

f7831d5d4a84571cce531ca478c4a4eb.ppt
- Количество слайдов: 71
 Advanced Topics in Pipelining - SMT and Single-Chip Multiprocessor Priya Govindarajan CMPE 200
Advanced Topics in Pipelining - SMT and Single-Chip Multiprocessor Priya Govindarajan CMPE 200
 Introduction n Researchers have proposed two alternative microarchitectures that exploit multiple threads of control: n simultaneous multithreading SMT [1] n chip multiprocessors CMP [2]
Introduction n Researchers have proposed two alternative microarchitectures that exploit multiple threads of control: n simultaneous multithreading SMT [1] n chip multiprocessors CMP [2]
 CMP Vs SMT n n Why software and hardware trends will favor the CMP microarchitecture. Conclusion on the performance results from comparison of simulated superscalar, SMT, and CMP microarchitectures.
CMP Vs SMT n n Why software and hardware trends will favor the CMP microarchitecture. Conclusion on the performance results from comparison of simulated superscalar, SMT, and CMP microarchitectures.
 SMT Discussion Outline n n n n Introduction Mutithreading MT Approaches of Multithreading Motivation for introducing SMT Implementation of SMT CPU Performance estimates Architectural abstraction
SMT Discussion Outline n n n n Introduction Mutithreading MT Approaches of Multithreading Motivation for introducing SMT Implementation of SMT CPU Performance estimates Architectural abstraction
 Introduction to SMT n n n SMT processors augment wide (issuing many instructions at once) superscalar processors with hardware that allows the processor to execute instructions from multiple threads of control concurrently Dynamically selecting and executing instructions from many active threads simultaneously. Higher utilization of the processor’s execution resources Provides latency tolerance in case a thread stalls due to cache misses or data dependencies. When multiple threads are not available, however, the SMT simply looks like a conventional wide-issue superscalar.
Introduction to SMT n n n SMT processors augment wide (issuing many instructions at once) superscalar processors with hardware that allows the processor to execute instructions from multiple threads of control concurrently Dynamically selecting and executing instructions from many active threads simultaneously. Higher utilization of the processor’s execution resources Provides latency tolerance in case a thread stalls due to cache misses or data dependencies. When multiple threads are not available, however, the SMT simply looks like a conventional wide-issue superscalar.
 Introduction to SMT n n SMT uses the insight that a dynamically scheduled processor already has many of h/w mechanisms needed to support the integrated exploitation of TLP through MT. MT can be built on top of out-of-order processor by adding a per thread register renaming, PCs and providing capability for instructions from multiple threads to commit.
Introduction to SMT n n SMT uses the insight that a dynamically scheduled processor already has many of h/w mechanisms needed to support the integrated exploitation of TLP through MT. MT can be built on top of out-of-order processor by adding a per thread register renaming, PCs and providing capability for instructions from multiple threads to commit.
 Mutithreading: Exploiting Thread-Level Parallelism n Multithreading n n Multiple threads to share the functional units of a single processor in an overlapping fashion. The processor must duplicate the independent state of each thread. (register file, a separate PC, page table) Memory can be shared through the virtual memory mechanisms, which already support multiprocessing Needs hardware support for changing the threads.
Mutithreading: Exploiting Thread-Level Parallelism n Multithreading n n Multiple threads to share the functional units of a single processor in an overlapping fashion. The processor must duplicate the independent state of each thread. (register file, a separate PC, page table) Memory can be shared through the virtual memory mechanisms, which already support multiprocessing Needs hardware support for changing the threads.
 Multithreading…. n Two main approaches to multithreading n n Fine-grained multithreading Coarse-grained multithreading
Multithreading…. n Two main approaches to multithreading n n Fine-grained multithreading Coarse-grained multithreading
 Fine-grained. . Coarse-grained multithreading n n Switches between threads on each instruction, causing interleaving Interleaving in round -robin. Skipping any threads that r stalled n Switches threads only on costly stalls.
Fine-grained. . Coarse-grained multithreading n n Switches between threads on each instruction, causing interleaving Interleaving in round -robin. Skipping any threads that r stalled n Switches threads only on costly stalls.
 Fine-grained multithreading Advantages n Hides throughput losses that arise from both short and long stalls. Disadvantages n Slows down the execution of an individual threads, since a thread that is ready to execute without stalls will be delayed by instructions from other threads.
Fine-grained multithreading Advantages n Hides throughput losses that arise from both short and long stalls. Disadvantages n Slows down the execution of an individual threads, since a thread that is ready to execute without stalls will be delayed by instructions from other threads.
