c7f247741bb97e778944a91857284b77.ppt
- Количество слайдов: 74



harnessing the Power of communities: mo. By & Beyond Mark Wilkinson PI Bioinformatics i. CAPTURE Centre for Cardiovascular and Pulmonary Research Assistant Professor Dept. of Medical Genetics UBC, Vancouver

A brief history of Bio. Moby • Model Organism Bring Your own Database Interface Conference, Sept, 2001 (MOBY-DIC) • May 21, 2002 – Genome Canada Platform Award • May 25, 2002 – API Version 0. 1 deployed, including the messaging layer that still exists today • July 18, 2002 – first Moby Client released (now gbrowse_moby, part of gbrowse from GMOD) • June 9, 2003 – API Version 0. 5 deployed • Currently, the API is at version 0. 86; version 1. 0 API in preparation for release end of November

What does Bio. Moby do?

The MOBY-S Plan • • • Create an ontology of bioinformatics data-types Define a serialization of this ontology (data syntax) Create an open API over this ontology Define Web Service inputs and outputs v. v. Ontology Register Services in an ontology-aware Registry • Machines can find an appropriate service • Machines can execute that service unattended • Ontology is community-extensible

Overview of MOBY-S Transactions MOBY hosts & services Alignment Sequence Gene names Sequence Align Express. Phylogeny Protein Primers Alleles … MOBY Central

MOBY-S in detail • MOBY-S Data typing system: Semantic Type • MOBY-S Data typing system: Syntactic Type

MOBY-S in detail • MOBY-S Data typing system: Semantic Type • MOBY-S Data typing system: Syntactic Type
 • Any identifiable piece of data is an “entity” •")
Moby Namespaces (from GO) • Any identifiable piece of data is an “entity” • Identifiers for these entities fall under “Namespaces” – NCBI has gi numbers (gi Namespace) – GO Terms have accession numbers (GO Namespace) • Namespaces indicate data’s semantic type. – GO: 0003476 a Gene Ontology Term – gi|163483 a Gen. Bank record • Namespace + ID precisely specifies a data “entity” • This differs from an LSID in that our identifiers ARE NOT OPAQUE – they are semantically rich

MOBY-S in detail • MOBY-S Data typing system: Semantic Type • MOBY-S Data typing system: Syntactic Type

The MOBY-S Object Ontology • Syntactic types are defined by a GO-like ontology – Data Class name at each node – Edges define the relationships between Classes – GO used as a model because of its familiarity in the community Edge • Edges define of three relationships node – IS A • Inheritance relationship • All properties of the parent are present in the child – HAS A • Container relationship of ‘exactly 1’ – HAS • Container relationship with ‘ 1 or more’ node

The Simplest Moby Data-Type <Object namespace=‘NCBI_gi’ id=‘ 111076’/> Object The combination of a namespace and an identifier within that namespace uniquely identify a data entity, not its location(s), nor its representation

A Primitive Data-type ISA Date. Time ISA Float ISA Integer Object ISA String <Integer namespace=‘’ id=‘’>38</Integer>

A Derived Data-Type <Virtual. Sequence namespace=‘NCBI_gi’ id=‘ 111076’> <Integer namespace=‘’ id=‘’ article. Name=“length”>38</Integer> </ Virtual. Sequence > ISA Object ISA Integer HASA String Virtual Sequence

A Derived Data-Type <Generic. Sequence namespace=‘NCBI_gi’ id=‘ 111076’> <Integer namespace=‘’ id=‘’ article. Name=“length”>38</Integer> <String namespace=‘’ id=‘’ article. Name=“Sequence. String”> ATGATGATAGAGGGCCCGGCGCGCGC </String> </ Generic. Sequence > ISA Object ISA Integer HASA String Virtual Sequence ISA Generic Sequence

