9f177a584fdc37e3e88a7f105a346a3b.ppt
- Количество слайдов: 62



• Date: Fri, 15 Feb 2002 12: 53: 45 -0700 Subject: IOC awards presidency also to Gore 2/18 (RNN)-- In a surprising, but widely anticipated move, the International Olympic Committee president just came on TV and announced that IOC decided to award a presidency to Albert Gore Jr. too. Gore Jr. won the popular vote initially, but to the surprise of TV viewers world wide, Bush was awarded the presidency by the electoral college judges. Mr. Bush, who "beat" gore, still gets to keep his presidency. "We decided to put the two men on an equal footing and we are not going to start doing the calculations of all the different votes that (were) given. Besides, who knows what those seniors in Palm Beach were thinking? " said the IOC president. The specific details of shared presidency are still being worked out--but it is expected that Gore will be the president during the day, when Mr. Bush typically is busy in the Gym working out. In a separate communique the IOC suspended Florida for an indefinite period from the union. Speaking from his home (far) outside Nashville, a visibly elated Gore profusely thanked Canadian people for starting this trend. He also remarked that this will be the first presidents' day when the sitting president can be on both coasts simultaneously. When last seen, he was busy using the "Gettysburg" template in the latest MS Powerpoint to prepare an eloquent speech for his inauguration-cum-first-state-of-the-union. --RNN Related Sites: Gettysburg Powerpoint template: http: //www. norvig. com/Gettysburg/
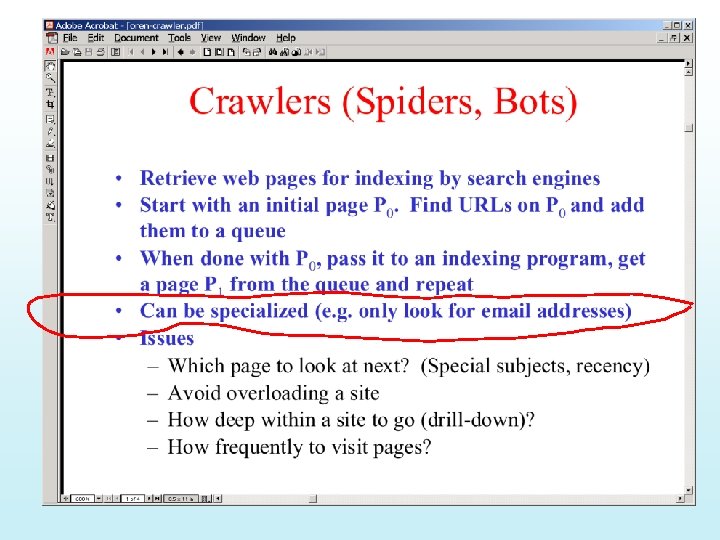
 Crawling Announcements: Next class: INTERACTIVE (read Google")
Agenda: Page Rank issues (computation; Collusion etc) Crawling Announcements: Next class: INTERACTIVE (read Google paper and come prepared with smart questions/comments/answers) Homework 2 socket closed. . Question: Are you reading the papers? ? ? ?

Adding Page. Rank to a Search. Engine • Weighted sum of importance+similarity with query • Score(q, d) = w sim(q, p) + (1 -w) R(p), = 0, otherwise if sim(q, p) > 0 • Where – 0<w<1 – sim(q, p), R(p) must be normalized to [0, 1].
 The left most column Shows")
Stability of Rank Calculations (From Ng et. al. ) The left most column Shows the original rank Calculation -the columns on the right are result of rank calculations when 30% of pages are randomly removed


