b63fea00d14d03ed6032a0c3fec8ceec.ppt
- Количество слайдов: 81



Developing a Bioinformatics Program Meiliu Lu and Nick Ewing For the Summer Institute in Bioinformatics 2001, UC Davis

Outline • Getting Started • Setting up Workstations / Unix • When are Java, C++, Perl used? • AI applications in Bioinformatics • Database Architecture • Introduction to Biological Databases
 1999 • Meetings to draft course")
Getting Started • Attending workshops (BU and CSU) 1999 • Meetings to draft course proposal • Experimental offering 2000 Fall • Experimental offering 2001 Fall • New course web site (show and tell): http: //gaia. ecs. csus. edu/~mei/biox 01/syllabus/bio 296 c. html

Program Designs • Sample Bioinformatics programs in US: • Ph. D. program, example: Boston University • BS, MS program, example: UC Santa Crutz • Courses that supporting existing Bio Science program, example: CSU Sacramento • Certificate program, example: Stanford University • Workshops/summer institutes like this

Bioinformatics and Bioinformaticians • The goal is finding out how living things work • Like molecular biology methods expanded what biologists were capable of studying • Bioinformatics is a tool and Bioinformaticians are the tool-builders • It is critical that they understand biological problems and computation solutions in order to produce useful tools

Essential Skills for Bioinformaticians • Fairly deep background in some aspect of molecular biology (MB) • Understand the central dogma of MB • Substantial experience with at least one of two major MB software packages • Comfortable working with Unix • Experience with programming in a language such as C/C++/Java, a scripting language such as Perl, and spreadsheet tools such as Excel

CSU Bioinformatics Modules for Undergrads 1. 2. 3. 4. 5. 6. 7. 8. 9. Overview of bioinformatics Databases Bioinformatics Computing Fundamentals Genomics Phylogenetic reconstruction Protein and RNA structure prediction Computational cell biology and proteomics Gene expression analysis Disease genetics

Additional CS Courses for Bioinformaticians • System Programming • Databases • Data Structures and Algorithms • Computer Network and Internet • Artificial Intelligence • Machine Learning

Additional BIO Courses for Bioinformaticians • Any more advanced courses in the following areas: – Molecular biology – Genetics, genomics – Biochemistry – More specialized coursework: e. g. virology, immunology, microbiology, etc.

Setting up Workstations • In order to make the most of bioinformatics, you need to have access to the internet and learn Unix • Why use Unix or Linux (Unix for PC)? • Most scientific software is developed on Unix machines, and serious researchers will want access to programs that can be run only under Unix

Support for Bioinformatics Class • A computer lab with 20+ workstations • Each workstation has internet access • PC/Unix workstation with access to a Unix server through telnet • Internet access for instructor’s laptop and multimedia projector • White board

Our Lab
, sequoia(web & CGI) both are")
Unix Servers at ECS CSUS • Specification: gaia (web), sequoia(web & CGI) both are HP model 9000/800, 240 MHz RISC CPU running Apache Web Server • Price range for a Unix server: from $1, 200 Linux PC up to $10 K for Sun or HP • System configuration: 4 to 8 GB disk, 512 to 1024 MB memory • 100 Mbps Ethernet ($50) connection and tape backup system ($800) at least twice a week

Our Servers
")
A Very Brief Introduction to Unix • Computer hardware without an operating system (OS) is like a dead animal • OS handles the low level processes that make hardware work together • OS provides an environment for you to run and develop programs • OS allows you convenient access to your files and programs

Why Use Unix? • Unix is a powerful OS for multiuser computer systems developed at AT&T Bell Lab in 1969 • Unix is the OS of the World Wide Web • Bioinformatics researchers have developed software for Unix • Until the mid-1990 s, the only workstations able to visualize protein structure data in real time were Silicon Graphics and Sun Unix workstations

Linux • An open source version of Unix, named after its original developer, Linus Torvalds of the Univ. of Helsiki in Finland • One man project to create a free Unix for PC ran on 27% of servers shipped last year • Best known distribution: Red Hat http: //www. redhat. com/support/hardwar e/