 Coarse-grained multithreading Advantages n Relieves the need to have thread switching be essentially free and is much less likely to slow down the execution of an individual threads
Coarse-grained multithreading Advantages n Relieves the need to have thread switching be essentially free and is much less likely to slow down the execution of an individual threads
 Coarse-grained multithreading Disadvantages n n n Throughput losses, especially from shorter stalls. This is because coarse grained issues instructions from a single thread, when a stall occurs, the pipeline must be emptied or frozen. New thread begins executing after the stall must fill the pipeline before instructions will be able to complete.
Coarse-grained multithreading Disadvantages n n n Throughput losses, especially from shorter stalls. This is because coarse grained issues instructions from a single thread, when a stall occurs, the pipeline must be emptied or frozen. New thread begins executing after the stall must fill the pipeline before instructions will be able to complete.
 Simultaneous Multithreading Is a variation on multithreading that uses the resources of a multiple-issue processors, dynamically scheduled processor to exploit TLP at the same time it exploits ILP. Why ? n Modern multiple-issue processors often have more functional unit parallelism available than a single thread can effectively use. n With register renaming and dynamic scheduling, multiple instructions from independent threads can be issued without any dependences among them. n
Simultaneous Multithreading Is a variation on multithreading that uses the resources of a multiple-issue processors, dynamically scheduled processor to exploit TLP at the same time it exploits ILP. Why ? n Modern multiple-issue processors often have more functional unit parallelism available than a single thread can effectively use. n With register renaming and dynamic scheduling, multiple instructions from independent threads can be issued without any dependences among them. n
 Basic Out-of-order Pipeline
Basic Out-of-order Pipeline
 SMT Pipeline
SMT Pipeline
 Challenges for SMT processor n n n Dealing with a larger register file needed to hold multiple contexts Maintaining low overhead on the clock cycle, particularly in issue , completion Ensuring cache conflicts by simultaneous execution of multiple threads do not cause significant performance degradation.
Challenges for SMT processor n n n Dealing with a larger register file needed to hold multiple contexts Maintaining low overhead on the clock cycle, particularly in issue , completion Ensuring cache conflicts by simultaneous execution of multiple threads do not cause significant performance degradation.
 SMT n SMT will significantly enhance multistream performance across a wide range of applications without significant hardware cost and without major architectural changes
SMT n SMT will significantly enhance multistream performance across a wide range of applications without significant hardware cost and without major architectural changes
 Instruction Issue Reduced function unit utilization due to dependencies
Instruction Issue Reduced function unit utilization due to dependencies
 Superscalar Issue Superscalar leads to more performance, but lower utilization
Superscalar Issue Superscalar leads to more performance, but lower utilization
 Simultaneous Multithreading Maximum utilization of function units by independent operations
Simultaneous Multithreading Maximum utilization of function units by independent operations
 Fine Grained Multithreading Interleaving – no empty slot Intra-thread dependencies still limit performance
Fine Grained Multithreading Interleaving – no empty slot Intra-thread dependencies still limit performance
 Shared") Architectural Abstraction n n 1 CPU with 4 Thread Processing Units (TPUs ) Shared hardware resources
Architectural Abstraction n n 1 CPU with 4 Thread Processing Units (TPUs ) Shared hardware resources
 System Block Diagram
System Block Diagram
 Changes for SMT n n Basic pipeline – unchanged Replicated resources n n n Program counters Register maps Shared resources n n n Register file (size increased) Instruction queue First and second level caches Translation buffers Branch predictor
Changes for SMT n n Basic pipeline – unchanged Replicated resources n n n Program counters Register maps Shared resources n n n Register file (size increased) Instruction queue First and second level caches Translation buffers Branch predictor
 Multithreaded applications Performance
Multithreaded applications Performance
 Single-Chip Multiprocessor n n CMPs use relatively simple single-thread processor cores to exploit only moderate amounts of parallelism within any one thread, while executing multiple threads in parallel across multiple processor cores. If an application cannot be effectively decomposed into threads, CMPs will be underutilized.
Single-Chip Multiprocessor n n CMPs use relatively simple single-thread processor cores to exploit only moderate amounts of parallelism within any one thread, while executing multiple threads in parallel across multiple processor cores. If an application cannot be effectively decomposed into threads, CMPs will be underutilized.
