ba8f9f27bbdb289776a44febf6987341.ppt
- Количество слайдов: 100



BINARY SEARCH TREE • A Binary Search Tree is a binary tree that is either an empty or in which every node contain a key and satisfies the following conditions : • The key in the left child of a node (if it exists) is less than the key in its parent node. • The key in the right child of a node (if it exists) is greater than or equal to the key in its parent node. • The left and right sub trees of the root are again binary search tree. Arbitrary binary tree Binary search tree
 ADT Implementation of BST: struct BSTNode { int data; BSTNode")
BINARY SEARCH TREE (ADT) ADT Implementation of BST: struct BSTNode { int data; BSTNode *left; BSTNode *right; } struct BSTnode*left=NULL , *right=NULL; BSTs can be implemented using either arrays or linked lists. However, linked list structures are more common and more efficient. The implementation uses nodes with two pointers namely, left and right.
 A BST implementation")
BINARY SEARCH TREE (ADT) A BST implementation

OPERATIONS- TRAVERSAL, SEARCHING, INSERTION AND DELETION • There are four basic BST operations: traversal, search, insert, and delete. • Traversals: Traverse the items in a binary search tree in preorder, inorder, or postorder • Searches: Retrieve the item with a given search key from a binary search tree • Insertion: Insert a new item into a binary search tree • Deletion Delete the item with a given search key from a binary search tree

TRAVERSALS Traversals: Traverse the items in a binary search tree in preorder, inorder, or postorder • There are 3 types of traversals: Ø 1. Pre-Order Ø 2. In-Order Ø 3. Post-Order

INORDER TRAVERSAL To traverse a non-empty binary tree using in order, perform the following operations recursively at each node, starting with the root node: 1. Traverse the left sub tree. 2. Visit the root. 3. Traverse the right sub tree. Visit the nodes in the left subtree, then visit the root of the tree, then visit the nodes in the right subtree Inorder(tree) If tree is not NULL Inorder(Left(tree)) Visit Info(tree) Inorder(Right(tree)) ("visit" means that the algorithm does something with the values in the node, e. g. , print the value)

Inorder Traversal : A E H J M T Y Visit second tree ‘J’ ‘T’ ‘E’ ‘A’ ‘H’ Visit left subtree first ‘M’ ‘Y’ Visit right subtree last

PREORDER TRAVERSAL • To traverse a non-empty binary tree in preorder, perform the following operations recursively at each node, starting with the root node: 1. Visit the root. 2. Traverse the left sub tree. 3. Traverse the right sub tree. • Visit the root of the tree first, then visit the nodes in the left subtree, then visit the nodes in the right subtree Preorder(tree) If tree is not NULL Visit Info(tree) Preorder(Left(tree)) Preorder(Right(tree))

Preorder Traversal: J E A H T M Y Visit first tree ‘J’ ‘T’ ‘E’ ‘A’ ‘H’ Visit left subtree second ‘M’ ‘Y’ Visit right subtree last

POSTORDER TRAVERSAL • To traverse a non-empty binary tree in post order, perform the following operations recursively at each node, starting with the root node: 1. Traverse the left sub tree. 2. Traverse the right sub tree. 3. Visit the root. • Visit the nodes in the left subtree first, then visit the nodes in the right subtree, then visit the root of the tree Postorder(tree) If tree is not NULL Postorder(Left(tree)) Postorder(Right(tree)) Visit Info(tree)

Postorder Traversal: A H E M Y T J Visit last tree ‘J’ ‘T’ ‘E’ ‘A’ ‘H’ Visit left subtree first ‘M’ ‘Y’ Visit right subtree second

