7136acdfcb079a07e4ee71799f5b0752.ppt
- Количество слайдов: 84



CS 6633 資訊檢索 Information Retrieval and Web Search Lecture 3 Index construction 資電 125 Based on ppt files by Hinrich Schütze

Plan n Last lecture: n n Unix Python Hadoop, Map. Reduce, Lucene This time: n Index construction

Index construction n n How do we construct an index? What strategies can we use with limited main memory?

Our corpus for this lecture n Number of docs = n = 1 million n n Each doc has 1, 000 terms Each term appear 1 -2 times (1. 5 times) Number of distinct terms = m = 500 K 667 million postings entries

How many postings? n n Number of 1’s in the i th block = n J / i Summing this over m / J blocks, we have For our numbers, this should be about 667 million postings. My estimate n n n Each term appear 1 -2 times (1. 5 times) Distinct terms in each doc, roughly, 600 So, 600 x n or 600 million

Recall index construction n Documents are parsed to extract words and these are saved with the Document ID. Doc 1 I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me. Doc 2 So let it be with Caesar. The noble Brutus hath told you Caesar was ambitious

Key step n After all documents have been parsed the inverted file is sorted by terms. We focus on this sort step. We have 667 M items to sort.

Index construction n As we build up the index, cannot exploit compression tricks n n Parse docs one at a time. Final postings for any term – incomplete until the end. (actually you can exploit compression, but this becomes a lot more complex) At 10 -12 bytes per postings entry, demands 700 M x 10 bytes = 7 gigabytes
")
System parameters for design n Disk seek ~ 10 milliseconds (slow, so seek less) Block transfer from disk ~ 1 microsecond per byte (following a seek) (fast) All other ops ~ 10 microseconds (fast) n E. g. , compare two postings entries and decide their merge order

Bottleneck n n n Parse and build postings entries one doc at a time Now sort postings entries by term (then by doc within each term) Doing this with random disk seeks would be too slow – must sort N=667 M records If every comparison took 2 disk seeks, and N items could be sorted with N log 2 N comparisons, how long would this take?
 records (term, doc, freq).")
Sorting with fewer disk seeks n n 12 -byte (4+4+4) records (term, doc, freq). These are generated as we parse docs. Must now sort 667 M such 12 -byte records by term. Define a Block ~ 10 M such records n n n can “easily” fit a couple into memory. Will have 64 such blocks to start with. Will sort within blocks first, then merge the blocks into one long sorted order.

Sorting 64 blocks of 10 M records n First, read each block and sort within: n n n Quicksort takes 2 N ln N expected steps In our case 2 x (10 M ln 10 M) steps Exercise: estimate total time to read each block from disk and quicksort it. 64 times this estimate - gives us 64 sorted runs of 10 M records each. Need 2 copies of data on disk, throughout.

Merging 64 sorted runs n n Merge tree of log 264= 6 layers. During each layer, read into memory runs in blocks of 10 M, merge, write back. 1 2 3 1 4 2 3 Runs being merged. 4 Disk Merged run.

Merge tree … 1 run … ? 2 runs … ? 4 runs … ? 8 runs, 80 M/run 16 runs, 40 M/run 32 runs, 20 M/run Sorted runs. Bottom level of tree. … 1 2 63 64

Merging 64 runs n n Time estimate for disk transfer: 6 x (64 runs x 120 MB x 10 -6 sec) x 2 ~ 25 hrs. Disk block transfer time. Why is this an Overestimate? # Layers in merge tree Work out how these transfers are staged, and the total time for merging. Read + Write

Exercise - fill in this table Step 1 2 Read 2 sorted blocks for merging, write back 3 ? 64 initial quicksorts of 10 M records each Merge 2 sorted blocks 4 Add (2) + (3) = time to read/merge/write 5 64 times (4) = total merge time Time

Large memory indexing n n Suppose instead that we had 16 GB of memory for the above indexing task. Exercise: What initial block sizes would we choose? What index time does this yield? Repeat with a couple of values of n, m. In practice, spidering often interlaced with indexing. n Spidering bottlenecked by WAN speed and many other factors - more on this later.

