12d6eed9e98ad17550ab570dadfd8f42.ppt
- Количество слайдов: 72



Brave Open World О квазилингвистических интернет-ресурсах В. П. Селегей (в сотрудничестве с В. И. Беликовым)

Разрешите представиться l l l Основное место работы: лингвистический отдел ABBYY (лингвистическая поддержка проектов Fine. Reader, Lingvo, Compreno) Кафедры Ко. Линг в МФТИ и РГГУ Конференция Диалог: www. dialogue-21. ru и : ежегодник «Компьютерная лингвистика и интеллектуальные технологии» (индекс Scopus) Основные направление деятельности: NLP (Natural Language Processing), основанное на развитых лингвистических моделях, компьютерная лексикография, корпусная лингвистика Немного об ABBYY:
лингвистические ресурсы, зачем они нужны и как ими")
План лекции l l Что такое (квази)лингвистические ресурсы, зачем они нужны и как ими пользоваться Дивный открытый мир – это новый мир созданных с помощью Ко. Линг и/или с помощью краудсорсинга ресурсов, которые часто не напрямую связаны с целями лингвистов. Манящее, но опасное (см. лекцию А. Ч. Пиперски) Открытое стремится к связности как способу преодолеть ограниченность (концепция Linked. Data). Для науки важно, что закрытые ресурсы для ее развития плохо применимы: открытость – единственный способ надежной верификации и развития.

Зачем нужны «ресурсы» l l l l Острая проблема неполноты данных для исследований. Откуда возникла эта проблема? Почему раньше хватало, а теперь – нет? Только 3 фактора: Расширились границы лингвистического описания, появились новые субъекты и новые жанры. Пространство дифференциальных параметров, которые нужно принимать во внимание, увеличилось на порядок Принципиальное многоязычие потребовало иной точности и полноты данных Компьютерная лингвистика требует описаний, причем реального, а не языка «в пробирке» . Новая языковая ситуация выдвигает новые задачи и требования: лингвистика вынуждена обращаться к актуальному – одно только нормативное уже никому не интересно, даже чиновникам.

Лингвистические ресурсы l l l Исторически между исходным объектом языкового исследования (речью во всей совокупности речевых жанров и регистров) и собственно результатами анализа: словарями и грамматиками находилось специальное аналитическое устройство: голова лингвиста. Оказалось, что ее недостаточно. На помощь приходят лингвистические ресурсы: специально созданные в помощь исследователю коллекции структурированных языковых данных. Например, размеченные (относительно конкретных языковых явлений) корпуса текстов, типологические базы данных, комьютерные модели морфологии, лексикосемантические иерархии типа Word. Net и прочие *Net К сожалению, таких создаваемых вручную ресурсов недостаточно.

Квазилингвистические ресурсы l l Quasi- is used to form adjectives and nouns that describe something as being in many ways like something else, without actually being that thing. Например: Квазисинонимия (но квазилингвист). Квази. ЛР, как правило (не всегда), имеют целью создания нечто нелингвистическое. Например, энциклопедические описания (Wikipedia) или системы поиска в Интернете (Google, Яндекс, Bing и т. п. ), электронные библиотеки, автоматически создаваемые интернет-корпуса, краудсорсинговые wiki-проекты. Мы можем использовать такие инструменты для исследований языка, но получаемые ответы следует принимать с большой осторожностью (особенно в связи с имеющейся тенденцией приписывать им особую объективность). Что делает такие инструменты «квази» : немасштабируемость, специфика разметки, грубая (плохая) обработка данных, субъективность (наивность) составителя и т. п.

Примеры квазиинструментов

l l Гугль. Букс: корпус или игрушка? Немного об устройстве

Сферический поиск в гугловакууме

l l l Мой дядя самых честных правил, Когда не в шутку занемог, Он уважать себя заставил И лучше выдумать не мог Какая из фраз наиболее «крылата» ?

Гугльбуксы

Гугльбуксы

Гугльбуксы

Поиск паремий

Гугльбуксы

Нет сомнения, что google books n-граммы отражают не состояние языка, а состав изданий конкретного года. Но Ф. И. Тютчев написал «Есть в осени первоначальной. . . » в 1857 году, а в ГБ n-граммах оно появляется лишь с 1919 г.

