

7f498ec2bbcd8f44108b7697e39496b3.ppt
- Количество слайдов: 47
 Dryad A digital data repository
Dryad A digital data repository
 A typical published data package • Contains data that belongs in a specialized repository (e. g. Genbank, Treebase, Morphbank, PDB, etc. ) • But also contains orphan data
A typical published data package • Contains data that belongs in a specialized repository (e. g. Genbank, Treebase, Morphbank, PDB, etc. ) • But also contains orphan data
 What value is orphan data? • Validation of results § Dinosaur DNA • Development of improved methodologies § Mutation accumulation experiments • Meta-analysis § Particularly at NESCent & NCEAS • Synthesis § GBIF demonstration project
What value is orphan data? • Validation of results § Dinosaur DNA • Development of improved methodologies § Mutation accumulation experiments • Meta-analysis § Particularly at NESCent & NCEAS • Synthesis § GBIF demonstration project
 Published works in evolutionary biology • 27 papers from 5 different journals. • 41% had supplemental materials. • But only 7% included raw orphan data. § Exceptions included simulation results and sequence alignments. § Still, 67% of papers using alignments did not provide them. • Genbank submission was generally honored. • 78% analyzed data not deposited in any repository. • 48% were based at least in part on data from other publications. • Evolutionary biologists use published data more
Published works in evolutionary biology • 27 papers from 5 different journals. • 41% had supplemental materials. • But only 7% included raw orphan data. § Exceptions included simulation results and sequence alignments. § Still, 67% of papers using alignments did not provide them. • Genbank submission was generally honored. • 78% analyzed data not deposited in any repository. • 48% were based at least in part on data from other publications. • Evolutionary biologists use published data more

 • “The act of") Uniform Principle for Sharing Integral Data and Materials Expeditiously (UPSIDE) • “The act of publishing is a quid pro quo in which authors receive credit and acknowledgment in exchange for disclosure of their scientific findings. ” • “An author’s obligation is not only to release data and materials to enable others to verify or replicate published findings [. . . ] but also to provide them in a form on which other scientists can build with further research. ” • “All members of the scientific community […] have equal responsibility for upholding community standards as participants in the publication system, and all should be equally able to derive benefits from it. ”
Uniform Principle for Sharing Integral Data and Materials Expeditiously (UPSIDE) • “The act of publishing is a quid pro quo in which authors receive credit and acknowledgment in exchange for disclosure of their scientific findings. ” • “An author’s obligation is not only to release data and materials to enable others to verify or replicate published findings [. . . ] but also to provide them in a form on which other scientists can build with further research. ” • “All members of the scientific community […] have equal responsibility for upholding community standards as participants in the publication system, and all should be equally able to derive benefits from it. ”
 requested data from the corresponding authors of") Data sharing in practice • Wicherts (2004) requested data from the corresponding authors of 141 articles recently published in American Psychological Association (APA) journals. • All authors had signed a commitment to share their data upon request "6 months later, after writing more than 400 e-mails–and sending some corresponding authors detailed descriptions of our study aims, approvals of our ethical committee, signed assurances not to share data with others, and even our full resumes-we ended up with a meager 38 positive reactions and the actual data sets from 64 studies (25. 7% of the total number of 249 data sets). This means that 73% of the authors did not share their data. "
Data sharing in practice • Wicherts (2004) requested data from the corresponding authors of 141 articles recently published in American Psychological Association (APA) journals. • All authors had signed a commitment to share their data upon request "6 months later, after writing more than 400 e-mails–and sending some corresponding authors detailed descriptions of our study aims, approvals of our ethical committee, signed assurances not to share data with others, and even our full resumes-we ended up with a meager 38 positive reactions and the actual data sets from 64 studies (25. 7% of the total number of 249 data sets). This means that 73% of the authors did not share their data. "
 Obstacles to data reuse • In a survey of 1240 geneticists § 47% had been denied at least one request for data or materials in the preceding 3 yrs § 28% reported that they had been unable to confirm published research because of data withholding • The most common reasons cited for withholding: § Too much effort to produce the data (80%) § Protecting the ability of a junior colleague to publish (64%) § Protecting their own ability to publish (57%).
Obstacles to data reuse • In a survey of 1240 geneticists § 47% had been denied at least one request for data or materials in the preceding 3 yrs § 28% reported that they had been unable to confirm published research because of data withholding • The most common reasons cited for withholding: § Too much effort to produce the data (80%) § Protecting the ability of a junior colleague to publish (64%) § Protecting their own ability to publish (57%).

