89cf489e03b26cdaf2dfc9e31c386d2f.ppt
- Количество слайдов: 68



Hands on! Speakers: Ted Dunning, Robin Anil OSCON 2011, Portland

About Us § Ted Dunning: Chief Application Architect at Map. R Committer and PMC Member at Apache Mahout Previously: Music. Match (Yahoo! Music), Veoh recommendation, ID Analytics § Robin Anil: Software Engineer at Google Committer and PMC Member at Apache Mahout Previously: Yahoo! (Display ads), Minekey recommendation
 § Overview of Algorithms in Mahout (10")
Agenda § Intro to Mahout (5 mins) § Overview of Algorithms in Mahout (10 mins) § Hands on Mahout! - Clustering (30 mins) - Classification (30 mins) - Advanced topics with Q&A (15 mins)

Mission To build a scalable machine learning library

Scale! § Scale to large datasets - Hadoop Map. Reduce implementations that scales linearly with data. - Fast sequential algorithms whose runtime doesn’t depend on the size of the data - Goal: To be as fast as possible for any algorithm § Scalable to support your business case - Apache Software License 2 § Scalable community - Vibrant, responsive and diverse - Come to the mailing list and find out more

Current state of ML libraries § Lack community § Lack scalability § Lack documentations and examples § Lack Apache licensing § Are not well tested § Are Research oriented § Not built over existing production quality libraries § Lack “Deployability”

Algorithms and Applications

Clustering § Call it fuzzy grouping based on a notion of similarity

Mahout Clustering § Plenty of Algorithms: K-Means, Fuzzy K-Means, Mean Shift, Canopy, Dirichlet § Group similar looking objects § Notion of similarity: Distance measure: - Euclidean - Cosine - Tanimoto - Manhattan

Classification § Predicting the type of a new object based on its features § The types are predetermined Dog Cat

Mahout Classification § Plenty of algorithms - Naïve Bayes - Complementary Naïve Bayes - Random Forests - Logistic Regression (SGD) - Support Vector Machines (patch ready) § Learn a model from a manually classified data § Predict the class of a new object based on its features and the learned model

Part 1 - Clustering
 § The vector denoted by")
Understanding data - Vectors Y X=5, Y=3 (5, 3) § The vector denoted by point (5, 3) is simply Array([5, 3]) or Hash. Map([0 => 5], [1 => 3]) X

Representing Vectors – The basics § Now think 3, 4, 5, …. . n-dimensional § Think of a document as a bag of words. “she sells sea shells on the sea shore” § Now map them to integers she => 0 sells => 1 sea => 2 and so on § The resulting vector [1. 0, 2. 0, … ]

Vectors § Imagine one dimension for each word. § Each dimension is also called a feature § Two techniques - Dictionary Based - Randomizer Based

Clustering Reuters dataset

Step 1 – Convert dataset into a Hadoop Sequence File § http: //www. daviddlewis. com/resources/testcollections/reuters 21578. tar. gz § Download (8. 2 MB) and extract the SGML files. - $ mkdir -p mahout-work/reuters-sgm - $ cd mahout-work/reuters-sgm && tar xzf. . /reuters 21578. tar. gz && cd. . § Extract content from SGML to text file - $ bin/mahout org. apache. lucene. benchmark. utils. Extract. Reuters mahout-work/reuters-sgm mahoutwork/reuters-out

Step 1 – Convert dataset into a Hadoop Sequence File § Use seqdirectory tool to convert text file into a Hadoop Sequence File - $ bin/mahout seqdirectory -i mahout-work/reuters-out -o mahout-work/reuters-out-seqdir -c UTF-8 -chunk 5

Hadoop Sequence File § Sequence of Records, where each record is a <Key, Value> pair - <Key 1, Value 1> - <Key 2, Value 2> - … - … - <Keyn, Valuen> § Key and Value needs to be of class org. apache. hadoop. io. Text - Key = Record name or File name or unique identifier - Value = Content as UTF-8 encoded string § TIP: Dump data from your database directly into Hadoop Sequence Files (see next slide)
; File. System fs = File.")
Writing to Sequence Files Configuration conf = new Configuration(); File. System fs = File. System. get(conf); Path path = new Path("testdata/part-00000"); Sequence. File. Writer writer = new Sequence. File. Writer( fs, conf, path, Text. class); for (int i = 0; i < MAX_DOCS; i++) writer. append(new Text(documents(i). Id()), new Text(documents(i). Content())); } writer. close();

