a32bade6ff088a2f7e806bc2aa8894eb.ppt
- Количество слайдов: 83



An introduction to biological databases August 2001

Database or databank ? At the beginning, subtle distinctions were done between databases and databanks (in UK, but not in the USA), such as: « Database management programs for the gestion of databanks » From now on, the term « database » (db) is usually preferred
 updated periodically (release)")
What is a database ? A collection of structured searchable (index) updated periodically (release) cross-referenced (hyperlinks) -> table of contents -> new edition -> links with other db data Includes also associated tools (software) necessary for db access, db updating, db information insertion, db information deletion…. Data storage managment: flat files, relational databases…

Databases: a « flat file » example « Introduction To Database » Teacher Database (flat file, 3 entries) Accession number: 1 First Name: Amos Last Name: Bairoch Course: DEA=oct-nov-dec 2000 http: //www. expasy. org/people/amos. html // Accession number: 2 First Name: Laurent Last name: Falquet Course: EMBnet=sept 2000, sept 2001; DEA=oct-nov-dec 2000; // Accession number 3: First Name: Marie-Claude Last name: Blatter Garin Course: EMBnet=sept 2000; sept 2001; DEA=oct-nov-dec 2000; http: //www. expasy. org/people/Marie-Claude. Blatter-Garin. html // Easy to manage: all the entries are visible at the same time !
 Relational database ( « table file")
Databases: a « relational » example (cont. ) Relational database ( « table file » ): Teacher Accession number Education Amos 1 Biochemistry Laurent 2 Biochemistry M-Claude 3 Biochemistry Course Date Involved teachers DEA Oct-nov-dec 2000 1, 3 EMBnet Sept 2000, Sept 2001 2, 3 Easier to manage; choice of the output

Why biological databases ? Explosive growth in biological data Data (sequences, 3 D structures, 2 D gel analysis, MS analysis…. ) are no longer published in a conventional manner, but directly submitted to databases Essential tools for biological research, as classical publications used to be !

Some statistics More than 1000 different databases Generally accessible through the web ( Variable size: <100 Kb to >10 Gb Google: http: //www. google. ch/ Biohunt: http: //www. expasy. org/Bio. Hunt/ Amos’ links: www. expasy. ch/alinks. html DNA: > 10 Gb Protein: 1 Gb 3 D structure: 5 Gb Other: smaller Update frequency: daily to annually

Biological databases Some databases in the field of molecular biology… AATDB, Ace. Db, ACUTS, ADB, AFDB, AGIS, AMSdb, ARR, As. Db, BBDB, BCGD, Beanref, Biolmage, Bio. Mag. Res. Bank, BIOMDB, BLOCKS, Bov. GBASE, BOVMAP, BSORF, BTKbase, CANSITE, Carb. Bank, CARBHYD, CATH, CAZY, CCDC, CD 4 OLbase, CGAP, Chick. GBASE, Colibri, COPE, Cotton. DB, CSNDB, CUTG, Cyano. Base, db. CFC, db. EST, db. STS, DDBJ, DGP, Dicty. Db, Picty_c. DB, DIP, DOGS, DOMO, DPD, DPlnteract, ECDC, ECGC, EC 02 DBASE, Eco. Cyc, Eco. Gene, EMBL, EMD db, ENZYME, EPD, Epo. DB, ESTHER, Fly. Base, Fly. View, GCRDB, GENATLAS, Genbank, Gene. Cards, Genline, Gen. Link, GENOTK, Gen. Prot. EC, GIFTS, GPCRDB, GRAP, GRBase, g. RNAsdb, GRR, GSDB, HAEMB, HAMSTERS, HEART-2 DPAGE, HEXAdb, HGMD, HIDB, HIDC, Hl. Vdb, Hot. Molec. Base, HOVERGEN, HPDB, HSC-2 DPAGE, ICN, ICTVDB, IL 2 RGbase, IMGT, Kabat, KDNA, KEGG, Klotho, LGIC, MAD, Maize. Db, MDB, Medline, Mendel, MEROPS, MGDB, MGI, MHCPEP 5 Micado, Mito. Dat, MITOMAP, MJDB, Mmt. DB, Mol-R-Us, MPDB, MRR, Mut. Base, Myc. DB, NRSub, 0 -lyc. Base, OMIA, OMIM, OPD, ORDB, OWL, PAHdb, Pat. Base, PDB, PDD, Pfam, Phospho. Base, Pig. BASE, PIR, PKR, PMD, PPDB, PRESAGE, PRINTS, Pro. Dom, Prolysis, PROSITE, PROTOMAP, Rat. MAP, RDP, REBASE, RGP, SBASE, SCOP, Seq. Anai. Ref, SGD, SGP, Sheep. Map, Soybase, SPAD, SRNA db, SRPDB, STACK, Sty. Gene, Sub 2 D, Subti. List, SWISS-2 DPAGE, SWISS-3 DIMAGE, SWISSMODEL Repository, SWISS-PROT, Tel. DB, TGN, tm. RDB, TOPS, TRANSFAC, TRR, Uni. Gene, URNADB, V BASE, VDRR, Vector. DB, WDCM, WIT, Worm. Pep, YEPD, YPM, etc. . . . !!!!

Distribution of sequence databases Books, articles Computer tapes Floppy disks CD-ROM FTP On-line services WWW DVD 1968 -> 1985 1982 ->1992 1984 -> 1990 1989 -> ? 1982 -> 1994 1993 -> ? 2001 -> ?
 -> Primary db Genomics Protein")
Categories of databases for Life Sciences Sequences (DNA, protein) -> Primary db Genomics Protein domain/family -> Secondary db Mutation/polymorphism Proteomics (2 D gel, MS) 3 D structure -> Structure db Metabolism Bibliography Others

Sequence Databases: some « technical » definitions Data storage management: flat file: text file relational (e. g. , Oracle) object oriented (rare in biological field) Flat file format: fasta GCG NBRF/PIR MSF…. standardized format ?
")
Ideal minimal content of a « sequence » db Sequences !! Accession number (AC) References Taxonomic data ANNOTATION/CURATION Keywords Cross-references Documentation

