4131b3db9aff24a0071ec321e44041c6.ppt
- Количество слайдов: 14



CBio. C: Massive Collaborative Curation of Biomedical Literature Future Directions

Recap: The Problem l Curation of “knowledge” nuggets from Biomedical articles. l l l About 15 million abstracts in Pubmed 3 million published by US and EU researchers during 1994 -2004 (800 articles per day) 300 K articles published so far reporting protein-protein interactions in human, yeast and mouse. l BIND (in 7 yrs) -- 23 K ; DIP – 3 K; MINT – 2. 4 K.

Recap: our proposed solution l l Harness available human power: scientists around the world Seamlessly provide curation platform (webbased) to pop up while they research Even a little input from each counts Collaborators get immediate rewards
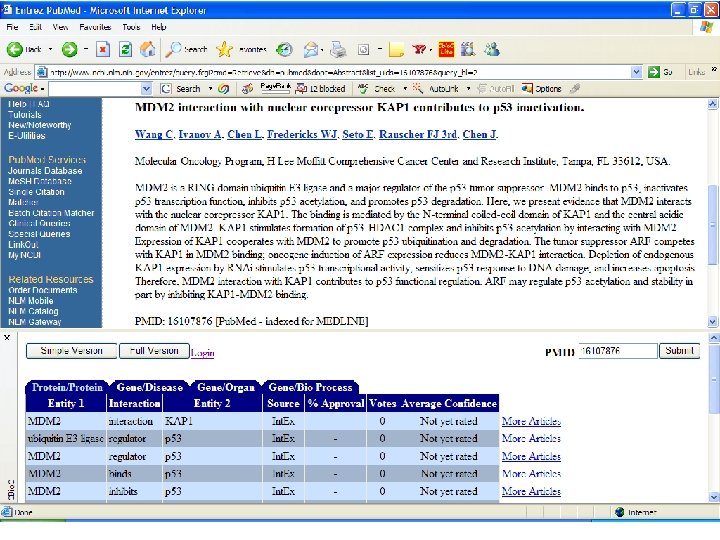
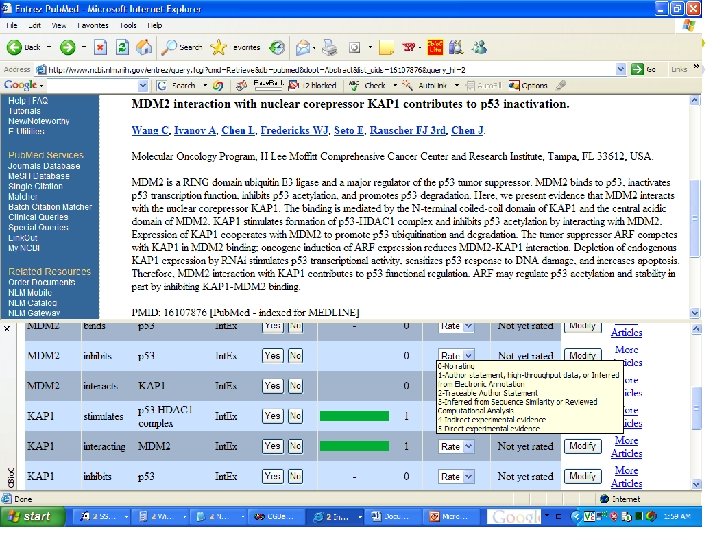
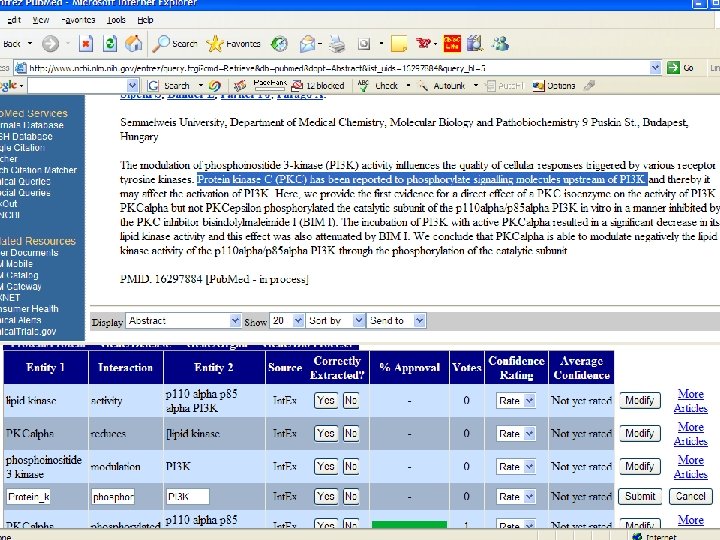
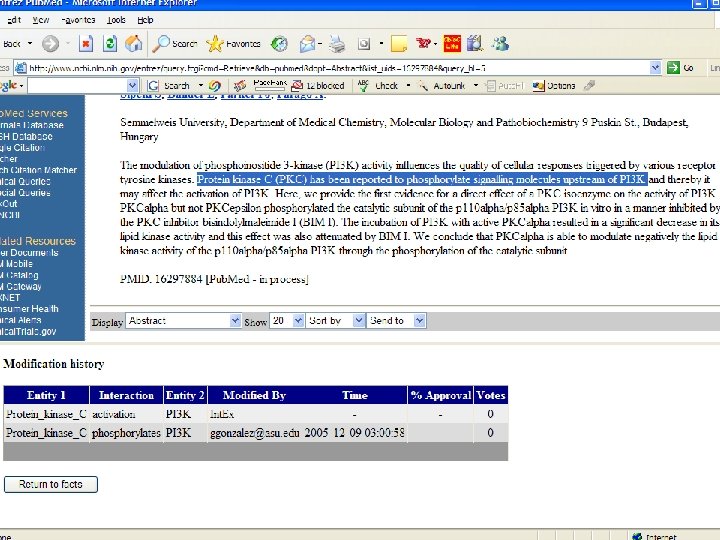
 Have")
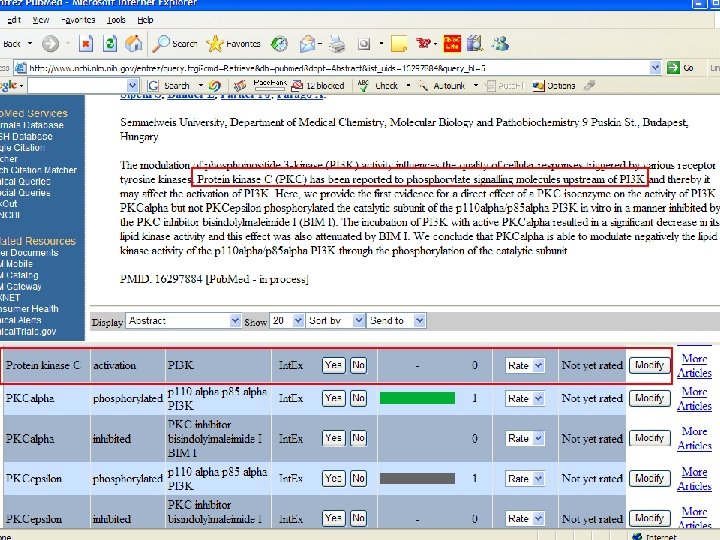
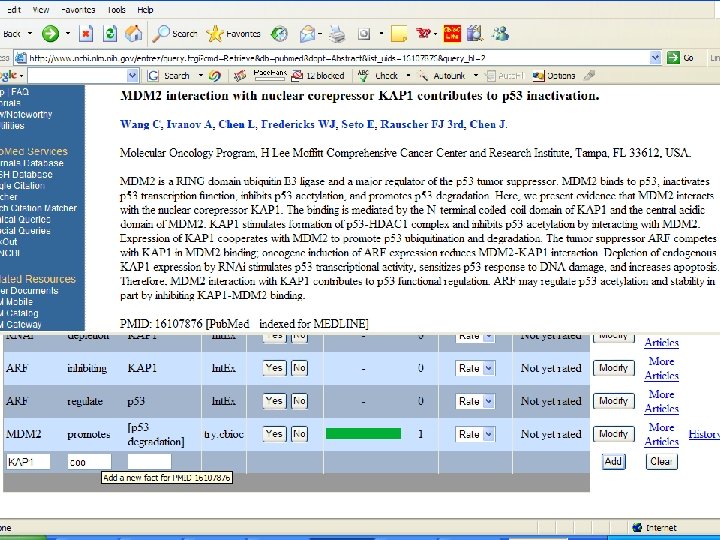
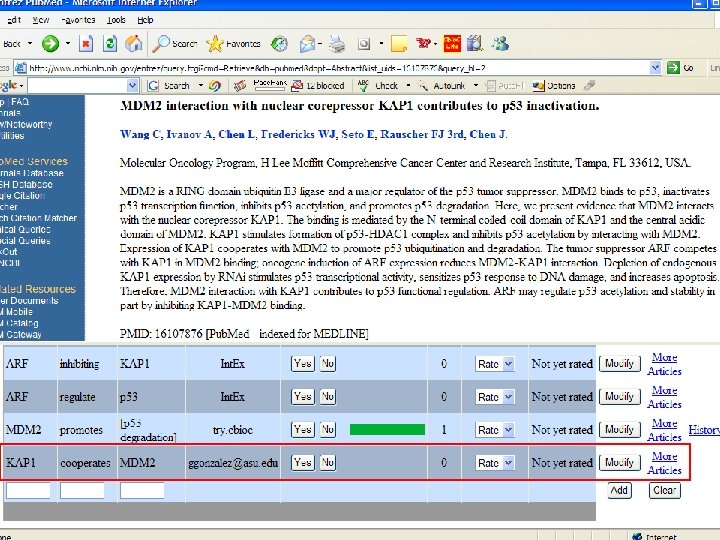
Future work & projects Extraction of other relationships (gene-disease, gene-organ. . . ) Have prototype in related project, need improvement and formal testing (measuring accuracy) Extraction of organism info for each entity in a relationship High-priority. Use