

af4055cc071696608dced15d3be80e1e.ppt
- Количество слайдов: 49
 Genomics: Gene prediction and Annotations Kishor K. Shende Information Officer Bioinformatics Center, Barkatullah University Bhopal
Genomics: Gene prediction and Annotations Kishor K. Shende Information Officer Bioinformatics Center, Barkatullah University Bhopal
 Gene Prediction Strategies TAA TAG TGA Prokaryotes Gene Architecture Initiation -36 -10 ATG Protein 1 Promoter Protein 2 Protein 3 Termination Exon-2 Termination Gene Regulatory Seq. ATG Initiation Exon-1 Intron-1 Splicing Sites Eukaryotes Gene Architecture TAA TAG TGA
Gene Prediction Strategies TAA TAG TGA Prokaryotes Gene Architecture Initiation -36 -10 ATG Protein 1 Promoter Protein 2 Protein 3 Termination Exon-2 Termination Gene Regulatory Seq. ATG Initiation Exon-1 Intron-1 Splicing Sites Eukaryotes Gene Architecture TAA TAG TGA
 Codon Usage Tables Ø Each amino acid can be encoded by several codons Ø Each organism has characteristic pattern of codon usage
Codon Usage Tables Ø Each amino acid can be encoded by several codons Ø Each organism has characteristic pattern of codon usage
 Problems in Gene Prediction Ø Distinguishing Pseudogenes from Genes Ø Exon-Intron Structure in Eukaryotes, Exon flanking regions – not very well conserved Ø Alternative Splicing – Shuffling of Exons Ø Genes can overlap each other and occur on different strand of DNA
Problems in Gene Prediction Ø Distinguishing Pseudogenes from Genes Ø Exon-Intron Structure in Eukaryotes, Exon flanking regions – not very well conserved Ø Alternative Splicing – Shuffling of Exons Ø Genes can overlap each other and occur on different strand of DNA
 Gene Identification 1. Homology Based Gene prediction Ø Sequence Similarity Search against gene database using BLAST and FAST searching tools Ø EST (Expressed Sequence Tags) similarity search 2. Ab initio Gene Prediction Ø Prokaryotes - ORF finding Ø Eukaryotes - Promoter prediction - Start-Stop codon prediction - Splice site Prediction (Exon-Intron and Intron –Exon) - Poly. A signal prediction
Gene Identification 1. Homology Based Gene prediction Ø Sequence Similarity Search against gene database using BLAST and FAST searching tools Ø EST (Expressed Sequence Tags) similarity search 2. Ab initio Gene Prediction Ø Prokaryotes - ORF finding Ø Eukaryotes - Promoter prediction - Start-Stop codon prediction - Splice site Prediction (Exon-Intron and Intron –Exon) - Poly. A signal prediction
 ORF Finding in Prokaryotes Easier due to ………. . Ø Small Genome have high gene density (Haemophilus influenza – 85% genic) Ø No Introns or Few Introns Ø Operons - One Transcript, many genes Ø Open Reading Frames (ORF) - Contigous set of codons, start with Met-codon, ends with stop codon
ORF Finding in Prokaryotes Easier due to ………. . Ø Small Genome have high gene density (Haemophilus influenza – 85% genic) Ø No Introns or Few Introns Ø Operons - One Transcript, many genes Ø Open Reading Frames (ORF) - Contigous set of codons, start with Met-codon, ends with stop codon
 1. ORF Findings: Ø Simplest method Ø Length of DNA sequence that contains a contiguous set of codons, each of which specifies an Amino Acid Ø Six possible reading frames Start Codon Sense Strand Antisense Strand 2 3 A T G C C A T C A G T 3’ 1 G C C A T T G T A 5’ 3 Position 2 Position 1 Central Dogma DNA 5’ m. RAN 2 1 Start Codon Protein 3’
1. ORF Findings: Ø Simplest method Ø Length of DNA sequence that contains a contiguous set of codons, each of which specifies an Amino Acid Ø Six possible reading frames Start Codon Sense Strand Antisense Strand 2 3 A T G C C A T C A G T 3’ 1 G C C A T T G T A 5’ 3 Position 2 Position 1 Central Dogma DNA 5’ m. RAN 2 1 Start Codon Protein 3’
 ORF Prediction: Based on Position of Start Codon & Stop Codon Start Codon A U ORF Stop Codon U G OR OR Protein Coding Region G A U A G No Protein: Code for Protein Due to the Presence of many in-frame stop codons
ORF Prediction: Based on Position of Start Codon & Stop Codon Start Codon A U ORF Stop Codon U G OR OR Protein Coding Region G A U A G No Protein: Code for Protein Due to the Presence of many in-frame stop codons
 Example of ORF There are six possible ORFs in each sequence for both directions of transcription.