Sharing Software • Install local applications in /usr/local, with executable files in /usr/local/bin • Commercial packages: Sequence analysis – GCG Protein structure analysis – Quanta or Insight • Free software/academic software over internet

Unix File System • Like the taxonomy of species developed by the early biologists: from general to specific • Hierarchy file organization: directories, subdirectories, …, files (see a tree diagram) • Common problem: failure to share information effectively due to poor file organization

Tree Diagram of Hierarchy biox syllabus. htm Graphics grading. htm schedule. htm notes week 1 Lec. htm assignment Lab 1. htm

Basic Unix Skills • Get a Unix account • Commends for working with dir and file: cd, ls, cat, rm, mkdir, rmdir, pwd, mv • Change file ownership and permission with chmod • How to use pipes, redirect file input and output • Edit files with pico or vi

Useful Unix Features • Communicating with the web • telnet, opens a session on a remote Unix machine • ftp, the File Transfer Protocol is a method for transferring file from one computer to another • Creating archives of your data after your project is complete

The C Language • C evolved from B by Dennis Richie at Bell Lab in 1972, and B was used to create early versions of Unix • C became the development language of Unix and virtually all new major OS are written in C and/or C++, say, MS Windows • Blast and other legendary Bioinformatics tools were implemented in C

The C++ Language • C++ is a superset of C developed by Bjarne Stroustup at Bell Lab in 1979 • C++ is a better C, in other words, C with classes (object oriented technology, reusebility) • C++ was designed to provide better program organization together with C’s efficiency and flexibility for systems programming • Choice for more recent Bioinformatics software implementation

The Java Language • Java was developed by James Gosling at Sun Microsystems in 1991 • A simple, object-oriented, distributed, interpreted, robust, secure, architecture neutral, portable, high-performance, multithreaded, and dynamic language • Choice among network programmers and for Infor. Max, a leading global developer of bioinformatics software

Infor. Max • Founded in 1990, today Infor. Max products are used by 1, 870 research organizations and more than 25, 000 individual scientists worldwide • to understand extract value from the massive amounts of data being generated by the Genomic Revolution • Among the Company's customers are 23 of the top 25 pharmaceutical companies

Java Makes the Difference • Infor. Max’s market-leading products include Vector NTI® Suite, the most widely used software suite for enhancing laboratory productivity, and Geno. Max ™ for integrated analysis of genomic and proteomic data. • Technology highlights: knowledge based software engineering, strong in data integration, and Java as implementation language

Vector NTI® Suite • For both PC and Mac platforms with 4 major application programs • Vector NTI for mapping and illustration, primer design and analysis, and strategic recombinant design • Bio. Plot for protein and nucleic acid sequence analysis; • Align. X for multiplesequence alignment; • Contig. Express for sequencing project management and fragment assembly.

Geno. Max. TM • Facilitates management, analysis, and mining of sequence, expression, and gene function data • Speed and security are ensured through the employment of client-server architecture, Oracle® relational databases, Java-based graphical user interface • Modules include Sequence Analysis, Gene Expression Analysis, and Protein 3 -D Structure

Workers at Infor. Max • To get a job at Infor. Max, people have to pass many tests and procedures • People who are very good mathematicians or programmers with good knowledge of biology (Russian roots) • Mathematicians and programmers built professional code with advice from medical biologists

From Infor. Max CEO Alex Titomirov The sequencing of both the human genome and other genomes has presented us with an order-ofmagnitude increase in the opportunities to diagnose and treat human, plant and animal diseases, but this also created an enormous and complex store of scientific information that can only be mined with computers.

