5870f65bfd9cba28275bb1c503d7939e.ppt
- Количество слайдов: 112



HADOOP ECHOSYSTEM AND IBM BIG INSIGHTS Rafie Tarabay eng_rafie@mans. edu. eg mrafie@eg. ibm. com

WHEN YOU HAVE BIG DATA? When you have one of the next 3 items Variety: Manage and benefit from diverse data types and data structures Velocity: Analyze streaming data and large volumes of persistent data Volume: Scale from terabytes to zettabytes

BI vs Big Data Analysis BI : Business Users determine what question to ask, then IT Structures the data to answer that question. Sample of BI tasks: Monthly sales reports, Profitability analysis, Customer surveys Big Data Approach: IT delivers a platform to enable creative discovery, then Business Explores what questions could be asked Sample of Big. Data tasks: Brand sentiment, Product strategy, Maximum asset utilization

DATA REPRESENTATION FORMATS USED FOR BIG DATA Common data representation formats used for big data include: Row- or record-based encodings: −Flat files / text files −CSV and delimited files −Avro / Sequence. File −JSON −Other formats: XML, YAML Column-based storage formats: −RC / ORC file −Parquet No. SQL Database

What is Parquet, RC/ORC file formats, and Avro? Parquet is a columnar storage format, Allows compression schemes to be specified on a per-column level Offer better write performance by storing metadata at the end of the file Provides the best results in benchmark performance tests RC/ORC file formats developed to support Hive and use a columnar storage format Provides basic statistics such as min, max, sum, and count, on columns Avro data files are a compact, efficient binary format

No. SQL Databases No. SQL is a new way of handling variety of data. No. SQL DB can handle Millions of Queries per Sec while normal RDBMS can handle Thousands of Queries per Sec only, and both are follow CAP Theorem. Types of No. SQL datastores: • Key-value stores: Mem. Cache. D, REDIS, and Riak • Column stores: HBase and Cassandra • Document stores: Mongo. DB, Couch. DB, Cloudant, and Mark. Logic • Graph stores: Neo 4 j and Sesame

CAP Theorem states that in the presence of a network partition, one has to choose between consistency and availability. * Consistency means Every read receives the most recent write or an error * Availability means Every request receives a (non-error) response (without guarantee that it contains the most recent write) HBase, and Mongo. DB ---> CP [give data Consistency but not Availability] Cassandra , Couch. DB ---> AP [give data Availability but not Consistency] while traditional Relational DBMS are CA [support Consistency and Availability but not network partition]

Time line for Hadoop
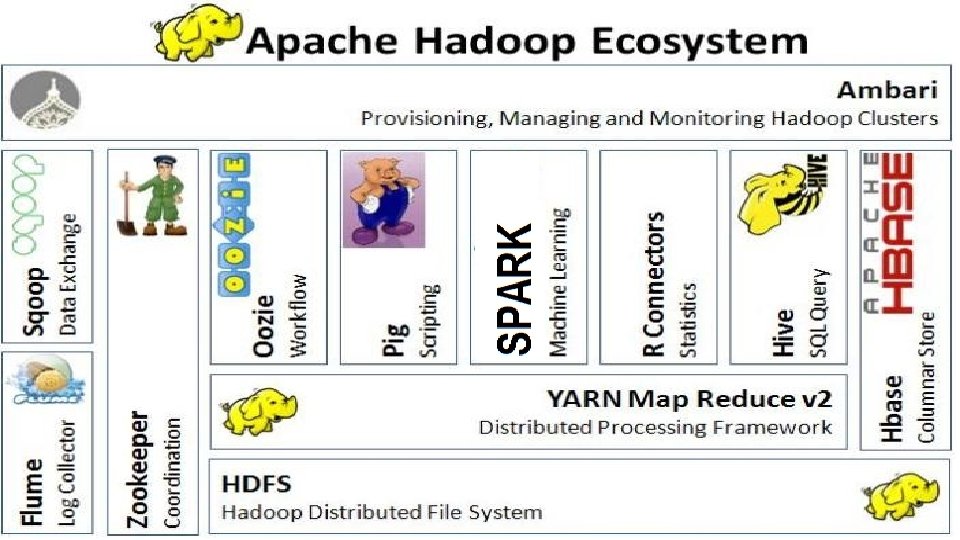

HADOOP

Apache Hadoop Stack The core of Apache Hadoop consists of a storage part, known as Hadoop Distributed File System (HDFS), and a processing part which is a Map. Reduce programming model. Hadoop splits files into large blocks and distributes them across nodes in a cluster. It then transfers packaged code into nodes to process the data in parallel. Hadoop HDFS : [IBM has alternative file system for Hadoop with name GPFS] § where Hadoop stores data § a file system that spans all the nodes in a Hadoop cluster § links together the file systems on many local nodes to make them into one large file system that spans all the data nodes of the cluster Hadoop Map. Reduce v 1 : an implementation for large-scale data processing. Map. Reduce engine consists of : - Job. Tracker : receive client applications jobs and send orders to the Task. Trackes who are nearest to the data as possible. - Task. Tracke: exists on cluster's nodes to receive the orders from Job. Tracker YARN (it is the newer version of Map. Reduce): each cluster has a Resource Manager, and each data node runs a Node Manager. For each job, one slave node will act as the Application Master, monitoring resources/tasks, etc.

Advantages and disadvantages of Hadoop • Hadoop is good for: § processing massive amounts of data through parallelism § handling a variety of data (structured, unstructured, semi-structured) § using inexpensive commodity hardware • Hadoop is not good for: § processing transactions (random access) § when work cannot be parallelized § Fast access to data § processing lots of small files § intensive calculations with small amounts of data What hardware is not used for Hadoop? • RAID • Linux Logical Volume Manager (LVM) • Solid-state disk (SSD)

HSFS
 principles • • Distributed, scalable, fault tolerant, high throughput")
Hadoop Distributed File System (HDFS) principles • • Distributed, scalable, fault tolerant, high throughput Data access through Map. Reduce Files split into blocks (aka splits) 3 replicas for each piece of data by default Can create, delete, and copy, but cannot update Designed for streaming reads, not random access Data locality is an important concept: processing data on or near the physical storage to decrease transmission of data