 Deposition at publication • Avoids loss, corruption, obsolescence of data files • That is when authors are best able to ensure the correctness of data and metadata • Authors have incentive to deposit their data in order to complete the publication process • Journals are best able to monitor compliance with policy • In short, the Genbank model works. § And it is perhaps the only model that works.
Deposition at publication • Avoids loss, corruption, obsolescence of data files • That is when authors are best able to ensure the correctness of data and metadata • Authors have incentive to deposit their data in order to complete the publication process • Journals are best able to monitor compliance with policy • In short, the Genbank model works. § And it is perhaps the only model that works.
 Systematic Biology policy Data: All datasets used in the research for the manuscript must be made available to reviewers unless the data are already published elsewhere. For manuscripts involving phylogenetic analyses, electronic copies of data sets (e. g. nucleotide sequence data and new alignments of previously published data), in nexus format, must be supplied. Data files should also be provided for morphological analyses. All data files should be uploaded onto Manuscript Central during the submission process. Alternative arrangements may be made for very large data files associated with studies using simulations. Sequence data: All nucleotide sequence data and alignments must be submitted to Genbank or EMBL before the paper can be published. In addition, all data matricies and resulting trees must be submitted to Tree. Base (www. treebase. org). Genbank and Tree. Base reference numbers should be provided in the final version of the paper.
Systematic Biology policy Data: All datasets used in the research for the manuscript must be made available to reviewers unless the data are already published elsewhere. For manuscripts involving phylogenetic analyses, electronic copies of data sets (e. g. nucleotide sequence data and new alignments of previously published data), in nexus format, must be supplied. Data files should also be provided for morphological analyses. All data files should be uploaded onto Manuscript Central during the submission process. Alternative arrangements may be made for very large data files associated with studies using simulations. Sequence data: All nucleotide sequence data and alignments must be submitted to Genbank or EMBL before the paper can be published. In addition, all data matricies and resulting trees must be submitted to Tree. Base (www. treebase. org). Genbank and Tree. Base reference numbers should be provided in the final version of the paper.

 Advantages to you, the author • Access to your colleagues’ data • Visibility and citability for your own data § Another way for your work to have high impact • Integration § Combinability with other data adds value to your own • Long-term preservation § Including data format migration • Ad hoc data sharing can be burdensome § Deposition to multiple specialized repositories § Fulfilling individual requests for data takes effort
Advantages to you, the author • Access to your colleagues’ data • Visibility and citability for your own data § Another way for your work to have high impact • Integration § Combinability with other data adds value to your own • Long-term preservation § Including data format migration • Ad hoc data sharing can be burdensome § Deposition to multiple specialized repositories § Fulfilling individual requests for data takes effort
 Draft Joint Data Archiving Policy • As a condition for publication, all data used in the paper should be archived in an appropriate public archive. • The data should be given with sufficient detail that, together with the contents of the paper, each result in the published paper may be re-created. • Authors may elect to have the data publicly available at time of publication, or, if the archive allows, may opt to embargo access to the data […]. • Exceptions may be granted at the discretion of the editor, especially for sensitive information such as the location of endangered species. • The aim is for the consortium of journals to adopt this policy simultaneously.
Draft Joint Data Archiving Policy • As a condition for publication, all data used in the paper should be archived in an appropriate public archive. • The data should be given with sufficient detail that, together with the contents of the paper, each result in the published paper may be re-created. • Authors may elect to have the data publicly available at time of publication, or, if the archive allows, may opt to embargo access to the data […]. • Exceptions may be granted at the discretion of the editor, especially for sensitive information such as the location of endangered species. • The aim is for the consortium of journals to adopt this policy simultaneously.
