

de668b24f59bb4319f138dc748e0e872.ppt
- Количество слайдов: 40
 Gene Synthesis using DNAWorks Dr. David Hoover Helix Systems, SCB, CIT, NIH
Gene Synthesis using DNAWorks Dr. David Hoover Helix Systems, SCB, CIT, NIH
 Gene Synthesis Several methods • ligation - incredibly tedious and inefficient • Fok. I - sequence dependent (type IIs r. e. ) • serial cloning - sequence dependent • assembly or self-priming PCR
Gene Synthesis Several methods • ligation - incredibly tedious and inefficient • Fok. I - sequence dependent (type IIs r. e. ) • serial cloning - sequence dependent • assembly or self-priming PCR
 Gene Synthesis Methods Thermodynamically Balanced Conventional Thermodynamically Balanced Inside-Out
Gene Synthesis Methods Thermodynamically Balanced Conventional Thermodynamically Balanced Inside-Out
 Protein Expression Protein/Structure Independent Factors: • promoters and upstream elements • translational initiation and termination • m. RNA stability • codon bias Protein/Structure Dependent Factors: • folding and aggregation • proteolysis and degradation • secretion and localization
Protein Expression Protein/Structure Independent Factors: • promoters and upstream elements • translational initiation and termination • m. RNA stability • codon bias Protein/Structure Dependent Factors: • folding and aggregation • proteolysis and degradation • secretion and localization
 Codon Bias
Codon Bias
 Synthetic Genes Benefits: • Codon use optimized for host • Flexibility in subcloning • Ease of complex mutagenesis Problems: • Time consuming • Complicated • Error-prone
Synthetic Genes Benefits: • Codon use optimized for host • Flexibility in subcloning • Ease of complex mutagenesis Problems: • Time consuming • Complicated • Error-prone
 DNA 2. 0 (http: //www.") Commercial Sources Blue Heron Biotechnology (http: //www. blueheronbio. com) DNA 2. 0 (http: //www. dna 20. com/) Gene Script Corporation (http: //www. genscript. com/) Bio. Nexus Inc. (http: //www. genesynthesis. net/) Entelechon (http: //www. entelechon. com/) Gene. Art (http: //www. geneart. com/) Codon Devices (http: //www. codondevices. com/)
Commercial Sources Blue Heron Biotechnology (http: //www. blueheronbio. com) DNA 2. 0 (http: //www. dna 20. com/) Gene Script Corporation (http: //www. genscript. com/) Bio. Nexus Inc. (http: //www. genesynthesis. net/) Entelechon (http: //www. entelechon. com/) Gene. Art (http: //www. geneart. com/) Codon Devices (http: //www. codondevices. com/)
 Commerical Sources Typical costs: • $0. 79 - $3. 60 / bp • Complexities? • Intellectual property? • 800 bp = $1000 (Gene Script)
Commerical Sources Typical costs: • $0. 79 - $3. 60 / bp • Complexities? • Intellectual property? • 800 bp = $1000 (Gene Script)
") Genes From Scratch • • • oligos ~ $0. 20 / nt (NIH discount) PCR reagents ~ $2 / reaction sequencing ~ $20 / 600 bp electrophoresis ~ $3 / gel labor ~ $20 / hr GFP, 238 aa, 714 bp, 20 oligos, 1134 nt, 2 reactions, 2 gels, 4 sequences, ~10 hrs = $517
