Обзор языка SQL.ppt
- Количество слайдов: 89



Информационное обеспечение Обзор языка SQL Буханов С. А. bukhanov@yandex. ru
 представляет собой")
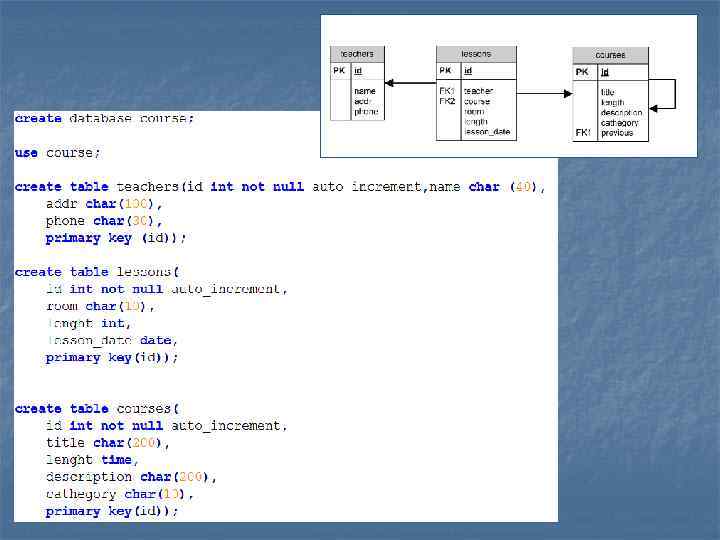
Язык SQL n n Язык SQL (Structured Query Language структурированный язык запросов) представляет собой стандартный высокоуровневый язык описания данных и манипулирования ими в системах управления базами данных (СУБД), построенных на основе реляционной модели данных. Язык SQL был разработан фирмой IBM в конце 70 -х годов. Первый международный стандарт языка был принят международной стандартизирующей организацией ISO в 1989 г. , а новый (более полный) - в 1992 г. В настоящее время все производители реляционных СУБД поддерживают с различной степенью соответствия стандарт SQL 92.

Операции n n n Основными операциями над таблицами являются следующие. Проекция - построение новой таблицы из исходной путем включения в нее избранных столбцов исходной таблицы. Ограничение - построение новой таблицы из исходной путем включения в нее тех строк исходной таблицы, которые отвечают некоторому критерию в виде логического условия (ограничения). Объединение - построение новой таблицы из 2 -ух или более исходных путем включения в нее всех строк исходных таблиц (при условии, конечно, что они подобны). Декартово произведение - построение новой таблицы из 2 -ух или более исходных путем включения в нее строк, образованных всеми возможными вариантами конкатенации (слияния) строк исходных таблиц. Количество строк новой таблицы определяется как произведение количеств строк всех исходных таблиц.

Операторы языка n n Программа на языке SQL представляет собой простую линейную последовательность операторов языка SQL. Операторы языка SQL строятся с применением: n n зарезервированных ключевых слов; идентификаторов (имен) таблиц и столбцов таблиц; логических, арифметических и строковых выражений, используемых для формирования критериев поиска информации в БД и для вычисления значений ячеек результирующих таблиц; идентификаторов (имен) операций и функций, используемых в выражениях.
 и")
Операторы языка n n В языке SQL не делается различия между прописными (большими) и строчными (маленькими) буквами, т. е. , например, строки "SELECT", "Select", "select" представляют собой одно и то же ключевое слово. Для конструирования имен таблиц и их столбцов допустимо использовать буквы, цифры и знак "_" (подчеркивание), но первым символом имени обязательно должна быть буква.

Операторы языка n n Запрещено использование ключевых слов и имен функций в качестве идентификаторов таблиц и имен столбцов. Полный список ключевых слов и имен функций (а он весьма обширен) можно найти в документации на конкретную СУБД. Оператор начинается с ключевого слова-глагола (например, "CREATE" - создать, "UPDATE" - обновить, "SELECT" - выбрать и т. п. ) и заканчивается знаком "; " (точка с запятой). Оператор записывается в свободном формате и может занимать несколько строк. Допустимыми разделителями лексических единиц в операторе являются: n n n один или несколько пробелов, один или несколько символов табуляции, один или несколько символов "новая строка".

Операторы языка n Комментарии при использовании в различных СУБД в текстах "программ" на языке SQL могут помечаться следующими способами: от двойного минуса ("--") до конца строки; n от символа "#" до конца строки; n между последовательностями "/*" и "*/" (стиль комментариев языка СИ). n

Типы данных n n n Типы данных, используемые в языке SQL для хранения информации в столбцах таблиц БД, весьма разнообразны. Разные производители реляционных СУБД варьируют множество типов данных, регламентируемых стандартом, реализуя свои собственные версии и расширения. В качестве основных возьмем следующие типы данных: n INT[(len)] - целое число длиной 4 байта, представляемое при выводе максимально len цифрами; n SMALLINT[(len)] - целое число длиной 2 байта, представляемое при выводе максимально len цифрами; n FLOAT[(len, dec)] - действительное число, представляемое при выводе максимально len символами с dec цифрами после десятичной точки; n CHAR(size) - строка символов фиксированной длины размером size символов; n VARCHAR(size) - строка символов переменной длины максимальным размером до size символов; n BLOB (Binary Large OBject) - массив произвольных (двоичных) байтов (максимальный размер зависит от реализации, обычно это 65535 байт); этот тип данных может использоваться, например, для хранения изображений; n DATE - астрономическая дата; n TIME - астрономическое время.
 записываются как последовательности символов,")
Типы данных n n Символьные константы (типа CHAR и VARCHAR) записываются как последовательности символов, заключенные в одиночные апострофы, например `brass` (латунь). Десятичные константы (типа FLOAT) могут записываться в "научной" нотации как последовательности следующих компонент: n n n n знак числа; десятичное число с точкой; символ "е"; знак ("+" или "-") показателя степени; целое число, играющее роль показателя степени числа 10. Например, десятичное число -0, 123 может быть записано как -12. 3 е-2. Отличие типов данных CHAR и VARCHAR заключается в том, что для хранения в таблице строк символов типа CHAR используется точно size байт (хотя содержание хранимых строк может быть значительно короче), в то время как для строк типа VARCHAR незанятые символами строк ("пустые") байты в таблице не хранятся.

Состав языка SQL n n Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде. Поэтому, в язык SQL в качестве составных частей входят: n n язык манипулирования данными (Data Manipulation Language, DML) язык определения данных (Data Definition Language, DDL) язык управления данными (Data Control Language, DCL). Это не отдельные языки, а различные команды одного языка. Такое деление проведено только лишь с точки зрения различного функционального назначения этих команд.

