

![Definition Finding n After that, following patterns are applied to identify definitions: [1] Bing](https://present5.com/presentation/2e29495f90cd8d88ed5161c48faaee85/image-61.jpg "Definition Finding n After that, following patterns are applied to identify definitions: [1] Bing")







 2) 3) The overall system is composed of five main")
 A definition finder: It uses the technique presented in definition finding")
![System Architecture [1] Bing Liu, Chee Wee Chin, Hwee Tou Ng. Mining Topic-Specific Concepts](https://present5.com/presentation/2e29495f90cd8d88ed5161c48faaee85/image-71.jpg "System Architecture [1] Bing Liu, Chee Wee Chin, Hwee Tou Ng. Mining Topic-Specific Concepts")












")




")
")
")
")


2e29495f90cd8d88ed5161c48faaee85.ppt
- Количество слайдов: 98
 CSE 634 Data Mining Concepts and Techniques Association Rule Mining Barbara Mucha Tania Irani Irem Incekoy Mikhail Bautin Course Instructor: Prof. Anita Wasilewska State University of New York, Stony Brook Group 6
CSE 634 Data Mining Concepts and Techniques Association Rule Mining Barbara Mucha Tania Irani Irem Incekoy Mikhail Bautin Course Instructor: Prof. Anita Wasilewska State University of New York, Stony Brook Group 6
 References n n n Data Mining: Concepts & Techniques by Jiawei Han and Micheline Kamber Presentation Slides of Prateek Duble Presentation Slides of the Course Book. Mining Topic-Specific Concepts and Definitions on the Web Effective Personalization Based on Association Rule Discovery from Web Usage Data
References n n n Data Mining: Concepts & Techniques by Jiawei Han and Micheline Kamber Presentation Slides of Prateek Duble Presentation Slides of the Course Book. Mining Topic-Specific Concepts and Definitions on the Web Effective Personalization Based on Association Rule Discovery from Web Usage Data
 Overview n Basic Concepts of Association Rule Mining n Association & Apriori Algorithm Paper: Mining Topic-Specific Concepts and Definitions on the Web n Paper: Effective Personalization Based on Association Rule Discovery from Web Usage Data n Barbara Mucha
Overview n Basic Concepts of Association Rule Mining n Association & Apriori Algorithm Paper: Mining Topic-Specific Concepts and Definitions on the Web n Paper: Effective Personalization Based on Association Rule Discovery from Web Usage Data n Barbara Mucha
 Outline n What is association rule mining? n Methods for association rule mining n Examples n Extensions of association rule Barbara Mucha
Outline n What is association rule mining? n Methods for association rule mining n Examples n Extensions of association rule Barbara Mucha
 What Is Association Rule Mining? n Frequent patterns: patterns (set of items, sequence, etc. ) that occur frequently in a database n Frequent pattern mining: finding regularities in data ¨ What products were n Beer and diapers? ! ¨ What often purchased together? are the subsequent purchases after buying a car? ¨ Can we automatically profile customers? Barbara Mucha
What Is Association Rule Mining? n Frequent patterns: patterns (set of items, sequence, etc. ) that occur frequently in a database n Frequent pattern mining: finding regularities in data ¨ What products were n Beer and diapers? ! ¨ What often purchased together? are the subsequent purchases after buying a car? ¨ Can we automatically profile customers? Barbara Mucha
 database of transactions, (2)") Basic Concepts of Association Rule Mining n n Given: (1) database of transactions, (2) each transaction is a list of items (purchased by a customer in a visit) Find: all rules that correlate the presence of one set of items with that of another set of items ¨ n E. g. , 98% of people who purchase tires and auto accessories also get automotive services done Applications * Maintenance Agreement (What the store should do to boost Maintenance Agreement sales) ¨ Home Electronics * (What other products should the store stocks up? ) ¨ Attached mailing in direct marketing ¨ Barbara Mucha
Basic Concepts of Association Rule Mining n n Given: (1) database of transactions, (2) each transaction is a list of items (purchased by a customer in a visit) Find: all rules that correlate the presence of one set of items with that of another set of items ¨ n E. g. , 98% of people who purchase tires and auto accessories also get automotive services done Applications * Maintenance Agreement (What the store should do to boost Maintenance Agreement sales) ¨ Home Electronics * (What other products should the store stocks up? ) ¨ Attached mailing in direct marketing ¨ Barbara Mucha
 Association Rule Definitions n n n Set of items: I={I 1, I 2, …, Im} Transactions: D = {t 1, t 2, . . , tn} be a set of transactions, where a transaction, t, is a set of items Itemset: {Ii 1, Ii 2, …, Iik} I Support of an itemset: Percentage of transactions which contain that itemset. Large (Frequent) itemset: Itemset whose number of occurrences is above a threshold. Barbara Mucha
Association Rule Definitions n n n Set of items: I={I 1, I 2, …, Im} Transactions: D = {t 1, t 2, . . , tn} be a set of transactions, where a transaction, t, is a set of items Itemset: {Ii 1, Ii 2, …, Iik} I Support of an itemset: Percentage of transactions which contain that itemset. Large (Frequent) itemset: Itemset whose number of occurrences is above a threshold. Barbara Mucha
 Rule Measures: Support & Confidence n An association rule is of the form : X Y where X, Y are subsets of I, and X INTERSECT Y = EMPTY n Each rule has two measures of value, support, and confidence. n Support indicates the frequencies of the occurring patterns, and confidence denotes the strength of implication in the rule. n The support of the rule X Y is support (X UNION Y) c is the CONFIDENCE of rule X Y if c% of transactions that contain X also contain Y, which can be written as the radio: n support(X UNION Y)/support(X) Barbara Mucha