A Derived Data-Type <DNASequence namespace=‘NCBI_gi’ id=‘ 111076’> <Integer namespace=‘’ id=‘’ article. Name=“length”>38</Integer> <String namespace=‘’ id=‘’ article. Name=“Sequence. String”> ATGATGATAGAGGGCCCGGCGCGCGC </String> </ DNASequence > ISA Object ISA Integer HASA String Virtual Sequence ISA Generic Sequence ISA DNA Sequence

Legacy file formats • Containing “String” allows us to define ontological classes that represent legacy data types (e. g. the 20 existing sequence formats!) <NCBI_Blast_Report namespace=‘NCBI_gi’ id=‘ 115325’> <String namespace=‘’ id=‘’ article. Name=‘content’> TBLASTN 2. 0. 4 [Feb-24 -1998] Reference: Altschul, Stephen F. , Thomas L. Madden, Alejandro A. Schä ffer, Jinghui Zhang, Zheng Zhang, Webb Miller, and David J. Lipman (1997), "Gapped BLAST and PSI-BLAST: a new generation of protein database search programs", Nucleic Acids Res. 25: 3389 -3402. Query= gi|1401126 (504 letters) Database: Non-redundant Gen. Bank+EMBL+DDBJ+PDB sequences 336, 723 sequences; 677, 679, 054 total letters Searchingdone Sequences producing significant alignments: Score (bits) E Value gb|U 49928|HSU 49928 Homo sapiens TAK 1 binding protein (TAB 1) m. RNA. . . 1009 0. 0 emb|Z 36985|PTPP 2 CMR P. tetraurelia m. RNA for protein phosphatase t. . . 58 4 e-07 emb|X 77116|ATMRABI 1 A. thaliana m. RNA for ABI 1 protein 53 1 e-05 </String> </NCBI_Blast_Report>

Binaries – pictures, movies • We base 64 encode binaries, and then define a hierarchy of data classes that Contain String • base 64_encoded_jpeg ISA text/base 64 ISA text/plain HASA String <base 64_encoded_jpeg namespace=‘TAIR_image’ id=‘ 3343532’> <String namespace=‘’ id=‘’ article. Name=‘content’> MIAGCSq. GSIb 3 DQEHAq. CAMIACAQEx. Cz. AJBg. Ur. Dg. MCGg. UAMIAGCSq. GSIb 3 DQEHAQAAo. IIJQDCC Av 4 wgg. Jno. AMCAQICAwh. H 9 j. ANBgkqhki. G 9 w 0 BAQQFADCBkj. ELMAk. GA 1 UEBh. MCWk. Ex. FTATBg. NV BAg. TDFdlc 3 Rlcm 4 g. Q 2 Fw. ZTESMBAGA 1 UEBx. MJQ 2 Fw. ZSBUb 3 du. MQ 8 w. DQYDVQQKEw. ZUa. GF 3 d. GUx HTAb. Bg. NVBAs. TFENlcn. Rp. Zmlj. YXRl. IFNlcn. Zp. Y 2 Vz. MSgw. Jg. YDVQQDEx 9 QZXJzb 25 hb. CBGcm. Vl b. WFpb. CBSU 0 Eg. Mj. Aw. MC 44 Lj. Mw. MB 4 XDTAy. MDkx. NTIx. MDkw. MVo. XDTAz. MDkx. NTIx. MDkw. MVow. Qj. Ef MB 0 GA 1 UEAx. MWVGhhd 3 Rl. IEZy. ZWVt. YWls. IE 1 lb. WJlcj. Ef. MB 0 GCSq. GSIb 3 DQEJARYQampr. M 0 Bt </String> </base 64_encoded_jpeg>