Sequence database: example SWISS-PROT Flat file taxonomy reference annotations Cross-references Keywords ID AC DT DT DT DE GN OS OC OC OX RN RP RX RA RA RA RT RT RL …. CC CC … DR DR DR …. EPO_HUMAN STANDARD; PRT; 193 AA. P 01588; Q 9 UHA 0; Q 9 UEZ 5; Q 9 UDZ 0; 21 -JUL-1986 (Rel. 01, Created) 21 -JUL-1986 (Rel. 01, Last sequence update) 20 -AUG-2001 (Rel. 40, Last annotation update) Erythropoietin precursor. EPO. Homo sapiens (Human). Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. NCBI_Tax. ID=9606; [1] SEQUENCE FROM N. A. MEDLINE=85137899; Pub. Med=3838366; Jacobs K. , Shoemaker C. , Rudersdorf R. , Neill S. D. , Kaufman R. J. , Mufson A. , Seehra J. , Jones S. S. , Hewick R. , Fritsch E. F. , Kawakita M. , Shimizu T. , Miyake T. ; "Isolation and characterization of genomic and c. DNA clones of human erythropoietin. "; Nature 313: 806 -810(1985). -!- FUNCTION: ERYTHROPOIETIN IS THE PRINCIPAL HORMONE INVOLVED IN THE REGULATION OF ERYTHROCYTE DIFFERENTIATION AND THE MAINTENANCE OF A PHYSIOLOGICAL LEVEL OF CIRCULATING ERYTHROCYTE MASS. -!- SUBCELLULAR LOCATION: SECRETED. -!- TISSUE SPECIFICITY: PRODUCED BY KIDNEY OR LIVER OF ADULT MAMMALS AND BY LIVER OF FETAL OR NEONATAL MAMMALS. -!- PHARMACEUTICAL: Available under the names Epogen (Amgen) and Procrit (Ortho Biotech). EMBL; X 02158; CAA 26095. 1; -. EMBL; X 02157; CAA 26094. 1; -. EMBL; M 11319; AAA 52400. 1; -. EMBL; AF 053356; AAC 78791. 1; -. EMBL; AF 202308; AAF 23132. 1; -. EMBL; AF 202306; AAF 23132. 1; JOINED. KW Erythrocyte maturation; Glycoprotein; Hormone; Signal; Pharmaceutical.
 annotation sequence FT SIGNAL 1 27 FT CHAIN 28")
Sequence database: example (cont. ) annotation sequence FT SIGNAL 1 27 FT CHAIN 28 193 ERYTHROPOIETIN. FT PROPEP 190 193 MAY BE REMOVED IN PROCESSED PROTEIN. FT DISULFID 34 188 FT DISULFID 56 60 FT CARBOHYD 51 51 N-LINKED (GLCNAC. . . ). FT CARBOHYD 65 65 N-LINKED (GLCNAC. . . ). FT CARBOHYD 110 N-LINKED (GLCNAC. . . ). FT CARBOHYD 153 O-LINKED (GALNAC. . . ). FT VARIANT 131 132 SL -> NF (IN AN HEPATOCELLULAR FT CARCINOMA). FT / FTId=VAR_009870. FT VARIANT 149 P -> Q (IN AN HEPATOCELLULAR CARCINOMA). FT / FTId=VAR_009871. FT CONFLICT 40 40 E -> Q (IN REF. 1; CAA 26095). FT CONFLICT 85 85 Q -> QQ (IN REF. 5). FT CONFLICT 140 G -> R (IN REF. 1; CAA 26095). ** ** ######### INTERNAL SECTION ######### **CL 7 q 22; SQ SEQUENCE 193 AA; 21306 MW; C 91 F 0 E 4 C 26 A 52033 CRC 64; MGVHECPAWL WLLLSLLSLP LGLPVLGAPP RLICDSRVLE RYLLEAKEAE NITTGCAEHC SLNENITVPD TKVNFYAWKR MEVGQQAVEV WQGLALLSEA VLRGQALLVN SSQPWEPLQL HVDKAVSGLR SLTTLLRALG AQKEAISPPD AASAAPLRTI TADTFRKLFR VYSNFLRGKL KLYTGEACRT GDR //

Sequence database: example …a SWISS-PROT entry, in fasta format: >sp|P 01588|EPO_HUMAN ERYTHROPOIETIN PRECURSOR - Homo sapiens (Human). MGVHECPAWLWLLLSLLSLPLGLPVLGAPPRLICDSRVLERYLLEAKEAE NITTGCAEHCSLNENITVPDTKVNFYAWKRMEVGQQAVEVWQGLALLSEA VLRGQALLVNSSQPWEPLQLHVDKAVSGLRSLTTLLRALGAQKEAISPPD AASAAPLRTITADTFRKLFRVYSNFLRGKLKLYTGEACRTGDR

Database 1: nucleotide sequence Laurent Falquet
, gene nomenclature and links")
Databases 2: genomics Contain information on genes, gene location (mapping), gene nomenclature and links to sequence databases; has usually no sequence; Exist for most organisms important for life science research; Examples: MIM, GDB (human), MGD (mouse), Fly. Base (Drosophila), SGD (yeast), Maize. DB (maize), Subti. List (B. subtilis), etc. ; Format: generally relational (Oracle, Sy. Base or Ace. Db).

MIM OMIM™: Online Mendelian Inheritance in Man a catalog of human genes and genetic disorders contains a summary of literature, pictures, and reference information. It also contains numerous links to articles and sequence information.

MIM: example *133170 ERYTHROPOIETIN; EPO Alternative titles; symbols EP TABLE OF CONTENTS TEXT REFERENCES SEE ALSO CONTRIBUTORS CREATION DATE EDIT HISTORY Database Links Gene Map Locus: 7 q 21 Note: pressing the symbol will find the citations in MEDLINE whose text most closely matches the text of the preceding OMIM paragraph, using the Entrez MEDLINE neighboring function. TEXT Human erythropoietin is an acidic glycoprotein hormone with molecular weight 34, 000. As the prime regulator of red cell production, its major functions are to promote erythroid differentiation and to initiate hemoglobin synthesis. Sherwood and Shouval (1986) described a human renal carcinoma cell line that continuously produces erythropoietin. Eschbach et al. (1987) demonstrated the effectiveness of recombinant human erythropoietin in treating the anemia of end-stage renal disease. Lee-Huang (1984) cloned human erythropoietin c. DNA in E. coli. Mc. Donald et al. (1986) and Shoemaker and Mitsock (1986) cloned the mouse gene and the latter workers showed that coding DNA and amino acid sequence are about 80% conserved between man and mouse. This is a much higher order of conservation than for various interferons, interleukin-2, and GM-CSF. ……

For information: Sequence and genomic database projects - Ensembl - TIGR

Ensembl: automatic annotation of eukaryotic genomes Contains all the human genome DNA sequences currently available in the public domain. Automated annotation: by using different software tools, features are identified in the DNA sequences: Genes (known or predicted) Single nucleotide polymorphisms (SNPs) Repeats Homologies Created and maintained by the EBI and the Sanger Center (UK)