The Perl Language • Perl was designed and implemented by Larry Wall, version 1. 0 in 1987 • Perl – Practical Extraction and Report Language (easy to use, efficient, complete) • It has support of modules and object oriented programming, and is still evolving and growing

Automating Data Analysis with Perl • Although a lot of software tools exists for bioinformatics, but sometimes the best solution is to do it yourself • Perl is ideally suited to this task • Wealth of exiting Perl code for bioinformatics, smooth data integration, cross-platform portability, and enthusiastic user community (www. bioperl. org)

How Perl Saved the Human Genome Project • Without interchangeability, an informatics group is locked into using the in-house software. • If another center develops a better software tool to attack the same problem, a tremendous effort is required by the first center to retool their system in order to use that tool • This is where Perl came to the rescue – a glue language

Components of DNAsequencing project • A trace editor to analyze, display, and allow biologists to edit the short DNA read chromatograms from DNA-sequencing machines. • A read assembler to find overlaps between the reads and assemble them in long contiguous sections. • An assembly editor to view the assemblies and make changes in places where the assembler went wrong. • A database to keep track of everything.

Perl aid communication between components developed separately

When the time came to interchange data • Between two groups, two trace editors, three assemblers, two assembly editors, and (thankfully) one database. • If two Perl scripts were required for each pair of components (one for each direction), 62 different scripts would be needed • Each time format of one of these modules changed, 14 scripts might need to be examined and fixed.
 solution")
A common data-exchange format (CAF) solution

Perl as Solution to Data Integration • Perl has been the solution of choice for genome centers whenever they need to exchange data or to retrofit one center's software module to work with another center's system • Although genome informatics groups are constantly tinkering with other languages such as Python, Tcl, and recently Java, nothing comes close to Perl's popularity

How has Perl achieved this position? • Remarkably good for slicing, dicing, twisting, wringing, smoothing, summarizing data files • Forgiving • Component-oriented • Perl programs are easy to write and fast to develop • Good language for web CGI scripting since more labs turn to the Web for publishing their data and providing service

CGI Programming in Perl • The interface between the HTML on the client and the software on the server is called Common Gateway Interface (CGI) • Development of such software is called CGI programming • CGI is used in all major Bioinformatics database servers

Advantages using Perl for CGI Programming • Easy to learn enough to write CGI applications • Direct access to system evironmental variables • Simple interfacing to non-Perl systems, such as the Oracle database system • Easy to port among all web server platforms
, 1996 by W 3 C’s, permits authors to")
XML • XML (Extensible Markup Languages), 1996 by W 3 C’s, permits authors to create their own markup • Particularly useful in genome annotation • Example: GAME-XML at Berkeley Drosophila Genome Project to represent sequence features

Programming Languages Used in Bioinformatics • C, C++, Java, Perl are major players • XML, increasingly important • Python, cross-platform, object-oriented, can be used to write large-scale Internet applications • Java. Script, an easy-to-use programming language that can be embedded in the header of your web pages, ideal for building dynamic and interactive web pages

What Does Informatics Mean to Biologists? • Functional aspect: representation, storage, distribution of data, and to allow the user to ask complex questions about the data bioinformatics infrastructure • Scientific aspect: analytical tools to discover knowledge in data to develop predictive methods that allow scientists to model the function and phenotype of an organism based only on its genome sequence

What Challenges Does Biology Offer CS? • Cracking the genome code is complex: prediction methods and models • Amount of data is growing at an exponential rate: data management • Biological data is very complex and interlinked: information systems that allow biologist to seamlessly follow these links without getting lost • Each gene isn’t an independent entity: putting genomic and biochemical data together into models of biochemistry and physiology

Artificial Intelligence • A sub-field of Computer Science that is now also called intelligent systems • Two of many definitions of AI : 1. complex information processing 2. creating machines that can engage on behaviors that humans consider intelligent

