59ec624ef649c5ec02e490e84641d25d.ppt
- Количество слайдов: 86
 Accelerator Compiler for the VENICE Vector Processor Zhiduo Liu Supervisor: Guy Lemieux Sep. 28 th, 2012
Accelerator Compiler for the VENICE Vector Processor Zhiduo Liu Supervisor: Guy Lemieux Sep. 28 th, 2012
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 Motivation FPGA DL VH Par. C Er lan Sys Multi-core tem g P Verilog Ver en. M ilog Ope Op n. CL ava a. J SSE Blu MPI esp d GPU Open. GL ec ea X 1 hr CUDA t P Fo Stream. It 0 Sh r tr Many-core MPP nge pen. H O C o Vector hapel ess Computer p Processor … S clusters Cilk
Motivation FPGA DL VH Par. C Er lan Sys Multi-core tem g P Verilog Ver en. M ilog Ope Op n. CL ava a. J SSE Blu MPI esp d GPU Open. GL ec ea X 1 hr CUDA t P Fo Stream. It 0 Sh r tr Many-core MPP nge pen. H O C o Vector hapel ess Computer p Processor … S clusters Cilk
 Motivation FPGA DL VH Par. C Er lan Sys Multi-core tem g P Verilog Ver en. M ilog Ope Op n. CL ava a. J SSE Blu MPI esp d GPU Open. GL ec ea X 1 hr CUDA t P Fo Stream. It 0 Sh r tr Many-core MPP nge pen. H O C o Vector hapel ess Computer p Processor … S clusters Cilk Simplification
Motivation FPGA DL VH Par. C Er lan Sys Multi-core tem g P Verilog Ver en. M ilog Ope Op n. CL ava a. J SSE Blu MPI esp d GPU Open. GL ec ea X 1 hr CUDA t P Fo Stream. It 0 Sh r tr Many-core MPP nge pen. H O C o Vector hapel ess Computer p Processor … S clusters Cilk Simplification
 Motivation Single Description …
Motivation Single Description …
 Contributions q. The compiler serves as a new back-end of a singledescription multiple-device language. q. The compiler makes VENICE easier to program and debug. q. The compiler provides auto-parallelization and optimization. [1] Z. Liu, A. Severance, S. Singh and G. Lemieux, “Accelerator Compiler for the VENICE Vector Processor, ” in FPGA 2012. [2] C. Chou, A. Severance, A. Brant, Z. Liu, S. Sant, G. Lemieux, “VEGAS: soft vector processor with scratchpad memory, ” in FPGA 2011.
Contributions q. The compiler serves as a new back-end of a singledescription multiple-device language. q. The compiler makes VENICE easier to program and debug. q. The compiler provides auto-parallelization and optimization. [1] Z. Liu, A. Severance, S. Singh and G. Lemieux, “Accelerator Compiler for the VENICE Vector Processor, ” in FPGA 2012. [2] C. Chou, A. Severance, A. Brant, Z. Liu, S. Sant, G. Lemieux, “VEGAS: soft vector processor with scratchpad memory, ” in FPGA 2011.
