6deffbccbc837d9a022c5bed1b467f48.ppt
- Количество слайдов: 91


")
High Performance Computing – CISC 811 Dr Rob Thacker Dept of Physics (308 A) thacker@physics

Today’s Lecture HPC Libraries Part 1: Motivations and benefits, serial libraries n Part 2: Parallel libraries, ACTS collection n Part 3: Netlib, HPL n

Part 1: HPC Libraries Motivations, benefits n Serial HPC libraries n

Is our current programming model viable? "We need to move away from a coding style suited for serial machines, where every macrostep of an algorithm needs to be thought about and explicitly coded, to a higher-level style, where the compiler and library tools take care of the details. And the remarkable thing is, if we adopt this higher-level approach right now, even on today's machines, we will see immediate benefits in our productivity. " W. H. Press and S. A. Teukolsky, 1997 Numerical Recipes: Does This Paradigm Have a future?

Motivations, concerns n In developing large applications, three significant issues must be addressed: n n Complexity n Increasingly sophisticated models, may need to link to other solvers n n Productivity n Time to the first solution (prototype) and time to solution (production) Performance n Increasingly complex algorithms, architectures What strategies should be applied? n Some appear mutually exclusive: best performance would reduce productivity if you tailor every single part of the code
")
Unavoidable tension Scientists frequently need highest performance Algorithms have long lifetimes (longer than hardware) Low level programming High level programming
 n n")
Library approach n Why not use libraries? (provided they suit your problem) n n Main drawback – loss of understanding of code inner workings n n n Optimization – many library functions are often assembly optimized Well tested – libraries are used by far more people than your local research group Support – frequently commercial packages come with online forums or email support Is this really an issue? 99. 9% of the software you use you didn’t write Also you are forced into using the library interface, but usual this is not a significant concern Secondary drawback may be cost

Library ownership n Three main possibilities n Public Domain n Most common for numerical software n Commercial n Becoming more common as Universities attempt to gain from Intellectual property n Vendor Specific n Many of the big vendors release platform specific optimized versions of the larger public domain packages

Potential benefits of libraries n n Allows easier collaboration (provided library is freely available to everyone!) Software using GPL’d libraries can be released publicly as source-code n n n You can contribute back improvements to the user community Source based libraries can be adapted to your needs Bottomline is that your time to solution is reduced!

Bugs are a serious issue… On June 4, 1996, an Ariane 5 rocket launched by the European Space Agency exploded just forty seconds after its lift-off from Kourou, French Guiana. The rocket was on its first voyage, after a decade of development costing $7 billion. The problem was a software error in the inertial reference system. Specifically a 64 bit floating point number relating to the horizontal velocity of the rocket with respect to the platform was converted to a 16 bit signed integer. On August 23, 1991, the first concrete base structure for the Sleipner A platform sprang a leak and sank under a controlled ballasting operation during preparation for deck mating in Gandsfjorden outside Stavanger, Norway. The post accident investigation traced the error to inaccurate finite element approximation of the linear elastic model of the tricell (using the popular finite element program NASTRAN). The shear stresses were underestimated by 47% leading to insufficient design. In particular, certain concrete walls were not thick enough.

Something to think about… n ~ 20 years ago 1 x 106 Floating Point Ops/sec (Mflop/s) n n ~ 10 years ago 1 x 109 Floating Point Ops/sec (Gflop/s) n n n Vector & Shared memory computing, bandwidth aware Block partitioned, latency tolerant ~ Today 1 x 1012 Floating Point Ops/sec (Tflop/s) n n n Scalar based Highly parallel, distributed processing, message passing, network based data decomposition, communication/computation Coming soon 1 x 1015 Floating Point Ops/sec (Pflop/s) n n n Many more levels of memory hierarchy, combination of grids&HPC More adaptive, latency and bandwidth aware, fault tolerant, extended precision, attention to SMP nodes Application codes will need to address these issues

The Evolving Performance Gap 1, 000 Peak Performance Peak performance is skyrocketing l In 1990 s, peak performance increased 100 x; in 2000 s, it will increase 1000 x But 100 Teraflops l Performance Gap 10 1 Real Performance 0. 1 1996 2000 Efficiency for many science applications declined from 40 -50% on the vector supercomputers of 1990 s to as little as 5 -10% on parallel supercomputers of today Need research on l Mathematical methods and algorithms that achieve high performance on a single processor and scale to thousands of processors l More efficient programming models for massively parallel supercomputers 2004 We don’t want everyone working on the same problem though!