Story of Deep Blue Historical Notes of Computer Game Playing • 1846 Charles Babbage --the first discussion of feasibility of computer game playing (design but not build Tic. Tac-Toe) • 1945 Konrad Zuse, the first person to design a programmable computer, developed ideas as to how mechanical chess play might be accomplished
 • 1950 Claude Shannon described minixaxing with a depth")
Story of Deep Blue (continued) • 1950 Claude Shannon described minixaxing with a depth cutoff and evaluation function clearly in detail • 1951 Alan Turing wrote the first actual computer program capable of playing a full game of chess but not actually ran on computer.
 • 1957, 6 x 6, 1958 full game of")
Story of Deep Blue (continued) • 1957, 6 x 6, 1958 full game of standard chess by Alex Bernstein • 1958, John Mc. Carthy conceived the idea of alpha-beta search. 1958, 1959, Newell and Samuel used the method in chess programs • 1967, the first two computer chess programs to play a match against each other. Kotok. Mc. Carthy program and the "ITEP“- Moscow Institute of Theoretical and Experimental Physics (3 -1 victory for the ITEP)
 • 1975 Knuth and Moore gave correctness proof and")
Story of Deep Blue (continued) • 1975 Knuth and Moore gave correctness proof and complexity analysis of alpha-beta game-searching algorithm • 1982 Pearl shows alpha-beta to be asymptotically optimal among all gamesearching algorithms
 • The Fredkin Prize, established in 1980, offered: •")
Story of Deep Blue (continued) • The Fredkin Prize, established in 1980, offered: • $5000 -- 1 st program to achieve Master rating (Belle 1983) • $10, 000 -- 1 st program to achieve USCF, near grandmaster level (Deep Thought 1989) • $100, 000 -- 1 st program to defeat the human world champion (Deep Blue 1997)

1997 Rematch Garry Kasparov vs Deep Blue

• 1999, IBM announced a $100 million research initiative to build the world's fastest supercomputer, "Blue Gene", to tackle fundamental problems in computational biology. • The Blue Gene system will be capable of performing 1, 000, 000 operations per second • To do simulation to advance our understanding of biologically important processes, in particular the mechanisms behind protein folding.

Opportunity and Motivation • Explore novel research into areas: machine architecture, programming models, algorithmic techniques, and biomolecular simulation science • Life sciences have benefited from computational capabilities and will be driving the requirements for data, network, and computational capabilities in the future

Protein Folding Knowledge • The knowledge derived from research on protein folding can be applied to related life sciences problems of great scientific and commercial interest: – Protein-drug interactions (docking) – Enzyme catalysis (through use of hybrid quantum and classical methods) – Refinement of protein structures created through other methods

AI Applications in Bioinformatics • AI (in particular, machine learning, data mining, cluster analysis, pattern recognition, and knowledge representation) can provide key solutions for the new challenges posed by Biology • Computer scientists accustomed to dealing with a binary alphabet {0, 1} • The four letter alphabet of DNA {A, T, C, G} is sufficient for encoding messages of arbitrary complexity

The Architecture of Complexity

Promising Areas for AI • Prediction of protein’s structure and function • Semiautomatic drug design • Interpretation of nucleotide sequences • Knowledge acquisition from genetic data

Data Mining • Machine learning based data-mining tools will let us transform biological sequences, observations, and knowledge into structured and meaningful information that scientists can query, visualize and understand • Help discover the fundamental connection between genetic sequences and functions of living organisms
")
Gene Discovery in DNA Sequences Steven L. Salzberg, The Institute for Genomic Research (TIGR) • Genomics is the science of studying the complete genetic content of living organisms • A genome is the complete DNA complement of an organism • One of the central discovery challenges for newly sequenced DNA is that of identifying genes (the portions of the DNA that get transcribed to RNA), their protein products, and functions of them

Computational Techniques • Genome projects today use computational techniques almost exclusively to identify genes, because traditional lab techniques are very slow and expensive • Two main techniques: 1. Sequence alignment 2. Computational gene finding

Sequence Alignment • Compare each new DNA sequence with all known sequences to find other similar sequences • When scientists find a sequence with good similarity, they can infer that the new sequence has a similar function to the previously known gene • Dynamic programming is the key technique which lets biologist align sequences of length M and N in time O(NM) • Fasta and Blast are extensions of this approach

Pros and Cons of Sequence Homology Search • Advantage: scientists can very quickly identify the likely function of previously uncharacterized genes • Disadvantage: many newly sequenced genes have no homologs; that is no similar gene has ever before been sequenced • The number of unknown genes reported has ranged from 30% to 50%

Computational Gene Finding • Researchers must instead rely on genefinding programs to identify the genes initially, and then wait for follow-up research to characterize their functions • Gene-finding programs are essentially machine learning programs that must be trained from existing gene databases

