5ed07b6a00e4c66c6d6fff4db33b36bc.ppt
- Количество слайдов: 26



Combining Speech Attributes for Speech Recognition Jeremy Morris November 9, 2006
 ► Conditional Random Fields ► Experiments & Results ►")
Overview ► Problem Statement (Motivation) ► Conditional Random Fields ► Experiments & Results ► Future Work

Problem Statement ► Developed as part of the ASAT Project § Automatic Speech Attribute Transcription § Project to build tools to extract and parse speech attributes from a speech signal ► Goal: Develop a system for bottom-up speech recognition using 'speech attributes'

Speech Attributes? ► Any information that could be useful for recognizing the spoken language § Phonetic attributes ►Consonants have manner, place of /d/ manner: stop place of artic: articulation, dental voicing: voiced voicing ►Vowels have height, frontness, roundness, tenseness ►Speaker attributes (gender, /ae/ etc. ) age, /iy/ height: low § Anyfrontness: high other useful attributes that could/t/ used be frontness: front manner: stop roundness: nonround of artic: dental for speech recognition place tenseness: tense voicing: unvoiced
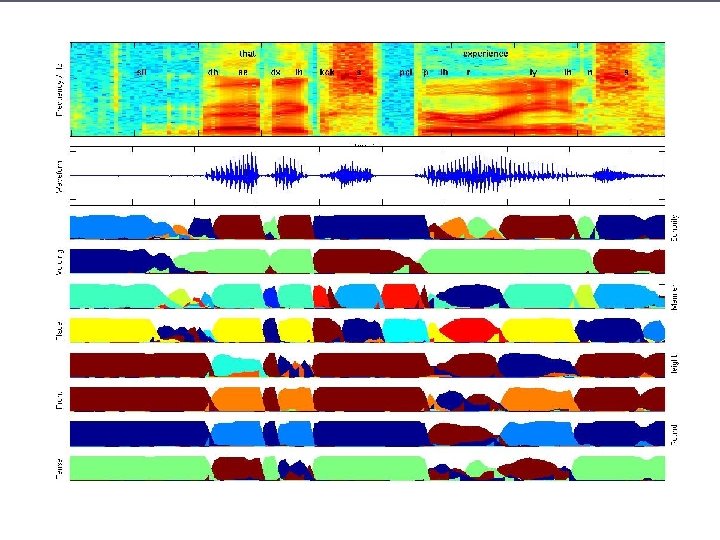

Feature Combination ► Our piece of this project is to find ways to combine speech attributes together and use them to recognize language § Other groups are working on finding features to extract and methods of extracting them § Note that there is no guarantee that attributes will be independent of each other § In fact, many attributes will be strongly correllated or dependent on other attributes ►e. g. voicing for vowels

Evidence Combination ► Two hyp basic ways to build hypotheses Bottom Up Top Down hyp Generate a the data Examine hypothesis Searchiffor a data fits See the hypothesis the that fits hypothesis data
 P(X|/iy/) Automated Speech Recogintion Systems (ASR) use")
Top Down ► Traditional /iy/ X P(/iy/) P(X|/iy/) Automated Speech Recogintion Systems (ASR) use a topdown approach § Hypothesis is the phone we are predicting § Data is some encoding of the acoustic speech signal § A likelihood of the signal given the phone label is learned from data § A prior probability for the phone label is learned from the data § These are combined through Bayes Rule to give us the posterior probability P(label | data)

Bottom Up ► Bottom-up models have the same high-level goal – determine the label from the observation /iy/ P(/iy/|X) § But instead of a likelihood, the posterior probability P(label | data) is learned directly from the data ► Neural Networks can be used to learn probabilities in this manner X

Speech is a Sequence /k/ ► Speech /k/ /iy/ is not a single, independent event § It is a combination of multiple events over time ►A model to recognize spoken language should take into account dependencies across time

Speech is a Sequence /k/ /iy/ X X X ►A top down model can be extended into a time sequence as a Hidden Markov Model (HMM) § Now our likelihood of the data is over the entire sequence instead of a single phone

Conditional Random Fields ►A form of discriminative modelling § Has been used successfully in various domains such as part of speech tagging and other Natural Language Processing tasks ► Processes evidence bottom-up § Combines multiple features of the data § Builds the probability P( sequence | data)

Conditional Random Fields ► Conceptual Overview § Each attribute of the data we are trying to model fits into a feature function that associates the attribute and a possible label ►A ►A positive value if the attribute appears in the data zero value if the attribute is not in the data § Each feature function carries a weight that gives the strength of that feature function for the proposed label ► High positive weights indicate a good association between the feature and the proposed label ► High negative weights indicate a negative association between the feature and the proposed label ► Weights close to zero indicate the feature has little or no impact on the identity of the label

Conditional Random Fields /k/ /iy/ X X X ► CRFs have transition feature functions and state feature functions § Transition functions add associations between transitions from one label to another § State functions help determine the identity of the state

Conditional Random Fields Transition Feature Function Transition Feature Weight Function State Feature Weight Association Indicates the strengthof an attribute with a Association of Indicates the strength of the phone-to-phone transition the phone label association of this attribute association ofathis attribute withe. g. f(P(stop), /k/) this with this label e. g. g(attr, /iy/, /k/) transition

Experiments ► Goal: Implement a Conditional Random Field Model on speech attribute data § Perform phone recognition § Compare results to those obtained via a Tandem system ► Experimental Data § TIMIT read speech corpus § Moderate-sized corpus of clean, prompted speech, complete with phonetic-level transcriptions