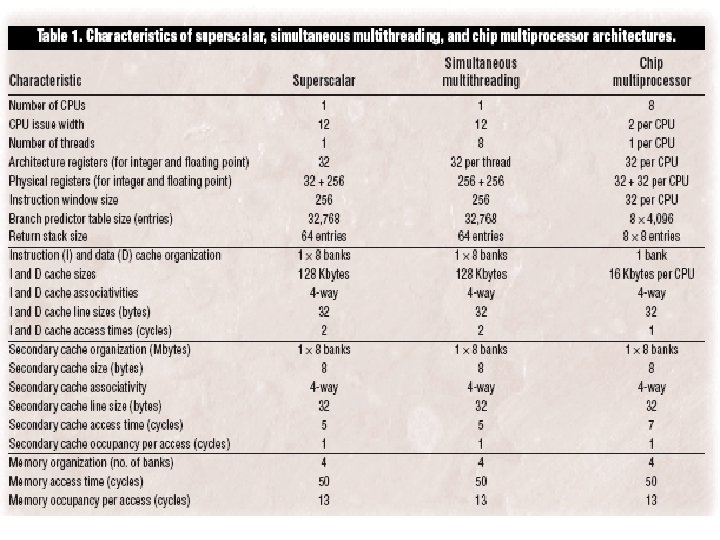
 Comparing Alternative Architectures Issue up to 12 instructions per cycle Super scalar Architecture
Comparing Alternative Architectures Issue up to 12 instructions per cycle Super scalar Architecture
 Comparing … SMT Architecture 8 separate PCs , executes instructions from 8 diff thread concurre Multi ban caches
Comparing … SMT Architecture 8 separate PCs , executes instructions from 8 diff thread concurre Multi ban caches
 Chip multiprocessor architecture 8 small 2 issue superscalar processors. Depend on TLP
Chip multiprocessor architecture 8 small 2 issue superscalar processors. Depend on TLP
 SMT and Memory n n Large demands on memory SMT require more bandwidth from primary cache (MT allows more load and store) To allow this they have 128 -kbye cache Complex MESI(modified , exclusive, shared and invalid) cache-coherence protocol
SMT and Memory n n Large demands on memory SMT require more bandwidth from primary cache (MT allows more load and store) To allow this they have 128 -kbye cache Complex MESI(modified , exclusive, shared and invalid) cache-coherence protocol
 CMP and Memory n n n Eight cores are independent and integrated with their individual pairs of caches – another form of clustering leads to high-frequency design for primary cache system Small cache size and tight connection to these caches allows single-cycle access. Need simpler coherence scheme
CMP and Memory n n n Eight cores are independent and integrated with their individual pairs of caches – another form of clustering leads to high-frequency design for primary cache system Small cache size and tight connection to these caches allows single-cycle access. Need simpler coherence scheme
 Quantitative performance. . CPU cores n To keep the processors execution units busy, SMT features n n advanced branch prediction register renaming out-of-order issue non blocking data caches. Which makes it inherently complex
Quantitative performance. . CPU cores n To keep the processors execution units busy, SMT features n n advanced branch prediction register renaming out-of-order issue non blocking data caches. Which makes it inherently complex
 CMP Approach…h/w simple n n number of registers increases Number of ports on each register must increase n CMP Solution Exploit ILP using more processors instead of large issue widths within single processor
CMP Approach…h/w simple n n number of registers increases Number of ports on each register must increase n CMP Solution Exploit ILP using more processors instead of large issue widths within single processor
 SMT Approach n n n Longer cycle times Long, high capacitance I/O wires span the large buffers, queues and register files Extensive use of multiplexers and crossbars to interconnect these units adds more capacitance Delays associates dominate delay along CPU’s critical path The cycle time impact of these structures can be mitigated by careful design using deep pipelining, by breaking the structures with small, fast clusters of closely related components by short wires. But deep pipelining increases branch misprediction penalities and clustering tends to reduce the ability of the processor to find and exploit instruction level parallelism.
SMT Approach n n n Longer cycle times Long, high capacitance I/O wires span the large buffers, queues and register files Extensive use of multiplexers and crossbars to interconnect these units adds more capacitance Delays associates dominate delay along CPU’s critical path The cycle time impact of these structures can be mitigated by careful design using deep pipelining, by breaking the structures with small, fast clusters of closely related components by short wires. But deep pipelining increases branch misprediction penalities and clustering tends to reduce the ability of the processor to find and exploit instruction level parallelism.
 CMP Solution n Short cycle time to be be targeted with relatively little design effort, since its h/w is naturally clusteredeach of the small CPUs is already a very small fast cluster of components. Since OS allocates a single s/w thread of control to each processor, the partitioning of work among the “clusters” is natural and requires no h/w to dynamically allocate instructions to different clusters Heavy reliance on s/w to direct instructions to clusters limits the amount of ILP of CMP but allows the clusters within CMP to be small and fast.
CMP Solution n Short cycle time to be be targeted with relatively little design effort, since its h/w is naturally clusteredeach of the small CPUs is already a very small fast cluster of components. Since OS allocates a single s/w thread of control to each processor, the partitioning of work among the “clusters” is natural and requires no h/w to dynamically allocate instructions to different clusters Heavy reliance on s/w to direct instructions to clusters limits the amount of ILP of CMP but allows the clusters within CMP to be small and fast.