Не является полноценным Big Corpus по целому l l l ряду причин: Отсутствие морфоразметки (и невозможность полноценной постразметки n-gramm) Отрыв n-gramm от контекста + абсолютные ограничения в выдаче (не менее 40) Произвольность датировок: даты (пере)изданий, а не написания текстов. Отсутствие дифференциальных признаков текстов. Ошибки OCR (особенно в текстах до реформы) По совокупности причин результаты диахронических исследований оказываются неинтерпретируемыми
 l l l Как сравнить «нуль» и «ноль» ? Гугление?")
По нолям (маленький пример) l l l Как сравнить «нуль» и «ноль» ? Гугление? НКРЯ? Ru. Ten Гугль. Букс Дифференциальный корпус с разметкой

Гугляж l l … Приведем весьма яркие данные поисковой системы Google по формам множественного числа [слов ноль и нуль] ‹…› нолях — 1880 употреблений, нулях — 48000 употреблений. (Ю. Д. Апресян. Введение // Проспект активного словаря русского языка, 2010, стр. 37. ) У Ю. Д. получилась разница в 25 раз (в 2010 году). Как она получена? Ищем…

l l l Первая выдача: Разница примерно в 10 раз. Верно ли, что в 2015 «ноль» отыграл половину? Настоящий лингвист смотрит выдачу до конца. Листаем…

Цифры с «последних» страниц: l Без «очень похожих» разница невелика, направлена в другую сторону, и не совпадает вверху и внизу страниц l Просим «похожие» …

для нолях эксперимент закончился показом 17 -й страницы, для нулях — 18 -й. Вот и вся статистика, о чем она говорит — неизвестно.

Надежным источником статистической информации о языке могут служить только корпуса. НКРЯ для этой цели иногда подходит, иногда нет: Для нолях мы получили лишь две опечатки ( следует читать полях.
: Соотошение — 1 к")
результат поиска в ГИКРЯ (дифф. интернет-корпус в 20 млрд. слов): Соотошение — 1 к 17, 5, но это часть правды, поскольку для разных форм соотношение но…/ну… различно, иногда значительно.

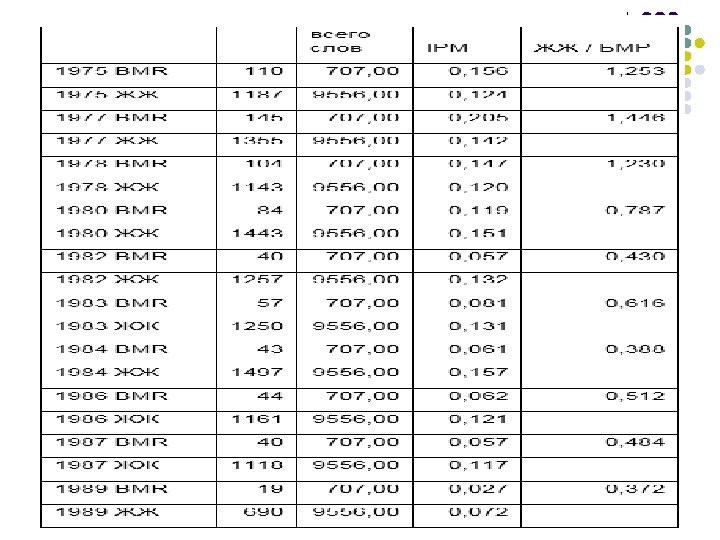
Абсолютная статистика для самого большого сегмента ГИКРЯ — ЖЖ — такова:

Дательный единственного во всех сегментах опережает остальные формы: и в «литературном» , и блогах, и в несколько более молодой среде ВКонтакте:

Общий вывод: неотвратимость использования Big Corpora l l Большие интернет-корпуса с полностью автоматической языковой и метатекстовой разметкой обещают стать наиболее ценными инструментами лингвистических исследований. Вопрос в том, являются ли они лингвистическими или квазилингвистическими инструментами

Ru. Ten l l l Автор: Адам Килгарифф Корпус собран из Рунета Spider. Ling in 2011. Дедублицирован, очищен от обвязки. Морфоразметка RFTagger + Tree. Tagger. Текущая версия 14. 5 млрд. слов: удалены страницы (1 млрд. слов) с сайтов «with high relative frequency of word порно» . Основная проблема: случайность процедуры сбора корпуса, отсутствие метатекстовой разметки.

