

 C E N T R E F O R I N T E G R A T I V E B I O I N F O R M A T I C S V U Introduction to bioinformatics Lecture 2 Genes and Genomes
C E N T R E F O R I N T E G R A T I V E B I O I N F O R M A T I C S V U Introduction to bioinformatics Lecture 2 Genes and Genomes
 Organisational • Course website: http: //ibi. vu. nl/teaching/mnw_2 year/mnw 2_2008. php or click on http: //ibi. vu. nl (>teaching >Introduction to Bioinformatics) • Course book: • Bioinformatics and Molecular Evolution by Paul G. Higgs and Teresa K. Attwood (Blackwell Publishing), 2005, ISBN (Pbk) 1 -4051 -0683 -2 • Essential Bioinformatics by Jin Xiong, Cambridge University Press, 2006, ISBN 0521840988 • Lots of information about Bioinformatics can be found on the web.
Organisational • Course website: http: //ibi. vu. nl/teaching/mnw_2 year/mnw 2_2008. php or click on http: //ibi. vu. nl (>teaching >Introduction to Bioinformatics) • Course book: • Bioinformatics and Molecular Evolution by Paul G. Higgs and Teresa K. Attwood (Blackwell Publishing), 2005, ISBN (Pbk) 1 -4051 -0683 -2 • Essential Bioinformatics by Jin Xiong, Cambridge University Press, 2006, ISBN 0521840988 • Lots of information about Bioinformatics can be found on the web.
 DNA sequence. . . acctc ctgtgcaaga acatgaaaca nctgtggttc tcccagatgg gtcctgtccc aggtgcacct gcaggagtcg ggcccaggac tggggaagcc tccagagctc aaaaccccac ttggtgacac aactcacaca tgcccacggt gcccagagcc caaatcttgt gacacacctc ccccgtgccc acggtgccca gagcccaaat cttgtgacac acctccccca tgcccacggt gcccagagcc caaatcttgt gacacacctc ccccgtgccc ccggtgccca gcacctgaac tcttgggagg accgtcagtc ttcctcttcc ccccaaaacc caaggatacc cttatgattt cccggacccc tgaggtcacg tgcgtggtgg tggacgtgag ccacgaagac ccnnnngtcc agttcaagtg gtacgtggac ggcgtggagg tgcataatgc caagacaaag ctgcgggagg agcagtacaa cagcacgttc cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag tgcaaggtct ccaacaaagc aaccaagtca gcctgacctggtcaaa ggcttctacc ccagcgacat cgccgtggag tgggagagca atgggcagcc ggagaacaac tacaacacca cgcctcccat gctggactcc gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg aacatcttct catgctccgt gatgcatgag gctctgcaca accgctacac gcagaagagc ctctc. . .
DNA sequence. . . acctc ctgtgcaaga acatgaaaca nctgtggttc tcccagatgg gtcctgtccc aggtgcacct gcaggagtcg ggcccaggac tggggaagcc tccagagctc aaaaccccac ttggtgacac aactcacaca tgcccacggt gcccagagcc caaatcttgt gacacacctc ccccgtgccc acggtgccca gagcccaaat cttgtgacac acctccccca tgcccacggt gcccagagcc caaatcttgt gacacacctc ccccgtgccc ccggtgccca gcacctgaac tcttgggagg accgtcagtc ttcctcttcc ccccaaaacc caaggatacc cttatgattt cccggacccc tgaggtcacg tgcgtggtgg tggacgtgag ccacgaagac ccnnnngtcc agttcaagtg gtacgtggac ggcgtggagg tgcataatgc caagacaaag ctgcgggagg agcagtacaa cagcacgttc cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag tgcaaggtct ccaacaaagc aaccaagtca gcctgacctggtcaaa ggcttctacc ccagcgacat cgccgtggag tgggagagca atgggcagcc ggagaacaac tacaacacca cgcctcccat gctggactcc gacggctcct tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg aacatcttct catgctccgt gatgcatgag gctctgcaca accgctacac gcagaagagc ctctc. . .