 SMT and CMP n Architectural point of view, the SMT processor’s flexibility makes it superior. n n n However, the need to limit the effects of interconnect delays, which are becoming much slower than transistor gate delays, will also drive the billion-transistor chip design. Interconnect delays will force the microarchitecture to be partitioned into small, localized processing elements. CMP is much more promising because it is already partitioned into individual processing cores. n Because these cores are relatively simple, they are amenable to speed optimization and can be designed relatively easily.
SMT and CMP n Architectural point of view, the SMT processor’s flexibility makes it superior. n n n However, the need to limit the effects of interconnect delays, which are becoming much slower than transistor gate delays, will also drive the billion-transistor chip design. Interconnect delays will force the microarchitecture to be partitioned into small, localized processing elements. CMP is much more promising because it is already partitioned into individual processing cores. n Because these cores are relatively simple, they are amenable to speed optimization and can be designed relatively easily.
 Compiler support for SMT and CMP n n Programmers must find TLP in order to maximize CMP performance SMT requires programmers to explicitly divide code into threads to get maximum performance but unlike CMP, it can dynamically find more ILP if TLP is limited. But with multithreaded OS these problems should prove to be less daunting Having all eight of the CPUs on a single chip allows designers to exploit TLP even when threads communicate frequently
Compiler support for SMT and CMP n n Programmers must find TLP in order to maximize CMP performance SMT requires programmers to explicitly divide code into threads to get maximum performance but unlike CMP, it can dynamically find more ILP if TLP is limited. But with multithreaded OS these problems should prove to be less daunting Having all eight of the CPUs on a single chip allows designers to exploit TLP even when threads communicate frequently
 Performance results n A comparison of three architectures indicates that a multiprocessor on a chip will be easiest to implement while still offering excellent performance.
Performance results n A comparison of three architectures indicates that a multiprocessor on a chip will be easiest to implement while still offering excellent performance.
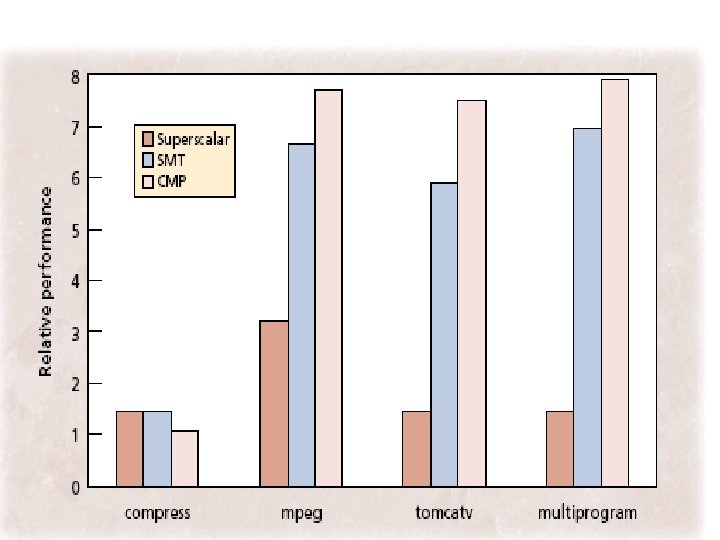
 Disadvantages of CMP n n When code cannot be MT, only one processor can be targeted to the task However, a single 2 issue processor on CMP is only moderately slower than superscalar or SMT, since applications with little thread-level parallelism also lack ILP
Disadvantages of CMP n n When code cannot be MT, only one processor can be targeted to the task However, a single 2 issue processor on CMP is only moderately slower than superscalar or SMT, since applications with little thread-level parallelism also lack ILP
 Conclusion on CMP n n n CMP is promising candidate for a billion-transistor architecture. Offers superior performance using simple h/w Code that can be parallelized into multiple threads, the small CMP cores will perform comparable or better Easier to design and optimize SMTs use resources more efficiently than CMP, but more execution units can be included in a CMP of similar area, since less die area need be devoted to wide-issue logic.
Conclusion on CMP n n n CMP is promising candidate for a billion-transistor architecture. Offers superior performance using simple h/w Code that can be parallelized into multiple threads, the small CMP cores will perform comparable or better Easier to design and optimize SMTs use resources more efficiently than CMP, but more execution units can be included in a CMP of similar area, since less die area need be devoted to wide-issue logic.