SEARCH Searches: Retrieve the item with a given search key from a binary search tree. Three BST search algorithms: • Find the smallest node • Find the largest node • Find a requested node
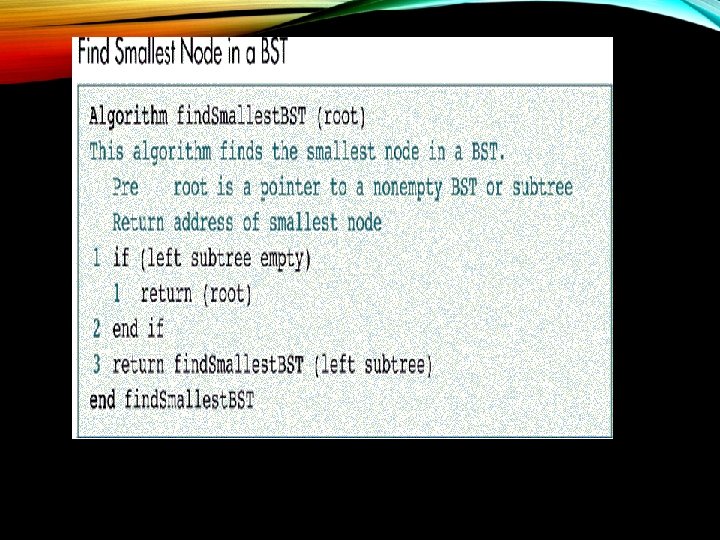
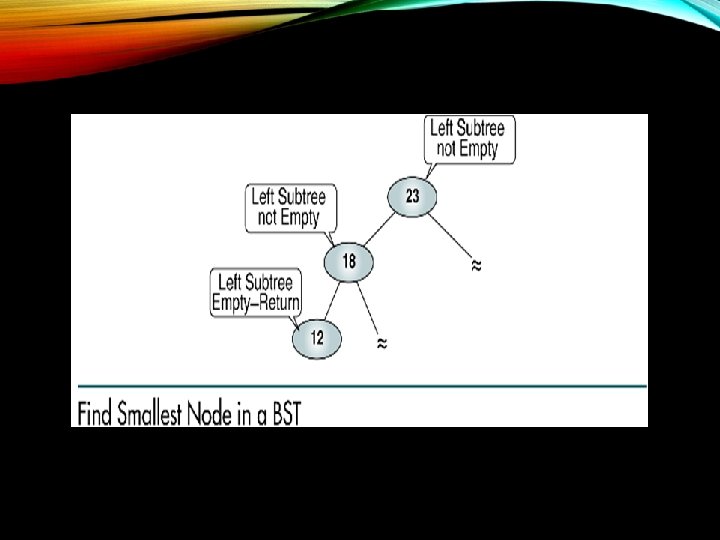
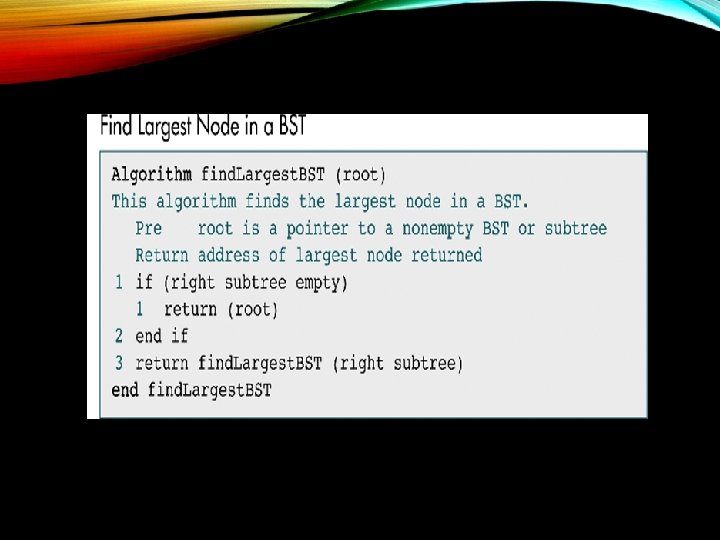