 Genome size Organism Number of base pairs X-174 virus 5, 386 Epstein Bar Virus 172, 282 Mycoplasma genitalium 580, 000 Hemophilus Influenza 1. 8 106 Yeast (S. Cerevisiae) 12. 1 106 Human 3. 2 109 Wheat 16 109 Lilium longiflorum 90 109 Salamander 100 109 Amoeba dubia 670 109
Genome size Organism Number of base pairs X-174 virus 5, 386 Epstein Bar Virus 172, 282 Mycoplasma genitalium 580, 000 Hemophilus Influenza 1. 8 106 Yeast (S. Cerevisiae) 12. 1 106 Human 3. 2 109 Wheat 16 109 Lilium longiflorum 90 109 Salamander 100 109 Amoeba dubia 670 109
 Four DNA nucleotide building blocks G-C is more strongly hydrogen-bonded than A-T
Four DNA nucleotide building blocks G-C is more strongly hydrogen-bonded than A-T
 A gene codes for a protein DNA CCTGAGCCAACTATTGATGAA transcription m. RNA CCUGAGCCAACUAUUGAUGAA translation Protein PEPTIDE
A gene codes for a protein DNA CCTGAGCCAACTATTGATGAA transcription m. RNA CCUGAGCCAACUAUUGAUGAA translation Protein PEPTIDE
 Central Dogma of Molecular Biology Replication DNA Transcription m. RNA Translation Protein Transcription is carried out by RNA polymerase (II) Translation is performed on ribosomes Replication is carried out by DNA polymerase Reverse transcriptase copies RNA into DNA Transcription + Translation = Expression
Central Dogma of Molecular Biology Replication DNA Transcription m. RNA Translation Protein Transcription is carried out by RNA polymerase (II) Translation is performed on ribosomes Replication is carried out by DNA polymerase Reverse transcriptase copies RNA into DNA Transcription + Translation = Expression
: transfer") But DNA can also be transcribed into non-coding RNA … qt. RNA (transfer): transfer of amino acids to the ribosome during protein synthesis. qr. RNA (ribosomal): essential component of the ribosomes (complex with r. Proteins). qsn. RNA (small nuclear): mainly involved in RNA-splicing (removal of introns). sn. RNPs. qsno. RNA (small nucleolar): involved in chemical modifi-cations of ribosomal RNAs and other RNA genes. sno. RNPs. q. SRP RNA (signal recognition particle): form RNA-protein complex involved in m. RNA secretion. q. Further: micro. RNA, e. RNA, g. RNA, tm. RNA etc.
But DNA can also be transcribed into non-coding RNA … qt. RNA (transfer): transfer of amino acids to the ribosome during protein synthesis. qr. RNA (ribosomal): essential component of the ribosomes (complex with r. Proteins). qsn. RNA (small nuclear): mainly involved in RNA-splicing (removal of introns). sn. RNPs. qsno. RNA (small nucleolar): involved in chemical modifi-cations of ribosomal RNAs and other RNA genes. sno. RNPs. q. SRP RNA (signal recognition particle): form RNA-protein complex involved in m. RNA secretion. q. Further: micro. RNA, e. RNA, g. RNA, tm. RNA etc.