Простой пример: сегментные частотные словари l l l Относительные частоты слов «хохолок» и «цинично» Частотный словарь НКРЯ Шаров-Ляшевская 1 : 1 Живой Журнал 1: 6 Блоги Mail. ru 1 : 15 Новости 1 : 120 Смешение текстов разных сегментов в Ru. Ten дает также и неинтерпретируемое распределение лексических значений многозначных слов.
")
Зависимость данных от корпуса (слово «блок» )
 l Вопросы: l")
Зависимость данных от корпуса (смесь Ru. Ten vs. сегмент ЖЗ ГИКРЯ) l Вопросы: l Какой результат «правильней» : средний или сегментный? l Как обеспечить объективность расчетов?
 l l l ГИКРЯ – проект создания корпуса")
Проект Генерального Интернеткорпуса Русского Языка (ГИКРЯ) l l l ГИКРЯ – проект создания корпуса для целей дифференциальной лингвистики и лексикографии, объемом ок. 50 миллиардов словоупотреблений. В ГИКРЯ представлены все существенные социальные, жанровые, тематические сегменты Интернета. Одна из основных целей проекта – разработка методов классификации на основании априорных данных из авторских профилей. Совместный проект Института Лингвистики РГГУ, МФТИ, ABBYY, университета Лидса, МГУ. Пролегомены к проекту Генерального интернет-корпуса русского языка (ГИКРЯ) В. И. Беликов, В. П. Селегей, С. А. Шаров (РГГУ) Диалог 2012 32

Дифференциальная полнота l l l В отличие от понятия сбалансированностирепрезентативности, дифференциальная полнота означает не просто предположительную типологическую полноту корпуса в некоей правильной пропорции, но полную метатекстовую разметку и наличие в корпусе статистически значимого объема текстов каждого типа. В дифференциально полном корпусе результат обработки любого запроса может быть разложен по типологическим координатам. Вопрос о составе «реального» языка (в процентах для каждого типа признается бессмысленным). Для всякой вариативности, для всякого значимого различия в языковых свойствах, обнаруженных в корпусе, должен быть найден соответствующий дифференциальный признак. 33

Дифференциальный корпус

Статистика по «усредненному» русскому языку — это фикция. В разных жанрах, типах дискурса, в разных возрастах и регионах статистика будет различаться. Вот какие прилагательные наиболее часто сополагаются со словом «альбом» в разных сегментах ГИКРЯ

Комментарий к исследованию А. Ч. Пиперски и l l l l Вот что можно узнать об упомянутых лексических единицах из «простого» корпуса и мегакорпуса: ссобойка ссобойчик тормозок НКРЯ 0 0 0 3 ГИКРЯ 470 170 9 814 в том числе в блогах и ВКонтакте: Россия 89 17 3 206 Белоруссия 166 86 0 11 Украина 16 1 1 179*

Лексикографическая польза ГИКРЯ Иногда не нужна никакая статистика, достаточно беглого взгляда в выдачу. «Толковый словарь русской разговорной речи. Вып. 1: А—И» (2014): «[В словаре] дается описание преимущественно разговорной лексики культурных центров России — Москвы и в меньшей степени) Петербурга» . И такая статья: Замахнуть ‘выпить спиртного’.

Лексикографическая польза ГИКРЯ В Журальном зале ГИКРЯ замахнуть в таком значении встретилось 12 раз в 11 текстах, происхождение авторов таково: Нижнекамск (Татарстан), Сарапул (Удмуртия), Челябинск, Коркино (Челябинская обл. ), Пермь (3 автора), Екатеринбург, Усть-Каменогорск, Красноярск, Владивосток.

Почему и ГИКРЯ – квазилингвистический корпус l l l Квазилингвистическим корпус делает не только произвольность состава, но и заведомая ненадежность разметки, которая предполагается доступной для исследователя. Корпуса с автоматически снятой морфологической неоднозначностью – квазилингвистические (плотвы и трески – (с) А. Пиперски). Можно ли получить достойный (с точки зрения лингвистаисследователя) результат сомнительными средствами? Как это делается сегодня: что и как делает POS-тагер? Анализ пригодности авторазметки для лингвистических исследований – в начальном состоянии (ЛЛШ-15 – удивительное исключение!). Другие проблемы: неясность самой системы дифференциальных параметров.