Example of ORF There are six possible ORFs in each sequence for both directions of transcription.
 Difficulty in ORF Prediction: 1. Prokaryotes & Viruses: Presence of multiple genes on m. RNA and Overlapping genes in which two different proteins may be encoded in different reading frames of the same m. RNA 2. Eukaryotes: Protein coding region (Exon) is followed by non-coding region (Intron) 3. Differential m. RNA splicing create different m. RNA, hence different proteins 4. Variation in Genetic Code from Universal code Reliability of ORF Prediction: Characteristics of ORF regions 1. Ordered list of specific codons that reflects the evolutionary origin of the gene and constraints associated with gene expressions 2. Characteristics pattern of use of synonymous codons i. e. codons that stands for same Amino Acid 3. In Eukaryotes strong preferences for codon pairs at Intron-Exon or Exon-Intron junction 4. High genome content of GC have a strong bias of G & C in the third codon positions
Difficulty in ORF Prediction: 1. Prokaryotes & Viruses: Presence of multiple genes on m. RNA and Overlapping genes in which two different proteins may be encoded in different reading frames of the same m. RNA 2. Eukaryotes: Protein coding region (Exon) is followed by non-coding region (Intron) 3. Differential m. RNA splicing create different m. RNA, hence different proteins 4. Variation in Genetic Code from Universal code Reliability of ORF Prediction: Characteristics of ORF regions 1. Ordered list of specific codons that reflects the evolutionary origin of the gene and constraints associated with gene expressions 2. Characteristics pattern of use of synonymous codons i. e. codons that stands for same Amino Acid 3. In Eukaryotes strong preferences for codon pairs at Intron-Exon or Exon-Intron junction 4. High genome content of GC have a strong bias of G & C in the third codon positions
 3 Test of ORF First Test: It is based on an unusual type of sequence variation that is found in ORF have been devised to variety that a predicted ORF is in fact likely to encode a protein Second Test: It is analyzed, to determine whether the codon in the ORF correspond to these used in other genes of the same organism Third Test: ORF may be translated into an amino acid sequence and the resulting sequence then compound to the databases of existing sequence
3 Test of ORF First Test: It is based on an unusual type of sequence variation that is found in ORF have been devised to variety that a predicted ORF is in fact likely to encode a protein Second Test: It is analyzed, to determine whether the codon in the ORF correspond to these used in other genes of the same organism Third Test: ORF may be translated into an amino acid sequence and the resulting sequence then compound to the databases of existing sequence
 Repeated Sequence Elements and Nucleosome Structure 1. Eukaryotic DNA is wrapped around histon-protein complexes 2. Some base pairs in the major or minor grooves of the DNA molecules face the nucleosome surface 3. Other pair face outside of the structures 4. Nucleosome located in the promoter regions are remodeled in a manner that can influence the availability of binding sites for regulatory proteins making them more or less available Hidden Morkov Model (HMM) of Eukaryotic Internal Exon Computational Background: Repeated patterns of sequence have been found in the Introns and Exons and near the start site of Transcriptuion of Eukaryotic genes Bending Pattern: Bending is influenced by 1. Repeated pattern i. e. not T, A or G, G 2. AA/TT dinucleotide
Repeated Sequence Elements and Nucleosome Structure 1. Eukaryotic DNA is wrapped around histon-protein complexes 2. Some base pairs in the major or minor grooves of the DNA molecules face the nucleosome surface 3. Other pair face outside of the structures 4. Nucleosome located in the promoter regions are remodeled in a manner that can influence the availability of binding sites for regulatory proteins making them more or less available Hidden Morkov Model (HMM) of Eukaryotic Internal Exon Computational Background: Repeated patterns of sequence have been found in the Introns and Exons and near the start site of Transcriptuion of Eukaryotic genes Bending Pattern: Bending is influenced by 1. Repeated pattern i. e. not T, A or G, G 2. AA/TT dinucleotide
 Ab initio gene prediction Predictions are based on the observation that gene DNA sequence is not random: - Gene-coding sequence has start and stop - codons. Each species has a characteristic pattern of synonymous codon usage. Non-coding ORFs are very short. Gene would correspond to the longest ORF. These methods look for the characteristic features of genes and score them high.
