

c33598f09a1ed5fb772d106d080385f6.ppt
- Количество слайдов: 76
 Automatic Speech Recognition Introduction
Automatic Speech Recognition Introduction
 The Human Dialogue System
The Human Dialogue System
 The Human Dialogue System
The Human Dialogue System
 Computer Dialogue Systems Dialogue Management Audition signal Automatic Natural Language Speech Recognition Understanding signal words Planning logical form Natural Language Generation Text-tospeech words signal
Computer Dialogue Systems Dialogue Management Audition signal Automatic Natural Language Speech Recognition Understanding signal words Planning logical form Natural Language Generation Text-tospeech words signal
 Computer Dialogue Systems Dialogue Mgmt. Audition signal ASR NLU words NLG Planning logical form Text-tospeech words signal
Computer Dialogue Systems Dialogue Mgmt. Audition signal ASR NLU words NLG Planning logical form Text-tospeech words signal
 Parameters of ASR Capabilities • Different types of tasks with different difficulties – – – – Speaking mode (isolated words/continuous speech) Speaking style (read/spontaneous) Enrollment (speaker-independent/dependent) Vocabulary (small < 20 wd/large >20 kword) Language model (finite state/context sensitive) Signal-to-noise ratio (high > 30 d. B/low < 10 d. B) Transducer (high quality microphone/telephone)
Parameters of ASR Capabilities • Different types of tasks with different difficulties – – – – Speaking mode (isolated words/continuous speech) Speaking style (read/spontaneous) Enrollment (speaker-independent/dependent) Vocabulary (small < 20 wd/large >20 kword) Language model (finite state/context sensitive) Signal-to-noise ratio (high > 30 d. B/low < 10 d. B) Transducer (high quality microphone/telephone)
 message noisy channel Message + Channel =Signal Decoding model:") The Noisy Channel Model (Shannon) message noisy channel Message + Channel =Signal Decoding model: find Message*= argmax P(Message|Signal) But how do we represent each of these things?
The Noisy Channel Model (Shannon) message noisy channel Message + Channel =Signal Decoding model: find Message*= argmax P(Message|Signal) But how do we represent each of these things?
 What are the basic units for acoustic information? When selecting the basic unit of acoustic information, we want it to be accurate, trainable and generalizable. Words are good units for small-vocabulary SR – but not a good choice for large-vocabulary & continuous SR: • Each word is treated individually –which implies large amount of training data and storage. • The recognition vocabulary may consist of words which have never been given in the training data. • Expensive to model interword coarticulation effects.
What are the basic units for acoustic information? When selecting the basic unit of acoustic information, we want it to be accurate, trainable and generalizable. Words are good units for small-vocabulary SR – but not a good choice for large-vocabulary & continuous SR: • Each word is treated individually –which implies large amount of training data and storage. • The recognition vocabulary may consist of words which have never been given in the training data. • Expensive to model interword coarticulation effects.
