

Динмаические структуры данных.pptx
- Количество слайдов: 73
 Динамические структуры данных
Динамические структуры данных
 Динамические структуры данных • Часто в серьезных программах надо использовать данные, размер и структура которых должны меняться в процессе работы. • Динамические массивы здесь не выручают, поскольку заранее нельзя сказать, сколько памяти надо выделить – это выясняется только в процессе работы. Например, надо проанализировать текст и определить, какие слова и в каком количество в нем встречаются, причем эти слова нужно расставить по алфавиту.
Динамические структуры данных • Часто в серьезных программах надо использовать данные, размер и структура которых должны меняться в процессе работы. • Динамические массивы здесь не выручают, поскольку заранее нельзя сказать, сколько памяти надо выделить – это выясняется только в процессе работы. Например, надо проанализировать текст и определить, какие слова и в каком количество в нем встречаются, причем эти слова нужно расставить по алфавиту.
 Динамические структуры данных • В таких случаях применяют данные особой структуры, которые представляют собой отдельные элементы, связанные с помощью ссылок. • Каждый элемент (узел) состоит из двух областей памяти: поля данных и ссылок. Ссылки – это адреса других узлов этого же типа, с которыми данный элемент логически связан.
Динамические структуры данных • В таких случаях применяют данные особой структуры, которые представляют собой отдельные элементы, связанные с помощью ссылок. • Каждый элемент (узел) состоит из двух областей памяти: поля данных и ссылок. Ссылки – это адреса других узлов этого же типа, с которыми данный элемент логически связан.
 Линейный список • В простейшем случае каждый узел содержит всего одну ссылку. Для определенности будем считать, что решается задача частотного анализа текста – определения всех слов, встречающихся в тексте и их количества. В этом случае область данных элемента включает строку (длиной не более 40 символов) и целое число.
Линейный список • В простейшем случае каждый узел содержит всего одну ссылку. Для определенности будем считать, что решается задача частотного анализа текста – определения всех слов, встречающихся в тексте и их количества. В этом случае область данных элемента включает строку (длиной не более 40 символов) и целое число.
 хранить адрес") Линейный список • Чтобы не потерять список, мы должны где-то (в переменной) хранить адрес его первого узла – он называется «головой» списка. В программе надо объявить два новых типа данных – узел списка Node и указатель на него PNode. Узел представляет собой структуру, которая содержит три поля - строку, целое число и указатель на такой же узел.
Линейный список • Чтобы не потерять список, мы должны где-то (в переменной) хранить адрес его первого узла – он называется «головой» списка. В программе надо объявить два новых типа данных – узел списка Node и указатель на него PNode. Узел представляет собой структуру, которая содержит три поля - строку, целое число и указатель на такой же узел.
![Линейный список struct Node { char word[40]; // область данных int count; Node *next;](https://present5.com/presentation/96158231_143546884/image-6.jpg "Линейный список struct Node { char word[40]; // область данных int count; Node *next;") Линейный список struct Node { char word[40]; // область данных int count; Node *next; // ссылка на следующий узел }; typedef Node *PNode; // тип данных: указатель на узел PNode Head = NULL;
Линейный список struct Node { char word[40]; // область данных int count; Node *next; // ссылка на следующий узел }; typedef Node *PNode; // тип данных: указатель на узел PNode Head = NULL;
 Создание элемента списка • Для того, чтобы добавить узел к списку, необходимо создать его, то есть выделить память под узел и запомнить адрес выделенного блока. Будем считать, что надо добавить к списку узел, соответствующий новому слову, которое записано в переменной New. Word. Составим функцию, которая создает новый узел в памяти и возвращает его адрес.
Создание элемента списка • Для того, чтобы добавить узел к списку, необходимо создать его, то есть выделить память под узел и запомнить адрес выделенного блока. Будем считать, что надо добавить к списку узел, соответствующий новому слову, которое записано в переменной New. Word. Составим функцию, которая создает новый узел в памяти и возвращает его адрес.
![Создание элемента списка PNode Create. Node ( char New. Word[] ) { PNode New.](https://present5.com/presentation/96158231_143546884/image-8.jpg "Создание элемента списка PNode Create. Node ( char New. Word[] ) { PNode New.") Создание элемента списка PNode Create. Node ( char New. Word[] ) { PNode New. Node = new Node; // указатель на новый узел strcpy(New. Node->word, New. Word); // записать слово New. Node->count = 1; // счетчик слов = 1 New. Node->next = NULL; // следующего узла нет return New. Node; // результат функции – адрес узла }
Создание элемента списка PNode Create. Node ( char New. Word[] ) { PNode New. Node = new Node; // указатель на новый узел strcpy(New. Node->word, New. Word); // записать слово New. Node->count = 1; // счетчик слов = 1 New. Node->next = NULL; // следующего узла нет return New. Node; // результат функции – адрес узла }
 Добавление узла в начало списка • При добавлении нового узла New. Node в начало списка надо • 1) установить ссылку узла New. Node на голову существующего списка и • 2) установить голову списка на новый узел.
Добавление узла в начало списка • При добавлении нового узла New. Node в начало списка надо • 1) установить ссылку узла New. Node на голову существующего списка и • 2) установить голову списка на новый узел.
 {") Добавление узла в начало списка void Add. First (PNode &Head, PNode New. Node) { New. Node->next = Head; Head = New. Node; } Предполагается, что адрес начала списка хранится в Head. Важно, что здесь и далее адрес начала списка передается по ссылке, так как при добавлении нового узла он изменяется внутри процедуры.