Notable Public Domain Numerical Libraries n LAPACK n n BLAS n n Sparse problems PIM n n Numerical Quadrature ITPACK n n Ordinary d. e. solving (see also the DASSL toolkit) QUADPACK n n Linear equation solving (now incorporated in LAPACK) ODEPACK n n Fast linear algebra kernels LINPACK n n Linear equations, eigenproblems Linear systems Check out mathtools. net for a vast list of libraries
 n n FORTRAN library of simple subroutine which can")
Basic Linear Algebra Subprograms (BLAS) n n FORTRAN library of simple subroutine which can be used to build more sophisticated LA programs (dates back to 1970’s) BLAS is divided into four types and three levels n Single, double, complex and double complex Level 1 (vector-vector operations) n Level 2 (matrix-vector operations) n Level 3 (matrix-matrix operations) Functions are prefixed with the type of the variables: n n n s, d, c, or z for single, double, complex, or double complex (z).

BLAS routines n Some of the BLAS 1 subprograms are: x. COPY - copy one vector to another n x. SWAP - swap two vectors n x. SCAL - scale a vector by a constant n x. AXPY - add a multiple of one vector to another n x. DOT - inner product n x. ASUM - 1 -norm of a vector n x. NRM 2 - 2 -norm of a vector n Ix. AMAX - find maximal entry in a vector n

Levels 2 & 3 n Some of the BLAS 2 subprograms are: n n n x. GEMV - general matrix-vector multiplication x. GER - general rank-1 update x. SYR 2 - symmetric rank-2 update x. TRSV - solve a triangular system of equations Some of the BLAS 3 subprograms are: n n x. GEMM - general matrix-matrix multiplication x. SYMM - symmetric matrix-matrix multiplication x. SYRK - symmetric rank-k update x. SYR 2 K - symmetric rank-2 k update

Tuning Advantages Linear algebra is always faster using an optimized library! PHi. PAC: C = A * B

BLAS and C n CBLAS is a C version of the libraries n n Available from Netlib However, you can still call FORTRAN versions from C n you will need to declare the involved BLAS routine as “extern” n extern void dgemv_(char *trans, int *m, int *n, double *alpha, double *a, int *lda, double *x, int *incx, double *beta, double *y, int *incy );

VSIPL www. vsipl. org n Vector Signal and Image Processing Library n Origins in defence contracts to produce an API for embedded programming n Developed in C, bindings for C++ under development n Main functionality n n Vector based frequency domain analysis routines

LAPACK n BLAS is used as the building block for the Linear Algegra Package, LAPACK n Website describing and distributing a portable version of the library: http: //www. netlib. org/lapack/ n Includes online manual n n n http: //www. netlib. org/lapack/lug/index. html Vendors frequently distribute their own assembly level optimized versions of the library (e. g. Intel MKL, and AMD ACML) This library consists of a set of higher level linear algebra functions with interface described at: n http: //www. netlib. org/lapack/individualroutines. html

LAPACK n There a very large number of linear algebra subroutines available in LAPACK n All follow a XYYZZZ format, where X denotes the datatype, YY the type of matrix and ZZZ describes the computation performed. For example: n dgetrf is used to compute LU factorizations of a matrix (d=double, ge=general, trf=triangular factorization) n dgetrs uses an LU factorization from dgetrf to solve a system n dgetri uses the LU above to compute the inverse of a matrix n dgesv essentially a combined call to dgetrf and dgetrs n dgeev computes the eigenvalues of a matrix.

Gnu Scientific Library n n http: //www. gnu. org/software/gsl/ GSL is a numerical library for C and C++ programmers Free software, available under GNU GPL The library provides a wide range of mathematical routines n n n e. g. random number generators special functions least-squares fitting There are over 1000 functions in total. The project was conceived in 1996 by Dr M. Galassi and Dr J. Theiler of Los Alamos National Laboratory.