Язык манипулирования данными n n Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд: SELECT (выбрать) INSERT (вставить) UPDATE (обновить) DELETE (удалить)

Язык определения данных n n Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются: CREATE DATABASE (создать базу данных) CREATE TABLE (создать таблицу) CREATE VIEW (создать виртуальную таблицу) CREATE INDEX (создать индекс) CREATE TRIGGER (создать триггер) CREATE PROCEDURE (создать сохраненную процедуру) ALTER DATABASE (модифицировать базу данных) ALTER TABLE (модифицировать таблицу) ALTER VIEW (модифицировать виртуальную таблицу) ALTER INDEX (модифицировать индекс) ALTER TRIGGER (модифицировать триггер) ALTER PROCEDURE (модифицировать сохраненную процедуру) DROP DATABASE (удалить базу данных) DROP TABLE (удалить таблицу) DROP VIEW (удалить виртуальную таблицу) DROP INDEX (удалить индекс) DROP TRIGGER (удалить триггер) DROP PROCEDURE (удалить сохраненную процедуру)

Язык управления данными n n n Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде. Более точно его можно назвать "язык управления доступом". Он состоит из двух основных команд: GRANT (дать права) REVOKE (забрать права)



Вывод информации о таблице

CREATE DATABASE - создание базы данных n n Для создания базы данных в My. SQL используется SQL запрос CREATE DATABASE. Формат запроса: CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] database_name [CHARACTER SET charset] [COLLATE collation] В запросе используются обязательные параметры: n n В запросе используются необязательные параметры: n n DATABASE - указывает на то что будет создана база данных. SCHEMA - синоним параметра DATABASE database_name - название создаваемой базы данных IF NOT EXISTS - указывает что создать базу данных следует только в том случае если её еще не существует. Если попытаться создать базу данных, которая уже существует, не указав параметр IF NOT EXISTS, то результатом выполнения запроса будет ошибка № 1007 (подробнее в разделе коды ошибок в My. SQL). CHARACTER SET charset - указывает какая кодировка (charset) будет использоваться в создаваемой базе данных. Значение допустимые для параметра charset зависят от версии My. SQL сервера. Если не указывать этот параметр база данных будет создана в кодировке используемой по умолчанию. COLLATE collation - указывает порядок сортировки (collation) для заданного типа CHARACTER SET. Значения допустимые для параметра collation зависят от выбранной кодировки (charset). Пример: n n CREATE DATABASE employee CHARACTER SET utf 8 COLLATE utf 8_general_ci Данный запрос создаст базу данных employee с кодировкой utf 8 и порядком сортировки utf 8_general_ci. Если база данных employee уже существует то результатом выполнения будет ошибка: Can't create database 'employee'; database exists.

DROP DATABASE - удаление базы данных n Для удаления базы данных в My. SQL используется SQL запрос DROP DATABASE. n Формат запроса: n DROP {DATABASE | SCHEMA} [IF EXISTS] database_name n В запросе используются обязательные параметры: n n n n DATABASE - указывает на то что будет удалена база данных. SCHEMA - синоним параметра DATABASE database_name - название удаляемой базы данных В запросе используются необязательные параметры: n IF NOT EXISTS - указывает что удаление базы данных следует производить только в том случае если база существует. Если попытаться удалить несуществующую базу данных без параметра IF NOT EXISTS, то результатом выполнения запроса будет ошибка (подробнее в разделе коды ошибок в My. SQL). Пример: DROP DATABASE employee; Данный запрос удалит базу данных employee. Если база данных employee не существует то результатом выполнения будет ошибка Can't drop database ' employee'; database doesn't exist.

CREATE TABLE - создание таблицы n Для создания таблицы в базе данных в My. SQL используется SQL запрос CREATE TABLE. n Формат запроса: n n CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name (create_definition) [table_options] [select_statement] В запросе используются обязательные параметры: n n n table_name - название создаваемой таблицы create_definition - описывает структуру таблицы (названия и типы полей, ключи, индексы и т. д. ) Формат строки с описанием полей таблицы: field_name type [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [PRIMARY KEY] [INDEX] [UNIQUE] [FULLTEXT] обязательные поля: n field_name - задает название поля n type - задает тип данных для поля (описание типов данных в My. SQL)

CREATE TABLE - создание таблицы n не обязательные поля: n NOT NULL | NULL - указывает на допустимость значения NULL для данного поля. n DEFAULT default_value - задает значение по умолчанию равное значению default_value для данного поля. n AUTO_INCREMENT - указывает что при каждом добавлении новой записи в таблицу значение для поля с типом AUTO_INCREMENT будет увеличиватся на единицу. Параметром AUTO_INCREMENT могут обладать только поля с целочисленным типом данных но не больше одного поля с параметром AUTO_INCREMENT на таблицу. n PRIMARY KEY - первичный ключ таблицы. Первичным ключом могут быть значения как одно поля, так и нескольких. Значения первичного ключа должны быть уникальны, это позволяет однозначно идентифицировать каждую запись в таблице. Поиск данных по первичному ключу происходит гораздо быстрее чем по другим полям. n INDEX - указывает на то что данное поле будет иметь индек. Поиск по полям с индексом происходит быстрее чем по полям без индекса. Использование индексов увеличивает размер базы данных. n UNIQUE - указывает на то что все значения данного поля будут уникальными. Попытка записать не уникальное значение в данное поле будет приводить к ошибке. Поиск по уникальным поля происходит быстрее чем для полей с неуникальными данными. n FULLTEXT - указывает на то что к данным хранящимся в данном поле будет возможно применить полнотекстовый поиск.

CREATE TABLE - создание таблицы n В запросе используются необязательные параметры: n n n TEMPORARY - параметр указывает на то что таблица будет создана только для текущего соединения с сервером My. SQL и будет удалена при окончании соединения. Создание таблиц TEMPORARY с одинаковыми именами, но для разных соединений не приведет к ошибке. IF NOT EXISTS - указывает что создать таблицу следует только в том случае если таблица не существует. Если попытаться удалить несуществующую базу данных без параметра IF NOT EXISTS, то результатом выполнения запроса будет ошибка. table_options - задает дополнительные параметры таблицы. Например тип таблицы (описание типов таблиц в My. SQL) или другие параметры оказывающие влияние на работу таблицу в целом. n select_statement - заполняет созданную таблицу значениями полученными в результате выполнения SQL запроса (SELECT)