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 ALIGN WR RD ALIGN EX 1 EX 2 ACCUM
ALIGN WR RD ALIGN EX 1 EX 2 ACCUM
 Program in VENICE assembly • Allocate vectors in scratchpad • Move data from main memory to scratchpad • Wait for DMA transaction to be completed • Setup for vector instructions • Perform vector computations • Wait for vector operations to be completed • Move data from scratchpad to main memory • Wait for DMA transaction to be completed • Deallocate memory from scratchpad #include "vector. h“ int main() { int A[] = {1, 2, 3, 4, 5, 6, 7, 8}; const int data_len = sizeof ( A ); int *va = ( int *) vector_malloc ( data_len ); vector_dma_to_vector ( va, A, data_len ); vector_wait_for_dma (); vector_set_vl ( data_len / sizeof (int) ); vector ( SVW, VADD, va, 42, va ); vector_instr_sync (); vector_dma_to_host ( A, va, data_len ); vector_wait_for_dma (); vector_free (); }
Program in VENICE assembly • Allocate vectors in scratchpad • Move data from main memory to scratchpad • Wait for DMA transaction to be completed • Setup for vector instructions • Perform vector computations • Wait for vector operations to be completed • Move data from scratchpad to main memory • Wait for DMA transaction to be completed • Deallocate memory from scratchpad #include "vector. h“ int main() { int A[] = {1, 2, 3, 4, 5, 6, 7, 8}; const int data_len = sizeof ( A ); int *va = ( int *) vector_malloc ( data_len ); vector_dma_to_vector ( va, A, data_len ); vector_wait_for_dma (); vector_set_vl ( data_len / sizeof (int) ); vector ( SVW, VADD, va, 42, va ); vector_instr_sync (); vector_dma_to_host ( A, va, data_len ); vector_wait_for_dma (); vector_free (); }
 Program in Accelerator #include "Accelerator. h" using namespace Parallel. Arrays; using namespace Microsoft. Targets; int main() { int A[] = {1, 2, 3, 4, 5, 6, 7, 8}; • Create a Target • Create Parallel Array objects • Write expressions • Call To. Array to evaluate expressions • Delete Target object Target *tgt = Create. Vector. Target(); Target *tgt = Create. Multicore. Target(); Target *tgt= Create. DX 9 Target(); IPA b = IPA( A, sizeof (A)/sizeof (int)); IPA c = b + 42; tgt->To. Array( c, A, sizeof (A)/sizeof (int)); tgt->Delete(); }
Program in Accelerator #include "Accelerator. h" using namespace Parallel. Arrays; using namespace Microsoft. Targets; int main() { int A[] = {1, 2, 3, 4, 5, 6, 7, 8}; • Create a Target • Create Parallel Array objects • Write expressions • Call To. Array to evaluate expressions • Delete Target object Target *tgt = Create. Vector. Target(); Target *tgt = Create. Multicore. Target(); Target *tgt= Create. DX 9 Target(); IPA b = IPA( A, sizeof (A)/sizeof (int)); IPA c = b + 42; tgt->To. Array( c, A, sizeof (A)/sizeof (int)); tgt->Delete(); }
 Assembly Programming : Accelerator Programming : Write in Accelerator Write Assembly Compile with Microsoft Visual Studio Doesn’t compile? Or result incorrect? Compile with Gcc Download to board Get Result Doesn’t compile? Result Incorrect?
Assembly Programming : Accelerator Programming : Write in Accelerator Write Assembly Compile with Microsoft Visual Studio Doesn’t compile? Or result incorrect? Compile with Gcc Download to board Get Result Doesn’t compile? Result Incorrect?