 n n n n n D. TULLSEN, S. EGGERS, AND H. LEVY, “Simultaneous Multithreading: Maximizing On-Chip Parallelism, ” Proc. 22 nd Ann. Int’l Symp. Computer Architecture, ACM Press, New York, 1995, pp. 392 -403. J. BORKENHAGEN, R. EICKEMEYER, AND R. KALLA : A Multithreaded Power. PC Processor for Commercial Servers, IBM Journal of Research and Development, November 2000, Vol. 44, No. 6, pp. 885 -98. J. LO, S. EGGERS, J. EMER, H. LEVY, R. STAMM, AND D. TULLSEN. Converting thread-level parallelism into instruction-level parallelism via simultaneous multithreading. ACM Transactions on Computer Systems , 15(2), August 1997. Kunle Olukotun, Basem A. Nayfeh, Lance Hammond, Ken Wilson, and Kunyung Chang. The case for a single-chip multiprocessor. In Proceedings of the Seventh International Conference on Architectural Support for Programming Languages and Operating Systems, pages 2 --11, Cambridge, Massachusetts, October 1 --5, 1996. LANCE HAMMOND, BASEM A NAYFEH, KUNLE OLUKOTUn. A Single-Chip Multiprocessor. IEEE September 1997 GULATI, M. AND BAGHERZADEH, N. 1996. Performance study of a multithreaded superscalar microprocessor. In the 2 nd International Symposium on High-Performance Computer Architecture(Feb. ). 291– 301. KYOUNG PARK, SUNG-HOON CHOI, YONGWHA CHUNG, WOO-JONG HAHN AND SUK-HAN YOON. On-Chip Multiprocessor with Siultaneous Multithreading. http: //etrij. etri. re. kr/etrij/pdfdata/22 -04 -02. pdf NAYFEH, B. A. , HAMMOND, L. , AND OLUKOTUN, K. 1996. Evaluation of design alternatives for a multiprocessor microprocessor. In the 23 rd Annual International Symposium on Computer Architecture (May). 67– 77. OLUKOTUN, K. , NAYFEH, B. A. , HAMMOND, L. , WILSON, K. , AND CHANG, K. 1996. The case for a single-chip multiprocessor. In the 7 th International Conference on Architectural Support for Programming Languages and Operating Systems (Oct. ). ACM, New York, 2– 11. LANCE HAMMOND, BENEDICT A. HUBBERT, MICHAEL SIU, MANOHAR K. PRABHU, MICHAEL CHEN, KUNLE OLUKOTUN. The Stanford Hydra CMP. IEEE Micro March/April 2000 (Vol. 20, No. 2) n n n S. EGGERS, J. EMER, H. LEVY, J. LO, R. STAMM, D. TULLSEN. Simultaneous Multithreading: A Platform for Next-generation Processors. In IEEE Micro, pages 12 -18, September/October 1997 V. KRISHNAN AND J. TORRELLAS. Hardware and Software Support for Speculative Execution of Sequential Binaries on Chip. Multiprocessor. In ACM International Conference on Supercomputing (ICS’ 98) , pages 85 -92, June 1998. goethe. ira. uka. de/people/ungerer/proc-arch/ EUROPAR-tutorial-slides. ppt http: //www. acm. uiuc. edu/banks/20/6/page 4. html Simultaneous Multithreading home page http: //www. cs. washington. edu/research/smt/
n n n n n D. TULLSEN, S. EGGERS, AND H. LEVY, “Simultaneous Multithreading: Maximizing On-Chip Parallelism, ” Proc. 22 nd Ann. Int’l Symp. Computer Architecture, ACM Press, New York, 1995, pp. 392 -403. J. BORKENHAGEN, R. EICKEMEYER, AND R. KALLA : A Multithreaded Power. PC Processor for Commercial Servers, IBM Journal of Research and Development, November 2000, Vol. 44, No. 6, pp. 885 -98. J. LO, S. EGGERS, J. EMER, H. LEVY, R. STAMM, AND D. TULLSEN. Converting thread-level parallelism into instruction-level parallelism via simultaneous multithreading. ACM Transactions on Computer Systems , 15(2), August 1997. Kunle Olukotun, Basem A. Nayfeh, Lance Hammond, Ken Wilson, and Kunyung Chang. The case for a single-chip multiprocessor. In Proceedings of the Seventh International Conference on Architectural Support for Programming Languages and Operating Systems, pages 2 --11, Cambridge, Massachusetts, October 1 --5, 1996. LANCE HAMMOND, BASEM A NAYFEH, KUNLE OLUKOTUn. A Single-Chip Multiprocessor. IEEE September 1997 GULATI, M. AND BAGHERZADEH, N. 1996. Performance study of a multithreaded superscalar microprocessor. In the 2 nd International Symposium on High-Performance Computer Architecture(Feb. ). 291– 301. KYOUNG PARK, SUNG-HOON CHOI, YONGWHA CHUNG, WOO-JONG HAHN AND SUK-HAN YOON. On-Chip Multiprocessor with Siultaneous Multithreading. http: //etrij. etri. re. kr/etrij/pdfdata/22 -04 -02. pdf NAYFEH, B. A. , HAMMOND, L. , AND OLUKOTUN, K. 1996. Evaluation of design alternatives for a multiprocessor microprocessor. In the 23 rd Annual International Symposium on Computer Architecture (May). 67– 77. OLUKOTUN, K. , NAYFEH, B. A. , HAMMOND, L. , WILSON, K. , AND CHANG, K. 1996. The case for a single-chip multiprocessor. In the 7 th International Conference on Architectural Support for Programming Languages and Operating Systems (Oct. ). ACM, New York, 2– 11. LANCE HAMMOND, BENEDICT A. HUBBERT, MICHAEL SIU, MANOHAR K. PRABHU, MICHAEL CHEN, KUNLE OLUKOTUN. The Stanford Hydra CMP. IEEE Micro March/April 2000 (Vol. 20, No. 2) n n n S. EGGERS, J. EMER, H. LEVY, J. LO, R. STAMM, D. TULLSEN. Simultaneous Multithreading: A Platform for Next-generation Processors. In IEEE Micro, pages 12 -18, September/October 1997 V. KRISHNAN AND J. TORRELLAS. Hardware and Software Support for Speculative Execution of Sequential Binaries on Chip. Multiprocessor. In ACM International Conference on Supercomputing (ICS’ 98) , pages 85 -92, June 1998. goethe. ira. uka. de/people/ungerer/proc-arch/ EUROPAR-tutorial-slides. ppt http: //www. acm. uiuc. edu/banks/20/6/page 4. html Simultaneous Multithreading home page http: //www. cs. washington. edu/research/smt/