 Eukaryotes have spliced genes … q q q Promoter: involved in transcription initiation (TF/RNApol-binding sites) TSS: transcription start site UTRs: un-translated regions (important for translational control) Exons will be spliced together by removal of the Introns Poly-adenylation site important for transcription termination (but also: m. RNA stability, export m. RNA from nucleus etc. )
Eukaryotes have spliced genes … q q q Promoter: involved in transcription initiation (TF/RNApol-binding sites) TSS: transcription start site UTRs: un-translated regions (important for translational control) Exons will be spliced together by removal of the Introns Poly-adenylation site important for transcription termination (but also: m. RNA stability, export m. RNA from nucleus etc. )
 DNA makes m. RNA makes Protein
DNA makes m. RNA makes Protein
 DNA makes RNA makes Protein … yet another picture to appreciate the above statement
DNA makes RNA makes Protein … yet another picture to appreciate the above statement
: protein that binds to DNA and to a polymerase (Pol II)") Transcription Factor (TF): protein that binds to DNA and to a polymerase (Pol II) Transcription Factors Polymerase: complex protein that transcribes DNA into m. RNA TF binding site (TFBS) TF m. RNA Pol II transcription TATA Transcription factor – polymerase interaction sets off gene transcription… m. RNA transcription TF binding site (closed) TATA Nucleosomes (chromatin structures composed of histones) are structures round which DNA coils. This blocks access of TFs TF binding site (open) … many TFBSs are possible upstream of a gene
Transcription Factor (TF): protein that binds to DNA and to a polymerase (Pol II) Transcription Factors Polymerase: complex protein that transcribes DNA into m. RNA TF binding site (TFBS) TF m. RNA Pol II transcription TATA Transcription factor – polymerase interaction sets off gene transcription… m. RNA transcription TF binding site (closed) TATA Nucleosomes (chromatin structures composed of histones) are structures round which DNA coils. This blocks access of TFs TF binding site (open) … many TFBSs are possible upstream of a gene
 Some facts about human genes q There about 20. 000 – 25. 000 genes in the human genome (~ 3% of the genome) q Average gene length is ~ 8. 000 bp q Average of 5 -6 exons per gene q Average exon length is ~ 200 bp q Average intron length is ~ 2000 bp q 8% of the genes have a single exon q Some exons can be as small as 1 or 3 bp
Some facts about human genes q There about 20. 000 – 25. 000 genes in the human genome (~ 3% of the genome) q Average gene length is ~ 8. 000 bp q Average of 5 -6 exons per gene q Average exon length is ~ 200 bp q Average intron length is ~ 2000 bp q 8% of the genes have a single exon q Some exons can be as small as 1 or 3 bp
 DMD: the largest known human gene q The largest known human gene is DMD, which stands for “Dystrophin (muscular dystrophy, Duchenne and Becker types)” q The gene encodes the protein dystrophin: the gene’s size is ~ 2. 4 milion bp over 79 exons q X-linked recessive disease (affects boys) q Two variants: Duchenne-type (DMD) and becker-type (BMD) q Duchenne-type: more severe, frameshift-mutations Becker-type: milder phenotype, “in frame”- mutations Posture changes during progression of Duchenne muscular dystrophy
DMD: the largest known human gene q The largest known human gene is DMD, which stands for “Dystrophin (muscular dystrophy, Duchenne and Becker types)” q The gene encodes the protein dystrophin: the gene’s size is ~ 2. 4 milion bp over 79 exons q X-linked recessive disease (affects boys) q Two variants: Duchenne-type (DMD) and becker-type (BMD) q Duchenne-type: more severe, frameshift-mutations Becker-type: milder phenotype, “in frame”- mutations Posture changes during progression of Duchenne muscular dystrophy