 Why phones are better units than words: an example
Why phones are better units than words: an example
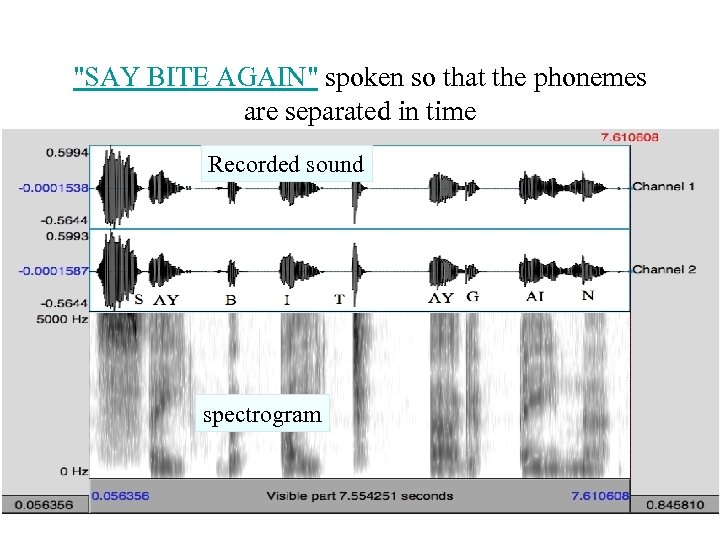 "SAY BITE AGAIN" spoken so that the phonemes are separated in time Recorded sound spectrogram
"SAY BITE AGAIN" spoken so that the phonemes are separated in time Recorded sound spectrogram
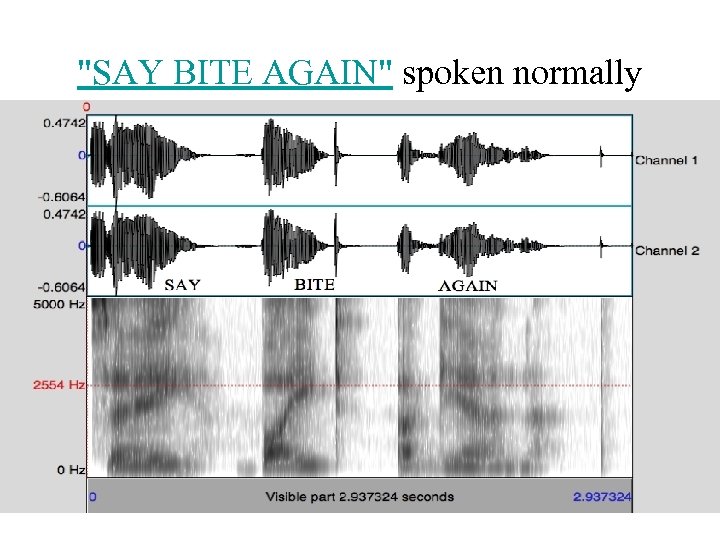 "SAY BITE AGAIN" spoken normally
"SAY BITE AGAIN" spoken normally
 And why phones are still not the perfect choice Phonemes are more trainable (there are only about 50 phonemes in English, for example) and generalizable (vocabulary independent). However, each word is not a sequence of independent phonemes! Our articulators move continuously from one position to another. The realization of a particular phoneme is affected by its phonetic neighbourhood, as well as by local stress effects etc. Different realizations of a phoneme are called allophones.
And why phones are still not the perfect choice Phonemes are more trainable (there are only about 50 phonemes in English, for example) and generalizable (vocabulary independent). However, each word is not a sequence of independent phonemes! Our articulators move continuously from one position to another. The realization of a particular phoneme is affected by its phonetic neighbourhood, as well as by local stress effects etc. Different realizations of a phoneme are called allophones.
 Example: different spectrograms for “eh”
Example: different spectrograms for “eh”
 Triphone model Each triphone captures facts about preceding and following phone • Monophone: p, t, k • Triphone: iy-p+aa • a-b+c means “phone b, preceding by phone a, followed by phone c” In practice, systems use order of 100, 000 3 phones, and the 3 phone model is the one currently used (e. g. Sphynx)
Triphone model Each triphone captures facts about preceding and following phone • Monophone: p, t, k • Triphone: iy-p+aa • a-b+c means “phone b, preceding by phone a, followed by phone c” In practice, systems use order of 100, 000 3 phones, and the 3 phone model is the one currently used (e. g. Sphynx)
 Parts of an ASR System Feature Calculation Acoustic Modeling k @ Pronunciation Modeling cat: k@t dog: dog mail: m. Al the: D&, DE … Produces Maps acoustics Maps 3 phones acoustic vectors to 3 phones to words (xt) Language Modeling cat dog: 0. 00002 cat the: 0. 0000005 the cat: 0. 029 the dog: 0. 031 the mail: 0. 054 … Strings words together
Parts of an ASR System Feature Calculation Acoustic Modeling k @ Pronunciation Modeling cat: k@t dog: dog mail: m. Al the: D&, DE … Produces Maps acoustics Maps 3 phones acoustic vectors to 3 phones to words (xt) Language Modeling cat dog: 0. 00002 cat the: 0. 0000005 the cat: 0. 029 the dog: 0. 031 the mail: 0. 054 … Strings words together
 Feature calculation interpretations
Feature calculation interpretations
 Frequency Feature calculation Time Find energy at each time step in each frequency channel
Frequency Feature calculation Time Find energy at each time step in each frequency channel
 Frequency Feature calculation Time Take Inverse Discrete Fourier Transform to decorrelate frequencies
Frequency Feature calculation Time Take Inverse Discrete Fourier Transform to decorrelate frequencies
 Feature calculation Input: Output: acoustic observations vectors -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … …
Feature calculation Input: Output: acoustic observations vectors -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … …
 Robust Speech Recognition • Different schemes have been developed for dealing with noise, reverberation – Additive noise: reduce effects of particular frequencies – Convolutional noise: remove effects of linear filters (cepstral mean subtraction) cepstrum: fourier transfor of the LOGARITHM of the spectrum
Robust Speech Recognition • Different schemes have been developed for dealing with noise, reverberation – Additive noise: reduce effects of particular frequencies – Convolutional noise: remove effects of linear filters (cepstral mean subtraction) cepstrum: fourier transfor of the LOGARITHM of the spectrum
 How do we map from vectors to word sequences? -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … ? ? ? “That you” …
How do we map from vectors to word sequences? -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … ? ? ? “That you” …
! -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6") HMM (again)! -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … Pattern recognition with HMMs “That you” …
HMM (again)! -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … Pattern recognition with HMMs “That you” …
 by breaking the problem up into") ASR using HMMs • Try to solve P(Message|Signal) by breaking the problem up into separate components • Most common method: Hidden Markov Models – Assume that a message is composed of words – Assume that words are composed of sub-word parts (3 phones) – Assume that 3 phones have some sort of acoustic realization – Use probabilistic models for matching acoustics to phones to words
ASR using HMMs • Try to solve P(Message|Signal) by breaking the problem up into separate components • Most common method: Hidden Markov Models – Assume that a message is composed of words – Assume that words are composed of sub-word parts (3 phones) – Assume that 3 phones have some sort of acoustic realization – Use probabilistic models for matching acoustics to phones to words
 Creating HMMs for word sequences: Context independent units 3 phones
Creating HMMs for word sequences: Context independent units 3 phones
 “Need” 3 phone model
“Need” 3 phone model
 Hierarchical system of HMMs HMM of a triphone Higher level HMM of a word Language model HMM of a triphone
Hierarchical system of HMMs HMM of a triphone Higher level HMM of a word Language model HMM of a triphone
 To simplify, let’s now ignore lower level HMM Each phone node has a “hidden” HMM (H 2 MM)
To simplify, let’s now ignore lower level HMM Each phone node has a “hidden” HMM (H 2 MM)
 HMMs for ASR go g g home o o o h o o o m m x 0 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 Markov model backbone composed of sequences of 3 phones (hidden because we don’t know correspondences) Acoustic observations Each line represents a probability estimate (more later)
HMMs for ASR go g g home o o o h o o o m m x 0 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 Markov model backbone composed of sequences of 3 phones (hidden because we don’t know correspondences) Acoustic observations Each line represents a probability estimate (more later)
 HMMs for ASR go g o home h o m x 0 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 Markov model backbone composed of phones (hidden because we don’t know correspondences) Acoustic observations Even with same word hypothesis, can have different alignments (red arrows). Also, have to search over all word hypotheses
HMMs for ASR go g o home h o m x 0 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 Markov model backbone composed of phones (hidden because we don’t know correspondences) Acoustic observations Even with same word hypothesis, can have different alignments (red arrows). Also, have to search over all word hypotheses