Machine Learning Approaches • Machine Learning methods are well suited to sequence analysis • They can learn useful descriptions of genetic concepts when given only instances, rather than explicit definitions, of those concepts • Understanding the natural and the artificial worlds conceptual models

How does it work in nature: • Prokaryotes do not have introns • Single cell eukaryotes have less introns • Other eukaryotes may have up to 90% introns.
 • Eukaryotic gene")
Gene-finding programs • Prokaryotic gene finding use interpolated Markov models (IMMs) • Eukaryotic gene finding is more difficult due to low coding density and presence of introns, and use Hidden Markov models (HMMs) • Many other AI approaches are used to meet this challenge including decision trees, neural networks and rule-based systems

Challenges and Discoveries Ahead • Eukaryotic gene finding continues to be an active and important area – more research into algorithms with greater accuracy • Much of annotation will likely be either inaccurate or incomplete when the human genome is first decoded • Expertise in the computational biology requires training in two traditional distinct fields: computer science and molecular biology

Facts about Databases • A lot of biologists and scientists don’t realize that if you build a database and you tolerate five percent sloppiness in the definition of individual concepts, when you execute a query that joins across 15 concepts, you’ve got less than a 50: 50 chance of getting the answer you want. – Robert Ronnins, NSF
 is the software system")
An Overview of DBMS • A Database Management System (DBMS) is the software system that allows users to define, create and maintain a database and provides controlled access to the data (examples: Oracle, My. SQL, Access) • The database administrator (DBA) • The end users • The application programmers
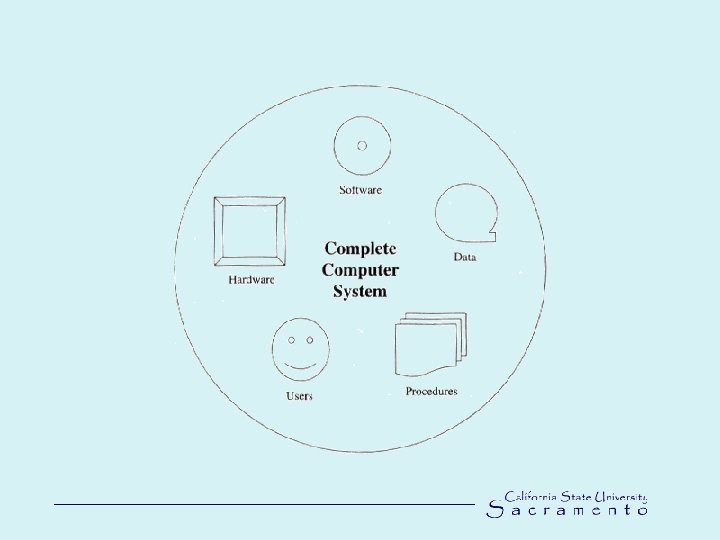