Ab initio gene prediction Predictions are based on the observation that gene DNA sequence is not random: - Gene-coding sequence has start and stop - codons. Each species has a characteristic pattern of synonymous codon usage. Non-coding ORFs are very short. Gene would correspond to the longest ORF. These methods look for the characteristic features of genes and score them high.
 Ab initio gene prediction methods n n Gene. Scan – Fourier transform of DNA sequence to find characteristic patterns. Gene. Parser – predicts the most likely combination of exons/introns. Dynamic programming. Gene. Mark – mostly for prokaryotes, Hidden Markov Models. Also for Eukaryotes Grail II – predicts exons, promoters, Poly(A) sites. Neural network plus dynamic programming.
Ab initio gene prediction methods n n Gene. Scan – Fourier transform of DNA sequence to find characteristic patterns. Gene. Parser – predicts the most likely combination of exons/introns. Dynamic programming. Gene. Mark – mostly for prokaryotes, Hidden Markov Models. Also for Eukaryotes Grail II – predicts exons, promoters, Poly(A) sites. Neural network plus dynamic programming.
 Gene Preference Score : Important indicator of coding region Observation: frequencies of codons and codon pairs in coding and non -coding regions are different. Given a sequence of codons: and assuming independence, the probability of finding coding region: The probability of finding sequence “C” in non-coding regions: The gene preference score:
Gene Preference Score : Important indicator of coding region Observation: frequencies of codons and codon pairs in coding and non -coding regions are different. Given a sequence of codons: and assuming independence, the probability of finding coding region: The probability of finding sequence “C” in non-coding regions: The gene preference score:
 – sequenced") Confirming gene location using EST libraries n n Expressed Sequence Tags (ESTs) – sequenced short segments of c. DNA. They are organized in the database “Uni. Gene”. If region matches ESTs with high statistical significance, then it is a gene or pseudogene.
Confirming gene location using EST libraries n n Expressed Sequence Tags (ESTs) – sequenced short segments of c. DNA. They are organized in the database “Uni. Gene”. If region matches ESTs with high statistical significance, then it is a gene or pseudogene.
 – nucleotides, which are correctly predicted to be") Gene prediction accuracy True positives (TP) – nucleotides, which are correctly predicted to be within the gene. Actual positives (AP) – nucleotides, which are located within the actual gene. Predicted positives (PP) – nucleotides, which are predicted in the gene. Sensitivity = TP / AP Specificity = TP / PP
Gene prediction accuracy True positives (TP) – nucleotides, which are correctly predicted to be within the gene. Actual positives (AP) – nucleotides, which are located within the actual gene. Predicted positives (PP) – nucleotides, which are predicted in the gene. Sensitivity = TP / AP Specificity = TP / PP
 Gene prediction accuracy
Gene prediction accuracy
 Common Difficulties of Gene Prediction n First and last exons difficult to annotate because they contain UTRs. Smaller genes are not statistically significant so they are thrown out. Algorithms are trained with sequences from known genes which biases them against genes about which nothing is known.
Common Difficulties of Gene Prediction n First and last exons difficult to annotate because they contain UTRs. Smaller genes are not statistically significant so they are thrown out. Algorithms are trained with sequences from known genes which biases them against genes about which nothing is known.
 Genome Analysis for Gene Prediction Genome analysis Genome – the sum of genes and intergenic sequences of haploid cell. The value of genome sequences lies in their annotation n n Annotation – Characterizing genomic features using computational and experimental methods Genes: levels of annotation n Gene Prediction – Where are genes? What do they encode? What proteins/pathways involved in?
Genome Analysis for Gene Prediction Genome analysis Genome – the sum of genes and intergenic sequences of haploid cell. The value of genome sequences lies in their annotation n n Annotation – Characterizing genomic features using computational and experimental methods Genes: levels of annotation n Gene Prediction – Where are genes? What do they encode? What proteins/pathways involved in?