GSL Features n The library uses an object-oriented design n n It is intended for ordinary scientific users n n Different algorithms can be plugged-in easily or changed at run-time without recompiling the program Users with a knowledge of C programming will be able to use the library quickly Interface is designed to be simple to link into very high-level languages, such as GNU Guile or Python Library is thread-safe Many of the routines are C “re”implementations of FORTRAN routines (e. g. FFTPACK) n Modern coding conventions and optimizations have been applied

Full list of functions Complex Numbers Roots of Polynomials Special Functions Vectors and Matrices Permutations Sorting BLAS Support Linear Algebra Eigensystems Fast Fourier Transforms Quadrature Random Numbers Quasi-Random Sequences Random Distributions Statistics Histograms N-Tuples Monte Carlo Integration Simulated Annealing Differential Equations Interpolation Numerical Differentiation Chebyshev Approximation Series Acceleration Discrete Hankel Transforms Root-Finding Minimization Least-Squares Fitting Physical Constants IEEE Floating-Point

Compiling and Linking n The library header files are installed in their own `gsl' directory n Include statements need `gsl/' directory prefix: #include <gsl/gsl_math. h> n Compile objects first: gcc -c myprog. c n Then link: gcc example. o -lgslcblas -lm

FFTW n n http: //www. fftw. org “Fastest Fourier Transform in the West” Authored by Frigo and Johnson at MIT C subroutine library for discrete Fourier transforms n n n Portable Multiple dimensions Arbitrary input sizes, real and complex transforms n n n n Discrete cosine and sine transforms Parallel versions available (both shared (pthreads) and distributed memory (MPI)) C and FORTRAN API Supports SIMD extensions (e. g. SSE) Self-tuning n n Small prime factors are best though Contains many different FFT algorithms and optimal one is chosen at runtime Has undergone a number of evolutions, and is now at version 3. 0 Won 1999 J. H. Wilkinson Prize for Numerical Software

Using FFTW n Need to include header files n n Must also link to libraries n n n -lfftw 3 -lm but may also need to specify path – will be installation dependent Having created arrays(“in” and “out”), must create a “plan” n n #include <fftw 3. h> or include “fftw 3. f” plan=fftw_plan_dft_1 d(N, in, out, FFTW_FORWARD, FFTW_ESTIMATE) call dfftw_plan_dft_1 d(plan, N, in, out, FFTW_FORWARD, FFTW_ESTIMATE) Precise plan routine will depend upon the FFT operation you wish to perform Call to plan allows system to evaluate architecture and transform and then optimize the algorithm to be used in the FFT Having created the plan the transform is executed by specifying fftw_execute(plan) See the fftw website for precise details

2 GHz Opteron speeds

2 GHz Opteron speeds

2 GHz Opteron speeds

Parallel FFTW: Shared Memory n FFTW includes both a pthreads based SMP library and can be compiled with Open. MP support on platforms where it is available n n Threaded version requires additional memory n n On HPCVL it is compiled with Open. MP support Call fftw_init_threads()before using the threaded version SMP parallel plans require knowledge of how many threads are going to be used Call fftw_plan_with_nthreads(nthreads) n Note that since plans are specific to the number of threads, if you change the number of threads you must create a new plan n When work is completed you must call fftw_cleanup_threads() n n deallocate memory for threads At linking stage must also include parallel library -lfftw 3_threads n Note only fftw_execute is using a parallel region n

Parallel FFTW: MPI n n Only available for older 2. x libraries which have a different API MPI data decomposition is “slab” based. n n For 3 d arrays this is potentially limiting – can only use L processors if you have an L 3 array However, communication costs are high so this is not often a significant barrier Uses MPI_Alltoall primitive which can occasionally lead to poor performance (depends on MPI implementation) Must enable support when FFTW is compiled and must also link to -lfftw_mpi
 { const int NX")
Example code #include <fftw_mpi. h> int main(int argc, char **argv) { const int NX =. . . , NY =. . . ; fftwnd_mpi_plan; fftw_complex *data; MPI_Init(&argc, &argv); plan = fftw 2 d_mpi_create_plan(MPI_COMM_WORLD, NX, NY, FFTW_FORWARD, FFTW_ESTIMATE); . . . allocate and initialize data. . . fftwnd_mpi(p, 1, data, NULL, FFTW_NORMAL_ORDER); . . . fftwnd_mpi_destroy_plan(plan); MPI_Finalize(); }
 Performance results on T 3 D for MPI transform (3 d, complex)")
(Old) Performance results on T 3 D for MPI transform (3 d, complex)
 n Developed in collaboration with Numerical Algorithms Group (NAG)")
AMD Core Math Library (ACML) n Developed in collaboration with Numerical Algorithms Group (NAG) n n Distribution via registration (but they have never sent me spam!) 32 bit (Athlon) and 64 bit (Opteron) versions Cannot be linked with Intel 8. 1 compiler though – turf war! n n Latest version = 3. 1 Forces you to use Intel MKL Exploits knowledge of cache architecture to improve execution speed
 n n n")
ACML Components: Linear Algebra, FFTs n Basic Linear Algebra Subroutines (BLAS) n n n Linear Algebra PACKage (LAPACK) § § n Must provide your own MPI implementation (see part 2) FFTs § n 28 (threaded) routines Use BLAS to perform complex operations Scalable LAPACK (Sca. LAPACK, MPI parallel LAPACK) also included § n Level 1 (vector-vector operations) Level 2 (matrix-vector operations) Level 3 (matrix-matrix operations) Plus routines for sparse vectors 1 D, 2 D, single and double precision plus all combinations of real-tocomplex etc C and FORTRAN APIs