Ensembl: www. ensembl. org With Ensembl you can. . . - Search the DNA from the human genome - Browse chromosomes - Find genes, SNPs and mouse genome matches - Look for proteins and protein families Ensemble provides: - Identification of 90% of known human genes in the genome sequence - Prediction of 10, 000 additional genes, all with supporting evidence

Ensembl: Browse chromosomes
 The TIGR Databases are a collection of curated")
The Institute for Genomic Research (TIGR) The TIGR Databases are a collection of curated databases containing: DNA and protein sequence, gene expression, cellular role, protein family, taxonomic data Almost for microbes, plants but also humans. TIGR is engaged in sequencing BACs from human chromosome 16 as well as a large-scale BAC end sequencing project.
 http: //www. expasy. org/sprot/")
Database 3: protein sequence SWISS-PROT: created in 1986 (A. Bairoch) http: //www. expasy. org/sprot/ Tr. EMBL: created in 1996; complement to SWISS-PROT; derived from automated EMBL CDS translations ( « proteomic » version of EMBL) PIR-PSD: Protein Information Resources http: //pir. georgetown. edu/
: Peptide/Protein Sequence Database (PRF/SEQDB) http:")
Database 3: protein sequence PRF: Protein Research Foundation (Japan): Peptide/Protein Sequence Database (PRF/SEQDB) http: //www. prf. or. jp/en/index. html Gen. Pept: produced by parsing the corresponding Gen. Bank release for translated coding regions. Many specialized protein databases for specific families or groups of proteins. Examples: YPD (yeast proteins), AMSDb (antibacterial peptides), GPCRDB (7 TM receptors), IMGT (immune system) etc.
 and EMBL/EBI (UK) Fully-annotated (manually), non-redundant, crossreferenced, documented")
SWISS-PROT Collaboration between the SIB (CH) and EMBL/EBI (UK) Fully-annotated (manually), non-redundant, crossreferenced, documented protein sequence database. ~100 ’ 000 sequences from more than 6’ 800 different species; 70 ’ 000 references (publications); 550 ’ 000 cross-references (databases); ~200 Mb of annotations. Weekly releases; available from about 50 servers across the world, the main source being Ex. PASy

SWISS-PROT: example Never changed
")
SWISS-PROT (cont. )
")
SWISS-PROT (cont. )
 We cannot cope with the speed with which new")
Tr. EMBL (TRanslation of EMBL) We cannot cope with the speed with which new data is coming out AND we do not want to dilute the quality of SWISS-PROT -> Tr. EMBL, created in 1996. Tr. EMBL is automatically generated (from annotated EMBL coding sequences (CDS)) and annotated using software tools. Contains all what is not yet in SWISS-PROT + Tr. EMBL = all known protein sequences. Well-structured SWISS-PROT-like resource.

The simplified story of a SWISS-PROT entry c. DNAs, genomes, …. EMBLnew EMBL « Automatic » • Redundancy check (merge) • Family attribution (Inter. Pro) • Annotation (computer) Tr. EMBL « Manual » • Redundancy (merge, conflicts) • Annotation (manual) • SWISS-PROT tools (macros…) • SWISS-PROT documentation • Medline • Databases (MIM, MGD…. ) • Brain storming CDS Tr. EMBLnew SWISS-PROT Once in SWISS-PROT, the entry is no more in Tr. EMBL, but still in EMBL (archive) CDS: proposed and submitted at EMBL by authors or by genome projects (can be experimentally proved or derived from gene prediction programs). Tr. EMBL does not translate DNA sequences, nor use gene prediction programs: only take CDS already annotated in the EMBL entry.

The two defined classes of entries are: STANDARD Data which are complete to the standards laid down by the SWISS-PROT database. PRELIMINARY Sequence entries which have not yet been annotated by the SWISS-PROT staff up to the standards laid down by SWISS-PROT. These entries are exclusively found in Tr. EMBL. Remark 1: Some PRELIMINARY entries are manually CURATED (there is no flag yet for utilisators, but soon…) Remark 2: Tr. EMBL= SPTr. EMBL + REMTr. EMBL: SPTr. EMBL contains Tr. EMBL entries which are going to be integrated into SWISS-PROT. SPTR (SWall) = SWISS-PROT + Tr. EMBLnew

Tr. EMBL: a platform for the improvement of automatic annotation tools • After a lot of testing, many new annotation tools are going to be applied systematically (Signal. P, TMMPred, REP, Inter. Pro domain assignement). • EVIDENCE TAGS are added to any part of a Tr. EMBL entry not derived from the original EMBL entry (not visible for external users). -> follow up of all added informations

Tr. EMBL: example « Old » Tr. EMBL which does not exist anymore, because it has been integrated into the SWISS-PROT EPO_HUMAN entry: low redundancy


Redundancy • SWISS-PROT and Tr. EMBL introduces some degree of redundancy • Only 100 % identical sequences are automatically merged between SWISS-PROT and Tr. EMBL; • Complete sequences or fragments with 1 -3 conflicts will be automatically merged soon (first genome projects; check for chromosomal location and gene names)

SWISS-PROT / Tr. EMBL: a minimal of redundancy Human EPO: Blastp results

SWISS-PROT and Tr. EMBL introduce a new arithmetical concept ! How many sequences in SWISS-PROT + Tr. EMBL ? 100’ 000 + 540’ 000 = about 400’ 000 (august 2001) SWISS-PROT and Tr. EMBL (SPTR) a minimum of redundancy

SWISS-PROT and Tr. EMBL introduce a new arithmetical concept ! In the case of human data, the redundancy is very high: 7’ 300 + 33’ 000 = about 20’ 000

Database 3: Protein sequence Something else ?