Extending legacy data types • • With legacy data-types defined, we can extend them as we see fit annotated_jpeg ISA base 64_encoded_jpeg annotated_jpeg HASA 2 D_Coordinate_set annotated_jpeg HASA Description <annotated_jpeg namespace=‘TAIR_Image’ id=‘ 3343532’> <2 D_Coordinate_set namespace=‘’ id=‘’ article. Name=“pixel. Coordinates”> <Integer namespace=‘’ id=‘’ article. Name=“x_coordinate”>3554</Integer> <Integer namespace=‘’ id=‘’ article. Name=“y_coordinate”>663</Integer> </2 D_Coordinate_set> <String namespace=‘’ id=‘’ article. Name=“Description”> This is the phenotype of a ufo-1 mutant under long daylength, 16’C </String> <String namespace=‘’ id=‘’ article. Name=“content”> MIAGCSq. GSIb 3 DQEHAq. CAMIACAQEx. Cz. AJBg. Ur. Dg. MCGg. UAMIAGCSq. GSIb 3 DQEHAQAAo. IIJQDCC Av 4 wgg. Jno. AMCAQICAwh. H 9 j. ANBgkqhki. G 9 w 0 BAQQFADCBkj. ELMAk. GA 1 UEBh. MCWk. Ex. FTATBg. NV </String> </annotated_jpeg>

The same object… annotated_jpeg ISA base 64_encoded_jpeg HASA 2 D_Coordinate_set HASA Description <annotated_jpeg namespace=‘TAIR_Image’ id=‘ 3343532’> <2 D_Coordinate_set namespace=‘’ id=‘’ article. Name=“pixel. Coordinates”> <Integer namespace=‘’ id=‘’ article. Name=“x_coordinate”> 3554 </Integer> <Integer namespace=‘’ id=‘’ article. Name=“y_coordinate”> 663 </Integer> </2 D_Coordinate_set> <String namespace=‘’ id=‘’ article. Name=“Description”> This is the phenotype of a ufo-1 mutant under long daylength, 16’C </String> <String namespace=‘’ id=‘’ article. Name=“content”> MIAGCSq. GSIb 3 DQEHAq. CAMIACAQEx. Cz. AJBg. Ur. Dg. MCGg. UAMIAGCSq. GSIb 3 DQEHAQAAo. IIJQDCC Av 4 wgg. Jno. AMCAQICAwh. H 9 j. ANBgkqhki. G 9 w 0 BAQQFADCBkj. ELMAk. GA 1 UEBh. MCWk. Ex. FTATBg. NV </String> </annotated_jpeg>

The same object… annotated_jpeg ISA base 64_encoded_jpeg HASA 2 D_Coordinate_set HASA Description <annotated_jpeg namespace=‘TAIR_Image’ id=‘ 3343532’> <Cross. Reference> <Object namespace=“TAIR_Allele” id=“ufo-1”/> </Cross. Reference> <2 D_Coordinate_set namespace=‘’ id=‘’ article. Name=“pixel. Coordinates”> <Cross. Reference> <Object namespace=‘TAIR_Tissue’ id=‘ 122’/> </Cross. Reference> <Integer namespace=‘’ id=‘’ article. Name=“x_coordinate”> 3554 </Integer> <Integer namespace=‘’ id=‘’ article. Name=“y_coordinate”> 663 </Integer> </2 D_Coordinate_set> <String namespace=‘’ id=‘’ article. Name=“Description”> This is the phenotype of a ufo-1 mutant under long daylength, 16’C </String> MIAGCSq. GSIb 3 DQEHAq. CAMIACAQEx. Cz. AJBg. Ur. Dg. MCGg. UAMIAGCSq. GSIb 3 DQEHAQAAo. IIJQDCC Av 4 wgg. Jno. AMCAQICAwh. H 9 j. ANBgkqhki. G 9 w 0 BAQQFADCBkj. ELMAk. GA 1 UEBh. MCWk. Ex. FTATBg. NV

How to think about MOBY Objects and Namespaces Data perspective X Data perspective Y Object X Object Y Record in “gi” Namespace (Genbank record)

Why define Objects in an ontology? Bioinformatics service providers are not all experienced programmers The Moby Object Ontology provides an environment within which “naïve” service providers can create new complex data-types WITHOUT generating new flatfile formats, and without having to understand XML Schema Minimize future heterogeneity between new data-types to improve interoperability without requiring endless schema-to-schema mapping efforts.