Distributed indexing n For web-scale indexing: must use a distributed computing cluster n n Each can unpredictably slow down or fail How do we exploit such a pool of machines?

Distributed indexing n n Maintain a master machine directing the indexing job – considered “safe”. Break up indexing into sets of (parallel) tasks. n n n Document partition Dictionary partition Master machine assigns each task to an idle machine from a pool.

Parallel tasks n We will use two sets of parallel tasks n n n Parsers Inverters Break the input document corpus into splits n Each split is a subset of documents (document partition) Master assigns a split to an idle parser machine n Parser reads a document at a time and emits (term, doc) pairs n

Parallel tasks n n Parser writes pairs into j partitions Each for a range of terms’ first letters n n n Dictionary partition (e. g. , a-f, g-p, q-z) – here j=3. Now to complete the index inversion

Data flow assign Master assign Parser splits a-f g-p q-z Parser a-f g-p q-z Postings Inverter a-f Inverter g-p Inverter q-z
 pairs for a partition Sorts and writes")
Inverters n n Collect all (term, doc) pairs for a partition Sorts and writes to postings list Each partition contains a set of postings Similar to Hadoop and Map. Reduce

Dynamic indexing n Docs come in over time n n n postings updates for terms already in dictionary new terms added to dictionary Docs get deleted

Simplest approach n n Maintain “big” main index New docs go into “small” auxiliary index Search across both, merge results Deletions n n n Invalidation bit-vector for deleted docs Filter docs output on a search result by this invalidation bit-vector Periodically, re-index into one main index

Issue with big and small indexes n Corpus-wide statistics are hard to maintain n n Document frequencies Term weights Spelling correction Ignore the small index for such ordering Affect document ranking
 Exercise: Given")
Building positional indexes n n n Still a sorting problem (but larger) Exercise: Given 1 GB of memory, adapt the block merge described earlier

Building n-gram indexes n n n As text is parsed, enumerate n-grams. For each n-gram, need pointers to all dictionary terms containing it – the “postings”. Note that the same “postings entry” can arise repeatedly in parsing the docs – need efficient “hash” to keep track of this. n E. g. , that the trigram uou occurs in the term deciduous will be discovered on each text occurrence of deciduous
 pairs have been enumerated,")
Building n-gram indexes n n n Once all (n-gram term) pairs have been enumerated, sort ngram for inversion About 6 trigrams per term on average For a vocabulary of 500 K terms, this is about 3 million tngrams and pointers to postings Compress the dictionary Compress the postings

Index on disk vs. memory n n Most retrieval systems keep the dictionary in memory and the postings on disk Web search engines frequently keep both in memory n massive memory requirement n feasible for large web service installations n less so for enterprise application (internal use) where query loads are lighter

Indexing in the real world n Typically, don’t have all documents sitting on a local filesystem n n Documents need to be spidered Could be dispersed over a WAN with varying connectivity Have already discussed distributed indexers Could be (secure content) in n n Databases Content management applications Email applications Must schedule distributed spiders for Web documents

Content residing in applications n n Mail systems/groupware, content management contain the most “valuable” documents http often not the most efficient way of fetching these documents - native API fetching n n Specialized, repository-specific connectors These connectors also facilitate document viewing when a search result is selected for viewing

Secure documents n Each document is accessible to a subset of users n n n Usually implemented through some form of Access Control Lists (ACLs) Search users are authenticated Query should retrieve a document only if user can access it n n So if there are docs matching your search but you’re not privy to them, “Sorry no results found” E. g. , as a lowly employee in the company, I get “No results” for the query “salary roster”

Users in groups, docs from groups n Index the ACLs and filter results by them Documents Users n 0/1 0 if user can’t read doc, 1 otherwise. Often, user membership in an ACL group verified at query time – slowdown