 Nucleic acid basics q Nucleic acids are polymers nucleotide nucleoside q Each monomer consists of 3 moieties
Nucleic acid basics q Nucleic acids are polymers nucleotide nucleoside q Each monomer consists of 3 moieties
 q A base can be of 5 rings q Purines") Nucleic acid basics (2) q A base can be of 5 rings q Purines and Pyrimidines can base-pair (Watson- Crick pairs) Watson and Crick, 1953
Nucleic acid basics (2) q A base can be of 5 rings q Purines and Pyrimidines can base-pair (Watson- Crick pairs) Watson and Crick, 1953
 q DNA and") Nucleic acid as hetero-polymers q Nucleosides, nucleotides (Ribose sugar, RNA precursor) q DNA and RNA strands (2’-deoxy ribose sugar, DNA precursor) REMEMBER: ü ü (2’-deoxy thymidine triphosphate, nucleotide) ü DNA = deoxyribonucleotides; RNA = ribonucleotides (OH-groups at the 2’ position) Note the directionality of DNA (5’-3’ & 3’-5’) or RNA (5’-3’) DNA = A, G, C, T ; RNA = A, G, C, U
Nucleic acid as hetero-polymers q Nucleosides, nucleotides (Ribose sugar, RNA precursor) q DNA and RNA strands (2’-deoxy ribose sugar, DNA precursor) REMEMBER: ü ü (2’-deoxy thymidine triphosphate, nucleotide) ü DNA = deoxyribonucleotides; RNA = ribonucleotides (OH-groups at the 2’ position) Note the directionality of DNA (5’-3’ & 3’-5’) or RNA (5’-3’) DNA = A, G, C, T ; RNA = A, G, C, U
 So … DNA RNA
So … DNA RNA
 base") Stability of base-pairing q C-G base pairing is more stable than A-T (A-U) base pairing (why? ) q 3 rd codon position has freedom to evolve (synonymous mutations) q Species can therefore optimise their G-C content (e. g. thermophiles are GC rich) (consequences for codon use? ) Thermocrinis ruber, heat-loving bacteria
Stability of base-pairing q C-G base pairing is more stable than A-T (A-U) base pairing (why? ) q 3 rd codon position has freedom to evolve (synonymous mutations) q Species can therefore optimise their G-C content (e. g. thermophiles are GC rich) (consequences for codon use? ) Thermocrinis ruber, heat-loving bacteria
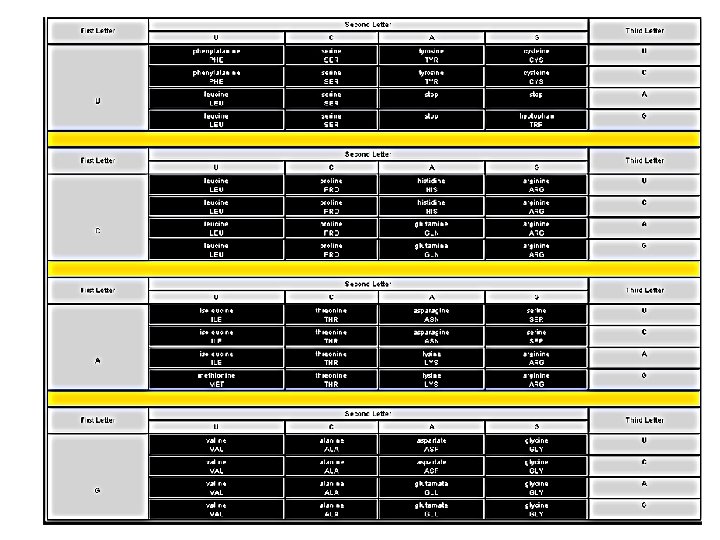
 Amino Acid Isoleucine Single Letter Code DNA codons I ATT, ATC, ATA Leucine L CTT, CTC, CTA, CTG, TTA, TTG Valine V GTT, GTC, GTA, GTG Phenylalanine F TTT, TTC Methionine M, Start ATG Cysteine c TGT, TGC Alanine A GCT, GCC, GCA, GCG Glycine G GGT, GGC, GGA, GGG Proline P CCT, CCC, CCA, CCG Threonine T ACT, ACC, ACA, ACG Serine S TCT, TCC, TCA, TCG, AGT, AGC Tyrosine Y TAT, TAC Tryptophan W TGG Glutamine Q CAA, CAG Asparagine N AAT, AAC Histidine H CAT, CAC Glutamic acid E GAA, GAG Aspartic acid D GAT, GAC Lysine K AAA, AAG Arginine R CGT, CGC, CGA, CGG, AGA, AGG Stop codons Stop TAA, TAG, TGA
Amino Acid Isoleucine Single Letter Code DNA codons I ATT, ATC, ATA Leucine L CTT, CTC, CTA, CTG, TTA, TTG Valine V GTT, GTC, GTA, GTG Phenylalanine F TTT, TTC Methionine M, Start ATG Cysteine c TGT, TGC Alanine A GCT, GCC, GCA, GCG Glycine G GGT, GGC, GGA, GGG Proline P CCT, CCC, CCA, CCG Threonine T ACT, ACC, ACA, ACG Serine S TCT, TCC, TCA, TCG, AGT, AGC Tyrosine Y TAT, TAC Tryptophan W TGG Glutamine Q CAA, CAG Asparagine N AAT, AAC Histidine H CAT, CAC Glutamic acid E GAA, GAG Aspartic acid D GAT, GAC Lysine K AAA, AAG Arginine R CGT, CGC, CGA, CGG, AGA, AGG Stop codons Stop TAA, TAG, TGA
 content") DNA compositional biases q Base compositions of genomes: G+C (and therefore also A+T) content varies between different genomes q The GC-content is sometimes used to classify organism in taxonomy q High G+C content bacteria: Actinobacteria e. g. in Streptomyces coelicolor it is 72% Low G+C content: Plasmodium falciparum (~20%) q Other examples: Saccharomyces cerevisiae (yeast) 38% Arabidopsis thaliana (plant) 36% Escherichia coli (bacteria) 50%