 Assembly Programming : Accelerator Programming : 1. Hard to program 2. Long debug cycle 3. Not portable 4. Manual – Not always optimal or correct (wysiwyg) 1. Easy to program 2. Easy to debug 3. Can also target other devices 4. Automated compiler optimizations
Assembly Programming : Accelerator Programming : 1. Hard to program 2. Long debug cycle 3. Not portable 4. Manual – Not always optimal or correct (wysiwyg) 1. Easy to program 2. Easy to debug 3. Can also target other devices 4. Automated compiler optimizations
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 D #include "Accelerator. h" using namespace Parallel. Arrays; using namespace Microsoft. Targets; × int main() { Target *tgt. Vector = Create. Vector. Target(); const int length = 8192; int a[] = {1, 2, 3, 4, … , 8192}; int d[length]; IPA A = IPA( a, length); IPA B = Evaluate( Rotate(A, [1]) + 1 ); IPA C = Evaluate( Abs( A + 2 )); IPA D = ( A + B ) * C ; + Abs + A A 2 + Rot tgt. Vector->To. Array( D, d, length * sizeof(int)); tgt. Vector->Delete(); } A 1
D #include "Accelerator. h" using namespace Parallel. Arrays; using namespace Microsoft. Targets; × int main() { Target *tgt. Vector = Create. Vector. Target(); const int length = 8192; int a[] = {1, 2, 3, 4, … , 8192}; int d[length]; IPA A = IPA( a, length); IPA B = Evaluate( Rotate(A, [1]) + 1 ); IPA C = Evaluate( Abs( A + 2 )); IPA D = ( A + B ) * C ; + Abs + A A 2 + Rot tgt. Vector->To. Array( D, d, length * sizeof(int)); tgt. Vector->Delete(); } A 1
 D × + Abs + A A 2 + Rot A 1
D × + Abs + A A 2 + Rot A 1
 1") D × + Abs + A A 2 + A (rot) 1
D × + Abs + A A 2 + A (rot) 1
 + Abs A") C B Abs + D × A + 1 (rot) + Abs A + A 2 D + × A 2 A (rot) 1 C + A B
C B Abs + D × A + 1 (rot) + Abs A + A 2 D + × A 2 A (rot) 1 C + A B
 D × + 1 A") Combine Operations C B Abs + A (rot) D × + 1 A C 2 + A B
Combine Operations C B Abs + A (rot) D × + 1 A C 2 + A B
 C |+| × 1 A 2") Combine Operations B A D + (rot) C |+| × 1 A 2 C + A B
Combine Operations B A D + (rot) C |+| × 1 A 2 C + A B
 “Virtual Vector Register File” Scratchpad Memory
“Virtual Vector Register File” Scratchpad Memory
 “Virtual Vector Register File”
“Virtual Vector Register File”
 “Virtual Vector Register File” Number of vector registers = ? Vector register size = ?
“Virtual Vector Register File” Number of vector registers = ? Vector register size = ?
 “Virtual Vector Register File” Number of vector registers = ? Vector register size = ?
“Virtual Vector Register File” Number of vector registers = ? Vector register size = ?
 02") Evaluation Order B + A 13 + 11 × C 2 (rot) 02 5 2 13 14 A 1 (rot) D C 11 23 + 02 A B 11 12
Evaluation Order B + A 13 + 11 × C 2 (rot) 02 5 2 13 14 A 1 (rot) D C 11 23 + 02 A B 11 12
 D + A C +") Count number of virtual vector registers B (rot) D + A C + × 1 A (rot) 2 C + A B
Count number of virtual vector registers B (rot) D + A C + × 1 A (rot) 2 C + A B
 D + A C +") Count number of virtual vector registers B (rot) D + A C + × 1 A (rot) 2 C + A B
Count number of virtual vector registers B (rot) D + A C + × 1 A (rot) 2 C + A B
 Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B
Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B
 Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B
Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B
 Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 B
Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 B
 Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 B
Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 B
 Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 C 1 B
Count number of virtual vector registers B C D + + × A 1 (rot) A (rot) 2 C + A Ref Count A 3 B 1 C 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No num. Loads = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No num. Loads = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No num. Loads = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 3 A Yes B 1 B No C 1 C No num. Loads = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 num. Temps = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B No C 1 C No num. Loads = 1 num. Temps = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 1 A 2 A Yes num. Temps = 1 B No num. Total = 2 C 1 C No max. Total = 2 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 1 A 2 A Yes num. Temps = 1 B No num. Total = 2 C 1 C No max. Total = 2 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 2 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 1 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C No num. Loads = 2 num. Temps = 1 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 2 A 1 A Yes num. Temps = 1 B Yes num. Total = 3 C 1 C No max. Total = 3 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 2 A 1 A Yes num. Temps = 1 B Yes num. Total = 3 C 1 C No max. Total = 3 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C Yes num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 1 A Yes B 1 B Yes C 1 C Yes num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 1 B Yes C 1 C Yes num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 1 B Yes C 1 C Yes num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 1 C Yes num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 1 C Yes num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 1 C Yes num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 1 C Yes num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 0 C No num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 0 C No num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 0 C No num. Loads = 3 num. Temps = 0 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active A 0 A No B 0 B No C 0 C No num. Loads = 3 num. Temps = 0 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 3 A 0 A No num. Temps = 0 B No num. Total = 3 C 0 C No max. Total = 3 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 3 A 0 A No num. Temps = 0 B No num. Total = 3 C 0 C No max. Total = 3 B
 Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 0 A No num. Temps = 0 B No num. Total = 0 C No max. Total = 3 B
Count number of virtual vector registers B C D + + × A A 1 (rot) 2 C + A Ref Count Active num. Loads = 0 A No num. Temps = 0 B No num. Total = 0 C No max. Total = 3 B
 “Virtual Vector Register File” Number of vector registers = 3 Vector register size = ?
