

485d35d48835f6bed2bf0e6c6c8c5979.ppt
- Количество слайдов: 53
 Элементы математической статистики § 1 Задачи математической статистики Математическая статистика является разделом математики, непосредственно примыкающим к теории вероятностей. Теория вероятностей служит обоснованием методов математической статистики. В математической статистике рассматриваются методы нахождения законов и числовых характеристик случайных величин по результатам экспериментов и наблюдений. К задачам математической статистики относятся: 1) разработка методов сбора и группировки статистических данных, полученных в результате наблюдений или специальных экспериментов; 2) разработка методов анализа статистических данных в зависимости от целей исследования. Вторая задача является более сложной и более объемной.
Элементы математической статистики § 1 Задачи математической статистики Математическая статистика является разделом математики, непосредственно примыкающим к теории вероятностей. Теория вероятностей служит обоснованием методов математической статистики. В математической статистике рассматриваются методы нахождения законов и числовых характеристик случайных величин по результатам экспериментов и наблюдений. К задачам математической статистики относятся: 1) разработка методов сбора и группировки статистических данных, полученных в результате наблюдений или специальных экспериментов; 2) разработка методов анализа статистических данных в зависимости от целей исследования. Вторая задача является более сложной и более объемной.
 оценки неизвестной вероятности случайного события; нахождения неизвестной функции распределения;") Здесь разрабатываются методы: а) оценки неизвестной вероятности случайного события; нахождения неизвестной функции распределения; оценки параметров распределения, вид которого известен; оценки зависимости случайной величин от одной или нескольких других случайных величин; б) проверки статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен. § 2 Генеральная совокупность и выборочная совокупность ( выборка) п 1. Основные понятия. Пусть проводятся наблюдения или специальные эксперименты для изучения некоторого качественного или количественного признака - некоторой случайной величины. Совокупность всех возможных значений ( реализаций) исследуемой случайной величины называется генеральной совокупностью.
Здесь разрабатываются методы: а) оценки неизвестной вероятности случайного события; нахождения неизвестной функции распределения; оценки параметров распределения, вид которого известен; оценки зависимости случайной величин от одной или нескольких других случайных величин; б) проверки статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен. § 2 Генеральная совокупность и выборочная совокупность ( выборка) п 1. Основные понятия. Пусть проводятся наблюдения или специальные эксперименты для изучения некоторого качественного или количественного признака - некоторой случайной величины. Совокупность всех возможных значений ( реализаций) исследуемой случайной величины называется генеральной совокупностью.
 Она может состоят из конечного или бесконечного множества значений, называемым элементами генеральной совокупности. Однако на практике часто невозможно получить все значения генеральной совокупности, и, как правило, получают ограниченное множество возможных значений случайной величины. Множество значений случайной величины, полученных в результате наблюдений, называется случайной выборкой ( выборочной совокупностью) или просто выборкой. Число n значений случайной величины, образующих выборку, называется объемом выборки. Задачи математической статистики решаются через изучение свойств выборки. На основе этого изучения обобщаются и выводятся свойства всей генеральной совокупности. Полученные таким образом выводы называются статистическими.
Она может состоят из конечного или бесконечного множества значений, называемым элементами генеральной совокупности. Однако на практике часто невозможно получить все значения генеральной совокупности, и, как правило, получают ограниченное множество возможных значений случайной величины. Множество значений случайной величины, полученных в результате наблюдений, называется случайной выборкой ( выборочной совокупностью) или просто выборкой. Число n значений случайной величины, образующих выборку, называется объемом выборки. Задачи математической статистики решаются через изучение свойств выборки. На основе этого изучения обобщаются и выводятся свойства всей генеральной совокупности. Полученные таким образом выводы называются статистическими.
 В связи с этим, выборка должна быть получена так, чтобы она наиболее полно и точно представляла генеральную совокупность – была репрезентативной (представительной). В соответствии с законом больших чисел выборка будет репрезентативной, если объекты исследования отбирать случайным образом. Для этого разработаны различные методы получения выборки. К ним относятся: 1) отбор объектов не требующий разделения генеральной совокупности на части: а) простой случайный бесповторный; б) простой случайный повторный; 2) отбор объектов, при котором генеральная совокупность разбивается на части: а) типический отбор; б) механический; в) серийный.
В связи с этим, выборка должна быть получена так, чтобы она наиболее полно и точно представляла генеральную совокупность – была репрезентативной (представительной). В соответствии с законом больших чисел выборка будет репрезентативной, если объекты исследования отбирать случайным образом. Для этого разработаны различные методы получения выборки. К ним относятся: 1) отбор объектов не требующий разделения генеральной совокупности на части: а) простой случайный бесповторный; б) простой случайный повторный; 2) отбор объектов, при котором генеральная совокупность разбивается на части: а) типический отбор; б) механический; в) серийный.
 п. 2. Статистическое распределение выборки. Эмпирическая функция распределения. Полигон и гистограмма. Пусть из генеральной совокупность извлечена выборка объема n , при этом, значение С. В. х1 повторяется n 1 раз, значение х2 - n 2 раз, … , значение xk - nk раз, . Наблюдаемые значения . x i называются вариантами, а - ni частотами. Последовательность значений xi , записанных в возрастающем ( убывающем ) порядке, называется вариационным рядом. Отношения называются относительными частотами.
п. 2. Статистическое распределение выборки. Эмпирическая функция распределения. Полигон и гистограмма. Пусть из генеральной совокупность извлечена выборка объема n , при этом, значение С. В. х1 повторяется n 1 раз, значение х2 - n 2 раз, … , значение xk - nk раз, . Наблюдаемые значения . x i называются вариантами, а - ni частотами. Последовательность значений xi , записанных в возрастающем ( убывающем ) порядке, называется вариационным рядом. Отношения называются относительными частотами.
 Статистическим распределением выборки называется перечень вариант xi и соответствующих им частот ni или относительных частот wi , ( 1 ) Обозначим - относительная частота события X < x , здесь nx - число наблюдений (вариант) , для которых xi < x.
Статистическим распределением выборки называется перечень вариант xi и соответствующих им частот ni или относительных частот wi , ( 1 ) Обозначим - относительная частота события X < x , здесь nx - число наблюдений (вариант) , для которых xi < x.
, определяющая для каждого значения x относительную частоту") Определение. Эмпирической функцией распределения называется функция F*(x), определяющая для каждого значения x относительную частоту события X < x. Таким образом, , nх – число вариант меньших x , n – объем выборки. Свойства эмпирической функции F*(x) аналогичны свойствам теоретической функции распределения F(x). Для наглядного изображения статистические распределения отображают графически. К таким графикам относят полигон и гистограмму. Полигоном частот называют ломаную линию соединяющую точки (х1; n 1), (x 2; n 2), …, (xk; nk). Аналогично, полигон может быть построен для относительных частот.
Определение. Эмпирической функцией распределения называется функция F*(x), определяющая для каждого значения x относительную частоту события X < x. Таким образом, , nх – число вариант меньших x , n – объем выборки. Свойства эмпирической функции F*(x) аналогичны свойствам теоретической функции распределения F(x). Для наглядного изображения статистические распределения отображают графически. К таким графикам относят полигон и гистограмму. Полигоном частот называют ломаную линию соединяющую точки (х1; n 1), (x 2; n 2), …, (xk; nk). Аналогично, полигон может быть построен для относительных частот.
 Гистограммой называется фигура, состоящая из прямоугольников, основания которых образуют отрезки [ xi ; xi+1], а высота отношение частоты (или относительной частоты) к длине отрезка. § 3 Числовые характеристики выборки К числовым характеристикам выборки относятся : выборочное среднее , выборочная дисперсия и среднее квадратическое отклонение, эмпирические моменты различных порядков и др. Пусть х1, х2, …, хn – выборка из генеральной совокупности и все значения xi различны. Выборочным средним называется число Если в выборке значения вариант повторяются (см. § 2 формула (1)) и известны их частоты, то выборочное среднее находится по формуле . .