Добавление узла в начало списка void Add. First (PNode &Head, PNode New. Node) { New. Node->next = Head; Head = New. Node; } Предполагается, что адрес начала списка хранится в Head. Важно, что здесь и далее адрес начала списка передается по ссылке, так как при добавлении нового узла он изменяется внутри процедуры.
 Добавление узла после заданного Дан адрес New. Node нового узла и адрес p одного из существующих узлов в списке. Требуется вставить в список новый узел после узла с адресом p. Эта операция выполняется в два этапа: 1) установить ссылку нового узла на узел, следующий за данным; 2) установить ссылку данного узла p на New. Node.
Добавление узла после заданного Дан адрес New. Node нового узла и адрес p одного из существующих узлов в списке. Требуется вставить в список новый узел после узла с адресом p. Эта операция выполняется в два этапа: 1) установить ссылку нового узла на узел, следующий за данным; 2) установить ссылку данного узла p на New. Node.
 { New.") Добавление узла после заданного void Add. After (PNode p, PNode New. Node) { New. Node->next = p->next; p->next = New. Node; }
Добавление узла после заданного void Add. After (PNode p, PNode New. Node) { New. Node->next = p->next; p->next = New. Node; }
 Добавление узла перед заданным Эта схема добавления самая сложная. Проблема заключается в том, что в простейшем линейном списке (он называется односвязным, потому что связи направлены только в одну сторону) для того, чтобы получить адрес предыдущего узла, нужно пройти весь список сначала. Задача сведется либо к вставке узла в начало списка (если заданный узел – первый), либо к вставке после заданного узла.
Добавление узла перед заданным Эта схема добавления самая сложная. Проблема заключается в том, что в простейшем линейном списке (он называется односвязным, потому что связи направлены только в одну сторону) для того, чтобы получить адрес предыдущего узла, нужно пройти весь список сначала. Задача сведется либо к вставке узла в начало списка (если заданный узел – первый), либо к вставке после заданного узла.
 {") Добавление узла перед заданным void Add. Before(PNode &Head, PNode p, PNode New. Node) { PNode q = Head; if (Head == p) { Add. First(Head, New. Node); // вставка перед первым узлом return; } while (q && q->next!=p) // ищем узел, за которым следует p q = q->next; if ( q ) // если нашли такой узел, Add. After(q, New. Node); // добавить новый после него }
Добавление узла перед заданным void Add. Before(PNode &Head, PNode p, PNode New. Node) { PNode q = Head; if (Head == p) { Add. First(Head, New. Node); // вставка перед первым узлом return; } while (q && q->next!=p) // ищем узел, за которым следует p q = q->next; if ( q ) // если нашли такой узел, Add. After(q, New. Node); // добавить новый после него }
 Добавление узла перед заданным Существует еще один интересный прием: если надо вставить новый узел New. Node до заданного узла p, вставляют узел после этого узла, а потом выполняется обмен данными между узлами New. Node и p. Таким образом, по адресу p в самом деле будет расположен узел с новыми данными, а по адресу New. Node – с теми данными, которые были в узле p, то есть мы решили задачу.
Добавление узла перед заданным Существует еще один интересный прием: если надо вставить новый узел New. Node до заданного узла p, вставляют узел после этого узла, а потом выполняется обмен данными между узлами New. Node и p. Таким образом, по адресу p в самом деле будет расположен узел с новыми данными, а по адресу New. Node – с теми данными, которые были в узле p, то есть мы решили задачу.
 Добавление узла в конец списка • Для решения задачи надо сначала найти последний узел, у которого ссылка равна NULL, а затем воспользоваться процедурой вставки после заданного узла. Отдельно надо обработать случай, когда список пуст.
Добавление узла в конец списка • Для решения задачи надо сначала найти последний узел, у которого ссылка равна NULL, а затем воспользоваться процедурой вставки после заданного узла. Отдельно надо обработать случай, когда список пуст.
 { PNode") Добавление узла в конец списка void Add. Last(PNode &Head, PNode New. Node) { PNode q = Head; if (Head == NULL) { // если список пуст, Add. First(Head, New. Node); // вставляем первый элемент return; } while (q->next) q = q->next; // ищем последний элемент Add. After(q, New. Node); }
Добавление узла в конец списка void Add. Last(PNode &Head, PNode New. Node) { PNode q = Head; if (Head == NULL) { // если список пуст, Add. First(Head, New. Node); // вставляем первый элемент return; } while (q->next) q = q->next; // ищем последний элемент Add. After(q, New. Node); }
 Проход по списку • Для того, чтобы пройти весь список и сделать что-либо с каждым его элементом, надо начать с головы и, используя указатель next, продвигаться к следующему узлу. PNode p = Head; // начали с головы списка while ( p != NULL ) { // пока не дошли до конца // делаем что-нибудь с узлом p p = p->next; // переходим к следующему узлу }
Проход по списку • Для того, чтобы пройти весь список и сделать что-либо с каждым его элементом, надо начать с головы и, используя указатель next, продвигаться к следующему узлу. PNode p = Head; // начали с головы списка while ( p != NULL ) { // пока не дошли до конца // делаем что-нибудь с узлом p p = p->next; // переходим к следующему узлу }
 Поиск узла в списке • Часто требуется найти в списке нужный элемент (его адрес или данные). Надо учесть, что требуемого элемента может и не быть, тогда просмотр заканчивается при достижении конца списка. Такой подход приводит к следующему алгоритму: 1) начать с головы списка; 2) пока текущий элемент существует (указатель – не NULL), проверить нужное условие и перейти к следующему элементу; 3) закончить, когда найден требуемый элемент или все элементы списка просмотрены.
