f3e6639bd5e590e0f11d18e0388cfaa3.ppt
- Количество слайдов: 24



Architecture for graphical maps of Web contents Krzysztof Ciesielski, Michal Draminski, Mieczyslaw Klopotek, Mariusz Kujawiak, Slawomir Wierzchon Institute of Computer Science, PAS, Warsaw University of Podlasie, Siedlce Białystok University of Technology

Agenda Motivation Architecture Map interface Map creation Map clustering Execution time of map creation Convergence of map creation Future direction

Motivation the Web and also intranets become increasingly content-rich a good way of presenting massive document sets in an understandable way will be crucial in the near future. The BEATCA project envisages creation of a user-friendly content presentation of moderate size document collections (with millions of documents).

Our approach The presentation method is based on the Web. SOM's map idea and is enriched with novel methods of document analysis, clustering and visualization. A special architecture has been elaborated to enable experiments with various brands of map creation algorithm. Our research targets at creation of a full-fledged search engine (with working name Beatca) for small collections of documents capable of representing on-line replies to queries in graphical form on a document map.

Architecture We follow the general architecture for search engines, the preparation of documents for retrieval is done by an indexer, which turns the HTML etc. representation of a document into a vector-space model representation, the map creator is applied, turning the vector-space representation into a form appropriate for on-the-fly map generation, Maps are used by the query processor responding to user's queries.

Architecture. . . . Base Registry Robot Indexer Search Engine Optimizer HT Base Vector Base Indexer Mapper Optimizer . . . . Vector Base Map HT Base . .

User interface Search results are presented on a document map The map can have one of two forms: – The traditional flat map rotating torus
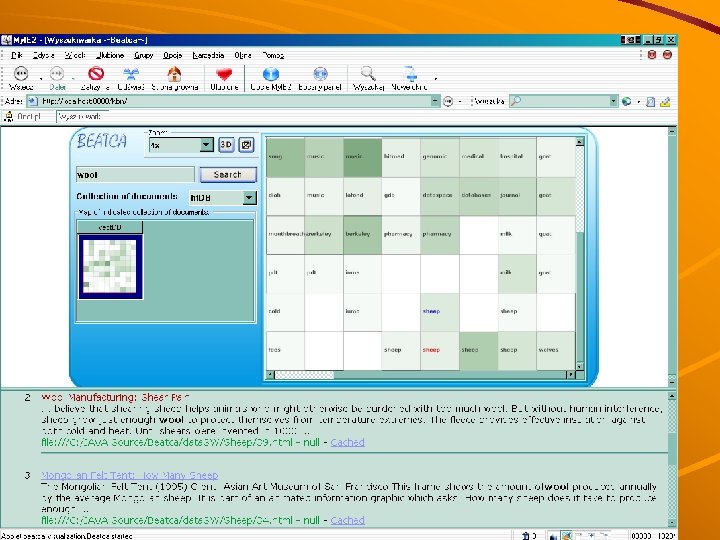

Rotating torus representation of the map

How are the maps created A modified Web. SOM method is used Based on our observation of radical reduction of document vector variation Multi-level maps

A map for 20 newsgroups

A detailed map for Syskill&Webert 4 document groups

A high level map for Syskill&Webert 4 document groups

Clustering groups documents A fuzzy isodata method used Entropy based Initialisation with Minimum weight spanning tree Clustered documents are labeled by weighed centroids of cell reference vectors modified with entropy

Approximate clustering using minimal spanning tree for 5 newsgroups
 Cluster #1 sci. math Cluster #2")
Word Rank Label candidates for clusters (5 newsgroups) Cluster #1 sci. math Cluster #2 sci. med / sci. math Cluster #3 talk. religion misc (a) Cluster #4 soc. culture. israel Cluster #5 comp. windows. x Cluster #6 talk. religion misc (b) 1 die cipher men israel boot funding 2 probable block raped palestinian windows study 3 theory stream women gun files taxes 4 registers key children aziz menus stock 5 mathematics otp child iraqis lib health 6 equation algorithms sex koppel icon market 7 kr hsm soc israeli label social 8 cos simon father jews folder mercer 9 sequence combinations paternity resolution msvcrtd governing 10 tex shen feminist oliver pcr vaccinations 11 space distinction trolling utah daffyd measurement 12 gravitational encryption white johnc shortcut ss 13 wave epimethius lib nra netzero duke 14 latex randomness england 1991 obj quantum 15 pdf smartcard support firearms tab jama 16 mac entropy woman settlements kernel hopems 17 files yahoo black palestine duck bushes 18 israel ici brother permitted installed computer 19 debt model chat gis backup companies 20 unsigned lottery media iraq desktop diabetes