HDFS: architecture • Master / Slave architecture • Name. Node § Regulates access to files by clients • Data. Node § Many Data. Nodes per cluster § Manages storage attached to the nodes § Periodically reports status to Name. Node § Data is stored across multiple nodes § File 1 a b c d Manages the file system namespace and metadata § Name. Nodes and components will fail, so for reliability data is replicated across multiple nodes a b d b a c a d c Data. Nodes c b d

Hadoop HDFS: read and write files from HDFS Create sample text file on Linux # echo “My First Hadoop Lesson” > test. txt Linux List system files to ensure file creation # ls -lt List current files on your home directory in HDFS # hadoop fs -ls / Create new directory in HDFS – name it test # hadoop fs -mkdir test Load test. txt file into Hadoop HDFS # hadoop fs -put test. txt test/ View contents of HDFS file test. txt # hadoop fs -cat test/test. txt

hadoop fs - Command Reference ls <path> Lists the contents of the directory specified by path, showing the names, permissions, owner, size and modification date for each entry. lsr <path> Behaves like -ls, but recursively displays entries in all subdirectories of path. du <path> Shows disk usage, in bytes, for all the files which match path; filenames are reported with the full HDFS protocol prefix. dus <path> Like -du, but prints a summary of disk usage of all files/directories in the path. mv <src><dest> Moves the file or directory indicated by src to dest, within HDFS. cp <src> <dest> Copies the file or directory identified by src to dest, within HDFS. rm <path> Removes the file or empty directory identified by path. rmr <path> Removes the file or directory identified by path. Recursively deletes any child entries (i. e. , files or subdirectories of path).

hadoop fs - Command Reference put <local. Src> <dest> Copies the file or directory from the local file system identified by local. Src to dest within the DFS. copy. From. Local <local. Src> <dest> Identical to -put move. From. Local <local. Src> <dest> Copy file or directory from the local file system identified by local. Src to dest within HDFS, and then deletes the local copy on success. get [-crc] <src> <local. Dest> Copies the file or directory in HDFS identified by src to the local file system path identified by local. Dest. getmerge <src> <local. Dest> Retrieves all files that match the path src in HDFS, and copies them local to a single, merged file local. Dest. cat <filen-ame> Displays the contents of filename on stdout. copy. To. Local <src> <local. Dest> Identical to -get move. To. Local <src> <local. Dest> Works like -get, but deletes the HDFS copy on success. mkdir <path> Creates a directory named path in HDFS. Creates any parent directories in path that are missing (e. g. , mkdir -p in Linux).
![hadoop fs - Command Reference stat [format] <path> Prints information about path. Format is](https://present5.com/presentation/5870f65bfd9cba28275bb1c503d7939e/image-19.jpg "hadoop fs - Command Reference stat [format] <path> Prints information about path. Format is")
hadoop fs - Command Reference stat [format] <path> Prints information about path. Format is a string which accepts file size in blocks (%b), filename (%n), block size (%o), replication (%r), and modification date (%y, %Y). tail [-f] <file 2 name> Shows the last 1 KB of file on stdout. chmod [-R] mode, . . . <path>. . . Changes the file permissions associated with one or more objects identified by path. . Performs changes recursively with R. mode is a 3 -digit octal mode, or {augo}+/-{rwx. X}. Assumes if no scope is specified and does not apply an umask. chown [-R] [owner][: [group]] <path>. . . Sets the owning user and/or group for files or directories identified by path. . Sets owner recursively if -R is specified. chgrp [-R] group <path>. . . Sets the owning group for files or directories identified by path. . Sets group recursively if -R is specified. help <cmd-name> Returns usage information for one of the commands listed above. You must omit the leading '-' character in cmd.

YARN

YARN Sometimes called Map. Reduce 2. 0, YARN decouples scheduling capabilities from the data processing component Hadoop clusters can now run interactive querying and streaming data applications simultaneously. Separating HDFS from Map. Reduce with YARN makes the Hadoop environment more suitable for operational applications that can't wait for batch jobs to finish.
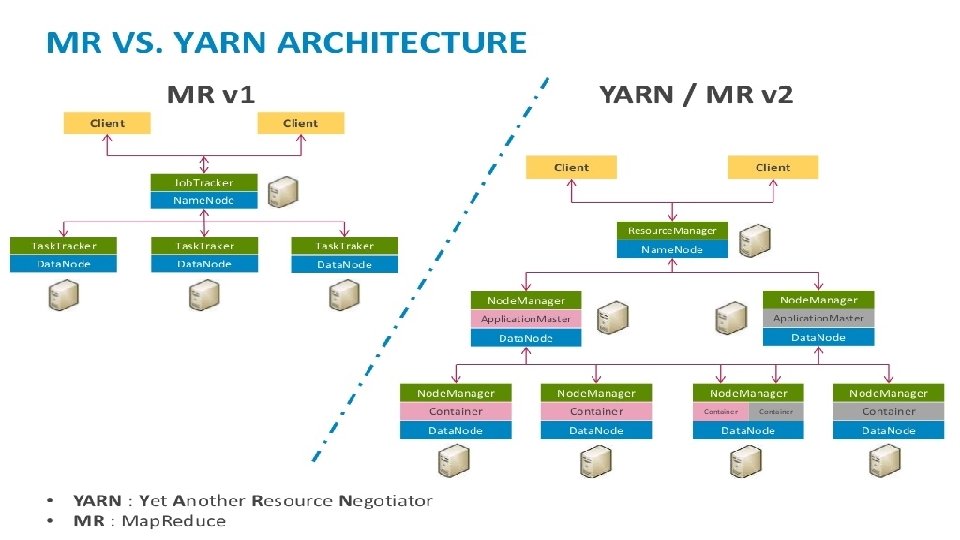

YARN

HBASE HBase is a No. SQL column family database that runs on top of Hadoop HDFS (it is the default Hadoop Database ). Can handle large tables which have billions of rows and millions of columns with fault tolerance and horizontal scalability. HBase concept was inspired by Google’s Big Table. Schema does not need to be defined up front support high performance random r/w applications Data is stored in HBase table(s) Tables are made of rows and columns Row stored in order by row keys Query data using get/put/scan only For more information https: //www. tutorialspoint. com/hbase/index. htm