Rule Measures: Support & Confidence n An association rule is of the form : X Y where X, Y are subsets of I, and X INTERSECT Y = EMPTY n Each rule has two measures of value, support, and confidence. n Support indicates the frequencies of the occurring patterns, and confidence denotes the strength of implication in the rule. n The support of the rule X Y is support (X UNION Y) c is the CONFIDENCE of rule X Y if c% of transactions that contain X also contain Y, which can be written as the radio: n support(X UNION Y)/support(X) Barbara Mucha
 Support & Confidence : An Example Let minimum support 50%, and minimum confidence 50%, then we have, ¨A C (50%, 66. 6%) ¨C A (50%, 100%) Barbara Mucha
Support & Confidence : An Example Let minimum support 50%, and minimum confidence 50%, then we have, ¨A C (50%, 66. 6%) ¨C A (50%, 100%) Barbara Mucha
 Types of Association Rule Mining n Boolean vs. quantitative associations (Based on the types of values handled) ¨ buys(x, “computer”) buys(x, “financial software”) [. 2%, 60%] ¨ age(x, “ 30. . 39”) ^ income(x, “ 42. . 48 K”) buys(x, “PC”) [1%, 75%] n Single dimension vs. multiple dimensional associations ¨ buys(x, “computer”) buys(x, “financial software”) [. 2%, 60%] ¨ age(x, “ 30. . 39”) ^ income(x, “ 42. . 48 K”) buys(x, “PC”) [1%, 75%] Barbara Mucha
Types of Association Rule Mining n Boolean vs. quantitative associations (Based on the types of values handled) ¨ buys(x, “computer”) buys(x, “financial software”) [. 2%, 60%] ¨ age(x, “ 30. . 39”) ^ income(x, “ 42. . 48 K”) buys(x, “PC”) [1%, 75%] n Single dimension vs. multiple dimensional associations ¨ buys(x, “computer”) buys(x, “financial software”) [. 2%, 60%] ¨ age(x, “ 30. . 39”) ^ income(x, “ 42. . 48 K”) buys(x, “PC”) [1%, 75%] Barbara Mucha
 Types of Association Rule Mining n Single level vs. multiple-level analysis ¨ What brands of beers are associated with what brands of diapers? n Various extensions ¨ Correlation, causality analysis n Association does not necessarily imply correlation or causality ¨ Constraints n E. g. , enforced small sales (sum < 100) trigger big buys (sum > 1, 000)? Barbara Mucha
Types of Association Rule Mining n Single level vs. multiple-level analysis ¨ What brands of beers are associated with what brands of diapers? n Various extensions ¨ Correlation, causality analysis n Association does not necessarily imply correlation or causality ¨ Constraints n E. g. , enforced small sales (sum < 100) trigger big buys (sum > 1, 000)? Barbara Mucha
 and minimum confidence") Association Discovery n Given a user specified minimum support (called MINSUP) and minimum confidence (called MINCONF), an important n PROBLEM is to find all high confidence, large itemsets (frequent sets, sets with high support). (where support and confidence are larger than minsup and minconf). n This problem can be decomposed into two subproblems: n 1. Find all large itemsets: with support > minsup (frequent sets). n 2. For a large itemset, X and B X (or Y X) , find those rules, X{B} => B ( X-Y Y) for which confidence > minconf. Barbara Mucha
Association Discovery n Given a user specified minimum support (called MINSUP) and minimum confidence (called MINCONF), an important n PROBLEM is to find all high confidence, large itemsets (frequent sets, sets with high support). (where support and confidence are larger than minsup and minconf). n This problem can be decomposed into two subproblems: n 1. Find all large itemsets: with support > minsup (frequent sets). n 2. For a large itemset, X and B X (or Y X) , find those rules, X{B} => B ( X-Y Y) for which confidence > minconf. Barbara Mucha
 Basics n Itemset: a set of items ¨ E. g. , n acm={a, c, m} Support of itemsets ¨ Sup(acm)=3 n n Given min_sup=3, acm is a frequent pattern Frequent pattern mining: find all frequent patterns in a database Barbara Mucha Transaction database TDB TID Items bought 100 f, a, c, d, g, I, m, p 200 a, b, c, f, l, m, o 300 b, f, h, j, o 400 500 b, c, k, s, p a, f, c, e, l, p, m, n
Basics n Itemset: a set of items ¨ E. g. , n acm={a, c, m} Support of itemsets ¨ Sup(acm)=3 n n Given min_sup=3, acm is a frequent pattern Frequent pattern mining: find all frequent patterns in a database Barbara Mucha Transaction database TDB TID Items bought 100 f, a, c, d, g, I, m, p 200 a, b, c, f, l, m, o 300 b, f, h, j, o 400 500 b, c, k, s, p a, f, c, e, l, p, m, n
 Mining Association Rules—An Example Min. support 50% Min. confidence 50% For rule A C: support = support({A &C}) = 50% confidence = support({A &C})/support({A}) = 66. 6% The Apriori principle: Any subset of a frequent itemset must be frequent
Mining Association Rules—An Example Min. support 50% Min. confidence 50% For rule A C: support = support({A &C}) = 50% confidence = support({A &C})/support({A}) = 66. 6% The Apriori principle: Any subset of a frequent itemset must be frequent
 Rules from frequent sets X = {mustard, sausage, beer}; frequency = 0. 4 n Y = {mustard, sausage, beer, chips}; frequency = 0. 2 n If the customer buys mustard, sausage, and beer, then the probability that he/she buys chips is 0. 5 n Barbara Mucha
Rules from frequent sets X = {mustard, sausage, beer}; frequency = 0. 4 n Y = {mustard, sausage, beer, chips}; frequency = 0. 2 n If the customer buys mustard, sausage, and beer, then the probability that he/she buys chips is 0. 5 n Barbara Mucha
 Applications n Mine: ¨ Sequential patterns n find inter-transaction patterns such that the presence of a set of items is followed by another item in the time-stamp ordered transaction set. ¨ Periodic patterns n It can be envisioned as a tool forecasting and prediction of the future behavior of time-series data. ¨ Structural Patterns n Structural patterns describe how classes and objects can be combined to form larger structures. Barbara Mucha
Applications n Mine: ¨ Sequential patterns n find inter-transaction patterns such that the presence of a set of items is followed by another item in the time-stamp ordered transaction set. ¨ Periodic patterns n It can be envisioned as a tool forecasting and prediction of the future behavior of time-series data. ¨ Structural Patterns n Structural patterns describe how classes and objects can be combined to form larger structures. Barbara Mucha