“Rich” documents n How do we index images? n Content based retrieval: n n n “show me a picture similar to this orange circle” Not successful In practice, image search usually based on n meta-data such as file name e. g. , monalisa. jpg n Surrounding caption, text n New approaches exploit social tagging (e. g. , flickr. com)

Passage/sentence retrieval n n Suppose we want to retrieve not an entire document matching a query, but only a passage/sentence - say, in a very long document Can index passages/sentences as minidocuments – what should the index units be? n Store structured document in XML n New issue: XML search

How does Google index the Web? n For web-scale indexing: must use a distributed computing cluster (Hadoop) n Hadoop n n Cluster of over 1, 000 regular PCs Each can unpredictably slow down or fail Block of 64 M Instead of merge sort hashing or bucketing n n Arbitrary runs defined by hash(key) Eliminate log(N) layers

Parser: Tokenization

Tokenization n n Input: “Friends, Romans and Countrymen” Output: Tokens n n Each such token is now a candidate for an index entry, after further processing n n Friends Romans Countrymen Described below But what are valid tokens to emit?

Tokenization n Issues in tokenization: n Finland’s capital n Finland? Finlands? Finland’s? Hewlett-Packard Hewlett and Packard as two tokens? n n n State-of-the-art: break up hyphenated sequence. co-education ? the hold-him-back-and-drag-him-away-maneuver ? It’s effective to get the user to put in possible hyphens San Francisco: one token or two? How do you decide it is one token?

Numbers n n n 3/12/91 Mar. 12, 1991 55 B. C. B-52 My PGP key is 324 a 3 df 234 cb 23 e 100. 2. 86. 144 n Often, don’t index as text. n n n But often very useful: think about things like looking up error codes/stacktraces on the web (One answer is using n-grams: Lecture 3) Will often index “meta-data” separately n Creation date, format, etc.

Tokenization: Language issues n L'ensemble one token or two? n n n L ? L’ ? Le ? Want l’ensemble to match with un ensemble German noun compounds are not segmented n n Lebensversicherungsgesellschaftsangestellter ‘life insurance company employee’

Tokenization: language issues n Chinese and Japanese have no spaces between words: n n n 莎拉波娃现在居住在美国东南部的佛罗里达。 Not always guaranteed a unique tokenization Further complicated in Japanese, with multiple alphabets intermingled n Dates/amounts in multiple formats フォーチュン 500社は情報不足のため時間あた$500 K(約6, 000万円) Katakana Hiragana Kanji Romaji End-user can express query entirely in hiragana!
 is basically written right to")
Tokenization: language issues n n n Arabic (or Hebrew) is basically written right to left, but with certain items like numbers written left to right Words are separated, but letter forms within a word form complex ligatures. ﺍﺳﺘﻘﻠﺖ ﺍﻟﺠﺰﺍﺋﺮ ﻓﻲ ﺳﻨﺔ 2691 ﺑﻌﺪ 231 ﻋﺎﻣﺎ ﻣﻦ ﺍﻻﺣﺘﻼﻝ ﺍﻟﻔﺮﻧﺴﻲ ← → ←→ ← start ‘Algeria achieved its independence in 1962 after 132 years of French occupation. ’ With Unicode, the surface presentation is complex, but the stored form is straightforward

Normalization n Need to “normalize” terms in indexed text as well as query terms into the same form n n We most commonly implicitly define equivalence classes of terms n n e. g. , by deleting periods in a term Alternative is to do asymmetric expansion: n n We want to match U. S. A. and USA Enter: window Search: window, windows Enter: windows Search: Windows, windows Enter: Windows Search: Windows Potentially more powerful, but less efficient

Normalization: other languages n n Accents: résumé vs. resume. Most important criterion: n n n How are your users like to write their queries for these words? Even in languages that standardly have accents, users often may not type them German: Tuebingen vs. Tübingen n Should be equivalent

Normalization: other languages n n Need to “normalize” indexed text as well as query terms into the same form 7月30日 vs. 7/30 Character-level alphabet detection and conversion n n Tokenization not separable from this. Sometimes ambiguous: Morgen will ich in MIT … Is this German “mit”?