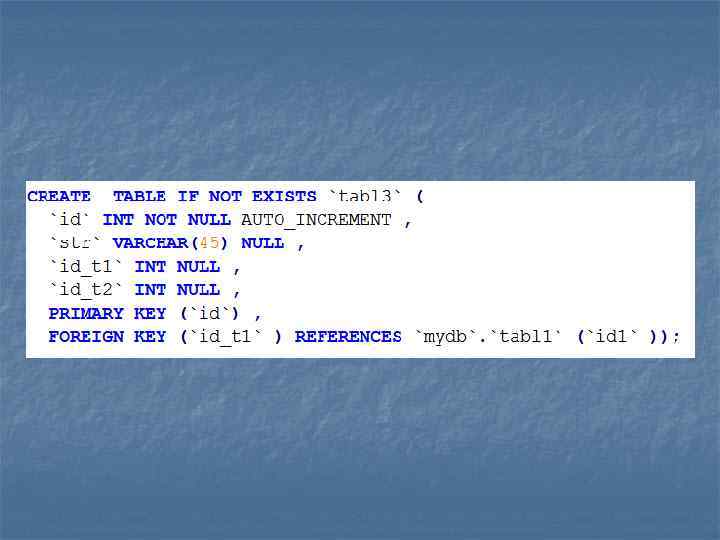
ALTER TABLE - изменение структуры существующей таблицы n n Оператор ALTER TABLE обеспечивает возможность изменять структуру существующей таблицы. Например, можно добавлять или удалять столбцы, создавать или уничтожать индексы или переименовывать столбцы либо саму таблицу. Можно также изменять комментарий для таблицы и ее тип. ALTER [IGNORE] TABLE tbl_name alter_spec [, alter_spec. . . ] alter_specification: n ADD [COLUMN] create_definition [FIRST | AFTER column_name ] n ADD [COLUMN] (create_definition, . . . ) n ADD INDEX [index_name] (index_col_name, . . . ) n ADD PRIMARY KEY (index_col_name, . . . ) n ADD UNIQUE [index_name] (index_col_name, . . . ) n ADD FULLTEXT [index_name] (index_col_name, . . . ) n ADD [CONSTRAINT symbol] FOREIGN KEY index_name (index_col_name, . . . ) [reference_definition] n ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT} n CHANGE [COLUMN] old_col_name create_definition [FIRST | AFTER column_name] n MODIFY [COLUMN] create_definition [FIRST | AFTER column_name] n DROP [COLUMN] col_name n DROP PRIMARY KEY n DROP INDEX index_name n DISABLE KEYS n ENABLE KEYS n RENAME [TO] new_tbl_name n ORDER BY col n table_options

ALTER TABLE - изменение структуры существующей таблицы n n n n Ниже приводятся примеры, показывающие некоторые случаи употребления команды ALTER TABLE. Пример начинается с таблицы t 1, которая создается следующим образом: CREATE TABLE t 1 (a INTEGER, b CHAR(10)); Для того чтобы переименовать таблицу из t 1 в t 2: ALTER TABLE t 1 RENAME t 2; Для того чтобы изменить тип столбца с INTEGER на TINYINT NOT NULL (оставляя имя прежним) и изменить тип столбца b с CHAR(10) на CHAR(20) с переименованием его с b на c: ALTER TABLE t 2 MODIFY a TINYINT NOT NULL, CHANGE b c CHAR(20); Для того чтобы добавить новый столбец INT с именем d: ALTER TABLE t 2 ADD d INT;

ALTER TABLE - изменение структуры существующей таблицы n Для того чтобы добавить индекс к столбцу d и сделать столбец a первичным ключом: n ALTER TABLE t 2 ADD INDEX (d), ADD PRIMARY KEY (a); n n Для того чтобы удалить столбец c: ALTER TABLE t 2 DROP COLUMN c; Для того чтобы добавить новый числовой столбец AUTO_INCREMENT с именем c: ALTER TABLE t 2 ADD c INT UNSIGNED NOT NULL AUTO_INCREMENT, ADD INDEX (c);
![DROP TABLE - удаление таблицы n n DROP TABLE [IF EXISTS] tbl_name [, tbl_name,](https://present5.com/presentation/6473112_27990134/image-27.jpg "DROP TABLE - удаление таблицы n n DROP TABLE [IF EXISTS] tbl_name [, tbl_name,")
DROP TABLE - удаление таблицы n n DROP TABLE [IF EXISTS] tbl_name [, tbl_name, . . . ] [RESTRICT | CASCADE] Оператор DROP TABLE удаляет одну или несколько таблиц. Все табличные данные и определения удаляются.

INSERT - вставка данных n n Оператор INSERT вставляет новые строки в существующую таблицу. Форма данной команды INSERT. . . VALUES вставляет строки в соответствии с точно указанными в команде значениями: INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO] tbl_name [(col_name, . . . )] VALUES (expression, . . . ), (. . . ), . . . n Выражение expression может относится к любому столбцу, который ранее был внесен в список значений. Например, можно указать следующее: INSERT INTO tbl_name (col 1, col 2) VALUES(15, col 1*2); n Но нельзя указать: INSERT INTO tbl_name (col 1, col 2) VALUES(col 2*2, 15);

INSERT - вставка данных n n n n Форма INSERT. . . SELECT вставляет строки, выбранные из другой таблицы или таблиц : INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO] tbl_name [(col_name, . . . )] SELECT. . . Если не указан список столбцов для INSERT. . . VALUES или INSERT. . . SELECT, то величины для всех столбцов должны быть определены в списке VALUES() или в результате работы SELECT. Если порядок столбцов в таблице неизвестен, для его получения можно использовать DESCRIBE tbl_name. Если указывается ключевое слово LOW_PRIORITY, то выполнение данной команды INSERT будет задержано до тех пор, пока другие клиенты не завершат чтение этой таблицы. В этом случае данный клиент должен ожидать, пока данная команда вставки не будет завершена, что в случае интенсивного использования таблицы может потребовать значительного времени. В противоположность этому команда INSERT DELAYED позволяет данному клиенту продолжать операцию сразу же. Если в команде INSERT со строками, имеющими много значений, указывается ключевое слово IGNORE, то все строки, имеющие дублирующиеся ключи PRIMARY или UNIQUE в этой таблице, будут проигнорированы и не будут внесены. Если не указывать IGNORE, то данная операция вставки прекращается при обнаружении строки, имеющей дублирующееся значение существующего ключа.