Intel Math Kernel Library n n Version 9. 0 recently released Free for non-commercial use n n Students come under this banner, but faculty do not! Graduate students are becoming a grey area… Online support forum Library functions: n n n Linear Algebra - BLAS and LAPACK Linear Algebra - PARDISO Sparse Solver Discrete Fourier Transforms Vector Math Library Vector Statistical Library n random number generators

Cluster Math Kernel Library n Adds Sca. LAPACK and parallel BLAS routines to MKL Roughly 20% performance improvement over Netlib distribution of Sca. LAPACK.

PESSL, SCSL & CXML n SGI provide their SCSL library free n n PESSL is IBM’s parallel library n n n “Scientific Computing Software Library” Provides same basic features as ACML (linear algebra) Ported to Altix systems, but need to compare speed to Intel MKL before using “Parallel Engineering and Scientific Subroutine Library” Again, same basic features as ACML, and also includes random number generator CXML is Compaq’s library for the Alphaserver

Random Number Generators n Numerical recipes RAN 2 and RAN 3 are both reasonable RNGs n n Note RAN 3 does fail some of the more esoteric tests GSL library provides over 40 different generators Includes Knuth’s algorithms n Mersenne Twister as well n

Mersenne Twister n n n http: //www. math. sci. hiroshima-u. ac. jp/~m-mat/MT/emt. html Developed by Matsumoto and Nishimura Period is 2^19937 -1 (106000) n n Fast generation n n C rand() has been substituted, and now there are no much difference in speed Efficient use of the memory n n 623 -dimensional equidistribution property is assured The implemented C-code mt 19937. c consumes only 624 words of working area Currently the generator of choice for most problems (except crypto)

Summary Part 1 n Libraries offer a number of benefits Optimization n Robustness n Portability n Time to solution improvements n

Part 2: Parallel Libraries n n n BLACS ACTS collection Sca. LAPACK

BLACS Basic Linear Algebra Communication Subprograms n Conceptual aid in design and coding (design tool) n Associate widely known mnemonic names with communication n Improved readability and provides standard interface n “Self documentation” n

BLACS data decomposition 0 1 2 0 0 1 2 1 3 4 5 2 6 7 8 Communication Modes: All processes in row All processes in column All grid processes 2 d processor grid Types of BLACS routines: point-to-point communication, broadcast, combine operations and support routines.
matrix from")
Communication Routines n Send/Receive n n _ denotes datatype: n n Send (sub)matrix from one process to another: _xx. SD 2 D(ICTXT, [UPLO, DIAG], M, N, A, LDA, RDEST, CDEST) _xx. RV 2 D(ICTXT, [UPLO, DIAG], M, N, A, LDA, RSRC, CSRC) I (integer), S (single), D (double), C (complex), Z (double complex) xx denotes matrix type n GE = general, TR=trapezoidal
 IF( MYROW. EQ.")
Point-to-Point example CALL BLACS_GRIDINFO( ICTXT, NPROW, NPCOL, & MYROW, MYCOL ) IF( MYROW. EQ. 0. AND. MYCOL. EQ. 0 ) THEN CALL DGESD 2 D( ICTXT, 5, 1, X, 5, 1, 0 ) ELSE IF( MYROW. EQ. 1. AND. MYCOL. EQ. 0 ) THEN CALL DGERV 2 D( ICTXT, 5, 1, Y, 5, 0, 0 ) END IF

Contexts n n The concept of a communicator is imbedded within BLACS as a “context” Contexts are thus the mechanism by which you: n n Create arbitrary groups of processes upon which to execute Create an indeterminate number of overlapping or disjoint grids Isolate each grid so that grids do not interfere with each other Initialization routines return a context (integer) which is then passed to the communication routines n Equivalent to specifying COMM in MPI calls