Genes From Scratch • • • oligos ~ $0. 20 / nt (NIH discount) PCR reagents ~ $2 / reaction sequencing ~ $20 / 600 bp electrophoresis ~ $3 / gel labor ~ $20 / hr GFP, 238 aa, 714 bp, 20 oligos, 1134 nt, 2 reactions, 2 gels, 4 sequences, ~10 hrs = $517
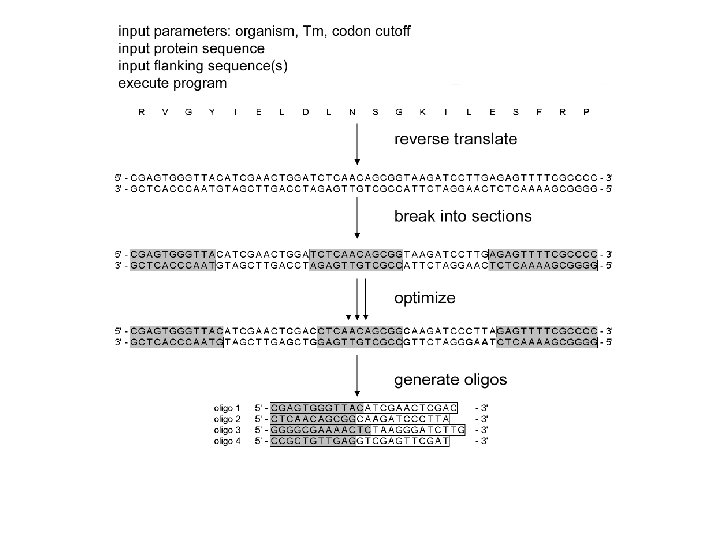
 How to design oligos reverse-translate protein into DNA, optimum codon usage break into fragments of equal overlap Tm optimize: • hairpins / m. RNA structure • repeats / mispriming • restriction site inclusion / exclusion • length
How to design oligos reverse-translate protein into DNA, optimum codon usage break into fragments of equal overlap Tm optimize: • hairpins / m. RNA structure • repeats / mispriming • restriction site inclusion / exclusion • length
 DNAWorks http: //helixweb. nih. gov/dnaworks/
DNAWorks http: //helixweb. nih. gov/dnaworks/
 DNAWorks Output 181 TCTGGTGAAGGCGAGGGTGACGCGACCTACGGTAAACTCTCAAAT agaccact TGCCATTTGAGAGTTTAAGTAGACGTGG <--- 4 S G E G D A T Y G K L T L K F I C T | | | | 7 ---> 241 ggttccttggccgaccctggttactaccttctcttacggtgttcag TGCCCGTTTGACGGCCAAGGAACCGGCTGG tc <--- 6 T G K L P V P W P T L V T T F S Y G V Q | | | |
DNAWorks Output 181 TCTGGTGAAGGCGAGGGTGACGCGACCTACGGTAAACTCTCAAAT agaccact TGCCATTTGAGAGTTTAAGTAGACGTGG <--- 4 S G E G D A T Y G K L T L K F I C T | | | | 7 ---> 241 ggttccttggccgaccctggttactaccttctcttacggtgttcag TGCCCGTTTGACGGCCAAGGAACCGGCTGG tc <--- 6 T G K L P V P W P T L V T T F S Y G V Q | | | |
 DNAWorks Options • Job Name • E-mail Address
DNAWorks Options • Job Name • E-mail Address
, H. sapiens, C.") DNAWorks Options Codon Frequency Table • E. coli (standard, class II), H. sapiens, C. elegans, D. melanogaster, M. musculus, P. pastoris, R. norvegicus, S. cerevesiae, X. laevis • Custom CFT
DNAWorks Options Codon Frequency Table • E. coli (standard, class II), H. sapiens, C. elegans, D. melanogaster, M. musculus, P. pastoris, R. norvegicus, S. cerevesiae, X. laevis • Custom CFT
 Gly Gly Glu Asp Val Val Ala Ala Arg Ser Lys GGG GGA GGT GGC GAG GAA GAT GAC GTG GTA GTT GTC GCG GCA GCT GCC AGG AGA AGT AGC AAG AAA 599428. 00 597986. 00 392298. 00 814464. 00 1441162. 00 1043166. 00 789799. 00 914677. 00 1028789. 00 257442. 00 399567. 00 528840. 00 271820. 00 579156. 00 672416. 00 1018345. 00 432954. 00 434655. 00 441137. 00 706723. 00 1163126. 00 879684. 00 16. 49 16. 45 10. 79 22. 41 39. 65 28. 70 21. 73 25. 16 28. 30 7. 08 10. 99 14. 55 7. 48 15. 93 18. 50 28. 02 11. 91 11. 96 12. 14 19. 44 32. 00 24. 20 0. 25 0. 16 0. 34 0. 58 0. 42 0. 46 0. 54 0. 46 0. 12 0. 18 0. 24 0. 11 0. 23 0. 26 0. 40 0. 21 0. 15 0. 24 0. 57 0. 43
Gly Gly Glu Asp Val Val Ala Ala Arg Ser Lys GGG GGA GGT GGC GAG GAA GAT GAC GTG GTA GTT GTC GCG GCA GCT GCC AGG AGA AGT AGC AAG AAA 599428. 00 597986. 00 392298. 00 814464. 00 1441162. 00 1043166. 00 789799. 00 914677. 00 1028789. 00 257442. 00 399567. 00 528840. 00 271820. 00 579156. 00 672416. 00 1018345. 00 432954. 00 434655. 00 441137. 00 706723. 00 1163126. 00 879684. 00 16. 49 16. 45 10. 79 22. 41 39. 65 28. 70 21. 73 25. 16 28. 30 7. 08 10. 99 14. 55 7. 48 15. 93 18. 50 28. 02 11. 91 11. 96 12. 14 19. 44 32. 00 24. 20 0. 25 0. 16 0. 34 0. 58 0. 42 0. 46 0. 54 0. 46 0. 12 0. 18 0. 24 0. 11 0. 23 0. 26 0. 40 0. 21 0. 15 0. 24 0. 57 0. 43