 American Society of Naturalists American Naturalist Ecological Society of America Ecology, Ecological Letters, Ecological Monographs, etc. European Society for Evolutionary Biology Journal of Evolutionary Biology Society for Integrative and Comparative Biology Society for Molecular Biology and Evolution Society for the Study of Evolution Society for Systematic Biology Commercial journals Molecular Ecology Molecular Phylogenetics and Evolution
American Society of Naturalists American Naturalist Ecological Society of America Ecology, Ecological Letters, Ecological Monographs, etc. European Society for Evolutionary Biology Journal of Evolutionary Biology Society for Integrative and Comparative Biology Society for Molecular Biology and Evolution Society for the Study of Evolution Society for Systematic Biology Commercial journals Molecular Ecology Molecular Phylogenetics and Evolution
 Can this vision be achieved by specialized databases? • There a growing number of specialized databases to which deposition is expected (Genbank, Treebase) § And others are emerging (Morphbank, PDB, etc) • A world in which every datatype had its own required database, each with its own submission system § Would be a huge burden on authors § Would inevitably leave some data orphaned § Might never be financially possible
Can this vision be achieved by specialized databases? • There a growing number of specialized databases to which deposition is expected (Genbank, Treebase) § And others are emerging (Morphbank, PDB, etc) • A world in which every datatype had its own required database, each with its own submission system § Would be a huge burden on authors § Would inevitably leave some data orphaned § Might never be financially possible
 What is the alternative? • A catch-all digital library for data that are § Heterogeneous § Idiosyncratically structured
What is the alternative? • A catch-all digital library for data that are § Heterogeneous § Idiosyncratically structured

 Expert and stakeholder workshops • “Data Preservation, Sharing, and Discovery: Challenges for Small Science in the Digital Era”, NESCent May 2007 § Goal: a shared, trusted digital library of published data § Questions ü Adoption and sustainability ü Intellectual property ü Infrastructure ü Data lifecycle management • A variety of other workshops § NSF Office of Cyberinfrastructure § Series organized by ESA 2006 -2007
Expert and stakeholder workshops • “Data Preservation, Sharing, and Discovery: Challenges for Small Science in the Digital Era”, NESCent May 2007 § Goal: a shared, trusted digital library of published data § Questions ü Adoption and sustainability ü Intellectual property ü Infrastructure ü Data lifecycle management • A variety of other workshops § NSF Office of Cyberinfrastructure § Series organized by ESA 2006 -2007
 A hierarchy of goals Synthesis Sharing Collection/Preservation Discovery
A hierarchy of goals Synthesis Sharing Collection/Preservation Discovery
 Dryad • Repository: www. datadryad. org • Project wiki: driade. nescent. org
Dryad • Repository: www. datadryad. org • Project wiki: driade. nescent. org
 Phase I • Accepts heterogeneous data. § Submission by email to submit@datadryad. org • Assigns globally unique data identifiers. • One can search over shallow metadata.
Phase I • Accepts heterogeneous data. § Submission by email to submit@datadryad. org • Assigns globally unique data identifiers. • One can search over shallow metadata.
 Metadata • “Data about data” • Important for § Findability § Interpretability § Maintainability
Metadata • “Data about data” • Important for § Findability § Interpretability § Maintainability
 • PREMIS (preservation) § § § §") Phase I Metadata • Dublin Core (bibliographic) • PREMIS (preservation) § § § § Name Title Identifier Source Contributor Rights Date Description Subject/keywords Data type Format Size Locality § Fixity/checksum • DDI (document) § Contact § Software format • Darwin Core/EML § Geographic range § Temporal range § Taxonomic scope
Phase I Metadata • Dublin Core (bibliographic) • PREMIS (preservation) § § § § Name Title Identifier Source Contributor Rights Date Description Subject/keywords Data type Format Size Locality § Fixity/checksum • DDI (document) § Contact § Software format • Darwin Core/EML § Geographic range § Temporal range § Taxonomic scope
 What to submit • The data needed to replicate the results in the publication. § Any additional information needed to make the data usable. • Any format is acceptable § Preferred formats (eg ASCII NEXUS) will be specified where appropriate. • Curation § Basic QA/QC to ensure electronic files are valid and contain what they advertise. § Ultimate responsibility for the correctness of the data is in the hands of the submitter.
What to submit • The data needed to replicate the results in the publication. § Any additional information needed to make the data usable. • Any format is acceptable § Preferred formats (eg ASCII NEXUS) will be specified where appropriate. • Curation § Basic QA/QC to ensure electronic files are valid and contain what they advertise. § Ultimate responsibility for the correctness of the data is in the hands of the submitter.
 Unpublished data in Dryad • Datasets of special historical, educational and scientific significance § Particularly long-term data collections that are greater than the sum of their parts. § NESCent’s Distinguished Visiting Scholar program. • Prepublished data from NESCent scientists. • Otherwise, unpublished data is not accepted.
Unpublished data in Dryad • Datasets of special historical, educational and scientific significance § Particularly long-term data collections that are greater than the sum of their parts. § NESCent’s Distinguished Visiting Scholar program. • Prepublished data from NESCent scientists. • Otherwise, unpublished data is not accepted.
 §") Issues of intellectual property • Some data can be copyrighted (e. g. images) § Most data cannot, although law varies by jurisdiction • Most experts downplay the role of legal agreements in regulating data reuse within a “Science Commons” • Instead, scientific norms (for reuse, and for attribution) are thought to be more appropriate § When immediate data sharing might be truly deleterious, an embargo is an option.