ID less communication n Messages with BLACS are tagless n n Why is this an issue? n n Generated internally within the library If tags are not unique it is possible to create not deterministic behaviour (have race conditions on message arrival) BLACS allows the user to specify what range of IDs the BLACS can use n This ensures it can be used with other packages

ACTS Collection n “Advanced Compu. Tational Software” n n US Department of Energy program, run in conjunction with NSF and DARPA n n n n Set of software tools Extended support for experimental software Provide technical support (acts-support@nersc. gov) Maintain ACTS information center (http: //acts. nersc. gov) Coordinate efforts with US supercomputing centers Enable large scale scientific applications Educate and train Unclear how much support issue extends beyond US borders, although there are registered users across the globe

ACTS is a guided project

ACTS Motivation Large Scientific Codes: New Architecture: • May or may not need rerewriting New Developments: • Difficult to compare New Architecture: • Extensive re-rewriting New or extended Physics: • Extensive re-rewriting or increase overhead A Common Programming Practice Algorithmic Implementations Application Data Layout Control I/O Tuned and machine Dependent modules New Architecture: • Minimal to Extensive rewriting New Architecture or S/W • Extensive tuning • May require new programming paradigms • Difficult to maintain!
 Approach USER's APPLICATION CODE (Main Control) AVAILABLE Application Data Layout LIBRARIES")
The ACTS (“ideal”) Approach USER's APPLICATION CODE (Main Control) AVAILABLE Application Data Layout LIBRARIES & PACKAGES AVAILABLE Algorithmic Implementations LIBRARIES & PACKAGES Tuned and machine Dependent modules AVAILABLE I/O LIBRARIES

ACTS Tools and functions Category Tool Functionalities Aztec Algorithms for the iterative solution of large sparse linear systems. Hypre Algorithms for the iterative solution of large sparse linear systems, intuitive grid-centric interfaces, and dynamic configuration of parameters. PETSc Tools for the solution of PDEs that require solving large-scale, sparse linear and nonlinear systems of equations. OPT++ Object-oriented nonlinear optimization package. SUNDIALS Solvers for the solution of systems of ordinary differential equations, nonlinear algebraic equations, and differential-algebraic equations. Sca. LAPACK Library of high performance dense linear algebra routines for distributed-memory message-passing. Super. LU General-purpose library for the direct solution of large, sparse, nonsymmetric systems of linear equations. TAO Large-scale optimization software, including nonlinear least squares, unconstrained minimization, bound constrained optimization, and general nonlinear optimization. Global Arrays Library for writing parallel programs that use large arrays distributed across processing nodes and that offers a sharedmemory view of distributed arrays. Overture Object-Oriented tools for solving computational fluid dynamics and combustion problems in complex geometries. CUMULVS Framework that enables programmers to incorporate fault-tolerance, interactive visualization and computational steering into existing parallel programs Globus Services for the creation of computational Grids and tools with which applications can be developed to access the Grid. PAWS Framework for coupling parallel applications within a component-like model. SILOON Tools and run-time support for building easy-to-use external interfaces to existing numerical codes. TAU Set of tools for analyzing the performance of C, C++, Fortran and Java programs. ATLAS and PHi. PAC Tools for the automatic generation of optimized numerical software for modern computer architectures and compilers. PETE Extensible implementation of the expression template technique (C++ technique for passing expressions as function arguments). Numerical Code Development Code Execution Library Development

ATLAS n Automatically Tuned Linear Algebra Software n n Provides a subset of both BLAS and LAPACK functionality n n Another University of Tennessee project! Largely an unsupported project though http: //math-atlas. sourceforge. net/ Provided foundation for work on BLAS and LAPACK in AMDs ACML Takes optimization step further by giving the computer itself possibilities for optimization at compile time n n “AEOS”: Automated Empirical Optimization of Software Similar motivation as FFTW
 900 Mhz Itanium")
ATLAS Benchmarks DGEMM performance: ARCH ATLAS COMP % Peak PEAK (Gflop) 900 Mhz Itanium 2 3. 6. 0 icc 90% 3. 6 1. 6 Ghz Opteron 3. 6. 0 gcc 88% 3. 2 1062 Mhz Ultra. SPARC III 3. 7. 8 gcc 3. 3 82% 2. 124 600 Mhz Athlon 3. 5. 7 gcc 2. 95. 3 80% 1. 2 2. 8 Ghz Pentium 4 E 3. 7. 3 gcc 3. 3. 2 77% 5. 6 2. 6 Ghz Pentium 4 3. 6. 0 gcc 77% 5. 2 1 Ghz Pentium. III 3. 7. 7 gcc 2. 95. 3 76% 1 1 Ghz Efficieon 3. 7. 7 gcc 3. 2 60% 2