INSERT - вставка данных n Команда INSERT. . . SELECT обеспечивает возможность быстрого внесения большого количества строк в таблицу из одной или более таблиц. INSERT INTO tbl 2 (Name) SELECT tbl 1. Name FROM tbl 1 WHERE tbl 1. zarplata > 10000; n Для команды INSERT. . . SELECT необходимо соблюдение следующих условий: n n n Целевая таблица команды INSERT не должна появляться в утверждении FROM части SELECT данного запроса, поскольку в ANSI SQL запрещено производить выборку из той же таблицы, в которую производится вставка. Проблема заключается в том, что операция SELECT, возможно, найдет записи, которые были внесены ранее в течение того же самого прогона команды. При использовании команд, внутри которых содержатся многоступенчатые выборки, можно легко попасть в очень запутанную ситуацию! Столбцы AUTO_INCREMENT работают, как обычно.
![UPDATE - изменение данных n n n n UPDATE [LOW_PRIORITY] [IGNORE] tbl_name SET col_name](https://present5.com/presentation/6473112_27990134/image-31.jpg "UPDATE - изменение данных n n n n UPDATE [LOW_PRIORITY] [IGNORE] tbl_name SET col_name")
UPDATE - изменение данных n n n n UPDATE [LOW_PRIORITY] [IGNORE] tbl_name SET col_name 1=expr 1 [, col_name 2=expr 2, . . . ] [WHERE where_definition] [LIMIT #] Оператор UPDATE обновляет столбцы в соответствии с их новыми значениями в строках существующей таблицы. В выражении SET указывается, какие именно столбцы следует модифицировать и какие величины должны быть в них установлены. В выражении WHERE, если оно присутствует, задается, какие строки подлежат обновлению. В остальных случаях обновляются все строки. Если задано выражение ORDER BY, то строки будут обновляться в указанном в нем порядке. Если указывается ключевое слово LOW_PRIORITY, то выполнение данной команды UPDATE задерживается до тех пор, пока другие клиенты не завершат чтение этой таблицы. Если указывается ключевое слово IGNORE, то команда обновления не будет прервана, даже если при обновлении возникнет ошибка дублирования ключей. Строки, из-за которых возникают конфликтные ситуации, обновлены не будут.

UPDATE - изменение данных n n n Если доступ к столбцу из указанного выражения осуществляется по аргументу tbl_name, то команда UPDATE использует для этого столбца его текущее значение. Например, следующая команда устанавливает столбец age в значение, на единицу большее его текущей величины: UPDATE persondata SET age=age+1; Значения команда UPDATE присваивает слева направо. Например, следующая команда дублирует столбец age, затем инкрементирует его: UPDATE persondata SET age=age*2, age=age+1; Если столбец устанавливается в его текущее значение, то My. SQL замечает это и не обновляет его. Можно использовать LIMIT #, чтобы убедиться, что было изменено только заданное количество строк.

DELETE – удаление строк из таблицы n Удаляет записи из таблицы. n DELETE FROM table_name WHERE where_definition n [ORDER BY n] [LIMIT row_count] n where_definition имеет формат: n where_expr или where_expr [AND | OR] where_expr n n В выражении WHERE, если оно присутствует, задается, какие строки подлежат удалению. Если вызван DELETE без WHERE, то таблица будет очищена. n Примеры: n n n DELETE FROM employee WHERE fn = 'Иванов' LIMIT 1; DELETE FROM tel_numb WHERE fio='Петров' AND tel='23 -45 -45‘;

Оператор SELECT

Синтаксис оператора выборки n В довольно сильно упрощенном виде оператор выборки данных имеет следующий синтаксис: Оператор выборки : : = n [ORDER BY {{Имя столбца-результата [ASC | DESC]} | {Положительное целое [ASC | DESC]}}. , . . ]; Табличное выражение : : = n Табличное выражение Select-выражение [ ] n {UNION | INTERSECT | EXCEPT} [ALL] {Select-выражение | TABLE Имя таблицы | Select-выражение : : = Конструктор значений таблицы} SELECT [ALL | DISTINCT] {{{Скалярное выражение | Функция агрегирования | Select-выражение} [AS Имя столбца]}. , . . } | {{Имя таблицы |Имя корреляции}. *} |* FROM { {Имя таблицы [AS] [Имя корреляции] [(Имя столбца. , . . )]} | {Select-выражение [AS] Имя корреляции [(Имя столбца. , . . )]} | Соединенная таблица }. , . . [WHERE Условное выражение] [GROUP BY {[{Имя таблицы|Имя корреляции}. ]Имя столбца}. , . . ] [HAVING Условное выражение]

Стадии n n Стадия 1. Выполнение одиночного оператора SELECT Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно: n Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, n Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то n Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A. сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B. строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
. Если в операторе SELECT присутствует раздел n Шаг 5")
Стадии n Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел n Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D. генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.

Стадии n n Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1 -й стадии, объединяются, вычитаются или пересекаются. Стадия 3. Упорядочение результата Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.

Отбор данных из одной таблицы n Выбрать все данные из таблицы поставщиков (ключевые слова SELECT… FROM…): n n n В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P. Выбрать все строки из таблицы поставщиков, удовлетворяющих некоторому условию (ключевое слово WHERE…): n n SELECT * FROM P; SELECT * FROM P WHERE P. PNUM > 2; В качестве условия в разделе WHERE можно использовать сложные логические выражения, использующие поля таблиц, константы, сравнения (>, <, = и т. д. ), скобки, союзы AND и OR, отрицание NOT.

Отбор данных из одной таблицы n Выбрать все данные из таблицы поставщиков (ключевые слова SELECT… FROM…): SELECT * FROM P ; n В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P.

Отбор данных из одной таблицы n Выбрать все строки из таблицы поставщиков, удовлетворяющих некоторому условию (ключевое слово WHERE…): SELECT * FROM P WHERE P. PNUM > 2; n В качестве условия в разделе WHERE можно использовать сложные логические выражения, использующие поля таблиц, константы, сравнения (>, <, = и т. д. ), скобки, союзы AND и OR, отрицание NOT.

Отбор данных из одной таблицы n Выбрать некоторые колонки из исходной таблицы (указание списка отбираемых колонок): SELECT P. NAME FROM P ; n n В результате получим таблицу с одной колонкой, содержащую все наименования поставщиков. Если в исходной таблице присутствовало несколько поставщиков с разными номерами, но одинаковыми наименованиями, то в результирующей таблице будут строки с повторениями - дубликаты строк автоматически не отбрасываются.

n Отбор данных из одной таблицы Выбрать некоторые колонки из исходной таблицы, удалив из результата повторяющиеся строки (ключевое слово DISTINCT): SELECT DISTINCT P. NAME FROM P ; n Использование ключевого слова DISTINCT приводит к тому, что в результирующей таблице будут удалены все повторяющиеся строки.