Issues of intellectual property • Some data can be copyrighted (e. g. images) § Most data cannot, although law varies by jurisdiction • Most experts downplay the role of legal agreements in regulating data reuse within a “Science Commons” • Instead, scientific norms (for reuse, and for attribution) are thought to be more appropriate § When immediate data sharing might be truly deleterious, an embargo is an option.
 http: //hdl. handle. net/10255/dryad. 23
http: //hdl. handle. net/10255/dryad. 23
 http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle
http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle
 http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle Handle belongs to Dryad
http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle Handle belongs to Dryad
 http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle Handle belongs to Dryad Specific item ID
http: //hdl. handle. net/10255/dryad. 23 Identifier is a handle Handle belongs to Dryad Specific item ID
 Testing for Unequal Rates of Morphological") • Paper citation § Sidlauskas B (2007) Testing for Unequal Rates of Morphological Diversification in the Absence of a Detailed Phylogeny: A Case Study From Characiform Fishes. Evolution 61 (2), 299– 316, doi: 10. 1111/j. 15585646. 2007. 00022. x • Data citation § Sidlauskas B (2007) Relative warps. hdl: 10255/dryad. 23
• Paper citation § Sidlauskas B (2007) Testing for Unequal Rates of Morphological Diversification in the Absence of a Detailed Phylogeny: A Case Study From Characiform Fishes. Evolution 61 (2), 299– 316, doi: 10. 1111/j. 15585646. 2007. 00022. x • Data citation § Sidlauskas B (2007) Relative warps. hdl: 10255/dryad. 23
 Dryad Phase 1
Dryad Phase 1
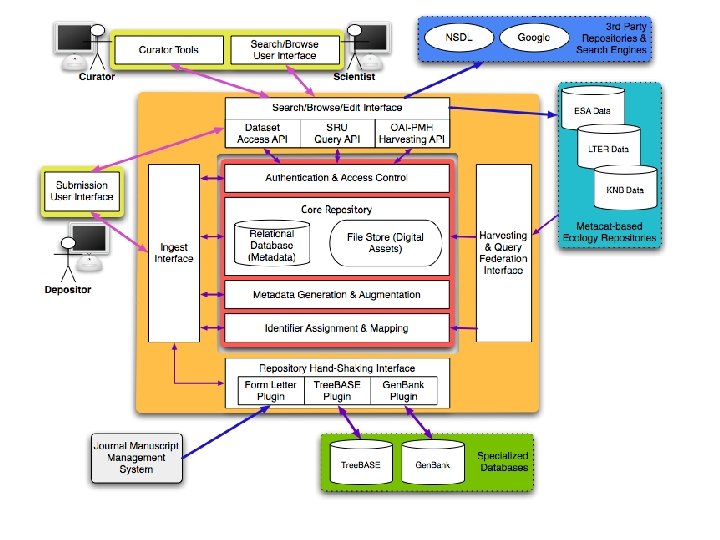
 Goals for Phase II • Integrate data deposition with journal submission. • Provide one-stop data deposition § Through handshaking with specialized repositories. • Generate richer metadata through Natural Language Processing. • Replicate data among sites for preservation (LOCKSS). • Enhance search, retrieval and harvesting § Using library standards (OAI-PMH, SRU) § Transparent access (for Dryad, Meta. Cat, etc) • Establish a self-sustainable business model.
Goals for Phase II • Integrate data deposition with journal submission. • Provide one-stop data deposition § Through handshaking with specialized repositories. • Generate richer metadata through Natural Language Processing. • Replicate data among sites for preservation (LOCKSS). • Enhance search, retrieval and harvesting § Using library standards (OAI-PMH, SRU) § Transparent access (for Dryad, Meta. Cat, etc) • Establish a self-sustainable business model.