Поиск узла в списке • Часто требуется найти в списке нужный элемент (его адрес или данные). Надо учесть, что требуемого элемента может и не быть, тогда просмотр заканчивается при достижении конца списка. Такой подход приводит к следующему алгоритму: 1) начать с головы списка; 2) пока текущий элемент существует (указатель – не NULL), проверить нужное условие и перейти к следующему элементу; 3) закончить, когда найден требуемый элемент или все элементы списка просмотрены.
![Поиск узла в списке PNode Find (PNode Head, char New. Word[]) { PNode q](https://present5.com/presentation/96158231_143546884/image-20.jpg "Поиск узла в списке PNode Find (PNode Head, char New. Word[]) { PNode q") Поиск узла в списке PNode Find (PNode Head, char New. Word[]) { PNode q = Head; while (q && strcmp(q->word, New. Word)) q = q->next; return q; } • Функция ищет в списке элемент, соответствующий заданному слову (для которого поле word совпадает с заданной строкой New. Word), и возвращает его адрес или NULL, если такого узла нет.
Поиск узла в списке PNode Find (PNode Head, char New. Word[]) { PNode q = Head; while (q && strcmp(q->word, New. Word)) q = q->next; return q; } • Функция ищет в списке элемент, соответствующий заданному слову (для которого поле word совпадает с заданной строкой New. Word), и возвращает его адрес или NULL, если такого узла нет.
 Задача построения алфавитночастотного словаря • Для того, чтобы добавить новое слово в нужное место (в алфавитном порядке), требуется найти адрес узла, перед которым надо вставить новое слово. Это будет первый от начала списка узел, для которого «его» слово окажется «больше» , чем новое слово.
Задача построения алфавитночастотного словаря • Для того, чтобы добавить новое слово в нужное место (в алфавитном порядке), требуется найти адрес узла, перед которым надо вставить новое слово. Это будет первый от начала списка узел, для которого «его» слово окажется «больше» , чем новое слово.
![Задача построения алфавитночастотного словаря PNode Find. Place (PNode Head, char New. Word[]) { PNode](https://present5.com/presentation/96158231_143546884/image-22.jpg "Задача построения алфавитночастотного словаря PNode Find. Place (PNode Head, char New. Word[]) { PNode") Задача построения алфавитночастотного словаря PNode Find. Place (PNode Head, char New. Word[]) { PNode q = Head; while (q && (strcmp(q->word, New. Word) > 0)) q = q->next; return q; } • Чтобы добавить новое слово в нужное место (в алфавитном порядке), требуется найти адрес узла, перед которым надо вставить новое слово.
Задача построения алфавитночастотного словаря PNode Find. Place (PNode Head, char New. Word[]) { PNode q = Head; while (q && (strcmp(q->word, New. Word) > 0)) q = q->next; return q; } • Чтобы добавить новое слово в нужное место (в алфавитном порядке), требуется найти адрес узла, перед которым надо вставить новое слово.
 Удаление узла • Эта процедура также связана с поиском заданного узла по всему списку, так как нам надо поменять ссылку у предыдущего узла, а перейти к нему непосредственно невозможно. Если мы нашли узел, за которым идет удаляемый узел, надо просто переставить ссылку.
Удаление узла • Эта процедура также связана с поиском заданного узла по всему списку, так как нам надо поменять ссылку у предыдущего узла, а перейти к нему непосредственно невозможно. Если мы нашли узел, за которым идет удаляемый узел, надо просто переставить ссылку.
 { PNode q = Head;") Удаление узла void Delete. Node(PNode &Head, PNode Old. Node) { PNode q = Head; if (Head == Old. Node) Head = Old. Node->next; // удаляем первый элемент else { while (q && q->next != Old. Node) // ищем элемент q = q->next; if ( q == NULL ) return; // если не нашли, выход q->next = Old. Node->next; } delete Old. Node; // освобождаем память }
Удаление узла void Delete. Node(PNode &Head, PNode Old. Node) { PNode q = Head; if (Head == Old. Node) Head = Old. Node->next; // удаляем первый элемент else { while (q && q->next != Old. Node) // ищем элемент q = q->next; if ( q == NULL ) return; // если не нашли, выход q->next = Old. Node->next; } delete Old. Node; // освобождаем память }
 Двусвязный список • Многие проблемы при работе с односвязным списком вызваны тем, что в них невозможно перейти к предыдущему элементу. Возникает естественная идея – хранить в памяти ссылку не только на следующий, но и на предыдущий элемент списка. Для доступа к списку используется не одна переменная-указатель, а две – ссылка на «голову» списка (Head) и на «хвост» - последний элемент (Tail).
Двусвязный список • Многие проблемы при работе с односвязным списком вызваны тем, что в них невозможно перейти к предыдущему элементу. Возникает естественная идея – хранить в памяти ссылку не только на следующий, но и на предыдущий элемент списка. Для доступа к списку используется не одна переменная-указатель, а две – ссылка на «голову» списка (Head) и на «хвост» - последний элемент (Tail).