Отбор данных из одной таблицы n Использование скалярных выражений и переименований колонок в запросах (ключевое слово AS…): SELECT TOVAR. TNAME, TOVAR. KOL, TOVAR. PRICE, "=" AS EQU, TOVAR. KOL*TOVAR. PRICE AS SUMMA FROM TOVAR ; n В результате получим таблицу с колонками, которых не было в исходной таблице TOVAR: TNAME KOL PRICE EQU SUMMA Болт 10 100 = 1000 Гайка 20 200 = 4000 Винт 30 300 = 9000

n Отбор данных из одной SELECT таблицы PD. PNUM, Упорядочение результатов запроса (ключевое слово ORDER BY…): PD. DNUM, PD. VOLUME FROM PD ORDER BY DNUM; n В результате получим следующую таблицу, упорядоченную по полю DNUM: PNUM DNUM VOLUME 1 1 100 2 1 150 3 1 1000 1 2 200 2 2 250 1 3 300

Отбор данных из одной таблицы n Упорядочение результатов запроса по нескольким полям с возрастанием или убыванием (ключевые слова ASC, DESC): SELECT PD. PNUM, PD. DNUM, PD. VOLUME FROM PD ORDER BY DNUM ASC, VOLUME DESC; n n В результате получим таблицу, в которой строки идут в порядке возрастания значения поля DNUM, а строки, с одинаковым значением DNUM идут в порядке убывания значения поля VOLUME: Если явно не указаны ключевые слова ASC или DESC, то по умолчанию принимается упорядочение по возрастанию (ASC). PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300
 PNUM Иванов 4 2")
Отбор данных из нескольких таблиц Таблица «PD» Таблица «P» (Поставщики) PNUM Иванов 4 2 Петров 1 3 n PSTATUS 1 n PNAME Сидоров 2 PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300 Естественное соединение таблиц способ 1 - явное указание условий соединения: SELECT P. PNUM, P. PNAME, PD. DNUM, PD. VOLUME FROM P, PD WHERE P. PNUM = PD. PNUM; n n В результате получим новую таблицу, в которой строки с данными о поставщиках соединены со строками с данными о поставках деталей: Соединяемые таблицы перечислены в разделе FROM оператора, условие соединения приведено в разделе WHERE. Раздел WHERE, помимо условия соединения таблиц, может также содержать и условия отбора строк. PNUM PNAME DNUM VOLUME 1 Иванов 1 100 1 Иванов 2 200 1 Иванов 3 300 2 Петров 1 150 2 Петров 2 250 3 Сидоров 1 1000
 PNUM Иванов 4 2")
Отбор данных из нескольких таблиц Таблица «PD» Таблица «P» (Поставщики) PNUM Иванов 4 2 Петров 1 3 n PSTATUS 1 n PNAME Сидоров 2 PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300 Естественное соединение таблиц способ 2 - ключевые слова JOIN… USING…: SELECT P. PNUM, P. PNAME, PD. DNUM, PD. VOLUME FROM P JOIN PD USING PNUM; n Ключевое слово USING позволяет явно указать, по каким из общих колонок таблиц будет производиться соединение. PNUM PNAME DNUM VOLUME 1 Иванов 1 100 1 Иванов 2 200 1 Иванов 3 300 2 Петров 1 150 2 Петров 2 250 3 Сидоров 1 1000
 PNUM Иванов 4 2")
Отбор данных из нескольких таблиц Таблица «PD» Таблица «P» (Поставщики) PNUM Иванов 4 2 Петров 1 3 n PSTATUS 1 n PNAME Сидоров 2 PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300 Естественное соединение таблиц способ 3 - ключевое слово NATURAL JOIN : SELECT P. PNUM, P. PNAME, PD. DNUM, PD. VOLUME FROM P NATURAL JOIN PD; n n В разделе FROM не указано, по каким полям производится соединение. NATURAL JOIN автоматически соединяет по всем одинаковым полям в таблицах. PNUM PNAME DNUM VOLUME 1 Иванов 1 100 1 Иванов 2 200 1 Иванов 3 300 2 Петров 1 150 2 Петров 2 250 3 Сидоров 1 1000
 Таблица «PD» PNUM PNAME PSTATUS 1")
Отбор данных из нескольких таблиц Таблица «P» (Поставщики) Таблица «PD» PNUM PNAME PSTATUS 1 Иванов 4 1000 2 Петров 1 1 150 3 Сидоров 2 1 1 100 2 2 250 1 2 200 DNUM DNAME DSTATUS 1 3 300 1 Болт 3 2 Гайка 2 3 Винт 1 PNUM VOLUME 3 1 2 n DNUM Естественное соединение трех таблиц: Таблица «D» (Детали) SELECT P. PNAME, D. DNAME, PD. VOLUME FROM P NATURAL JOIN PD NATURAL JOIN D; n В результате получим следующую таблицу: PNAME DNAME VOLUME Иванов Болт 100 Иванов Гайка 200 Иванов Винт 300 Петров Болт 150 Петров Гайка 250 Сидоров Болт 1000

Соединение таблиц по произвольному условию n Ответ на вопрос "какие поставщики имеют право поставлять какие детали? " дает следующий запрос: Таблица «D» (Детали) DNUM DNAME DSTATUS 1 Болт 3 2 Гайка 2 3 Винт 1 SELECT P. PNUM, P. PNAME, P. PSTATUS, D. DNUM, D. DNAME, D. DSTATUS FROM P, D WHERE P. PSTATUS >= D. DSTATUS; n Таблица «P» (Поставщики) PNUM PNAME PSTATUS 1 Иванов 4 2 Петров 1 3 Сидоров 2 В результате получим следующую таблицу: PNUM PNAME PSTATUS DNUM DNAME DSTATUS 1 Иванов 4 1 Болт 3 1 Иванов 4 2 Гайка 2 1 Иванов 4 3 Винт 1 2 Петров 1 3 Винт 1 3 Сидоров 2 2 Гайка 2 3 Сидоров 2 3 Винт 1
 Таблица «P» (Поставщики) DNUM PNAME PSTATUS Болт 3")
Прямое произведение таблиц Таблица «D» (Детали) Таблица «P» (Поставщики) DNUM PNAME PSTATUS Болт 3 1 Иванов 4 2 Гайка 2 2 Петров 1 3 n DSTATUS 1 n DNAME Винт 1 3 Сидоров 2 Т. к. не указано условие соединения таблиц, то каждая строка первой таблицы соединится с каждой строкой второй таблицы. Прямое произведение таблиц: SELECT n P. PNUM, P. PNAME, D. DNUM, D. DNAME FROM P, D ; В результате получим следующую таблицу: PNUM PNAME DNUM DNAME 1 Иванов 1 Болт 1 Иванов 2 Гайка 1 Иванов 3 Винт 2 Петров 1 Болт 2 Петров 2 Гайка 2 Петров 3 Винт 3 Сидоров 1 Болт 3 Сидоров 2 Гайка 3 Сидоров 3 Винт
 n Иногда приходится выполнять запросы, в которых: n n")
Использование имен корреляции (алиасов, псевдонимов) n Иногда приходится выполнять запросы, в которых: n n n n таблица соединяется сама с собой, одна таблица соединяется дважды с другой таблицей. При этом используются имена корреляции (алиасы, псевдонимы), которые позволяют различать соединяемые копии таблиц. Имена корреляции вводятся в разделе FROM и идут через пробел после имени таблицы. Имена корреляции должны использоваться в качестве префикса перед именем столбца и отделяются от имени столбца точкой. Если в запросе указываются одни и те же поля из разных экземпляров одной таблицы, они должны быть переименованы для устранения неоднозначности в именованиях колонок результирующей таблицы. Определение имени корреляции действует только во время выполнения запроса.