PIG

PIG Apache Pig is used for querying data stored in Hadoop clusters. It allows users to write complex Map. Reduce transformations using high-level scripting language called Pig Latin. Pig translates the Pig Latin script into Map. Reduce tasks by using its Pig Engine component so that it can be executed within YARN for access to a single dataset stored in the HDFS. Programmers need not write complex code in Java for Map. Reduce tasks rather they can use Pig Latin to perform Map. Reduce tasks. Apache Pig provides nested data types like tuples, bags, and maps that are missing from Map. Reduce along with built-in operators like joins, filters, ordering etc. Apache Pig can handle structured, unstructured, and semi-structured data. For more information https: //www. tutorialspoint. com/apache_pig_overview. htm

HIVE

Hive The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax. Allows SQL developers to write Hive Query Language (HQL) statements that are similar to standard SQL statements. Hive shell, JDBC, and ODBC are supported Access to files stored either directly in Apache HDFS or in other data storage systems such as Apache HBase For more information https: //www. tutorialspoint. com/hive_introduction. htm

Create Database/Tables in Hive hive> CREATE DATABASE IF NOT EXISTS userdb; hive> SHOW DATABASES; hive> DROP DATABASE IF EXISTS userdb CASCADE; (to drop all tables also) hive> CREATE TABLE IF NOT EXISTS employee (id int, name String, salary String, destination String) COMMENT ‘Employee details’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘t’ LINES TERMINATED BY ‘n’ STORED AS TEXTFILE; hive> ALTER TABLE employee RENAME TO emp; hive> ALTER TABLE employee CHANGE name ename String; hive> ALTER TABLE employee CHANGE salary Double; hive> ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name’); hive> DROP TABLE IF EXISTS employee; hive> SHOW TABLES;

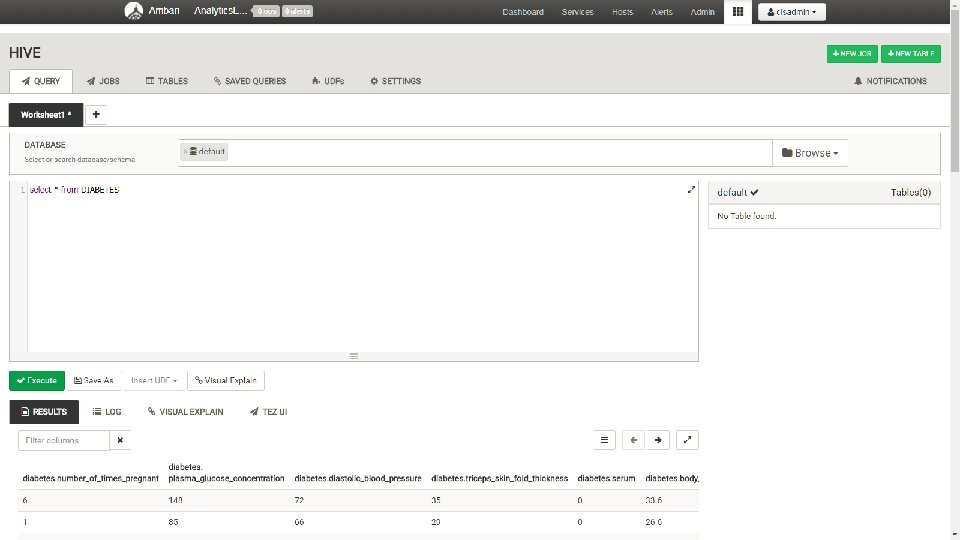
Select, Views hive> SELECT * FROM employee WHERE Id=1205; hive> SELECT * FROM employee WHERE Salary>=40000; hive> SELECT 20+30 ADD FROM temp; hive> SELECT * FROM employee WHERE Salary>40000 && Dept=TP; hive> SELECT round(2. 6) from temp; hive> SELECT floor(2. 6) from temp; hive> SELECT ceil(2. 6) from temp; hive> CREATE VIEW emp_30000 AS SELECT * FROM employee WHERE salary>30000; hive> DROP VIEW emp_30000;
 AS")
Index, Order by, Group by, Join hive> CREATE INDEX inedx_salary ON TABLE employee(salary) AS 'org. apache. hadoop. hive. ql. index. compact. Compact. Index. Handler'; hive> DROP INDEX index_salary ON employee; hive> SELECT Id, Name, Dept FROM employee ORDER BY DEPT; hive> SELECT Dept, count(*) FROM employee GROUP BY DEPT; hive> SELECT c. ID, c. NAME, c. AGE, o. AMOUNT FROM CUSTOMERS c JOIN ORDERS o ON (c. ID = o. CUSTOMER_ID); hive> SELECT c. ID, c. NAME, o. AMOUNT, o. DATE FROM CUSTOMERS c LEFT OUTER JOIN ORDERS o ON (c. ID = o. CUSTOMER_ID); hive> SELECT c. ID, c. NAME, o. AMOUNT, o. DATE FROM CUSTOMERS c FULL OUTER JOIN ORDERS o ON (c. ID = o. CUSTOMER_ID);

Java example for Hive JDBC import java. sql. SQLException; import java. sql. Connection; import java. sql. Result. Set; import java. sql. Statement; import java. sql. Driver. Manager; public class Hive. QLOrder. By { public static void main(String[] args) throws SQLException { Class. for. Name(org. apache. hadoop. hive. jdbc. Hive. Driver); // Register driver and create driver instance Connection con = Driver. Manager. get. Connection("jdbc: hive: //localhost: 10000/userdb", ""); // get connection Statement stmt = con. create. Statement(); // create statement Resultset res = stmt. execute. Query("SELECT * FROM employee ORDER BY DEPT; "); // execute statement System. out. println(" ID t Name t Salary t Designation t Dept "); while (res. next()) { System. out. println(res. get. Int(1) + " " + res. get. String(2) + " " + res. get. Double(3) + " " + res. get. String(4) + " " + res. get. String(5)); } con. close(); } } $ javac Hive. QLOrder. By. java $ java Hive. QLOrder. By