Case folding n Reduce all letters to lower case n exception: upper case (in mid-sentence? ) n n e. g. , General Motors Fed vs. fed SAIL vs. sail Often best to lower case everything, since users will use lowercase regardless of ‘correct’ capitalization…

Stop words n With a stop list, you exclude from dictionary entirely the commonest words. Intuition: n n n They have little semantic content: the, a, and, to, be They take a lot of space: ~30% of postings for top 30 But the trend is away from doing this: n n n Good compression techniques (lecture 5) means the space for including stopwords in a system is very small Good query optimization techniques mean you pay little at query time for including stop words. You need them for: n n n Phrase queries: “King of Denmark” Various song titles, etc. : “Let it be”, “To be or not to be” “Relational” queries: “flights to London”

Thesauri and soundex n Handle synonyms and homonyms n Hand-constructed equivalence classes n n n Rewrite to form equivalence classes Index such equivalences n n e. g. , car = automobile tank = M 1 = Abrams tank = acquarium color = colour When the document contains automobile, index it under car as well (usually, also vice-versa) Or expand query? When the query contains automobile, look under car as well
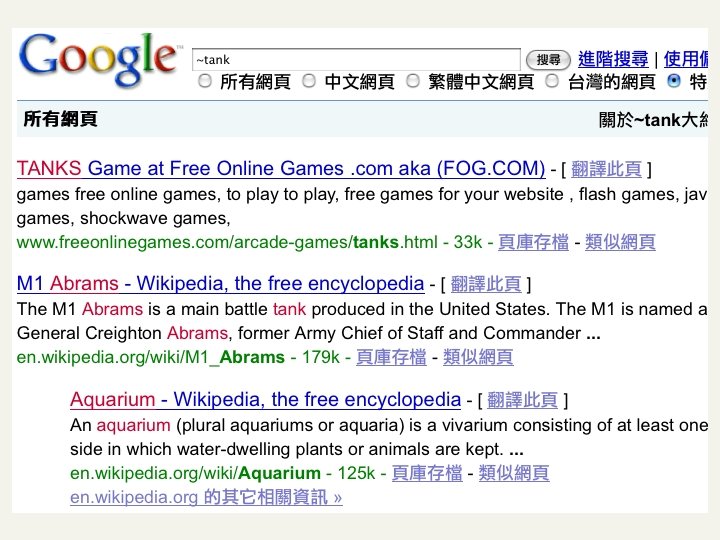

Soundex n Heuristics to expand a query into phonetic equivalents n n Language specific – mainly for names Pafnuty Lvovich Chebyshev was a Russian mathematician. His name can be alternatively transliterated as Chebychev, Chebyshov, Tchebycheff or Tschebyscheff

Lemmatization n n Reduce inflectional/variant forms to base form E. g. , n n am, are, is be car, cars, car's, cars' car the boy's cars are different colors the boy car be different color Lemmatization implies doing “proper” reduction to dictionary headword form

Stemming n n Reduce terms to their “roots” before indexing “Stemming” suggest crude affix chopping n n language dependent e. g. , automate(s), automatic, automation all reduced to automat. for example compressed and compression are both accepted as equivalent to compress. for exampl compress and compress ar both accept as equival to compress

Porter’s algorithm n Commonest algorithm for stemming English n n Results suggest at least as good as other stemming options Conventions + 5 phases of reductions n n n phases applied sequentially each phase consists of a set of commands sample convention: Of the rules in a compound command, select the one that applies to the longest suffix.

Typical rules in Porter n n n sses ss ies i ational ate tional tion Weight of word sensitive rules (m>1) EMENT → n n replacement → replac cement → cement

Other stemmers n Other stemmers exist, e. g. , Lovins stemmer http: //www. comp. lancs. ac. uk/computing/research/stemming/general/lovins. htm n n Single-pass, longest suffix removal (about 250 rules) Motivated by linguistics as well as IR Full morphological analysis – at most modest benefits for retrieval Do stemming and other normalizations help? n Often very mixed results: really help recall for some queries but harm precision on others

Language-specificity n Many of the above features embody transformations that are n n Language-specific and Often, application-specific These are “plug-in” addenda to the indexing process Both open source and commercial plug-ins available for handling these

Dictionary entries – first cut ensemble. french 時間. japanese MIT. english mit. german guaranteed. english entries. english sometimes. english tokenization. english These may be grouped by language (or not…). More on this in ranking/query processing.