Пример использования имен корреляции n Отобрать все пары поставщиков таким образом, чтобы первый поставщик в паре имел статус, больший статуса второго поставщика: Таблица «P» (Поставщики) SELECT PNUM PNAME PSTATUS 1 Иванов 4 2 Петров 1 3 Сидоров 2 P 1. PNAME AS PNAME 1, P 1. PSTATUS AS PSTATUS 1, P 2. PNAME AS PNAME 2, P 2. PSTATUS AS PSTATUS 2 FROM P P 1, P P 2 WHERE P 1. PSTATUS 1 > P 2. PSTATUS 2 ; n В результате получим следующую таблицу: PNAME 1 PSTATUS 1 PNAME 2 PSTATUS 2 Иванов 4 Петров 1 Иванов 4 Сидоров 2 Петров 1

Использование агрегатных функций в запросах n Таблица «P» PNUM PSTATUS 1 Иванов 4 2 Петров 1 3 n PNAME Сидоров 2 Получить общее количество поставщиков (ключевое слово COUNT ): SELECT COUNT(*) AS N FROM P ; n В результате получим таблицу с одним столбцом и одной строкой, содержащей количество строк из таблицы P: N 3

Использование агрегатных функций в запросах n Таблица «PD» n Получить общее, максимальное, минимальное и среднее количества поставляемых деталей (ключевые слова SUM, MAX, MIN, AVG): PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 SELECT SUM(PD. VOLUME ) AS SM, MAX(PD. VOLUME ) AS MX, MIN(PD. VOLUME ) AS MN, AVG(PD. VOLUME ) AS AV FROM PD; n 2 2 250 1 2 200 1 3 300 В результате получим следующую таблицу с одной строкой: SM MX MN AV 2000 100 3333

Использование агрегатных функций с группировками n Для каждой детали получить суммарное поставляемое количество (ключевое слово GROUP BY…): SELECT PD. DNUM, SUM(PD. VOLUME) AS SM FROM PD GROUP BY PD. DNUM ; n n Таблица «PD» PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300 Этот запрос будет выполняться следующим образом. n n n Сначала строки исходной таблицы будут сгруппированы так, чтобы в каждую группу попали строки с одинаковыми значениями DNUM. Потом внутри каждой группы будет просуммировано поле VOLUME. От каждой группы в результирующую таблицу будет включено по одной строке. DNUM SM 1 1250 2 450 3 300

Использование агрегатных функций с группировками n n В списке отбираемых полей оператора SELECT, содержащего раздел GROUP BY можно включать только агрегатные функции и поля, которые входят в условие группировки. Следующий запрос может выдать синтаксическую ошибку: SELECT PD. PNUM, PD. DNUM, SUM(PD. VOLUME ) AS SM GROUP BY PD. DNUM ; n n n Причина ошибки в том, что в список отбираемых полей включено поле PNUM, которое не входит в раздел GROUP BY. И действительно, в каждую полученную группу строк может входить несколько строк с различными значениями поля PNUM. Из каждой группы строк будет сформировано по одной итоговой строке. При этом нет однозначного ответа на вопрос, какое значение выбрать для поля PNUM в итоговой строке. Замечание. Некоторые диалекты SQL не считают это за ошибку. Запрос будет выполнен, но предсказать, какие значения будут внесены в поле PNUM в результирующей таблице, невозможно.

Использование агрегатных функций с группировками + HAVING … n Получить номера деталей, суммарное поставляемое количество которых превосходит 400 (ключевое слово HAVING…): SM 1 1250 2 n PNUM DNUM VOLUME 3 1 1000 1 150 PD. DNUM, 1 1 100 SUM(PD. VOLUME ) AS SM 2 2 250 GROUP BY PD. DNUM 1 2 200 HAVING SUM(PD. VOLUME ) > 400; 1 3 300 В результате получим следующую таблицу: n Замечание. Условие, что суммарное DNUM n Таблица «PD» 2 SELECT n n 450 поставляемое количество должно быть больше 400 не может быть сформулировано в разделе WHERE, т. к. в этом разделе нельзя использовать агрегатные функции. Условия, использующие агрегатные функции должны быть размещены в специальном разделе HAVING. В одном запросе могут встретиться как условия отбора строк в разделе WHERE, так и условия отбора групп в разделе HAVING. Условия отбора групп нельзя перенести из раздела HAVING в раздел WHERE. Аналогично и условия отбора строк нельзя перенести из раздела WHERE в раздел HAVING, за исключением условий, включающих поля из списка группировки GROUP BY.

Использование подзапросов n n Очень удобным средством, позволяющим формулировать запросы более понятным образом, является возможность использования подзапросов, вложенных в основной запрос. Получить список поставщиков, статус которых меньше максимального статуса в таблице поставщиков (сравнение с подзапросом): SELECT * FROM P WHERE P. STATUS < (SELECT MAX(P. STATUS ) FROM P ); n n Т. к. поле P. STATUS сравнивается с результатом подзапроса, то подзапрос должен быть сформулирован так, чтобы возвращать таблицу, состоящую ровно из одной строки и одной колонки. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: n n Выполнить один раз вложенный подзапрос и получить максимальное значение статуса. Просканировать таблицу поставщиков P, каждый раз сравнивая значение статуса поставщика с результатом подзапроса, и отобрать только те строки, в которых статус меньше максимального.

Использование предиката IN n Получить список поставщиков, поставляющих деталь номер 2: SELECT * FROM P WHERE P. PNUM IN (SELECT DISTINCT PD. PNUM FROM PD WHERE PD. DNUM = 2 ); n n В данном случае вложенный подзапрос может возвращать таблицу, содержащую несколько строк. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: n Выполнить один раз вложенный подзапрос и получить список номеров n поставщиков, поставляющих деталь номер 2. Просканировать таблицу поставщиков P, каждый раз проверяя, содержится ли номер поставщика в результате подзапроса.

Использование предиката EXIST n Получить список поставщиков, поставляющих деталь номер 2: SELECT * FROM P WHERE EXIST (SELECT * FROM PD WHERE PD. PNUM = P. PNUM AND PD. DNUM = 2 ); n n n PNUM DNUM VOLUME 3 1 1000 2 1 150 1 1 100 2 2 250 1 2 200 1 3 300 Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: n n Таблица «PD» Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P. В результат запроса включить только те строки из таблицы поставщиков, для которых вложенный подзапрос вернул непустое множество строк. В отличие от предыдущих примеров, вложенный подзапрос содержит параметр (внешнюю ссылку), передаваемый из основного запроса - номер поставщика P. PNUM. Такие подзапросы называются коррелируемыми (correlated). Внешняя ссылка может принимать различные значения для каждой строки-кандидата, оцениваемого с помощью подзапроса, поэтому подзапрос должен выполняться заново для каждой строки, отбираемой в основном запросе. Такие подзапросы характерны для предиката EXIST, но могут быть использованы и в других подзапросах. Может показаться, что запросы, содержащие коррелируемые подзапросы будут выполняться медленнее, чем запросы с некоррелируемыми подзапросами. На самом деле это не так, т. к. то, как пользователь, сформулировал запрос, не определяет, как этот запрос будет выполняться. Язык SQL является непроцедурным, а декларативным. Это значит, что пользователь, формулирующий запрос, просто описывает, каким должен быть результат запроса, а как этот результат будет получен - за это отвечает сама СУБД.