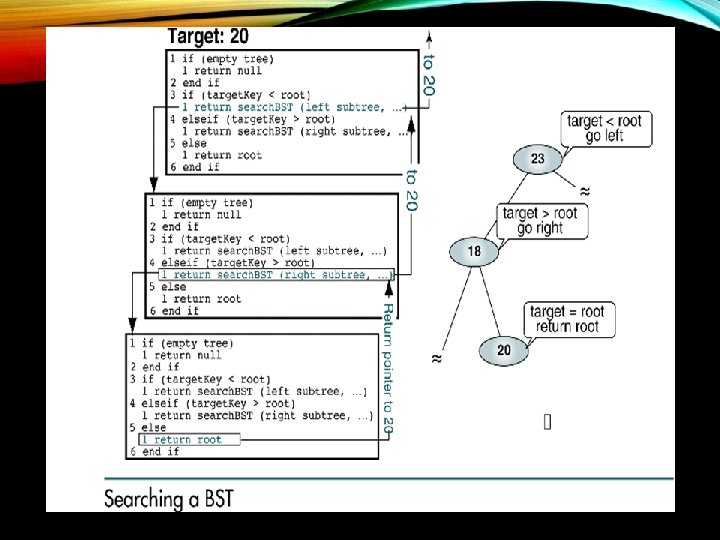

BST INSERTION • To insert data, all we need to do is follow the branches to an empty sub tree and then insert the new node. • In other words, all inserts take place at a leaf or at a leaf like node – a node that has only one null sub tree.
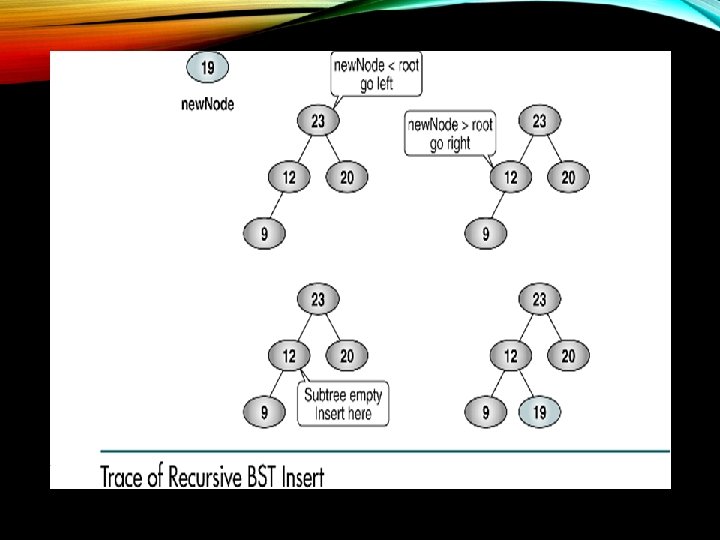
 Insert node containing new data into BST using")
Algorithm add. BST (root, new. Node) Insert node containing new data into BST using recursion. Pre root is address of current node in a BST new. Node is address of node containing data Post neew. Node inserted into the tree Return address of potential new tree root if (empty tree) set root to new. Node return new. Node end if Locate null subtree for insertion if(new. Node<root) return add. BST(left subtree, new. Node) else return add. BST(right subtree, new. Node) end if end add. BST 3/15/2018


DELETION The following possible cases are expected during a node deletion: • The node to be deleted has no children. In this case, all we need to do is delete the node. • The node to be deleted has only a right sub tree. We delete the node and attach the right sub tree to the deleted node’s parent. • The node to be deleted has only a left sub tree. We delete the node and attach the left sub tree to the deleted node’s parent. • The node to be deleted has two sub trees. It is possible to delete a node from the middle of a tree, but the result tends to create very unbalanced trees.

NODE TO BE REMOVED HAS NO CHILDREN.

NODE TO BE REMOVED HAS ONE CHILD.

