0. 35 0. 0 0. 88 1. 95 Каждый документ представлен вектором вещественных чисел из tf-idf весов ∈ R|V|. 65 65
Бинарная → числовая → взвешенная матрица Anthony Julius The Hamlet and Caesar Tempest Cleopatra ANTHONY BRUTUS CAESAR CALPURNIA CLEOPATRA MERCY WORSER. . . 5. 25 1. 21 8. 59 0. 0 2. 85 1. 51 1. 37 3. 18 6. 10 2. 54 1. 54 0. 0 0. 0 1. 90 0. 11 0. 0 1. 51 0. 0 0. 12 4. 15 Othello Macbeth . . . 0. 0 0. 25 0. 0 5. 25 0. 35 0. 0 0. 88 1. 95 Каждый документ представлен вектором вещественных чисел из tf-idf весов ∈ R|V|. 65 65
 Документы как векторы §Каждый документ теперь представляется как вектор вещественных чисел, соответствующих tf-idf весу ∈ R|V|. §Итак у нас есть |V|-размерное векторное пространство. §Термины являются осями пространства §Документы являются точками или векторами в этом пространстве. §Очень большая размерность: десятки миллионов, если применять это к webпоисковым механизмам. §Каждый вектор сильно разрежен – большинство компонент равны нулю. 66
Документы как векторы §Каждый документ теперь представляется как вектор вещественных чисел, соответствующих tf-idf весу ∈ R|V|. §Итак у нас есть |V|-размерное векторное пространство. §Термины являются осями пространства §Документы являются точками или векторами в этом пространстве. §Очень большая размерность: десятки миллионов, если применять это к webпоисковым механизмам. §Каждый вектор сильно разрежен – большинство компонент равны нулю. 66
 Вероятностное латентносемантическое индексирование • Вероятностная модель основана на точной оценке вероятности того, что данный документ является релевантным (точнее, пертинентным) данному запросу • Анализирует не сами слова, а словосочетания.
Вероятностное латентносемантическое индексирование • Вероятностная модель основана на точной оценке вероятности того, что данный документ является релевантным (точнее, пертинентным) данному запросу • Анализирует не сами слова, а словосочетания.
 Page Rank • Вес страницы определяется как взвешенная сумма весов страниц, с которых есть ссылки на исходную • Сильно связная компонента • Злоупотребления: случайные и злонамеренные
Page Rank • Вес страницы определяется как взвешенная сумма весов страниц, с которых есть ссылки на исходную • Сильно связная компонента • Злоупотребления: случайные и злонамеренные
 Персонализация • • Учет географии Учет предыдущих запросов Группы пользователей Учет типа запроса (персональные страницы, магазины)
Персонализация • • Учет географии Учет предыдущих запросов Группы пользователей Учет типа запроса (персональные страницы, магазины)