Гистограммой называется фигура, состоящая из прямоугольников, основания которых образуют отрезки [ xi ; xi+1], а высота отношение частоты (или относительной частоты) к длине отрезка. § 3 Числовые характеристики выборки К числовым характеристикам выборки относятся : выборочное среднее , выборочная дисперсия и среднее квадратическое отклонение, эмпирические моменты различных порядков и др. Пусть х1, х2, …, хn – выборка из генеральной совокупности и все значения xi различны. Выборочным средним называется число Если в выборке значения вариант повторяются (см. § 2 формула (1)) и известны их частоты, то выборочное среднее находится по формуле . .
 Выборочной дисперсией называется число . В случае повторяющихся вариант выборочная дисперсия равна . Для вычисления выборочной дисперсии используется также формула В статистике используется также исправленная дисперсия .
Выборочной дисперсией называется число . В случае повторяющихся вариант выборочная дисперсия равна . Для вычисления выборочной дисперсии используется также формула В статистике используется также исправленная дисперсия .
 Средним квадратическим отклонением выборки называется число или исправленным среднеквадратическим. Простейшей мерой рассеяния выборки является размах выборки К числовым характеристикам выборки относятся также моменты: начальные k - го порядка центральные k - го порядка Очевидно, что
Средним квадратическим отклонением выборки называется число или исправленным среднеквадратическим. Простейшей мерой рассеяния выборки является размах выборки К числовым характеристикам выборки относятся также моменты: начальные k - го порядка центральные k - го порядка Очевидно, что
 Для некоторых законов распределения генеральной совокупности вычисляют асимметрию и эксцесс: В случае нормального закона распределения асимметрия характеризует отклонение эмпирического ( на основе стат. данных) максимума от теоретического в направлении оси ОХ. Эксцесс характеризует отклонение максимума в направлении оси ОУ. Другими характеристиками являются мода , медиана, коэффициент вариации. § 4. Статистические оценки параметров распределения. п. 1 Понятие оценки параметра Любая наблюдаемая случайная величина подчиняется некоторому закону распределения. Каждый закон зависит от некоторого числа параметров. Поэтому закон распределения можно считать определенным, если на основе статистических данных найдены значения параметров закона.
Для некоторых законов распределения генеральной совокупности вычисляют асимметрию и эксцесс: В случае нормального закона распределения асимметрия характеризует отклонение эмпирического ( на основе стат. данных) максимума от теоретического в направлении оси ОХ. Эксцесс характеризует отклонение максимума в направлении оси ОУ. Другими характеристиками являются мода , медиана, коэффициент вариации. § 4. Статистические оценки параметров распределения. п. 1 Понятие оценки параметра Любая наблюдаемая случайная величина подчиняется некоторому закону распределения. Каждый закон зависит от некоторого числа параметров. Поэтому закон распределения можно считать определенным, если на основе статистических данных найдены значения параметров закона.
 Поэтому закон распределения можно считать определенным, если на основе статистических данных найдены значения параметров закона. Однако, в связи с тем, что статистические данные являются не полными, а иногда не достаточно точными, то значения параметров распределения по выборке можно найти только с некоторой степенью точности. Приближенное значение параметра закона распределения, полученное на основе выборки, называется оценкой параметра. Истинное значение параметра закона распределения будем обозначать Θ , а его приближенное значение ( оценку ) Θ*. Так как любая оценка параметра находится на основе выборки, то она является функцией выборки, т. е. Θ = Θ(х1, х2 , …, хn ). Любую функцию Θ(х1, х2 , …, хn ), зависящую от выборки и поэтому являющуюся случайной величиной, принято называть статистикой.
Поэтому закон распределения можно считать определенным, если на основе статистических данных найдены значения параметров закона. Однако, в связи с тем, что статистические данные являются не полными, а иногда не достаточно точными, то значения параметров распределения по выборке можно найти только с некоторой степенью точности. Приближенное значение параметра закона распределения, полученное на основе выборки, называется оценкой параметра. Истинное значение параметра закона распределения будем обозначать Θ , а его приближенное значение ( оценку ) Θ*. Так как любая оценка параметра находится на основе выборки, то она является функцией выборки, т. е. Θ = Θ(х1, х2 , …, хn ). Любую функцию Θ(х1, х2 , …, хn ), зависящую от выборки и поэтому являющуюся случайной величиной, принято называть статистикой.
 Оценки параметров законов распределения изучаемой случайной величины бывают двух видов: точечные и интервальные. Точечные оценки выражаются одним числом, а интервальные - двумя числами – границами интервала, который содержит неизвестный параметр Θ с некоторой вероятностью. п. 2 Свойства точечных оценок Для того, чтобы статистические оценки давали «хорошие» приближения оцениваемых параметров, они должны удовлетворять определенным требованиям. Статистическая оценка Θ* называется несмещенной, если ее математическое ожидание равно оцениваемому параметру при любом объеме выборки, т. е. М(Θ*) = Θ*. В противном случае оценка называется смещенной.
Оценки параметров законов распределения изучаемой случайной величины бывают двух видов: точечные и интервальные. Точечные оценки выражаются одним числом, а интервальные - двумя числами – границами интервала, который содержит неизвестный параметр Θ с некоторой вероятностью. п. 2 Свойства точечных оценок Для того, чтобы статистические оценки давали «хорошие» приближения оцениваемых параметров, они должны удовлетворять определенным требованиям. Статистическая оценка Θ* называется несмещенной, если ее математическое ожидание равно оцениваемому параметру при любом объеме выборки, т. е. М(Θ*) = Θ*. В противном случае оценка называется смещенной.
 Если это требование не выполняется, то оценка Θ*, полученная по разным выборкам, будет в среднем либо завышать, либо занижать значение Θ. К сожалению, часто практически важные оценки являются смещенными, хотя и слабо. Для оценки, смещенной слабо: М(Θ*) → Θ, n →∞ Было бы, однако, ошибочным считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Чем больше дисперсия оценки, тем больше ее значения рассеяны вокруг ее среднего значения и, следовательно, удалены от значения оцениваемого параметра. По этой причине к оценке предъявляется требование эффективности. Статистическая оценка Θ* называется эффективной, если при заданном объеме выборки она имеет наименьшую дисперсию. При больших объемах выборки необходимо выполнение еще одного требования. Оно называется состоятельностью оценки.
Если это требование не выполняется, то оценка Θ*, полученная по разным выборкам, будет в среднем либо завышать, либо занижать значение Θ. К сожалению, часто практически важные оценки являются смещенными, хотя и слабо. Для оценки, смещенной слабо: М(Θ*) → Θ, n →∞ Было бы, однако, ошибочным считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Чем больше дисперсия оценки, тем больше ее значения рассеяны вокруг ее среднего значения и, следовательно, удалены от значения оцениваемого параметра. По этой причине к оценке предъявляется требование эффективности. Статистическая оценка Θ* называется эффективной, если при заданном объеме выборки она имеет наименьшую дисперсию. При больших объемах выборки необходимо выполнение еще одного требования. Оно называется состоятельностью оценки.
 Статистическая оценка Θ* называется состоятельной, если ее значение при n →∞ сходится по вероятности к значению оцениваемого параметра, Для состоятельных оценок значительные ошибки при оценивании маловероятны. Если дисперсия несмещенной оценки при n →∞, стремится к нулю, то такая оценка оказывается и состоятельной. Это непосредственно вытекает из неравенства Чебышева: Из неравенства Чебышева видно, что, для того чтобы доказать несмещенность и состоятельность оценки, достаточно изучить ее математическое ожидание и дисперсию. Следует заметить, что на практике часто для простоты расчетов используют незначительно смещенные оценки или оценки, обладающие большей дисперсией по сравнению с эффективными оценками.