 • Codon Frequency Threshold") DNAWorks Options Parameters • Annealing Temperature • Oligo Length (random) • Codon Frequency Threshold (random, strict, scored) • Oligonucleotide, Na+/K+, Mg 2+ Concentrations • Number of Solutions • TBIO • No gaps in assembly
DNAWorks Options Parameters • Annealing Temperature • Oligo Length (random) • Codon Frequency Threshold (random, strict, scored) • Oligonucleotide, Na+/K+, Mg 2+ Concentrations • Number of Solutions • TBIO • No gaps in assembly
 DNAWorks Options Balancing act • Fast, simple, cheap? • Slow, complex, expensive? - reliable • Reusable and interchangeable oligos?
DNAWorks Options Balancing act • Fast, simple, cheap? • Slow, complex, expensive? - reliable • Reusable and interchangeable oligos?
 • Custom Site Screen") DNAWorks Options Others • Restriction Site Screen (non-degenerate, degenerate sequences) • Custom Site Screen (mind the format!) • Weights (experimental)
DNAWorks Options Others • Restriction Site Screen (non-degenerate, degenerate sequences) • Custom Site Screen (mind the format!) • Weights (experimental)
 • nucleotide (can be degenerate) •") DNAWorks Options Sequences • protein (X = stop) • nucleotide (can be degenerate) • almost any file format • reverse sequence • fix sequence in gap
DNAWorks Options Sequences • protein (X = stop) • nucleotide (can be degenerate) • almost any file format • reverse sequence • fix sequence in gap
 • Header • Initial") DNAWorks Output Web output • Input for DNAWorks (standalone version) • Header • Initial parameters • Optimization log • Final scores • Final summary
DNAWorks Output Web output • Input for DNAWorks (standalone version) • Header • Initial parameters • Optimization log • Final scores • Final summary
 DNAWorks Output Total output • Sequence blocks • CFT blocks • Pattern block • Trials • Final Summary
DNAWorks Output Total output • Sequence blocks • CFT blocks • Pattern block • Trials • Final Summary
 DNAWorks Output Trial outputs • Initial parameters • Final DNA sequence • Assembly • Final scores • Codon report • Histograms • Oligo sequences
DNAWorks Output Trial outputs • Initial parameters • Final DNA sequence • Assembly • Final scores • Codon report • Histograms • Oligo sequences
 Scores / Penalties • • codon usage length melting temperature repeat pattern mispriming AT/GC contents gapfix
Scores / Penalties • • codon usage length melting temperature repeat pattern mispriming AT/GC contents gapfix
 Mutant Run • Design oligos based on previous set of oligos • Parameters taken from previous run • For single mutation, will output 1 or 2 oligos only
Mutant Run • Design oligos based on previous set of oligos • Parameters taken from previous run • For single mutation, will output 1 or 2 oligos only