 Application Difficulties n n n Wal-Mart knows that customers who buy Barbie dolls have a 60% likelihood of buying one of three types of candy bars. What does Wal-Mart do with information like that? 'I don't have a clue, ' says Wal-Mart's chief of merchandising, Lee Scott www. kdnuggets. com/news/98/n 01. html Diapers and beer urban legend http: //web. onetel. net. uk/~hibou/Beer%20 and% 20 Nappies. html Barbara Mucha
Application Difficulties n n n Wal-Mart knows that customers who buy Barbie dolls have a 60% likelihood of buying one of three types of candy bars. What does Wal-Mart do with information like that? 'I don't have a clue, ' says Wal-Mart's chief of merchandising, Lee Scott www. kdnuggets. com/news/98/n 01. html Diapers and beer urban legend http: //web. onetel. net. uk/~hibou/Beer%20 and% 20 Nappies. html Barbara Mucha
 Thank You! Barbara Mucha
Thank You! Barbara Mucha
") CSE 634 Data Mining Concepts and Techniques Association & Apriori Algorithm Tania Irani (105573836) Course Instructor: Prof. Anita Wasilewska State University of New York, Stony Brook
CSE 634 Data Mining Concepts and Techniques Association & Apriori Algorithm Tania Irani (105573836) Course Instructor: Prof. Anita Wasilewska State University of New York, Stony Brook
 References n Data Mining: Concepts & Techniques by Jiawei Han and Micheline Kamber n Presentation Slides of Prof. Anita Wasilewska
References n Data Mining: Concepts & Techniques by Jiawei Han and Micheline Kamber n Presentation Slides of Prof. Anita Wasilewska
 n Frequent-Pattern Growth (FP-Growth)") Agenda n The Apriori Algorithm (Mining single-dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
Agenda n The Apriori Algorithm (Mining single-dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
 The Apriori Algorithm: Key Concepts n K-itemsets: An itemset having k items in it. n Support or Frequency: Number of transactions that contain a particular itemset. n Frequent Itemsets: An itemset that satisfies minimum support. (denoted by Lk for frequent k-itemset). n Apriori Property: All non-empty subsets of a frequent itemset must be frequent. n Join Operation: Ck, the set of candidate k-itemsets is generated by joining Lk-1 with itself. (L 1: frequent 1 -itemset, Lk: frequent k-itemset) n Prune Operation: Lk, the set of frequent k-itemsets is extracted from Ck by pruning it – getting rid of all the non-frequent k-itemsets in Ck Iterative level-wise approach: k-itemsets used to explore (k+1)itemsets. The Apriori Algorithm finds frequent k-itemsets.
The Apriori Algorithm: Key Concepts n K-itemsets: An itemset having k items in it. n Support or Frequency: Number of transactions that contain a particular itemset. n Frequent Itemsets: An itemset that satisfies minimum support. (denoted by Lk for frequent k-itemset). n Apriori Property: All non-empty subsets of a frequent itemset must be frequent. n Join Operation: Ck, the set of candidate k-itemsets is generated by joining Lk-1 with itself. (L 1: frequent 1 -itemset, Lk: frequent k-itemset) n Prune Operation: Lk, the set of frequent k-itemsets is extracted from Ck by pruning it – getting rid of all the non-frequent k-itemsets in Ck Iterative level-wise approach: k-itemsets used to explore (k+1)itemsets. The Apriori Algorithm finds frequent k-itemsets.
 How is the Apriori Property used in the Algorithm? n Mining single-dimensional Boolean association rules is a 2 step process: ¨ Using the Apriori Property find the frequent n itemsets: Each iteration will generate Ck (candidate k-itemsets from Ck-1) and Lk (frequent k-itemsets) ¨ Use the frequent k-itemsets to generate association rules.
How is the Apriori Property used in the Algorithm? n Mining single-dimensional Boolean association rules is a 2 step process: ¨ Using the Apriori Property find the frequent n itemsets: Each iteration will generate Ck (candidate k-itemsets from Ck-1) and Lk (frequent k-itemsets) ¨ Use the frequent k-itemsets to generate association rules.
 Finding frequent itemsets using the Apriori Algorithm: Example TID T 100 List of Items n I 1, I 2, I 5 n T 100 I 2, I 4 T 100 I 2, I 3 n T 100 I 1, I 2, I 4 n T 100 I 1, I 3 T 100 I 2, I 3 T 100 n I 1, I 3 n T 100 I 1, I 2 , I 3, I 5 T 100 I 1, I 2, I 3 Consider a database D, consisting of 9 transactions. Each transaction is represented by an itemset. Suppose min. support required is 2 (2 out of 9 = 2/9 =22 % ) Say min. confidence required is 70%. We have to first find out the frequent itemset using Apriori Algorithm. Then, Association rules will be generated using min. support & min. confidence.
Finding frequent itemsets using the Apriori Algorithm: Example TID T 100 List of Items n I 1, I 2, I 5 n T 100 I 2, I 4 T 100 I 2, I 3 n T 100 I 1, I 2, I 4 n T 100 I 1, I 3 T 100 I 2, I 3 T 100 n I 1, I 3 n T 100 I 1, I 2 , I 3, I 5 T 100 I 1, I 2, I 3 Consider a database D, consisting of 9 transactions. Each transaction is represented by an itemset. Suppose min. support required is 2 (2 out of 9 = 2/9 =22 % ) Say min. confidence required is 70%. We have to first find out the frequent itemset using Apriori Algorithm. Then, Association rules will be generated using min. support & min. confidence.
 Step 1: Generating candidate and frequent 1 itemsets with min. support = 2 Scan D for count of each candidate Itemset Sup. Count {I 1} 6 {I 2} Compare candidate support count with minimum support count Itemset Sup. Count {I 1} 6 7 {I 2} 7 {I 3} 6 {I 4} 2 {I 5} 2 C 1 L 1 § In the first iteration of the algorithm, each item is a member of the set of candidates Ck along with its support count. § The set of frequent 1 -itemsets L 1, consists of the candidate 1 itemsets satisfying minimum support.
Step 1: Generating candidate and frequent 1 itemsets with min. support = 2 Scan D for count of each candidate Itemset Sup. Count {I 1} 6 {I 2} Compare candidate support count with minimum support count Itemset Sup. Count {I 1} 6 7 {I 2} 7 {I 3} 6 {I 4} 2 {I 5} 2 C 1 L 1 § In the first iteration of the algorithm, each item is a member of the set of candidates Ck along with its support count. § The set of frequent 1 -itemsets L 1, consists of the candidate 1 itemsets satisfying minimum support.