PHOENIX

Apache Phoenix is an open source, massively parallel, relational database engine supporting OLTP for Hadoop using Apache HBase as its backing store. Phoenix provides a JDBC driver that hides the intricacies of the no. SQL store enabling users to create, delete, and alter SQL tables, views, indexes, and sequences; insert and delete rows singly and in bulk; and query data through SQL. Phoenix compiles queries and other statements into native no. SQL store APIs rather than using Map. Reduce enabling the building of low latency applications on top of no. SQL stores. Apache phoenix is a good choice for low-latency and mid-size table (1 M - 100 M rows) Apache phoenix is faster than Hive, and Impala
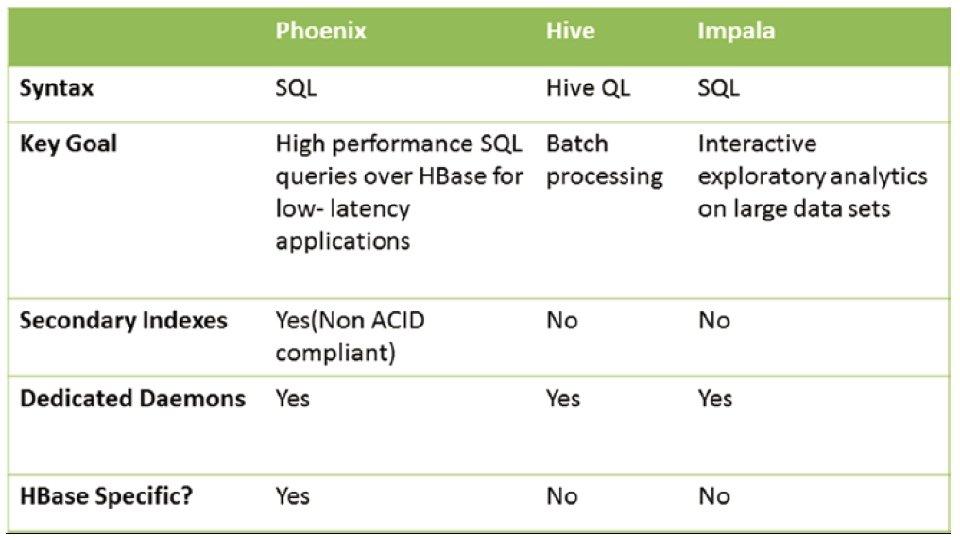

Phoenix main features support transaction Support User defined functions Support Secondary Indexes supports view syntax

SOLR
 Solr is used to build search applications deliver high performance")
Solr (enterprise search engine) Solr is used to build search applications deliver high performance with support for execution of parallel SQL queries. . . It was built on top of Lucene (full text search engine). Solr can be used along with Hadoop to search large volumes of text-centric data. . Not only search, Solr can also be used for storage purpose. Like other No. SQL databases, it is a non-relational data storage and processing technology. Support Fulltext Search, It utilizes the RAM, not the CPU. PDF, Word document indexing Auto-suggest, Stop words, synonyms, etc. Supports replication Communicate with the search server via Index directly from the database with custom queries For more information: HTTP (it can even return Json, Native PHP/Ruby/Python) https: //www. tutorialspoint. com/apache_solr_overview. htm

ELASTICSEARCH-HADOOP
 ES-Hadoop is a real-time FTS search and analytics engine Connect the massive")
Elasticsearch-Hadoop (ES-Hadoop) ES-Hadoop is a real-time FTS search and analytics engine Connect the massive data storage and deep processing power of Hadoop with the real-time search and analytics of Elasticsearch. ES-Hadoop connector lets you get quick insight from your big data and makes working in the Hadoop ecosystem even better. ES-Hadoop lets you index Hadoop data into the Elastic Stack to take full advantage of the speedy Elasticsearch engine and beautiful Kibana visualizations. With ES-Hadoop, you can easily build dynamic, embedded search applications to serve your Hadoop data or perform deep, low-latency analytics using full-text, geospatial queries and aggregations. ES-Hadoop lets you easily move data bi-directionally between Elasticsearch and Hadoop while exposing HDFS as a repository for long-term archival.

SQOOP

SQOOP • Import data from relational database tables into HDFS • Export data from HDFS into relational database tables Sqoop works with all databases that have a JDBC connection. JDBC driver JAR files should exists in $SQOOP_HOME/lib It uses Map. Reduce to import and export the data Imports data can be stored as Text files Binary files Into HBase Into Hive

OOZIE

Oozie Apache Oozie is a scheduler system to run and manage Hadoop jobs in a distributed environment. It allows to combine multiple complex jobs to be run in a sequential order to achieve a bigger task. Within a sequence of task, two or more jobs can also be programmed to run parallel to each other. One of the main advantages of Oozie is that it is tightly integrated with Hadoop stack supporting various Hadoop jobs like Hive, Pig, Sqoop as well as system-specific jobs like Java and Shell. Oozie has three types of jobs: Oozie Workflow Jobs − These are represented as Directed Acyclic Graphs (DAGs) to specify a sequence of actions to be executed. Oozie Coordinator Jobs − These consist of workflow jobs triggered by time and data availability. Oozie Bundle − These can be referred to as a package of multiple coordinator and workflow jobs. For more information https: //www. tutorialspoint. com/apache_oozie_introduction. htm

R-HADOOP

R Hadoop RHadoop is a collection of five R packages that allow users to manage and analyze data with Hadoop. Rhdfs: Connect HDFSto R. Rhbase: connect HBASE to R Rmr 2: enable R to perform statistical analysis using Map. Reduce Ravro: enable R to read and write avro files from local and HDFS Plyrmr: enable user to perform common data manipulation operations, as found in plyr and reshape 2, on data sets stored on Hadoop

SPARK

Spark with Hadoop 2+ • Spark is an alternative in-memory framework to Map. Reduce • Supports general workloads as well as streaming, interactive queries and machine learning providing performance gains • Spark jobs can be written in Scala, Python, or Java; APIs are available for all three • Run Spark Scala shells by (spark-shell) Spark Python shells by (pyspark) Apache Spark was the world record holder in 2014 for sorting. By sorting 100 TB of data on 207 machines in 23 minutes but Hadoop Map. Reduce took 72 minutes on 2100 machines.

Spark libraries Spark SQL: is a Spark module for structured data processing, in which in-memory processing is its core. Using Spark SQL, can read the data from any structured sources, like JSON, CSV, parquet, avro, sequencefiles, jdbc , Hive etc. example: scala> sql. Context. sql("SELECT * FROM src"). collect scala> hive. Context. sql("SELECT * FROM src"). collect Spark Streaming: Write applications to process streaming data in Java or Scala. Receives data from: Kafka, Flume, HDFS / S 3, Kinesis, Twitter Pushes data out to: HDFS, Databases, Dashboard MLLib: Spark 2+ has new optimized library support machine learning functions on a cluster based on new Data. Frame-based API in the spark. ml package. Graph. X: API for graphs and parallel computation

FLUME

Flume • Flume was created to allow you to flow data stream from a source into your Hadoop note that HDFS files does not support update by default. The source of data stream can be • • TCP traffic on the port Logs that constantly appended. ie, Log file of the web server Tweeter feeds ….

