6f9e6bb3bf4d6e868d94e73072a13685.ppt
- Количество слайдов: 70



Exploiting large scale web semantics to build end user applications Enrico Motta Professor of Knowledge Technologies Knowledge Media Institute The Open University

Aims of the Talk • What is the Semantic Web – Perspectives • The SW as a ‘web of data’ • The SW as a new context in which to build semantic applications and an unprecedented opportunity in which to address some classic AI problems – Typical misconceptions • What the SW is not! • Semantic Web for Users – Applications that do something interesting and useful to users, by exploiting available web semantics

The Semantic Web as a ‘Web of Data’ Making data available to SW-aware software

<foaf: Person rdf: about="http: //identifiers. kmi. open. ac. uk/people/enrico-motta/"> <foaf: name>Enrico Motta</foaf: name> <foaf: first. Name>Enrico</foaf: first. Name> <foaf: surname>Motta</foaf: surname> <foaf: phone rdf: resource="tel: +44 -(0)1908 -653506"/> <foaf: homepage rdf: resource="http: //kmi. open. ac. uk/people/motta/"/> <foaf: workplace. Homepage rdf: resource="http: //kmi. open. ac. uk/"/> <foaf: depiction rdf: resource="http: //kmi. open. ac. uk/img/members/enrico. jpg"/> <foaf: topic_interest>Knowledge Technologies</foaf: topic_interest> <foaf: topic_interest>Semantic Web</foaf: topic_interest> <foaf: topic_interest>Ontologies</foaf: topic_interest> <foaf: topic_interest>Problem Solving Methods</foaf: topic_interest> <foaf: topic_interest>Knowledge Modelling</foaf: topic_interest> <foaf: topic_interest>Knowledge Management</foaf: topic_interest> <foaf: based_near> <geo: Point> <geo: lat>52. 024868</geo: lat> <geo: long>-0. 707143</geo: long> <contact: nearest. Airport> <airport: name>London Luton Airport</airport: name> <airport: iata. Code>LTN</airport: iata. Code> <airport: location>Luton, United Kingdom</airport: location> <geo: lat>51. 8666667</geo: lat> <geo: long>-0. 36666667</geo: long> <rdfs: see. Also rdf: resource="http: //www. daml. org/cgi-bin/airport? LTN"/> <foaf: current. Project> <foaf: name>Aqua. Log</foaf: name>

The web of SW documents

Current status of the semantic web • 10 -20 million semantic web documents – Expressed in RDF, OWL, DAML+OIL • 7 K-10 K ontologies – These cover a variety of domains - music, multimedia, computing, management, bio-medical sciences, upper level concepts, etc… • Hence: – To a significant extent the semantic web is already in place – However, domain coverage is very uneven – Still primarily a research enterprise, however interest is rapidly increasing in both governmental and business organizations • “early adopters” phase The above figures refer to resources which are publicly accessible on the web

> d da ta ta da da ta > d at a <data> a < d at a a <d ta > at ta <d a t da a at <data> d at a >

Bibliographic Data CS Dept Data Geography AKT Reference Ontology RDF Data

“Corporate Semantic Webs” • A ‘corporate ontology’ is used to provide a homogeneous view over heterogeneous data sources. • Often tackle Enterprise Information Integration scenarios • Hailed by Gartner as one of the key emerging strategic technology trends – E. g. , Garlik is a multi-million startup recently set up in UK to support personal information management, which uses an ontology to integrate data mined from the web on a large scale
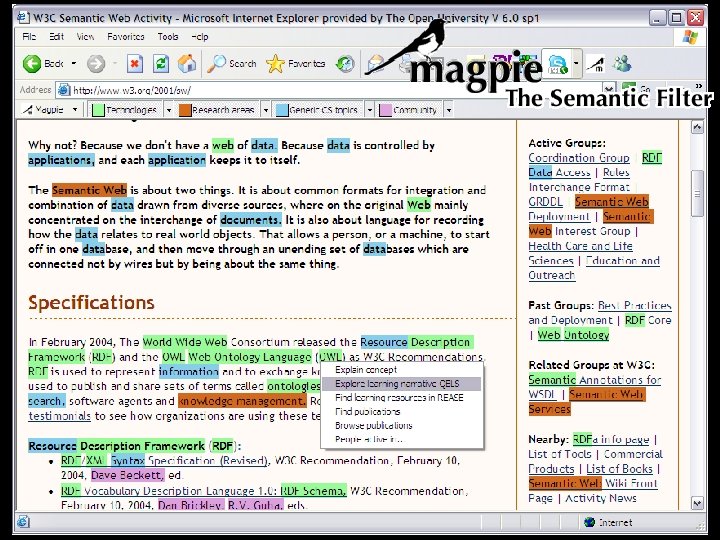
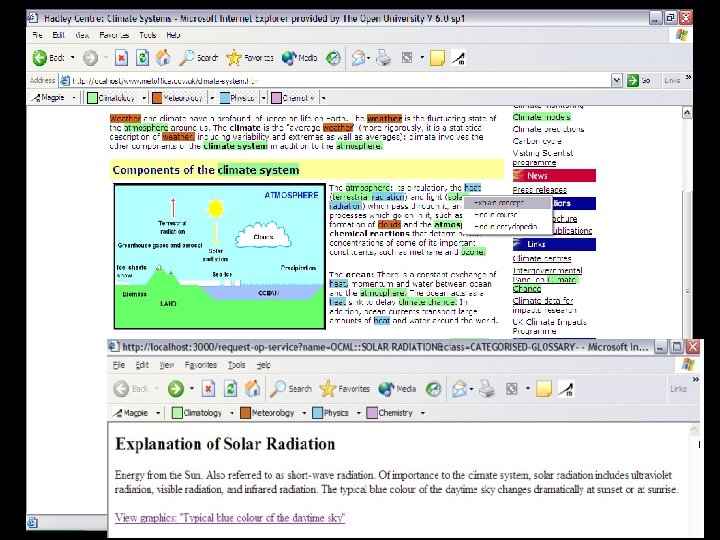