 The Stanford Hydra Chip Multiprocessor Kunle Olukotun The Hydra Team Computer Systems Laboratory Stanford University
The Stanford Hydra Chip Multiprocessor Kunle Olukotun The Hydra Team Computer Systems Laboratory Stanford University
 Technology Architecture n Transistors are cheap, plentiful and fast n n n Wires are cheap, plentiful and slow n n n Moore’s law 100 million transistors by 2000 Wires get slower relative to transistors Long cross-chip wires are especially slow Architectural implications n n Plenty of room for innovation Single cycle communication requires localized blocks of logic
Technology Architecture n Transistors are cheap, plentiful and fast n n n Wires are cheap, plentiful and slow n n n Moore’s law 100 million transistors by 2000 Wires get slower relative to transistors Long cross-chip wires are especially slow Architectural implications n n Plenty of room for innovation Single cycle communication requires localized blocks of logic
 Exploiting Program Parallelism Levels of Parallelism Process Thread Loop Instruction 1 10 100 1 K 10 K Grain Size (instructions) 100 K 1 M
Exploiting Program Parallelism Levels of Parallelism Process Thread Loop Instruction 1 10 100 1 K 10 K Grain Size (instructions) 100 K 1 M
 Hydra Approach n n A single-chip multiprocessor architecture composed of simple fast processors Multiple threads of control n n Memory renaming and thread-level speculation n n Exploits parallelism at all levels Makes it easy to develop parallel programs Keep design simple by taking advantage of single chip implementation
Hydra Approach n n A single-chip multiprocessor architecture composed of simple fast processors Multiple threads of control n n Memory renaming and thread-level speculation n n Exploits parallelism at all levels Makes it easy to develop parallel programs Keep design simple by taking advantage of single chip implementation
 Outline n n n n Base Hydra Architecture Performance of base architecture Speculative thread support Speculative thread performance Improving speculative thread performance Hydra prototype design Conclusions
Outline n n n n Base Hydra Architecture Performance of base architecture Speculative thread support Speculative thread performance Improving speculative thread performance Hydra prototype design Conclusions
 The Base Hydra Design Single-chip multiprocessor Four processors Separate primary caches Write-through data caches to maintain coherence n n n Shared 2 nd-level cache Low latency interprocessor communication (10 cycles) Separate read and write
The Base Hydra Design Single-chip multiprocessor Four processors Separate primary caches Write-through data caches to maintain coherence n n n Shared 2 nd-level cache Low latency interprocessor communication (10 cycles) Separate read and write
 Hydra vs. Superscalar 4 Hydra 4 x 2 -way issue 3. 5 n Superscalar 6 -way issue 3 2 n 1. 5 1 n pmake OLTP tomcatv swim applu MPEG 2 apsi m 88 ksim 0 eqntott 0. 5 compress Speedup 2. 5 ILP only SS 30 -50% better than single Hydra processor ILP & fine thread SS and Hydra comparable ILP & coarse thread Hydra 1. 5– 2 better
Hydra vs. Superscalar 4 Hydra 4 x 2 -way issue 3. 5 n Superscalar 6 -way issue 3 2 n 1. 5 1 n pmake OLTP tomcatv swim applu MPEG 2 apsi m 88 ksim 0 eqntott 0. 5 compress Speedup 2. 5 ILP only SS 30 -50% better than single Hydra processor ILP & fine thread SS and Hydra comparable ILP & coarse thread Hydra 1. 5– 2 better
 Problem: Parallel Software n Parallel software is limited n n n Hand-parallelized applications Auto-parallelized dense matrix FORTRAN applications Traditional auto-parallelization of Cprograms is very difficult n n Threads have data dependencies synchronization Pointer disambiguation is difficult and expensive
Problem: Parallel Software n Parallel software is limited n n n Hand-parallelized applications Auto-parallelized dense matrix FORTRAN applications Traditional auto-parallelization of Cprograms is very difficult n n Threads have data dependencies synchronization Pointer disambiguation is difficult and expensive