Generate Vectors from Sequence Files § Steps 1. Compute Dictionary 2. Assign integers for words 3. Compute feature weights 4. Create vector for each document using word-integer mapping and feature-weight Or § Simply run $ bin/mahout seq 2 sparse

Generate Vectors from Sequence Files § $ bin/mahout seq 2 sparse -i mahout-work/reuters-out-seqdir/ -o mahout-work/reuters-out-seqdir-sparse-kmeans § Important options - Ngrams - Lucene Analyzer for tokenizing - Feature Pruning - Min support - Max Document Frequency - Min LLR (for ngrams) - Weighting Method - TF v/s TFIDF - lp-Norm - Log normalize length

Start K-Means clustering § $ bin/mahout kmeans -i mahout-work/reuters-out-seqdir-sparse-kmeans/tfidf-vectors/ -c mahout-work/reuters-kmeans-clusters -o mahout-work/reuters-kmeans -dm org. apache. mahout. distance. Cosine. Distance. Measure –cd 0. 1 -x 10 -k 20 –ow § Things to watch out for - Number of iterations - Convergence delta - Distance Measure - Creating assignments

K-Means clustering c 2 c 1 c 3

K-Means clustering c 2 c 1 c 3

K-Means clustering c 2 c 1 c 3

K-Means clustering c 2 c 1 c 3

Inspect clusters § $ bin/mahout clusterdump -s mahout-work/reuters-kmeans/clusters-9 -d mahout-work/reuters-out-seqdir-sparse-kmeans/dictionary. file-0 -dt sequencefile -b 100 -n 20 Typical output : VL-21438{n=518 c=[0. 56: 0. 019, 00: 0. 154, 00. 03: 0. 018, 00. 18: 0. 018, … Top Terms: iran => 3. 1861672217321213 strike => 2. 567886952727918 iranian => 2. 133417966282966 union => 2. 116033937940266 said workers gulf => 2. 101773806290277 => 2. 066259451354332 => 1. 9501374918521601 had => 1. 6077752463145605 he => 1. 5355078004962228

FAQs § How to get rid of useless words § How to see documents to cluster assignments § How to choose appropriate weighting § How to run this on a cluster § How to scale § How to choose k § How to improve similarity measurement

FAQs § How to get rid of useless words - Increase min. Support and or decrease df. Percent - Use Stopwords. Analyzer § How to see documents to cluster assignments - Run clustering process at the end of centroid generation using –cl § How to choose appropriate weighting - If its long text, go with tfidf. Use normalization if documents different in length § How to run this on a cluster - Set HADOOP_CONF directory to point to your hadoop cluster conf directory § How to scale - Use small value of k to partially cluster data and then do full clustering on each cluster.

FAQs § How to choose k - Figure out based on the data you have. Trial and error - Or use Canopy Clustering and distance threshold to figure it out - Or use Spectral clustering § How to improve Similarity Measurement - Not all features are equal - Small weight difference for certain types creates a large semantic difference - Use Weighted. Distance. Measure - Or write a custom Distance. Measure

Interesting problems § Cluster users talking about OSCON’ 11 and cluster them based on what they are tweeting - Can you suggest people to network with. § Use user generate tags that people have given for musicians and cluster them - Use the cluster to pre-populate suggest-box to autocomplete tags when users type § Cluster movies based on abstract and description and show related movies. - Note: How it can augment recommendations or collaborative filtering algorithms.

More clustering algorithms § Canopy § Fuzzy K-Means § Mean Shift § Dirichlet process clustering § Spectral clustering.

Part 2 - Classification

Preliminaries § Code is available from github: - git@github. com: tdunning/Chapter-16. git § EC 2 instances available § Thumb drives also available § Email to ted. dunning@gmail. com § Twitter @ted_dunning

A Quick Review § What is classification? - goes-ins: predictors - goes-outs: target variable § What is classifiable data? - continuous, categorical, word-like, text-like - uniform schema § How do we convert from classifiable data to feature vector?