Effect of collusion on Page. Rank C A B B Assuming a=0. 8 and K=[1/3] Rank(A)=Rank(B)=Rank(C)= 0. 5774 Rank(A)=0. 37 Rank(B)=0. 6672 Rank(C)=0. 6461 Moral: By referring to each other, a cluster of pages can artificially boost their rank (although the cluster has to be big enough to make an appreciable difference. Solution: Put a threshold on the number of intra-domain links that will count Counter: Buy two domains, and generate a cluster among those. .
")
What about non-principal eigen vectors? • Principal eigen vector gives the authorities (and hubs) • What do the other ones do? – They may be able to show the clustering in the documents (see page 23 in Kleinberg paper) • The clusters are found by looking at the positive and negative ends of the secondary eigen vectors (ppl vector has only +ve end…)
 – Data too")
Practicality • Challenges – M no longer sparse (don’t represent explicitly!) – Data too big for memory (be sneaky about disk usage) • Stanford version of Google : – – 24 million documents in crawl 147 GB documents 259 million links Computing pagerank “few hours” on single 1997 workstation • But How? – Next discussion from Haveliwala paper…

Efficient Computation: Preprocess • Remove ‘dangling’ nodes – Pages w/ no children • Then repeat process – Since now more danglers • Stanford Web. Base – 25 M pages – 81 M URLs in the link graph – After two prune iterations: 19 M nodes

Representing ‘Links’ Table • Stored on disk in binary format Source node (32 bit int) Outdegree (16 bit int) Destination nodes (32 bit int) 0 4 12, 26, 58, 94 1 3 5, 56, 69 2 5 1, 9, 10, 36, 78 • Size for Stanford Web. Base: 1. 01 GB – Assumed to exceed main memory
![Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] =](https://present5.com/presentation/9f177a584fdc37e3e88a7f105a346a3b/image-11.jpg "Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] =")
Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] = 1/N while residual > { d Dest[d] = 0 while not Links. eof() { Links. read(source, n, dest 1, … destn) for j = 1… n Dest[destj] = Dest[destj]+Source[source]/n } d Dest[d] = c * Dest[d] + (1 -c)/N /* dampening */ residual = Source – Dest /* recompute every few iterations */ Source = Dest }

Analysis of Algorithm 1 • If memory is big enough to hold Source & Dest – IO cost per iteration is | Links| – Fine for a crawl of 24 M pages – But web ~ 800 M pages in 2/99 [NEC study] – Increase from 320 M pages in 1997 [same authors] • If memory is big enough to hold just Dest – Sort Links on source field – Read Source sequentially during rank propagation step – Write Dest to disk to serve as Source for next iteration – IO cost per iteration is | Source| + | Dest| + | Links| • If memory can’t hold Dest – Random access pattern will make working set = | Dest| – Thrash!!!

Block-Based Algorithm • Partition Dest into B blocks of D pages each – If memory = P physical pages – D < P-2 since need input buffers for Source & Links • Partition Links into B files – Linksi only has some of the dest nodes for each source – Linksi only has dest nodes such that • DD*i <= dest < DD*(i+1) • Where DD = number of 32 bit integers that fit in D pages = Dest dest node source node Links (sparse) Source
 (16 bit) Destination")
Partitioned Link File Source node Outdegr Num out (32 bit int) (16 bit) Destination nodes (32 bit int) 0 1 2 4 3 5 2 1 3 12, 26 5 1, 9, 10 0 1 2 4 3 5 1 1 1 58 56 36 0 1 2 4 3 5 1 1 1 94 69 78 Buckets 0 -31 Buckets 32 -63 Buckets 64 -95

Block-based Page Rank algorithm

Analysis of Block Algorithm • IO Cost per iteration = – B*| Source| + | Dest| + | Links|*(1+e) – e is factor by which Links increased in size • Typically 0. 1 -0. 3 • Depends on number of blocks • Algorithm ~ nested-loops join