KAFKA

Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Kafka is suitable for both offline and online message consumption. Kafka messages are persisted on the disk and replicated within the cluster to prevent data loss. Kafka is built on top of the Zoo. Keeper synchronization service. It integrates very well with Apache Storm and Spark for real-time streaming data analysis. messages are persisted in a topic. consumers can subscribe to one or more topic and consume all the messages in that topic.

KNOX

KNOX Hadoop clusters is unsecured by default and any one can call it and we can block direct access to Hadoop using Knox Gateway is a REST API Gateway to interact with Hadoop clusters. Knox allow control, integration, monitoring and automation administrative and analytical tasks Knox provide Authentication using LDAP and Active Directory Authentication

SLIDER
 YARN resource management and scheduling works well for batch")
SLIDER (SUPPORT LONG-RUNNING DISTRIBUTED SERVICES) YARN resource management and scheduling works well for batch workloads, but not for interactive or real-time data processing services Apache Slider extends YARN to support long-running distributed services on an Hadoop cluster, Supports restart after process failure, support Live Long and Process (LLAP) Applications can be stopped then started This enables best-effort placement close to the previous locations The distribution of the deployed application across the YARN cluster is persisted Applications which remember the previous placement of data (such as HBase) can exhibit fast start-up times from this feature. YARN itself monitors the health of "YARN containers" hosting parts of the deployed application YARN notifies the Slider manager application of container failure Slider then asks YARN for a new container, into which Slider deploys a replacement for the failed component, keeping the size of managed applications consistent with the specified configuration Slider implements all its functionality through YARN APIs and the existing application shell scripts The goal of the application was to have minimal code changes and impact on existing applications

ZOOKEEPER

Zoo. Keeper • Zookeeper is a distributed coordination service that manages large sets of nodes. On any partial failure, clients can connect to any node to receive correct, up-to-date information • Services depend on Zoo. Keeper Hbase, Map. Reduce, and Flume Z-Node • znode is a file that persists in memory on the Zoo. Keeper servers • znode can be updated by any node in the cluster • Applications can synchronize their tasks across the distributed cluster by updating their status in a Zoo. Keeper znode, which would then inform the rest of the cluster of a specific node’s status change. • ZNode Shell command: Create, delete, exists, get. Children, get. Data, set. Data, get. ACL, sync Watches events • any node in the cluster can register to be informed of changes to specific znode (watch) • Watches are one-time triggers and always ordered. Client sees watched event before new ZNode data. • ZNode watches events: Node. Children. Changed, Node. Created, Node. Data. Changed, Node. Deleted

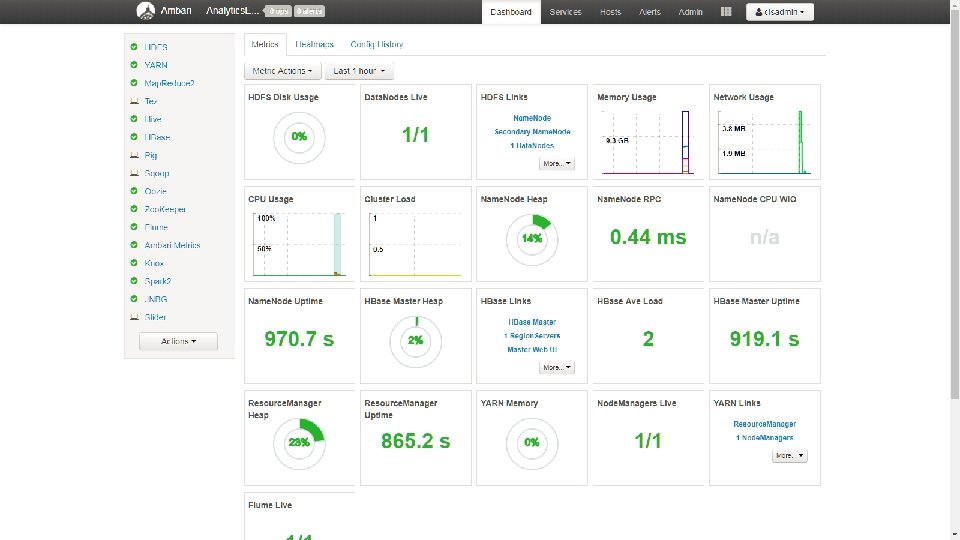
AMBARI
 Ambari View is developed by Horton. Works. Ambari")
AMBARI (GUI TOOLS TO MANAGE HADOOP) Ambari View is developed by Horton. Works. Ambari is a GUI tool you can use to create(install) manage the entire hadoop cluster. You can keep on expanding by adding nodes and monitor the health, space utilization etc through Ambari views are more to help users to use the installed components/services like hive, pig, capacity scheduler to see the cluster-load and manage YARN workload management, provisioning cluster resources, manage files etc. We have another GUI tool with name HUE developed by Cloudera

IBM BIG-INSIGHTS V 4. 0

How to get IBM Big. Insights? https: //www. ibm. com/hadoop https: //www. ibm. com/analytics/us/en/technology/hadoop-trials. html

