6fe524564f9e2f392f8557df4d8361c6.ppt
- Количество слайдов: 56

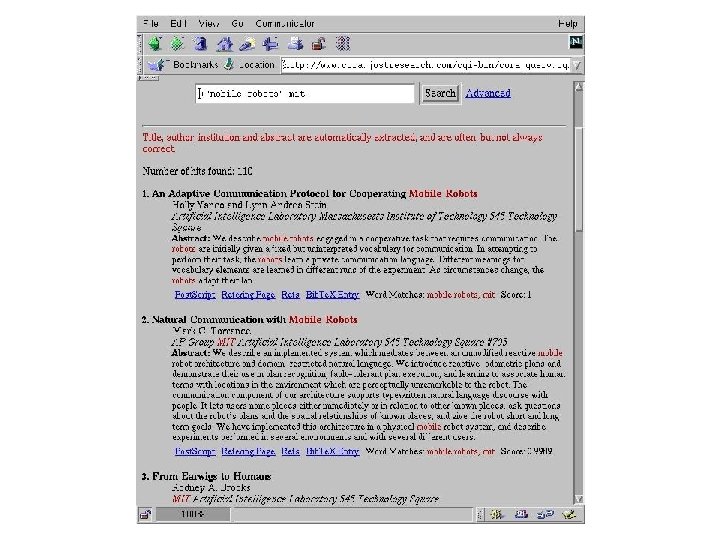

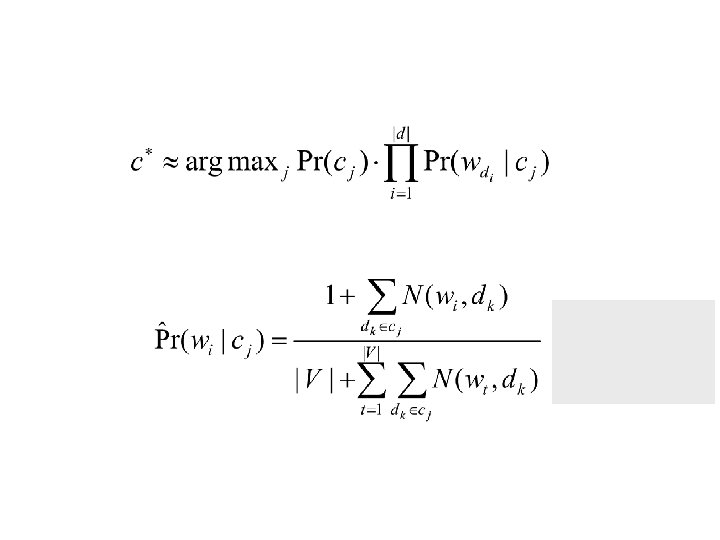

 Larry Wasserman (CMU Statistics)") Andrew Mc. Callum Roni Rosenfeld Tom Mitchell Andrew Ng (Berkeley) Larry Wasserman (CMU Statistics)
Andrew Mc. Callum Roni Rosenfeld Tom Mitchell Andrew Ng (Berkeley) Larry Wasserman (CMU Statistics)
 “Shrinkage” / “Deleted Interpolation”
“Shrinkage” / “Deleted Interpolation”
 E-step M-step
E-step M-step
 E-step M-step
E-step M-step
 15 classes, 15 k documents, 1. 7 million words, 52 k vocabulary
15 classes, 15 k documents, 1. 7 million words, 52 k vocabulary
