8b29bf273a88ea3cd95042840c61bd40.ppt
- Количество слайдов: 42


 Huang")
Data Mining Using IBM Intelligent Miner Presented by: Qiyan (Jennifer ) Huang

Outline • Introduction • Mining Process • Main Functionalities of Intelligent Miner • Other Data Mining Products • Data Mining and Privacy • Summary • References

What is Data Mining • Data mining: discovering interesting patterns from large amounts of data – Knowledge discovery (mining) in databases (KDD), data/pattern analysis, information harvesting, business intelligence, etc.

Evolution of Database Technology • 1960 s: – Data collection, database creation • 1970 s: – Relational data model, relational DBMS implementation • 1980 s ~ present: – RDBMS, advanced data models 1990 s— 2000 s: – Data mining and data warehousing, multimedia databases, and Web databases

Data Mining VS. Database Query • Database – Identify customers who have purchased more than $10, 000 in the last month. – Find all customers who have purchased milk • Data Mining – Identify customers with similar buying habits. (Clustering) – Find all items which are frequently purchased with milk. (association rules)
 Pattern Evaluation Data Mining Task-relevant Data Warehouse Selection Data Cleaning")
Data Mining Process (KDD) Pattern Evaluation Data Mining Task-relevant Data Warehouse Selection Data Cleaning Databases J. Han. and M. Kamber. Data Mining: Concepts and Techniques, 2001

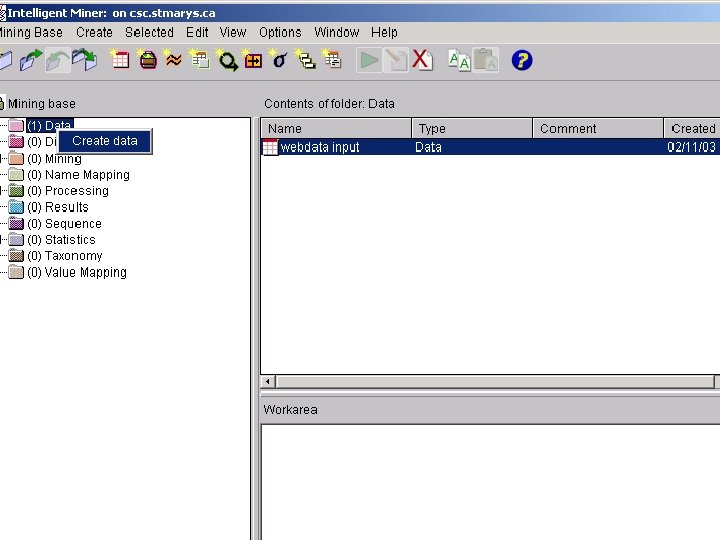
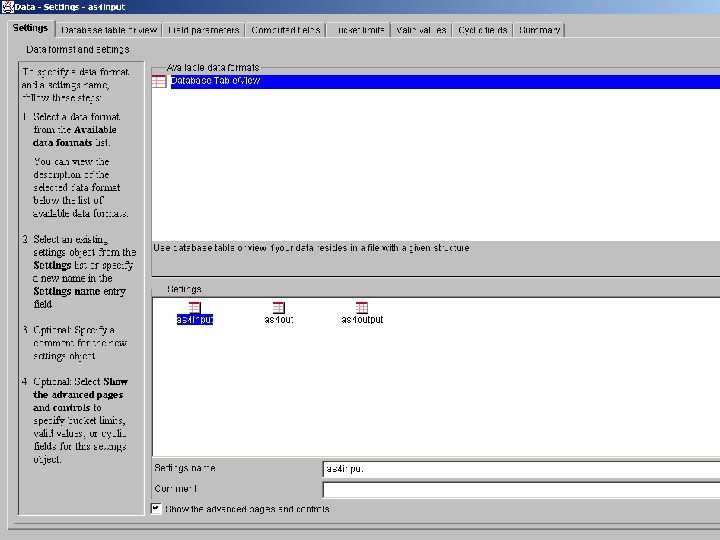
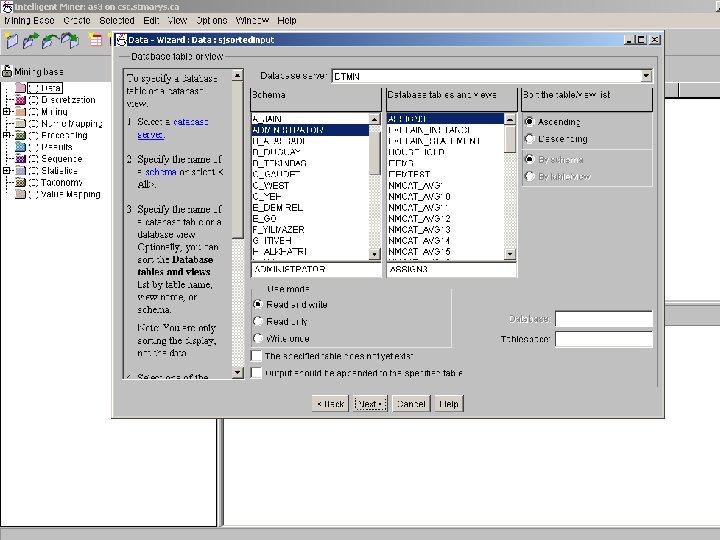
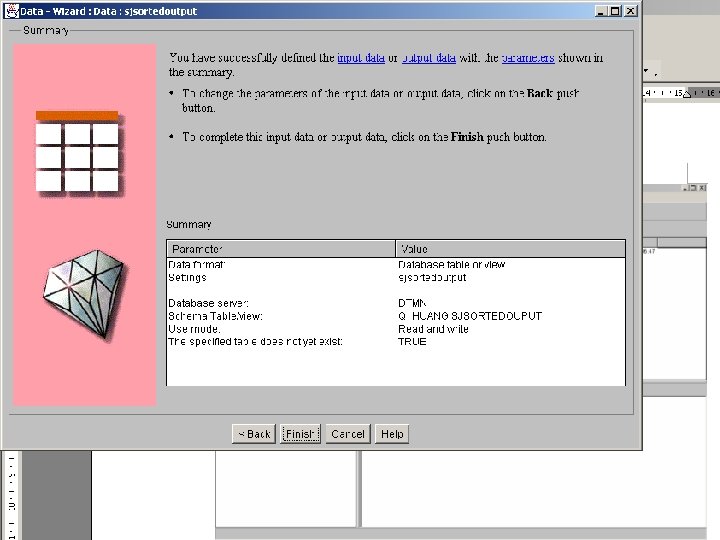
About DB 2 Intelligent Miner • DB 2 Intelligent Miner for Data “focused on the large-scale mining, such as large volumes of data, parallel data mining on Windows NT, Sun Solaris, and OS/390” – IBM