 Step 2: Generating candidate and frequent 2 itemsets with min. support = 2 Generate C 2 candidates from L 1 x L 1 Itemset Scan D for count of each candidate Compare Itemset candidate support count with minimum{I 1, I 2} support count Sup Count Itemset Sup. Count {I 1, I 2} 4 {I 1, I 4} {I 1, I 3} 4 {I 1, I 5} {I 1, I 4} 1 {I 1, I 5} 2 {I 2, I 3} 4 {I 2, I 4} 2 {I 2, I 5} 2 {I 3, I 4} 0 {I 3, I 5} 1 {I 4, I 5} 0 {I 1, I 2} {I 1, I 3} {I 3, I 5} {I 4, I 5} C 2 4 L 2 Note: We haven’t used Apriori Property yet!
Step 2: Generating candidate and frequent 2 itemsets with min. support = 2 Generate C 2 candidates from L 1 x L 1 Itemset Scan D for count of each candidate Compare Itemset candidate support count with minimum{I 1, I 2} support count Sup Count Itemset Sup. Count {I 1, I 2} 4 {I 1, I 4} {I 1, I 3} 4 {I 1, I 5} {I 1, I 4} 1 {I 1, I 5} 2 {I 2, I 3} 4 {I 2, I 4} 2 {I 2, I 5} 2 {I 3, I 4} 0 {I 3, I 5} 1 {I 4, I 5} 0 {I 1, I 2} {I 1, I 3} {I 3, I 5} {I 4, I 5} C 2 4 L 2 Note: We haven’t used Apriori Property yet!
 Step 3: Generating candidate and frequent 3 itemsets with min. support = 2 Generate C 3 candidates from L 2 Itemset Scan D for count of each candidate Compare candidate support count Itemset with min support count Sup Count Itemset Sup. Count {I 1, I 2, I 5} {I 1, I 2, I 3} 2 {I 1, I 3, I 5} {I 1, I 2, I 5} 2 {I 1, I 2, I 3} {I 2, I 3, I 4} {I 2, I 3, I 5} {I 2, I 4, I 5} C 3 L 3 Contains non-frequent (2 -itemset) subsets § The generation of the set of candidate 3 -itemsets C 3, involves use of the Apriori Property. § When Join step is complete, the Prune step will be used to reduce the size of C 3. Prune step helps to avoid heavy computation due to large Ck.
Step 3: Generating candidate and frequent 3 itemsets with min. support = 2 Generate C 3 candidates from L 2 Itemset Scan D for count of each candidate Compare candidate support count Itemset with min support count Sup Count Itemset Sup. Count {I 1, I 2, I 5} {I 1, I 2, I 3} 2 {I 1, I 3, I 5} {I 1, I 2, I 5} 2 {I 1, I 2, I 3} {I 2, I 3, I 4} {I 2, I 3, I 5} {I 2, I 4, I 5} C 3 L 3 Contains non-frequent (2 -itemset) subsets § The generation of the set of candidate 3 -itemsets C 3, involves use of the Apriori Property. § When Join step is complete, the Prune step will be used to reduce the size of C 3. Prune step helps to avoid heavy computation due to large Ck.
 Step 4: Generating frequent 4 -itemset n L 3 Join L 3 C 4 = {{I 1, I 2, I 3, I 5}} n This itemset is pruned since its subset {{I 2, I 3, I 5}} is not frequent. n Thus, C 4 = φ, and the algorithm terminates, having found all of the frequent items. n This completes our Apriori Algorithm. What’s Next ? n These frequent itemsets will be used to generate strong association rules (where strong association rules satisfy both minimum support & minimum confidence).
Step 4: Generating frequent 4 -itemset n L 3 Join L 3 C 4 = {{I 1, I 2, I 3, I 5}} n This itemset is pruned since its subset {{I 2, I 3, I 5}} is not frequent. n Thus, C 4 = φ, and the algorithm terminates, having found all of the frequent items. n This completes our Apriori Algorithm. What’s Next ? n These frequent itemsets will be used to generate strong association rules (where strong association rules satisfy both minimum support & minimum confidence).
 Step 5: Generating Association Rules from frequent k-itemsets n Procedure: ¨ For each frequent itemset l, generate all nonempty subsets of l ¨ For every nonempty subset s of l, output the rule “s (l - s)” if support_count(l) / support_count(s) ≥ min_conf where min_conf is minimum confidence threshold. 70% in our case. n Back To Example: ¨ Lets take l = {I 1, I 2, I 5} ¨ The nonempty subsets of Lets take l are {I 1, I 2}, {I 1, I 5}, {I 2, I 5}, {I 1}, {I 2}, {I 5}
Step 5: Generating Association Rules from frequent k-itemsets n Procedure: ¨ For each frequent itemset l, generate all nonempty subsets of l ¨ For every nonempty subset s of l, output the rule “s (l - s)” if support_count(l) / support_count(s) ≥ min_conf where min_conf is minimum confidence threshold. 70% in our case. n Back To Example: ¨ Lets take l = {I 1, I 2, I 5} ¨ The nonempty subsets of Lets take l are {I 1, I 2}, {I 1, I 5}, {I 2, I 5}, {I 1}, {I 2}, {I 5}
![Step 5: Generating Association Rules from frequent k-itemsets [Cont. ] n The resulting association](https://present5.com/presentation/2e29495f90cd8d88ed5161c48faaee85/image-30.jpg "Step 5: Generating Association Rules from frequent k-itemsets [Cont. ] n The resulting association") Step 5: Generating Association Rules from frequent k-itemsets [Cont. ] n The resulting association rules are: ¨ R 1: I 1 ^ I 2 I 5 n Confidence = sc{I 1, I 2, I 5} / sc{I 1, I 2} = 2/4 = 50% n R 1 is Rejected. ¨ R 2: I 1 ^ I 5 I 2 n Confidence = sc{I 1, I 2, I 5} / sc{I 1, I 5} = 2/2 = 100% n R 2 is Selected. ¨ R 3: I 2 ^ I 5 I 1 n Confidence = sc{I 1, I 2, I 5} / sc{I 2, I 5} = 2/2 = 100% n R 3 is Selected.
Step 5: Generating Association Rules from frequent k-itemsets [Cont. ] n The resulting association rules are: ¨ R 1: I 1 ^ I 2 I 5 n Confidence = sc{I 1, I 2, I 5} / sc{I 1, I 2} = 2/4 = 50% n R 1 is Rejected. ¨ R 2: I 1 ^ I 5 I 2 n Confidence = sc{I 1, I 2, I 5} / sc{I 1, I 5} = 2/2 = 100% n R 2 is Selected. ¨ R 3: I 2 ^ I 5 I 1 n Confidence = sc{I 1, I 2, I 5} / sc{I 2, I 5} = 2/2 = 100% n R 3 is Selected.