“Virtual Vector Register File” Number of vector registers = 3 Vector register size = ?
 “Virtual Vector Register File” Number of vector registers = 3 Vector register size = Capacity/3
“Virtual Vector Register File” Number of vector registers = 3 Vector register size = Capacity/3
 Convert to LIR D 5 3 |+| + A 1 2 4 3 1 3 C + A 2 A 1 (rot) × C B 2 B 1 Result: D A Result: B Result: C B A(rot) A + 1 2 C + |+| × 2
Convert to LIR D 5 3 |+| + A 1 2 4 3 1 3 C + A 2 A 1 (rot) × C B 2 B 1 Result: D A Result: B Result: C B A(rot) A + 1 2 C + |+| × 2
 1 + Result: C A 2 |+| Result:") Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C ×
Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C ×
 1 + Result: C A 2 |+| Result:") Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × 1 2 3 4 . . . 8192
Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × 1 2 3 4 . . . 8192
 1 + Result: C A 2 |+| Result:") Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × 1 2 3 4 . . . 8192 1
Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × 1 2 3 4 . . . 8192 1
 1 + Result: C A 2 |+| Result:") Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 );
Code Generation Result: B A(rot) 1 + Result: C A 2 |+| Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 );
 Code Generation Result: C A 2 |+| Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va );
Code Generation Result: C A 2 |+| Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va );
 Code Generation Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va ); vector ( VVW, VADD, vb, va );
Code Generation Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va ); vector ( VVW, VADD, vb, va );
 Code Generation Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va ); vector ( VVW, VADD, vb, va ); vector ( VVW, VADD, vc, vb ); } vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); vector_wait_for_dma (); vector_free (); }