Благорастворение воздухов

Снятие омонимии

Сколько жанров помещается на кончике иглы l Квазилингвистическая жанровая разметка

Непараметризованная сегментая неодородность

О достаточности корпусных данных l l l Как правильно поставить лингвистический эксперимент и получить результат быстро? Конь перепрыгнул барьер Конь перепрыгнул через барьер Есть ли разница в значении, и как это доказать? 45

О достаточности объема корпусных данных 46
 l перепрыгивать \"барьер\" 92 перепрыгивать \"через")
Частоты в блогах ЖЖ (> 50 млрд слов) l перепрыгивать "барьер" 92 перепрыгивать "через барьер" 81 перепрыгивать "препятствие" 74 перепрыгивать "через препятствие" 63 перепрыгивать "забор" 410 перепрыгивать "через забор" 800 перепрыгивать "яму" 48 перепрыгивать "через яму" 34 перепрыгивать "ручей" 87 перепрыгивать "через ручей" 123 перепрыгивать "лужу" 212 перепрыгивать"через лужу 235 47

Результат
 даже")
Промежуточные итоги l l l Без генерализации запросов (перехода к классам сходных объектов) даже корпуса в десятки миллиардов слов оказываются недостаточными. Пример: региональная вариативность Необходимо искать надежно идентифицируемые и при этом лингвистически содержательные дифференциальные признаки.

Актуальные проблемы l l l Языковая разметка: снятие неоднозначности Лексико-семантическая разметка: проблема филиации, применение дистрибуционных подходов Метатектстовая разметка. Неясность самой системы категорий, особенно в случае жанрово-тематической автоматической классификации. Модели текста: l Учет жанрово-тематической неоднородности. l Идентификация чужого текста (дедубликация, определение цитат, паремий). Способы оценки достоверности количественных результатов поиска Рассмотрим некоторые из этих проблем на материале существующих больших корпусов РЯ

Лексико-энциклопедические связанные ресурсы


Word. Net: основные сведения l l l Разработан в Принстонском университете США. Начало разработки - 1984 г. Первоначально создавался как модель человеческой памяти, поэтому многие решения мотивируются психолингвистически. Идеолог - Джордж Миллер (George Miller). Вызвал больший интерес у компьютерных лингвистов, чем у психолингвистов. В 1995 году появился в Интернете в свободном доступе. На его основе были выполнены тысячи экспериментов в области АОТ и информационного поиска. Word. Net версии 3. 0: около 155 тыс. лексем и словосочетаний, сгруппированных в 117 тысяч понятий-синсетов (synset); около 200 тыс. элементов синсетов. Существуют национальные версии Word. Net практически для всех распространенных языков Почему Word. Net является квазилингвистическим ресурсом? (не в большей степени, чем любой словарь).

Babel. Net:

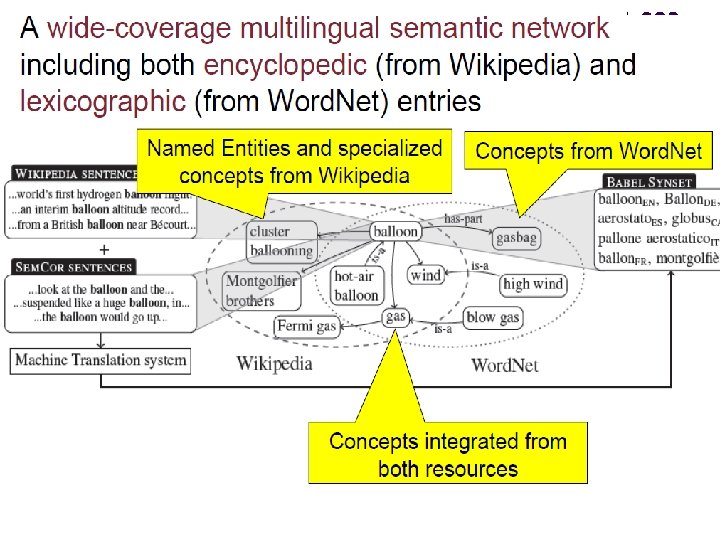
l BNet is both a multilingual encyclopedic dictionary, with lexicographic and encyclopedic coverage of terms, and a semantic network which connects concepts and named entities in a very large network of semantic relations, made up of more than 13 million entries, called Babel synsets. Each Babel synset represents a given meaning and contains all the synonyms which express that meaning in a range of different languages. l Babel. Net 3. 0 covers 271 languages and is obtained from the automatic integration of: Word. Net, a popular computational lexicon of English (version 3. 0), Open Multilingual Word. Net, a collection of wordnets available in different languages (August 2013 dump), Wikipedia, the largest collaborative multilingual Web encyclopedia (November 2014 dump), Omega. Wiki, a large collaborative multilingual dictionary (November 2014 dump), Wiktionary, a collaborative project to produce a free-content multilingual dictionary (August 2014 dump), Wikidata, a free knowledge base that can be read and edited by humans and machines alike (November 2014 dump). Additionally, it contains translations obtained from sense-annotated sentences. The correctness of the Word. Net-Wikipedia mapping in Babel. Net 3. 0 has been estimated at around 91% on open-text words. l l l l