![Step 5: Generating Association Rules from Frequent Itemsets [Cont. ] ¨ R 4: I](https://present5.com/presentation/2e29495f90cd8d88ed5161c48faaee85/image-31.jpg "Step 5: Generating Association Rules from Frequent Itemsets [Cont. ] ¨ R 4: I") Step 5: Generating Association Rules from Frequent Itemsets [Cont. ] ¨ R 4: I 1 I 2 ^ I 5 Confidence = sc{I 1, I 2, I 5} / sc{I 1} = 2/6 = 33% n R 4 is Rejected. ¨ R 5: I 2 I 1 ^ I 5 n Confidence = sc{I 1, I 2, I 5} / {I 2} = 2/7 = 29% n R 5 is Rejected. ¨ R 6: I 5 I 1 ^ I 2 n Confidence = sc{I 1, I 2, I 5} / {I 5} = 2/2 = 100% n R 6 is Selected. n We have found three strong association rules.
Step 5: Generating Association Rules from Frequent Itemsets [Cont. ] ¨ R 4: I 1 I 2 ^ I 5 Confidence = sc{I 1, I 2, I 5} / sc{I 1} = 2/6 = 33% n R 4 is Rejected. ¨ R 5: I 2 I 1 ^ I 5 n Confidence = sc{I 1, I 2, I 5} / {I 2} = 2/7 = 29% n R 5 is Rejected. ¨ R 6: I 5 I 1 ^ I 2 n Confidence = sc{I 1, I 2, I 5} / {I 5} = 2/2 = 100% n R 6 is Selected. n We have found three strong association rules.
 n Frequent-Pattern Growth") Agenda n The Apriori Algorithm (Mining single dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
Agenda n The Apriori Algorithm (Mining single dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
 Mining Frequent Patterns Without Candidate Generation n Compress a large database into a compact, Frequent. Pattern tree (FP-tree) structure ¨ ¨ n Highly condensed, but complete for frequent pattern mining Avoid costly database scans Develop an efficient, FP-tree-based frequent pattern mining method ¨ A divide-and-conquer methodology: n n Divide the new DB into a set of conditional DBs – each associated with one frequent item n ¨ Compress DB into FP-tree, retain itemset associations Mine each such database seperately Avoid candidate generation
Mining Frequent Patterns Without Candidate Generation n Compress a large database into a compact, Frequent. Pattern tree (FP-tree) structure ¨ ¨ n Highly condensed, but complete for frequent pattern mining Avoid costly database scans Develop an efficient, FP-tree-based frequent pattern mining method ¨ A divide-and-conquer methodology: n n Divide the new DB into a set of conditional DBs – each associated with one frequent item n ¨ Compress DB into FP-tree, retain itemset associations Mine each such database seperately Avoid candidate generation
 FP-Growth Method : An Example TID List of Items T 100 I 1, I 2, I 5 T 100 I 2, I 4 T 100 I 2, I 3 T 100 I 1, I 2, I 4 T 100 I 1, I 3 T 100 n I 2, I 3 T 100 I 1, I 3 T 100 n n n I 1, I 2 , I 3, I 5 n T 100 I 1, I 2, I 3 Consider the previous example of a database D, consisting of 9 transactions. Suppose min. support count required is 2 (i. e. min_sup = 2/9 = 22 % ) The first scan of the database is same as Apriori, which derives the set of 1 -itemsets & their support counts. The set of frequent items is sorted in the order of descending support count. The resulting set is denoted as L = {I 2: 7, I 1: 6, I 3: 6, I 4: 2, I 5: 2}
FP-Growth Method : An Example TID List of Items T 100 I 1, I 2, I 5 T 100 I 2, I 4 T 100 I 2, I 3 T 100 I 1, I 2, I 4 T 100 I 1, I 3 T 100 n I 2, I 3 T 100 I 1, I 3 T 100 n n n I 1, I 2 , I 3, I 5 n T 100 I 1, I 2, I 3 Consider the previous example of a database D, consisting of 9 transactions. Suppose min. support count required is 2 (i. e. min_sup = 2/9 = 22 % ) The first scan of the database is same as Apriori, which derives the set of 1 -itemsets & their support counts. The set of frequent items is sorted in the order of descending support count. The resulting set is denoted as L = {I 2: 7, I 1: 6, I 3: 6, I 4: 2, I 5: 2}
 FP-Growth Method: Construction of FP-Tree n n n n First, create the root of the tree, labeled with “null”. Scan the database D a second time (First time we scanned it to create 1 -itemset and then L), this will generate the complete tree. The items in each transaction are processed in L order (i. e. sorted order). A branch is created for each transaction with items having their support count separated by colon. Whenever the same node is encountered in another transaction, we just increment the support count of the common node or Prefix. To facilitate tree traversal, an item header table is built so that each item points to its occurrences in the tree via a chain of node-links. Now, The problem of mining frequent patterns in database is transformed to that of mining the FP-Tree.
FP-Growth Method: Construction of FP-Tree n n n n First, create the root of the tree, labeled with “null”. Scan the database D a second time (First time we scanned it to create 1 -itemset and then L), this will generate the complete tree. The items in each transaction are processed in L order (i. e. sorted order). A branch is created for each transaction with items having their support count separated by colon. Whenever the same node is encountered in another transaction, we just increment the support count of the common node or Prefix. To facilitate tree traversal, an item header table is built so that each item points to its occurrences in the tree via a chain of node-links. Now, The problem of mining frequent patterns in database is transformed to that of mining the FP-Tree.
 FP-Growth Method: Construction of FP-Tree null{} Item Sup Node. Id Count link I 2 7 I 1 6 I 3 2 I 5 2 I 1: 2 6 I 4 I 2: 7 I 1: 4 I 3: 2 I 4: 1 I 3: 2 I 5: 1 I 4: 1 I 5: 1 An FP-Tree that registers compressed, frequent pattern information
FP-Growth Method: Construction of FP-Tree null{} Item Sup Node. Id Count link I 2 7 I 1 6 I 3 2 I 5 2 I 1: 2 6 I 4 I 2: 7 I 1: 4 I 3: 2 I 4: 1 I 3: 2 I 5: 1 I 4: 1 I 5: 1 An FP-Tree that registers compressed, frequent pattern information
 pattern bases 1. 2. 3. 4. 5.") Mining the FP-Tree by Creating Conditional (sub) pattern bases 1. 2. 3. 4. 5. Start from each frequent length-1 pattern (as an initial suffix pattern). Construct its conditional pattern base which consists of the set of prefix paths in the FP-Tree co-occurring with suffix pattern. Then, construct its conditional FP-Tree & perform mining on this tree. The pattern growth is achieved by concatenation of the suffix pattern with the frequent patterns generated from a conditional FP-Tree. The union of all frequent patterns (generated by step 4) gives the required frequent itemset.