Aqua. Log

Applications that exploit large scale semantic content

The web of data

Gateways to the SW Application Semantic Web

• Sophisticated quality control mechanism – Detects duplications – Fixes obvious syntax problems • E. g. , duplicated ontology IDs, namespaces, etc. . • Structures ontologies in a network – Using relations such as: extends, inconsistent. With, duplicates • Provides interfaces for both human users and software programs • Provides efficient API • Supports formal queries (SPARQL) • Variety of ontology ranking mechanisms • Modularization/Combination support • Plug-ins for Protégé and Ne. On Toolkit • Very cool logo!

Case Study 1: Automatic Alignment of Thesauri in the Agricultural/Fishery Domain
 Semantic Relation (")
Method Access Semantic Web Scarlet Deduce Concept_A (e. g. , Supermarket) Semantic Relation ( ) Concept_B (e. g. , Building) - SCARLET - matching by Harvesting the SW - Automatically select and combine multiple online ontologies to derive a relation

Two strategies Building Organic. Chemical Public. Building Shop Lipid Steroid Supermarket Cholesterol Semantic Web Scarlet Supermarket Building Scarlet Cholesterol Organic. Chemical (A) (B) Deriving relations from (A) one ontology and (B) across ontologies.
 thesaurus • 28.")
Experiment Matching: • AGROVOC • UN’s Food and Agriculture Organisation (FAO) thesaurus • 28. 174 descriptor terms • 10. 028 non-descriptor terms • NALT • US National Agricultural Library Thesaurus • 41. 577 descriptor terms • 24. 525 non-descriptor terms

226 Used Ontologies http: //139. 91. 183. 30: 9090/RDF/VRP/Examples/tap. rdf http: //reliant. teknowledge. com/DAML/SUMO. daml http: //reliant. teknowledge. com/DAML/Mid-level-ontology. daml http: //gate. ac. uk/projects/ htechsight/Technologies. daml http: //reliant. teknowledge. com/DAML/Economy. daml
 • Evaluators: –")
Evaluation 1 - Precision • Manual assessment of 1000 mappings (15%) • Evaluators: – Researchers in the area of the Semantic Web – 6 people split in two groups • Results: – Comparable to best results for background knowledge based matchers.

Evaluation 2 – Error Analysis

Case Study 2: Folksonomy Tagspace Enrichment

Features of Web 2. 0 sites • Tagging as opposed to rigid classification • Dynamic vocabulary does not require much annotation effort and evolves easily • Shared vocabulary emerge over time – certain tags become particularly popular

Limitations of tagging • Different granularity of tagging – rome vs colosseum vs roman monument – Flower vs tulip – Etc. . • Multilinguality • Spelling errors, different terminology, plural vs singular, etc… • This has a number of negative implications for the effective use of tagged resources – e. g. , Search exhibits very poor recall

Giving meaning to tags

What does it mean to add semantics to tags? 1. Mapping a tag to a SW element "japan" <akt: Country Japan> 2. Linking two "SW tags" using semantic relations {japan, asia} <japan sub. Region. Of asia>