DNA compositional biases q Base compositions of genomes: G+C (and therefore also A+T) content varies between different genomes q The GC-content is sometimes used to classify organism in taxonomy q High G+C content bacteria: Actinobacteria e. g. in Streptomyces coelicolor it is 72% Low G+C content: Plasmodium falciparum (~20%) q Other examples: Saccharomyces cerevisiae (yeast) 38% Arabidopsis thaliana (plant) 36% Escherichia coli (bacteria) 50%
 q Autosomal,") Genetic diseases: cystic fibrosis q Known since very early on (“Celtic gene”) q Autosomal, recessive, hereditary disease (Chr. 7) q Symptoms: q Exocrine glands (which produce sweat and mucus) q Abnormal secretions q Respiratory problems q Reduced fertility and (male) anatomical anomalies 3, 000 30, 000 20, 000
Genetic diseases: cystic fibrosis q Known since very early on (“Celtic gene”) q Autosomal, recessive, hereditary disease (Chr. 7) q Symptoms: q Exocrine glands (which produce sweat and mucus) q Abnormal secretions q Respiratory problems q Reduced fertility and (male) anatomical anomalies 3, 000 30, 000 20, 000
 q Gene product: CFTR (cystic fibrosis transmembrane conductance regulator) q CFTR") cystic fibrosis (2) q Gene product: CFTR (cystic fibrosis transmembrane conductance regulator) q CFTR is an ABC (ATP-binding cassette) transporter or traffic ATPase. q These proteins transport molecules such as sugars, peptides, inorganic phosphate, chloride, and metal cations across the cellular membrane. q CFTR transports chloride ions (Cl-) ions across the membranes of cells in the lungs, liver, pancreas, digestive tract, reproductive tract, and skin.
cystic fibrosis (2) q Gene product: CFTR (cystic fibrosis transmembrane conductance regulator) q CFTR is an ABC (ATP-binding cassette) transporter or traffic ATPase. q These proteins transport molecules such as sugars, peptides, inorganic phosphate, chloride, and metal cations across the cellular membrane. q CFTR transports chloride ions (Cl-) ions across the membranes of cells in the lungs, liver, pancreas, digestive tract, reproductive tract, and skin.
 q CF gene CFTR has 3 -bp deletion leading to Del") cystic fibrosis (3) q CF gene CFTR has 3 -bp deletion leading to Del 508 (Phe) in 1480 aa protein (epithelial Cl- channel) q Protein degraded in Endoplasmatic Reticulum (ER) instead of inserted into cell membrane Diagram depicting the five domains of the CFTR membrane protein (Sheppard 1999). The delta. F 508 deletion is the most common cause of cystic fibrosis. The isoleucine (Ile) at amino acid position 507 remains unchanged because both ATC and ATT code for isoleucine Theoretical Model of NBD 1. PDB identifier 1 NBD as viewed in Protein Explorer http: //proteinexplorer. org
cystic fibrosis (3) q CF gene CFTR has 3 -bp deletion leading to Del 508 (Phe) in 1480 aa protein (epithelial Cl- channel) q Protein degraded in Endoplasmatic Reticulum (ER) instead of inserted into cell membrane Diagram depicting the five domains of the CFTR membrane protein (Sheppard 1999). The delta. F 508 deletion is the most common cause of cystic fibrosis. The isoleucine (Ile) at amino acid position 507 remains unchanged because both ATC and ATT code for isoleucine Theoretical Model of NBD 1. PDB identifier 1 NBD as viewed in Protein Explorer http: //proteinexplorer. org
 Let’s return to DNA and RNA structure … q Unlike three dimensional structures of proteins, DNA molecules assume simple double helical structures independent of their sequences. q There are three kinds of double helices that have been observed in DNA: type A, type B, and type Z, which differ in their geometries. q RNA on the other hand, can have as diverse structures as proteins, as well as simple double helix of type A. q The ability of being both informational and diverse in structure suggests that RNA was the prebiotic molecule that could function in both replication and catalysis (The RNA World Hypothesis). q In fact, some viruses encode their genetic materials by RNA (retrovirus)
