1dab0ae2f49a1711cbb9dd0d4c5cd65f.ppt
- Количество слайдов: 57



Genetics in Epidemiology Nazarbayev University July 2012 Jan Dorman, Ph. D University of Pittsburgh, PA, USA jsd@pitt. edu

Genetics in Epidemiology • Is important because – It focuses on heritable & non-modifiable determinants of disease – It allows examination of gene-gene & geneenvironment interactions – It can contribute to personalized medicine • Is being transformed because – Human Genome Project is complete – Genetic variation can be now examined across the entire genome at a very low cost – Contribution of GWAS has been enormous in terms of identifying disease-susceptibility genes

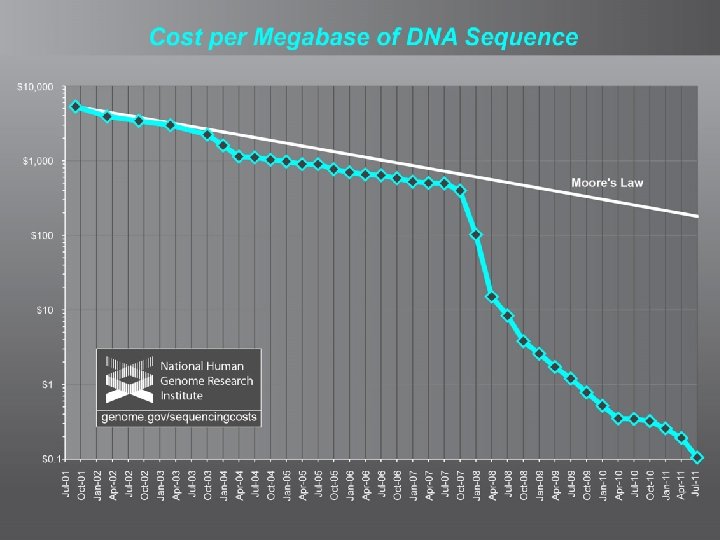
Human Genome Project • February 2010 marked the 10 th anniversary of the completion of the human genome project • Initial sequence was finished early because of advancements in genome sequence technology • Resulted in drastically reduced labor & delivery costs

Human Genome Sequencing Costs • 2000 – Human Genome Project – $3 billion • 2007 – James Watson – $2 million • 2009 – Illumina & Helicos – $50, 000 • 2010 – Illumina Hi. Seq – $10, 000 • 2014 – Multiple companies – $1, 000
?")
Genetics in Epidemiology • Is there evidence of familial aggregation of the disorder (phenotype)? – Is a positive family history an independent risk factor for the disorder? • For many chronic disorders, a positive family history is associated with odds ratios between 2 -6 • Is there evidence of heritability? – A heritability of 50% indicates that ~ ½ of the variation in disease risk in a population is due to genetics

J Intern Med 2008; 263: 16

Candidate Gene Approach • Are there potential candidate genes? – Genes that are selected based on known biological, physiological, or functional relevance to the phenotype under investigation – Approach is limited by its reliance on existing knowledge about the biology of disease – Associations may be population-specific • E. g. , type 2 diabetes – Genes encoding molecules known to primarily influence pancreatic β-cell or insulin action • ABCC 8 (sulphonylurea receptor), INSR, etc. PLOS Bio 2003; 1: 41
 – Hypothesis: common genetic variants (>5%) ;")
Alternative Approach • Genome-wide association studies (GWAS) – Hypothesis: common genetic variants (>5%) ; common diseases (traits) • Limited number of variants, each with a small effect • No a priori hypotheses • Power to identify rare variants (1 -5%) is limited – First publication was in 2005 • Complement factor H & age-related macular degeneration – Require • Large, well-characterized populations • Genotyping across the entire genome • Sophisticated data analysis – collaborate on this!!