Вопросы 10. 09. 2012 Введение в Ко. Линг. Магистратура МФТИ/РГГУ 59

Wordnet как словарь • The noun forest has 2 senses • 1. forest, woods -- (the trees and other plants in a large densely wooded area) • 2. forest, woodland, timber -- (land that is covered with trees and shrubs) • The verb forest has 1 sense • 1. afforest, forest -- (establish a forest on previously unforested land; "afforest the mountains") -------------------------Осталось за кадром математическое и метафорические использования (лес рук)

Wordnet как иерархия: гиперонимы Отношение гиперонимии: от вида к роду 1. forest, woods – => vegetation, flora -=> collection, aggregation, accumulation, assemblage => group, grouping 2. forest, woodland, timber => land, dry land, earth, ground, solid ground, terra firma => object, physical object => entity, something ---------------------NLC: DEEP_STRUCTURE_ELEMENTS : LEXICAL_ELEMENTS : ENTITY_LIKE_CLASSES : SPACE_AND_SPATIAL_OBJECTS : THE_EARTH_AND_ITS_SPATIAL_PARTS : DRY_LAND_PARTS : LAND_BY_COVEREDNESS : LAND_COVERED_BY_GROWTH : FOREST : forest

Wordnet как иерархия: гипонимы Отношение гипонимии: виды одного рода 1. forest, woods -- => grove -- (a small growth of trees without underbrush) => old growth, virgin forest -- (forest or woodland having a mature or overmature ecosystem more or less uninfluenced by human activity) => second growth -- (a second growth of trees covering an area where the original stand was destroyed by fire or cutting) 2. forest, woodland, timber – => Black Forest, Schwarzwald -- (a hilly forest region in southwestern Germany) => greenwood -- (woodlands in full leaf) => jungle -- (an impenetrable equatorial forest) => rain forest, tropical rain forest -- (a tropical forest with heavy annual rainfall) => riparian forest -- (woodlands along the banks of stream or river) => Sherwood Forest -- (an ancient forest in central England) => silva, sylva -- (the forest trees growing in a country or region) …
 Родо-видовые: l l Меронимия")
Word. Net как сеть семантических отношений l l Синонимия (синсеты) Родо-видовые: l l Меронимия (часть-целое): рука – человек, крыло-птица Lexical entailment (лексическое следование) l l a verb X entails Y if X cannot be done unless Y is, or has been, done: Если человек храпит, значит, он спит Каузальные отношения между глаголами (causal relations) l l Гипероним/гипоним Troponymy (тропонимия) для глаголов: X is a troponym of Y if to X is to Y in some manner: трястись (X) = бояться (Y) Give – have Антонимия (для прилагательных)

Проблемы Word. Net: синонимия vs. родо-видовое отношение Четыре синсета, каждый следующий гипоним предыдущего: sameness -- (the quality of being alike) l similarity -- (the quality of being similar) l likeness, alikeness, similitude -- (similarity in appearance or character or nature between persons or things) § resemblance -- (similarity in appearance or external or superficial details

Мульда, пухто и альтфатер

Что в словарях и энциклопедиях: В 3 изд. «Большой советской энциклопедии» сообщается, что: l l l контр-адмирал В. М. Альтфатер «Родился в дворянской семье ‹…› перешел на сторону Советской власти, участвовал в мирных переговорах в Бресте ‹…› Сыграл видную роль в создании советского ВМФ и обороне Петрограда» . Мульда — «в сталеплавильном производстве — стальная, обычно литая коробка для загрузки шихты» . Про пухто ничего не сообщается.

В Ижевске: В Решении Городской Думы г. Ижевска «Об утверждении Правил обеспечения чистоты и порядка на территории застройки индивидуальными домовладениями г. Ижевска» от 31. 10. 2002 говорится: Совместно с председателями уличных комитетов определить и согласовать с Центром Госсанэпиднадзора места расположения мульд и график вывоза бытовых отходов;

В Петербурге: «Приказ» территориального управления Василеостровского административного района Санкт. Петербурга от 25. 07. 2002: О проведении конкурсов путем запроса ценовых котировок по выбору поставщиков компьютеров и разработчиков электронных слоев (уборочных территорий, размещения пухто, свалок и урн) для нужд территориального управления.