![Двусвязный список struct Node {char word[40]; // область данных int count; Node *next, *prev;](https://present5.com/presentation/96158231_143546884/image-26.jpg "Двусвязный список struct Node {char word[40]; // область данных int count; Node *next, *prev;") Двусвязный список struct Node {char word[40]; // область данных int count; Node *next, *prev; // ссылки на соседние узлы }; typedef Node *PNode; // тип данных «указатель на узел» PNode Head = NULL, Tail = NULL;
Двусвязный список struct Node {char word[40]; // область данных int count; Node *next, *prev; // ссылки на соседние узлы }; typedef Node *PNode; // тип данных «указатель на узел» PNode Head = NULL, Tail = NULL;
 Операции с двусвязным списком • • • Добавление узла в начало списка Добавление узла в конец списка Добавление узла после заданного Поиск узла в списке Удаление узла
Операции с двусвязным списком • • • Добавление узла в начало списка Добавление узла в конец списка Добавление узла после заданного Поиск узла в списке Удаление узла
 Добавление узла в начало списка
Добавление узла в начало списка
") Добавление узла в начало списка void Add. First(PNode &Head, PNode &Tail, PNode New. Node) { New. Node->next = Head; New. Node->prev = NULL; if ( Head ) Head->prev = New. Node; Head = New. Node; if ( ! Tail ) Tail = Head; // этот элемент – первый }
Добавление узла в начало списка void Add. First(PNode &Head, PNode &Tail, PNode New. Node) { New. Node->next = Head; New. Node->prev = NULL; if ( Head ) Head->prev = New. Node; Head = New. Node; if ( ! Tail ) Tail = Head; // этот элемент – первый }
 Добавление узла после заданного Удаление узла
Добавление узла после заданного Удаление узла
 Добавление узла после заданного void Add. After (PNode &Head, PNode &Tail, PNode p, PNode New. Node) { if ( ! p->next ) Add. Last (Head, Tail, New. Node); // вставка в конец списка else { New. Node->next = p->next; // меняем ссылки нового узла New. Node->prev = p; p->next->prev = New. Node; // меняем ссылки соседних узлов p->next = New. Node; } }
Добавление узла после заданного void Add. After (PNode &Head, PNode &Tail, PNode p, PNode New. Node) { if ( ! p->next ) Add. Last (Head, Tail, New. Node); // вставка в конец списка else { New. Node->next = p->next; // меняем ссылки нового узла New. Node->prev = p; p->next->prev = New. Node; // меняем ссылки соседних узлов p->next = New. Node; } }
 { if (Head ==") Удаление узла void Delete(PNode &Head, PNode &Tail, PNode Old. Node) { if (Head == Old. Node) { Head = Old. Node->next; // удаляем первый элемент if ( Head ) Head->prev = NULL; else Tail = NULL; // удалили единственный элемент } else { Old. Node->prev->next = Old. Node->next; if ( Old. Node->next ) Old. Node->next->prev = Old. Node->prev; else Tail = NULL; // удалили последний элемент } delete Old. Node; }
Удаление узла void Delete(PNode &Head, PNode &Tail, PNode Old. Node) { if (Head == Old. Node) { Head = Old. Node->next; // удаляем первый элемент if ( Head ) Head->prev = NULL; else Tail = NULL; // удалили единственный элемент } else { Old. Node->prev->next = Old. Node->next; if ( Old. Node->next ) Old. Node->next->prev = Old. Node->prev; else Tail = NULL; // удалили последний элемент } delete Old. Node; }
 Стеки, очереди
Стеки, очереди
 Стек • Стек – это упорядоченный набор элементов, в котором добавление новых и удаление существующих элементов допустимо только с одного конца, который называется вершиной стека. • Стек называют структурой типа LIFO (Last In – First Out) – последним пришел, первым ушел.
Стек • Стек – это упорядоченный набор элементов, в котором добавление новых и удаление существующих элементов допустимо только с одного конца, который называется вершиной стека. • Стек называют структурой типа LIFO (Last In – First Out) – последним пришел, первым ушел.
 Стек
Стек
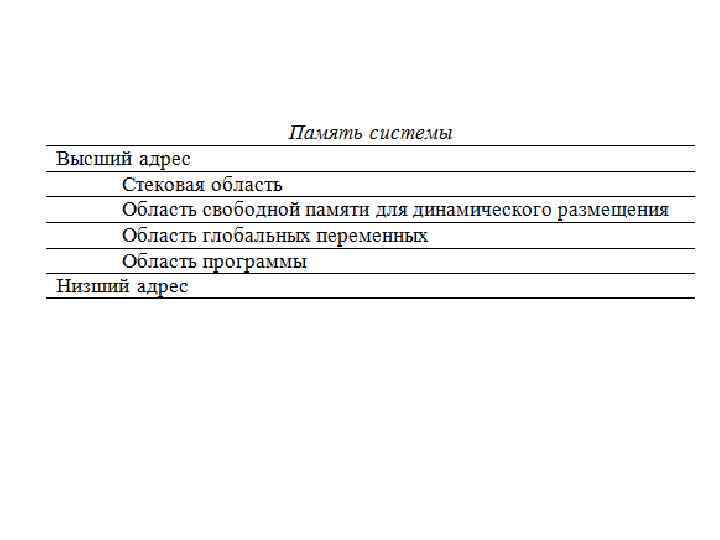
 Стек В современных компьютерах стек используется для • размещения локальных переменных; • размещения параметров процедуры или функции; • сохранения адреса возврата (по какому адресу надо вернуться из процедуры); • временного хранения данных, особенно при программировании на Ассемблере.
Стек В современных компьютерах стек используется для • размещения локальных переменных; • размещения параметров процедуры или функции; • сохранения адреса возврата (по какому адресу надо вернуться из процедуры); • временного хранения данных, особенно при программировании на Ассемблере.
 •") Две операции при работе со стеком • добавление элемента на вершину стека (Push) • снятие элемента с вершины стека (Pop) Поэтому для реализации стека необходимо написать две функции: push(), которая "заталкивает" значение в стек, и pop(), которая "выталкивает" значение из стека
Две операции при работе со стеком • добавление элемента на вершину стека (Push) • снятие элемента с вершины стека (Pop) Поэтому для реализации стека необходимо написать две функции: push(), которая "заталкивает" значение в стек, и pop(), которая "выталкивает" значение из стека
 Способы задания стека • Также необходимо выделить область памяти, которая будет использоваться в качестве стека. Для этой цели можно отвести массив или динамически выделить фрагмент памяти с помощью функций языка С, предусмотренных для динамического распределения памяти.