Database 3: protein sequence PIR-PSD: Protein Information Resources http: //pir. georgetown. edu/ PRF: Protein Research Foundation (Japan): Peptide/Protein Sequence Database (PRF/SEQDB) http: //www. prf. or. jp/en/index. html Gen. Pept: produced by parsing the corresponding Gen. Bank release for translated coding regions. Many specialized protein databases for specific families or groups of proteins. Examples: YPD (yeast proteins), AMSDb (antibacterial peptides), GPCRDB (7 TM receptors), IMGT (immune system) etc.
 Protein Information Resource, created in 1984 Maintained by MIPS")
PIR-International Protein Sequence Database (PIR-PSD) Protein Information Resource, created in 1984 Maintained by MIPS (Germany) and JIPID (Japan) Successor of the National Biochemical Research Foundation (NBRF) protein sequence database developed in 1965 by M. O. Dayhoff « Atlas of Protein Sequence and Structure » Also produce a computer generated supplemental database of Gen. Bank/EMBL translations (PATCHX) « Well » annotated Automatically classified into protein families (Pro. Class). In august 2001: 239’ 764 entries.
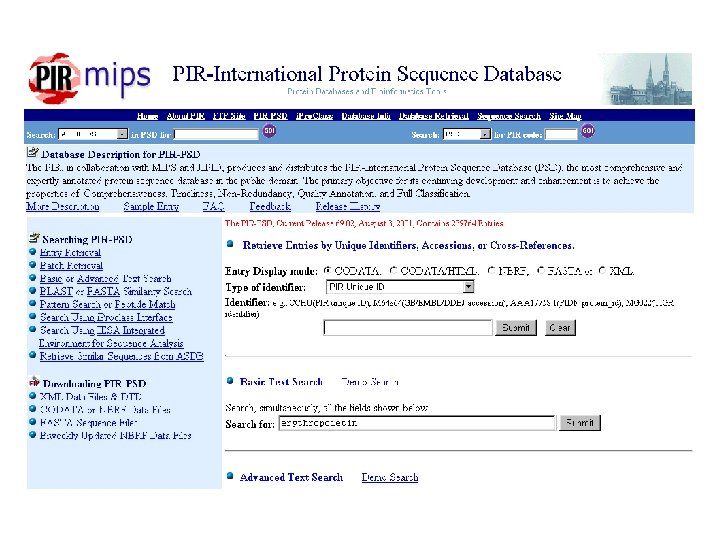

PIR-PSD: example « well annotated »

Database 4: protein domain/family Contains biologically significant « pattern / profiles/ HMM » formulated in such a way that, with appropriate computional tools, it can rapidly and reliably determine to which known family of proteins (if any) a new sequence belongs to -> tools to identify what is the function of uncharacterized proteins translated from genomic or c. DNA sequences ( « functional diagnostic » )

Protein domain/family Most proteins have « modular » structure Estimation: ~ 3 domains / protein Domains (conserved sequences or structures) are identified by multi sequence alignments Domains can be defined by different methods: Pattern (regular expression); used for very conserved domains Profiles (weighted matrices): two-dimensional tables of position specific match-, gap-, and insertion-scores, derived from aligned sequence families; used for less conserved domains Hidden Markov Model (HMM); probabilistic models; an other method to generate profiles.
 Immunoglobulin and major")
Some statistics 15 most common protein domains for H. sapiens (Incomplete) Immunoglobulin and major histocompatibility complex domain Zinc finger, C 2 H 2 type Eukaryotic protein kinase Rhodopsin-like GPCR superfamily Pleckstrin homology (PH) domain RING finger Src homology 3 (SH 3) domain RNA-binding region RNP-1 (RNA recognition motif) EF-hand family Homeobox domain Krab box PDZ domain (also known as DHR or GLGF) Fibronectin type III domain EGF-like domain Cadherin domain http: //www. ebi. ac. uk/proteome/HUMAN/interpro/top 15 d. html

Protein domain/family db Secondary databases are the fruit of analyses of the sequences found in the primary sequence db Either manually curated (i. e. PROSITE, Pfam, etc. ) or automatically generated (i. e. Pro. Dom, DOMO) Some depend on the method used to detect if a protein belongs to a particular domain/family (patterns, profiles, HMM)