Mining the FP-Tree by Creating Conditional (sub) pattern bases 1. 2. 3. 4. 5. Start from each frequent length-1 pattern (as an initial suffix pattern). Construct its conditional pattern base which consists of the set of prefix paths in the FP-Tree co-occurring with suffix pattern. Then, construct its conditional FP-Tree & perform mining on this tree. The pattern growth is achieved by concatenation of the suffix pattern with the frequent patterns generated from a conditional FP-Tree. The union of all frequent patterns (generated by step 4) gives the required frequent itemset.
 FP-Tree Example Continued Item Conditional pattern base Conditional FP-Tree Frequent pattern generated I 5 {(I 2 I 1: 1), (I 2 I 1 I 3: 1)} I 2 I 5: 2, I 1 I 5: 2, I 2 I 1 I 5: 2 I 4 {(I 2 I 1: 1), (I 2: 1)} I 2 I 4: 2 I 3 {(I 2 I 1: 2), (I 2: 2), (I 1: 2)} , I 2 I 3: 4, I 1 I 3: 2 , I 2 I 1 I 3: 2 I 1 {(I 2: 4)} I 2 I 1: 4 Mining the FP-Tree by creating conditional (sub) pattern bases Now, following the above mentioned steps: § Lets start from I 5 is involved in 2 branches namely {I 2 I 1 I 5: 1} and {I 2 I 1 I 3 I 5: 1}. § Therefore considering I 5 as suffix, its 2 corresponding prefix paths would be {I 2 I 1: 1} and {I 2 I 1 I 3: 1}, which forms its conditional pattern base.
FP-Tree Example Continued Item Conditional pattern base Conditional FP-Tree Frequent pattern generated I 5 {(I 2 I 1: 1), (I 2 I 1 I 3: 1)} I 2 I 5: 2, I 1 I 5: 2, I 2 I 1 I 5: 2 I 4 {(I 2 I 1: 1), (I 2: 1)} I 2 I 4: 2 I 3 {(I 2 I 1: 2), (I 2: 2), (I 1: 2)} , I 2 I 3: 4, I 1 I 3: 2 , I 2 I 1 I 3: 2 I 1 {(I 2: 4)} I 2 I 1: 4 Mining the FP-Tree by creating conditional (sub) pattern bases Now, following the above mentioned steps: § Lets start from I 5 is involved in 2 branches namely {I 2 I 1 I 5: 1} and {I 2 I 1 I 3 I 5: 1}. § Therefore considering I 5 as suffix, its 2 corresponding prefix paths would be {I 2 I 1: 1} and {I 2 I 1 I 3: 1}, which forms its conditional pattern base.
 FP-Tree Example Continued n n n Out of these, only I 1 & I 2 is selected in the conditional FP-Tree because I 3 does not satisfy the minimum support count. For I 1, support count in conditional pattern base = 1 + 1 = 2 For I 2, support count in conditional pattern base = 1 + 1 = 2 For I 3, support count in conditional pattern base = 1 Thus support count for I 3 is less than required min_sup which is 2 here. Now, we have a conditional FP-Tree with us. All frequent pattern corresponding to suffix I 5 are generated by considering all possible combinations of I 5 and conditional FP-Tree. The same procedure is applied to suffixes I 4, I 3 and I 1. Note: I 2 is not taken into consideration for suffix because it doesn’t have any prefix at all.
FP-Tree Example Continued n n n Out of these, only I 1 & I 2 is selected in the conditional FP-Tree because I 3 does not satisfy the minimum support count. For I 1, support count in conditional pattern base = 1 + 1 = 2 For I 2, support count in conditional pattern base = 1 + 1 = 2 For I 3, support count in conditional pattern base = 1 Thus support count for I 3 is less than required min_sup which is 2 here. Now, we have a conditional FP-Tree with us. All frequent pattern corresponding to suffix I 5 are generated by considering all possible combinations of I 5 and conditional FP-Tree. The same procedure is applied to suffixes I 4, I 3 and I 1. Note: I 2 is not taken into consideration for suffix because it doesn’t have any prefix at all.
 Why Frequent Pattern Growth Fast ? n Performance study shows ¨ FP-growth is an order of magnitude faster than Apriori n Reasoning ¨ No candidate generation, no candidate test ¨ Use compact data structure ¨ Eliminate repeated database scans ¨ Basic operation is counting and FP-tree building
Why Frequent Pattern Growth Fast ? n Performance study shows ¨ FP-growth is an order of magnitude faster than Apriori n Reasoning ¨ No candidate generation, no candidate test ¨ Use compact data structure ¨ Eliminate repeated database scans ¨ Basic operation is counting and FP-tree building
 n Frequent-Pattern Growth") Agenda n The Apriori Algorithm (Mining single dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
Agenda n The Apriori Algorithm (Mining single dimensional boolean association rules) n Frequent-Pattern Growth (FP-Growth) Method n Summary
 Summary n Association rules are generated from frequent itemsets. n Frequent itemsets are mined using Apriori algorithm or Frequent. Pattern Growth method. n Apriori property states that all the subsets of frequent itemsets must also be frequent. n Apriori algorithm uses frequent itemsets, join & prune methods and Apriori property to derive strong association rules. n Frequent-Pattern Growth method avoids repeated database scanning of Apriori algorithm. n FP-Growth method is faster than Apriori algorithm.
Summary n Association rules are generated from frequent itemsets. n Frequent itemsets are mined using Apriori algorithm or Frequent. Pattern Growth method. n Apriori property states that all the subsets of frequent itemsets must also be frequent. n Apriori algorithm uses frequent itemsets, join & prune methods and Apriori property to derive strong association rules. n Frequent-Pattern Growth method avoids repeated database scanning of Apriori algorithm. n FP-Growth method is faster than Apriori algorithm.