: compute Max probability sequence X= acoustic observations, (3)phones, phone") For every HMM (in hierarchy): compute Max probability sequence X= acoustic observations, (3)phones, phone sequences W= (3)phones, phone sequences, word sequences p(he|that) th a iy sh uh COMPUTE: argmax. W P(W|X) =argmax. W P(X|W)P(W)/P(X) =argmax. W P(X|W)P(W) iy y uw t p(you|that) h h d
For every HMM (in hierarchy): compute Max probability sequence X= acoustic observations, (3)phones, phone sequences W= (3)phones, phone sequences, word sequences p(he|that) th a iy sh uh COMPUTE: argmax. W P(W|X) =argmax. W P(X|W)P(W)/P(X) =argmax. W P(X|W)P(W) iy y uw t p(you|that) h h d
, need to look at (in") Search • When trying to find W*=argmax. W P(W|X), need to look at (in theory) – All possible (3 phone, word. . etc) sequences – All possible segmentations/alignments of W&X • Generally, this is done by searching the space of W – Viterbi search: dynamic programming approach that looks for the most likely path – A* search: alternative method that keeps a stack of hypotheses around • If |W| is large, pruning becomes important • Need also to estimate transition probabilities
Search • When trying to find W*=argmax. W P(W|X), need to look at (in theory) – All possible (3 phone, word. . etc) sequences – All possible segmentations/alignments of W&X • Generally, this is done by searching the space of W – Viterbi search: dynamic programming approach that looks for the most likely path – A* search: alternative method that keeps a stack of hypotheses around • If |W| is large, pruning becomes important • Need also to estimate transition probabilities
 Training: speech corpora • Have a speech corpus at hand – Should have word (and preferrably phone) transcriptions – Divide into training, development, and test sets • Develop models of prior knowledge – Pronunciation dictionary – Grammar, lexical trees • Train acoustic models – Possibly realigning corpus phonetically
Training: speech corpora • Have a speech corpus at hand – Should have word (and preferrably phone) transcriptions – Divide into training, development, and test sets • Develop models of prior knowledge – Pronunciation dictionary – Grammar, lexical trees • Train acoustic models – Possibly realigning corpus phonetically
 Acoustic Model dh a -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … a t 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … Na(m, S) P(X|state=a) • Assume that you can label each vector with a phonetic label • Collect all of the examples of a phone together and build a Gaussian model (or some other statistical model, e. g. neural networks)
Acoustic Model dh a -0. 1 0. 3 1. 4 -1. 2 2. 3 2. 6 … 0. 2 0. 1 1. 2 -1. 2 4. 4 2. 2 … a t 0. 2 0. 0 1. 2 -1. 2 4. 4 2. 2 … -6. 1 -2. 1 3. 1 2. 4 1. 0 2. 2 … Na(m, S) P(X|state=a) • Assume that you can label each vector with a phonetic label • Collect all of the examples of a phone together and build a Gaussian model (or some other statistical model, e. g. neural networks)
 Pronunciation model • Pronunciation model gives connections between phones and words 1 -pdh 1 -pa dh a pdh 1 -pt pa t pt • Multiple pronunciations (tomato): ow t m ah ey ah t ow
Pronunciation model • Pronunciation model gives connections between phones and words 1 -pdh 1 -pa dh a pdh 1 -pt pa t pt • Multiple pronunciations (tomato): ow t m ah ey ah t ow
 Training models for a sound unit
Training models for a sound unit
 Language Model • Language model gives connections between words (e. g. , bigrams: probability of two word sequences) p(he|that) dh a h iy y uw t p(you|that)
Language Model • Language model gives connections between words (e. g. , bigrams: probability of two word sequences) p(he|that) dh a h iy y uw t p(you|that)