Let’s return to DNA and RNA structure … q Unlike three dimensional structures of proteins, DNA molecules assume simple double helical structures independent of their sequences. q There are three kinds of double helices that have been observed in DNA: type A, type B, and type Z, which differ in their geometries. q RNA on the other hand, can have as diverse structures as proteins, as well as simple double helix of type A. q The ability of being both informational and diverse in structure suggests that RNA was the prebiotic molecule that could function in both replication and catalysis (The RNA World Hypothesis). q In fact, some viruses encode their genetic materials by RNA (retrovirus)
 Three dimensional structures of double helices Side view: A-DNA, B-DNA, Z-DNA Space-filling models of A, B and Z- DNA Top view: A-DNA, B-DNA, Z-DNA
Three dimensional structures of double helices Side view: A-DNA, B-DNA, Z-DNA Space-filling models of A, B and Z- DNA Top view: A-DNA, B-DNA, Z-DNA
 Major and minor grooves
Major and minor grooves
 Forces that stabilize nucleic acid double helix q There are two major forces that contribute to stability of helix formation: ü Hydrogen bonding in base-pairing ü Hydrophobic interactions in base stacking 5’ 3’ 3’ 5’ Same strand stacking cross-strand stacking
Forces that stabilize nucleic acid double helix q There are two major forces that contribute to stability of helix formation: ü Hydrogen bonding in base-pairing ü Hydrophobic interactions in base stacking 5’ 3’ 3’ 5’ Same strand stacking cross-strand stacking
 Types of DNA double helix q Type A q Type B q Type Z major conformation RNA minor conformation DNA major conformation DNA minor conformation DNA Right-handed helix Short and broad Right-handed helix Long and thin Left-handed helix Longer and thinner
Types of DNA double helix q Type A q Type B q Type Z major conformation RNA minor conformation DNA major conformation DNA minor conformation DNA Right-handed helix Short and broad Right-handed helix Long and thin Left-handed helix Longer and thinner
 Secondary structures of Nucleic acids q DNA is primarily in duplex form q RNA is normally single stranded which can have a diverse form of secondary structures other than duplex. q RNA can form duplexes by folding back onto itself q DNA duplex is mostly in the B-form, RNA duplex regions in the A-form q DNA is more stable than RNA
Secondary structures of Nucleic acids q DNA is primarily in duplex form q RNA is normally single stranded which can have a diverse form of secondary structures other than duplex. q RNA can form duplexes by folding back onto itself q DNA duplex is mostly in the B-form, RNA duplex regions in the A-form q DNA is more stable than RNA
 Non B-DNA Secondary structures q Cruciform DNA q Slipped DNA q Triple helical DNA Hoogsteen basepairs Source: Van Dongen et al. (1999) , Nature Structural Biology 6, 854 - 859
Non B-DNA Secondary structures q Cruciform DNA q Slipped DNA q Triple helical DNA Hoogsteen basepairs Source: Van Dongen et al. (1999) , Nature Structural Biology 6, 854 - 859
 RNA Secondary structures q RNA pseudoknots q Cloverleaf r. RNA structure 16 S r. RNA Secondary Structure Based on Phylogenetic Data Source: Cornelis W. A. Pleij in Gesteland, R. F. and Atkins, J. F. (1993) THE RNA WORLD. Cold Spring Harbor Laboratory Press.
RNA Secondary structures q RNA pseudoknots q Cloverleaf r. RNA structure 16 S r. RNA Secondary Structure Based on Phylogenetic Data Source: Cornelis W. A. Pleij in Gesteland, R. F. and Atkins, J. F. (1993) THE RNA WORLD. Cold Spring Harbor Laboratory Press.