Monogenetic vs. Common Disorders

GWAS • 2 tiered approach – 1 st tier: genotyping identifies the ‘discovery set’ – 2 nd tier: discovery set genotyped in another population • Replication is a requirement for publication – 3 rd tier: rule out false positives & false negatives • Requires consortia • Possible because – High-density genotype platforms • By 2007 – chips contained 500, 000 – 1, 000 markers – DNA samples were available from wellcharacterized epidemiological cohorts

GWAS Example NEJM 2010; 362: 166

GWAS Example NEJM 2010; 362: 166

GWAS Example NEJM 2010; 362: 166
 associations – Most alleles are common (>5%)")
GWAS • Have identified novel gene-disease (trait) associations – Most alleles are common (>5%) – Most have small effect sizes (OR ~1. 5) • Are providing insights into pathways of complex diseases

Published Genome-Wide Associations published for 249 traits NHGRI GWA Catalog www. genome. gov/GWAStudies

Genetics Review

Anatomy of the Cell

Chromosomes, Genes & DNA • Somatic cells are diploid - 46 chromosomes – 22 pairs autosomes; 1 pair sex chromosomes • Each pair of autosomes is homologous – Contains the same genes in the same order – 1 is maternal, the other is paternal • Chromosome are composed of deoxyribonucleic acid (DNA) – Genome contains 3 billion base pairs (haploid) – ~1% encode proteins • Genes are located on chromosomes

Human Karyogram

Figure of a Chromosome

DNA Double Helix

Base Pairs of a Double Helix T C A G

Structure of a Gene A gene is a functional unit that includes introns, exons enhancer & promoter sequences & untranslated sequences at the 5’ & 3’ ends

Transcription Results in m. RNA

Primary Transcript

m. RNA Processing

From Genes to Proteins via m. RNA • Proteins consist of 1+ polypeptide chains • Polypeptides chains are made of amino acids • There are 20 amino acids – Their order in is determined by the m. RNA sequence read in triplet • Genetic code – 64 combinations of 3 bases called codons – 3 are stop codons (UAA, UGA, UAG) • Genetic code is degenerate • Genetic code is universal

Genetic Code

m. RNA Determines AA Sequence

Translation is Protein Synthesis

Post-Translation Modifications

Advancements in Biotechnology

Original Method for DNA Sequencing
 • Revolutionized molecular genetics • Exploits the in vivo processes")
Polymerase Chain Reaction (PCR) • Revolutionized molecular genetics • Exploits the in vivo processes of DNA replication to copy short DNA fragments in vitro within a few hours • Exponential increase of target DNA sequences • Highly sensitive – need small amount of template DNA • DNA ‘photocopier’

PCR - Cycle 1 5’ A C G T T A C C G T G A A C G T C T T A 3’ Denaturation, ~30 seconds H bonds dissolve at 95 o. C 3’ T G C A A T G G C A C T T G C A G A A T 5’

PCR - Cycle 1 5’ A C G T T A C C G T G A A C G T C T T A 3’ 3’ C A G A AT 5’ Anneal primers, ~30 seconds at 35 -65 o. C Temperature determined by sequence / length 5’ A C G T T A 3’ 3’ T G C A A T G G C A C T T G C A G A A T 5’

PCR - Cycle 1 5’ A C G T T A C C G T G A A C G T C T T A 3’ T G C A A T G G C A C T T G C A G A A T 5’ Extension of Primers, ~30 seconds at 70 -75 o. C Taq polymerase - thermostable 5’ A C G T T A C C G T G A A C G T C T T A 3’ T G C A A T G G C A C T T G C A G A A T 5’

Post-Genome Era
 • Tandem repeat Sequences – Microsatellites")
Human Genetic Variation • Single nucleotide polymorphisms (SNPs) • Tandem repeat Sequences – Microsatellites (<8 bp) – Minisatellites (VNTRs; 8 -100 bp) • Copy number variants (CNVs; 1 Kb – 1 Mb) • Insertions – deletions (indels; 100 bp – 1 Kb) • Note: size limitations are arbitrary – no biological basis & definitions are not consistent across studies

SNPs • • ~10 million SNPs in human genome & counting Most common type of genetic variation 2 alleles; e. g. , A → T Occurs across the entire genome & in stable regions • Many SNPs are in linkage disequilibrium – SNPs close together are more likely to travel together in a block than SNPs far apart – Can use 1 ‘tagging’ SNP per block – cost effective

