1146457d23682c412ae73ba7b511c6b6.ppt
- Количество слайдов: 35



Chapter 9 Distributed File Systems: case studies • NFS - Network File System • AFS - Andrew File System • Coda - COnstant Data Availability • COSMOS - Scalable Single-image File System (i. e. , S 2 FS)

9. 2 AFS: Andrew File System • Introduction to AFS - originally a research project at CMU leaded by Satyanarayanan - now a commercial product from Transarc >> DFS and Coda are all decedents of AFS, now DFS has become an important component of DCE, and Coda is still an ongoing project - design goal >> a single, scalable world-wide filesystem >> compatible with UNIX >> location-independent name space >> fault-tolerance >> good performance comparable to traditional time-sharing system

• Unusual Features of AFS - whole-file transfers & whole-file are cached >> don’t divide into blocks or chunks >> exception: divide huge files into huge chunks(64 k bytes) - files cached on client’s disk >> client cache large, perhaps several Gig today - to achieve best approximation to one-copy file semantics >> AFS 1. 0: session semantics using timestamp-based mechanism » after a successful open: latest(F, S) » after a successful close: update(F, S) >> AFS 2. 0: weaker session semantics using callback-based mechanism » after a successful open: latest(F, S, 0) or (lost. Callback(S, T) and in Cache(F) and latest(F, S, T)) where T is a system constant representing the interval at which callback promises must be renewed.

• Structure of AFS Client machine Application program Server machine AFS client “Venus” AFS server “Vice” RPC System call interception OS kernel Local file system

• Design and implementation of AFS - Vice & Venus are user-level processes and make use of a nonpreemptive threads package >> internally, files identified by 96 -bit Ids 32 bits Volume number File handle Uniquifier >> directory info is stored in flat filesystem implemented by Vice >> software(set of Venus processes) provides hierarchical view to users - design based on the hope that files will migrate to the desktops of people who use them >> if sharing is rare, almost all accesses will be local

• Cache Coherency in AFS - Key mechanism: callback promise >> represents server’s commitment to tell client when client’s copy become obsolete » granted to client when client gets copy of file » once exercised by server, callback promise vanishes >> fault-tolerance » on client reboot, client discards callback promises » server must remember promises it made, even if server crashes - client checks for callback promise only when file is opened - when writing, new version of file made visible to the world only on file close - result: “funny” sharing semantics >> opening file gets current snapshot of file >> closing file creates a new version >> concurrent write-sharing leads to unexpected results

• AFS performance - works very well in practice - the only known file system that scales to thousands of machine - whole-file caching works well - callbacks more efficient than the repeated consistency checking of NFS

9. 3 Coda: file system for disconnected operation • Introduction to Coda - observation >> AFS client often goes a long time without communicating with servers - Why not use an AFS-like implementation when disconnected from the network? >> on an airplane >> at home >> during network failure - Coda tries to do this - problem: how to get work done when server not available? >> AFS does a decent job already >> let user make a list of files to keep around >> somehow have system learn which files user tends to use >> replicate servers

• Server replication - Namespace divided into volumes - Volumes have replicas on different servers - Volume storage group(VSG) is set of servers with the volume - For performance, cache files on local disk - Server call-back breaks for consistency(cache invalidation) • Disconnected operation - When no servers in VSG are available - Rely on local cache while disconnected - Emulate servers on client - Cache misses become failures - Reintegrate when server becomes available

• For scalability - Callback cache coherence mechanism - Whole-file caching • Whole-file caching - Can be wasteful - Useful for disconnected computing - Failures are at open() granularity, not by blocks - Simpler failure scenarios • Claims - Users are good at predicting future needs - Voluntary and involuntary disconnections are similar enough to use the same techniques

• First- and second-class replicas - With disconnected computing, why replicate servers? - Server replicas are safer and more accurate - Disconnection is a measure of last resort - Replicas reduce the need for disconnection - How true is this? >> Maybe link failures are more common >> You’re spelunking or otherwise out of touch - Server replication costs a lot • Hoarding - In preparation for disconnection - Prioritize files to cache - Hoard profiles have explicit information - Recent references provide implicit information - Treatment of callback breaks >> Purge files and symbolic links at call-back break >> Re-fetch file at next reference >> Mark directory as “suspicious” but available

• Cache coherence for disconnected computing - Pessimistic >> Disallow conflicting operations >> May make file unavailable for a long time - Optimistic(their choice) >> Allow conflicting updates >> Great availability >> Detect conflicts >> Resort to manual resolution when necessary >> This is okay when little write-sharing - problem: how to keep disconnected versions consistent? >> what if two disconnected users write the same file at the same time » can’t use callback promises, since communication is impossible >> or, what if a write makes a disconnected version obsolete » can’t prevent this either