Protein domain/family db PROSITE Pro. Dom PRINTS Pfam SMART BLOCKS Patterns /Profiles Aligned motifs HMM (Hidden Markov Models) HMM Aligned motifs Inter. Pro
 § Contains functional domains fully annotated, based on")
Prosite § Created in 1988 (SIB) § Contains functional domains fully annotated, based on two methods: patterns and profiles § Entries are deposited in PROSITE in two distinct files: § Pattern/profiles with the lists of all matches in the parent version of SWISS-PROT § Documentation • Aug 2001: contains 1089 documentation entries that • describe 1474 different patterns, rules and • profiles/matrices.
: example ID AC DT DE PA NR Diagnostic NR performance NR CC")
Prosite (pattern): example ID AC DT DE PA NR Diagnostic NR performance NR CC CC DR List of DR matches DR DR DO // EPO_TPO; PATTERN. PS 00817; OCT-1993 (CREATED); NOV-1995 (DATA UPDATE); JUL-1998 (INFO UPDATE). Erythropoietin / thrombopoeitin signature. P-x(4)-C-D-x-R-[LIVM](2)-x-[KR]-x(14)-C. /RELEASE=38, 80000; /TOTAL=14(14); /POSITIVE=14(14); /UNKNOWN=0(0); /FALSE_POS=0(0); /FALSE_NEG=0; /PARTIAL=1; /TAXO-RANGE=? ? E? ? ; /MAX-REPEAT=1; /SITE=3, disulfide; /SITE=11, disulfide; P 48617, EPO_BOVIN , T; P 33707, EPO_CANFA , T; P 33708, EPO_FELCA , T; P 01588, EPO_HUMAN , T; P 07865, EPO_MACFA , T; Q 28513, EPO_MACMU , T; P 07321, EPO_MOUSE , T; P 49157, EPO_PIG , T; P 29676, EPO_RAT , T; P 33709, EPO_SHEEP , T; P 42705, TPO_CANFA , T; P 40225, TPO_HUMAN , T; P 40226, TPO_MOUSE , T; P 49745, TPO_RAT , T; P 42706, TPO_PIG , P; PDOC 00644;
: example PROSITE: PS 50097 ID AC DT DE MA MA MA MA")
Prosite (profile): example PROSITE: PS 50097 ID AC DT DE MA MA MA MA MA MA MA …. BTB; MATRIX. PS 50097; DEC-1999 (CREATED); DEC-1999 (DATA UPDATE); DEC-1999 (INFO UPDATE). BTB domain profile. /GENERAL_SPEC: ALPHABET='ABCDEFGHIKLMNPQRSTVWYZ'; LENGTH=67; /DISJOINT: DEFINITION=PROTECT; N 1=6; N 2=62; /NORMALIZATION: MODE=1; FUNCTION=LINEAR; R 1=. 9751; R 2=. 02068202; TEXT='-Log. E'; /CUT_OFF: LEVEL=0; SCORE=363; N_SCORE=8. 5; MODE=1; TEXT='!'; /CUT_OFF: LEVEL=-1; SCORE=267; N_SCORE=6. 5; MODE=1; TEXT='? '; /DEFAULT: D=-20; I=-20; B 1=-50; E 1=-50; MI=-105; MD=-105; IM=-105; DM=-105; MM=1; M 0=-2; /I: B 1=0; BI=-105; BD=-105; /M: SY='C'; M=-6, -10, 28, -14, -9, -15, -20, -14, -19, -15, -17, -14, -8, -19, -14, -15, 0, 0, -9, -32, -17, -12; /M: SY='D'; M=-16, 41, -28, 53, 15, -34, -11, -33, 0, -27, -25, 21, -11, 0, -8, 2, -6, -26, -38, -19, 7; /M: SY='V'; M=2, -23, -8, -24, -1, -24, -25, 16, -20, 7, 6, -20, -25, -23, -20, -10, -4, 24, -23, -9, -24; /M: SY='T'; M=-2, -13, -18, -19, -13, -7, -24, -19, 6, -8, -2, 1, -17, -11, -10, -1, 10, -24, -6, -13; /M: SY='L'; M=-11, -30, -22, -33, -24, 15, -32, -23, 25, -29, 35, 17, -26, -27, -23, -22, -24, -9, 16, -17, 3, -24; /M: SY='V'; M=0, -11, -18, -13, -10, -12, -20, -13, 1, -6, -4, 2, -10, -19, -6, -7, -4, -2, 8, -25, -9; /M: SY='V'; M=1, -25, -3, -29, -25, -26, 17, -22, 10, 7, -23, -25, -23, -22, -11, -3, 24, -27, -10, -25; /M: SY='D'; M=-6, 7, -26, 8, 7, -25, 6, -7, -27, 0, -23, -17, 8, -13, 0, -3, 3, -6, -23, -27, -17, 3; /I: I=-5; MI=0; IM=0; DM=-15; MD=-15; /M: SY='G'; M=-6, 8, -27, 8, -3, -27, 22, -7, -30, -8, -26, -19, 10, -14, -8, -9, 2, -9, -24, -28, -21, -6; /M: SY='K'; M=-7, -4, -23, -4, 7, -23, -13, -21, 10, -18, -9, -3, -12, 7, 9, -2, -4, -16, -25, -12, 6; /M: SY='E'; M=-8, -6, -21, -8, 1, -15, -21, -7, -10, -5, -3, -14, 0, -1, -2, -6, -26, -9, -1; /M: SY='F'; M=-12, -28, -22, -34, -26, 31, -21, 18, -26, 16, 9, -22, -27, -21, -20, -9, 14, -6, 13, -26; /M: SY='R'; M=-13, -9, -24, -10, -3, -11, -21, 7, -17, 7, -16, -4, -8, 2, 9, -9, -16, -20, -1, -2; /M: SY='A'; M=21, -15, -8, -22, -17, -10, -23, 0, -15, -5, -14, -18, -17, -19, 4, 6, 12, -24, -15, -17; /M: SY='H'; M=-15, 5, -22, 2, -1, -20, -16, 65, -26, -8, -21, -5, 15, -19, 6, -2, -11, -26, -32, 7, 0; /M: SY='K'; M=-12, -5, -29, -5, 5, -25, -18, -26, 34, -24, -9, -14, 8, 34, -8, -17, -20, -10, 5; /M: SY='A'; M=4, -12, -16, -10, -6, -18, -14, -2, -13, -1, -2, -11, -17, -12, -13, -3, 1, 2, -24, -8, -11; /M: SY='V'; M=-7, -26, -19, -31, -26, 7, -32, -24, 27, -23, 14, 11, -22, -25, -23, -22, -13, 0, 28, -19, 3, -26; /M: SY='L'; M=-10, -30, -21, 9, -30, -20, 22, -29, 47, 20, -29, -20, -29, -10, 12, -20, 0, -21; /M: SY='A'; M=18, -6, 0, -12, -8, -18, -6, -15, -10, -18, -12, -14, -8, -13, 18, 11, -5, -32, -19, -8;
: example (cont. ) …… MA MA MA NR NR NR CC DR")
Prosite (profile): example (cont. ) …… MA MA MA NR NR NR CC DR DR DR DR DO // /M: SY='T'; M=-3, 3, -16, 1, -3, -18, -12, -9, -20, -6, -19, -15, 2, -7, -6, 10, 15, -13, -27, -12, -5; /M: SY='G'; M=-1, 1, -25, 2, -9, -26, 31, -12, -32, -10, -26, -18, 4, -17, -12, -10, 1, -12, -24, -25, -22, -11; /M: SY='E'; M=-9, 3, -24, 4, 13, -25, -16, -1, -24, 13, -21, -13, 3, -9, 6, 13, -6, -20, -27, -13, 8; /M: SY='I'; M=-6, -21, -18, -25, -21, -29, -21, 14, 10, -19, -24, -17, -19, -13, -3, 19, -23, -20; /M: SY='E'; M=-4, 3, -23, 3, 4, -18, -11, -7, -1, -18, -13, 3, -9, -1, -5, 1, -4, -14, -25, -11, 1; /M: SY='I'; M=-8, -25, -23, -27, -20, 1, -30, -21, -20, 18, 12, -22, -18, -7, 16, -21, -20; /M: SY='P'; M=-6, 0, -24, 2, 1, -22, -13, -8, -21, -23, -15, 1, 14, -7, 3, 2, -19, -31, -18, -3; /M: SY='E'; M=-7, 1, -27, 4, 11, -24, -15, -4, -19, 2, -18, -11, 0, -1, 6, -1, -2, -6, -19, -25, -14, 7; /I: E 1=0; IE=-105; DE=-105; /RELEASE=39, 87397; /TOTAL=46(44); /POSITIVE=45(43); /UNKNOWN=1(1); /FALSE_POS=0(0); /FALSE_NEG=0; /PARTIAL=0; /TAXO-RANGE=? ? E? V; /MAX-REPEAT=2; O 14867, BAC 1_HUMAN, T; P 97302, BAC 1_MOUSE, T; P 97303, BAC 2_MOUSE, T; P 41182, BCL 6_HUMAN, T; P 41183, BCL 6_MOUSE, T; Q 01295, BRC 1_DROME, T; Q 01296, BRC 2_DROME, T; Q 01293, BRC 3_DROME, T; Q 28068, CALI_BOVIN, T; Q 13939, CALI_HUMAN, T; Q 08605, GAGA_DROME, T; Q 01820, GCL 1_DROME, T; P 10074, HKR 3_HUMAN, T; Q 04652, KELC_DROME, T; P 42283, LOLL_DROME, T; P 42284, LOLS_DROME, T; O 14682, PI 10_HUMAN, T; Q 05516, PLZF_HUMAN, T; O 43791, SPOP_HUMAN, T; P 42282, TTKA_DROME, T; P 17789, TTKB_DROME, T; P 21073, VA 55_VACCC, T; P 24768, VA 55_VACCV, T; P 21037, VC 02_VACCC, T; P 17371, VC 02_VACCV, T; P 32228, VC 04_SPVKA, T; P 32206, VC 13_SPVKA, T; P 21013, VF 03_VACCC, T; P 24357, VF 03_VACCV, T; P 22611, VMT 8_MYXVL, T; P 08073, VMT 9_MYXVL, T; O 43167, Y 441_HUMAN, T; Q 10225, YAZ 4_SCHPO, T; P 40560, YIA 1_YEAST, T; P 34324, YKV 2_CAEEL, T; P 34371, YLJ 8_CAEEL, T; P 34568, YNV 5_CAEEL, T; P 41886, YPT 9_CAEEL, T; Q 09563, YR 47_CAEEL, T; Q 10017, YSW 1_CAEEL, T; Q 13105, Z 151_HUMAN, T; Q 60821, Z 151_MOUSE, T; P 24278, ZN 46_HUMAN, T; Q 13829, TNP 1_HUMAN, ? ; PDOC 50097;