Linkage Disequilibrium Haplotype Block NEJM 2007; 356: 1094

SNPs ‘Tag’ Haplotype Blocks NEJM 2007; 356: 1094

International Hap. Map • Emerged as next logical step after sequencing human genome • Goal was to create a public genome-wide database of common genetic variants • Genotyped SNPs from 270 samples from: – Nigeria, Utah, Han Chinese, Japanese • Phase I – Typed 1 million common SNPs (>5%) to characterize LD patterns • Phase II – Typed 3 million rare SNPs (1 -5%)

DNA Microarray Used to genotype 500, 000 – 1+ million SNPs

International Hap. Map • Where are the SNPs? – – – 12% occur in protein coding regions 8% occur in gene regulatory regions 40% occur in non-coding introns 40% occur in intergenic sequences Regions of high linkage disequilibrium are similar across populations • Hap. Map was instrumental in facilitating GWAS
 –")
Tandem Repeat Sequences • 100, 000+ TRSs in human genome • Microsatellites (VNTRs) – Repeat units (8 – 100 bp) • Minisatellites – Repeat units (2 – 8 bp) – Eg. , CAGCAGCAGCGACAG • More than 200 diseases genes indentified – E. g. , Huntington’s disease, Fragile X syndrome

Copy Number Variants • Size is 1 Kb to 1 Mb – Duplications or deletions • Less is known about CNV – Term was introduced in 2004 • Are ubiquitous & reflect 12% of human genome • May span multiple genes • May change gene dosage or effect transcription and translation • Are creating a CNV map along with Hap. Map • Associated with autism, schizophrenia, lupus, Crohn’s disease, rheumatoid arthritis

Copy Number Variants

Indels • Insertions & deletions – Size 100 bp to 1 Kb – Millions in genome – Introduced in 2006 • Phenotype may depend on gene dosage • May occur within genes or in promoter • Also creating an indel map

Consequences of Genetic Variation • No change – In a non-coding region – In a coding region - genetic code is degenerate • • Change in 1 amino acid of a protein Change in multiple amino acids of a protein A truncated protein Change in gene expression – In a regulatory region or splice site • Next generation GWAS will be based on markers other than SNPs – Tandem repeats, CNV, indels

Genetic Variation Databases Database Content Address db. SNPs covering the human genome http: //www. ncbi. nlm. nih. gov/projects/SNPs Hap. Map Catalog of variants from http: //hapmap. org Hap. Map Project 1000 Genome Project Extension of Hap. Map – www. 1000 genomes. org aim to catalog 95% of variants with 1% freq UCSC Genome Bioinformatics Reference human genome sequence with annotation http: //genome. ucsc. edu Ensembl Genome browser, annotation, comparative genomics http: //www. ensembl. org /index. html

Genetic Variation Databases Database Content Address Gene. Cards Database of human http: //www. genecards. or genes linked to relevant g databases Pharm. GKB SNPs involved in drug metabolism DGV Database of Genomic http: //projects. tcag. ca/var Variants, including CNV iation SCAN SNP & CNV annotation http: //www. scandb. org/n based on gene function ewinterface & expression OMIM Online Mendelian Inheritance in Man – over 12, 000 genes http: //www. pharmgkb. org http: //www. ncbi. nlm. nih. g ov/sites/entrez? db=omim

Genetic Variation Databases Database Hu. GE navigator Content Human genome epidemiology knowledge base Address http: //hugenavigator. net/ Hu. GENavigator/home. do Best Pract Res Clin Endo Metab, 2012. 26: 119.

Collecting DNA • Sources of DNA – – Blood samples Buccal brushes Saliva samples Dried blood spots • Depends on – – – Conditions at time of collection Resources available to process samples What other biological samples will be collected Long & short term storage Quality control

Saliva vs. Blood Samples • Considerations – – – Lower cost More convenient & acceptable to patients Increases compliance Lower mean yield of DNA But quality is comparable No difference in success from high throughput genotyping

Other Considerations • Informed consent - What analysis can be performed now? What analysis can be performed in the future? Who has control of the specimen? Do you need to ‘re-consent’ the participants due to IRB changes? - Will you inform participants of results?
1dab0ae2f49a1711cbb9dd0d4c5cd65f.ppt