• Cache conflicts - Strategy >> hope it doesn’t happen >> if it happens, hope it doesn’t matter - if it does happen, try to patch things up automatically >> see the example in next page - if all else fails, ask user what to do - amazing fact: unfixable conflicts almost never happen >> typical user can go months without seeing an unfixable conflict - so Coda works wonderfully >> but : are workloads changing? - Can use these observations to improve AFS >> exercise callback promises lazily >> keep working despite network failures
 - CVV(Coda version vector) >> Example: Clients C 1")
- AVSG(available volume storage group) - CVV(Coda version vector) >> Example: Clients C 1 & C 2 use file F replicated at servers S 1, S 2, and S 3 VSG = {S 1, S 2, S 3}, AVSG[c 1] = {S 1, S 2}, AVSG[c 2] = {s 3} 1、initially, CVV[s 1]=CVV[s 2]=CVV[s 3]=(1, 1, 1) 2、C 1: open(F), write(F), close(F). CVV[s 1]=CVV[s 2]=(2, 2, 1) CVV[s 3]=(1, 1, 1) 3、C 2: open(F), write(F), close(F). CVV[s 1]=CVV[s 2]=(1, 1, 1) CVV[s 3]=(1, 1, 2) 4、AVSG[c 2]: {s 3}=>{s 1, s 2, s 3}, C 2 find: CVV[s 1]=CVV[s 2]=(2, 2, 1) && CVV[s 3]=(1, 1, 2), a conflict occurs! 3、AVSG[c 2]: {s 3}=>{s 1, s 2, s 3}, C 2 find: CVV[s 1]=CVV[s 2]=(2, 2, 1) && CVV[s 3]=(1, 1, 1), can be patched up automatically!

9. 4 COSMOS: Scalable Single-image file system • • • Research background COSMOS: a cluster file system Cooperative cache management in COSMOS Experimental results Summary
 User Interface JMS SEPS Job Management")
Dawning Superserver Architecture KISS (Keep it simple, scalable) User Interface JMS SEPS Job Management System Single Entry Point System CSMS cosmos Cluster Systems Management System Cluster File System AIX Operating System Power. PC Nodes PVM, MPI, NX BCL RMS PPE Basic Resource Parallel Communication Management Programming Library System Environment Communication Device Drivers Power. PC Nodes High-Speed Networks Power. PC Nodes

Objectives and Goals Objectives: • Design a Scalable Single-image File System for Dawning Superserver Goals: • • • Binary compatibility Strict UNIX semantics High I/O performance High scalability Without kernel code modification

Design Methods • Using cooperative caching to improve I/O performance • Using parallel and distributed meta-data management and disk I/O to gain high scalability • Using Vnode/VFS interface to comply with Unix file system • Using a token-based coherency protocol for strict Unix semantics

The Structure of COSMOS

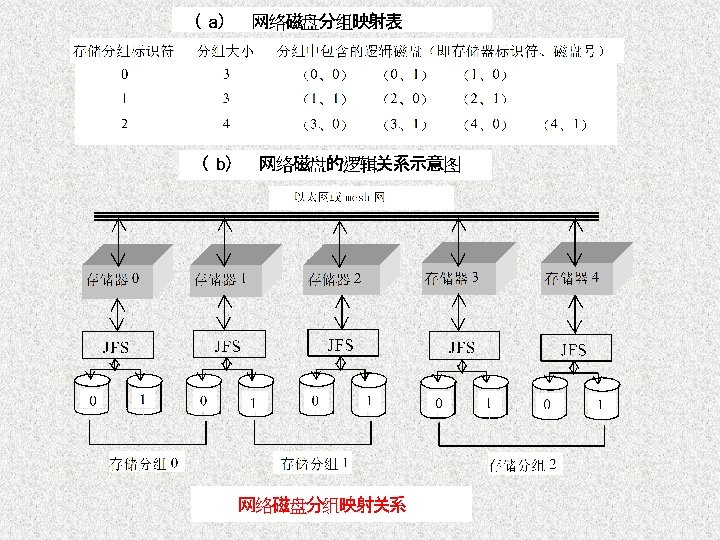
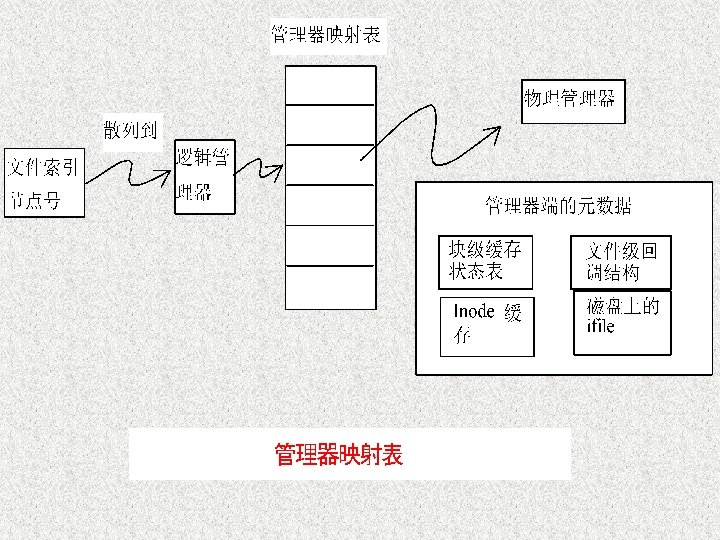
Another system view Application syscall nfs Vnode/VFS Remote cache jfs Client COSMOS’s kernel extension Shared cache Message queue Client networks Manager Cache state Metadata & directory Storager Data storage stripe
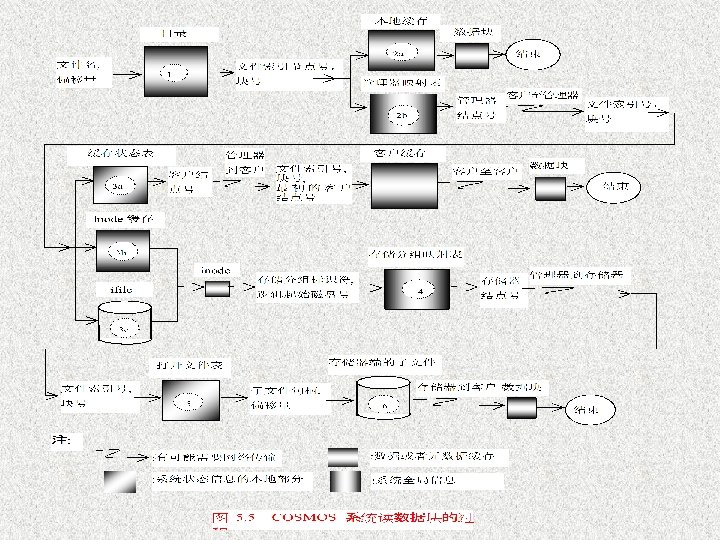