Main Functionalities • Cluster analysis – Group the data that share similar trends and patterns • Classification – Predict the outcome based on historical data • Association analysis – Finding frequent patterns.

Classification This follows an example from Quinlan’s ID 3

Classification

Classification This follows an example from Quinlan’s ID 3

Association – Association Rule: identifies relationships – Example “ 30% customers buy shirts in all the transactions, 60% of these customers will also by a tie” • Confidence factor is 60% • Support – if buying shirt and tie together is observed in 12% of all transactions, then the support is thus 12% • Lift = 60% / 30%=2
 5. 5286 7. 0388 5. 4662 5. 8805")
Association Support Confidence Type Lift (%) 5. 5286 7. 0388 5. 4662 5. 8805 5. 0163 7. 1279 5. 8226 5. 0697 5. 2836 5. 4350 5. 3459 34. 0800 34. 1300 34. 1700 34. 3400 34. 4900 34. 7400 34. 7600 34. 8300 34. 9400 35. 0200 + + + 2. 7300 2. 7400 2. 7500 2. 7600 2. 7800 3. 3900 2. 7400 3. 4100 2. 7600 Rule Body [203] + [1207] [203] + [1719] [202] + [802] [203] + [705] [202] + [1718] [711] + [203] [202] + [1702] [202] + [1207] [201] + [711] [201] + [1702] Rule Head => => => [1716] [1716] [710] [1703]

Data Mining Products • more than 50 commercial data mining tools • Wide range of pricing – – SAS Institute’s Enterprise Miner ~ $80 k SPSS Inc. Clementine ~ 75 K IBM Intelligent Miner ~ $60 k Desktop products start at few hundred dollars

Data Mining Products Data Ming Product Comparison on Algorithm IBM SAS SPSS Neural Network √ √ √ Decision Tree √ √ √ Clustering √ √ Association √ √ Nearest Neighbour √ Kohonen Self. Organizing Map √ √