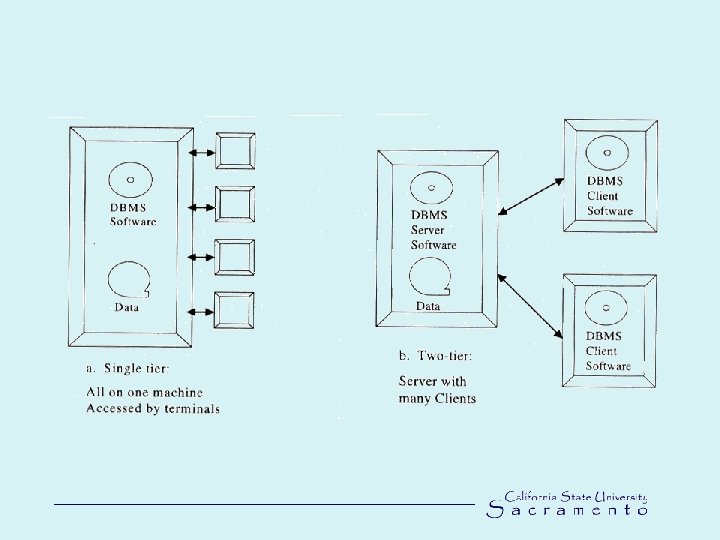
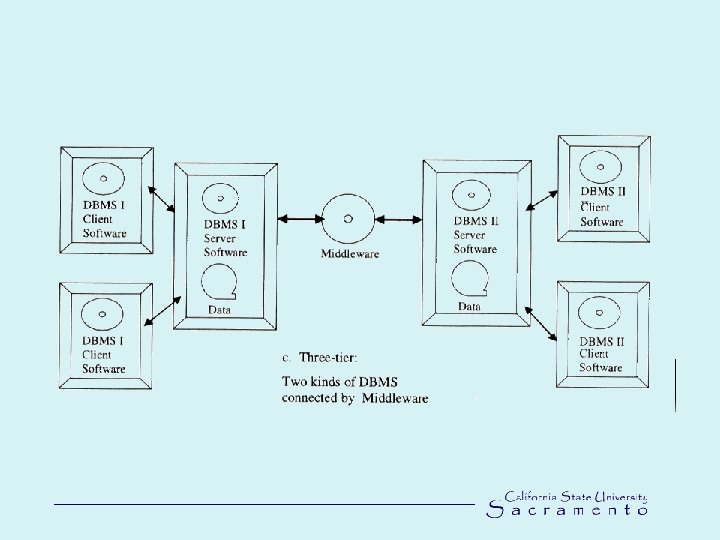
Databases Configurations • Multi-users or single user • Centralized or distributed • Single-, two- and three tier configuration (see following figures) • Actual data are separated from the programs that use the data

Data Models • Flat file indexing, index is one dimensional and difficult to make connection with attributes (PDB began as flat files) • Relational DBMS, a collection of tables, RDBMS can assemble any kind of book about proteins you want in a fly • Object-Oriented DBMS, can handle concurrent interaction by multiple clients and complex objects (PDB backend now)
")
Object-Oriented Technology • Fundamental idea: raise the level of abstraction (worry less about details) Key features: 1. Abstract data type (encapsulation, operations + data representation), an instance of an ADT is called Object 2. Inheritance (class) 3. Polymorphism and dynamic binding

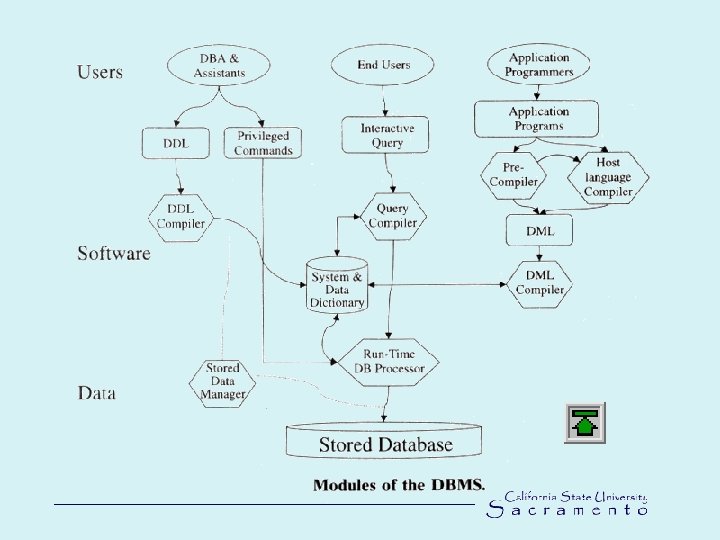
Database System Architecture • Data model describes the data and the relationships at the abstract level • Database schema describes the conceptual organization of the database system • Data definition language (DDL), provided by a software vendor, defines the organization at logical level create tables • Data dictionary contains the table names, column names and data type for each table
 • Data manipulation language (DML) allows the user to")
Database System Architecture (cont. ) • Data manipulation language (DML) allows the user to enter, to retrieve, and to update the data • The most common DML used by many DBMS is SQL • DBMS three-level architecture was formalized in 1975

DBMS Three-level Architecture • Internal level concerns the way data are physically stored on the hardware • Conceptual level: displaying views to external level and mapping definition to internal level • External level is the one concerned with the users
b63fea00d14d03ed6032a0c3fec8ceec.ppt