PFAM

Pro. Dom consists of an automated compilation of homologous domain alignment (procedure based on PSI-BLAST searches) Updating problem ! Last Pro. Dom update: March 30 th, 2001; built from SWISS-PROT + TREMBL December 2000.

Pro. Dom: example Your query

PRINTS Compendium of protein motif fingerprints Most protein families are characterized by several conserved motifs Fingerprint: set of motif(s) (simple or composite, such as multidomains) = signature of family membership True family members exhibit all elements of the fingerprint, while subfamily members may possess only a part

Protein domain/family: Composite databases Example: Inter. Pro Unification of PROSITE, PRINTS, Pfam, Pro. Dom and SMART into an integrated resource of protein families, domains and functional sites; Single set of «documents» linked to the various methods; Will be used to improve the functional annotation of SWISS-PROT (classification of unknown protein…) This release contains 3939 entries, representing 1009 domains, 2850 families, 65 repeats and 15 post-translational modification sites.

Inter. Pro: example IPR 001323 Name Type Erythropoietin/thrombopoeitin Family Abstract Erythropoietin, a plasma glycoprotein, is the primary physiological mediator of erythropoiesis [1]. It is involved in the regulation of the level of peripheral erythrocytes by stimulating the differentiation of erythroid progenitor cells, found in the spleen and bone marrow, into mature erythrocytes [2]. It is primarily produced in adult kidneys and foetal liver, acting by attachment to specific binding sites on erythroid progenitor cells, stimulating their differentiation [3]. Severe kidney dysfunction causes reduction in the plasma levels of erythropoietin, resulting in chronic anaemia - injection of purified erythropoietin into the blood stream can help to relieve this type of anaemia. Levels of erythropoietin in plasma fluctuate with varying oxygen tension of the blood, but androgens and prostaglandins also modulate the levels to some extent [3]. Erythropoietin glycoprotein sequences are well conserved, a consequence of which is that the hormones are cross-reactive among mammals, i. e. that from one species, say human, can stimulate erythropoiesis in other species, say mouse or rat [4]. Thrombopoeitin (TPO), a glycoprotein, is the mammalian hormone which functions as a megakaryocytic lineage specific growth and differentiation factor affecting the proliferation and maturation from their committed progenitor cells acting at a late stage of megakaryocyte development. It acts as a circulating regulator of platelet numbers. Examplelist P 33708 P 33709 P 49745 view matches for the examples Publications 1. Shoemaker C. B. , Mitsock L. D. 849 -858 (1986) 2. Takeuchi M. , Takasaki S. , Miyazaki H. , Kato T. , Hoshi S. , Kochibe N. , Kobata A. J. Biol. Chem. 263: 3657 -3663 (1988) 3. Lin F. K. , Lin C. H. , Lai P. H. , Browne J. K. , Egrie J. C. , Smalling R. , Fox G. M. , Chen K. K. , Castro M. , Suggs S. Gene 44: 201 -209 (1986) 4. Nagao M. , Suga H. , Okano M. , Masuda S. , Narita H. , Ikura K. , Sasaki R. Nucleotide sequence of rat erythropoietin. 1171: 99 -102 (1992) Children IPR 003013 Signatures PROSITE PS 00817 EPO_TPO PFAM PF 00758 EPO_TPO Matches Table Graphical

Databases 5: mutation/polymorphism Contain informations on sequence variations that are linked or not to genetic diseases; Mainly human but: OMIA - Online Mendelian Inheritance in Animals General db: OMIM HMGD - Human Gene Mutation db SVD - Sequence variation db HGBASE - Human Genic Bi-Allelic Sequences db db. SNP - Human single nucleotide polymorphism (SNP) db Disease-specific db: most of these databases are either linked to a single gene or to a single disease; p 53 mutation db ADB - Albinism db (Mutations in human genes causing albinism) Asthma and Allergy gene db ….

Mutation/polymorphisms: definitions SNPs: single nucleotide polymorphisms c-SNPs: coding single nucleotide polymorphisms SAPs: single amino-acid polymorphisms (Single Nucleotide Polymorphisms within c. DNA sequences) Missense mutation: -> SAP Nonsense mutation: -> STOP Insertion/deletion of nucleotides -> frameshift… ! Numbering of the mutation depends on the db (aa no 1 is not necessary the initiator Met !)