Comparing the Algorithms

Page. Rank Convergence…

Page. Rank Convergence…

Summary of Key Points • Page. Rank Iterative Algorithm • Rank Sinks • Efficiency of computation – Memory! – Single precision Numbers. – Don’t represent M* explicitly. – Break arrays into Blocks. – Minimize IO Cost. • Number of iterations of Page. Rank. • Weighting of Page. Rank vs. doc similarity.
![2/24 Shopping at job fairs Push my resume [But] jobs aren't what I seek](https://present5.com/presentation/9f177a584fdc37e3e88a7f105a346a3b/image-22.jpg "2/24 Shopping at job fairs Push my resume [But] jobs aren't what I seek")
2/24 Shopping at job fairs Push my resume [But] jobs aren't what I seek I will be your walking student advertisement Can't live on my research stipend Everybody wants a Google shirt HP, Amazon Pixar, Cray, and Ford I just can't decide Help me score the most free pens and free umbrellas or a coffee mug from Bell Labs Everybody wants a Google. . [Un]til I find a steady funder I'll make do with cheap-a## plunder Everybody wants a Google. . Wait! You will never need it It's free; I couldn't leave it Everybody wants a Google shirt Shameless corp'rate carrion crows Turn your backs and show your logos Everybody wants a Google shirt ("Everybody Wants a Google Shirt" is based on "Everybody Wants to Rule the World" by Tears for Fears. Alternate lyrics by Andy Collins, Kate Deibel, Neil Spring, Steve Wolfman, and Ken Yasuhara. )

Discussion • What parts of Google did you find to be in line with what you learned until now? • What parts of Google were different?

Some points… • Fancy hits? • Why two types of barrels? • How is indexing parallelized? • How does Google show that it doesn’t quite care about recall? • How does Google avoid crawling the same URL multiple times? • What are some of the memory saving things they do? • Do they use TF/IDF? • Do they normalize? (why not? ) • Can they support proximity queries? • How are “page synopses” made?
 • Are backlinks reliable metric of importance? – It is")
Beyond Google (and Pagerank) • Are backlinks reliable metric of importance? – It is a “one-size-fits-all” measure of importance… • Not user specific • Not topic specific – There may be discrepancy between back links and actual popularity (as measured in hits) » The “sense” of the link is ignored (this is okay if you think that all publicity is good publicity) • Mark Twain on Classics – “A classic is something everyone wishes they had already read and no one actually had. . ” (paraphrase) • Google may be its own undoing…(why would I need back links when I know I can get to it through Google? ) • Customization, customization… – Yahoo sez about their magic bullet. . (NYT 2/22/04) – "If you type in flowers, do you want to buy flowers, plant flowers or see pictures of flowers? "

The rest of the slides on Google as well as crawling were not specifically discussed one at a time, but have been discussed in essence (read “you are still responsible for them”)


P ER ID SE CA DY TU S

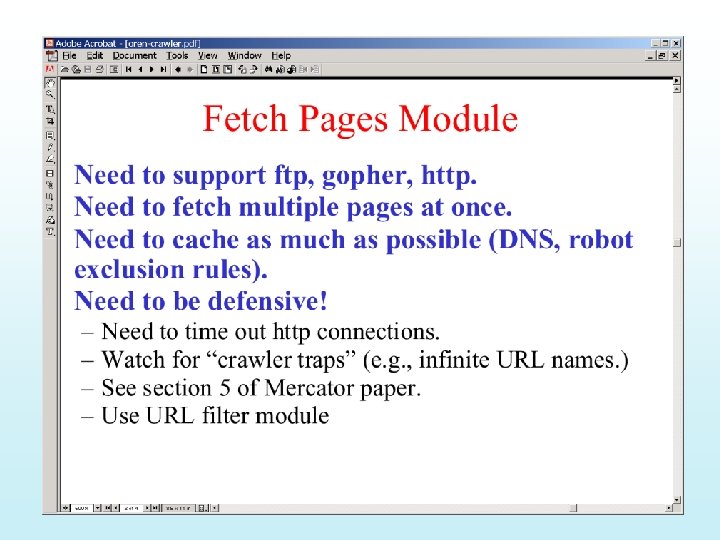
 2. How to extract URLs from a web page? Need to identify")
Robot (4) 2. How to extract URLs from a web page? Need to identify all possible tags and attributes that hold URLs. • Anchor tag: <a href=“URL” … > … </a> • Option tag: <option value=“URL”…> … </option> • Map: <area href=“URL” …> • Frame: <frame src=“URL” …> • Link to an image: <img src=“URL” …> • Relative path vs. absolute path: <base href= …>