 Dryad Phase II Partners NCSU Digital Library Program
Dryad Phase II Partners NCSU Digital Library Program
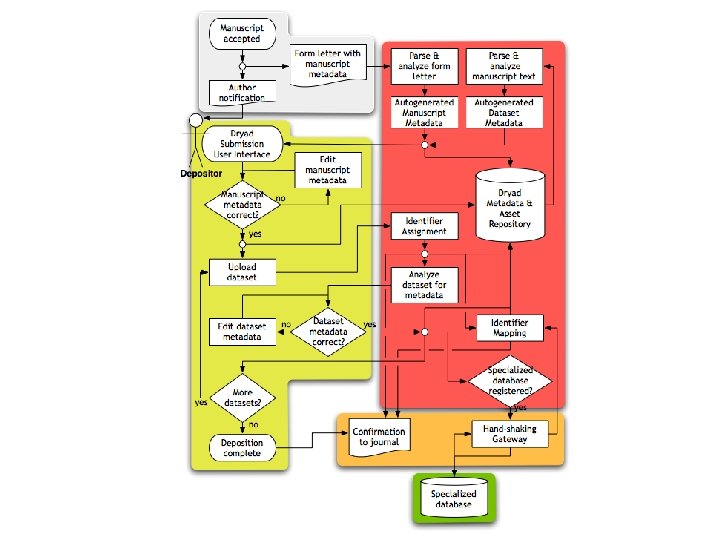
 Submission process
Submission process
 How will Dryad be managed? • Each journal has a voting representative on a Management Board • The MB sets policy regarding such things as § Data attribution and reuse § Embargos § Coordinated requirement for submission • The MB also has ultimate responsibility for financial self-sustainability
How will Dryad be managed? • Each journal has a voting representative on a Management Board • The MB sets policy regarding such things as § Data attribution and reuse § Embargos § Coordinated requirement for submission • The MB also has ultimate responsibility for financial self-sustainability
 Research topics • Gathering baseline information about data sharing and reuse § To better design the repository § And evaluate its future impact § Through user surveys, individual interviews, quantifying patterns the literature • Integration of multiple controlled vocabularies § For taxa, geography, concepts, etc. • Automated tools for metadata generation and curation
Research topics • Gathering baseline information about data sharing and reuse § To better design the repository § And evaluate its future impact § Through user surveys, individual interviews, quantifying patterns the literature • Integration of multiple controlled vocabularies § For taxa, geography, concepts, etc. • Automated tools for metadata generation and curation
 An incomplete list of credits • NESCent § Ryan Scherle, Rosie Kilgore, Hilmar Lapp • UNC Metadata Center § Jane Greenberg and an army of SILS students • Phase II partners § William Michener (LTER), Ilene Karsch Mizrachi (NCBI), Kristin Antelman (NCSU Digital LIbrary), Bill Piel (Tree. Base) • The many society officers, journal editors and other workshop participants § Special thanks to Mike Whitlock • All of you who have provided data and given generously of your time in various ways.
An incomplete list of credits • NESCent § Ryan Scherle, Rosie Kilgore, Hilmar Lapp • UNC Metadata Center § Jane Greenberg and an army of SILS students • Phase II partners § William Michener (LTER), Ilene Karsch Mizrachi (NCBI), Kristin Antelman (NCSU Digital LIbrary), Bill Piel (Tree. Base) • The many society officers, journal editors and other workshop participants § Special thanks to Mike Whitlock • All of you who have provided data and given generously of your time in various ways.

 Researchers") DRIADE Phase II DRIADE Journals Specialized repositories (eg Genbank, Morphbank, Paleo. DB, Treebase) Researchers
DRIADE Phase II DRIADE Journals Specialized repositories (eg Genbank, Morphbank, Paleo. DB, Treebase) Researchers
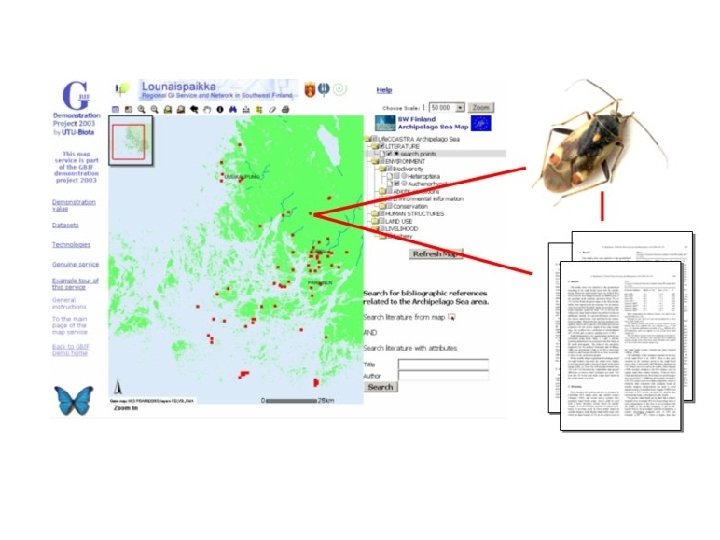
 Most published evolutionary data today
Most published evolutionary data today
 Morpho
Morpho
 GBIF KNB NSDL ICPSR MMI Provide tools and incentives to researchers Minimize technical expertise and time required by contributors for deposit and access Provide long-term data stewardship Accommodate heterogeneous digital datasets Respect intellectual property rights Focus on published datasets
GBIF KNB NSDL ICPSR MMI Provide tools and incentives to researchers Minimize technical expertise and time required by contributors for deposit and access Provide long-term data stewardship Accommodate heterogeneous digital datasets Respect intellectual property rights Focus on published datasets