 Thank You!
Thank You!
 Mining Topic-Specific Concepts and Definitions on the Web Irem Incekoy May 2003, Proceedings of the 12 th International conference on World Wide Web, ACM Press Bing Liu, University of Illinois at Chicago, 851 S. Morgan Street Chicago IL 60607 -7053 Chee Wee Chin, Hwee Tou Ng, National University of Singapore 3 Science Drive 2 Singapore
Mining Topic-Specific Concepts and Definitions on the Web Irem Incekoy May 2003, Proceedings of the 12 th International conference on World Wide Web, ACM Press Bing Liu, University of Illinois at Chicago, 851 S. Morgan Street Chicago IL 60607 -7053 Chee Wee Chin, Hwee Tou Ng, National University of Singapore 3 Science Drive 2 Singapore
 References n Agrawal, R. and Srikant, R. “Fast Algorithm for Mining Association Rules”, VLDB-94, 1994. n Anderson, C. and Horvitz, E. “Web Montage: A Dynamic Personalized Start Page”, WWW-02, 2002. n Brin, S. and Page, L. “The Anatomy of a Large. Scale Hypertextual Web Search Engine”, WWW 7, 1998.
References n Agrawal, R. and Srikant, R. “Fast Algorithm for Mining Association Rules”, VLDB-94, 1994. n Anderson, C. and Horvitz, E. “Web Montage: A Dynamic Personalized Start Page”, WWW-02, 2002. n Brin, S. and Page, L. “The Anatomy of a Large. Scale Hypertextual Web Search Engine”, WWW 7, 1998.
 Introduction When one wants to learn about a topic, one reads a book or a survey paper. n One can read the research papers about the topic. n None of these is very practical. n Learning from web is convenient, intuitive, and diverse. n
Introduction When one wants to learn about a topic, one reads a book or a survey paper. n One can read the research papers about the topic. n None of these is very practical. n Learning from web is convenient, intuitive, and diverse. n
 Purpose of the Paper n This paper’s task is “mining topic-specific knowledge on the Web”. n The goal is to help people learn in-depth knowledge of a topic systematically on the Web.
Purpose of the Paper n This paper’s task is “mining topic-specific knowledge on the Web”. n The goal is to help people learn in-depth knowledge of a topic systematically on the Web.
 Learning about a New Topic One needs to find definitions and descriptions of the topic. n One also needs to know the sub-topics and salient concepts of the topic. n Thus, one wants the knowledge as presented in a traditional book. n The task of this paper can be summarized as “compiling a book on the Web”. n
Learning about a New Topic One needs to find definitions and descriptions of the topic. n One also needs to know the sub-topics and salient concepts of the topic. n Thus, one wants the knowledge as presented in a traditional book. n The task of this paper can be summarized as “compiling a book on the Web”. n
 Proposed Technique n First, identify sub-topics or salient concepts of that specific topic. n Then, find and organize the informative pages containing definitions and descriptions of the topic and sub-topics.
Proposed Technique n First, identify sub-topics or salient concepts of that specific topic. n Then, find and organize the informative pages containing definitions and descriptions of the topic and sub-topics.
 Why are the current search tecnhiques not sufficient? For definitions and descriptions of the topic: Existing search engines rank web pages based on keyword matching and hyperlink structures. NOT very useful for measuring the informative value of the page. n For sub-topics and salient concepts of the topic: A single web page is unlikely to contain information about all the key concepts or sub-topics of the topic. Thus, sub-topics need to be discovered from multiple web pages. Current search engine systems do not perform this task. n
Why are the current search tecnhiques not sufficient? For definitions and descriptions of the topic: Existing search engines rank web pages based on keyword matching and hyperlink structures. NOT very useful for measuring the informative value of the page. n For sub-topics and salient concepts of the topic: A single web page is unlikely to contain information about all the key concepts or sub-topics of the topic. Thus, sub-topics need to be discovered from multiple web pages. Current search engine systems do not perform this task. n
 Related Work v v • Web information extraction wrappers Web query languages User preference approach Question answering in information retrieval Question answering is a closely-related work to this paper. The objective of a question-answering system is to provide direct answers to questions submitted by the user. In this paper’s task, many of the questions are about definitions of terms.
Related Work v v • Web information extraction wrappers Web query languages User preference approach Question answering in information retrieval Question answering is a closely-related work to this paper. The objective of a question-answering system is to provide direct answers to questions submitted by the user. In this paper’s task, many of the questions are about definitions of terms.
 1) Submit T to a search engine, which returns") The Algorithm Web. Learn (T) 1) Submit T to a search engine, which returns a set of relevant pages 2) The system mines the sub-topics or salient concepts of T using a set S of top ranking pages from the search engine 3) The system then discovers the informative pages containing definitions of the topic and sub-topics (salient concepts) from S 4) The user views the concepts and informative pages. If s/he still wants to know more about sub-topics then for each user-interested sub-topic Ti of T do Web. Learn (Ti);
The Algorithm Web. Learn (T) 1) Submit T to a search engine, which returns a set of relevant pages 2) The system mines the sub-topics or salient concepts of T using a set S of top ranking pages from the search engine 3) The system then discovers the informative pages containing definitions of the topic and sub-topics (salient concepts) from S 4) The user views the concepts and informative pages. If s/he still wants to know more about sub-topics then for each user-interested sub-topic Ti of T do Web. Learn (Ti);
 Sub-Topic or Salient Concept Discovery n Observation: Sub-topics or salient concepts of a topic are important word phrases, usually emphasized using some HTML tags (e. g. ,
Sub-Topic or Salient Concept Discovery n Observation: Sub-topics or salient concepts of a topic are important word phrases, usually emphasized using some HTML tags (e. g. ,
, sub-topic") Sub-Topic Discovery n After obtaining a set of relevant topranking pages (using Google), sub-topic discovery consists of the following 5 steps. 1) Filter out the “noisy” documents that rarely contain sub-topics or salientconcepts. The resulting set of documents is the source for sub-topic discovery.
Sub-Topic Discovery n After obtaining a set of relevant topranking pages (using Google), sub-topic discovery consists of the following 5 steps. 1) Filter out the “noisy” documents that rarely contain sub-topics or salientconcepts. The resulting set of documents is the source for sub-topic discovery.