 Solution: Data Speculation n Data speculation enables parallelization without regard for data-dependencies n n n Loads and stores follow original sequential semantics Speculation hardware ensures correctness Add synchronization only for performance Loop parallelization is now easily automated Other ways to parallelize code n Break code into arbitrary threads (e. g. speculative subroutines )
Solution: Data Speculation n Data speculation enables parallelization without regard for data-dependencies n n n Loads and stores follow original sequential semantics Speculation hardware ensures correctness Add synchronization only for performance Loop parallelization is now easily automated Other ways to parallelize code n Break code into arbitrary threads (e. g. speculative subroutines )
 Data Speculation Requirements I Ê Forward data between parallel threads ËDetect violations when reads occur too
Data Speculation Requirements I Ê Forward data between parallel threads ËDetect violations when reads occur too
 Data Speculation Requirements II ÌSafely discard bad state after violation ÍCorrectly retire speculative state
Data Speculation Requirements II ÌSafely discard bad state after violation ÍCorrectly retire speculative state
 Data Speculation Requirements III ÎMaintain multiple “views” of memory
Data Speculation Requirements III ÎMaintain multiple “views” of memory
 Hydra Speculation Support Ê Write bus and L 2 buffers provide forwarding Ë “Read” L 1 tag bits detect violations Ì “Dirty” L 1 tag bits and write buffers provide backup Í Write buffers reorder and retire speculative state Î Separate L 1 caches with pre-invalidation & smart L 2 forwarding
Hydra Speculation Support Ê Write bus and L 2 buffers provide forwarding Ë “Read” L 1 tag bits detect violations Ì “Dirty” L 1 tag bits and write buffers provide backup Í Write buffers reorder and retire speculative state Î Separate L 1 caches with pre-invalidation & smart L 2 forwarding
 Speculative Reads n L 1 hit The read bits are set Ë miss L 1 L 2 and write buffers are checked in parallel The newest bytes written to a line are pulled in by priority encoders on each byte (priority A-D)
Speculative Reads n L 1 hit The read bits are set Ë miss L 1 L 2 and write buffers are checked in parallel The newest bytes written to a line are pulled in by priority encoders on each byte (priority A-D)
 Speculative Writes Ê CPU writes to its L 1 cache & write buffer A Ë “Earlier” CPUs invalidate our L 1 & cause RAW hazard checks Ì “Later” CPUs just pre-invalidate our L 1 Í Non-speculative write buffer drains out into the L 2
Speculative Writes Ê CPU writes to its L 1 cache & write buffer A Ë “Earlier” CPUs invalidate our L 1 & cause RAW hazard checks Ì “Later” CPUs just pre-invalidate our L 1 Í Non-speculative write buffer drains out into the L 2
 Speculation Runtime System n Software Handlers n n n Control speculative threads through CP 2 interface Track order of all speculative threads Exception routines recover from data dependency violations Adds more overhead to speculation than hardware but more flexible and simpler to implement Complete description in “Data Speculation
Speculation Runtime System n Software Handlers n n n Control speculative threads through CP 2 interface Track order of all speculative threads Exception routines recover from data dependency violations Adds more overhead to speculation than hardware but more flexible and simpler to implement Complete description in “Data Speculation
 Creating Speculative Threads n Speculative loops n n n Speculative procedures n n n for and while loop iterations Typically one speculative thread per iteration Execute code after procedure speculatively Procedure calls generate a speculative thread Compiler support
Creating Speculative Threads n Speculative loops n n n Speculative procedures n n n for and while loop iterations Typically one speculative thread per iteration Execute code after procedure speculatively Procedure calls generate a speculative thread Compiler support
 Base Speculative Thread Performance 4 3. 5 Base n 2. 5 2 n 1. 5 n 1 0. 5 n sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 Entire applications GCC 2. 7. 2 -O 2 4 single-issue processors Accurate modeling of all aspects of Hydra
Base Speculative Thread Performance 4 3. 5 Base n 2. 5 2 n 1. 5 n 1 0. 5 n sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 Entire applications GCC 2. 7. 2 -O 2 4 single-issue processors Accurate modeling of all aspects of Hydra
 Improving Speculative Runtime System n Procedure support adds overhead to loops n n n Threads are not created sequentially Dynamic thread scheduling necessary Start and end of loop: 75 cycles End of iteration: 80 cycles Performance n n Best performing speculative applications use loops Procedure speculation often lowers