Способы задания стека • Также необходимо выделить область памяти, которая будет использоваться в качестве стека. Для этой цели можно отвести массив или динамически выделить фрагмент памяти с помощью функций языка С, предусмотренных для динамического распределения памяти.
![Реализация стека на массиве int stack[MAX]; int tos=0; /* вершина стека */ /* Затолкать](https://present5.com/presentation/96158231_143546884/image-40.jpg "Реализация стека на массиве int stack[MAX]; int tos=0; /* вершина стека */ /* Затолкать") Реализация стека на массиве int stack[MAX]; int tos=0; /* вершина стека */ /* Затолкать элемент в стек. */ void push(int i) { } if(tos >= MAX) { printf("Стек полонn"); return; } stack[tos] = i; tos++;
Реализация стека на массиве int stack[MAX]; int tos=0; /* вершина стека */ /* Затолкать элемент в стек. */ void push(int i) { } if(tos >= MAX) { printf("Стек полонn"); return; } stack[tos] = i; tos++;
 { tos--;") Реализация стека на массиве /* Получить верхний элемент стека. */ int pop(void) { tos--; if(tos < 0) { printf("Стек пустn"); return 0; } return stack[tos]; }
Реализация стека на массиве /* Получить верхний элемент стека. */ int pop(void) { tos--; if(tos < 0) { printf("Стек пустn"); return 0; } return stack[tos]; }
 Реализация стека на массиве Переменная tos ("top of stack" — "вершина стека") содержит индекс вершины стека. При реализации данных функций необходимо учитывать случаи, когда стек заполнен или пуст. В нашем случае признаком пустого стека является равенство tos нулю, а признаком переполнения стека — такое увеличение tos, что его значение указывает куда-нибудь за пределы последней ячейки массива.
Реализация стека на массиве Переменная tos ("top of stack" — "вершина стека") содержит индекс вершины стека. При реализации данных функций необходимо учитывать случаи, когда стек заполнен или пуст. В нашем случае признаком пустого стека является равенство tos нулю, а признаком переполнения стека — такое увеличение tos, что его значение указывает куда-нибудь за пределы последней ячейки массива.
 Использование стека • Прекрасный пример использования стека — калькулятор с четырьмя действиями. Большинство современных калькуляторов воспринимают стандартную запись выражений, называемую инфиксной записью, общая форма которой выглядит как операндоператор-операнд. • Например, чтобы сложить 100 и 200, необходимо ввести 100, нажать кнопку "плюс" ("+"), затем ввести 200 и нажать кнопку "равно" ("=").
Использование стека • Прекрасный пример использования стека — калькулятор с четырьмя действиями. Большинство современных калькуляторов воспринимают стандартную запись выражений, называемую инфиксной записью, общая форма которой выглядит как операндоператор-операнд. • Например, чтобы сложить 100 и 200, необходимо ввести 100, нажать кнопку "плюс" ("+"), затем ввести 200 и нажать кнопку "равно" ("=").
 применяется") Использование стека • Напротив, во многих ранних калькуляторах (и некоторых из производимых сегодня) применяется постфиксная запись или польская, в которой сначала вводятся оба операнда, а затем оператор. • Например, чтобы сложить 100 и 200 в постфиксной записи, необходимо ввести 100, затем 200, а потом нажать клавишу "плюс". В этом методе операнды при вводе заталкиваются в стек. При вводе оператора операнды извлекаются (выталкиваются) из стека, а результат помещается обратно в стек.
Использование стека • Напротив, во многих ранних калькуляторах (и некоторых из производимых сегодня) применяется постфиксная запись или польская, в которой сначала вводятся оба операнда, а затем оператор. • Например, чтобы сложить 100 и 200 в постфиксной записи, необходимо ввести 100, затем 200, а потом нажать клавишу "плюс". В этом методе операнды при вводе заталкиваются в стек. При вводе оператора операнды извлекаются (выталкиваются) из стека, а результат помещается обратно в стек.
 Реализация стека с помощью списка • В отличие от статической реализации на основе массива, при использовании механизма динамического выделения памяти в стек можно занести любое число элементов. • Ограничением является только размер области памяти, выделяемой для размещения динамически создаваемых переменных. При динамической реализации элементы стека могут располагаться в ЛЮБЫХ свободных областях памяти, но при этом необходимо как-то связывать соседние элементы друг с другом.
Реализация стека с помощью списка • В отличие от статической реализации на основе массива, при использовании механизма динамического выделения памяти в стек можно занести любое число элементов. • Ограничением является только размер области памяти, выделяемой для размещения динамически создаваемых переменных. При динамической реализации элементы стека могут располагаться в ЛЮБЫХ свободных областях памяти, но при этом необходимо как-то связывать соседние элементы друг с другом.
 Реализация стека с помощью списка • Рассмотрим пример стека, в котором хранятся символы (это простейший вариант, элементом стека могут быть любые типы данных или структур, так же, как и для списка). Реализуем стек на основе двусвязного списка. При этом количество элементов стека ограничивается только доступным объемом памяти.
Реализация стека с помощью списка • Рассмотрим пример стека, в котором хранятся символы (это простейший вариант, элементом стека могут быть любые типы данных или структур, так же, как и для списка). Реализуем стек на основе двусвязного списка. При этом количество элементов стека ограничивается только доступным объемом памяти.