NODE TO BE REMOVED HAS TWO CHILDREN

Deletion from the middle of a tree: • Rather than simply delete the node, we try to maintain the existing structure as much as possible by finding data to take the place of the deleted data. This can be done in one of the two ways. Ø We can find the largest node in the deleted node’s left subtree and move its data to replace the deleted node’s data. Ø We can find the smallest node on the deleted node’s right subtree and move its data to replace the deleted node’s data. • Either of these moves preserves the integrity of the binary search tree.

Delete the Node from BST

Program 1: BST Implementation


AVL TREES • Definition: balanced tree is a binary search tree, which is either (a) empty or (b) its left and right sub-trees are “more or less” of equal height • Definition: AVL (Adelson-Velski, Landis) tree is a binary search tree T, which is either (a) empty or (b) difference between heights of its left and right sub-trees is not greater than one and both sub-trees are also AVL trees • |hleft-hright| <=1 • A tree is said to be balanced if for each node, the number of nodes in the left subtree and the number of nodes in the right subtree differ by at most one.

Height of an AVL TREE • A tree is said to be height-balanced or AVL if for each node, the height of the left subtree and height of the right subtree differ by at most one. ØThe height of the left subtree minus the height of the right subtree of a node is called the balance of the node. For an AVL tree, the balances of the nodes are always -1, 0 or 1. ØGiven an AVL tree, if insertions or deletions are performed, the AVL tree may not remain height balanced.

AVL TREE 10 WITH BALANCE -1 FACTORS 1 7 0 3 0 1 0 5 1 40 0 8 1 30 -1 20 0 35 0 25 45 -1 0 60

AVL TREES SEARCH • To search an AVL search tree, the code for searching a binary search tree can be used without any change

Rebalancing Suppose the node to be rebalanced is X. There are 4 cases that we might have to fix (two are the mirror images of the other two): 1. 2. 3. 4. An insertion in the left subtree of the left child of X, An insertion in the right subtree of the left child of X, An insertion in the left subtree of the right child of X, or An insertion in the right subtree of the right child of X. Balance is restored by tree rotations.

SINGLE ROTATION • A single rotation switches the roles of the parent and child while maintaining the search order. • Single rotation handles the outside cases (i. e. 1 and 4). • We rotate between a node and its child. • Child becomes parent. Parent becomes right child in case 1, left child in case 4. • The result is a binary search tree that satisfies the AVL property.

Single rotation to fix case 1: Rotate right

Symmetric single rotation to fix case 4 : Rotate left

Single rotation fixes an AVL tree after insertion of 1.
.")
DOUBLE ROTATION • Single rotation does not fix the inside cases (2 and 3). • These cases require a double rotation, involving three nodes and four subtrees.

Single rotation does not fix case 2.

Left–right double rotation to fix case 2 Lift this up: first rotate left between (k 1, k 2), then rotate right betwen (k 3, k 2)

LEFT-RIGHT DOUBLE ROTATION • A left-right double rotation is equivalent to a sequence of two single rotations: • 1 st rotation on the original tree: a left rotation between X’s left-child and grandchild • 2 nd rotation on the new tree: a right rotation between X and its new left child.

Double rotation fixes AVL tree after the insertion of 5.

Right–Left double rotation to fix case 3.

AVL TREE INSERTION • First search the tree and find the place where the new item is to be inserted • Can search using algorithm similar to search algorithm designed for binary search trees • If the item is already in tree • Search ends at a nonempty subtree • Duplicates are not allowed • If item is not in AVL tree • Search ends at an empty subtree; insert the item there • After inserting new item in the tree • Resulting tree might not be an AVL tree

AVL tree before and after inserting 90 AVL tree before and after inserting 75

AVL tree before and after inserting 95 AVL tree before and after inserting 88

Item insertion into an initially empty AVL tree

EXAMPLE Insert 3, 2, 1, 4, 5, 6, 7, 16, 15, 14 3 3 3 2 2 Fig 1 2 1 3 Fig 4 Fig 2 1 2 Fig 3 1 3 Fig 5 2 1 3 Fig 6 4 4 5