В Одессе: Газета «Юг» , Одесса; 18. 11. 2004 : По полутемным улицам мимо ярко освещенных окон особняков чиновников нового президента идут от альтфатера к альтфатеру стройные колонны осчастливленных новой пенсией украинцев. Их обгоняют веселые ватаги бездомных ребятишек — как же не радоваться, ведь молодость и скорость берут свое: они могут урвать лучший кусок из общественного альтфатера!

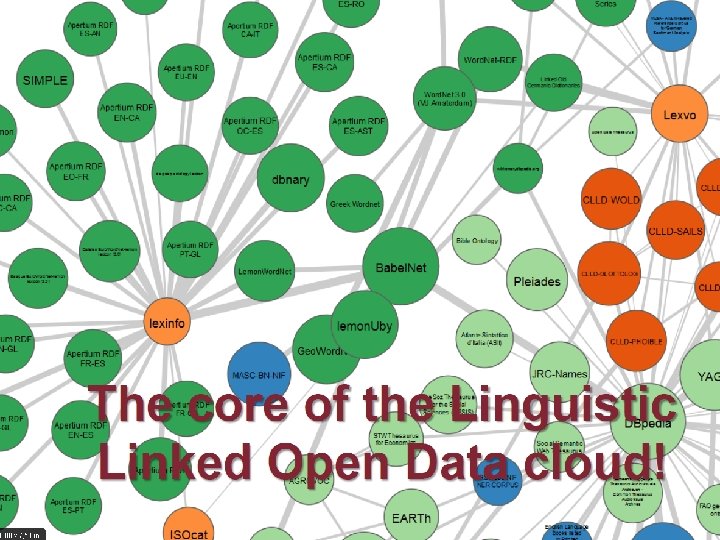
l l l l Ресурсы и квазиресурсы. ЗАчем они нужны. Интернет через окно поисковика – типичный квазиресурс. Корпус неизвсетного состава «но ну очень большой» . Словарь без примеров и помет (но тоже очень большой) и т. д. Параллельный корпус (мы не знаем приницпа «выравнивания» - Зализяняк и К). Дистрибуционная семантика – это что? Что делает ресурс «квази» - неясность по какому-либо существенному параметру: разметке, составу, статистике и т. п. Задача: объяснить прелести и выгоды квазиресурсов. Методические правила выявления их слабых мест и использования Открытое и связное: связность как преодоление ограниченности: у вас нет моделей в Ворднете – так возьмем их в Вики, связав эти два ресурса. Показать задачу немецкого описания Что делать с «неэнциклпедическими» сущностями – самое сложное.

Сколько бывает вопросов 1. 2. 3. 4. 5. Обращение, требующее ответа. Задать вопрос докладчику. Ответы на вопросы ЕГЭ по русскому языку. То или иное положение, обстоятельство как предмет изучения и суждения, задача, требующая решения, проблема. Национальный вопрос. Поднять вопрос. Вопрос ребром поставить. Оставить вопрос открытым. Изучить вопрос. Вопрос ясен. Дело, обстоятельство, касающееся, зависящее от чего-н. Положительное решение - вопрос времени. Вопрос чести. Вопрос жизни и смерти. Нечто неясное, до конца неизвестное (разг. ). Поедем или нет - это еще вопрос Разберем: Быть или не быть - вот в чем вопрос.

Кухня обучения. Сколько POS различает pos-tagger? l l l In part-of-speech tagging by computer, it is typical to distinguish from 50 to 150 separate parts of speech for English. Что практически означает tagset в 500 -800 «частей речи» для РЯ. For example, when the system learns the structure of Russian noun phrases, it does not take into account the agreement in case, number and gender. It only learns the fact that Afpmsg is normally followed by Ncmsgn, Ncmsgy or Npmsgy, while Afpfsd is followed by Ncfsdn, etc. However, if the set of training examples does not contain a proper masculine inanimate noun (Npmsgn) in this sequence, the tagger will fail to treat the sequence of Afpmsg Npmsgn as a noun phrase, even if the concept of animacity is not relevant to the noun phrase construction. (Sharoff, Nivre 2011).
12d6eed9e98ad17550ab570dadfd8f42.ppt