Improving Speculative Runtime System n Procedure support adds overhead to loops n n n Threads are not created sequentially Dynamic thread scheduling necessary Start and end of loop: 75 cycles End of iteration: 80 cycles Performance n n Best performing speculative applications use loops Procedure speculation often lowers
 Improved Speculative Performance 4 3. 5 Optimized RTS Base n 2. 5 2 1. 5 n 1 0. 5 sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 n Improves performance of all applications Most improvement for applications with fine-grained threads Eqntott uses procedure speculation
Improved Speculative Performance 4 3. 5 Optimized RTS Base n 2. 5 2 1. 5 n 1 0. 5 sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 n Improves performance of all applications Most improvement for applications with fine-grained threads Eqntott uses procedure speculation
 Optimizing Parallel Performance n Cache coherent shared memory n n n No explicit data movement 100+ cycle communication latency Need to optimize for data locality Look at cache misses (Mem. Spy, Flashpoint) Speculative threads n n No explicit data independence Frequent dependence violations limit performance
Optimizing Parallel Performance n Cache coherent shared memory n n n No explicit data movement 100+ cycle communication latency Need to optimize for data locality Look at cache misses (Mem. Spy, Flashpoint) Speculative threads n n No explicit data independence Frequent dependence violations limit performance
 Feedback and Code Transformations n Feedback tool n n n Synchronization n Collects violation statistics (PCs, frequency, work lost) Correlates read and write PC values with source code Synchronize frequently occurring violations Use non-violating loads Code Motion
Feedback and Code Transformations n Feedback tool n n n Synchronization n Collects violation statistics (PCs, frequency, work lost) Correlates read and write PC values with source code Synchronize frequently occurring violations Use non-violating loads Code Motion
 Code Motion Rearrange reads and writes to increase parallelism iteration i n Delay reads and advance writes read x iteration i+1 write x read x n Create local copies to allow earlier data read x write x read x’ forwarding read x’ n write x iteration i+1 read x write x
Code Motion Rearrange reads and writes to increase parallelism iteration i n Delay reads and advance writes read x iteration i+1 write x read x n Create local copies to allow earlier data read x write x read x’ forwarding read x’ n write x iteration i+1 read x write x
 Optimized Speculative Performance 4 3. 5 n Base performance 2. 5 n Optimized RTS with no manual intervention 2 1. 5 1 0. 5 sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 n Violation statistics used to manually transform code
Optimized Speculative Performance 4 3. 5 n Base performance 2. 5 n Optimized RTS with no manual intervention 2 1. 5 1 0. 5 sparse 1. 3 simplex ear cholesky alvin mpeg 2 ijpeg wc m 88 ksim grep eqntott 0 compress Speedup 3 n Violation statistics used to manually transform code
 Size of Speculative lines of write. State Write state Max no. n n n Max size determines size of write buffer for max performance Non-head processor stalls when write buffer fills up Small write buffers (< 64 lines) will achieve good performance 32 byte cache lines
Size of Speculative lines of write. State Write state Max no. n n n Max size determines size of write buffer for max performance Non-head processor stalls when write buffer fills up Small write buffers (< 64 lines) will achieve good performance 32 byte cache lines
 RC 32364") Hydra Prototype n Design based on Integrated Device Technology (IDT) RC 32364
Hydra Prototype n Design based on Integrated Device Technology (IDT) RC 32364
 Conclusions n Hydra offers a new way to design microprocessors n n Single-chip MP exploits parallelism at all levels Low overhead support for speculative parallelism Provides high performance on applications with medium to large-grain parallelism Allows performance optimization migration path for difficult to parallelize fine-grain
Conclusions n Hydra offers a new way to design microprocessors n n Single-chip MP exploits parallelism at all levels Low overhead support for speculative parallelism Provides high performance on applications with medium to large-grain parallelism Allows performance optimization migration path for difficult to parallelize fine-grain
 Hydra Team n Team Monica Lam, Lance Hammond, Mike Chen, Ben Hubbert, Manohar Prahbu, Mike Siu, Melvyn Lim and Maciek Kozyrczak (IDT) n URL n http: //www-hydra. stanford. edu
Hydra Team n Team Monica Lam, Lance Hammond, Mike Chen, Ben Hubbert, Manohar Prahbu, Mike Siu, Melvyn Lim and Maciek Kozyrczak (IDT) n URL n http: //www-hydra. stanford. edu