Cooperative Caching Client 1 read the first two blocks of file 1: f 1 b 0 and f 1 b 1 :req :ack :data Manager 2. 2 2. 1 1 Storager 4 Client 1 3. 2 disk f 1 b 1 Client 2 local cache remote cache f 1 b 0

Dual-Granularity Coherence Protocol Client state transitions at file granularity level not opened no callback 7 5 3 17 9 write-opened No callback 4 6 read-opened no callback 10 21 14 8 2 1 13 write-callback 11 16 read-callback 12 19 20 15 18
")
Dual-granularity Coherence Protocol Client state transitions at block granularity level no cache ( invalid) 2 1 14 Cached Read-token Clean 5 4 8 9 15 7 Cached Read-token Dirty 12 13 6 3 Cached Write-token Clean 10 11 Cached Write-token Dirty 16

Dual-granularity I/O Operation read operation under dual-granularity and single-granularity, here C represents the only client that has opened the read file 3 S 1 C 5 4 1 2 M (1): read request; (2): forward-data request; (3): forwarding data; (4): notify M that C has received data; (5): grant C a read-token. (a) single-granularity S 2 C 3 M (1): read request; (2): acknowledgement of read request; (3): tell M the event that C has just issued a read request. ( b) dual-granularity

Dual-granularity I/O Operations file flush under single-granularity and dual-granularity (when C is the only client who has opened the flushed file) 1 C M 2 3 4 C 1 S S Comment: (1): file flush request; (2): flush data request; (3): flush data request; (4): acknowledgement of flush data request. (a) single-granularity (b) dual-granularity

N-Chance Algorithm Main idea: • preferentially cache singlets and avoid duplicates Drawbacks: • the client must contact manager unless the displaced block is a a singlet forwarded from another client; • forward all the singlets; • random forward and doesn’t utilize the peers’ file access patterns

Enhanced N-Chance Algorithm Assume: client X decides to replace its ith cached block, bxi, and bxi belongs to file F, then bxi’s status may be : A: bxi is one of the singlet forwarded from another client; B: There’s no client using file F (i. e. no client has opened F); C: F has been opened by at least one client: C. 1: Only client X has opened F; C. 2: There is at least one remote client that has opened F;

Experimental results Performance comparison for the two protocols when running 2 clients using Andrew Benchmark

Experimental results I/O Bandwidth & scalability

Experimental results Comparison of NFS & COSMOS with Andrew benchmark

Summary • Reducing client-server communication and the number of disk accesses is critical for I/O scalability; • Cooperative caching reduces the number of network hops and disk accesses considerably, however, the network must be used to maintain cache coherence; • the dual-granularity approach is a new method to further reduce the server-end load and network communication.

In next class we’ll discuss: Chapter 10 Distributed Shared Memory That’s it, Thanks for your attention!
1146457d23682c412ae73ba7b511c6b6.ppt