Attribute Selection ► Attribute Detectors § Built using ICSI Quick. Net Neural Network software ► Two different types of attributes § Phonological feature detectors ► Place, Manner, Voicing, Vowel Height, Backness, etc. ► Features are grouped into eight classes, with each class having a variable number of possible values based on the IPA phonetic chart § Phone detectors ► Neural networks output based on the phone labels – one output per label § Classifiers were trained on 2960 utterances from the TIMIT training set ► Uses extracted 12 th order PLP coefficients (i. e. frequency coefficients) in a 9 frame window as inputs to the neural networks
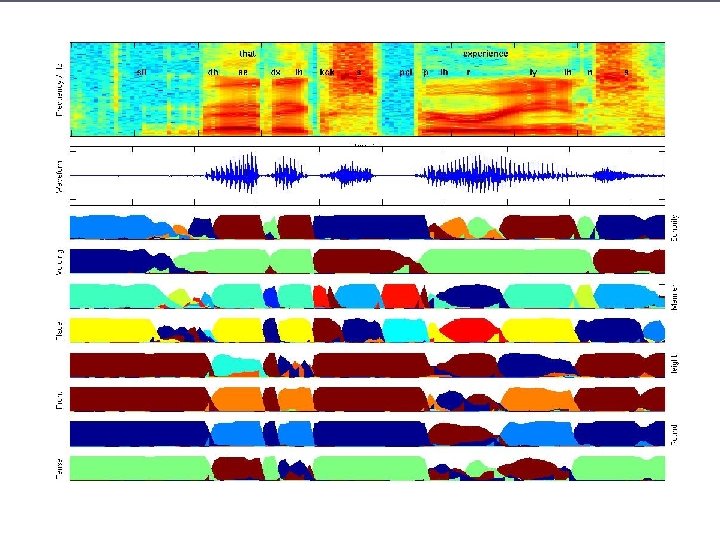

Experimental Setup ► Code built on the Java CRF toolkit on Sourceforge § http: //crf. sourceforge. net § Performs training to maximize the log-likelihood of the training set with respect to the model ►Does this via gradient descent – find the place where the gradient of the log-likelihood function goes to zero

Experimental Setup ► Output from the Neural Nets are themselves treated as feature functions for the observed sequence § Each attribute/label combination gives us a value for one feature function ► We also use a bias feature for each label § Currently, all combinations of features and labels are used as feature functions ► e. g. f(P(stop), /t/), f(P(stop), /ae/), etc. § Phone class features are used in the same manner ► e. g f(P(/t/), /ae/), etc. § Transition features use only a 0/1 bias feature ► 1 if the transition occurs at that timeframe in the training set ► 0 if the transition does not occur at that timeframe in the training set ► For comparison purposes, we compare to a baseline HMMtrained system that uses decorrellated features as inputs
 triphones Phone Recog Accuracy 67. 32% CRF")
Initial Results Model Label Space HMM (phones) triphones Phone Recog Accuracy 67. 32% CRF (phones) monophones 67. 27% HMM (features) triphones 66. 69% CRF (features) monophones 65. 25% HMM (phones/feas) (top 39) CRF (phones/feas) triphones 67. 96% monophones 68. 00%

Experimental Setup ► Initial CRF experiments show results comparable to triphone HMM results with only monophone labelling § No decorrellation of features needed § No assumptions about feature independence ► Comparison to HMM crippled in one way: § HMM training allowed for shifting of phone boundaries during training § CRF training used set phone boundaries for all training ► Another experiment – train the CRF, realign training labels, then retrain on realigned labels
 triphones Phone Recog Accuracy 67. 32% CRF")
Realignment Results Model Label Space HMM (phones) triphones Phone Recog Accuracy 67. 32% CRF (phones) base monophones 67. 27% CRF (phones) realign monophones 69. 63% HMM (features) triphones 66. 69% CRF (features) base monophones 65. 25% CRF (features) realign monophones 67. 52%

Experimental Setup ► CRFs can also make use of features on the transitions § For the initial experiments, transition feature functions only used bias features (e. g. 1 or 0 based on label in the training corpus) ► What if the phone classifications were used as the state features, and the feature classes were used as transition features? § Linguistic observation – feature spreading from phone to phone
 base monophones Phone Recog Accuracy 67. 27%")
Realignment Results Model Label Space CRF (phones) base monophones Phone Recog Accuracy 67. 27% CRF (phones) realign monophones 69. 63% CRF (features) base monophones 65. 25% CRF (features) realign monophones 67. 52% CRF (p+f) base monophones 68. 00% CRF (p + trans f) base monophones 69. 49% CRF (p + trans f) align monophones 70. 86%

Discussion & Future Work ► This seems to be a good model for the type of feature combination we want to perform § Makes use of arbitrary, possibly correllated features § Results on phone recognition task comparable or superior to the alternative sequence model (HMM) ► Future Work § New features ► What kinds of features can we add to improve our transitions? ► We hope to get more from the other research groups § New training methods ► Faster algorithms than the gradient descent method exist and need to be tested § Word recogntion ► We are thinking about how to model word recogntion in this framework § Larger corpora ► TIMIT is a comparably small corpus – we are looking to move to something bigger
5ed07b6a00e4c66c6d6fff4db33b36bc.ppt