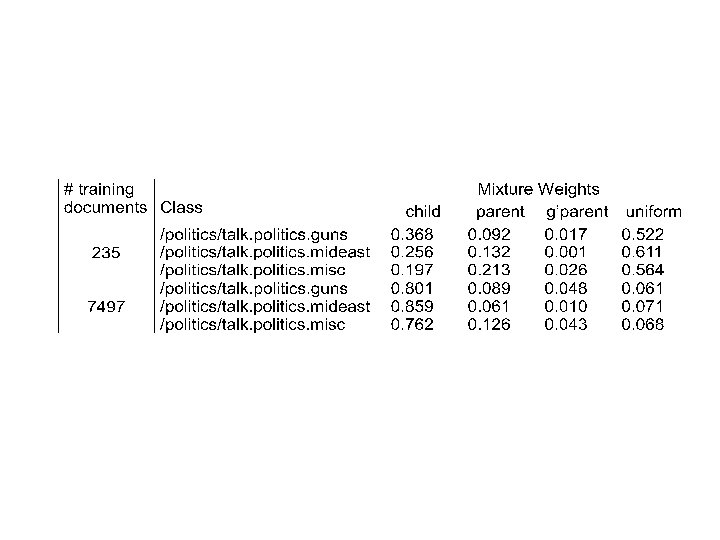
 71 classes, 6. 5 k documents, 1. 2 million words, 30 k vocabulary
71 classes, 6. 5 k documents, 1. 2 million words, 30 k vocabulary
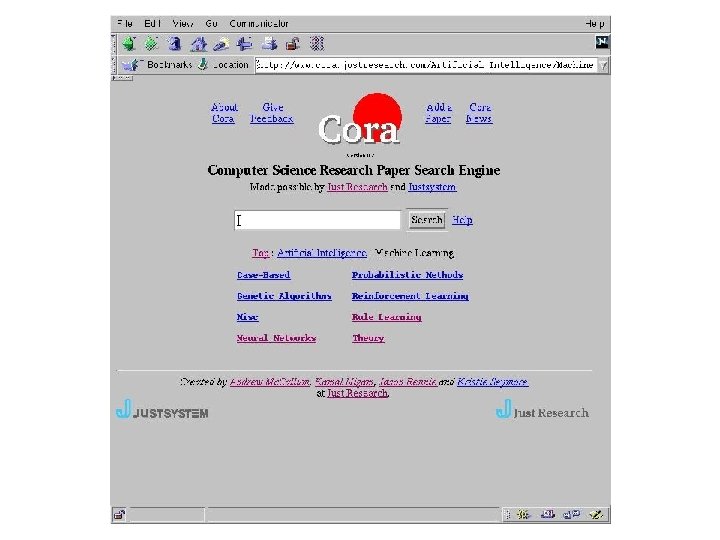
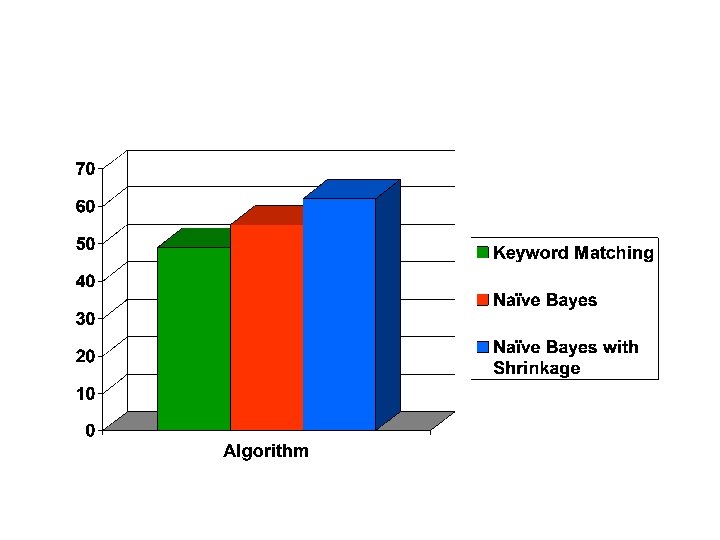
 Industry Sector Classification Accuracy
Industry Sector Classification Accuracy
 Newsgroups Classification Accuracy
Newsgroups Classification Accuracy
 264 classes, 14 k documents, 3 million words, 76 k vocabulary
264 classes, 14 k documents, 3 million words, 76 k vocabulary
 Yahoo Science Classification Accuracy
Yahoo Science Classification Accuracy