Code Generation Result: D A B + C × #include "vector. h“ int main(){ int A[8192] = {1, 2, 3, 4, … 8192}; int *va = ( int *) vector_malloc ( 32772 ); int *vb = ( int *) vector_malloc ( 32768 ); int *vc = ( int *) vector_malloc ( 32768 ); int *vd = ( int *) vector_malloc ( 32772 ); int *vtemp = va; vector_dma_to_vector ( va, A, 32772 ); for(int i=0; i<4; i++){ vector_set_vl ( 1024 ); vtemp = va; va = vd; vd = vtemp; vector_wait_for_dma (); if(i<3) vector_dma_to_vector ( va, A+(i+1)*1024, 32772 ); if(i>0){ vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); } vector ( SVW, VADD, vb, 1, va+1 ); vector_abs ( SVW, VADD, vc, 2, va ); vector ( VVW, VADD, vb, va ); vector ( VVW, VADD, vc, vb ); } vector_instr_sync (); vector_dma_to_host ( A+(i-1)*1024, vc, 32768 ); vector_wait_for_dma (); vector_free (); }
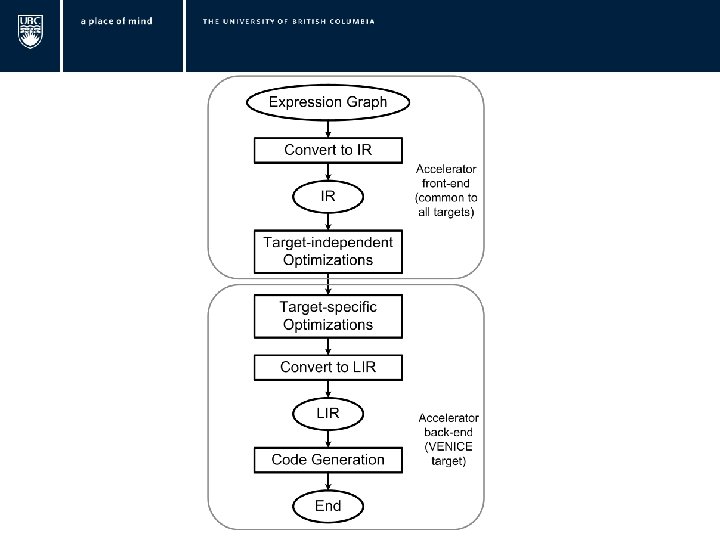
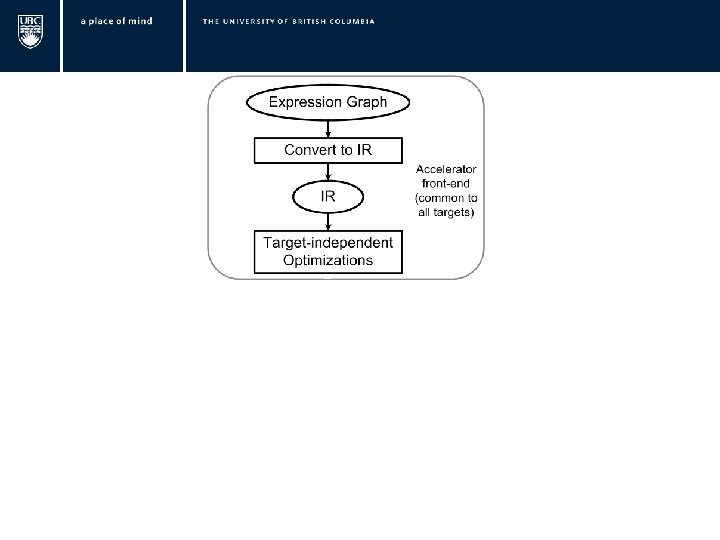
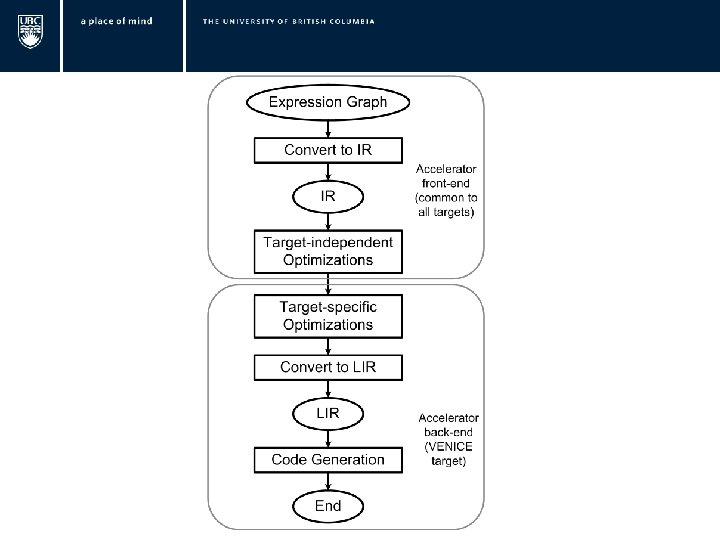
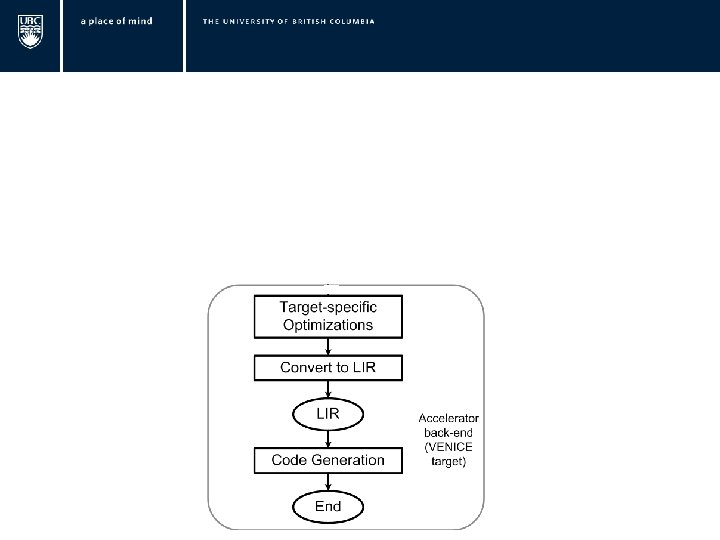
 Expression Graph Convert to IR LIR IR CSE Combine Memory transforms Calculate Register Size Allocate Memory Sub-divide IR Initialize Memory Move Bounds to Leaves Transfer Data To Scratchpad Constant folding Set VL Combine Operations Evaluation Ordering Buffer Counting Convert To LIR Write Vector Instructions Transfer Result To Host Need Double buffering? VENICE Code
Expression Graph Convert to IR LIR IR CSE Combine Memory transforms Calculate Register Size Allocate Memory Sub-divide IR Initialize Memory Move Bounds to Leaves Transfer Data To Scratchpad Constant folding Set VL Combine Operations Evaluation Ordering Buffer Counting Convert To LIR Write Vector Instructions Transfer Result To Host Need Double buffering? VENICE Code