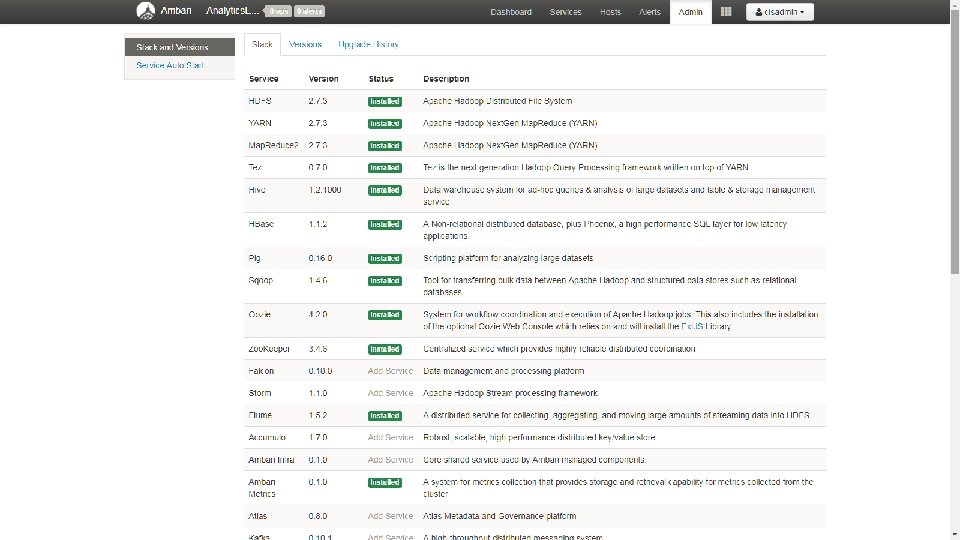
IBM Big. Insights for Apache Hadoop Offering Suite Big. Insights Quick Start Edition IBM Open Platform with Apache Hadoop Elite Support for IBM Open Platform with Apache Hadoop Big. Insights Analyst Module Big. Insights Data Scientist Module Big. Insights Enterprise Management Module Apache Hadoop Stack: HDFS, YARN, Map. Reduce, Ambari, Hbase, Hive, Oozie, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider ✔ ✔ ✔ * * * Big SQL - 100% ANSI compliant, high performant, secure SQL engine ✔ ✔ Big. Sheets - spreadsheet-like interface for discovery & visualization ✔ ✔ Big R - advanced statistical & data mining ✔ ✔ ✔ Machine Learning with Big R - machine learning algorithms apply to Hadoop data set ✔ ✔ ✔ Advanced Text Analytics - visual tooling to annotate automated text extraction ✔ ✔ ✔ IBM Big. Insights v 4 Big. Insights for Apache Hadoop * Paid support for IBM Open Platform with Apache Hadoop required for Big. Insights modules Enterprise Management- Enhanced cluster & resource mgmt & GPFS (POSIX-compliant) file systems ✔ Governance Catalog ✔ ✔ Cognos BI, Info. Sphere Streams, Watson Explorer, Data Click Pricing & licensing ✔ ✔ Free Yearly Subscription for support Node based pricing
![BIGINSIGHTS MAIN SERVICES GPFS Filesystem IBM Spectrum Symphony [Adaptive Map. Reduce] Big. SQL Big.](https://present5.com/presentation/5870f65bfd9cba28275bb1c503d7939e/image-70.jpg "BIGINSIGHTS MAIN SERVICES GPFS Filesystem IBM Spectrum Symphony [Adaptive Map. Reduce] Big. SQL Big.")
BIGINSIGHTS MAIN SERVICES GPFS Filesystem IBM Spectrum Symphony [Adaptive Map. Reduce] Big. SQL Big. Sheets Text Analytics Big R

Details IBM BIGINSIGHTS ENTERPRISE MANAGEMENT MODULES - GPFS FPO - Adaptive Map. Reduce

GPFS FPO Also know as “IBM Spectrum Scale”
 : HDFS alternative What is expected from GPFS? Compute Cluster")
IBM GPFS (Distributed Filesystem) : HDFS alternative What is expected from GPFS? Compute Cluster • high scale, high performance, high availability, data integrity • same data accessible from different computers • logical isolation: filesets are separate filesystems inside a filesystem HDFS • physical isolation: filesets can be put in separate storage pools • enterprise features (quotas, security, ACLs, snapshots, etc. ) GPFS-FPO GPFS: General Parallel File System FPO: File Placement Optimizer
 HDFS files can only access with Hadoop APIs. so, standard")
Hadoop file system (HDFS) HDFS files can only access with Hadoop APIs. so, standard applications cannot use it IBM GPFS file system (GPFS-FPO) Any application can access and use it using all the commands used in Windows/Unix Should define the size of disk space allocated to HDFS No need to define the size of disk space allocated to GPFS filesystems Does not handle security/access control Support access control on file and disk level Does not replicate metadata, has a single point of failure in the Name. Node Distributed metadata feature eliminates any single point of failure (metadata is replicated just like data) Should load all the metadata in memory to work Metadata doesn't need to get read into memory before the filesystem is available Dealing with small numbers of large files only dealing with large numbers of any files size and enables mixing of multiple storage types, support write-intensive applications Allows concurrent read but only one writer Allows concurrent read and write by multiple programs No Policy-based archiving: data can be migrated automatically to tapes If nobody has touches it for a given period (So as the data ages, it is automatically migrated to less-expensive storage)

HDFS vs. GPFS for Hadoop

GPFS: MAKE A FILE AVAILABLE TO HADOOP HDFS: hadoop fs -copy. From. Local /local/source/path /hdfs/target/path GPFS/UNIX: cp /source/path /target/path HDFS : hadoop fs -mv path 1/ path 2/ GPFS/regular UNIX: mv path 1/ path 2/ HDFS: diff < (hadoop fs -cat file 1) < (hadoop fs -cat file 2) GPFS/regular UNIX: diff file 1 file 2
![IBM SPECTRUM SYMPHONY [ADAPTIVE MAPREDUCE]](https://present5.com/presentation/5870f65bfd9cba28275bb1c503d7939e/image-77.jpg "IBM SPECTRUM SYMPHONY [ADAPTIVE MAPREDUCE]")
IBM SPECTRUM SYMPHONY [ADAPTIVE MAPREDUCE]
 While Hadoop clusters normally run one job at a")
Adaptive Map. Reduce (Platform Symphony) While Hadoop clusters normally run one job at a time, Platform Symphony is designed for concurrency, allowing up to 300 job trackers to run on a single cluster at the same time with agile reallocation of resources based on real-time changes to job priorities.