Статистическая оценка Θ* называется состоятельной, если ее значение при n →∞ сходится по вероятности к значению оцениваемого параметра, Для состоятельных оценок значительные ошибки при оценивании маловероятны. Если дисперсия несмещенной оценки при n →∞, стремится к нулю, то такая оценка оказывается и состоятельной. Это непосредственно вытекает из неравенства Чебышева: Из неравенства Чебышева видно, что, для того чтобы доказать несмещенность и состоятельность оценки, достаточно изучить ее математическое ожидание и дисперсию. Следует заметить, что на практике часто для простоты расчетов используют незначительно смещенные оценки или оценки, обладающие большей дисперсией по сравнению с эффективными оценками.
 п. 3 Методы получения точечных оценок Основными методами получения точечных оценок являются: метод моментов и метод наибольшего правдоподобия. а) Метод моментов – метод получения оценок параметров, который состоит в том, что если оцениваемый параметр распределения является функцией от моментов распределения (в самом простом случае сам является моментом), то в эту функцию просто подставляются эмпирические значения моментов, а полученное значение берется в качестве оценки для параметра. Этот метод впервые был использован К. Пирсоном в 1894 г. Самый простой пример применения метода моментов. Математическое ожидание – первый начальный, а дисперсия – второй центральный момент. В качестве оценок для их генеральных значений мы возьмем первый начальный и второй центральный моменты выборки (эмпирические моменты),
п. 3 Методы получения точечных оценок Основными методами получения точечных оценок являются: метод моментов и метод наибольшего правдоподобия. а) Метод моментов – метод получения оценок параметров, который состоит в том, что если оцениваемый параметр распределения является функцией от моментов распределения (в самом простом случае сам является моментом), то в эту функцию просто подставляются эмпирические значения моментов, а полученное значение берется в качестве оценки для параметра. Этот метод впервые был использован К. Пирсоном в 1894 г. Самый простой пример применения метода моментов. Математическое ожидание – первый начальный, а дисперсия – второй центральный момент. В качестве оценок для их генеральных значений мы возьмем первый начальный и второй центральный моменты выборки (эмпирические моменты),
 В общем случае, если же закон распределения изучаемой случайной величины содержит k параметров, то для получения оценок этих параметров первые k теоретических моментов приравниваются к k эмпирическим моментам найденным по выборке. Затем из полученной системы уравнений находят приближенные значения параметров. б) Метод наибольшего правдоподобия предложен Р. Фишером Пусть Х – дискретная случайная величина, которая в результате испытаний приняла значения х1, х2 , …, хn. Вид закона распределения С. В. Х известен. Обозначим вероятность того, что величина Х примет значение хi , через p(хi , Θ). Функцией правдоподобия ДСВ Х называется функция L(х1, х2 , …, хn ) = p(х1 , Θ) p(х2 , Θ) … p(хn , Θ). В качестве точечной оценки параметра Θ принимают такое его значение Θ*= Θ*(х1, х2 , …, хn ), при котором функция правдоподобия достигает максимума.
В общем случае, если же закон распределения изучаемой случайной величины содержит k параметров, то для получения оценок этих параметров первые k теоретических моментов приравниваются к k эмпирическим моментам найденным по выборке. Затем из полученной системы уравнений находят приближенные значения параметров. б) Метод наибольшего правдоподобия предложен Р. Фишером Пусть Х – дискретная случайная величина, которая в результате испытаний приняла значения х1, х2 , …, хn. Вид закона распределения С. В. Х известен. Обозначим вероятность того, что величина Х примет значение хi , через p(хi , Θ). Функцией правдоподобия ДСВ Х называется функция L(х1, х2 , …, хn ) = p(х1 , Θ) p(х2 , Θ) … p(хn , Θ). В качестве точечной оценки параметра Θ принимают такое его значение Θ*= Θ*(х1, х2 , …, хn ), при котором функция правдоподобия достигает максимума.
 Такую оценку Θ* называют оценкой наибольшего правдоподобия. Функции L и ln L достигают максимума при одном и том же значении , поэтому вместо отыскания максимума функции L находят максимум функции ln L. Эту функцию называют логарифмической функцией правдоподобия. Максимум ln L находят по схеме: 1) находят производную ; 2) приравнивают производную к нулю и определяют критическую точку; 3) находят вторую производную ; если вторая производная при Θ = Θ* отрицательна, то Θ* - точка максимума. Найденную точку максимума Θ* принимают в качестве оценки наибольшего правдоподобия параметра Θ.
Такую оценку Θ* называют оценкой наибольшего правдоподобия. Функции L и ln L достигают максимума при одном и том же значении , поэтому вместо отыскания максимума функции L находят максимум функции ln L. Эту функцию называют логарифмической функцией правдоподобия. Максимум ln L находят по схеме: 1) находят производную ; 2) приравнивают производную к нулю и определяют критическую точку; 3) находят вторую производную ; если вторая производная при Θ = Θ* отрицательна, то Θ* - точка максимума. Найденную точку максимума Θ* принимают в качестве оценки наибольшего правдоподобия параметра Θ.
 Пример. Найти методом наибольшего правдоподобия оценку параметра λ распределения Пуассона Решение. Функция правдоподобия будет иметь вид для Θ = λ L = p(х1 , λ) p(х2 , λ) … p(хn , λ) = Прологарифмируем функцию Найдем первую производную
Пример. Найти методом наибольшего правдоподобия оценку параметра λ распределения Пуассона Решение. Функция правдоподобия будет иметь вид для Θ = λ L = p(х1 , λ) p(х2 , λ) … p(хn , λ) = Прологарифмируем функцию Найдем первую производную
 Найдем критическую точку из уравнения Можно проверить, что вторая производная по λ будет отрицательна для данного значения λ. Из этого следует, что в качестве оценки наибольшего правдоподобия параметра λ распределения Пуассона надо принять выборочную среднюю. Для непрерывных случайных величин функция правдоподобия имеет вид L(х1, х2 , …, хn ) = f(х1 , Θ) f(х2 , Θ) … f(хn , Θ), - где f(х , Θ) плотность распределения НСВ Х.
Найдем критическую точку из уравнения Можно проверить, что вторая производная по λ будет отрицательна для данного значения λ. Из этого следует, что в качестве оценки наибольшего правдоподобия параметра λ распределения Пуассона надо принять выборочную среднюю. Для непрерывных случайных величин функция правдоподобия имеет вид L(х1, х2 , …, хn ) = f(х1 , Θ) f(х2 , Θ) … f(хn , Θ), - где f(х , Θ) плотность распределения НСВ Х.
 Оценку наибольшего правдоподобия неизвестного параметра распределения непрерывной случайной величины находят по схеме приведенной для ДСВ. В случае, если закон распределения зависит от нескольких параметров, то функция правдоподобия также будет зависеть от нескольких параметров. В это случае для определения критической точки находят частные производные по каждому параметру и решают систему уравнений. Проверка на экстремум в этом случае может быть достаточно сложной и для принятия решения используется эксперт. п 4. Надежности оценки. Связь между точностью и надежностью оценки Статистическая оценка Θ* является лишь приближенным значением неизвестного параметра Θ даже в том случае, если она несмещенная (в среднем совпадает с Θ*), состоятельная (стремится к Θ с ростом n) и эффективная (обладает наименьшей степенью случайных отклонений от Θ).