Data Flow Not quite so simple

Classifiable Data § Continuous - A number that represents a quantity, not an id - Blood pressure, stock price, latitude, mass § Categorical - One of a known, small set (color, shape) § Word-like - One of a possibly unknown, possibly large set § Text-like - Many word-like things, usually unordered

But that isn’t quite there § Learning algorithms need feature vectors - Have to convert from data to vector § Can assign one location per feature - or category - or word § Can assign one or more locations with hashing - scary - but safe on average

Data Flow
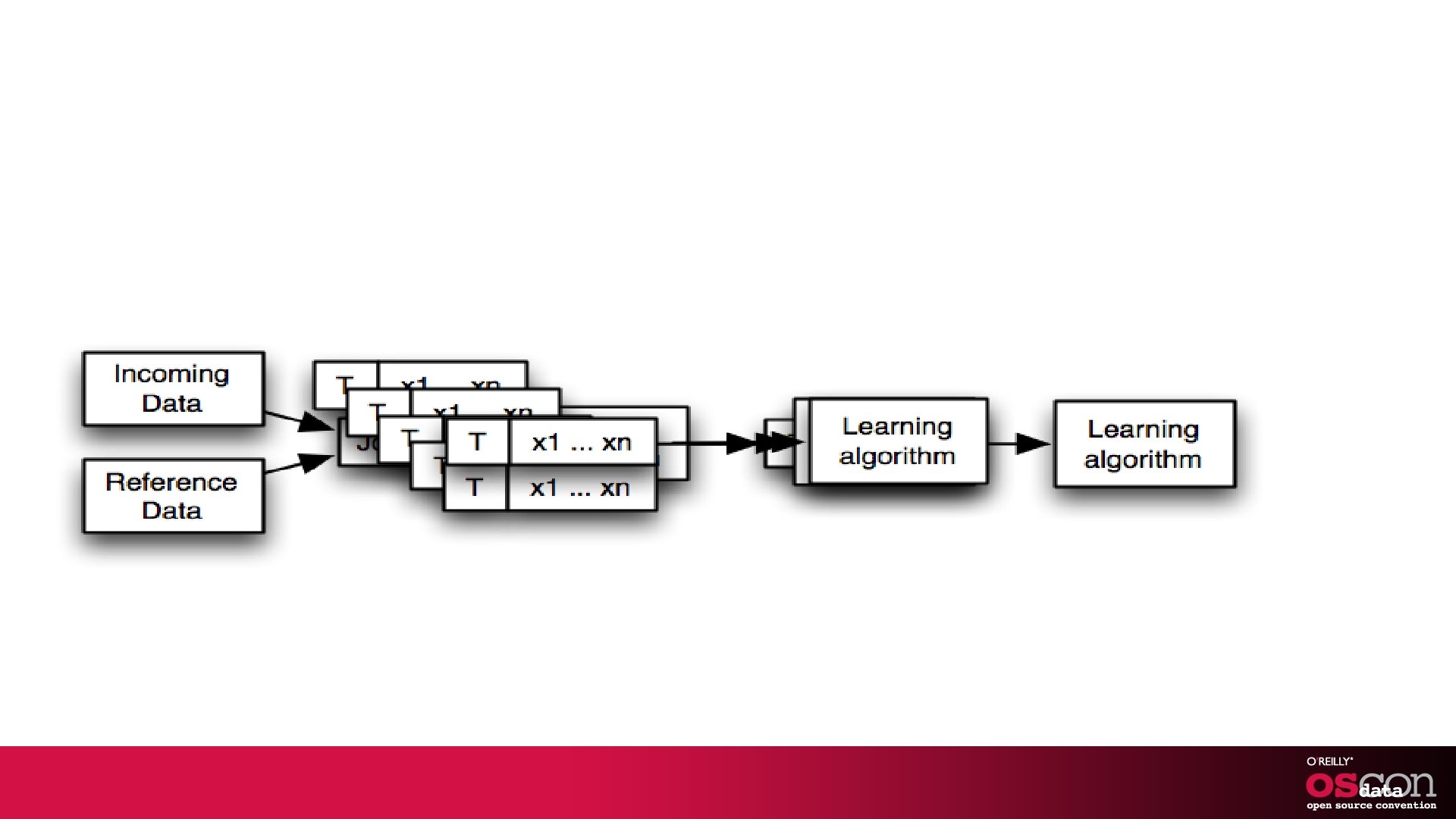

The pipeline Classifiable Data Vectors

Instance and Target Variable

Instance and Target Variable

Hashed Encoding

What about collisions?
")
Let’s write some code (cue relaxing background music)