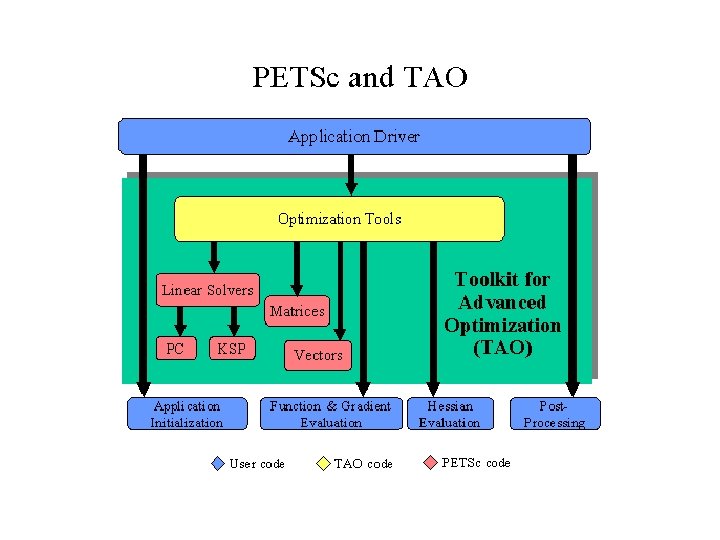
PETSc n Portable, Extensible Toolkit for Scientific Computation n Suite of data structures and routines for the scalable (parallel) solution of PDEs n n n http: //www-unix. mcs. anl. gov/petsc-as/ Argonne lab development Intended for use in large-scale application projects Not a black box solution though Easily interfaces with solvers written in C, FORTRAN and C++ All components are designed to be interoperable Works in distributed memory environment using MPI

Levels of Abstraction in Mathematical Software n Application-specific interface n n Programmer manipulates objects associated with the application High-level mathematics interface n Programmer manipulates mathematical objects n n Algorithmic and discrete mathematics interface n PETSc emphasis Programmer manipulates mathematical objects n n Sparse matrices, nonlinear equations Programmer manipulates algorithmic objects n n Weak forms, boundary conditions, meshes Solvers Low-level computational kernels n n BLAS-type operations FFT

Features • • PC ao r m ap l l l e et l e vd eo cc t u om r e sn • t s ac

Structure of PETSc – Layered Approach PETSc PDE Application Codes ODE Integrators Visualization Nonlinear Solvers Interface Linear Solvers Preconditioners + Krylov Methods Object-Oriented Grid Matrices, Vectors, Indices Management Profiling Interface Computation and Communication Kernels MPI, MPI-IO, BLAS, LAPACK

Functionality example: selected vector operations
 { Vec")
A Complete PETSc Program #include petscvec. h int main(int argc, char **argv) { Vec x; int n = 20, ierr; Petsc. Truth flg; Petsc. Scalar one = 1. 0, dot; } Petsc. Initialize(&argc, &argv, 0, 0); Petsc. Options. Get. Int(PETSC_NULL, "-n", &n, PETSC_NULL); Vec. Create(PETSC_COMM_WORLD, &x); Vec. Set. Sizes(x, PETSC_DECIDE, n); Vec. Set. From. Options(x); Vec. Set(&one, x); Vec. Dot(x, x, &dot); Petsc. Printf(PETSC_COMM_WORLD, "Vector length %dn", (int)dot); Vec. Destroy(x); Petsc. Finalize(); return 0;

TAO n Toolkit for Advanced Optimization n Aimed at the solution of large-scale optimization problems on high-performance architectures n n http: //www-unix. mcs. anl. gov/tao/ Another Argonne project Suitable for both single-processor and massively-parallel architecture Object oriented approach n Interoperable with other toolkits (PETSc for example)

Functionality Systems of nonlinear equations n Nonlinear least squares n Bound-constrained optimization n Linear and quadratic programming n Nonlinearly constrained optimization n Combinatorial optimization n Stochastic optimization n Global optimization n