Postings: Skip pointers

Recall basic merge n 2 Walk through the two postings simultaneously, in time linear in the total number of postings entries 8 2 4 8 16 1 2 3 5 32 8 64 17 21 128 Brutus 31 Caesar If the list lengths are m and n, the merge takes O(m+n) operations. Can we do better? Yes, if index isn’t changing too fast.
 128 16 2 4 8 16")
Augment postings with skip pointers (at indexing time) 128 16 2 4 8 16 32 n n 128 31 8 1 64 2 3 5 8 17 21 31 Why? To skip postings that will not figure in the search results. How? Where do we place skip pointers?

Query processing with skip pointers 128 16 2 4 8 16 32 128 31 8 1 64 2 3 5 8 17 21 31 Suppose we’ve stepped through the lists until we process 8 on each list. When we get to 16 on the top list, we see that its successor is 32. But the skip successor of 8 on the lower list is 31, so we can skip ahead past the intervening postings.

Where do we place skips? n Tradeoff: n n More skips shorter skip spans more likely to skip. But lots of comparisons to skip pointers. Fewer skips few pointer comparison, but then long skip spans few successful skips.

Placing skips n n Simple heuristic: for postings of length L, use L evenly-spaced skip pointers. This ignores the distribution of query terms. Easy if the index is relatively static; harder if L keeps changing because of updates. This definitely used to help; with modern hardware it may not (Bahle et al. 2002) n The cost of loading a bigger postings list outweighs the gain from quicker in memory merging

Spelling correction
 being indexed Retrieve")
Spell correction n Two principal uses n n n Correcting document(s) being indexed Retrieve matching documents when query contains a spelling error Two levels: n Isolated word: Check each word on its own for misspelling n n Will not catch typos resulting in correctly spelled words e. g. , from form Context-sensitive: Look at surrounding words n E. g. , I flew form Heathrow to Narita.

Document correction n Primarily for OCR’ed documents n n n Correction algorithms tuned for this Goal: the index (dictionary) contains fewer OCRinduced misspellings Can use domain-specific knowledge n E. g. , OCR can confuse O and D more often than it would confuse O and I (adjacent on the QWERTY keyboard, so more likely interchanged in typing).

最新的網路語料庫的研究 Source: Computational Linguistics, 2006, September 2006, Vol. 32,

OCR造成網路錯字,但也提供了 OCR後修正的研發資源! n 錯字更正舉例 n Cbmpany company n n Co rnpany company 利用網路語料庫 Web as Corpus 1. 字典 2. 錯誤規則 3. Google 搜尋 An /SO-9001 Cbmpany ------------------------------------------國暮電子股份有限公司 Wn市300科學 業園憂新安路 5號 5樓之' 電話: r 03)578 -4975分機: 601 電子郵件-simpson. jean@ambit. com. tw 傳真: (03)577 -5100 統一編號: 22099723 通訊事業 特別助理 簡 金 倉

步驟一:字典 n 有相當多的 Open Source 辭典 n n Word. Net CMU 人名清單 國立編譯館百科分類術語 Google Web 1 T Ngram (1 -5字) n 對與錯字並呈 GOOGLE 1 T N-gram Sample (辭典字及變化形) Word companionable companionate companioned companioning companionships companionway Freq 32359 6456 3630 2137 1621810 575439 5248 21877 company 1548816 61 companying compaq comparabilities comparability comparable comparatives compared 6918 1148153 660 467735 6918309 4365158 43651 54954087 32359365