2 2 1 1 4 4 3 5 Fig 8 Fig 7 6 4 4 2 2 1 5 5 6 3 Fig 9 4 Fig 10 2 1 6 3 1 6 7 3 5 Fig 11 7

4 4 2 2 6 7 3 1 1 Fig 12 1 6 3 Fig 14 5 15 7 16 16 5 Fig 13 4 7 3 16 5 2 6 15

4 4 2 1 2 6 3 Fig 15 5 15 1 7 3 6 16 7 14 5 14 Deletions can be done with similar rotations 15 Fig 16 16

DELETION • Deletion of a node x from an AVL tree requires the same basic ideas, including single and double rotations, that are used for insertion. • With each node of the AVL tree is associated a balance factor that is left high, equal or right high according, respectively, as the left subtree has height greater than, equal to, or less than that of the right subtree.

DELETION • Find the place to delete. • Swap with the in order successor. • Delete that node • Rebalance on the way up from the node you just deleted. • We may need more than one rebalance on the path from deleted node to root. Four cases Case 1: The node to be deleted is a leaf Case 2: The node to be deleted has no right child that is, its right subtree is empty Case 3: The node to be deleted has no left child that is, its left subtree is empty Case 4: The node to be deleted has a left child and a right child Cases 1– 3 are easier to handle than Case 4

AVL Tree Example : Case 1: The node to be deleted is a leaf • Now remove 53 14 11 7 4 17 12 8 53 13

AVL Tree Example: • Now remove 53, unbalanced 14 11 7 4 17 12 8 13

AVL Tree Example: • Balanced 11 7 4 14 8 12 17 13

AVL Tree Example: The node to be deleted has a left child and a right child • Balanced! Remove 11 11 7 4 14 8 12 17 13

AVL Tree Example: • Remove 11, replace it with the largest in its left branch 8 7 4 14 12 17 13

AVL Tree Example: • Remove 8, unbalanced 7 4 14 12 17 13

AVL Tree Example: • Remove 8, unbalanced 7 4 12 14 13 17

AVL Tree Example: • Balanced!! 12 7 4 14 13 Program 2: AVL Tree Implementation 17

B TREE 64 DEFINITION: A B tree of order m is an m-way search tree and hence may be empty. If non empty, then the following properties are satisfied on its extended tree representation: 1. The root node must have at least two child nodes and at most m child nodes. 2. All internal nodes other than the root node must have at least |m/2 | non empty child nodes and at most m non empty child nodes. 3. The number of keys in each internal node is one less than its number of child nodes and these keys partition the keys of the tree into sub trees. 4. All external nodes are at the same level.

B TREE 65

B TREE 66 INSERTION: For example construct a B-tree of order 5 using following numbers. 3, 14, 7, 1, 8, 5, 11, 17, 13, 6, 23, 12, 20, 26, 4, 16, 18, 24, 25, 19 The order 5 means at the most 4 keys are allowed. The internal node should have at least 3 non empty children and each leaf node must contain at least 2 keys. Step 1: Insert 3, 14, 7, 1

B TREE 67 Step 2: Insert 8, Since the node is full split the node at medium 1, 3, 7, 8, 14

B TREE Step 3: Insert 5, 11, 17 68

B TREE 69 Step 4: Now insert 13. But if we insert 13 then the leaf node will have 5 keys which is not allowed. Hence 8, 11, 13, 14, 17 is split and medium node 13 is moved up.

B TREE Step 5: insert 6, 23, 12, 20 without any split. 70

B TREE 71 Step 6: The 26 is inserted to the right most leaf node. Hence 14, 17, 20, 23, 26 the node is split and 20 will be moved up.