existing software for extraction, but need to use biological databases and algorithms for deducing info (not explicit), and allow users to correct this info. Example, PMID 16107876. Use ontologies and some automated tools to ensure consistency and cross-link info 2 people. Information entered by users needs to be validated against existing DB & ontologies. Also, need to tag our data for cross-reference. Example
 Support query processing in CBio. C at a basic")
Future work & projects (2) Support query processing in CBio. C at a basic level Users want/need to access the facts directly, not only “related articles” but facts about a specific vote patterns, entities, etc. Incorporate data from other interaction databases Done for one (BIND), but needs to be revamped to include other databases & left semi-automatized for updates Integrate CBio. C data w/ other Allow users to transparently access and traditionally curated databases query all the biological interaction databases. Need to map schemas, select appropriate sources “on the fly”, and provide provenance explanation on query results.
 Image extension - extracts images & information about images")
Future work & projects (3) Image extension - extracts images & information about images and allows collaborative curation. Take PDFs & other structured documents, and extract images with their captions & references within the text, then let users polish. Related. Develop adaptable software platform for similar applications. This is to be a flexible (adaptable) system that users can “generate” online for their own scientific needs. A “non-scientific” example. Curating & representing pathways: linking related facts There are others that have done representation, but need to design & implement UI consistent w/ CBio. C for curation. Example.
 Recommender system that uses data from “user network” (votes,")
Future work & projects (4) Recommender system that uses data from “user network” (votes, authors, etc) Have a related project that recommends, but need to take advantage of CBio. C’s data. Handle incomplete data in CBio. C Data obtained from text extraction or data integration is inherently incomplete. Here, we seek to predict missing values –using domain knowledge- and process queries even w/ the incomplete data Handle uncertain data in CBio. C Associate confidence levels to all the facts curated by CBio. C based on user trustworthiness and use these appropriately while processing user queries. Support advanced query processing UI to allow uncertainty & incompletness handling features described above.
4131b3db9aff24a0071ec321e44041c6.ppt