Оценку наибольшего правдоподобия неизвестного параметра распределения непрерывной случайной величины находят по схеме приведенной для ДСВ. В случае, если закон распределения зависит от нескольких параметров, то функция правдоподобия также будет зависеть от нескольких параметров. В это случае для определения критической точки находят частные производные по каждому параметру и решают систему уравнений. Проверка на экстремум в этом случае может быть достаточно сложной и для принятия решения используется эксперт. п 4. Надежности оценки. Связь между точностью и надежностью оценки Статистическая оценка Θ* является лишь приближенным значением неизвестного параметра Θ даже в том случае, если она несмещенная (в среднем совпадает с Θ*), состоятельная (стремится к Θ с ростом n) и эффективная (обладает наименьшей степенью случайных отклонений от Θ).
 В силу случайной природы изучаемых характеристик их сходимость к предельным значениям – сходимость по вероятности. Это означает, что точность оценок, вычисленных по выборке, имеет место не “всегда”, а только для подавляющего числа выборок. Таким образом, кроме обычного понятия точности оценок встает вопрос еще и об их надежности – в каком проценте случаев точность оценки не нарушается. В связи с этим с точностью оценки, полученной на основе выборки, математическая статистика связывает понятие “уровня доверия” к ней. “Уровень доверия”– это и есть ее надежность, процент (доля) случаев, для которых гарантируется требуемая точность оценки. То есть точности оценки можно доверять не на все 100%, а лишь с некоторым “уровнем доверия”. Например, если указано, что уровень доверия для оценки 0, 95, то из 100 выборок примерно 5 дадут оценки, которые на самом деле не удовлетворяют требованиям точности.
В силу случайной природы изучаемых характеристик их сходимость к предельным значениям – сходимость по вероятности. Это означает, что точность оценок, вычисленных по выборке, имеет место не “всегда”, а только для подавляющего числа выборок. Таким образом, кроме обычного понятия точности оценок встает вопрос еще и об их надежности – в каком проценте случаев точность оценки не нарушается. В связи с этим с точностью оценки, полученной на основе выборки, математическая статистика связывает понятие “уровня доверия” к ней. “Уровень доверия”– это и есть ее надежность, процент (доля) случаев, для которых гарантируется требуемая точность оценки. То есть точности оценки можно доверять не на все 100%, а лишь с некоторым “уровнем доверия”. Например, если указано, что уровень доверия для оценки 0, 95, то из 100 выборок примерно 5 дадут оценки, которые на самом деле не удовлетворяют требованиям точности.
 Является ли конкретная выборка “плохой” или “хорошей”, к сожалению, сказать нельзя, так что, если делать на основе выборочного метода вывод о всей совокупности, то вероятность ошибиться остается. Математическая статистика дает методику вычисления этой вероятности ошибки полученной оценки. Описание точности и надежности оценки Θ* параметра Θ дает распределение вероятностей разности оценки и истинного значения – (Θ* – Θ). Пусть точность оценки равна δ , а β надежность этой оценки. Тогда эти величины связаны между собой равенством Р( |Θ* – Θ |< δ) = β. (*) Из этого равенства следует, что чем точнее оценка ( δ мало ) тем меньше вероятность и надежность оценки и, наоборот, чем меньше точность оценки (δ велико) , тем выше надежность оценки. В этом равенстве две переменных величины δ и β, поэтому на практике одну из них необходимо выбрать произвольно. Выбирают обычно надежность, т. е. β. Обычно задаются уровнем надежности
Является ли конкретная выборка “плохой” или “хорошей”, к сожалению, сказать нельзя, так что, если делать на основе выборочного метода вывод о всей совокупности, то вероятность ошибиться остается. Математическая статистика дает методику вычисления этой вероятности ошибки полученной оценки. Описание точности и надежности оценки Θ* параметра Θ дает распределение вероятностей разности оценки и истинного значения – (Θ* – Θ). Пусть точность оценки равна δ , а β надежность этой оценки. Тогда эти величины связаны между собой равенством Р( |Θ* – Θ |< δ) = β. (*) Из этого равенства следует, что чем точнее оценка ( δ мало ) тем меньше вероятность и надежность оценки и, наоборот, чем меньше точность оценки (δ велико) , тем выше надежность оценки. В этом равенстве две переменных величины δ и β, поэтому на практике одну из них необходимо выбрать произвольно. Выбирают обычно надежность, т. е. β. Обычно задаются уровнем надежности
 равным 0, 9, 0, 95, 0, 99. И по выбранной надежности находят точность оценки. Рассмотрим связь оценки и надежности на примере выборочного среднего и какие выводы его распределение вероятностей позволяет сделать о точности и надежности точечной оценки для генерального среднего а. Выборочное среднее является случайной величиной, значение которой зависит от того, какие значения приняли варианты xi. Если наблюдения проводятся над нормальной случайной величиной с параметрами а и s, то, как сумма нормально распределенных случайных величин, она подчиняется нормальному закону. Ее математическое ожидание и дисперсия имеют значения равные ,
равным 0, 9, 0, 95, 0, 99. И по выбранной надежности находят точность оценки. Рассмотрим связь оценки и надежности на примере выборочного среднего и какие выводы его распределение вероятностей позволяет сделать о точности и надежности точечной оценки для генерального среднего а. Выборочное среднее является случайной величиной, значение которой зависит от того, какие значения приняли варианты xi. Если наблюдения проводятся над нормальной случайной величиной с параметрами а и s, то, как сумма нормально распределенных случайных величин, она подчиняется нормальному закону. Ее математическое ожидание и дисперсия имеют значения равные ,
 Следовательно, у величины то же математическое ожидание а, что и у генерального распределения, а дисперсия в n раз меньше: . Эти соотношения выведены без учета требования нормальности генерального распределения. В силу центральной предельной теоремы, если число наблюдений n велико, то каким бы ни было распределение у случайной величины, из которой делается выборка, если у него существует дисперсия, выборочное среднее , являясь суммой большого числа случайных величин, подчиняется закону, близкому к нормальному, так что формула верна в достаточно широком классе случаев. Из этих рассуждений следует также доказательство того, что выборочное среднее является несмещенной и, в силу теоремы Чебышева, состоятельной оценкой.
Следовательно, у величины то же математическое ожидание а, что и у генерального распределения, а дисперсия в n раз меньше: . Эти соотношения выведены без учета требования нормальности генерального распределения. В силу центральной предельной теоремы, если число наблюдений n велико, то каким бы ни было распределение у случайной величины, из которой делается выборка, если у него существует дисперсия, выборочное среднее , являясь суммой большого числа случайных величин, подчиняется закону, близкому к нормальному, так что формула верна в достаточно широком классе случаев. Из этих рассуждений следует также доказательство того, что выборочное среднее является несмещенной и, в силу теоремы Чебышева, состоятельной оценкой.
 Замечание. Оценка Dв является смещенной. Чтобы получить несмещенную точечную оценку s 2 для неизвестной дисперсии генеральной совокупности, эмпирическую дисперсию Dв исправляют следующим образом: – несмещенная оценка для дисперсии. Рассмотрим случайную величину . Она будет иметь нормальный закон распределения N(0, 1) Равенство (*) для этой случайной величины будет иметь вид или
Замечание. Оценка Dв является смещенной. Чтобы получить несмещенную точечную оценку s 2 для неизвестной дисперсии генеральной совокупности, эмпирическую дисперсию Dв исправляют следующим образом: – несмещенная оценка для дисперсии. Рассмотрим случайную величину . Она будет иметь нормальный закон распределения N(0, 1) Равенство (*) для этой случайной величины будет иметь вид или
 Величина в формуле (**) tβ определяется из равенства 2Φ( tβ ) =") (**) Величина в формуле (**) tβ определяется из равенства 2Φ( tβ ) = β, это следует из формулы заданного отклонения для нормально распределенной случайной величины. Величина является точностью оценки генерального среднего, т. е формула (**) дает одновременно точность, с которой значение описывает генеральное среднее а и надежность этой оценки (уровень доверия к ней).