Example program TAO tao; /* optimization solver */ mat H; /* Hessian matrix */ vec x, g; /* solution and gradient vectors */ double f; /* function to minimize */ int n; /* number of variables */ Application. Ctx usercontext; /* user-defined context */ Mat. Create(MPI_COMM_WORLD, n, n, &H); Vec. Create(MPI_COMM_WORLD, n, &x); Vec. Duplicate(x, &g); Tao. Create(MPI_COMM_WORLD, &tao); Tao. Set. Function(tao, x, Evaluate. Function, usercontext); Tao. Set. Gradient(tao, g, Evaluate. Gradient, usercontext); Tao. Set. Hessian(tao, H, Evaluate. Hessian, usercontext); Tao. Solve(tao); Tao. Destroy(tao);

Sca. LAPACK n n Scalable LAPACK Development team n n University of Tennessee University of California at Berkeley ORNL, Rice U. , UCLA, UIUC etc. Support in Commercial Packages n n n NAG Parallel Library (including Intel MKL and AMD ACML) IBM PESSL CRAY Scientific Library and SGI SCSL VNI IMSL Fujitsu, HP/Convex, Hitachi, NEC

Important details n Web page http: //www. netlib. org/s calapack n n n Includes Sca. LAPACK User’s Guide Language : Fortran Dense Matrix Problem Solvers n n n Linear Equations Least Squares Eigenvalue Package dependencies

Components of the API n Drivers n n Computational Components n n Performs Tasks: LU factorization, etc. Auxiliary Routines n n Solves a Complete Problem Scaling, Matrix Norm, etc. Matrix Redistribution/Copy Routine n Matrix on PE grid 1 -> Matrix on PE grid 2
 n LAPACK names with P prefix PXYYZZZ Computation Performed Matrix")
API (cont. . ) n LAPACK names with P prefix PXYYZZZ Computation Performed Matrix Type Data Types Data Type real X S double cmplx dble cmplx D C Z

TAU n Tuning and Analysis Utilities University of Oregon development n http: //www. cs. uoregon. edu/research/paracomp/ta u/tautools/ n n Program and performance analysis tool framework for high-performance parallel and distributed computing n TAU provides a suite of tools analysis of C, C++, FORTRAN 77/90, Python, High Performance FORTRAN, and Java programs

Useage n n n Instrument the program by inserting TAU macros into the program (this can be done automatically). Run the program. Files containing information about the program performance are automatically generated. View the results with TAU's pprof, the TAU visualizer racy (or paraprof), or a third-party visualizer (such as VAMPIR)

pprof

Additional facilities n TAU collects much more information than what is available through prof or gprof, the standard Unix utilities. Also available through TAU are: n n n n n Per-process, per-thread and per-host information (supports pthreads) Inclusive and exclusive function times Profiling groups that allow you to organize data collection Access to hardware counters on some systems Per-class and per-instance information Separate data for each template instantiation Start/stop timers for profiling arbitrary sections of code Support for collection of statistics on user-defined events TAU is designed so that when you turn off profiling (by disabling TAU macros) there is no overhead

CACTUS n n http: //www. cactuscode. org/ Developed as response to needs of large scale projects (initially developed for General Relativity calculations which have a large computation to communication ratio) Numerical/computational infrastructure to solve PDE’s Freely available, Open Source community framework n n n Abstraction: Cactus Flesh provides API for virtually all CS type operations n n n Cactus Divided in “Flesh” (core) and “Thorns” (modules or collections of subroutines) Multilingual: User apps Fortran, C, C++; automated interface between them Storage, parallelization, communication between processors, etc Interpolation, Reduction IO (traditional, socket based, remote viz and steering…) Checkpointing, coordinates “Grid Computing”: Cactus team and many collaborators worldwide, especially NCSA, Argonne/Chicago, LBL

Modularity of Cactus. . . Sub-app Legacy App 2 Application 1 User selects desired functionality… Code created. . . Application 2 . . . Abstractions. . . Cactus Flesh AMR (Gr. ACE, etc) MDS/Remote Spawn Symbolic Manip App Unstructured. . . MPI layer 3 I/O layer 2 Globus Metacomputing Services Remote Steer 2

Cactus & the Grid Cactus Application Thorns Distribution information hidden from programmer Initial data, Evolution, Analysis, etc Grid Aware Application Thorns Drivers for parallelism, IO, communication, data mapping PUGH: parallelism via MPI (MPICH-G 2, grid enabled message passing library) Single Proc Standard MPI Grid Enabled Communication Library MPICH-G 2 implementation of MPI, can run MPI programs across heterogenous computing resources