Applications of the approach • To improve recall in keyword search • To support annotation by dynamically suggesting relevant tags or visualizing the structure of relevant tags • To enable formal queries over a space of tags – Hence, going beyond keyword search • To support new forms of intelligent navigation – i. e. , using the 'semantic layer' to support navigation

Pre-processing Folksonomy Tags Clustering Clean tags Analyze co-occurrence of tags Group similar tags Co-occurence matrix Filter infrequent tags Cluster tags Concise tags Cluster 1 Yes Remaining tags? No 2 “related” tags Cluster 2 … Clustern SW search engine Find mappings & relation for pair of tags Wikipedia Google END <concept, relation, concept> Concept and relation identification

Examples Cluster_1: {admin application archive collection component control developer dom example form innovation interface layout planning program repository resourcecode} Information Object archive has-mention-of participant creator developer participates. In in-event activity innovation application planning resource type. Range example user component admin interface

Examples Cluster_2: {college commerce corporate course education high instructing learning lms school student} activities 4 learning 4 teaching 4 education training 1, 4 qualification school 2 corporate 1 institution post. Secondary School 2 student 3 studies. At takes. Course university 2, 3 offers. Course course 3 1 http: //gate. ac. uk/projects/htechsight/Employment. daml. 2 http: //reliant. teknowledge. com/DAML/Mid-level-ontology. daml. 3 http: //www. mondeca. com/owl/moses/ita. owl. 4 http: //www. cs. utexas. edu/users/mfkb/RKF/tree/CLib-core-office. owl. college 2

Faceted Ontology • Ontology creation and maintenance is automated • Ontology evolution is driven by task features and by user changes • Large scale integration of ontology elements from massively distributed online ontologies • Very different from traditional top-downdesigned ontologies

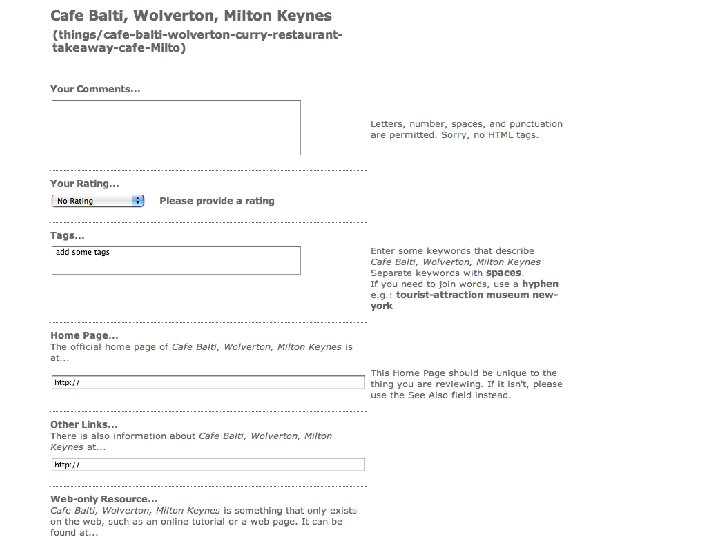
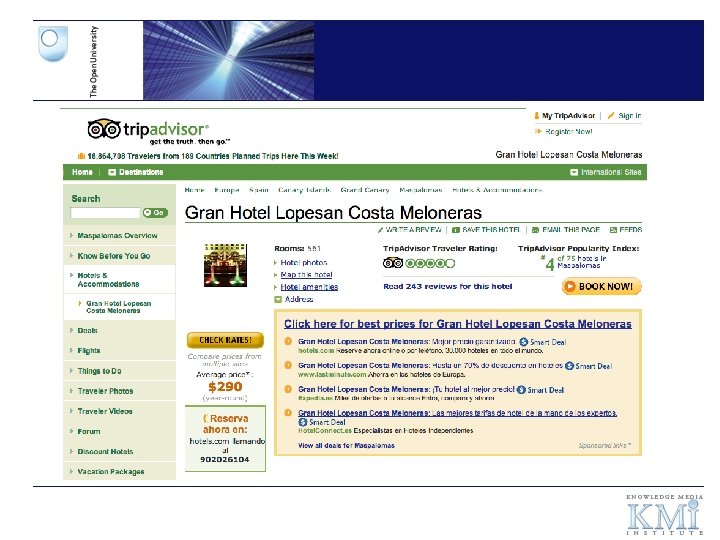
Case Study 3: Reviewing and Rating on the Web