 Flowchart: Gene Prediction Process Genomic DNA Sequence Analyze the Regulatory Sequences in the Gene 1. 2. 3. 4. Translate in all six Reading Frames & compare to Protein sequence database 5. 6. 7. 8. 2. Perform database similarity search of EST database of some Organism Use Gene Prediction program to locate genes
Flowchart: Gene Prediction Process Genomic DNA Sequence Analyze the Regulatory Sequences in the Gene 1. 2. 3. 4. Translate in all six Reading Frames & compare to Protein sequence database 5. 6. 7. 8. 2. Perform database similarity search of EST database of some Organism Use Gene Prediction program to locate genes
 Try this first using BLAST & FASTA PSI-BLAST, PHI-BLAST & Other BLAST/FAS TA programs & EST, c. DNA database search Compare with Genome of Other Organism ORF Finding Promoter, Splicing Site, Poly-A tail, 5’ TUR, 3’ UTR
Try this first using BLAST & FASTA PSI-BLAST, PHI-BLAST & Other BLAST/FAS TA programs & EST, c. DNA database search Compare with Genome of Other Organism ORF Finding Promoter, Splicing Site, Poly-A tail, 5’ TUR, 3’ UTR
 Let’s have some Practice on Gene Finding using some Gene Finding Programs 1. Gen. Mark (http: //exon. gatech. edu/Gene. Mark/ ) 2. Genscan (http: //genes. mit. edu/GENSCAN. html ) 3. Grail II (http: //compbio. ornl. gov/Grail-1. 3/ ) 4. Gene Finder in Glimmer. M (http: //www. tigr. org/tdb/glimmerm/glmr_form. ht ml )
Let’s have some Practice on Gene Finding using some Gene Finding Programs 1. Gen. Mark (http: //exon. gatech. edu/Gene. Mark/ ) 2. Genscan (http: //genes. mit. edu/GENSCAN. html ) 3. Grail II (http: //compbio. ornl. gov/Grail-1. 3/ ) 4. Gene Finder in Glimmer. M (http: //www. tigr. org/tdb/glimmerm/glmr_form. ht ml )
 HMMgene - Prediction of genes in vertebrate and C. elegans Gene Discovery Page Frame. Plot - protein-coding region prediction tool for high GC-content bacteria t. RNAscan-SE Search for transfer RNA genes in genomic sequence NETGENE - Predict splice sites in human genes ORF Finder BCM Gene Finder Grail Genemark Genie: A Gene Finder Based on Generalized Hidden Markov Models GENSCAN - predict complete gene structures Splice Site Prediction by Neural Network Procrustes Gene. Primer Gen. Lang MZEF Gene Finder Webgene - Tools for prediction and analysis of protein-coding gene structure MAR-Finder - Nuclear matrix attachment region prediction Glimmer bacterial/archael gene finder
HMMgene - Prediction of genes in vertebrate and C. elegans Gene Discovery Page Frame. Plot - protein-coding region prediction tool for high GC-content bacteria t. RNAscan-SE Search for transfer RNA genes in genomic sequence NETGENE - Predict splice sites in human genes ORF Finder BCM Gene Finder Grail Genemark Genie: A Gene Finder Based on Generalized Hidden Markov Models GENSCAN - predict complete gene structures Splice Site Prediction by Neural Network Procrustes Gene. Primer Gen. Lang MZEF Gene Finder Webgene - Tools for prediction and analysis of protein-coding gene structure MAR-Finder - Nuclear matrix attachment region prediction Glimmer bacterial/archael gene finder
 Promoter Region, Transscription Factor and Signals 1. TRANSFAC - Transcription Factor database TFD Transcription Factor Database Trans. Term - A Translational Signal Database PLACE - a database of plant cis-acting regulatory DNA elements NNPP: Promoter Prediction by Neural Network Fast. M/Model. Inspector TFSEARCH Mat. Ind and Mat. Inspector Transcription Element Search Software (TESS) Core. Promoter (Core-Promoter Prediction Program) Gene Express - analysis of genomic regulatory sequences Signal Scan Promoter. Inspector Promoter Scan II Pol 3 scan Target. Finder - finds DNA-binding proteins.
Promoter Region, Transscription Factor and Signals 1. TRANSFAC - Transcription Factor database TFD Transcription Factor Database Trans. Term - A Translational Signal Database PLACE - a database of plant cis-acting regulatory DNA elements NNPP: Promoter Prediction by Neural Network Fast. M/Model. Inspector TFSEARCH Mat. Ind and Mat. Inspector Transcription Element Search Software (TESS) Core. Promoter (Core-Promoter Prediction Program) Gene Express - analysis of genomic regulatory sequences Signal Scan Promoter. Inspector Promoter Scan II Pol 3 scan Target. Finder - finds DNA-binding proteins.
