26cfa83af470bd68901c7ad55b257908.ppt
- Количество слайдов: 25



Большие данные в социальных науках Катерина Губа НОЦ PAST-Центр НИ ТГУ
: 721– 23.")
Lazer, David et al. 2009. “Computational Social Science. ” Science 323 (February): 721– 23. • • • Из всех 15 половина авторов получила степени по социальным наука (социология, политическая наука, коммуникация, управление), остальные писали диссертации в области физики и компьютерных наук. А. Пентланд возглавляет в MIT подразделение “Connection Science” и лабораторию по изучению динамики поведения человека А. Барабаши, известный исследователь сетей, возглавляет Центр исследований сложных сетей. Н. Кристакис, автор бестселлера “Connected: The Surprising Power of Our Social Networks and How They Shape Our Lives” (в соавторстве с Дж. Фоулером). В Йеле возглавляет Лабораторию по исследованиям природы человека (Human Nature Lab), а также Институт исследований сетей (Yale Institute for Network Science). Постоянный автор статей в самых престижных междисциплинарных журналах – Science, Nature, PNAS. Д. Лазер, политолог, долгое время возглавлял программу по сетевому управлению в Гарварде, сейчас под его руководством проводятся исследования в области вычислительной политической науки в рамках лаборатории Lazer Lab в Северовосточном университете. Г. Кинг руководит Институтом количественной социальной науки в Гарварде.

Инфраструктурный взрыв • Федеральное финансирование: в США принят The Federal Big Data Research and Development Strategic Plan. • Журналы: Journal of Big Data, Big Data Research, Journal of Data Science, Big Data & Society. • Институты и центры: Stanford Center for Computational Social Science, Yale Institute for Network Science, Data & Society (NY), Urban Center for Computation and Data (Uchicago) и др. • Магистерские программы: Computational social science (University of Chicago). • Запрос в Wo. S “big data”: 2012 -- 36, 2013 - 106, 2014 – 293, 2015 - 493.
![Большие данные[Kitchin 2014: 2]: • большой объем; • высокая скорость накопления данных (они создаются](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-4.jpg "Большие данные[Kitchin 2014: 2]: • большой объем; • высокая скорость накопления данных (они создаются")
Большие данные[Kitchin 2014: 2]: • большой объем; • высокая скорость накопления данных (они создаются здесь и сейчас); • многообразие формы, неструктурированный и исчерпывающий характер; • высокая дискретность, что позволяет дробить данные на случаи и легко их идентифицировать; • гибкость в том, чтобы добавлять новую информацию, расширять объем и привязывать к другим типам данных. NSF: «большие, разноплановые, сложные, лонгитюдные иили распределенные данные, которые получены с помощью инструментов, сенсоров, интернет-транзакций, электронной почты, видео, кликов и других цифровых источников, доступных сегодня и в будущем» .
![[King 2009: 92] Новые данные сочетают два аспекта – это масштабные данные миллиона людей](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-5.jpg "[King 2009: 92] Новые данные сочетают два аспекта – это масштабные данные миллиона людей")
[King 2009: 92] Новые данные сочетают два аспекта – это масштабные данные миллиона людей об их мельчайших взаимодействиях. Вместо того, чтобы пытаться каждые два года извлечь мнения о политике у нескольких тысяч активистов путем искусственно созданной ситуации разговора в виде опросного интервью, мы можем использовать новые методы и извлечь десятки миллионов политических мнений, которые появляются ежедневно в блогах. Также как вместо того, чтобы изучать влияние контекста на взаимодействия людей, спрашивая респондентов об их последних контактах, мы можем собрать информацию за длительный промежуток времени об их телефонных звонках, письмах и сообщениях.
![[King, Pan, Roberts 2013] • Анализ ручного вида цензуры, когда записи в сетях подвергаются](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-6.jpg "[King, Pan, Roberts 2013] • Анализ ручного вида цензуры, когда записи в сетях подвергаются")
[King, Pan, Roberts 2013] • Анализ ручного вида цензуры, когда записи в сетях подвергаются цензуре уже после своего появления на сайте. • Записи собирались автоматически с 1382 сайтов в течение первой половины 2011 года. • При помощи компьютерного чтения текста записи были распределены по 85 тематическим группам, каждой группе исследователи присвоили уровень политической значимости (высокий, средний и низкий). Всего было собрано 3, 674, 698 записей, для анализа отобрано 127, 283 записи. Вмешательство цензора – 13%. • Блоговая активность вокруг реальных событий. Каждое событие было закодировано: имеет потенциал коллективного действия, критика цензоров, порнография, правительственная политика, другие новости.

Эпидемиологическая метафора «заражения» : слабые Vs сильные связи Какой тип связей необходим для распространения феноменов по сетям? Слабые связи простираются далеко, значит могут достичь больше людей, чем сильные связи, которые имеют тенденцию к кластеризации, то есть замыканию на плотные избыточные связи в небольшом круге. Социальное поведение подразумевает сложное влияние: людям обычно нужно вступить в контакт с несколькими источниками «инфекции» , прежде чем они люди почувствуют себя достаточно убежденными, чтобы перенять поведенческие образцы.