(**) Величина в формуле (**) tβ определяется из равенства 2Φ( tβ ) = β, это следует из формулы заданного отклонения для нормально распределенной случайной величины. Величина является точностью оценки генерального среднего, т. е формула (**) дает одновременно точность, с которой значение описывает генеральное среднее а и надежность этой оценки (уровень доверия к ней).
 § 5. Интервальные оценки для параметров п 1. Понятие доверительного интервала Ранее было сказано, что оценки параметров закона распределения бывают интервальными, т. е. когда оценка Θ* параметра Θ принадлежит некоторому интервалу (Θ 1 ; Θ 2). Проведя рассуждения, аналогичные точечным оценкам, можно сделать вывод, что для такого интервала мы также имеем некоторую надежность (или уровень доверия). Иными словами, если мы каким-либо способом получили интервал, содержащий оценку Θ* параметра Θ , то мы можем гарантировать, что он содержит Θ, лишь с некоторой вероятностью β. Определение. Интервал, содержащий оценку Θ* параметра Θ с некоторой вероятностью β, называется доверительным интервалом. Вероятность β называется доверительной вероятностью.
§ 5. Интервальные оценки для параметров п 1. Понятие доверительного интервала Ранее было сказано, что оценки параметров закона распределения бывают интервальными, т. е. когда оценка Θ* параметра Θ принадлежит некоторому интервалу (Θ 1 ; Θ 2). Проведя рассуждения, аналогичные точечным оценкам, можно сделать вывод, что для такого интервала мы также имеем некоторую надежность (или уровень доверия). Иными словами, если мы каким-либо способом получили интервал, содержащий оценку Θ* параметра Θ , то мы можем гарантировать, что он содержит Θ, лишь с некоторой вероятностью β. Определение. Интервал, содержащий оценку Θ* параметра Θ с некоторой вероятностью β, называется доверительным интервалом. Вероятность β называется доверительной вероятностью.
 Нетрудно видеть, что величина уровня доверия β, влияет на величину доверительного интервала: чем больше уровень доверия, тем шире интервал. Поэтому при построении интервальных оценок приходится также решать вопрос о том, что на какой риск мы готовы пойти в каждом конкретном случае ( задать уровень надежности доверительную вероятность), а математическая статистика в этом случае дает точность оценки, гарантируемую для заданного допустимого риска. Или, наоборот, можно получить от математической статистики ответ, что для данной точности уровень доверия будет иметь такое-то значение. И если он ниже допустимого, мы можем постараться добиться результатов, заслуживающих большего доверия. Например, увеличить число объектов, участвующих в исследовании. Математическая статистика показывает, что чем больше число отобранных для обследования объектов, тем меньше вероятность ошибки, и дает функциональную зависимость
Нетрудно видеть, что величина уровня доверия β, влияет на величину доверительного интервала: чем больше уровень доверия, тем шире интервал. Поэтому при построении интервальных оценок приходится также решать вопрос о том, что на какой риск мы готовы пойти в каждом конкретном случае ( задать уровень надежности доверительную вероятность), а математическая статистика в этом случае дает точность оценки, гарантируемую для заданного допустимого риска. Или, наоборот, можно получить от математической статистики ответ, что для данной точности уровень доверия будет иметь такое-то значение. И если он ниже допустимого, мы можем постараться добиться результатов, заслуживающих большего доверия. Например, увеличить число объектов, участвующих в исследовании. Математическая статистика показывает, что чем больше число отобранных для обследования объектов, тем меньше вероятность ошибки, и дает функциональную зависимость
 Между объемом выборки, точностью и вероятностью ошибки. При этом предлагаются “оптимальные” методики, при использовании которых величина вероятности ошибки минимальна. Выбрав уровень риска, на который мы готовы пойти, мы в каком-то смысле вместо достоверных событий, вероятность которых равна 1, начинаем считать за “практически достоверные” события, вероятность которых только близка к 1 (степень близости к 1 и есть наш уровень риска). Таким образом, можно сказать, что математическая статистика предлагает методики, следуя которым, мы будем не ошибаться в своих рассуждениях не “всегда”, а только “практически всегда”, в соответствии с выбранным нами “уровнем доверия” (указанием, что мы подразумеваем под понятием “практически всегда”). Принято уровень доверия брать равным 0, 95 или 0, 99. Если, приняв уровень доверия 0, 99, мы будем по выборкам строить доверительные интервалы, то в среднем 1 из 100 интервалов не будет содержать истинное значение параметра (какой именно 1 из 100 мы, конечно, не можем сказать).
Между объемом выборки, точностью и вероятностью ошибки. При этом предлагаются “оптимальные” методики, при использовании которых величина вероятности ошибки минимальна. Выбрав уровень риска, на который мы готовы пойти, мы в каком-то смысле вместо достоверных событий, вероятность которых равна 1, начинаем считать за “практически достоверные” события, вероятность которых только близка к 1 (степень близости к 1 и есть наш уровень риска). Таким образом, можно сказать, что математическая статистика предлагает методики, следуя которым, мы будем не ошибаться в своих рассуждениях не “всегда”, а только “практически всегда”, в соответствии с выбранным нами “уровнем доверия” (указанием, что мы подразумеваем под понятием “практически всегда”). Принято уровень доверия брать равным 0, 95 или 0, 99. Если, приняв уровень доверия 0, 99, мы будем по выборкам строить доверительные интервалы, то в среднем 1 из 100 интервалов не будет содержать истинное значение параметра (какой именно 1 из 100 мы, конечно, не можем сказать).
 Если примем уровень доверия 0, 95 и будем по выборкам строить доверительные интервалы, то в среднем 5 из 100 интервалов не будут содержать истинное значение параметра. Выбор уровня доверия остается за нами. Если цена ошибки высока (разорение, смертельный исход при операции) – может быть, следует задать уровень доверия равным 0, 999, если ошибка грозит тем, что придется взять кредит в банке – можно удовольствоваться уровнем 0, 95. Если лекарство безвредно, то достаточно того, что “оно помогает с уровнем доверия 70%”, чтобы рекомендовать его для применения. Доверительные интервальные оценки вычисляются в соответствии с выбранным уровнем доверия. При этом, конечно, надо учитывать, что чем выше заказанный уровень доверия, тем более расплывчатым будет ответ. Ответы математическая статистика выдает в виде формул, в которые уровень доверия входит как параметр. Так что часто они позволяют выбрать стратегию, позволяющую добиться желательной точности с нужным уровнем доверия к результатам.
Если примем уровень доверия 0, 95 и будем по выборкам строить доверительные интервалы, то в среднем 5 из 100 интервалов не будут содержать истинное значение параметра. Выбор уровня доверия остается за нами. Если цена ошибки высока (разорение, смертельный исход при операции) – может быть, следует задать уровень доверия равным 0, 999, если ошибка грозит тем, что придется взять кредит в банке – можно удовольствоваться уровнем 0, 95. Если лекарство безвредно, то достаточно того, что “оно помогает с уровнем доверия 70%”, чтобы рекомендовать его для применения. Доверительные интервальные оценки вычисляются в соответствии с выбранным уровнем доверия. При этом, конечно, надо учитывать, что чем выше заказанный уровень доверия, тем более расплывчатым будет ответ. Ответы математическая статистика выдает в виде формул, в которые уровень доверия входит как параметр. Так что часто они позволяют выбрать стратегию, позволяющую добиться желательной точности с нужным уровнем доверия к результатам.