Revyu. com




Trust Factors expertise the source has relevant expertise of the domain of the recommendation-seeking; this may be formally validated through qualifications or acquired over time. experience the source has experience of solving similar scenarios in this domain, but without extensive expertise. impartiality the source does not have vested interests in a particular resolution to the scenario. affinity the source has characteristics in common with the recommendation seeker, such as shared tastes, standards, values, viewpoints, interests, or expectations. track record the source has previously provided successful recommendations to the recommendation seeker.

subjective affinity solution factors emphasised objective expertise experience

Applying the framework to revyu. com • Affinity – Operationalised as the degree of overlap in items reviewed, and in ratings given • Experience – Proxy metric: Usage of particular tags (as proxies for topics) • Experience scores based on tagging data • Integrates also data from del. icio. us for those users who have chosen to publish their del. icio. us account on FOAF • Expertise – Proxy metric: Credibility – Captures the social aspect of expertise: endorsement

Using trust factors for ranking reviews

Power. Aqua and Power. Magpie

How does the Semantic Web relate to Artificial Intelligence research?

AI as Heuristic Search

The knowledge-based paradigm in AI “Today there has been a shift in paradigm. The fundamental problem of understanding intelligence is not the identification of a few powerful techniques, but rather the question of how to represent large amounts of knowledge in a fashion that permits their effective use” Goldstein and Papert, 1977

Knowledge Representation Hypothesis in AI Any mechanically embodied intelligent process will be comprised of structural ingredients that we as external observers naturally take to represent a propositional account of the knowledge that the overall process exhibits, and independent of such external semantic attribution, play a formal but causal and essential role in engendering the behaviour that manifests that knowledge Brian Smith, 1982

Knowledge-Based Systems Large Body of Knowledge Intelligent Behaviour

The Knowledge Acquisition Bottleneck Knowledge Large Body of Knowledge KA Bottleneck Intelligent Behaviour

The Cyc project

Structured libraries of reusable components Problem Solving Method Generic Task Library of PSMs Parametric Design Classification Scheduling Etc… Mapping Knowledge Mapping Ontology Application-specific Problem-Solving Knowledge Ontology Application Configuration Domain Model

The next knowledge medium • However, our approach based on structured libraries of problem solving components only addressed the economic cost of KBS development… “An information network with semi-automated services for the generation, distribution, and consumption of knowledge”

SW as Enabler of Intelligent Behaviour Both a platform for knowledge publishing and a large scale source of knowledge Intelligent Behaviour

KBS vs SW Systems Classic KBS SW Systems Provenance Centralized Distributed Size Small/Medium Extra Huge Repr. Schema Homogeneous Heterogeneous Quality High Very Variable Degree of trust High Very Variable

Key Paradigm Shift Classic KBS Intelligence SW Systems A function of sophisticated, logical, taskcentric problem solving A side-effect of being able to integrate different types of reasoning to handle size and heterogeneous quality and representation

Conclusions

Typical misconceptions… • “The SW is a long-term vision…” – Ehm…actually… it already exists… • “The SW will never work because nobody is going to annotate their web pages” – The SW is not about annotating web pages, the SW is a web of data, most of which are generated from DBs, or from web mining software, or from applications which produce SW technology • “The idea of a universal ontology has failed before and will fail again. Hence the SW is doomed” – The SW is not about a single universal ontology. Already there around 10 K ontologies and the number is growing… – SW applications may use 1, 2, 3, or even hundreds of ontologies.
,")
Large Scale Distributed Semantics • Widespread production of formalised knowledge models (ontologies and metadata), from a variety of different groups and individuals – E. g. , legal, bio-medical, governmental, environmental, music, art, multimedia, computing, etc. . – “Knowledge modelling to become a new form of literacy? ” • Stutt and Motta, 1997 • This large scale heterogenous resource will enable a new generation of semantic-aware technologies • These developments may provide a new context in which to address the economic barriers to KBS development • The SW already exists to some extent, however there is still a way to go, before it will reach the required degree of maturity

Large Scale Distributed Semantics • Much like AI, the semantic web will only succeed if it becomes ubiquitous and hidden “There's this stupid myth out there that A. I. has failed, but A. I. is everywhere around you every second of the day. People just don't notice it. You've got A. I. systems in cars, tuning the parameters of the fuel injection systems. When you land in an airplane, your gate gets chosen by an A. I. scheduling system. Every time you use a piece of Microsoftware, you've got an A. I. system trying to figure out what you're doing, like writing a letter, and it does a pretty damned good job. Every time you see a movie with computer-generated characters, they're all little A. I. characters behaving as a group. Every time you play a video game, you're playing against an A. I. system. ” Rodney Brooks

6f9e6bb3bf4d6e868d94e73072a13685.ppt