What is Platform Symphony ? § Platform Symphony distributes and virtualizes compute-intensive application services and processes across existing heterogeneous IT resources. § Platform Symphony creates a shared, scalable, and fault-tolerant infrastructure, delivering faster, more reliable application performance while reducing cost. § It provides an application framework that allows you to run distributed or parallel applications in a scaled-out grid environment. § Platform Symphony is fast middleware written in C++ although it presents programming interfaces in multiple languages including Java, C++, C#, and various scripting languages. § Client applications interact with a session manager though a client-side API, and the session manager guarantees the reliable execution of tasks distributed to various service instances. Services instances are orchestrated dynamically based on application demand resource sharing policies. So, § is a High-performance computing (HPC) software system , designed to deliver scalability and enhances performance for compute-intensive risk and analytical applications. § The product lets users run applications using distributed computing. "the first and only solution tailored for developing and testing Grid-ready service-oriented architecture applications"

Details IBM BIGINSIGHTS ANALYST MODULES - Big SQL - Big Sheet

BIG SQL

What is Big SQL -Industry-standard SQL query interface for Big. Insights data -New Hadoop query engine derived from decades of IBM R&D investment in RDBMS technology, including database parallelism and query optimization Why Big SQL -Easy on-ramp to Hadoop for SQL professionals -Support familiar SQL tools / applications (via JDBC and ODBC drivers) What operations are supported -Create tables / views. Store data in DFS, HBase, or Hive warehouse -Load data into tables (from local files, remote files, RDBMSs) -Query data (project, restrict, join, union, wide range of sub-queries, and built-in functions, UDFs, etc). -GRANT / REVOKE privileges, create roles, create column masks and row permissions -Transparently join / union data between Hadoop and RDBMSs in single query -Collect statistics and inspect detailed data access plan -Establish workload management controls -Monitor Big SQL usage

Why choose Big SQL instead of Hive and other vendors? Performance Application Portability & Integration Data shared with Hadoop ecosystem Comprehensive file format support Superior enablement of IBM and Third Party software Modern MPP runtime Powerful SQL query rewriter Cost based optimizer Optimized for concurrent user throughput Results not constrained by memory Rich SQL Comprehensive SQL Support IBM SQL PL compatibility Extensive Analytic Functions Federation Distributed requests to multiple data sources within a single SQL statement Main data sources supported: DB 2 LUW, Teradata, Oracle, Netezza, Informix, SQL Server Enterprise Features Advanced security/auditing Resource and workload management Self tuning memory management Comprehensive monitoring

BIG SHEETS

What you can do with Big. Sheets? • Model big data collected from various sources in spreadsheet-like structures • • Filter and enrich content with built-in functions Combine data in different workbooks Visualize results through spreadsheets, charts Export data into common formats (if desired) No programming knowledge needed

Details IBM BIGINSIGHTS DATA SCIENTIST MODULES - Text Analytics - Big R

Text Analytics

Approach for text analytics Rule development Analysis Label Sample snippets input Find clues Performance tuning Production Develop Test Profile Export extractors Refine rules for runtime performance Compile modules documents Access sample documents Locate examples of information to be extracted Create extractors that meet requirements Verify that appropriate data is being extracted

Big R

Limitations of open source R • R was originally created as a single user tool § Not naturally designed for parallelism § Key Take-Away Open Source R is a powerful tool, however, it has limited functionality in terms of parallelism and memory, thereby bounding the ability to analyze big data. Can not easily leverage modern multi-core CPUs • Big data > RAM § R is designed to run in-memory on a shared memory machine § Constrains the size of the data that you can reasonably work with • Memory capacity limitation § Forces R users to use smaller datasets § Sampling can lead to inaccurate or sub-optimal analysis All available information Analyzed information R APPROACH All available information analyzed BIG R APPROACH

Advantages of Big R Full integration of R into Big. Insights Hadoop − scalable − can data processing use existing R assets (code and CRAN packages) − wide class of algorithms and growing

How Big R syntax look like? Use Dataset "airline“ that contains Scheduled flights in US 1987 -2009 : Compute the mean departure delay for each airline on a monthly basis.

Simple Big R example # Connect to Big. Insights > bigr. connect(host="192. 168. 153. 219", user="bigr", password="bigr") # Construct a bigr. frame to access large data set > air <- bigr. frame(data. Source="DEL", data. Path="airline_demo. csv", …) # Filter flights delayed by 15+ mins at departure or arrival > air. Subset <- air[air$Cancelled == 0 & (air$Dep. Delay >= 15 | air$Arr. Delay >= 15), c("Unique. Carrier", "Origin", "Dest", "Dep. Delay", "Arr. Delay", "CRSElapsed. Time")] # What percentage of flights were delayed overall? > nrow(air. Subset) / nrow(air) [1] 0. 2269586 # What are the longest flights? > bf <- sort(air, by = air$Distance, decreasing = T) > bf <- bf[, c("Origin", "Dest", "Distance")] > head(bf, 3) Origin Dest Distance 1 HNL JFK 4983 2 EWR HNL 4962 3 HNL EWR 4962

BIG DATA DEMO Examples

STEPS To work on your own machine Download/Install VMWare Download coudera CDH image http: //www. devopsservice. com/install-mysql-workbench-on-ubuntu-14 -04 -and-centos-6/ Install My. SQL Workbench to control mysql using GUI interface http: //www. devopsservice. com/install-mysql-workbench-on-ubuntu-14 -04 -and-centos-6/ To work on IBM Cloud How to install Hue 3 on IBM Big. Insights 4. 0 to explore Big Data http: //gethue. com/how-to-install-hue-3 -on-ibm-biginsights-4 -0 -to-explore-big-data/