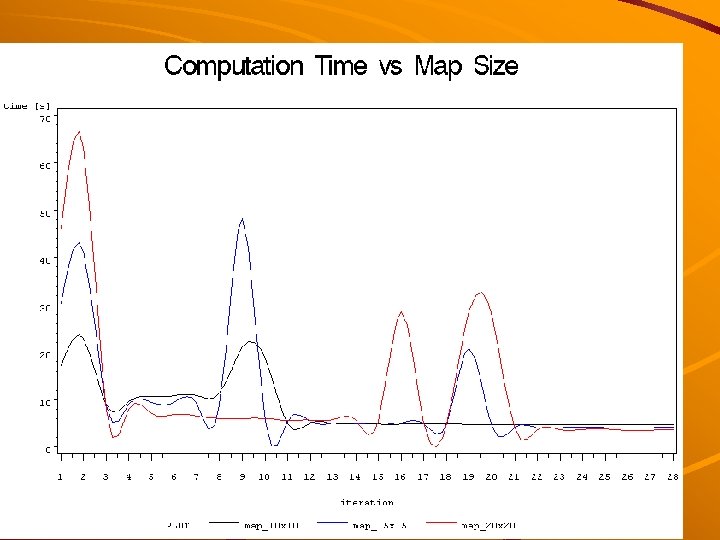
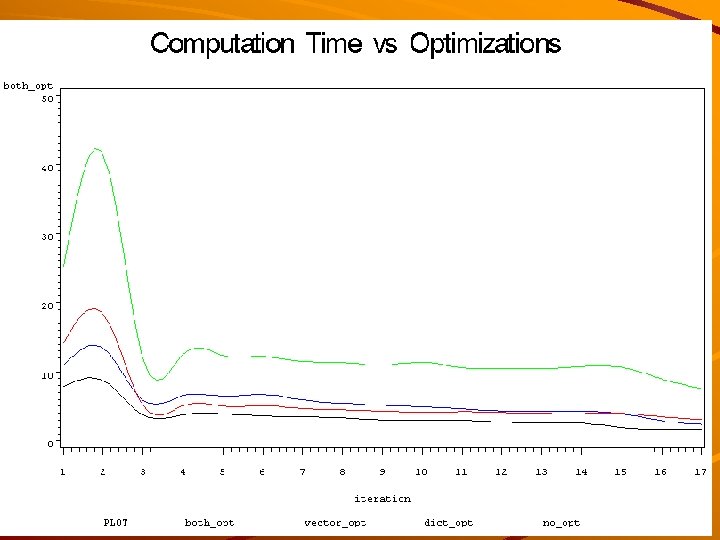
Experiments with execution time The impact of the following factors on the speed o 9 f map creation was investigated: Map size Optimization method – Dictionary optimization (extreme entropy and extreme frequency) – Reference vector optimization

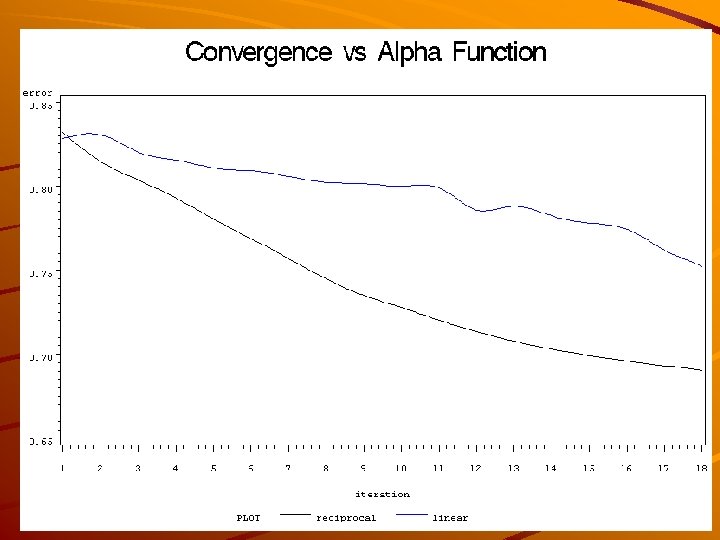
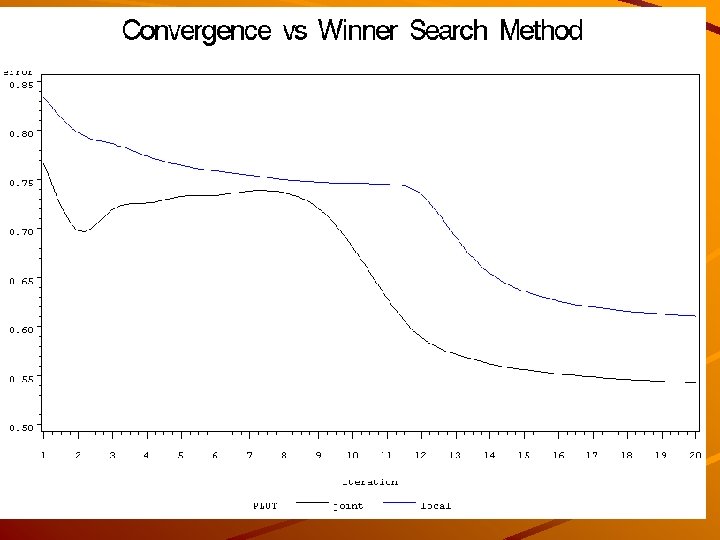
Convergence We checked the convergence of the maps to a stable state depending on Type of alpha function (search radius reduction) Type of winner search method

Future research We intend to integrate Bayesian and immune system methodologies with Web. SOM in order to achieve new clustering effects. Bayesian networks will be applied in particular to classify documents, to accelerate document clustering processes, to construct a thesaurus supporting query enrichment, and to keyword extraction. Immuno-genetic systems will be used for adaptive document clustering by referring to the mechanism of socalled metadynamics, for extraction of compact characteristics of document groups by exploitation of the mechanism of construction of universal and specialized antibodies , and for visualisation and adjustment of resolution of document maps.

Thank you Any questions?
f3e6639bd5e590e0f11d18e0388cfaa3.ppt