 3 D structures of RNA : transfer-RNA structures q Secondary structure of t. RNA (cloverleaf) q Tertiary structure of t. RNA
3 D structures of RNA : transfer-RNA structures q Secondary structure of t. RNA (cloverleaf) q Tertiary structure of t. RNA
 3 D structures of RNA : ribosomal-RNA structures q Secondary structure of large r. RNA (16 S) q Tertiary structure of large r. RNA subunit Ban et al. , Science 289 (905 -920), 2000
3 D structures of RNA : ribosomal-RNA structures q Secondary structure of large r. RNA (16 S) q Tertiary structure of large r. RNA subunit Ban et al. , Science 289 (905 -920), 2000
 3 D structures of RNA : Catalytic RNA q Secondary structure of self-splicing RNA q Tertiary structure of self-splicing RNA
3 D structures of RNA : Catalytic RNA q Secondary structure of self-splicing RNA q Tertiary structure of self-splicing RNA
 destabilize q") Some structural rules … q Base-pairing is stabilizing q Un-paired sections (loops) destabilize q 3 D conformation with interactions makes up for this
Some structural rules … q Base-pairing is stabilizing q Un-paired sections (loops) destabilize q 3 D conformation with interactions makes up for this
 Three main principles • DNA makes RNA makes Protein • Structure more conserved than sequence • Sequence Structure Function
Three main principles • DNA makes RNA makes Protein • Structure more conserved than sequence • Sequence Structure Function
 How to go from DNA to protein sequence A piece of double stranded DNA: 5’ attcgttggcaaatcgcccctatccggc 3’ 3’ taagcaaccgtttagcggggataggccg 5’ DNA direction is from 5’ to 3’
How to go from DNA to protein sequence A piece of double stranded DNA: 5’ attcgttggcaaatcgcccctatccggc 3’ 3’ taagcaaccgtttagcggggataggccg 5’ DNA direction is from 5’ to 3’
 How to go from DNA to protein sequence 6 -frame conceptual translation using the codon table: 5’ attcgttggcaaatcgcccctatccggc 3’ 3’ taagcaaccgtttagcggggataggccg 5’ So, there are six possibilities to make a protein from an unknown piece of DNA, only one of which might be a natural protein
How to go from DNA to protein sequence 6 -frame conceptual translation using the codon table: 5’ attcgttggcaaatcgcccctatccggc 3’ 3’ taagcaaccgtttagcggggataggccg 5’ So, there are six possibilities to make a protein from an unknown piece of DNA, only one of which might be a natural protein
 human genes, i. e. finding what they are and what") Remark • Identifying (annotating) human genes, i. e. finding what they are and what they do, is a difficult problem – First, the gene should be delineated on the genome • Gene finding methods should be able to tell a gene region from a nongene region • Start, stop codons, further compositional differences – Then, a putative function should be found for the gene located
Remark • Identifying (annotating) human genes, i. e. finding what they are and what they do, is a difficult problem – First, the gene should be delineated on the genome • Gene finding methods should be able to tell a gene region from a nongene region • Start, stop codons, further compositional differences – Then, a putative function should be found for the gene located
 Evolution and three-dimensional protein structure information Isocitrate dehydrogenase: The distance from the active site (in yellow) determines the rate of evolution (red = fast evolution, blue = slow evolution) Dean, A. M. and G. B. Golding: Pacific Symposium on Bioinformatics 2000
Evolution and three-dimensional protein structure information Isocitrate dehydrogenase: The distance from the active site (in yellow) determines the rate of evolution (red = fast evolution, blue = slow evolution) Dean, A. M. and G. B. Golding: Pacific Symposium on Bioinformatics 2000
 • Proteome (xray, NMR, mass") Genomic Data Sources • DNA/protein sequence • Expression (microarray) • Proteome (xray, NMR, mass spectrometry) • Metabolome • Physiome (spatial, temporal) Integrative bioinformatics
Genomic Data Sources • DNA/protein sequence • Expression (microarray) • Proteome (xray, NMR, mass spectrometry) • Metabolome • Physiome (spatial, temporal) Integrative bioinformatics
 Genomic Data Sources Vertical Genomics genome transcriptome proteome metabolome physiome Dinner discussion: Integrative Bioinformatics & Genomics VU
Genomic Data Sources Vertical Genomics genome transcriptome proteome metabolome physiome Dinner discussion: Integrative Bioinformatics & Genomics VU
") DNA makes RNA makes Protein (reminder)
DNA makes RNA makes Protein (reminder)