 Реализация стека с помощью списка • Для программной реализации элемент стека надо объявить как структуру, содержащую по крайней мере два поля – информационное и связующее. Для простоты будем считать, что информационное поле каждого элемента содержит только одно целое число. • struct Stack. Item { int Info; Stack. Item *Next; }; • .
Реализация стека с помощью списка • Для программной реализации элемент стека надо объявить как структуру, содержащую по крайней мере два поля – информационное и связующее. Для простоты будем считать, что информационное поле каждого элемента содержит только одно целое число. • struct Stack. Item { int Info; Stack. Item *Next; }; • .
 Реализация стека с помощью списка • Какие ссылочные переменные необходимы для поддержки работы стека? Во-первых, всегда необходимо знать адрес элемента, находящегося на вершине стека, т. е. помещенного в стек самым последним: • Stack. Item *Sp=NULL;
Реализация стека с помощью списка • Какие ссылочные переменные необходимы для поддержки работы стека? Во-первых, всегда необходимо знать адрес элемента, находящегося на вершине стека, т. е. помещенного в стек самым последним: • Stack. Item *Sp=NULL;
 Реализация стека с помощью списка • Тогда конструкция Sp->Info будет представлять саму информационную часть, а конструкция Sp>Next - адрес предыдущего элемента, который был помещен в стек непосредственно перед текущим. • Кроме того, для прохода по стеку от вершинного элемента к самому первому элементу необходима вспомогательная ссылочная переменная (например – с именем Current).
Реализация стека с помощью списка • Тогда конструкция Sp->Info будет представлять саму информационную часть, а конструкция Sp>Next - адрес предыдущего элемента, который был помещен в стек непосредственно перед текущим. • Кроме того, для прохода по стеку от вершинного элемента к самому первому элементу необходима вспомогательная ссылочная переменная (например – с именем Current).
") Реализация стека с помощью списка • Stack. Item *Current = Sp; while(Current != NULL) { cout << Current->Info << " "; Current = Current->Next; }
Реализация стека с помощью списка • Stack. Item *Current = Sp; while(Current != NULL) { cout << Current->Info << " "; Current = Current->Next; }
 Добавление нового элемента в вершину стека • Необходимые шаги: 1. выделить память для размещения нового элемента с помощью вспомогательной ссылочной переменной Tmp и стандартного оператора new Stack. Item *Tmp = new Stack. Item; 2. заполнить информационную часть нового элемента cin >> Tmp->Info 3. установить адресную часть нового элемента таким образом, чтобы она определяла адрес бывшего вершинного элемента: 4. Tmp->Next = Sp; изменить адрес вершины стека так, чтобы он определял в качестве вершины новый элемент: Sp = Tmp;
Добавление нового элемента в вершину стека • Необходимые шаги: 1. выделить память для размещения нового элемента с помощью вспомогательной ссылочной переменной Tmp и стандартного оператора new Stack. Item *Tmp = new Stack. Item; 2. заполнить информационную часть нового элемента cin >> Tmp->Info 3. установить адресную часть нового элемента таким образом, чтобы она определяла адрес бывшего вершинного элемента: 4. Tmp->Next = Sp; изменить адрес вершины стека так, чтобы он определял в качестве вершины новый элемент: Sp = Tmp;
 Удаление элемента с вершины стека • Необходимые шаги: 1. с помощью вспомогательной переменной Tmp адресуем удаляемый элемент: Tmp = Sp; 2. изменяем значение переменной Sp на адрес новой вершины стека: Sp = Tmp->Next; 3. каким-то образом обрабатываем удаленный с вершины элемент, например – просто освобождаем занимаемую им память вызовом delete Tmp;
Удаление элемента с вершины стека • Необходимые шаги: 1. с помощью вспомогательной переменной Tmp адресуем удаляемый элемент: Tmp = Sp; 2. изменяем значение переменной Sp на адрес новой вершины стека: Sp = Tmp->Next; 3. каким-то образом обрабатываем удаленный с вершины элемент, например – просто освобождаем занимаемую им память вызовом delete Tmp;
 Реализация стека с помощью двусвязного списка struct Node { char data; Node *next, *prev; }; typedef Node *PNode; Чтобы не работать с отдельными указателями на хвост и голову списка, объявим структуру, в которой будет храниться вся информация о стеке: struct Stack { PNode Head, Tail; };
Реализация стека с помощью двусвязного списка struct Node { char data; Node *next, *prev; }; typedef Node *PNode; Чтобы не работать с отдельными указателями на хвост и голову списка, объявим структуру, в которой будет храниться вся информация о стеке: struct Stack { PNode Head, Tail; };
 {") Добавление элемента на вершину стека void Push ( Stack &S, char x ) { PNode New. Node; New. Node = new Node; // создать новый узел. . . New. Node->data = x; // и заполнить его данными New. Node->next = S. Head; // S. Head – указатель на вершину стека New. Node->prev = NULL; //он последн. и поэтому ссылка NULL if ( S. Head ) // добавить в начало списка S. Head->prev = New. Node; // теперь указатель на вершину стека – адрес нового элемента S. Head = New. Node; if ( ! S. Tail ) S. Tail = S. Head; // если конец списка пуст, то стек пуст и конец совпадает с началом }
Добавление элемента на вершину стека void Push ( Stack &S, char x ) { PNode New. Node; New. Node = new Node; // создать новый узел. . . New. Node->data = x; // и заполнить его данными New. Node->next = S. Head; // S. Head – указатель на вершину стека New. Node->prev = NULL; //он последн. и поэтому ссылка NULL if ( S. Head ) // добавить в начало списка S. Head->prev = New. Node; // теперь указатель на вершину стека – адрес нового элемента S. Head = New. Node; if ( ! S. Tail ) S. Tail = S. Head; // если конец списка пуст, то стек пуст и конец совпадает с началом }
 Очередь • Очередь – это упорядоченный набор элементов, в котором добавление новых элементов допустимо с одного конца (он называется начало очереди), а удаление существующих элементов – только с другого конца, который называется концом очереди. • Хорошо знакомой моделью является очередь в магазине. Очередь называют структурой типа • FIFO (First In – First Out) – первым пришел, первым ушел.