The Object Ontology Defines an XML Schema • Object Ontology terms have “meaningful” names, but this is for human intuition only – DNA Sequence, Annotated_GIF • Object Ontology does not define the biological meaning, however it does define how every XML tag should be interpreted, therefore superior to pure XML/XML-Schema solutions • It does define the representation – SYNTAX

The Object Ontology Defines an XML Schema • The position of an ontology node precisely defines the syntax by which that node will be represented • End-users can define new data-types without having to write XML Schema! – This was an important aim of the project • A machine can “understand” the structure of any incoming message by querying its ontological type

A portion of the MOBY-S Object Ontology …community-built!
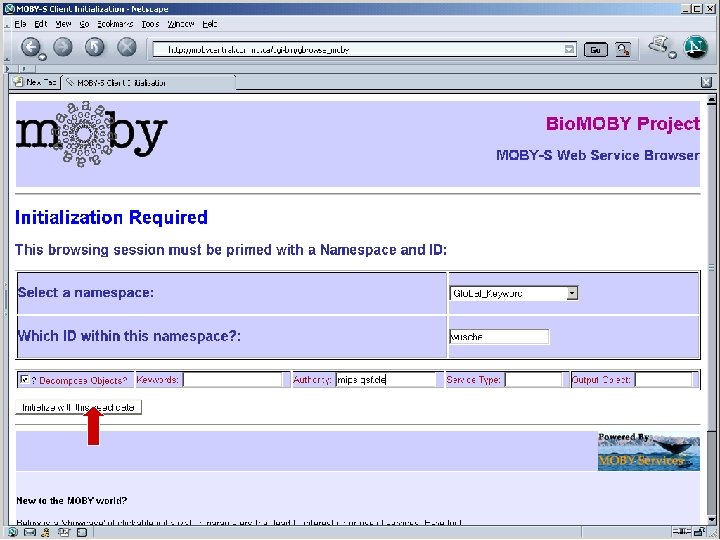
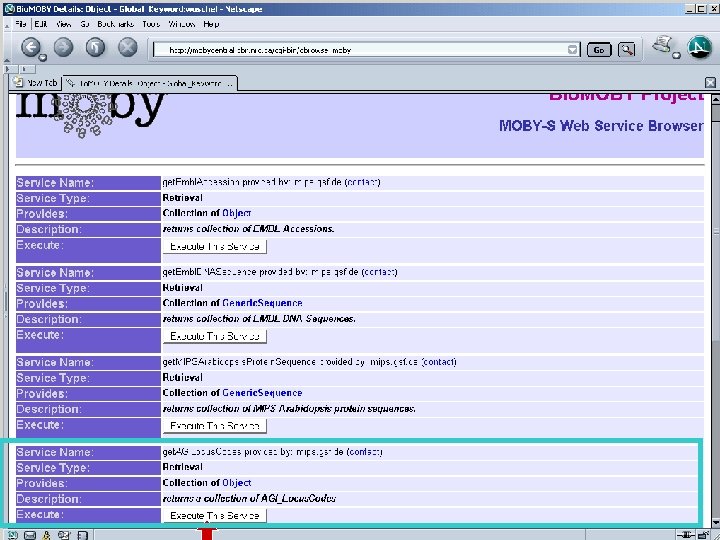
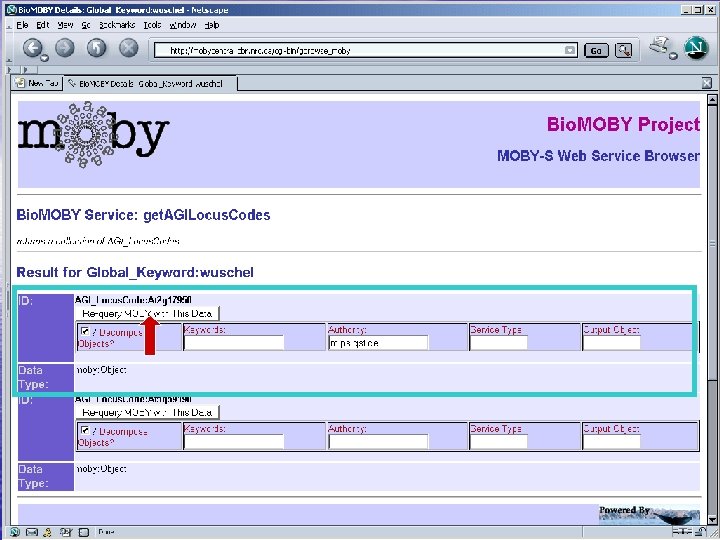
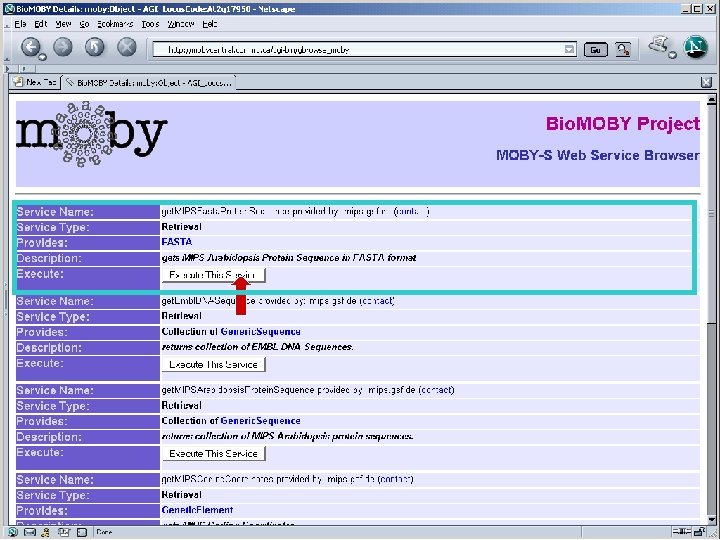
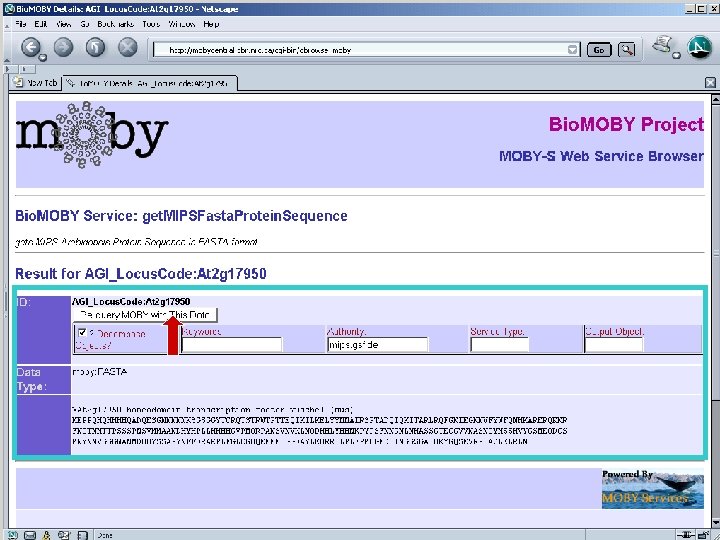
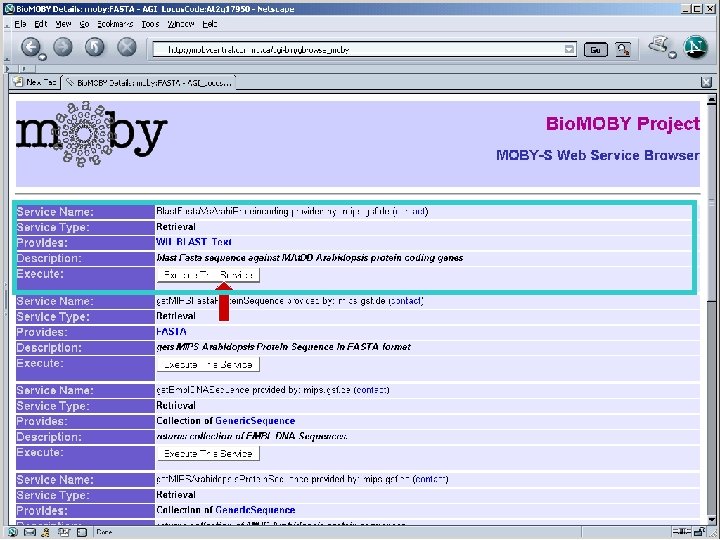
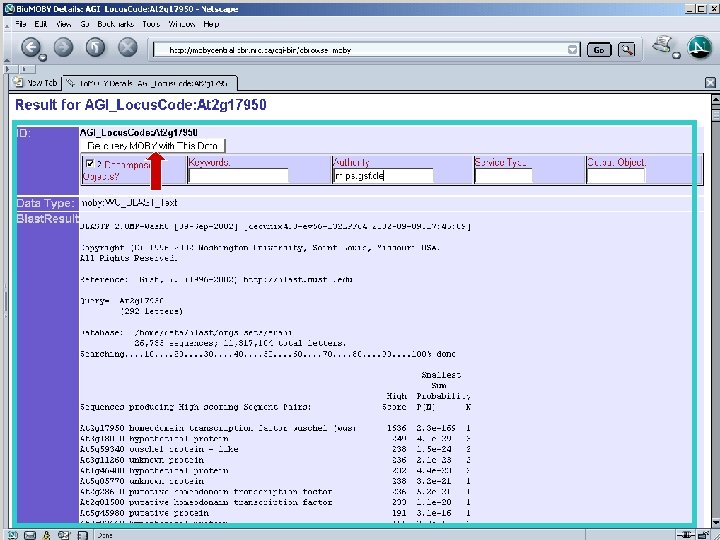
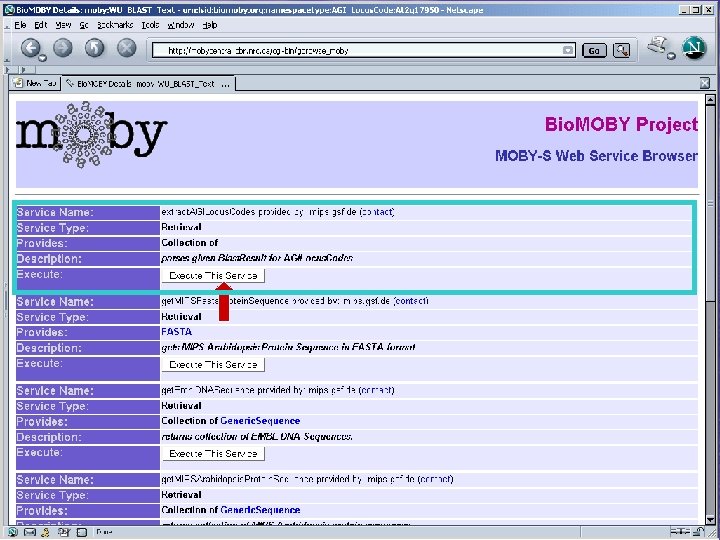