B TREE 72 Step 7: Insertion of node 4 causes left most node to split. The 1, 3, 4, 5, 6 causes key 4 to move up. Then insert 16, 18, 24, 25.

B TREE 73 Step 8: Finally insert 19. Then 4, 7, 13, 19, 20 needs to be split. The median 13 will be moved up to from a root node. The tree then will be -

B TREE DELETION: Consider a B-Tree 74

B TREE Delete 8 75

B TREE 76 Now we will delete 20, the 20 is not in a leaf node so we will find its successor which is 23, Hence 23 will be moved up to replace 20.

B TREE 77 Next we will delete 18. Deletion of 18 from the corresponding node causes the node with only one key, which is not desired (as per rule 4) in B-tree of order 5. The sibling node to immediate right has an extra key. In such a case we can borrow a key from parent and move spare key of sibling up.

B TREE 78 Now delete 5. But deletion of 5 is not easy. The first thing is 5 is from leaf node. Secondly this leaf node has no extra keys nor siblings to immediate left or right. In such a situation we can combine this node with one of the siblings. That means remove 5 and combine 6 with the node 1, 3. To make the tree balanced we have to move parent’s key down. Hence we will move 4 down as 4 is between 1, 3, and 6. The tree will be-

B TREE 79 But again internal node of 7 contains only one key which not allowed in B-tree. We then will try to borrow a key from sibling. But sibling 17, 24 has no spare key. Hence we can do is that, combine 7 with 13 and 17, 24. Hence the B-tree will be

B TREE 80 SEARCHING: The search operation on B-tree is similar to a search on binary search tree. Instead of choosing between a left and right child as in binary tree, B-tree makes an m -way choice. Consider a B-tree as given below.

B TREE 81 If we want to search 11 then 11 < 13 ; Hence search left node 11 > 7 ; Hence right most node 11 > 8 ; move in second block node 11 is found The running time of search operation depends upon the height of the tree. It is O(log n). C++ program example 1 , also show error simulation
 discovered first linear time string-matching algorithm by")
KMP ALGORITHM • Knuth, Morris and Pratt(KMP) discovered first linear time string-matching algorithm by analysis of the native algorithm. • It keeps the information that naive approach wasted gathered duringthe scan of the text. • By avoiding this waste of information, it achieves a running time of O(m + n). • The implementation of Knuth-Morris-Pratt algorithm is efficient because it minimizes the total number of comparisons of the pattern against the input string.

83 Let us consider an example of how to compute π for the pattern ‘p’. a b a c a Pattern I n i t i a l l y : m = length [ p]= 7 π[ 1 ]= 0 k=0 where m: the length of the pattern π[1]: prefix function k : initial potential value
![Step 1: q = 2 k=0 π[ 2 ]= 0 q 1 2 3](https://present5.com/presentation/ba8f9f27bbdb289776a44febf6987341/image-84.jpg "Step 1: q = 2 k=0 π[ 2 ]= 0 q 1 2 3")
Step 1: q = 2 k=0 π[ 2 ]= 0 q 1 2 3 4 5 6 7 P a b a c a π 0 0 Step 2: q = 3 k=0 π[ 3 ]= 1 q 1 2 3 4 5 6 7 P a b a c a π 0 0 1
![Step 3: q = 4 k=1 π[ 4 ]= 2 q 1 2 3](https://present5.com/presentation/ba8f9f27bbdb289776a44febf6987341/image-85.jpg "Step 3: q = 4 k=1 π[ 4 ]= 2 q 1 2 3")
Step 3: q = 4 k=1 π[ 4 ]= 2 q 1 2 3 4 5 6 7 P a b a c a π 0 0 1 2 Step 4: q = 5 k=2 π[ 5 ]= 3 q 1 2 3 4 5 6 7 P a b a c a π 0 0 1 2 3
![Step 5: q = 6 k=3 π[ 6 ]= 1 q 1 2 3](https://present5.com/presentation/ba8f9f27bbdb289776a44febf6987341/image-86.jpg "Step 5: q = 6 k=3 π[ 6 ]= 1 q 1 2 3")
Step 5: q = 6 k=3 π[ 6 ]= 1 q 1 2 3 4 5 6 7 P a b a c a π 0 0 1 2 3 1 Step 6: q = 7 k=1 π[ 7 ]= 1 q 1 2 3 4 5 6 7 P a b a c a π 0 0 1 2 3 1 1