Очередь • Очередь – это упорядоченный набор элементов, в котором добавление новых элементов допустимо с одного конца (он называется начало очереди), а удаление существующих элементов – только с другого конца, который называется концом очереди. • Хорошо знакомой моделью является очередь в магазине. Очередь называют структурой типа • FIFO (First In – First Out) – первым пришел, первым ушел.
 Операции с очередью – создание/удаление – добавление элемента в очередь – извлечение элемента из очереди – очистка очереди – проверка на заполненность • очередь пустая? • очередь полностью заполнена?
Операции с очередью – создание/удаление – добавление элемента в очередь – извлечение элемента из очереди – очистка очереди – проверка на заполненность • очередь пустая? • очередь полностью заполнена?
 Простая очередь front – указатель головы rear – указатель хвоста front = rear – очередь пуста front < rear – очередь не пуста Простая очередь быстро заполняется. Способы улучшения: • передвижка элементов к голове очереди (значение front не изменяется); • создание кольцевой очереди (последний слот "приклеивается" к первому). Структуры и алгоритмы 57
Простая очередь front – указатель головы rear – указатель хвоста front = rear – очередь пуста front < rear – очередь не пуста Простая очередь быстро заполняется. Способы улучшения: • передвижка элементов к голове очереди (значение front не изменяется); • создание кольцевой очереди (последний слот "приклеивается" к первому). Структуры и алгоритмы 57
 . . Кольцевая очередь Структуры и алгоритмы 58
. . Кольцевая очередь Структуры и алгоритмы 58
![Очередь const int MAXSIZE = 100; struct Queue { int data[MAXSIZE]; int size, head,](https://present5.com/presentation/96158231_143546884/image-59.jpg "Очередь const int MAXSIZE = 100; struct Queue { int data[MAXSIZE]; int size, head,") Очередь const int MAXSIZE = 100; struct Queue { int data[MAXSIZE]; int size, head, tail; };
Очередь const int MAXSIZE = 100; struct Queue { int data[MAXSIZE]; int size, head, tail; };
,") Реализация очереди с помощью массива • Если у стека один конец «закреплен» (не двигается), то у очереди «подвижны» оба конца. Чтобы не сдвигать все элементы в массиве при удалении или добавлении элемента, обычно используют две переменные head и tail – первая из них обозначает номер первого элемента в очереди, а вторая – номер последнего. Если они равны, то в очереди всего один элемент. • Массив как бы замыкается в кольцо – если массив закончился, но в начале массива есть свободные места, то новый элемент добавляется в начало массива, как показано на рисунках.
Реализация очереди с помощью массива • Если у стека один конец «закреплен» (не двигается), то у очереди «подвижны» оба конца. Чтобы не сдвигать все элементы в массиве при удалении или добавлении элемента, обычно используют две переменные head и tail – первая из них обозначает номер первого элемента в очереди, а вторая – номер последнего. Если они равны, то в очереди всего один элемент. • Массив как бы замыкается в кольцо – если массив закончился, но в начале массива есть свободные места, то новый элемент добавляется в начало массива, как показано на рисунках.
 и") Две основные операции с очередью 1. добавление элемента в конец очереди (Push. Tail) и 2. удаление элемента с начала очереди (Pop).
Две основные операции с очередью 1. добавление элемента в конец очереди (Push. Tail) и 2. удаление элемента с начала очереди (Pop).
") Добавление элемента в конец очереди void Push. Tail ( Queue &Q, int x ) { if ( Q. size == MAXSIZE ) { printf ("Очередь переполненаn"); return; } Q. tail++; if ( Q. tail >= MAXSIZE ) // замыкание в кольцо Q. tail = 0; Q. data[Q. tail] = x; Q. size ++; }
Добавление элемента в конец очереди void Push. Tail ( Queue &Q, int x ) { if ( Q. size == MAXSIZE ) { printf ("Очередь переполненаn"); return; } Q. tail++; if ( Q. tail >= MAXSIZE ) // замыкание в кольцо Q. tail = 0; Q. data[Q. tail] = x; Q. size ++; }
 Добавление элемента в конец очереди Поскольку очередь может начинаться не с начала массива (за счет того, что некоторые элементы уже «выбраны» ), после увеличения Q. tail надо проверить, не вышли ли мы за границу массива. Если это случилось, новый элемент записывается в начало массива (хотя является хвостом очереди). В процедуре предусмотрена обработка ошибки «переполнение очереди» . В этом случае на экран будет выдано сообщение «Очередь переполнена» . Можно также сделать функцию Push. Tail, которая будет возвращать 1 в случае удачного добавления элемента и 0 в случае ошибки.
Добавление элемента в конец очереди Поскольку очередь может начинаться не с начала массива (за счет того, что некоторые элементы уже «выбраны» ), после увеличения Q. tail надо проверить, не вышли ли мы за границу массива. Если это случилось, новый элемент записывается в начало массива (хотя является хвостом очереди). В процедуре предусмотрена обработка ошибки «переполнение очереди» . В этом случае на экран будет выдано сообщение «Очередь переполнена» . Можно также сделать функцию Push. Tail, которая будет возвращать 1 в случае удачного добавления элемента и 0 в случае ошибки.