Focused Crawling • • Classifier: Is crawled page P relevant to the topic? – Algorithm that maps page to relevant/irrelevant • Semi-automatic • Based on page vicinity. . Distiller: is crawled page P likely to lead to relevant pages? – Algorithm that maps page to likely/unlikely • Could be just A/H computation, and taking HUBS – Distiller determines the priority of following links off of P

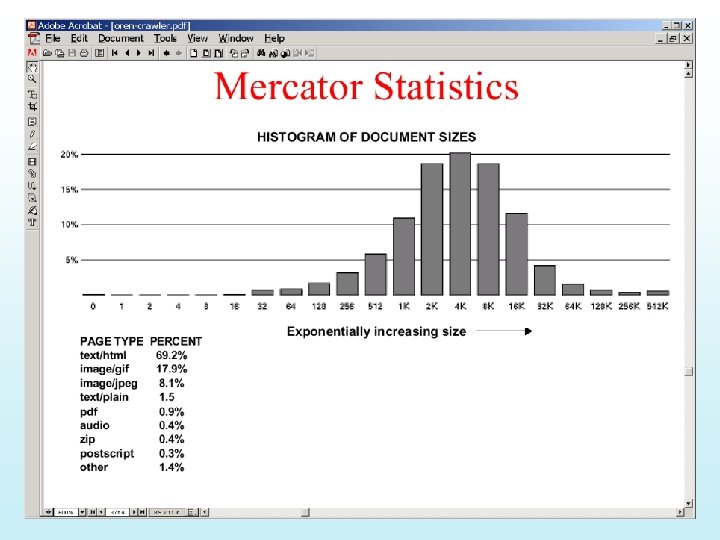
 Slides from http: //www. cs. huji. ac. il/~sdbi/2000/google/index. htm")
Anatomy of Google (circa 1999) Slides from http: //www. cs. huji. ac. il/~sdbi/2000/google/index. htm

Search Engine Size over Time per a ” p le’s 9 gle og oo go irca 9 g e “ sses re c Th cu ctu Dis chite Ar Number of indexed pages, self-reported Google: 50% of the web? Information from searchenginewatch. com

Google Search Engine Architecture SOURCE: BRIN & PAGE URL Server- Provides URLs to be fetched Crawler is distributed Store Server - compresses and stores pages for indexing Repository - holds pages for indexing (full HTML of every page) Indexer - parses documents, records words, positions, font size, and capitalization Lexicon - list of unique words found Hit. List – efficient record of word locs+attribs Barrels hold (doc. ID, (word. ID, hit. List*)*)* sorted: each barrel has range of words Anchors - keep information about links found in web pages URL Resolver - converts relative URLs to absolute Sorter - generates Doc Index - inverted index of all words in all documents (except stop words) Links - stores info about links to each page (used for Pagerank) Pagerank - computes a rank for each page retrieved Searcher - answers queries