 What to look for Final Summary • Avoid misprimes and repeats • Make sure overlaps are > 12 nt (Short) • Tm range should not be > 3°C (Tm. Range) Don't depend entirely on scores • Arbitrary, somewhat dependent on length
What to look for Final Summary • Avoid misprimes and repeats • Make sure overlaps are > 12 nt (Short) • Tm range should not be > 3°C (Tm. Range) Don't depend entirely on scores • Arbitrary, somewhat dependent on length
 Tricks Choosing codons • random - slower optimization, less constrained • strict - for the fussy • scored - if codon score really matters Tm, Length ranges, Number of Solutions • To find the "very best" solution • no more than 999
Tricks Choosing codons • random - slower optimization, less constrained • strict - for the fussy • scored - if codon score really matters Tm, Length ranges, Number of Solutions • To find the "very best" solution • no more than 999
 Tricks Design multi-use and interchangeable oligos • Flanking primers with standard overlaps • Intersperse nucleotide elements between protein elements • Gap-fix restriction sites • Allow for mutations later on Random mutagenesis • Nucleotide sequences can be degenerate
Tricks Design multi-use and interchangeable oligos • Flanking primers with standard overlaps • Intersperse nucleotide elements between protein elements • Gap-fix restriction sites • Allow for mutations later on Random mutagenesis • Nucleotide sequences can be degenerate
 Tricks Thermodynamically Balanced Inside-Out Mode • Multi-step PCR • More controlled, reliable method • Gao X. , et al. , Nucleic Acids Res 2003 Random oligo lengths • Faster, better optimization • For the not-so-fussy • Probably best for DNA-only genes
Tricks Thermodynamically Balanced Inside-Out Mode • Multi-step PCR • More controlled, reliable method • Gao X. , et al. , Nucleic Acids Res 2003 Random oligo lengths • Faster, better optimization • For the not-so-fussy • Probably best for DNA-only genes
") Tricks Set Tm higher • 64°C - 70°C • longer oligos, extra purification ($$$)
Tricks Set Tm higher • 64°C - 70°C • longer oligos, extra purification ($$$)
 Always double check! Nothing is foolproof • Think carefully about what you need BEFORE starting work • Always run final sequences through alternate program (EMBOSS, GCG-Lite) • Make sure oligos are what you intended
Always double check! Nothing is foolproof • Think carefully about what you need BEFORE starting work • Always run final sequences through alternate program (EMBOSS, GCG-Lite) • Make sure oligos are what you intended
 PCR • • Mix all oligos and additives Specific PCR protocols Analytical gel Isolate desired products
PCR • • Mix all oligos and additives Specific PCR protocols Analytical gel Isolate desired products
 Assembly Protocol Oligos 1 μl 625 n. M each d. NTPs 2 μl 2. 5 m. M each 0. 25 m. M each H 2 O 19 μl Buffer 2. 5 μl 10 X 1 X Pfu pol. 0. 5 μl 95°C 2. 0 ' 95°C 0. 5 ' 65>55°(-0. 5) 0. 5 ' 72°C 5' 4°C hold 1 X 20 X 1 X
Assembly Protocol Oligos 1 μl 625 n. M each d. NTPs 2 μl 2. 5 m. M each 0. 25 m. M each H 2 O 19 μl Buffer 2. 5 μl 10 X 1 X Pfu pol. 0. 5 μl 95°C 2. 0 ' 95°C 0. 5 ' 65>55°(-0. 5) 0. 5 ' 72°C 5' 4°C hold 1 X 20 X 1 X