Pipeline discovery “on the fly” • No explicit coordination between providers • Run-time discovery of appropriate Services • Automated execution of services • This is happening without semantics – Syntax only… well… almost… : -)

Conclusions from the Behaviour of this Simple Browser • Service discovery is a semantic problem • However interoperability is not • Data integration is still a problem – both syntactic and semantic - and we’ve just made that problem worse! – SYNTAX IS NOT THE PROBLEM!!!!

• Some “political” details about Bio. Moby as we are coming to the end of the current Genome Canada funding period and are trying to get renewal… hint, if there any GC external reviewers in the audience!
: 236 • Objects (data syntaxes): 161 • Service")
Moby: Breadth • Namespaces (semantic datatypes): 236 • Objects (data syntaxes): 161 • Service Types (analytical categories): 18 • Service Instances: 401 (+ ~200 Soaplab) – Hundreds more in “boutique” Moby registries serving specialized communities worldwide – All continents except Antarctica host Moby services
 •")
Moby: Impact • Mailing list count 175 members (84 on developers mailing list) • Google Scholar – ‘Bio. MOBY’ 147 – Citations of 2002 Bio. MOBY paper 72

Moby: Developer Activity • MOBY-DIC Chapter 7 meeting – Vancouver, May 6 -8, 2005 • 23 Developers attending – – – Asia USA Canada Germany Spain France • Mapped-out the route to the final 1. 0 version of the API

Moby Registry Activity Pla. Net implements own MOBY Central
 • EBI")
Moby: Exemplar Users • Pla. Net consortium (7+ sites, 100 -130 services) • EBI – SOAPLAB – my. Grid • Generation Challenge Programme of the CGIAR (18+ sites) • Genome Espania uses MOBY for much of the bioinformatics service provision in the GE Bioinformatics Platform
 • Browser-style client • Ahab & Ishmael (B")
Moby: Clients • Gbrowse_moby (M Wilkinson) • Browser-style client • Ahab & Ishmael (B Good, M Wilkinson) • “BLAST” & Semantic Web style clients • Pla. Net Locus_View (H Schoof, R Ernst) • Aggregator-style client • Blue-Jay (P Gordon) and Rat Genome Database prototype (S Twigger) • Menu-style clients • MOBY Graphs (M Senger) • Auto-workflow discovery tool • Taverna (T Oinn, M Senger, E Kawas), and MOWserv (INB, Spain) • Workflow builder/publisher/execution client • Enhanced support for MOBY currently being built • Eclipse plugins… etc…

Taverna Workbench Tom Oinn and Martin Senger my. Grid Project

MOWServ Web interface to the Spanish Instituto Nacional de Bioinformatica MOBY Central installation

INB Collaboration MOBY Enhancements • The INB has made several additions to the MOBY API – Detailed error reporting – Asynchronous service invocation • These will become part of the official API in the coming year.

Future plans for Moby • “Decentralization” and enrichment of the registry through distributed RDF-based service instance annotations + LSID resolution – Complete! • Mirroring of registries • RDF-based messaging – Bio. Moby pre-dates commodity Semantic Web tools like RDF/OWL by a couple of years…

Future plans for Moby • Mirroring of Services • Enhanced registry usage metadata capture • Ontological markup of Object Ontology Terms • Better support for Web Service tooling if possible – Unfortunately, W 3 C XML Schema is unable to describe MOBY messages… • Collaboration with the GBIF/DIGi. R community – biodiversity information served through MOBY

A weakness of MOBY Automated service discovery is fatally flawed due to insufficiently rich semantics…

The problem with Moby Chickens go in; Pies come out!

The problem with Moby What sort o’ pies?

The problem with Moby Apple!

The MOBY-S Service Ontology • A simple ISA hierarchy… too simple! • Primitive types include: – Analysis – Parsing – Registration – Retrieval – Resolution – Conversion – Rendering

A slice of the Service Ontology Parse this Parse_NCBI_Blast “The Exploding Bicycle” - A. Rector, U Manchester Parse that Parsing Service Analysis WU_Blast Alignment Blast NCBI_Blast

MOBY in the future • Tighter collaboration with my. Grid – We now have identical RDF data-models for our registry metadata • We inherit the excellent my. Grid Service Ontology, while retaining the power of the MOBY Object ontology!

Bio. Moby Conclusions • The bioinformatics community is facing missioncritical data management problems • The solution must be simple. • The community will adopt solutions that work even if they have to change their behaviour to do so • The community can be trusted to build useful, simple ontologies on its own`

The Semantic Web for Plant Genomics How do Web Services help us with the Semantic Web problem?