 Lexical trees STARTING STARTED STARTUP START-UP S-T-AA-R-TD S-T-AA-R-DX-IX-NG S-T-AA-R-DX-IX-DD S-T-AA-R-T-AX-PD R TD start IX S T NG starting IX DD started DX AA PD startup R T AX PD start-up
Lexical trees STARTING STARTED STARTUP START-UP S-T-AA-R-TD S-T-AA-R-DX-IX-NG S-T-AA-R-DX-IX-DD S-T-AA-R-T-AX-PD R TD start IX S T NG starting IX DD started DX AA PD startup R T AX PD start-up
 Judging the quality of a system • Usually, ASR performance is judged by the word error rate Error. Rate = 100*(Subs + Ins + Dels) / Nwords REF: I WANT TO GO HOME *** REC: * WANT TWO GO HOME NOW SC: D C S C C I 100*(1 S+1 I+1 D)/5 = 60%
Judging the quality of a system • Usually, ASR performance is judged by the word error rate Error. Rate = 100*(Subs + Ins + Dels) / Nwords REF: I WANT TO GO HOME *** REC: * WANT TWO GO HOME NOW SC: D C S C C I 100*(1 S+1 I+1 D)/5 = 60%
 Judging the quality of a system • Usually, ASR performance is judged by the word error rate • This assumes that all errors are equal – Also, a bit of a mismatch between optimization criterion and error measurement • Other (task specific) measures sometimes used – Task completion – Concept error rate
Judging the quality of a system • Usually, ASR performance is judged by the word error rate • This assumes that all errors are equal – Also, a bit of a mismatch between optimization criterion and error measurement • Other (task specific) measures sometimes used – Task completion – Concept error rate
 Sphinx 4 http: //cmusphinx. sourceforge. net
Sphinx 4 http: //cmusphinx. sourceforge. net
 Sphinx 4 Implementation
Sphinx 4 Implementation
 Sphinx 4 Implementation
Sphinx 4 Implementation
 Frontend • Feature extractor
Frontend • Feature extractor
") Frontend • Feature extractor • Mel-Frequency Cepstral Coefficients Feature vectors (MFCCs)
Frontend • Feature extractor • Mel-Frequency Cepstral Coefficients Feature vectors (MFCCs)
 • Acoustic Observations") Hidden Markov Models (HMMs) • Acoustic Observations
Hidden Markov Models (HMMs) • Acoustic Observations
 • Acoustic Observations • Hidden States") Hidden Markov Models (HMMs) • Acoustic Observations • Hidden States
Hidden Markov Models (HMMs) • Acoustic Observations • Hidden States
 • Acoustic Observations • Hidden States • Acoustic Observation likelihoods") Hidden Markov Models (HMMs) • Acoustic Observations • Hidden States • Acoustic Observation likelihoods
Hidden Markov Models (HMMs) • Acoustic Observations • Hidden States • Acoustic Observation likelihoods
 “Six”") Hidden Markov Models (HMMs) “Six”
Hidden Markov Models (HMMs) “Six”
 Sphinx 4 Implementation
Sphinx 4 Implementation
 Linguist • Constructs the search graph of HMMs from: – – Acoustic model Statistical Language model ~or~ Grammar Dictionary
Linguist • Constructs the search graph of HMMs from: – – Acoustic model Statistical Language model ~or~ Grammar Dictionary
 Acoustic Model • Constructs the HMMs of phones • Produces observation likelihoods
Acoustic Model • Constructs the HMMs of phones • Produces observation likelihoods
 Acoustic Model • • Constructs the HMMs for units of speech Produces observation likelihoods Sampling rate is critical! WSJ vs. WSJ_8 k
Acoustic Model • • Constructs the HMMs for units of speech Produces observation likelihoods Sampling rate is critical! WSJ vs. WSJ_8 k
 Acoustic Model • • • Constructs the HMMs for units of speech Produces observation likelihoods Sampling rate is critical! WSJ vs. WSJ_8 k TIDIGITS, RM 1, AN 4, HUB 4
Acoustic Model • • • Constructs the HMMs for units of speech Produces observation likelihoods Sampling rate is critical! WSJ vs. WSJ_8 k TIDIGITS, RM 1, AN 4, HUB 4