 п. 2 доверительный интервал для среднего в случае, когда среднее квадратическое отклонение σ теоретического распределения известно Легко видеть, что выведенная нами формула: (**) – это формула доверительного интервала с уровнем доверия β для математического ожидания а нормального распределения для случая, когда известно среднеквадратическое отклонение распределения σ. Равенство (**) может быть записано в виде или , 2Φ( tβ ) = β Нетрудно видеть, что чем больше n, тем уже интервал, а чем более близкую гарантию β мы требуем, тем доверительный интервал шире.
п. 2 доверительный интервал для среднего в случае, когда среднее квадратическое отклонение σ теоретического распределения известно Легко видеть, что выведенная нами формула: (**) – это формула доверительного интервала с уровнем доверия β для математического ожидания а нормального распределения для случая, когда известно среднеквадратическое отклонение распределения σ. Равенство (**) может быть записано в виде или , 2Φ( tβ ) = β Нетрудно видеть, что чем больше n, тем уже интервал, а чем более близкую гарантию β мы требуем, тем доверительный интервал шире.
 Кроме того, она позволяет оценить, каков должен быть объем выборки n, чтобы точность оценки, полученной по ней для генерального среднего, не превосходила заданного значения ε (эпсилон) с уровнем доверия β. В случаях, когда определение объема выборки в нашей власти, мы можем вычислить, на сколько надо увеличить ее объем, чтобы добиться нужной точности. Так как точность обратно пропорциональна корню из n, то для того, чтобы повысить точность в 2 раза, объем выборки надо увеличить в 4 раза; чтобы повысить точность в 10 раз, число испытаний надо увеличить в 100 раз. Написанное соотношение было выведено в предположении, что дисперсия исходного распределения известна (например, она раньше была установлена по выборке объема больше 50). А целью данного эксперимента является оценить только среднее. Рассмотрим теперь более распространенный случай – когда не только среднее, но и дисперсия генеральной совокупности не известны.
Кроме того, она позволяет оценить, каков должен быть объем выборки n, чтобы точность оценки, полученной по ней для генерального среднего, не превосходила заданного значения ε (эпсилон) с уровнем доверия β. В случаях, когда определение объема выборки в нашей власти, мы можем вычислить, на сколько надо увеличить ее объем, чтобы добиться нужной точности. Так как точность обратно пропорциональна корню из n, то для того, чтобы повысить точность в 2 раза, объем выборки надо увеличить в 4 раза; чтобы повысить точность в 10 раз, число испытаний надо увеличить в 100 раз. Написанное соотношение было выведено в предположении, что дисперсия исходного распределения известна (например, она раньше была установлена по выборке объема больше 50). А целью данного эксперимента является оценить только среднее. Рассмотрим теперь более распространенный случай – когда не только среднее, но и дисперсия генеральной совокупности не известны.
 п. 3. Доверительный интервал для среднего в случае, когда среднеквадратическое отклонение s теоретического распределения неизвестно Нами было показано, что когда дисперсия известна, выборочное среднее имеет нормальное распределение с параметрами а и . Мы отнормировали его – вычли из него математическое ожидание и поделили полученную разность на его среднеквадратическое отклонение. Тем самым перешли от него к стандартной нормальной величине и воспользовались ее свойствами и таблицами. Заменим в этой операции неизвестное среднеквадратическое отклонение его эмпирической оценкой. Рассмотрим статистику (в этой формуле s – корень из s 2 – исправленной, несмещенной оценки для дисперсии: ).
п. 3. Доверительный интервал для среднего в случае, когда среднеквадратическое отклонение s теоретического распределения неизвестно Нами было показано, что когда дисперсия известна, выборочное среднее имеет нормальное распределение с параметрами а и . Мы отнормировали его – вычли из него математическое ожидание и поделили полученную разность на его среднеквадратическое отклонение. Тем самым перешли от него к стандартной нормальной величине и воспользовались ее свойствами и таблицами. Заменим в этой операции неизвестное среднеквадратическое отклонение его эмпирической оценкой. Рассмотрим статистику (в этой формуле s – корень из s 2 – исправленной, несмещенной оценки для дисперсии: ).
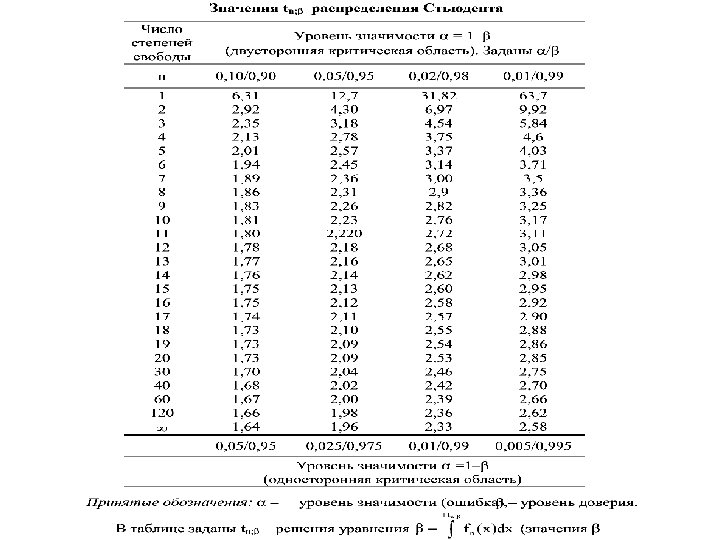
 При нахождении распределения вероятностей для статистики τ мы должны учесть, что неизвестное среднеквадратическое отклонение мы заменили в формулах на его эмпирический аналог. Можно показать, что τ имеет распределение Стьюдента с (n – 1) степенями свободы. Распределением Стьюдента с n степенями свободы называется распределение случайной величины где ξ, ξ 1, ξ 2, . . . , ξn – независимые, стандартные нормальные случайные величины. Это распределение симметрично, а при значениях n > 20 практически неотличимо от нормального. При меньших n разница всетаки есть и ее надо учитывать. Поэтому для распределения Стьюдента существуют многочисленные статистические таблицы.
При нахождении распределения вероятностей для статистики τ мы должны учесть, что неизвестное среднеквадратическое отклонение мы заменили в формулах на его эмпирический аналог. Можно показать, что τ имеет распределение Стьюдента с (n – 1) степенями свободы. Распределением Стьюдента с n степенями свободы называется распределение случайной величины где ξ, ξ 1, ξ 2, . . . , ξn – независимые, стандартные нормальные случайные величины. Это распределение симметрично, а при значениях n > 20 практически неотличимо от нормального. При меньших n разница всетаки есть и ее надо учитывать. Поэтому для распределения Стьюдента существуют многочисленные статистические таблицы.
 Применив те же рассуждения, которые были сделаны в предыдущем пункте, получаем формулу для доверительного интервала для среднего в случае неизвестной дисперсии. А именно, обозначим через tn; b значение, для которого , где ξ имеет распределение Стьюдента с n степенями свободы. Значение tn; b по заданному значению β находится по таблицам распределения Стьюдента аналогично тому, как определяется kβ для нормального распределения, используя таблицу функции Φ(х). При этом надо, правда, еще учитывать значение n. Как правило, таблицы распределения Стьюдента задаются не для всех β, а только для наиболее употребительных значений 0, 9, 0, 95 и 0, 99.
Применив те же рассуждения, которые были сделаны в предыдущем пункте, получаем формулу для доверительного интервала для среднего в случае неизвестной дисперсии. А именно, обозначим через tn; b значение, для которого , где ξ имеет распределение Стьюдента с n степенями свободы. Значение tn; b по заданному значению β находится по таблицам распределения Стьюдента аналогично тому, как определяется kβ для нормального распределения, используя таблицу функции Φ(х). При этом надо, правда, еще учитывать значение n. Как правило, таблицы распределения Стьюдента задаются не для всех β, а только для наиболее употребительных значений 0, 9, 0, 95 и 0, 99.