The Semantic Web: RDF Triples URI http: //biomoby. org dc: author URI http: // icapture. ubc. ca/ Wilkinson Basically, just entity-relationship diagrams

The Internet Credit to P. Lord, my. Grid

The World Wide Web Credit to P. Lord, my. Grid
 same. As Transcript. Of ISA activates component. Of has.")
The Semantic Web (low stack) same. As Transcript. Of ISA activates component. Of has. Product address cloned. By Credit to P. Lord, my. Grid

How do WS relate to the SW? • Bioinformatics information is mainly in Databases – Therefore not available as named documents (URI’s)… • Work on Semantic Web Services has focused primarily on semantic annotation of Web Service functionality (e. g. Moby & my. Grid) – i. e. the problem of Service Discovery • Can Web Services be used to build the Semantic Web? (credit to Phillip Lord, my. Grid, for this phraseology)

Web Services… no documents to point to! same. As Transcript. Of ISA activates component. Of has. Product address cloned. By

The Semantic Web same. As Transcript. Of ISA activates component. Of has. Product address cloned. By Credit to P. Lord, my. Grid

How do we make Web Services look like the Semantic Web? • Moby can help! • Two novel Moby clients - Ahab and Ishmael – are starting to create Semantic Webby outputs…

The Ahab Bio. Moby Client

Ahab

Ahab RDF

But Bio. Moby can run unattended! • Because of syntactic agreement among service providers, and • Because the machine can automatically disassemble complex objects, and • Because discovery and execution of services that act on those objects can be fully automated • Bio. Moby can build a massive Entity/Relationship model completely unattended

Okay, so get rid of the GUI… 1. Tell Ahab engine to chose all discovered 2. 3. 4. services for a piece of data Execute every service Take each output, and go to (1) Go home for an early weekend… This is Ishmael - a prototype Bio. Moby client

The Output from Ishmael same. As Transcript. Of ISA activates component. Of has. Product address cloned. By

my. SWeb • The output of Ishmael is “My Semantic Web” – Personalized Semantic Web-like RDF graph – Centered around your data of interest – Cachable/explorable by e. g. Haystack – Because each node is a Moby-like URI with a namespace & id, it auto-detects “re-discovery” of data elements (“loops” in the dataset)

Acknowledgements O|B|F • Bio. MOBY: A Bioinformatics Platform for Genome Canada • Ahab, Ishmael, i. CAPTURer: Genome BC Better Biomarkers in Transplantation • Cardio. SHARE: Canadian Institutes for Health Research (CIHR) • Taverna: my. Grid • Ben Good: CIHR Bioinformatics Training Programme

Participants and Supporters Edward Kawas – Lead Developer , Bio. MOBY project, UBC, Canada Benjamin Good – CIHR Bioinformatics Training Program, UBC, Canada Clarence Kwan – Genome Prairie Co-op student, UBC, Canada Bruce Mc. Manus – Co-director, i. CAPTURE Centre, UBC, Canada Carole Goble, Phillip Lord – my. Grid project, U Manchester, UK Martin Senger – my. Grid/Taverna, EBI, UK Bill Crosby & Matthew Links – U Windsor, Canada Heiko Schoof, Rebecca Ernst – MIPS, Germany Simon Twigger – Rat Genome Database, USA Yan Wong – Pasteur Institute, France Frank Gibbons – Harvard, USA David Gonzales Pisano – Centro Nacional Biotechnologia, Spain Damian Gessler & Gary Schiltz – NCGR, USA Lincoln Stein – Cold Spring Harbor Labs, USA Midori Harris - Gene Ontology Consortium, UK Richard Bruskiewich – CGIAR/IRRI, Philippines Mark Regan – ACPFG/UQueensland, Australia
c7f247741bb97e778944a91857284b77.ppt