Mutation/polymorphisms The SNP consortium http: //snp. cshl. org/ db. SNP at NCBI http: //www. ncbi. nlm. nih. gov/SNP/ Bayer, Roche, IBM, Pfizer, Novartis, Motorola…… Mission: develop up to 300, 000 SNPs distributed evenly throughout the human genome and make the informations related to these SNPs available to the public without intellectual property restrictions. The project started in April 1999 and is anticipated to continue until the end of 2001. Collaboration between the National Human Genome Research Institute and the National Center for Biotechnology Information (NCBI) Mission: central repository for both single base nucleotide subsitutions and short deletion and insertion polymorphisms Aug 2001 , db. SNP has submissions for 2’ 984’ 888 SNPs. Chromosome 21 db. SNP http: //csnp. isb-sib. ch/ A joint project between the Division of Medical Genetics of the University of Geneva Medical School and the SIB Mission: comprehensive c. SNP (Single Nucleotide Polymorphisms within c. DNA sequences) database and map of chromosome 21

Mutation/polymorphisms Very heterogeneous format; Generally modest size; There are initiatives to standardize and to unify these databases (SVD - Sequence Variation Database project at EBI: HMut. DB)

Databases 6: proteomics Contain informations obtained by 2 D-PAGE: master images of the gels and description of identified proteins Examples: SWISS-2 DPAGE, ECO 2 DBASE, Maize 2 DPAGE, Sub 2 D, Cyano 2 DBase, etc. Format: composed of image and text files Most 2 D-PAGE databases are “federated” and use SWISS-PROT as a master index There is currently no protein Mass Spectrometry (MS) database (not for long…)

This protein does not exist in the current release of SWISS-2 DPAGE. EPO_HUMAN (human plasma)

Databases 7: 3 D structure Contain the spatial coordinates of macromolecules whose 3 D structure has been obtained by X-ray or NMR studies Proteins represent more than 90% of available structures (others are DNA, RNA, sugars, virus, complex protein/DNA…) PDB (Protein Data Bank), SCOP (structural classification of proteins (according to the secondary structures)), BMRB (Bio. Mag. Res. Bank; RMN results) DSSP: Database of Secondary Structure Assignments. HSSP: Homology-derived secondary structure of proteins. FSSP: Fold Classification based on Structure-Structure Assignments. Future: Homology-derived 3 D structure db.
 (USA). Contains")
PDB: Protein Data Bank Managed by Research Collaboratory for Structural Bioinformatics (RCSB) (USA). Contains macromolecular structure data on proteins, nucleic acids, protein-nucleic acid complexes, and viruses. Specialized programs allow the vizualisation of the corresponding 3 D structure. Currently there are ~16’ 000 structure data for about 4’ 000 different molecules, but far less protein family (highly redundant) !

PDB: example HEADER COMPND SOURCE AUTHOR REVDAT JRNL JRNL REMARK REMARK REMARK REMARK ……… LYASE(OXO-ACID) 01 -OCT-91 12 CA 2 CARBONIC ANHYDRASE /II (CARBONATE DEHYDRATASE) (/HCA II) 12 CA 3 2 (E. C. 4. 2. 1. 1) MUTANT WITH VAL 121 REPLACED BY ALA (/V 121 A) 12 CA 4 HUMAN (HOMO SAPIENS) RECOMBINANT PROTEIN 12 CA 5 S. K. NAIR, D. W. CHRISTIANSON 12 CA 6 1 15 -OCT-92 12 CA 0 12 CA 7 AUTH S. K. NAIR, T. L. CALDERONE, D. W. CHRISTIANSON, C. A. FIERKE 12 CA 8 TITL ALTERING THE MOUTH OF A HYDROPHOBIC POCKET. 12 CA 9 TITL 2 STRUCTURE AND KINETICS OF HUMAN CARBONIC ANHYDRASE 12 CA 10 TITL 3 /II$ MUTANTS AT RESIDUE VAL-121 12 CA 11 REF J. BIOL. CHEM. V. 266 17320 1991 12 CA 12 REFN ASTM JBCHA 3 US ISSN 0021 -9258 071 12 CA 13 1 12 CA 14 2 12 CA 15 2 RESOLUTION. 2. 4 ANGSTROMS. 12 CA 16 3 12 CA 17 3 REFINEMENT. 12 CA 18 3 PROGRAM PROLSQ 12 CA 19 3 AUTHORS HENDRICKSON, KONNERT 12 CA 20 3 R VALUE 0. 170 12 CA 21 3 RMSD BOND DISTANCES 0. 011 ANGSTROMS 12 CA 22 3 RMSD BOND ANGLES 1. 3 DEGREES 12 CA 23 4 12 CA 24 4 N-TERMINAL RESIDUES SER 2, HIS 3, HIS 4 AND C-TERMINAL 12 CA 25 4 RESIDUE LYS 260 WERE NOT LOCATED IN THE DENSITY MAPS AND, 12 CA 26 4 THEREFORE, NO COORDINATES ARE INCLUDED FOR THESE RESIDUES. 12 CA 27
 SHEET 3 S 10 PHE 66 PHE 70 -1 O ASN")
PDB (cont. ) SHEET 3 S 10 PHE 66 PHE 70 -1 O ASN 67 N LEU 60 12 CA 68 SHEET 4 S 10 TYR 88 TRP 97 -1 O PHE 93 N VAL 68 12 CA 69 SHEET 5 S 10 ALA 116 ASN 124 -1 O HIS 119 N HIS 94 12 CA 70 SHEET 6 S 10 LEU 141 VAL 150 -1 O LEU 144 N LEU 120 12 CA 71 SHEET 7 S 10 VAL 207 LEU 212 1 O ILE 210 N GLY 145 12 CA 72 SHEET 8 S 10 TYR 191 GLY 196 -1 O TRP 192 N VAL 211 12 CA 73 SHEET 9 S 10 LYS 257 ALA 258 -1 O LYS 257 N THR 193 12 CA 74 SHEET 10 S 10 LYS 39 TYR 40 1 O LYS 39 N ALA 258 12 CA 75 TURN 1 T 1 GLN 28 VAL 31 TYPE VIB (CIS-PRO 30) 12 CA 76 TURN 2 T 2 GLY 81 LEU 84 TYPE II(PRIME) (GLY 82) 12 CA 77 TURN 3 T 3 ALA 134 GLN 137 TYPE I (GLN 136) 12 CA 78 TURN 4 T 4 GLN 137 GLY 140 TYPE I (ASP 139) 12 CA 79 TURN 5 THR 200 LEU 203 TYPE VIA (CIS-PRO 202) 12 CA 80 TURN 6 T 6 GLY 233 GLU 236 TYPE II (GLY 235) 12 CA 81 CRYST 1 42. 700 41. 700 73. 000 90. 00 104. 60 90. 00 P 21 2 12 CA 82 ORIGX 1 1. 000000 0. 00000 12 CA 83 ORIGX 2 0. 000000 1. 000000 0. 00000 12 CA 84 ORIGX 3 0. 000000 1. 000000 0. 00000 12 CA 85 SCALE 1 0. 023419 0. 000000 0. 006100 0. 00000 12 CA 86 SCALE 2 0. 000000 0. 023981 0. 000000 0. 00000 12 CA 87 SCALE 3 0. 000000 0. 014156 0. 00000 12 CA 88 ATOM 1 N TRP 5 8. 519 -0. 751 10. 738 1. 00 13. 37 12 CA 89 ATOM 2 CA TRP 5 7. 743 -1. 668 11. 585 1. 00 13. 42 12 CA 90 ATOM 3 C TRP 5 6. 786 -2. 502 10. 667 1. 00 13. 47 12 CA 91 ATOM 4 O TRP 5 6. 422 -2. 085 9. 607 1. 00 13. 57 12 CA 92 ATOM 5 CB TRP 5 6. 997 -0. 917 12. 645 1. 00 13. 34 12 CA 93 ATOM 6 CG TRP 5 5. 784 -0. 209 12. 221 1. 00 13. 40 12 CA 94 ATOM 7 CD 1 TRP 5 5. 681 1. 084 11. 797 1. 00 13. 29 12 CA 95 ATOM 8 CD 2 TRP 5 4. 417 -0. 667 12. 221 1. 00 13. 34 12 CA 96 ATOM 9 NE 1 TRP 5 4. 388 1. 418 11. 515 1. 00 13. 30 12 CA 97 ATOM 10 CE 2 TRP 5 3. 588 0. 375 11. 797 1. 00 13. 35 12 CA 98 ATOM 11 CE 3 TRP 5 3. 837 -1. 877 12. 645 1. 00 13. 39 12 CA 99 ATOM 12 CZ 2 TRP 5 2. 216 0. 208 11. 656 1. 00 13. 39 12 CA 100 ATOM 13 CZ 3 TRP 5 2. 465 -2. 043 12. 504 1. 00 13. 33 12 CA 101 ATOM 14 CH 2 TRP 5 1. 654 -1. 001 12. 009 1. 00 13. 34 12 CA 102 …….