Generating new features § Sometimes the existing features are difficult to use § Restating the geometry using new reference points may help § Automatic reference points using k-means can be better than manual references

K-means using target

K-means features
")
More code! (cue relaxing background music)

Integration Issues § Feature extraction is ideal for map-reduce - Side data adds some complexity § Clustering works great with map-reduce - Cluster centroids to HDFS § Model training works better sequentially - Need centroids in normal files § Model deployment shouldn’t depend on HDFS

Parallel Stochastic Gradient Descent Model I n p u t Train sub model Average models

Variational Dirichlet Assignment Model I n p u t Gather sufficient statistics Update model

Old tricks, new dogs § Mapper - Assign point to cluster Read from local disk from distributed cache - Emit cluster id, (1, point) § Combiner and reducer Read from HDFS to local disk by distributed cache - Sum counts, weighted sum of points - Emit cluster id, (n, sum/n) § Output to HDFS Written by map-reduce

Old tricks, new dogs § Mapper Read from NFS - Assign point to cluster - Emit cluster id, 1, point § Combiner and reducer - Sum counts, weighted sum of points - Emit cluster id, n, sum/n § Output to HDFS Map. R FS Written by map-reduce

Modeling architecture Side-data Now via NFS I n p u t Feature extraction and down sampling Data join Map-reduce Sequential SGD Learning

More in Mahout

Topic modeling § Grouping similar or co-occurring features into a topic - Topic “Lol Cat”: - Cat - Meow - Purr - Haz - Cheeseburger - Lol

Mahout Topic Modeling § Algorithm: Latent Dirichlet Allocation - Input a set of documents - Output top K prominent topics and the features in each topic

Recommendations § Predict what the user likes based on - His/Her historical behavior - Aggregate behavior of people similar to him

Mahout Recommenders § Different types of recommenders - User based - Item based § Full framework for storage, online and offline computation of recommendations § Like clustering, there is a notion of similarity in users or items - Cosine, Tanimoto, Pearson and LLR

Frequent Pattern Mining § Find interesting groups of items based on how they co-occur in a dataset

Mahout Parallel FPGrowth § Identify the most commonly occurring patterns from - Sales Transactions buy “Milk, eggs and bread” - Query Logs ipad -> apple, tablet, iphone - Spam Detection Yahoo! http: //www. slideshare. net/hadoopusergroup/mail-antispam

Get Started § http: //mahout. apache. org § dev@mahout. apache. org - Developer mailing list § user@mahout. apache. org - User mailing list § Check out the documentations and wiki for quickstart § http: //svn. apache. org/repos/asf/mahout/trunk/ Browse Code § Send me email! - tdunning@maprtech. com - tdunning@apache. org - robinanil@apache. org § Try out Map. R! - www. mapr. com

Resources § “Mahout in Action” Owen, Anil, Dunning, Friedman http: //www. manning. com/owen § “Taming Text” Ingersoll, Morton, Farris http: //www. manning. com/ingersoll § “Introducing Apache Mahout” http: //www. ibm. com/developerworks/java/library/j-mahout/

Thanks to § Apache Foundation § Mahout Committers § Google Summer of Code Organizers § And Students § OSCON § Open source!

References § news. google. com § Cat http: //www. flickr. com/photos/gattou/3178745634/ § Dog http: //www. flickr. com/photos/30800139@N 04/3879737638/ § Milk Eggs Bread http: //www. flickr. com/photos/nauright/4792775946/ § Amazon Recommendations § twitter
89cf489e03b26cdaf2dfc9e31c386d2f.ppt