 Identify important phrases in each page (discover phrases emphasized by HTML") Sub-Topic Discovery 2) Identify important phrases in each page (discover phrases emphasized by HTML markup tags). Rules to determine if a markup tag can safely be ignored § Contains a salutation title (Mr, Dr, Professor). § Contains an URL or an email address. § Contains terms related to a publication (conference, proceedings, journal). § Contains an image between the markup tags. § Too lengthy (the paper uses 15 words as the upper limit)
Sub-Topic Discovery 2) Identify important phrases in each page (discover phrases emphasized by HTML markup tags). Rules to determine if a markup tag can safely be ignored § Contains a salutation title (Mr, Dr, Professor). § Contains an URL or an email address. § Contains terms related to a publication (conference, proceedings, journal). § Contains an image between the markup tags. § Too lengthy (the paper uses 15 words as the upper limit)
 Sub-Topic Discovery n Also, in this step, some preprocessing techniques such as stopwords removal and word stemming are applied in order to extract quality text segments. v v Stopwords removal: Eliminating the words that occur too frequently and have little informational meaning. Word stemming: Finding the root form of a word by removing its suffix.
Sub-Topic Discovery n Also, in this step, some preprocessing techniques such as stopwords removal and word stemming are applied in order to extract quality text segments. v v Stopwords removal: Eliminating the words that occur too frequently and have little informational meaning. Word stemming: Finding the root form of a word by removing its suffix.
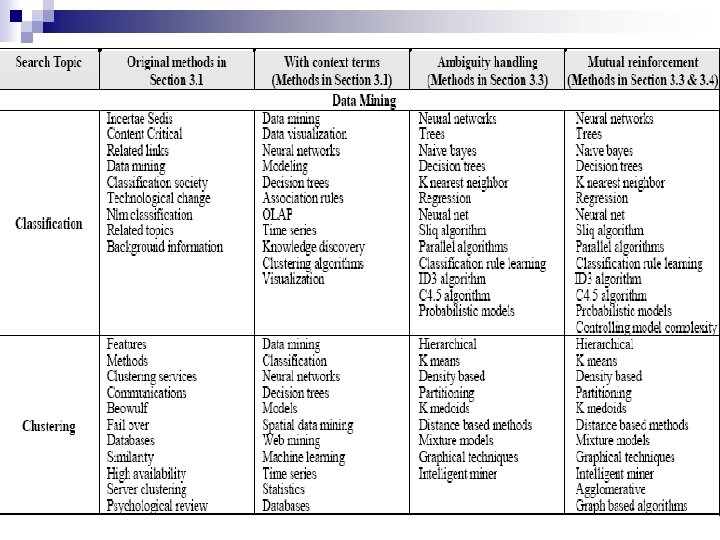
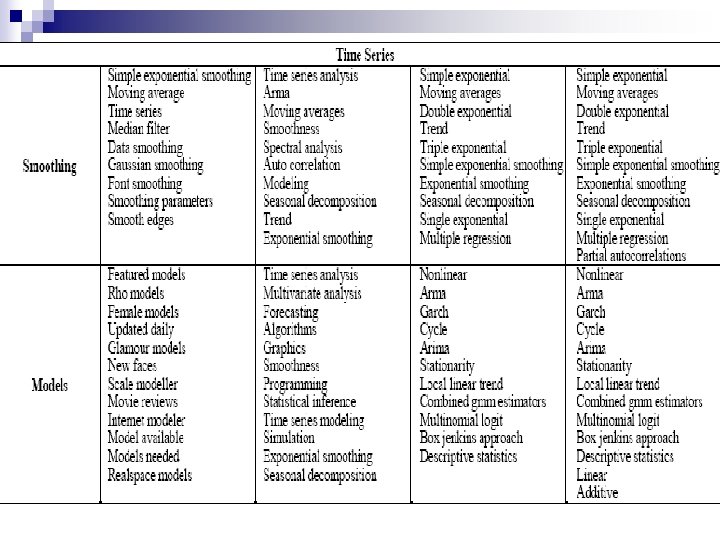
 Mine frequent occurring phrases: - Each piece of text extracted") Sub-Topic Discovery n 3) Mine frequent occurring phrases: - Each piece of text extracted in step 2 is stored in a dataset called a transaction set. - Then, an association rule miner based on Apriori algorithm is executed to find those frequent itemsets. In this context, an itemset is a set of words that occur together, and an itemset is frequent if it appears in more than two documents. - We only need the first step of the Apriori algorithm and we only need to find frequent itemsets with three words or fewer (this restriction can be relaxed).
Sub-Topic Discovery n 3) Mine frequent occurring phrases: - Each piece of text extracted in step 2 is stored in a dataset called a transaction set. - Then, an association rule miner based on Apriori algorithm is executed to find those frequent itemsets. In this context, an itemset is a set of words that occur together, and an itemset is frequent if it appears in more than two documents. - We only need the first step of the Apriori algorithm and we only need to find frequent itemsets with three words or fewer (this restriction can be relaxed).
 Eliminate itemsets that are unlikely to be sub-topics, and determine") Sub-Topic Discovery n 4) Eliminate itemsets that are unlikely to be sub-topics, and determine the sequence of words in a sub-topic. (postprocessing) n Heuristic: If an itemset does not appear alone as an important phrase in any page, it is unlikely to be a main sub-topic and it is removed.
Sub-Topic Discovery n 4) Eliminate itemsets that are unlikely to be sub-topics, and determine the sequence of words in a sub-topic. (postprocessing) n Heuristic: If an itemset does not appear alone as an important phrase in any page, it is unlikely to be a main sub-topic and it is removed.
 Rank the remaining itemsets. The remaining itemsets are regarded as") Sub-Topic Discovery n 5) Rank the remaining itemsets. The remaining itemsets are regarded as the sub-topics or salient concepts of the search topic and are ranked based on the number of pages that they occur.
Sub-Topic Discovery n 5) Rank the remaining itemsets. The remaining itemsets are regarded as the sub-topics or salient concepts of the search topic and are ranked based on the number of pages that they occur.
 Definition Finding n n n This step tries to identify those pages that include definitions of the search topic and its sub -topics discovered in the previous step. Preprocessing steps: Texts that will not be displayed by browsers (e. g. ,
Definition Finding n n n This step tries to identify those pages that include definitions of the search topic and its sub -topics discovered in the previous step. Preprocessing steps: Texts that will not be displayed by browsers (e. g. ,