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 370 x 100 V 1 human V 1") Speedup (relative to Nios II/f) 370 x 100 V 1 human V 1 compiler V 4 human V 4 compiler V 16 human 10 V 16 compiler V 64 human V 64 compiler 1 fir Speedups Compiler vs. Human V 1 V 4 V 16 V 64 fi 2 D r nd life le gb im ian ed m st ote m n ge a me o fir 2 Dfir life imgblend median motest 1. 04 x 1. 01 x 1. 09 x 1. 30 x 0. 97 x 1. 12 x 1. 42 x 1. 01 x 1. 10 x 1. 38 x 2. 24 x 1. 00 x 1. 02 x 0. 90 x 0. 92 x 0. 99 x 1. 07 x 0. 96 x 0. 81 x 1. 01 x 1. 04 x
Speedup (relative to Nios II/f) 370 x 100 V 1 human V 1 compiler V 4 human V 4 compiler V 16 human 10 V 16 compiler V 64 human V 64 compiler 1 fir Speedups Compiler vs. Human V 1 V 4 V 16 V 64 fi 2 D r nd life le gb im ian ed m st ote m n ge a me o fir 2 Dfir life imgblend median motest 1. 04 x 1. 01 x 1. 09 x 1. 30 x 0. 97 x 1. 12 x 1. 42 x 1. 01 x 1. 10 x 1. 38 x 2. 24 x 1. 00 x 1. 02 x 0. 90 x 0. 92 x 0. 99 x 1. 07 x 0. 96 x 0. 81 x 1. 01 x 1. 04 x
 Scaling performance of VENICE 64. 0 Speedups vs. V 1 32. 0 linear scale 16. 0 fir 8. 0 2 Dfir life 4. 0 imgblend 2. 0 median 1. 0 motest 0. 5 V 1 V 4 V 16 V 64
Scaling performance of VENICE 64. 0 Speedups vs. V 1 32. 0 linear scale 16. 0 fir 8. 0 2 Dfir life 4. 0 imgblend 2. 0 median 1. 0 motest 0. 5 V 1 V 4 V 16 V 64
 Scaling performance of AMD Opteron 16. 00 linear scale 8. 00 fir 4. 00 2 D fir 2. 00 imgblend 1. 00 life 0. 50 motest 0. 25 ore 1 c res o 2 c res o 4 c res o 8 c 1 o 6 c res Scaling performance of Intel Xeon o 2 c 3 Speedup vs. sequential 32. 00 4. 00 linear scale fir 2. 00 2 D fir 1. 00 imgblend life 0. 50 motest median 0. 25 1 core 2 cores 4 cores
Scaling performance of AMD Opteron 16. 00 linear scale 8. 00 fir 4. 00 2 D fir 2. 00 imgblend 1. 00 life 0. 50 motest 0. 25 ore 1 c res o 2 c res o 4 c res o 8 c 1 o 6 c res Scaling performance of Intel Xeon o 2 c 3 Speedup vs. sequential 32. 00 4. 00 linear scale fir 2. 00 2 D fir 1. 00 imgblend life 0. 50 motest median 0. 25 1 core 2 cores 4 cores