Major Data Structures • Big Files – virtual files spanning multiple file systems – addressable by 64 bit integers – handles allocation & deallocation of File Descriptions since the OS’s is not enough – supports rudimentary compression
 • Repository – tradeoff between speed & compression ratio –")
Major Data Structures (2) • Repository – tradeoff between speed & compression ratio – choose zlib (3 to 1) over bzip (4 to 1) – requires no other data structure to access it
 • Document Index – keeps information about each document –")
Major Data Structures (3) • Document Index – keeps information about each document – fixed width ISAM (index sequential access mode) index – includes various statistics • pointer to repository, if crawled, pointer to info lists – compact data structure – we can fetch a record in 1 disk seek during search
 • Lexicon – can fit in memory for reasonable price")
Major Data Structures (4) • Lexicon – can fit in memory for reasonable price • currently 256 MB • contains 14 million words • 2 parts – a list of words – a hash table
 • Hit Lists – includes position font & capitalization –")
Major Data Structures (4) • Hit Lists – includes position font & capitalization – account for most of the space used in the indexes – 3 alternatives: simple, Huffman , handoptimized – hand encoding uses 2 bytes for every hit
 • Hit Lists (2)")
Major Data Structures (4) • Hit Lists (2)
 • Forward Index – – – partially ordered used 64")
Major Data Structures (5) • Forward Index – – – partially ordered used 64 Barrels each Barrel holds a range of word. IDs requires slightly more storage each word. ID is stored as a relative difference from the minimum word. ID of the Barrel – saves considerable time in the sorting
 • Inverted Index – 64 Barrels (same as the Forward")
Major Data Structures (6) • Inverted Index – 64 Barrels (same as the Forward Index) – for each word. ID the Lexicon contains a pointer to the Barrel that word. ID falls into – the pointer points to a doclist with their hit list – the order of the doc. IDs is important • by doc. ID or doc word-ranking – Two inverted barrels—the short barrel/full barrel
 • Crawling the Web – – – fast distributed crawling")
Major Data Structures (7) • Crawling the Web – – – fast distributed crawling system URLserver & Crawlers are implemented in phyton each Crawler keeps about 300 connection open at peek time the rate - 100 pages, 600 K per second uses: internal cached DNS lookup – synchronized IO to handle events – number of queues – Robust & Carefully tested
 • Indexing the Web – Parsing • should know to")
Major Data Structures (8) • Indexing the Web – Parsing • should know to handle errors – – HTML typos kb of zeros in a middle of a TAG non-ASCII characters HTML Tags nested hundreds deep • Developed their own Parser – involved a fair amount of work – did not cause a bottleneck
 • Indexing Documents into Barrels – turning words into word.")
Major Data Structures (9) • Indexing Documents into Barrels – turning words into word. IDs – in-memory hash table - the Lexicon – new additions are logged to a file – parallelization • shared lexicon of 14 million pages • log of all the extra words
 • Indexing the Web – Sorting • creating the inverted")
Major Data Structures (10) • Indexing the Web – Sorting • creating the inverted index • produces two types of barrels t sa t k – for titles and anchor (Short barrels) loo s firs els g – for full text (full barrels) kin arrel l barr n Ra rt b ful o sorts every barrel separately Sh d then An running sorters at parallel • • • the sorting is done in main memory

Searching • Algorithm – . 5 Compute the rank of that – 1. Parse the query document – 2. Convert word into – 6. If we’re at the end of the word. IDs short barrels start at the doclists of the full barrel, – 3. Seek to the start of unless we have enough the doclist in the short barrel for every word – 7. If were not at the end of any doclist goto step 4 – 4. Scan through the doclists until there is a – 8. Sort the documents by rank document that return the top K matches all of the • (May jump here after 40 k pages) search terms

The Ranking System • The information – Position, Font Size, Capitalization – Anchor Text – Page. Rank • Hits Types – title , anchor , URL etc. . – small font, large font etc. .
 • Each Hit type has it’s own weight – Counts")
The Ranking System (2) • Each Hit type has it’s own weight – Counts weights increase linearly with counts at first but quickly taper off this is the IR score of the doc – (IDF weighting? ? ) • the IR is combined with Page. Rank to give the final Rank • For multi-word query – A proximity score for every set of hits with a proximity type weight • 10 grades of proximity

Feedback • A trusted user may optionally evaluate the results • The feedback is saved • When modifying the ranking function we can see the impact of this change on all previous searches that were ranked

Results • Produce better results than major commercial search engines for most searches • Example: query “bill clinton” – – – return results from the “Whitehouse. gov” email addresses of the president all the results are high quality pages no broken links no bill without clinton & no clinton without bill

Storage Requirements • Using Compression on the repository • about 55 GB for all the data used by the SE • most of the queries can be answered by just the short inverted index • with better compression, a high quality SE can fit onto a 7 GB drive of a new PC

Storage Statistics Web Page Statistics

System Performance • • • It took 9 days to download 26 million pages 48. 5 pages per second The Indexer & Crawler ran simultaneously The Indexer runs at 54 pages per second The sorters run in parallel using 4 machines, the whole process took 24 hours
9f177a584fdc37e3e88a7f105a346a3b.ppt