Социальное «заражение» • Bond, Robert M. et al. 2012. “A 61 -Million-Person Experiment in Social Influence and Political Mobilization. ” Nature 489(7415): 295– 98. • Centola, Damon. 2010. “The Spread of Behavior in an Online Social Network Experiment. ” Science 329(5996): 1194– 97. • Centola, Damon. 2011. “An Experimental Study of Homophily in the Adoption of Health Behavior. ” Science 334(6060): 1269– 72. • Christakis, Nicholas A. and James H. Fowler. 2013. “Social Contagion Theory: Examining Dynamic Social Networks and Humanbehavior. ” Statistics in Medicine 32(4): 556– 77.
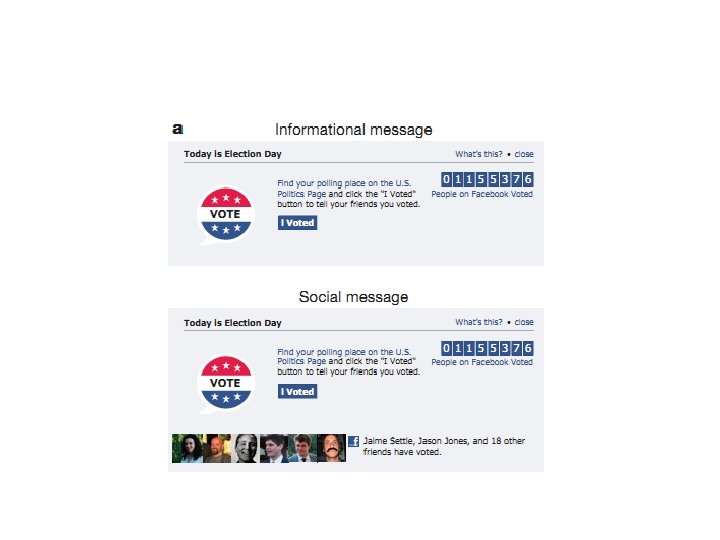
![[Bond et al. 2012] • Эксперимент 2010 г. , все американские пользователи Фейсбука с](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-9.jpg "[Bond et al. 2012] • Эксперимент 2010 г. , все американские пользователи Фейсбука с")
[Bond et al. 2012] • Эксперимент 2010 г. , все американские пользователи Фейсбука с 18 лет. • Первая группа (60, 055, 176). В новостной ленте показали «социальное сообщение» : в нем содержался призыв проголосовать, информация о месте голосования, а также показывались профили людей из числа друзей пользователя, которые уже проголосовали. • Вторая группа (611, 044). Информационное сообщение, в котором социальная составляющая сообщения отсутствовала. • Третья группа контрольная. • Действия, которые потом анализировались: нажатие ярлыка «I vote» , переход по информационной ссылке и голосование на выборах.

Количественные исследования науки • Доступность данных большого масштаба – публикаций, патентов, ссылок, грантовых заявок, которые содержат детализированную информацию об авторах. • Вместо метрик оценки научной результативности работы направлены на создание моделей, которые помогут глубже понять механизмы производства научного знания. • Выполняются учеными из самых разных дисциплин, преимущественно с естественным бэкграундом (компьютерные и инженерные науки, физика, математика).
: 721– 25")
Evans, James A. and Jacob G. Foster. 2011. “Metaknowledge. ” Science 331(6018): 721– 25
![Среди обнаруженных паттернов [Evans, Foster 2011]: • Проблема публикации только положительных исследований, тогда как](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-13.jpg "Среди обнаруженных паттернов [Evans, Foster 2011]: • Проблема публикации только положительных исследований, тогда как")
Среди обнаруженных паттернов [Evans, Foster 2011]: • Проблема публикации только положительных исследований, тогда как негативные результаты остаются в столе исследователя (file-drawer problem). • Цензура данных и выбор интерпретации в пользу уже опубликованных исследований, которые становятся «микропарадигмой» . • Избегание оригинальных стратегий в производстве научных знаний, которые очень рискованны в характере вознаграждении. • Существование «теорий-призраков» , когда способы рассуждений и доказательства истины не эксплицируются.
![[Sinatra et al. 2015] • Собрали 2, 4 миллиона статей с 1900 по 2012](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-14.jpg "[Sinatra et al. 2015] • Собрали 2, 4 миллиона статей с 1900 по 2012")
[Sinatra et al. 2015] • Собрали 2, 4 миллиона статей с 1900 по 2012 годы, опубликованные в 242 журналах, которые считаются в базе Web of Science как журналы по физике. • Проанализировали паттерн цитирования всех статей в Web of Science (40 миллионов), учитывая исходящие и входящие ссылки. Статья является физической, если в ней цитируются статьи ядра физики. • Два корпуса текстов: те, которые в библиографии оставляли ссылки на журналы по физике, и те, на которые ссылались статьи, опубликованные в журналах по физике (еще 5 миллионов).
![[Anderson 2008, цит. по Kitchin 2014: 4] [Сейчас существует лучший путь. Петабайты позволяют нам](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-15.jpg "[Anderson 2008, цит. по Kitchin 2014: 4] [Сейчас существует лучший путь. Петабайты позволяют нам")
[Anderson 2008, цит. по Kitchin 2014: 4] [Сейчас существует лучший путь. Петабайты позволяют нам сказать: «Хватит с нас корреляций» . Мы можем анализировать данные без гипотез о том, какие связи должны присутствовать в данных. Мы можем поместить все эти числа в самые большие кластеры компьютеров, которые только известны миру, и позволить статистическому алгоритму найти паттерн там, где его не видит наука… Корреляция заняла место каузальности, и наука может развиваться даже в отсутствии когерентных моделей, унифицированных теорий или любого существующего механического объяснения. Нет никакой причины, чтобы цепляться за старые дни]
![Анализ данных [Golder, Macy 2014]: • Умение работать с программными интерфейсами для скачивания данных](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-16.jpg "Анализ данных [Golder, Macy 2014]: • Умение работать с программными интерфейсами для скачивания данных")
Анализ данных [Golder, Macy 2014]: • Умение работать с программными интерфейсами для скачивания данных в структурированном виде, пригодном для анализа (по APIs). • Подготовка к анализу неструктурированных данных. Данные, полученные по APIs, требуется подготовить для обычного статистического анализа, а так как данные большие по объему, то и здесь нужны навыки программирования. • Создание веб-страниц и баз данных для хранения опросной информации и результатов экспериментов. • Манипулирование большими базами данных, которые состоят из миллионов случаев. • Машинное обучение, тематическое моделирование и т. п.

![Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-18.jpg "Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]")
Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]
![Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-19.jpg "Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]")
Различия между исследовательскими стилями социологии и компьютерной науки [Mc. Farland, Lewis, Goldberg 2015]
![[Abbott 2001] [Одна из главных причин, почему публика перестала интересоваться социологией, это наше презрение](https://present5.com/presentation/26cfa83af470bd68901c7ad55b257908/image-20.jpg "[Abbott 2001] [Одна из главных причин, почему публика перестала интересоваться социологией, это наше презрение")
[Abbott 2001] [Одна из главных причин, почему публика перестала интересоваться социологией, это наше презрение к описанию. Публика жаждет описания, но мы слишком презираем этот жанр. Сосредотачиваясь на одной только каузальности, мы отказываем в публикации статьям с чистым описанием, даже если описание выполнено с использованием количественных методов и имеет важные содержательные выводы. Коммерческие фирмы платят миллионы за такую работу. Наше общество, фактически, «описывается» самым детальным образом частными маркетинговыми фирмами. Но мы, хотя и любим воображать, что ответственны за публичное знание об обществе, презираем и описания и методы, которые обычно используются для количественных описаний. Наши социальные индикаторы представляют собой почти случайный набор переменных, пригодных для каузального анализа].
 Pontille,")
Линейная модель исследования Постановка проблемы исследования Гипотезы Метод и данные Результаты Заключение (discussion) Pontille, D. Authorship Practices and Institutional Contexts in Sociology: Elements for a Comparison of the United States and France // Science Technology Human Values. – 2003. – Vol. 28. – No. 2. – P. 217 -243.



Новые навыки • Умение работать с программными интерфейсами. Нужно уметь писать скрипт, который будет извлекать информацию. • Подготовка к анализу неструктурированных данных. • Создание веб-страниц и баз данных для хранения опросной информации и результатов экспериментов. • Манипулирование большими базами данных, которые состоят из миллионов случаев. • Машинное обучение, тематическое моделирование и т. п.

Литература • • • Abbott, Andrew. 2001. Time Matters. Chicago: Chicago University Press. Evans, James A. and Jacob G. Foster. 2011. “Metaknowledge. ” Science 331(6018): 721– 25 Halavais, Alexander. 2015. “Bigger Sociological Imaginations: Framing Big Social Data Theory and Methods. ” Information, Communication & Society 4462(June): 1– 12. King, Gary and Margaret E. Roberts. 2013. “How Censorship in China Allows Government Criticism but Silences Collective Expression. ” American Political Science Review (May): 1– 18. Kitchin, Rob. 2014. “Big Data, New Epistemologies and Paradigm Shifts. ” Big Data & Society 1(1): 1– 12. Lazer, David et al. 2009. “Computational Social Science. ” Science 323(February): 721– 23. Sinatra, Roberta, Pierre Deville, Michael Szell, Dashun Wang, and Albert-lászló Barabási. 2015. “A Century of Physics. ” Nature 11(10): 791– 96. Mc. Farland, Daniel A. , Kevin Lewis, and Amir Goldberg. 2015. “Sociology in the Era of Big Data: The Ascent of Forensic Social Science. ” American Sociologist. Bond, Robert M. et al. 2012. “A 61 -Million-Person Experiment in Social Influence and Political Mobilization. ” Nature 489(7415): 295– 98. Golder, Scott A. and Michael W. Macy. 2014. “Digital Footprints: Opportunities and Challenges for Online Social Research. ” Annual Review of Sociology 40(May): 129– 52.
26cfa83af470bd68901c7ad55b257908.ppt