USING IBM CLOUD
,")
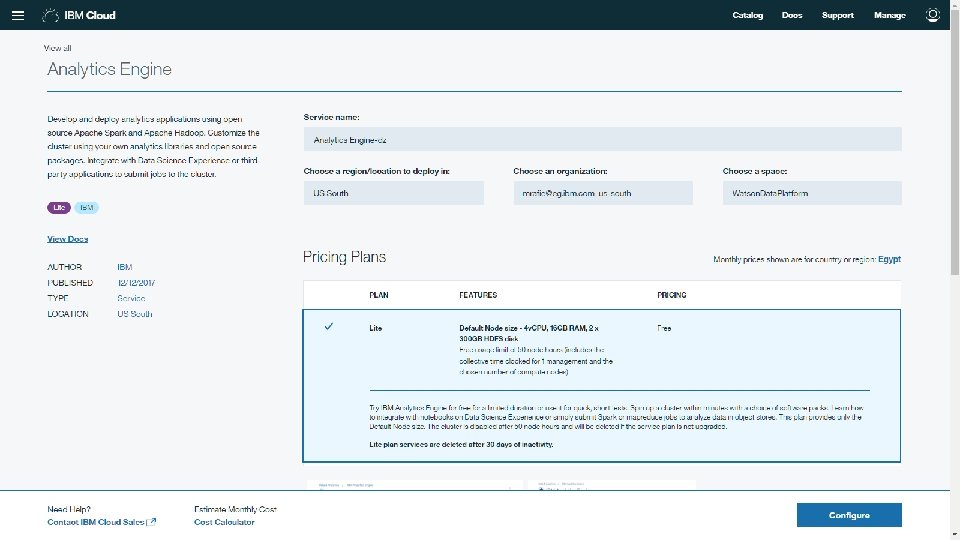
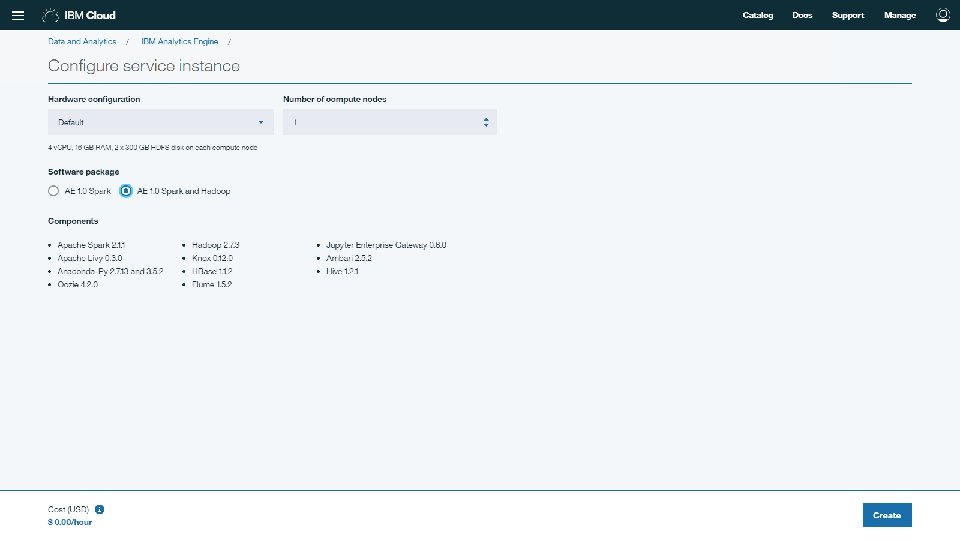
How to work with Hadoop on IBM cloud Login to IBM Cloud (Blue. Mix), and search for Hadoop You will get two results (Lite = Free), and (Subscription=with Cost) choose “Analytics Engine”

USING CLOUDERA VM

EXAMPLE 1 Copy file from HD to HDFS Using command line hadoop fs -put /HD PATH/temperature. csv Using HUE GUI /Hadoop Path/temp

EXAMPLE 2 Use Scoop to move my. Sql DB table to Hadoop file system inside hive directory > sqoop import-all-tables -m 1 --connect jdbc: mysql: //localhost: 3306/retail_db --username=retail_dba --password=cloudera --compression-codec=snappy --as-parquetfile --warehouse-dir=/user/hive/warehouse --hive-import -m parameter: number of. parquet files /usr/hive/warehouse is the default hive path To view tables after move to HDFS To get the actual hive Tables path, use terminally type hive then run command set hive. metastore. warehouse. dir; > hadoop fs -ls /user/hive/warehouse/

HIVE SAMPLE QUERY 1 show tables; To view current Hive tables Run SQL command on Hive tables select c. category_name, count(order_item_quantity) as count from order_items oi inner join products p on oi. order_item_product_id = p. product_id inner join categories c on c. category_id = p. product_category_id group by c. category_name order by count desc limit 10;

HIVE SAMPLE QUERY 2 select p. product_id, p. product_name, r. revenue from products p inner join ( select oi. order_item_product_id, sum(cast(oi. order_item_subtotal as float)) as revenue from order_items oi inner join orders o on oi. order_item_order_id = o. order_id where o. order_status <> 'CANCELED' and o. order_status <> 'SUSPECTED_FRAUD' group by order_item_product_id )r on p. product_id = r. order_item_product_id order by r. revenue desc limit 10;
 SQL engine. Impala")
CLOUDERA IMPALA Impala is an open source Massively Parallel Processing (MPP) SQL engine. Impala doesn’t require data to be moved or transformed prior to processing. So, it can handle Hive tables and give performance gain (Impala is 6 to 69 times faster than Hive) To refresh Impala to get new Hive tables run the next command impala-shell invalidate metadata; To list the available tables show tables; Now you can run the same Hive SQL commands !

EXAMPLE 3 Copy temperature. csv file from HD to new HDFS directory “temp” then load this file inside new Hive table hadoop fs -mkdir -p /user/cloudera/temp hadoop fs -put /var/www/html/temperature. csv /user/cloudera/temp Create Hive table based on CVS file hive> Create database weather; CREATE EXTERNAL TABLE IF NOT EXISTS weather. temperature ( place STRING COMMENT 'place', year INT COMMENT 'Year', month STRING COMMENT 'Month', temp FLOAT COMMENT 'temperature') ROW FORMAT DELIMITED FIELDS TERMINATED BY ', ' LINES TERMINATED BY 'n' STORED AS TEXTFILE LOCATION '/user/cloudera/temp/';

EXAMPLE 4 Using HUE create a workflow using Oozie to move data from my. SQL/CSV files to Hive Step 1: get the virtual machine IP using ifconfig Step 2: navigate to the http: //IP: 8888 , to get HUE login screen (cloudera/cloudera)

Step 3: Open Oozie: Workflows>Editors>Workflows> then click “create” button
 Hive 2 Script (New) Sqoop Shell SSH HDSF FS")
OOZIE ICONS Hive Script (old) Hive 2 Script (New) Sqoop Shell SSH HDSF FS
 delete HDFS folder 2) Copy my. Sql table as text")
Simple Oozie workflow 1) delete HDFS folder 2) Copy my. Sql table as text file to HDFS 3) Create Hive table based on this text file

ADD WORKFLOW SCHEDULE

SETUP WORKFLOW SETTINGS Workflow can contains some variables To define new variable ${Variable} Sometimes you need to define hive libpath in HUE to work with hive ozzie. libpath : /user/oozie/share/lib/hive
5870f65bfd9cba28275bb1c503d7939e.ppt