Использование предиката NOT EXIST n Получить список поставщиков, не поставляющих деталь номер 2: SELECT * FROM P WHERE NOT EXIST (SELECT * FROM PD WHERE PD. PNUM = P. PNUM AND PD. DNUM = 2 ); n Также как и в предыдущем примере, здесь используется коррелируемый подзапрос. Отличие в том, что в основном запросе будут отобраны те строки из таблицы поставщиков, для которых вложенный подзапрос не выдаст ни одной строки.

Использование предиката NOT EXIST n Получить имена поставщиков, поставляющих все детали: SELECT DISTINCT PNAME FROM P WHERE NOT EXIST (SELECT * FROM D WHERE NOT EXIST (SELECT * FROM PD WHERE PD. DNUM = D. DNUM AND PD. PNUM = P. PNUM )); n n Данный запрос содержит два вложенных подзапроса и реализует реляционную операцию деления отношений. Самый внутренний подзапрос параметризован двумя параметрами (D. DNUM, P. PNUM) и имеет следующий смысл: n n отобрать все строки, содержащие данные о поставках поставщика с номером PNUM детали с номером DNUM. Отрицание NOT EXIST говорит о том, что данный поставщик не поставляет данную деталь. Внешний к нему подзапрос, сам являющийся вложенным и параметризованным параметром P. PNUM, имеет смысл: n отобрать список деталей, которые не поставляются поставщиком PNUM. Отрицание NOT EXIST говорит о том, что для поставщика с номером PNUM не должно быть деталей, которые не поставлялись бы этим поставщиком. Это в точности означает, что во внешнем запросе отбираются только поставщики, поставляющие все детали.

Использование объединения n Получить имена поставщиков, имеющих статус, больший 3 или поставляющих хотя бы одну деталь номер 2 (объединение двух подзапросов - ключевое слово UNION): SELECT P. PNAME FROM P WHERE P. STATUS > 3 UNION SELECT P. PNAME FROM P, PD WHERE P. PNUM = PD. PNUM AND PD. DNUM = 2 ; n n Результирующие таблицы объединяемых запросов должны быть совместимы, т. е. иметь одинаковое количество столбцов и одинаковые типы столбцов в порядке их перечисления. Не требуется, чтобы объединяемые таблицы имели бы одинаковые имена колонок. Это отличает операцию объединения запросов в SQL от операции объединения в реляционной алгебре. Наименования колонок в результирующем запросе будут автоматически взяты из результата первого запроса в объединении.

Использование пересечения n Получить имена поставщиков, имеющих статус, больший 3 и одновременно поставляющих хотя бы одну деталь номер 2 (пересечение двух подзапросов - ключевое слово INTERSECT): SELECT P. PNAME FROM P WHERE P. STATUS > 3 INTERSECT SELECT P. PNAME FROM P, PD WHERE P. PNUM = PD. PNUM AND PD. DNUM = 2 ;

Использование разности n Получить имена поставщиков, имеющих статус, больший 3, за исключением тех, кто поставляет хотя бы одну деталь номер 2 (разность двух подзапросов - ключевое слово EXCEPT): SELECT P. PNAME FROM P WHERE P. STATUS > 3 EXCEPT SELECT P. PNAME FROM P, PD WHERE P. PNUM = PD. PNUM AND PD. DNUM = 2 ;

Синтаксис условных выражений раздела WHERE n n Условное выражение, используемое в разделе WHERE оператора SELECT должно вычисляться для каждой строки-кандидата, отбираемой оператором SELECT. Условное выражение может возвращать одно из трех значений истинности: TRUE, FALSE или UNKNOUN. Строка-кандидат отбирается в результатирующее множество строк только в том случае, если для нее условное выражение вернуло значение TRUE. Условные выражения имеют следующий синтаксис (в целях упрощения изложения приведены не все возможные предикаты): Условное выражение : : = [ ( ] [NOT] {Предикат сравнения | Предикат between | Предикат in | Предикат like | Предикат null | Предикат количественного сравнения | Предикат exist | Предикат unique | Предикат match | Предикат overlaps} [{AND | OR} Условное выражение] [ ) ] [IS [NOT] {TRUE | FALSE | UNKNOWN}] Предикат сравнения : : = Конструктор значений строки {= | < | > | <= | >= | <>} Конструктор значений строки

Предикаты оператора WHERE n n Предикат сравнения : : = Конструктор значений строки {= | < | > | <= | >= | <>} Конструктор значений строки Пример Сравнение поля таблицы и скалярного значения: n n Пример Сравнение двух сконструированных строк: n n POSTAV. VOLUME > 100 (PD. PNUM, PD. DNUM) = (1, 25) Этот пример эквивалентен условному выражению n PD. PNUM = 1 AND PD. DNUM = 25
![Предикаты оператора WHERE n Предикат between : : = Конструктор значений строки [NOT] BETWEEN](https://present5.com/presentation/6473112_27990134/image-70.jpg "Предикаты оператора WHERE n Предикат between : : = Конструктор значений строки [NOT] BETWEEN")
Предикаты оператора WHERE n Предикат between : : = Конструктор значений строки [NOT] BETWEEN Конструктор значений строки AND Конструктор значений строки n Пример n PD. VOLUME BETWEEN 10 AND 100
![Предикаты оператора WHERE n n Предикат in : : = Конструктор значений строки [NOT]](https://present5.com/presentation/6473112_27990134/image-71.jpg "Предикаты оператора WHERE n n Предикат in : : = Конструктор значений строки [NOT]")
Предикаты оператора WHERE n n Предикат in : : = Конструктор значений строки [NOT] IN {(Select-выражение) | (Выражение для вычисления значения. , . . )} Пример n n P. PNUM IN (SELECT PD. PNUM FROM PD WHERE PD. DNUM=2) Пример n P. PNUM IN (1, 2, 3, 5)

Предикаты оператора WHERE n n Предикат like : : = Выражение для вычисления значения строкипоиска [NOT] LIKE Выражение для вычисления значения строкишаблона [ESCAPE Символ] Предикат LIKE производит поиск строки-поиска в строке-шаблоне. В строке-шаблоне разрешается использовать два трафаретных символа: Символ подчеркивания "_" может использоваться вместо любого единичного символа в строке-поиска, Символ процента "%" может заменять набор любых символов в строке-поиска (число символов в наборе может быть от 0 и более).