Databases 8: metabolic Contain informations that describe enzymes, biochemical reactions and metabolic pathways; ENZYME and BRENDA: nomenclature databases that store informations on enzyme names and reactions; Metabolic databases: Eco. Cyc (specialized on Escherichia coli), KEGG, EMP/WIT; Usualy these databases are tightly coupled with query software that allows the user to visualise reaction schemes.

Databases 9: bibliographic Bibliographic reference databases contain citations and abstract informations of published life science articles; Example: Medline Other more specialized databases also exist (example: Agricola).

Medline MEDLINE covers the fields of medicine, nursing, dentistry, veterinary medicine, the health care system, and the preclinical sciences more than 4, 000 biomedical journals published in the United States and 70 other countries Contains over 10 million citations since 1966 until now Contains links to biological db and to some journals New records are added to Pre. MEDLINE daily! Many papers not dealing with human are not in Medline ! Before 1970, keeps only the first 10 authors ! Not all journals have citations since 1966 !
 Pub.")
Medline/Pubmed Pub. Med is developed by the National Center for Biotechnology Information (NCBI) Pub. Med provides access to bibliographic information such as MEDLINE, Pre. MEDLINE, Health. STAR, and to integrated molecular biology databases (composite db) PMID: 10923642 (Pub. Med ID), UI: 20378145 (Medline ID)

Databases 10: others There are many databases that cannot be classified in the categories listed previously; Examples: Re. Base (restriction enzymes), TRANSFAC (transcription factors), Carb. Bank, Glyco. Suite. DB (linked sugars), Protein-protein interactions db (DIR, Pro. Net, Interact), Protease db (MEROPS), biotechnology patents db, etc. ; As well as many other resources concerning any aspects of macromolecules and molecular biology.

Proliferation of databases What is the best db for sequence analysis ? Which does contain the highest quality data ? Which is the more comprehensive ? Which is the more up-to-date ? Which is the less redundant ? Which is the more indexed (allows complex queries) ? Which Web server does respond most quickly ? ……. ? ? ?
 ! Not all db are")
Some important practical remarks Databases: many errors (automated annotation) ! Not all db are available on all servers The update frequency is not the same for all servers; creation of db_new between releases (exemple: EMBLnew; Tr. EMBLnew…. ) Some servers add automatically useful cross-references to an entry (implicit links) in addition to already existing links (explicit links)
 allows any flat-file db to be")
Database retrieval tools Sequence Retrieval System (SRS, Europe) allows any flat-file db to be indexed to any other; allows to formulate queries across a wide range of different db types via a single interface, without any worry about data structure, query languages… Entrez (USA): less flexible than SRS but exploits the concept of « neighbouring » , which allows related articles in different db to be linked together, whether or not they are cross-referenced directly ATLAS: specific for macromolecular sequences db (i. e. NRL-3 D) ….

SRS

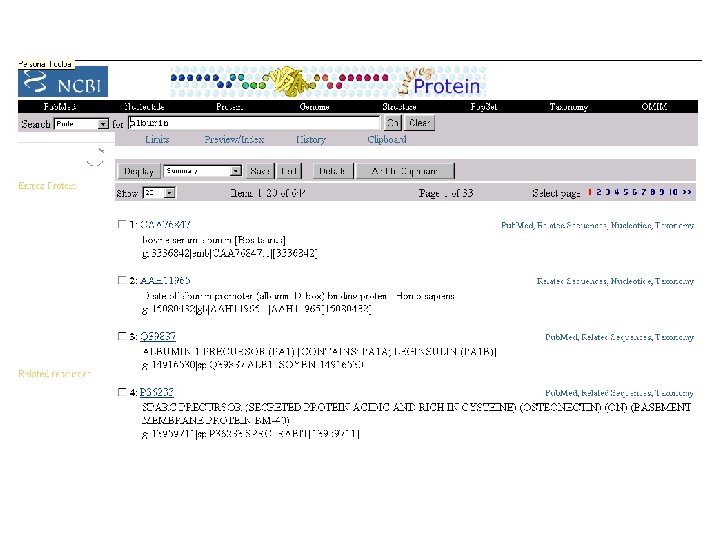
Entrez-protein NCBI: http: //www. ncbi. nlm. nih. gov/entrez/query. fcgi? db=Protein compiled from a variety of sources, including SWISS-PROT, PIR, PRF, PDB, and translations from annotated coding regions in Gen. Bank ( « Genpept » ) and Ref. Seq. PRF: Protein Research Foundation (Japan): Peptide/Protein Sequence Database (PRF/SEQDB) Ref. Seq: NCBI Reference Sequence project PDB: Protein Data Bank (3 D structure) PIR - International Protein Sequence Database Protein and DNA sequences

1
a32bade6ff088a2f7e806bc2aa8894eb.ppt