 Overview GENE PREDICTION TOOLS
Overview GENE PREDICTION TOOLS
 Gen. Mark Borodovsky's Bioinformatics Group at the") TM (http: //exon. gatech. edu/Gene. Mark/ ) Gen. Mark Borodovsky's Bioinformatics Group at the Georgia Institute of Technology, Atlanta, Georgia
TM (http: //exon. gatech. edu/Gene. Mark/ ) Gen. Mark Borodovsky's Bioinformatics Group at the Georgia Institute of Technology, Atlanta, Georgia
 Referen ce: Lukashin A. and Borodovsky") Gene. Mark. hmm for Prokaryotes (Version 2. 4) Referen ce: Lukashin A. and Borodovsky M. , Gene. Mark. hmm: new solutions for gene finding, NAR, 1998, Vol. 26, No. 4, pp. 1107 -1115 Bacterial and archaeal gene prediction, you can use the parallel combination of the Gene. Mark and Gene. Mark. hmm programs Heuristic Approach for Gene Prediction in Prokaryotes If the DNA sequence of interest belongs to a species whose name is not in the list of available models, use the Heuristic models option Self Training Program of Genmarks If the sequence is longer than 1 Mb, generate models with the selftraining program Gene. Mark. S
Gene. Mark. hmm for Prokaryotes (Version 2. 4) Referen ce: Lukashin A. and Borodovsky M. , Gene. Mark. hmm: new solutions for gene finding, NAR, 1998, Vol. 26, No. 4, pp. 1107 -1115 Bacterial and archaeal gene prediction, you can use the parallel combination of the Gene. Mark and Gene. Mark. hmm programs Heuristic Approach for Gene Prediction in Prokaryotes If the DNA sequence of interest belongs to a species whose name is not in the list of available models, use the Heuristic models option Self Training Program of Genmarks If the sequence is longer than 1 Mb, generate models with the selftraining program Gene. Mark. S
 Gene Prediction in Eukaryotes Eukaryotic gene prediction: Use the parallel combination of the Gene. Mark and Gene. Mark. hmm
Gene Prediction in Eukaryotes Eukaryotic gene prediction: Use the parallel combination of the Gene. Mark and Gene. Mark. hmm
 Select the Related Organisms from this list
Select the Related Organisms from this list
 Gene Prediction in EST and c. DNA To analyze ESTs and c. DNAs
Gene Prediction in EST and c. DNA To analyze ESTs and c. DNAs
 Gene Prediction in Viruses Viral gene prediction through virus database “VIOLIN”
Gene Prediction in Viruses Viral gene prediction through virus database “VIOLIN”
 Gen. Mark Output
Gen. Mark Output
 Gen. Mark Output