Предикаты оператора WHERE n n Предикат null : : = Конструктор значений строки IS [NOT] NULL Замечание. Предикат NULL применяется специально для проверки, не равно ли проверяемое выражение null-значению.

Предикаты оператора WHERE n n n Предикат количественного сравнения : : = Конструктор значений строки {= | < | > | <= | >= | <>} {ANY | SOME | ALL} (Select-выражение) Кванторы ANY и SOME являются синонимами и полностью взаимозаменяемы. Если указан один из кванторов ANY и SOME, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает хотя бы с одним значением, возвращаемом в подзапросе (selectвыражении). Если указан квантор ALL, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает с каждым значением, возвращаемом в подзапросе (select-выражении). Пример n P. PNUM = SOME (SELECT PD. PNUM FROM PD WHERE PD. DNUM=2)
 Предикат EXIST")
Предикаты оператора WHERE n n Предикат exist : : = EXIST (Select-выражение) Предикат EXIST возвращает значение TRUE, если результат подзапроса (selectвыражения) не пуст.
 Предикат UNIQUE")
Предикаты оператора WHERE n n Предикат unique : : = UNIQUE (Select-выражение) Предикат UNIQUE возвращает TRUE, если в результате подзапроса (selectвыражения) нет совпадающих строк.

Предикаты оператора WHERE n n Предикат match : : = Конструктор значений строки MATCH [UNIQUE] [PARTIAL | FULL] (Select-выражение) Предикат MATCH проверяет, будет ли значение, определенное в конструкторе строки совпадать со значением любой строки, полученной в результате подзапроса.

Предикаты оператора WHERE n n Предикат overlaps : : = Конструктор значений строки OVERLAPS Конструктор значений строки Предикат OVERLAPS, является специализированным предикатом, позволяющем определить, будет ли указанный период времени перекрывать другой период времени.

Синтаксис соединенных таблиц n n n В разделе FROM оператора SELECT можно использовать соединенные таблицы. Пусть в результате некоторых операций мы получаем таблицы A и B. Такими операциями могут быть, например, оператор SELECT или другая соединенная таблица. Тогда синтаксис соединенной таблицы имеет следующий вид: Соединенная таблица : : = Перекрестное соединение | Естественное соединение | Соединение посредством предиката | Соединение посредством имен столбцов | Соединение объединения Тип соединения : : = INNER | LEFT [OUTER] | RIGTH [OUTER] | FULL [OUTER]
 не является обязательными,")
Способы объединения таблиц n n OUTER - Ключевое слово OUTER (внешний) не является обязательными, оно не используется ни в каких операциях с данными. INNER - Тип соединения "внутреннее". Внутренний тип соединения используется по умолчанию, когда тип явно не задан. В таблицах А и В соединяются только те строки, для которых найдено совпадение.

Способы объединения таблиц n n CROSS JOIN - Перекрестное соединение возвращает просто декартово произведение таблиц. Такое соединение в разделе FROM может быть заменено списком таблиц через запятую. n Перекрестное соединение : : = Таблица А CROSS JOIN Таблица В

Способы объединения таблиц n n NATURAL JOIN - Естественное соединение производится по всем столбцам таблиц А и В, имеющим одинаковые имена. В результирующую таблицу одинаковые столбцы вставляются только один раз. n Естественное соединение : : = Таблица А [NATURAL] [Тип соединения] JOIN Таблица В

Способы объединения таблиц n JOIN … ON - Соединение посредством предиката соединяет строки таблиц А и В посредством указанного предиката. n Соединение посредством предиката : : = Таблица А [Тип соединения] JOIN Таблица В ON Предикат

Способы объединения таблиц n JOIN … USING - Соединение посредством имен столбцов соединяет отношения подобно естественному соединению по тем общим столбцам таблиц А и Б, которые указаны в списке USING. n Соединение посредством имен столбцов : : = Таблица А [Тип соединения] JOIN Таблица В USING (Имя столбца. , . . )
 - Тип соединения \"левое (внешнее)\". Левое")
Способы объединения таблиц n n n LEFT (OUTER) - Тип соединения "левое (внешнее)". Левое соединение таблиц А и В включает в себя все строки из левой таблицы А и те строки из правой таблицы В, для которых обнаружено совпадение. Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL.
 - Тип соединения \"правое (внешнее)\". Правое")
Способы объединения таблиц n n n RIGHT (OUTER) - Тип соединения "правое (внешнее)". Правое соединение таблиц А и В включает в себя все строки из правой таблицы В и те строки из левой таблицы А, для которых обнаружено совпадение. Для строк из таблицы В, для которых не найдено соответствия в таблице А, в столбцы, извлекаемые из таблицы А заносятся значения NULL.
 - Тип соединения \"полное (внешнее)\". Это комбинация")
Способы объединения таблиц n n FULL (OUTER) - Тип соединения "полное (внешнее)". Это комбинация левого и правого соединений. В полное соединение включаются все строки из обеих таблиц. Для совпадающих строк поля заполняются реальными значениями, для несовпадающих строк поля заполняются в соответствии с правилами левого и правого соединений.

Способы объединения таблиц n n UNION JOIN - Соединение объединения является обратным по отношению к внутреннему соединению. Оно включает только те строки из таблиц А и В, для которых не найдено совпадений. В них используются значения NULL для столбцов, полученных из другой таблицы. Если взять полное внешнее соединение и удалить из него строки, полученные в результате внутреннего соединения, то получится соединение объединения. n Соединение объединения : : = Таблица А UNION JOIN Таблица В
 n n n n n Иногда приходится выполнять запросы,")
Использование имен корреляции (алиасов, псевдонимов) n n n n n Иногда приходится выполнять запросы, в которых таблица соединяется сама с собой, или одна таблица соединяется дважды с другой таблицей. При этом используются имена корреляции (алиасы, псевдонимы), которые позволяют различать соединяемые копии таблиц. Имена корреляции вводятся в разделе FROM и идут через пробел после имени таблицы. Имена корреляции должны использоваться в качестве префикса перед именем столбца и отделяются от имени столбца точкой. Если в запросе указываются одни и те же поля из разных экземпляров одной таблицы, они должны быть переименованы для устранения неоднозначности в именованиях колонок результирующей таблицы. Определение имени корреляции действует только во время выполнения запроса. Пример SELECT P 1. PNAME AS PNAME 1, P 1. PSTATUS AS PSTATUS 1, P 2. PNAME AS PNAME 2, P 2. PSTATUS AS PSTATUS 2 FROM P P 1, P P 2 WHERE P 1. PSTATUS 1 > P 2. PSTATUS 2;
Обзор языка SQL.ppt