 Text Classification with Labeled and Unlabeled Documents Kamal Nigam Andrew Mc. Callum Sebastian Thrun Tom Mitchell
Text Classification with Labeled and Unlabeled Documents Kamal Nigam Andrew Mc. Callum Sebastian Thrun Tom Mitchell
 Can we use the unlabeled documents to increase accuracy?
Can we use the unlabeled documents to increase accuracy?
 Build a classification model using limited labeled data Use model to estimate the labels of the unlabeled documents
Build a classification model using limited labeled data Use model to estimate the labels of the unlabeled documents
 Baseball Ice Skating
Baseball Ice Skating
 Expectation Maximization is a class of iterative algorithms for maximum likelihood estimation with incomplete data.
Expectation Maximization is a class of iterative algorithms for maximum likelihood estimation with incomplete data.
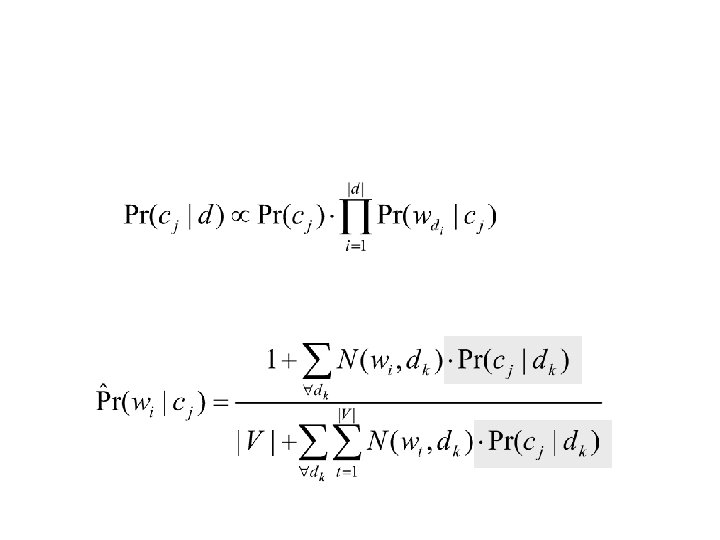
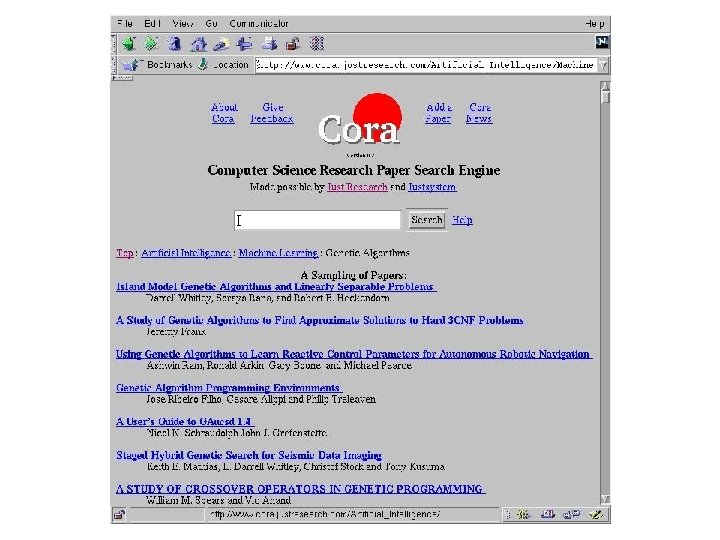
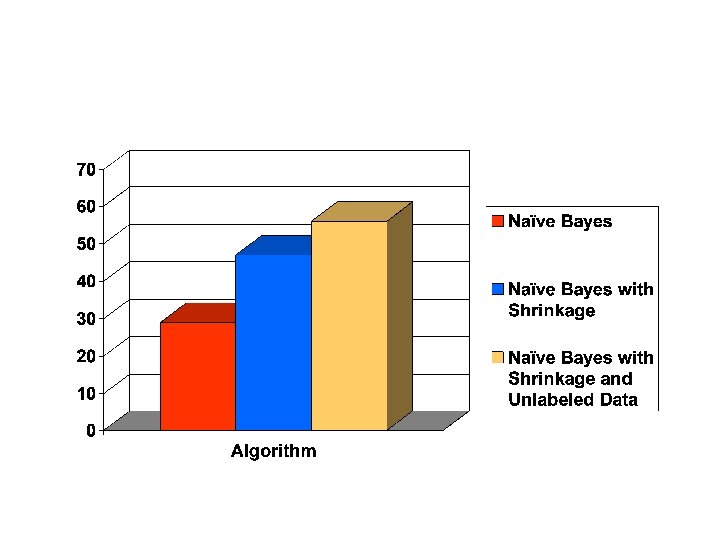
 4 classes, 4199 documents from CS academic departments
4 classes, 4199 documents from CS academic departments

 X X X = unlabeled
X X X = unlabeled
 X X X
X X X
 20 class labels, 20, 000 documents 62 k unique words
20 class labels, 20, 000 documents 62 k unique words
 Newsgroups Classification Accuracy varying # labeled documents
Newsgroups Classification Accuracy varying # labeled documents

 Web. KB Classification Accuracy varying # labeled documents
Web. KB Classification Accuracy varying # labeled documents
 Web. KB Classification Accuracy varying weight of unlabeled data
Web. KB Classification Accuracy varying weight of unlabeled data

 135 class labels, 12902 documents
135 class labels, 12902 documents
 XX
XX
 Reuters 21578 Precision-Recall Breakeven
Reuters 21578 Precision-Recall Breakeven