Gen. Mark Output
 New GENSCAN Web Server at MIT
New GENSCAN Web Server at MIT
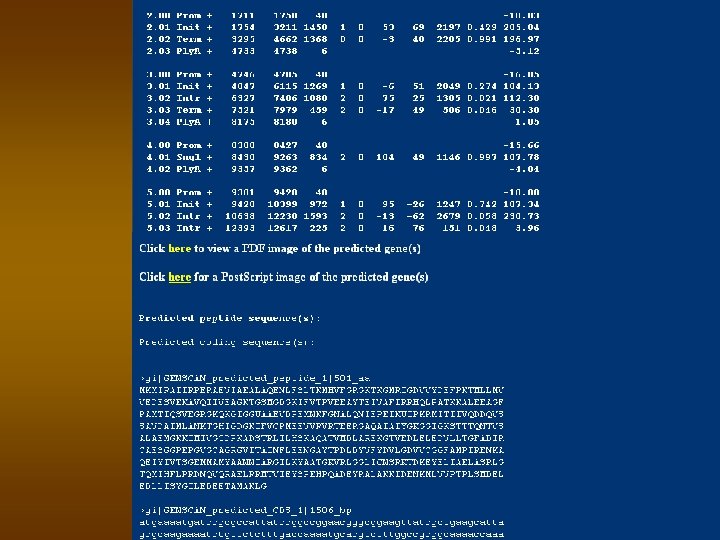
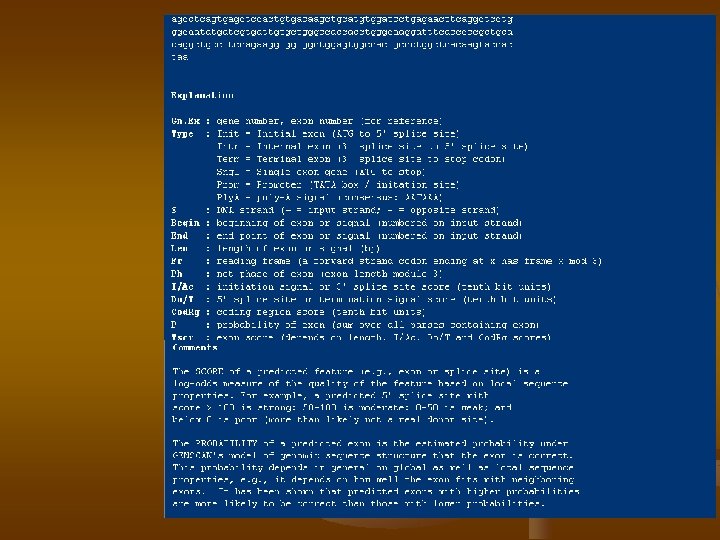
 Genescan Output
Genescan Output
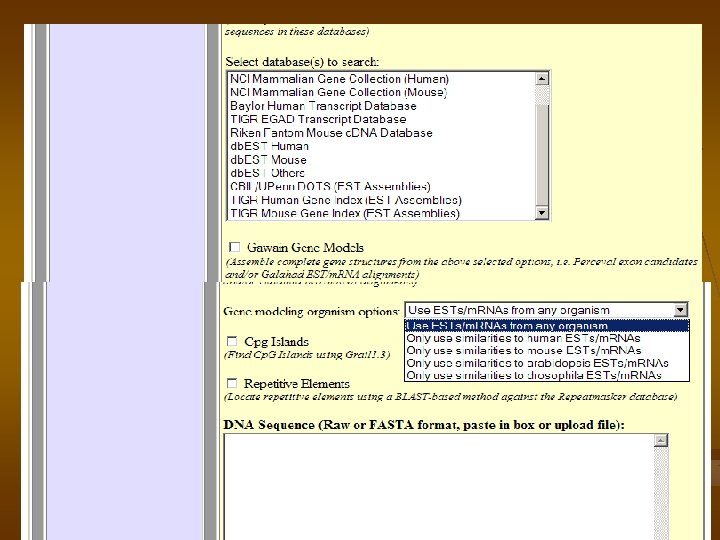
 Grail. EXP 1. Locate protein coding genes within DNA sequence, 2. Locate EST/m. RNA alignments, 3. Locate certain types of promoters, polyadenylation sites, Cp. G islands, and repetitive elements. Grail. EXP is a gene finder…………. 1. EST alignment utility 2. exon prediction program, 3. a promoter/polya recognizer, 4. a Cp. G island finer, 5. a repeat masker,
Grail. EXP 1. Locate protein coding genes within DNA sequence, 2. Locate EST/m. RNA alignments, 3. Locate certain types of promoters, polyadenylation sites, Cp. G islands, and repetitive elements. Grail. EXP is a gene finder…………. 1. EST alignment utility 2. exon prediction program, 3. a promoter/polya recognizer, 4. a Cp. G island finer, 5. a repeat masker,
 Grail. EXP Predicts exons, genes, promoters, polyas, Cp. G islands, EST similarities, and repetitive elements within DNA sequence
Grail. EXP Predicts exons, genes, promoters, polyas, Cp. G islands, EST similarities, and repetitive elements within DNA sequence
 Glimmer. M: http: //www. tigr. org/tdb/glimmerm/glmr_form. html A system for finding genes in microbial DNA, especially the genomes of bacteria and archaea. Glimmer (Gene Locator and Interpolated Markov Modeler) uses interpolated Markov models (IMMs) to identify the coding regions and distinguish them from noncoding DNA. Glimmer. HMM: For Eukaryotic Organisms Genesplicer: Fast, flexible system for detecting splice sites in the genomic DNA of various eukaryotes.
Glimmer. M: http: //www. tigr. org/tdb/glimmerm/glmr_form. html A system for finding genes in microbial DNA, especially the genomes of bacteria and archaea. Glimmer (Gene Locator and Interpolated Markov Modeler) uses interpolated Markov models (IMMs) to identify the coding regions and distinguish them from noncoding DNA. Glimmer. HMM: For Eukaryotic Organisms Genesplicer: Fast, flexible system for detecting splice sites in the genomic DNA of various eukaryotes.
 GLimmer. M Gene Finder
GLimmer. M Gene Finder
 Kishor K. Shende Information Officer Bioinformatics Center, Barkatullah University Bhopal
Kishor K. Shende Information Officer Bioinformatics Center, Barkatullah University Bhopal