 CPU fir Xeon E 5540 (2.") Compare to Intel CPU Benchmark Runtime (ms) CPU fir Xeon E 5540 (2. 53 GHz) VENICE (V 64, 100 MHz) Speedup 2 Dfir life imgblend median motest 0. 07 0. 44 0. 53 0. 12 9. 97 0. 24 0. 07 0. 29 0. 23 0. 33 3. 11 0. 22 1. 0 x 1. 5 x 2. 3 x 0. 4 x 3. 2 x 1. 1 x Compile Time Compile time(ms) fir 2 D fir life imgblend median motest geomean 4. 74 5. 05 4. 49 4. 44 92. 72 24. 27 10. 12
Compare to Intel CPU Benchmark Runtime (ms) CPU fir Xeon E 5540 (2. 53 GHz) VENICE (V 64, 100 MHz) Speedup 2 Dfir life imgblend median motest 0. 07 0. 44 0. 53 0. 12 9. 97 0. 24 0. 07 0. 29 0. 23 0. 33 3. 11 0. 22 1. 0 x 1. 5 x 2. 3 x 0. 4 x 3. 2 x 1. 1 x Compile Time Compile time(ms) fir 2 D fir life imgblend median motest geomean 4. 74 5. 05 4. 49 4. 44 92. 72 24. 27 10. 12
 Using smaller data types fir byte 2 D fir halfword Speedup using bytes V 1 3. 93 x V 4 3. 54 x V 16 2. 90 x Speedup using halfwords V 1 1. 96 x V 4 2. 00 x V 16 1. 97 x life byte imgblend median halfword byte 4. 36 x 3. 83 x 3. 22 x 4. 07 x 4. 03 x 4. 00 x 1. 54 x 1. 46 x 1. 83 x motest word geomean 4. 12 x 3. 79 x 3. 34 x 1. 71 x 1. 90 x
Using smaller data types fir byte 2 D fir halfword Speedup using bytes V 1 3. 93 x V 4 3. 54 x V 16 2. 90 x Speedup using halfwords V 1 1. 96 x V 4 2. 00 x V 16 1. 97 x life byte imgblend median halfword byte 4. 36 x 3. 83 x 3. 22 x 4. 07 x 4. 03 x 4. 00 x 1. 54 x 1. 46 x 1. 83 x motest word geomean 4. 12 x 3. 79 x 3. 34 x 1. 71 x 1. 90 x
 Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
Outline: q. Motivation q. Background q. Implementation q. Results q. Conclusion
 Conclusions: q. The compiler greatly improves the programming and debugging experience for VENICE. q. The compiler produces highly optimized VENICE code and achieves performance close-to or betterthan hand-optimized code. q. The compiler demonstrates the feasibility of using high-abstraction languages, such as Microsoft Accelerator with pluggable 3 rd-party back-end support to provide a sustainable solution for future emerging hardware.