, и под рукой нет таблиц распределения Стьюдента, а имеются") Если n велико (больше 20), и под рукой нет таблиц распределения Стьюдента, а имеются только более распространенные таблицы нормального распределения, то можно воспользоваться ими, считая, что с хорошей точностью tβ = kβ. Например, если требуемый уровень доверия 0, 95, то можно взять tn; β = 2, а если уровень доверия 0, 997, то tn; β = 3 ( правило 2σ и 3 σ для нормального распределения). Таким образом, для статистики τ, имеющей распределение Стьюдента с (n– 1) степенью свободы, можно записать: P{| τ | < tn– 1; β} = β и, проделав простые тождественные преобразования, получаем, что с вероятностью β выполняется или
Если n велико (больше 20), и под рукой нет таблиц распределения Стьюдента, а имеются только более распространенные таблицы нормального распределения, то можно воспользоваться ими, считая, что с хорошей точностью tβ = kβ. Например, если требуемый уровень доверия 0, 95, то можно взять tn; β = 2, а если уровень доверия 0, 997, то tn; β = 3 ( правило 2σ и 3 σ для нормального распределения). Таким образом, для статистики τ, имеющей распределение Стьюдента с (n– 1) степенью свободы, можно записать: P{| τ | < tn– 1; β} = β и, проделав простые тождественные преобразования, получаем, что с вероятностью β выполняется или
 Эти формула определяют доверительный интервала с уровнем доверия β для математического ожидания а нормального распределения для случая, когда среднеквадратическое отклонение распределения σ неизвестно. Пример. Для проверки по ускоренной методике были отобрано 20 приборов. Были получены следующие результаты наработки на отказ (в часах): 246; 247, 3; 247, 4; 251, 7; 252, 5; 252, 6; 252, 8; 252, 9; 253, 6; 254, 7; 254, 8; 256, 1; 256, 3; 256, 8; 257, 4; 259, 2. Найти доверительный интервал для математического ожидания с надёжностью 0, 95, предполагая, что измеряемая величина распределена нормально. Решение. Находим точечные оценки a и s:
Эти формула определяют доверительный интервала с уровнем доверия β для математического ожидания а нормального распределения для случая, когда среднеквадратическое отклонение распределения σ неизвестно. Пример. Для проверки по ускоренной методике были отобрано 20 приборов. Были получены следующие результаты наработки на отказ (в часах): 246; 247, 3; 247, 4; 251, 7; 252, 5; 252, 6; 252, 8; 252, 9; 253, 6; 254, 7; 254, 8; 256, 1; 256, 3; 256, 8; 257, 4; 259, 2. Найти доверительный интервал для математического ожидания с надёжностью 0, 95, предполагая, что измеряемая величина распределена нормально. Решение. Находим точечные оценки a и s:
 Определяем по таблице распределения Стьюдента для доверительной вероятности β = 0, 95 и числу степеней свободы (n – 1) = 19 соответствующее значение tβ = 2, 093 и по формуле находим искомый интервал: или 251, 27≤ a ≤ 254, 69 . п 4. Оценка требуемого объема выборки Формулы доверительного интервала позволяют заодно решить еще одну интересную задачу: каков должен быть объем выборки n, чтобы с надежностью β точность оценки, полученной по ней для а, не превосходила заданного значения ε, то есть (среднеквадратическое отклонение известно)? Действительно, так как по формуле доверительного интервала с
Определяем по таблице распределения Стьюдента для доверительной вероятности β = 0, 95 и числу степеней свободы (n – 1) = 19 соответствующее значение tβ = 2, 093 и по формуле находим искомый интервал: или 251, 27≤ a ≤ 254, 69 . п 4. Оценка требуемого объема выборки Формулы доверительного интервала позволяют заодно решить еще одну интересную задачу: каков должен быть объем выборки n, чтобы с надежностью β точность оценки, полученной по ней для а, не превосходила заданного значения ε, то есть (среднеквадратическое отклонение известно)? Действительно, так как по формуле доверительного интервала с
 вероятностью β выполняется , то нужное n находится из уравнения , то есть . Следовательно, результат тем точнее, чем больше объем выборки. п 5. Доверительный интервал для вероятности успеха в схеме Бернулли Пусть проводятся независимые испытания, в которых событие А наступает с неизвестной вероятностью р. Ставится задача с помощью выборочных испытаний построить для р точечную и интервальную оценки. Метод моментов нам указывает, что в качестве точечной оценки надо взять значение , где m – число успехов.
вероятностью β выполняется , то нужное n находится из уравнения , то есть . Следовательно, результат тем точнее, чем больше объем выборки. п 5. Доверительный интервал для вероятности успеха в схеме Бернулли Пусть проводятся независимые испытания, в которых событие А наступает с неизвестной вероятностью р. Ставится задача с помощью выборочных испытаний построить для р точечную и интервальную оценки. Метод моментов нам указывает, что в качестве точечной оценки надо взять значение , где m – число успехов.
 Действительно, таблица статистического распределения выборки объема n, в которой m раз произошел “успех” (выпала 1) и n–m раз “неуспех” ( выпал 0), имеет вид (табл. 3. 1): Таблица 3. 1 Неизвестная вероятность р равна математическому ожиданию генерального распределения. Следовательно, метод моментов рекомендует нам взять в качестве оценки для р эмпирическое среднее: Воспользуемся тем, что по теореме Муавра-Лапласа величина распределена приблизительно нормально, т. е. :
Действительно, таблица статистического распределения выборки объема n, в которой m раз произошел “успех” (выпала 1) и n–m раз “неуспех” ( выпал 0), имеет вид (табл. 3. 1): Таблица 3. 1 Неизвестная вероятность р равна математическому ожиданию генерального распределения. Следовательно, метод моментов рекомендует нам взять в качестве оценки для р эмпирическое среднее: Воспользуемся тем, что по теореме Муавра-Лапласа величина распределена приблизительно нормально, т. е. :
 Из этого получаем Воспользовавшись тем, что q = 1–p, получаем, что с вероятностью β выполняется неравенство: Таким образом, для построения доверительного интервала для p можно воспользоваться таблицами нормального распределения. Границы интервала зависят от неизвестной величины р. В руководствах по статистике можно найти формулы для границ, лишенные этого недостатка; мы же воспользуемся тем, что при больших n неизвестное р можно заменить его эмпирическим значением:
Из этого получаем Воспользовавшись тем, что q = 1–p, получаем, что с вероятностью β выполняется неравенство: Таким образом, для построения доверительного интервала для p можно воспользоваться таблицами нормального распределения. Границы интервала зависят от неизвестной величины р. В руководствах по статистике можно найти формулы для границ, лишенные этого недостатка; мы же воспользуемся тем, что при больших n неизвестное р можно заменить его эмпирическим значением:
 Формула доверительного интервала и в этом случае позволяет решить задачу: каков должен быть объем выборки n, чтобы с надежностью β точность оценки, полученной по ней для р, не превосходила заданного значения ε.
Формула доверительного интервала и в этом случае позволяет решить задачу: каков должен быть объем выборки n, чтобы с надежностью β точность оценки, полученной по ней для р, не превосходила заданного значения ε.
 п. 6 Односторонние доверительные интервалы На практике часто пользуются односторонними доверительными интервалами. Например, страховой компании не страшно, если произойдет страховых случаев намного меньше среднего, но страшно, если их произойдет намного больше среднего. Оценивая при покупке среднюю доходность объекта, лучше оценить ее по формуле “не меньше, чем”; при изучении среднего уровня воды в реке в областях, подверженным наводнениям, интересуются уровнем, выше которого вода не поднимется, а в областях, подверженных засухе, наоборот – уровнем, ниже которого вода не опустится. В таких случяаях строят не симметричный относительно оценки интервал, а максимально расширяют его за счет одной из его границ. Если мы построим двусторонний доверительный интервал с гарантией β, а затем максимально расширим его в одну сторону, то получим односторонний интервал с большей гарантией β' = β +(1– β)/2=(1+ β)/2.