 DNA makes RNA makes Protein: Expression data • More copies of m. RNA for a gene leads to more protein • m. RNA can now be measured for all the genes in a cell at ones through microarray technology • Can have 60, 000 spots (genes) on a single gene chip • Colour change gives intensity of gene expression (over- or under-expression)
DNA makes RNA makes Protein: Expression data • More copies of m. RNA for a gene leads to more protein • m. RNA can now be measured for all the genes in a cell at ones through microarray technology • Can have 60, 000 spots (genes) on a single gene chip • Colour change gives intensity of gene expression (over- or under-expression)

 Proteomics • Elucidating all 3 D structures of proteins in the cell • This is also called Structural Genomics • Finding out what these proteins do • This is also called Functional Genomics
Proteomics • Elucidating all 3 D structures of proteins in the cell • This is also called Structural Genomics • Finding out what these proteins do • This is also called Functional Genomics
 Protein-protein interaction networks
Protein-protein interaction networks
") Metabolic networks Glycolysis and Gluconeogenesis Kegg database (Japan)
Metabolic networks Glycolysis and Gluconeogenesis Kegg database (Japan)
 High-throughput Biological Data • Enormous amounts of biological data are being generated by high-throughput capabilities; even more are coming – genomic sequences – array. CGH (Comparative Genomic Hybridization) data, gene expression data – mass spectrometry data – protein-protein interaction data – protein structures –. . .
High-throughput Biological Data • Enormous amounts of biological data are being generated by high-throughput capabilities; even more are coming – genomic sequences – array. CGH (Comparative Genomic Hybridization) data, gene expression data – mass spectrometry data – protein-protein interaction data – protein structures –. . .
: 14500 Structures (6 March 2001) 10900") Protein structural data explosion Protein Data Bank (PDB): 14500 Structures (6 March 2001) 10900 x-ray crystallography, 1810 NMR, 278 theoretical models, others. . . Bioinformatics databases grow exponentially…
Protein structural data explosion Protein Data Bank (PDB): 14500 Structures (6 March 2001) 10900 x-ray crystallography, 1810 NMR, 278 theoretical models, others. . . Bioinformatics databases grow exponentially…
 with y the") Dickerson’s formula: equivalent to Moore’s law n = e 0. 19(y-1960) with y the year. Dickerson predicted that the Protein Data Bank (PDB) of protein three-dimensional structures would grow, starting with the first protein in 1960, as indicated by the above exponential growth function. On 27 March 2001 there were 12, 123 3 D protein structures in the PDB: Dickerson’s formula predicts 12, 066 (within 0. 5% -- not a bad prediction)!
Dickerson’s formula: equivalent to Moore’s law n = e 0. 19(y-1960) with y the year. Dickerson predicted that the Protein Data Bank (PDB) of protein three-dimensional structures would grow, starting with the first protein in 1960, as indicated by the above exponential growth function. On 27 March 2001 there were 12, 123 3 D protein structures in the PDB: Dickerson’s formula predicts 12, 066 (within 0. 5% -- not a bad prediction)!
 Sequence versus structural data • Structural genomics initiatives are now in full swing and growth is still exponential. • However, growth of sequence data is even more rapidly. There are now more than 600 completely sequenced genomes publicly available. Increasing gap between structural and sequence data (“Mind the gap”)
Sequence versus structural data • Structural genomics initiatives are now in full swing and growth is still exponential. • However, growth of sequence data is even more rapidly. There are now more than 600 completely sequenced genomes publicly available. Increasing gap between structural and sequence data (“Mind the gap”)
 Bioinformatics • Offers an ever more essential input to – Molecular Biology – Pharmacology (drug design) – Agriculture – Biotechnology – Clinical medicine – Anthropology – Forensic science – Chemical industries (detergent industries, etc. ) This list is from a molecular biology textbook – so not a self-absorbed bioinformatician is saying this…
Bioinformatics • Offers an ever more essential input to – Molecular Biology – Pharmacology (drug design) – Agriculture – Biotechnology – Clinical medicine – Anthropology – Forensic science – Chemical industries (detergent industries, etc. ) This list is from a molecular biology textbook – so not a self-absorbed bioinformatician is saying this…