步驟二: OCR 錯誤改正規則 o b
 n 寫一個機器人程式查詢 Google 或 使用 Web 1")
步驟三: 查詢 Cornpany (26, 200 / 281) n 寫一個機器人程式查詢 Google 或 使用 Web 1 T N-grams GOOGLE 1 T N-gram Sample (不列入辭典的錯字) Word Freq cornovaglia cornp 331 245 cornpany 281 cornparables cornpared cornpickers cornpipe cornplete cornponeflicks 4897 234 338 301 416 275 6456 467

結果:網路探勘建立優序錯字勘誤表

Query mis-spellings n Our principal focus here n n E. g. , the query Alanis Morisett We can either n n Retrieve documents indexed by the correct spelling, OR Return several suggested alternative queries with the correct spelling n Did you mean … ?

Isolated word correction n n Fundamental premise – there is a lexicon from which the correct spellings come Two basic choices for this n A standard lexicon such as n n n Webster’s English Dictionary An “industry-specific” lexicon – hand-maintained The lexicon of the indexed corpus n n n E. g. , all words on the web All names, acronyms etc. (Including the mis-spellings)

Isolated word correction n Given a lexicon and a character sequence Q, return the words in the lexicon closest to Q What’s “closest”? Several alternatives n n n Edit distance Weighted edit distance n-gram overlap

Edit distance n n Given two strings S 1 and S 2, the minimum number of basic operations to covert one to the other Basic operations are typically character-level n n n Insert Delete Replace E. g. , the edit distance from cat to dog is 3. Generally found by dynamic programming.

Edit distance n n n Also called “Levenshtein distance” See http: //www. merriampark. com/ld. htm for a nice example plus an applet to try on your own Seehttp: //www. norvig. com/spell-correct. html

Peter Norvig’s Spelling Corrector n n n People were amazed at how Google does spelling correction so well and quickly. People do not have good intuitions about statistical language processing problems and could benefit from an explanation Norvig wrote a toy spelling corrector (on the plane) n n n 21 lines of Python code 80 or 90% accuracy, 10 words per second An industrial-strength spell corrector like Google's is more complicated but the principle is the same
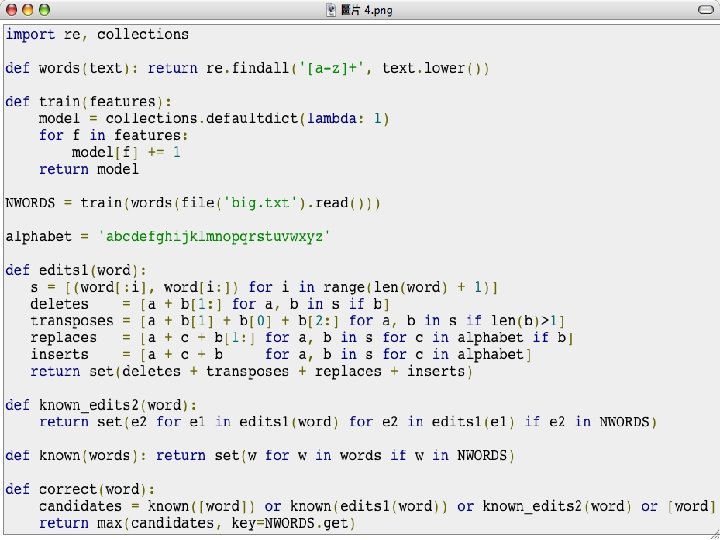
: # model = collections. defaultdict(lambda: 1) # for f in features:")
# def train(features): # model = collections. defaultdict(lambda: 1) # for f in features: # model[f] += 1 # return model # NWORDS = train(words(file('big. txt'). read())) NWORDS = {} for word in features: try: NWORDS[word] =+ 1 except Key. Error: NWORDS[word] = 1
 'spelling' >>> correct('korrecter') 'corrector'")
n n >>> correct('speling') 'spelling' >>> correct('korrecter') 'corrector'

Resources n MG Chapter 5
7136acdfcb079a07e4ee71799f5b0752.ppt