п. 6 Односторонние доверительные интервалы На практике часто пользуются односторонними доверительными интервалами. Например, страховой компании не страшно, если произойдет страховых случаев намного меньше среднего, но страшно, если их произойдет намного больше среднего. Оценивая при покупке среднюю доходность объекта, лучше оценить ее по формуле “не меньше, чем”; при изучении среднего уровня воды в реке в областях, подверженным наводнениям, интересуются уровнем, выше которого вода не поднимется, а в областях, подверженных засухе, наоборот – уровнем, ниже которого вода не опустится. В таких случяаях строят не симметричный относительно оценки интервал, а максимально расширяют его за счет одной из его границ. Если мы построим двусторонний доверительный интервал с гарантией β, а затем максимально расширим его в одну сторону, то получим односторонний интервал с большей гарантией β' = β +(1– β)/2=(1+ β)/2.
 Например, если β = 0, 90, то β' = 0, 90 + 0, 10/2 = 0, 95, а если β = 0, 95, то β' = 0, 95 + 0, 05/2 = 0, 975. Таким образом, “односторонний” подход позволяет увеличить уровень доверия, вернее, вдвое снизить ошибку α = 1– β' ( или при том же уровне доверия сузить интервал – вместо tβ можно взять t 2β – 1). Если при построении двусторонних доверительных интервалов надо было решать уравнение: то для построения односторонних доверительных интервалов надо решать уравнение: , .
Например, если β = 0, 90, то β' = 0, 90 + 0, 10/2 = 0, 95, а если β = 0, 95, то β' = 0, 95 + 0, 05/2 = 0, 975. Таким образом, “односторонний” подход позволяет увеличить уровень доверия, вернее, вдвое снизить ошибку α = 1– β' ( или при том же уровне доверия сузить интервал – вместо tβ можно взять t 2β – 1). Если при построении двусторонних доверительных интервалов надо было решать уравнение: то для построения односторонних доверительных интервалов надо решать уравнение: , .
, как для нормального распределения, так и для распределения Стьюдента, симметричная функция") Плотность f(x), как для нормального распределения, так и для распределения Стьюдента, симметричная функция (f(x) = f(–x)), следовательно, для них ошибка, состоящая в непопадании в интервал, симметричный относительно математического ожидания, делится поровну между попаданием в полуинтервал [–∞, –tβ] и полуинтервал [tβ, +∞], то есть вероятность каждого такого полуинтервала вдвое меньше ошибки двустороннего интервала. Следовательно, для поиска нужного kβ при построении одностороннего интервала, надо по заданному уровню доверия β найти его ошибку α = 1– β, затем удвоить ее, взять α' = 2α, вычислить для нее новый уровень доверия β' = 1– α' и найти kβ' для двустороннего интервала с таким уровнем доверия. Очень часто статистические таблицы составляются именно для односторонних интервалов. Этот способ является универсальным, а для несимметричных распределений единственно возможным.
Плотность f(x), как для нормального распределения, так и для распределения Стьюдента, симметричная функция (f(x) = f(–x)), следовательно, для них ошибка, состоящая в непопадании в интервал, симметричный относительно математического ожидания, делится поровну между попаданием в полуинтервал [–∞, –tβ] и полуинтервал [tβ, +∞], то есть вероятность каждого такого полуинтервала вдвое меньше ошибки двустороннего интервала. Следовательно, для поиска нужного kβ при построении одностороннего интервала, надо по заданному уровню доверия β найти его ошибку α = 1– β, затем удвоить ее, взять α' = 2α, вычислить для нее новый уровень доверия β' = 1– α' и найти kβ' для двустороннего интервала с таким уровнем доверия. Очень часто статистические таблицы составляются именно для односторонних интервалов. Этот способ является универсальным, а для несимметричных распределений единственно возможным.
 Значения up, для которых выполняется , называются квантилями. Формулы для односторонних доверительных интервалов, аналогичные формулам двусторонних интервалов: 1. Односторонние доверительные интервалы для математического ожидания а нормального распределения с уровнем доверия β для случая, когда среднеквадратическое отклонение распределения σ известно: и (kβ отыскивается в таблице по α = 1– β)
Значения up, для которых выполняется , называются квантилями. Формулы для односторонних доверительных интервалов, аналогичные формулам двусторонних интервалов: 1. Односторонние доверительные интервалы для математического ожидания а нормального распределения с уровнем доверия β для случая, когда среднеквадратическое отклонение распределения σ известно: и (kβ отыскивается в таблице по α = 1– β)

 2. Односторонние доверительные интервалы для математического ожидания m нормального распределения с уровнем доверия β для случая, когда среднеквадратическое отклонение распределения σ неизвестно: и (tn– 1; β отыскивается в таблице материалов по α = 1–β). Аналогично выписываются формулы односторонних доверительных интервалов для вероятности р схемы Бернулли.
2. Односторонние доверительные интервалы для математического ожидания m нормального распределения с уровнем доверия β для случая, когда среднеквадратическое отклонение распределения σ неизвестно: и (tn– 1; β отыскивается в таблице материалов по α = 1–β). Аналогично выписываются формулы односторонних доверительных интервалов для вероятности р схемы Бернулли.
 п. 7. Доверительный интервал для среднего в случае, когда среднеквадратическое отклонение σ теоретического распределения неизвестно Пусть случайная величина Х распределена нормально. Необходимо найти доверительный интервал для среднего квадратического отклонения σ генеральной совокупности по исправленному выборочному среднему квадратическому отклонению s. Задана надежность β. По общей теории оценки необходимо выполнение соотношения P(| σ - s|<ε) = β или P(s - ε < σ < s + ε ) = β. Далее двойное неравенство s - ε < σ < s + ε преобразуем к виду s(1 – ε /s) < σ < s(1 + ε /s) и обозначим q = ε /s, s(1 – q) < σ < s(1 + q). (*)
п. 7. Доверительный интервал для среднего в случае, когда среднеквадратическое отклонение σ теоретического распределения неизвестно Пусть случайная величина Х распределена нормально. Необходимо найти доверительный интервал для среднего квадратического отклонения σ генеральной совокупности по исправленному выборочному среднему квадратическому отклонению s. Задана надежность β. По общей теории оценки необходимо выполнение соотношения P(| σ - s|<ε) = β или P(s - ε < σ < s + ε ) = β. Далее двойное неравенство s - ε < σ < s + ε преобразуем к виду s(1 – ε /s) < σ < s(1 + ε /s) и обозначим q = ε /s, s(1 – q) < σ < s(1 + q). (*)
 Для определения параметра q используют еще одну случайную величину имеющую распределение ( хи – квадрат): Плотность распределения этой случайной величины имеет вид . Как известно, вероятность попадания случайной величины в заданный интервал равна Преобразуем неравенство (*), чтобы получить границы для
Для определения параметра q используют еще одну случайную величину имеющую распределение ( хи – квадрат): Плотность распределения этой случайной величины имеет вид . Как известно, вероятность попадания случайной величины в заданный интервал равна Преобразуем неравенство (*), чтобы получить границы для
 Получим Далее, . Последнее неравенство выполняется с вероятностью равной Из этого уравнения можно по заданным n и β найти q. Практически для отыскания q составлены таблицы.
Получим Далее, . Последнее неравенство выполняется с вероятностью равной Из этого уравнения можно по заданным n и β найти q. Практически для отыскания q составлены таблицы.