 { int temp;") Удаление элемента с начала очереди int Pop ( Queue &Q ) { int temp; if ( Q. size == 0 ) { printf ("Очередь пустаn"); return 32767; // сигнал об ошибке } temp = Q. data[Q. head]; Q. head ++; if ( Q. head >= MAXSIZE ) Q. head = 0; Q. size --; return temp; }
Удаление элемента с начала очереди int Pop ( Queue &Q ) { int temp; if ( Q. size == 0 ) { printf ("Очередь пустаn"); return 32767; // сигнал об ошибке } temp = Q. data[Q. head]; Q. head ++; if ( Q. head >= MAXSIZE ) Q. head = 0; Q. size --; return temp; }
 Удаление элемента с начала очереди • Функция Pop возвращает число, полученное с начала очереди, при этом размер очереди уменьшается на единицу. Если стек пуст, функция возвращает число 32767 (предполагается, что оно не может находиться в очереди по условию задачи и сигнализирует об ошибке).
Удаление элемента с начала очереди • Функция Pop возвращает число, полученное с начала очереди, при этом размер очереди уменьшается на единицу. Если стек пуст, функция возвращает число 32767 (предполагается, что оно не может находиться в очереди по условию задачи и сигнализирует об ошибке).
 Очередь на базе односвязной структуры
Очередь на базе односвязной структуры
 Реализация очереди с помощью двусвязного списка struct Node { int data; Node *next, *prev; }; typedef Node *PNode; struct Queue { PNode head, tail; // В самом начале надо //записать в обе ссылки NULL. };
Реализация очереди с помощью двусвязного списка struct Node { int data; Node *next, *prev; }; typedef Node *PNode; struct Queue { PNode head, tail; // В самом начале надо //записать в обе ссылки NULL. };
 { PNode Top.") Функция для получения первого элемента очереди int Pop (Queue &Q, ) { PNode Top. Node = Q. Head; int x; if ( ! Top. Node ) // если очередь пуста, то return 32767; x = Top. Node->data; Q. Head = Top. Node->next; if ( Q. Head ) Q. Head->prev = NULL; // переставить ссылки else Q. Tail = NULL; delete Top. Node; // освободить память return x; }
Функция для получения первого элемента очереди int Pop (Queue &Q, ) { PNode Top. Node = Q. Head; int x; if ( ! Top. Node ) // если очередь пуста, то return 32767; x = Top. Node->data; Q. Head = Top. Node->next; if ( Q. Head ) Q. Head->prev = NULL; // переставить ссылки else Q. Tail = NULL; delete Top. Node; // освободить память return x; }
") Добавление элемента в конец очереди void Push. Tail ( Queue &Q, int x ) { PNode New. Node; New. Node = new Node; // создать новый узел New. Node->data = x; // заполнить узел данными New. Node->prev = Q. Tail; New. Node->next = NULL; if ( Q. tail ) // добавить узел в конец списка Q. tail->next = New. Node; Q. tail = New. Node; if ( ! Q. head ) Q. head = Q. tail; }
Добавление элемента в конец очереди void Push. Tail ( Queue &Q, int x ) { PNode New. Node; New. Node = new Node; // создать новый узел New. Node->data = x; // заполнить узел данными New. Node->prev = Q. Tail; New. Node->next = NULL; if ( Q. tail ) // добавить узел в конец списка Q. tail->next = New. Node; Q. tail = New. Node; if ( ! Q. head ) Q. head = Q. tail; }
 Дек Deque – double ended queue Дек – очередь с двумя концами – последовательный список, в котором включение и исключение элементов возможны с обоих концов списка. Атрибуты дека: – массив слотов для размещения элементов дека; – указатель левой вершины; – указатель правой вершины; – указатель направления планируемой операции. Структуры и алгоритмы 70
Дек Deque – double ended queue Дек – очередь с двумя концами – последовательный список, в котором включение и исключение элементов возможны с обоих концов списка. Атрибуты дека: – массив слотов для размещения элементов дека; – указатель левой вершины; – указатель правой вершины; – указатель направления планируемой операции. Структуры и алгоритмы 70
 Очередь с приоритетом • добавить в очередь элемент с назначенным приоритетом; • извлечь из очереди и вернуть элемент с минимальным приоритетом (другие названия «Pop. Element(Off)» или «Get. Minimum» ) • просмотреть элемент с наивысшим приоритетом без извлечения (необязательная операция)
Очередь с приоритетом • добавить в очередь элемент с назначенным приоритетом; • извлечь из очереди и вернуть элемент с минимальным приоритетом (другие названия «Pop. Element(Off)» или «Get. Minimum» ) • просмотреть элемент с наивысшим приоритетом без извлечения (необязательная операция)
 и поддерживает операции добавления пары, поиска") Очередь с приоритетом позволяет хранить пары (ключ, значение) и поддерживает операции добавления пары, поиска пары с минимальным ключом и извлечения пары с минимальным ключом: • INSERT(ключ, значение) — добавляет пару в хранилище; • MIN — возвращает пару с минимальным значением ключа. • EXTRACT_MIN — возвращает пару с минимальным значением ключа, удаляя её из хранилища.
Очередь с приоритетом позволяет хранить пары (ключ, значение) и поддерживает операции добавления пары, поиска пары с минимальным ключом и извлечения пары с минимальным ключом: • INSERT(ключ, значение) — добавляет пару в хранилище; • MIN — возвращает пару с минимальным значением ключа. • EXTRACT_MIN — возвращает пару с минимальным значением ключа, удаляя её из хранилища.
 Очередь с приоритетом
Очередь с приоритетом