 Language Model • Word likelihoods
Language Model • Word likelihoods
 Language Model • ARPA format Example: 1 -grams: -3. 7839 board -0. 1552 -2. 5998 bottom -0. 3207 -3. 7839 bunch -0. 2174 2 -grams: -0. 7782 as the -0. 2717 -0. 4771 at all 0. 0000 -0. 7782 at the -0. 2915 3 -grams: -2. 4450 in the lowest -0. 5211 in the middle -2. 4450 in the on
Language Model • ARPA format Example: 1 -grams: -3. 7839 board -0. 1552 -2. 5998 bottom -0. 3207 -3. 7839 bunch -0. 2174 2 -grams: -0. 7782 as the -0. 2717 -0. 4771 at all 0. 0000 -0. 7782 at the -0. 2915 3 -grams: -2. 4450 in the lowest -0. 5211 in the middle -2. 4450 in the on
 public <basic. Cmd> = <start. Polite> <command> <end. Polite>; public") Grammar (example: command language) public
Grammar (example: command language) public
 Dictionary • Maps words to phoneme sequences
Dictionary • Maps words to phoneme sequences
 Dictionary • Example from cmudict. 06 d POULTICES POULTON POULTRY POUNCED POUNCEY POUNCING POUNCY P OW L T AH S IH Z P AW L T AH N P OW L T R IY P AW N S T P AW N S IY P AW N S IH NG P UW NG K IY
Dictionary • Example from cmudict. 06 d POULTICES POULTON POULTRY POUNCED POUNCEY POUNCING POUNCY P OW L T AH S IH Z P AW L T AH N P OW L T R IY P AW N S T P AW N S IY P AW N S IH NG P UW NG K IY
 Sphinx 4 Implementation
Sphinx 4 Implementation
 Search Graph
Search Graph
 Search Graph
Search Graph
 Search Graph • Can be statically or dynamically constructed
Search Graph • Can be statically or dynamically constructed
 Sphinx 4 Implementation
Sphinx 4 Implementation
 Decoder • Maps feature vectors to search graph
Decoder • Maps feature vectors to search graph
 Search Manager • Searches the graph for the “best fit”
Search Manager • Searches the graph for the “best fit”
 Search Manager • Searches the graph for the “best fit” • P(sequence of feature vectors| word/phone) • aka. P(O|W) -> “how likely is the input to have been generated by the word”
Search Manager • Searches the graph for the “best fit” • P(sequence of feature vectors| word/phone) • aka. P(O|W) -> “how likely is the input to have been generated by the word”
 F ay ay v v v F f ay ay v v F f f ay ay v v v F f f f ay ay ay v F f f ay ay v F f f f ay ay ay v …
F ay ay v v v F f ay ay v v F f f ay ay v v v F f f f ay ay ay v F f f ay ay v F f f f ay ay ay v …
 Viterbi Search Time O 1 O 2 O 3
Viterbi Search Time O 1 O 2 O 3
 Pruner • Uses algorithms to weed out low scoring paths during decoding
Pruner • Uses algorithms to weed out low scoring paths during decoding
 Result • Words!
Result • Words!
 Word Error Rate • Most common metric • Measure the # of modifications to transform recognized sentence into reference sentence
Word Error Rate • Most common metric • Measure the # of modifications to transform recognized sentence into reference sentence
 Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ”
Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ”
 Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ” • Requires 2 deletions, 1 substitution
Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ” • Requires 2 deletions, 1 substitution
 Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ”
Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ”
 Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ” • D S D
Word Error Rate • Reference: “This is a reference sentence. ” • Result: “This is neuroscience. ” • D S D
 Installation details • http: //cmusphinx. sourceforge. net/wiki/sphin x 4: howtobuildand_run_sphinx 4 • Student report on NLP course web site
Installation details • http: //cmusphinx. sourceforge. net/wiki/sphin x 4: howtobuildand_run_sphinx 4 • Student report on NLP course web site