• After iterating 6 times , the prefixfunction computations i s complete : The running time of the prefix function is O(m). q 1 2 3 4 5 6 7 P a b a c a π 0 0 1 2 3 1 Program 3: KMP. cpp

TEXT PROCESSING • We have seen that preprocessing the pattern speeds up pattern matching queries • After preprocessing the pattern in time proportional to the pattern length, the Boyer-Moore algorithm searches an arbitrary English text in (average) time proportional to the text length • If the text is large, immutable and searched for often (e. g. , works by Shakespeare), we may want to preprocess the text instead of the pattern in order to perform pattern matching queries in time proportional to the pattern length. • Tradeoffs in text searching 88

TRIES • A trie is a tree-based data structure for representing a set of strings, such as all the words in a text • A tries supports pattern matching queries in time proportional to the pattern size (or) • A trie is a tree-based data structure for storing strings in order to support fast pattern matching.

TRIES • Standard Tries • Compressed Tries • Suffix Tries 90

STANDARD TRIES • The standard trie for a set of strings S is an ordered tree such that: • each node but the root is labeled with a character • the children of a node are alphabetically ordered • the paths from the external nodes to the root yield the strings of S • Example: standard trie for the set of strings S = { bear, bell, bid, bull, buy, sell, stock, stop } 91
 space. Operations (find, insert, remove) take")
STANDARD TRIES • A standard trie uses O(n) space. Operations (find, insert, remove) take time O(dm) each, where: n = total size of the strings in S, m =size of the string parameter of the operation d =alphabet size,

WORD MATCHING WITH A TRIE • A standard trie supports the following operations on a preprocessed text in time O(m), where m = |X| -word matching: find the first occurence of word X in the text -prefix matching: find the first occurrence of the longest prefix of word X in the text • Each operation is performed by tracing a path in the trie starting at the root 93

COMPRESSED TRIES • Trie with nodes of degree at least 2 • Obtained from standard trie by compressing chains of redundant nodes Standard Trie: Compressed Trie: 94

COMPACT STORAGE OF COMPRESSED TRIES • A compressed trie can be stored in space O(s), where s = |S|, by using O(1) space index ranges at the nodes 95

INSERTION AND DELETION INTO/FROM A COMPRESSED TRIE 96

SUFFIX TRIE 97 • The suffix trie of a string X is the compressed trie of all the suffixes of X Tries

Compact representation:

Properties of Suffix Tries • The suffix trie for a text X of size n from an alphabet of size d -stores all the n(n-1)/2 suffixes of X in O(n) space -supports arbitrary pattern matching and prefix matching queries in O(dm) time, where m is the length of the pattern -can be constructed in O(dn) time 99

Application of Tries • The index of a search engine (collection of all searchable words) is stored into a compressed trie • Each leaf of the trie is associated with a word and has a list of pages (URLs) containing that word, called occurrence list • The trie is kept in internal memory • The occurrence lists are kept in external memory and are ranked by relevance • Boolean queries for sets of words (e. g. , Java and coffee) correspond to set operations (e. g. , intersection) on the occurrence lists • Additional information retrieval techniques are used, such as • stopword elimination (e. g. , ignore “the” “a” “is”) • stemming (e. g. , identify “add” “adding” “added”) • link analysis (recognize authoritative pages) 100
ba8f9f27bbdb289776a44febf6987341.ppt