The Flesh n n n Abstract API n evolve the same PDE with unigrid, AMR (MPI or shared memory, etc) without having to change any of the application code. Interfaces n set of data structures that a thorn exports to the world (global), to its friends (protected) and to nobody (private) and how these are inherited. Implementations n Different thorns may implement e. g. the evolution of the same PDE and we select the one we want at runtime. Scheduling n call in a certain order the routines of every thorn and how to handle their interdependencies. Parameters n many types of parameters and all of their essential consistency checked before running

Summary Part 2 n ACTS is a collection of software for HPC that includes a number of useful tools n n Numerical libraries Code development software Profiling software Sca. LAPACK extends LAPACK to distributed memory architectures n Built on top of PBLAS which uses BLACS

Part 3: Odds and ends Netlib and other useful websites n HPL library n VTK n

Netlib n The Netlib repository contains n n freely available software, documents, databases of interest to the numerical & scientific computing communities The repository is maintained by n n The collection is mirrored at several sites around the world n n AT&T Bell Laboratories University of Tennessee Oak Ridge National Laboratory Kept synchronized Effective search engine to help locate software of potential use

High Performance LINPACK n n Portable and freely available implementation of the LINPACK Benchmark – used for Top 500 ranking Developed at UTK Innovative Computing Laboratory n n HPL solves a (random) dense linear system in double precision (64 bits) arithmetic on distributed-memory computers n n n A. Petitet, R. C. Whaley, J. Dongarra, A. Cleary Requires MPI 1. 1 be installed Also requires an implementation of either the BLAS or the Vector Signal Image Processing Library VSIPL Provides a testing and timing program n Quantifies the accuracy of the obtained solution as well as the time it took to compute it
")
Rice University HPC software n Center for High Performance Software Research (Hi. Per. Soft) established in October 1998 n http: //www. hipersoft. rice. edu/ n n Rice has a strong history of innovative HPC tools n HPCToolkit is an open-source suite of multiplatform tools for profile-based performance analysis of applications

HPCtoolkit n The toolkit components include: n n n n hpcrun: a tool for profiling executions of unmodified application binaries using statistical sampling of hardware performance counters. hpcprof & xprof: tools for interpeting sample-based execution profiles and relating them back to program source lines. bloop: a tool for analyzing application binaries to recover program structure; namely, to identify where loops are present and what program source lines they contain. hpcview: a tool for correlating program structure information, multiple samplebased performance profiles, and program source code to produce a performance database. hpcviewer: a java-based GUI for exploring databases consisting of performance information correlated with program source. Supported platforms: Pentium+Linux, Opteron+Linux, Athlon+Linux, Itanium+Linux, Alpha+Tru 64 and MIPS+Irix. HPCToolkit is open-source software released with a BSD-like license.

CALGO n Collected algorithms of the ACM n n All software is refereed for originality, accuracy, robustness, completeness, portability, and lasting value n n http: //www. acm. org/pubs/calgo/ Use of ACM Algorithms is subject to the ACM Software Copyright and License Agreement Available on CD

MGnet www. mgnet. org n Site devoted to Multi-grid and adaptive mesh refinement algorithms n n n Run by Craig Douglas Has links to a number of packages for multigrid Some are public domain n Others are copyrighted n n Very useful resource for MG methods

NCSA n National Center for Supercomputing Applications n n www. ncsa. uiuc. edu Their application repository is a very useful guide to what software is available in a given field

NHSE n National HPC Software Exchange n www. nhse. org Numerous reports, libraries n Unfortunately has been suspended in light of a lack of funding (2004) n Access to meta-repository is still available (and links there in) n

VTK n The Visualization Toolkit n n Portable open-source software system for 3 D computer graphics, image processing, and visualization n n http: //public. kitware. com/VTK/what-is-vtk. php Object-oriented approach VTK is at a higher level of abstraction than rendering libraries like Open. GL VTK applications can be written directly in C++, Tcl, Java, or Python Large user community n Many source code contributions

Summary Part 3 n When looking for a library first place to stop is netlib!
 Productivity crisis, future of HPC")
Next lecture n (Last lecture!) Productivity crisis, future of HPC
6deffbccbc837d9a022c5bed1b467f48.ppt