Data Mining & Privacy • Release limited subset of data • • • – Hide attributes that potentially related to personal information Release Encrypted Data Audit to detect misuse of Data Set up Data Mining Controller

Summary • Introduction to Data Mining • A KDD Data Mining Process • Functionalities of Intelligent Miner • Commercial Data Mining Tools • Data Mining & Privacy

References Angoss Whitepaper: http: //www. angoss. com/Prod. Serv/Analytical. Tools/kseeker/whitepaper. html. Retrieved on Oct 26 th, 2003 C. Clifton. & D. Marks Security and Privacy Implications of Data Ming. 1996 D. W. Abbott, I. P. Matkovsky & J. F. Elder IV. An Evaluation of High-end Data Mining Tools Elder Research. http: //www. rgrossman. com/faq/dm-02. htm. Retrieved on Oct 28 th, 2003 IBM. BD 2 Intelligent Mine. http: //www-3. ibm. com/software/data/iminer/. Retrieved on Oct 26 th, 2003 J. F. Elder & D. W. Abbott. August, 1988 A comparison of Leading Data Mining Tools J. Han. and M. Kamber. Data Mining: Concepts and Techniques, 2000 http: //www. cald. cs. cmu. edu/summerschool 03/Privacy. Preserving. DM. ppt Retrieved on Nov 10 th, 2003 Robert Grossman http: //www. datamininglab. com/toolcomp. html#comparison. Retrieved on Oct 20 th, 2003 SPSS. http: //www. spss. com/. Retrieved on Nov 12 th, 2003


Evolution of Database Technology • 1960 s: – Data collection, database creation, and network DBMS • 1970 s: – Relational data model, relational DBMS implementation • 1980 s: – RDBMS, advanced data models 1990 s— 2000 s: – Data mining and data warehousing, multimedia databases, and Web databases

Data Mining: On What Kind of Data? • Data Sources – – Relational database Data warehouses Transactional databases WWW – – – Audio Image Text • Data types

Output: A Decision Tree for “buys_computer” age? <=30 student? overcast 30. . 40 yes >40 credit rating? no yes excellent fair no yes

Neural network x 0 w 0 x 1 w 1 - mk xn å f wn Input weight vector x vector w weighted sum Activation function output y

Neural network 0. 15 0. 09 0. 32 0. 25 0. 27 0. 11 0. 29 0. 23

Neural network

Applications of Clustering • Pattern Recognition • Image Processing • Economic Science (especially market research) • WWW – Document classification – Cluster Weblog data to discover groups of similar access patterns

Data Mining & Privacy Data Mining Tool Mining Controller Data warehouse

Examples of Clustering Applications • Marketing: Help marketers discover distinct groups in their customer bases, and then use this knowledge to develop targeted marketing programs • Insurance: Identifying groups of motor insurance policy holders with a high average claim cost • City-planning: Identifying groups of houses according to their house type, value, and geographical location • Earth-quake studies: Observed earth quake epicenters should be clustered along continent faults

Association and pattern analysis – Applications: • Basket data analysis, cross-marketing, catalog design, loss-leader analysis, clustering, classification, etc. – Examples. “diapers”) ® buys(x, “beers”) [0. 5%, 60%] • major(x, “CS”) ^ takes(x, “DB”) ® grade(x, “A”) [1%, 75%] • buys(x,

• • Data Mining: On What Kind of Data? Relational databases Data warehouses Transactional databases Advanced DB and information repositories – Object-oriented and object-relational databases – Text databases and multimedia databases – Heterogeneous and legacy databases – WWW

Steps of a KDD Process • Learning the application domain: • • • – relevant prior knowledge and goals of application Creating a target data set: data selection Data cleaning and preprocessing: (may take 60% of effort!) Data reduction and transformation: – Find useful features, dimensionality/variable reduction, invariant representation. • Choosing functions of data mining – summarization, classification, regression, association, clustering. • Choosing the mining algorithm(s) • Data mining: search for patterns of interest • Pattern evaluation and knowledge presentation – visualization, transformation, removing redundant patterns, etc. • Use of discovered knowledge

Strength and Weakness Strength – Algorithm breadth – Graphical output – Available for PC and mainframe environment Weakness – No automation – Data has to reside in IBM’s database system
8b29bf273a88ea3cd95042840c61bd40.ppt