 Amplification Protocol PCR mix 2 μl ? ? d. NTPs 8 μl 2. 5 m. M each 0. 2 m. M each 3' primer 4 μl 10 μM 400 n. M 5' primer 4 μl 10 μM 400 n. M Buffer 10 μl 10 X 1 X H 2 O 70 μl Pfu pol. 2 μl 95°C 2. 0 ' 95°C 0. 5 ' 62°C 0. 5 ' 72°C 5' 4°C hold 1 X 20 X 1 X
Amplification Protocol PCR mix 2 μl ? ? d. NTPs 8 μl 2. 5 m. M each 0. 2 m. M each 3' primer 4 μl 10 μM 400 n. M 5' primer 4 μl 10 μM 400 n. M Buffer 10 μl 10 X 1 X H 2 O 70 μl Pfu pol. 2 μl 95°C 2. 0 ' 95°C 0. 5 ' 62°C 0. 5 ' 72°C 5' 4°C hold 1 X 20 X 1 X
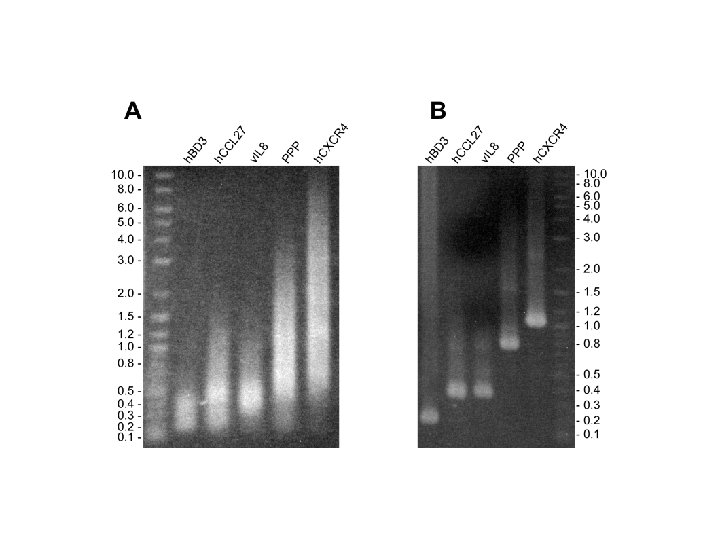
 • Wrong size product (mispriming) • Mutations (2") Problems • No product (complete failure) • Wrong size product (mispriming) • Mutations (2 out of 3 correct, 2 errors/kb) Sequencing is warranted. . .
Problems • No product (complete failure) • Wrong size product (mispriming) • Mutations (2 out of 3 correct, 2 errors/kb) Sequencing is warranted. . .
") Fixes • Optimize PCR conditions • Break gene synthesis into steps (TBIO)
Fixes • Optimize PCR conditions • Break gene synthesis into steps (TBIO)
 Errors p = mutation rate / 1000 nt / duplication (Cline et al. , Nucleic Acids Res 24 (1996)) Taq polymerase = 0. 008 KOD (Novagen) = 0. 0027 Pfu. Ultra (Stratagene) = 0. 00043 The probability of a gene n bp in length having no errors using a polymerase with mutation rate p: p' = (1 - p)n Therefore, p' for a 738 bp gene = (1 - 0. 00043)738 = 0. 728
Errors p = mutation rate / 1000 nt / duplication (Cline et al. , Nucleic Acids Res 24 (1996)) Taq polymerase = 0. 008 KOD (Novagen) = 0. 0027 Pfu. Ultra (Stratagene) = 0. 00043 The probability of a gene n bp in length having no errors using a polymerase with mutation rate p: p' = (1 - p)n Therefore, p' for a 738 bp gene = (1 - 0. 00043)738 = 0. 728
 Errors The number of clones needed to screen to find a correct gene with 95% confidence: N = log(0. 05)/log(1 -p') Thus, log(0. 05)/log(1 -0. 728) = 3 clones need to be sequenced. From Wu et al. , J Biotech 124 (2006)
Errors The number of clones needed to screen to find a correct gene with 95% confidence: N = log(0. 05)/log(1 -p') Thus, log(0. 05)/log(1 -0. 728) = 3 clones need to be sequenced. From Wu et al. , J Biotech 124 (2006)
 Time • • Find protein of interest, design oligos, order oligos Run PCR, integrate into sequencing vector, transform Pick colony, grow overnight culture Miniprep construct, integrate into expression vector, transform • Pick colony, grow overnight culture • Run expression growth trials ~ 1 week between concept and initial trial (at best!!) Can be automated and parallelized (96 well plates? )
Time • • Find protein of interest, design oligos, order oligos Run PCR, integrate into sequencing vector, transform Pick colony, grow overnight culture Miniprep construct, integrate into expression vector, transform • Pick colony, grow overnight culture • Run expression growth trials ~ 1 week between concept and initial trial (at best!!) Can be automated and parallelized (96 well plates? )