Conclusions: q. The compiler greatly improves the programming and debugging experience for VENICE. q. The compiler produces highly optimized VENICE code and achieves performance close-to or betterthan hand-optimized code. q. The compiler demonstrates the feasibility of using high-abstraction languages, such as Microsoft Accelerator with pluggable 3 rd-party back-end support to provide a sustainable solution for future emerging hardware.
 Thank you !
Thank you !
 Optimal VL for V 16 8192 16384") Look-up Table Input Data Sizes (words) Optimal VL for V 16 8192 16384 32768 65536 131072 262144 524288 1048576 1 4096 8192 8192 2 4096 8192 8192 3 2048 4096 8192 4 1024 2048 4096 8192 5 1024 2048 4096 8192 6 1024 2048 4096 8192 7 1024 2048 4096 8192 8 1024 2048 4096 8192 9 1024 2048 4096 8192 10 1024 2048 4096 8192 11 1024 2048 4096 8192 12 1024 2048 4096 8192 13 1024 2048 4096 8192 14 1024 2048 4096 8192 15 1024 2048 4096 8192 16 1024 2048 4096 8192 Instruction Count
Look-up Table Input Data Sizes (words) Optimal VL for V 16 8192 16384 32768 65536 131072 262144 524288 1048576 1 4096 8192 8192 2 4096 8192 8192 3 2048 4096 8192 4 1024 2048 4096 8192 5 1024 2048 4096 8192 6 1024 2048 4096 8192 7 1024 2048 4096 8192 8 1024 2048 4096 8192 9 1024 2048 4096 8192 10 1024 2048 4096 8192 11 1024 2048 4096 8192 12 1024 2048 4096 8192 13 1024 2048 4096 8192 14 1024 2048 4096 8192 15 1024 2048 4096 8192 16 1024 2048 4096 8192 Instruction Count
 Using different vector length on a benchmark has an input size of 8192 words 6400 1 op 5400 2 ops 4900 3 ops 4400 5 ops 3900 6 ops 7 ops 3400 8 ops 2900 Buffer Sizes (words) 2 81 9 96 40 48 20 24 10 2 51 6 2400 25 Cycle Count 5900
Using different vector length on a benchmark has an input size of 8192 words 6400 1 op 5400 2 ops 4900 3 ops 4400 5 ops 3900 6 ops 7 ops 3400 8 ops 2900 Buffer Sizes (words) 2 81 9 96 40 48 20 24 10 2 51 6 2400 25 Cycle Count 5900
 Using different vector length on a benchmark has 16 ops 8192 1. 25 16384 1. 20 32768 65536 1. 15 131072 262144 1. 10 524288 1. 05 Buffer Sizes (words) 92 81 96 40 48 20 24 10 2 51 6 1. 00 25 Cycle Count/Element 1. 30
Using different vector length on a benchmark has 16 ops 8192 1. 25 16384 1. 20 32768 65536 1. 15 131072 262144 1. 10 524288 1. 05 Buffer Sizes (words) 92 81 96 40 48 20 24 10 2 51 6 1. 00 25 Cycle Count/Element 1. 30
 “Virtual Vector Register File” Number of vector registers = 4 Vector register size = 1024
“Virtual Vector Register File” Number of vector registers = 4 Vector register size = 1024
 After (ms) Speedup V 4 2.") Combine Operators for Motion Estimation Before (ms) After (ms) Speedup V 4 2. 03 1. 36 1. 49 x V 16 0. 55 0. 37 1. 48 x V 64 0. 30 0. 21 1. 43 x
Combine Operators for Motion Estimation Before (ms) After (ms) Speedup V 4 2. 03 1. 36 1. 49 x V 16 0. 55 0. 37 1. 48 x V 64 0. 30 0. 21 1. 43 x
 Performance Degradation on median int *v_min = v_input 1; int *v_max = v_input 2; vector ( VVW, VOR, v_tmp, v_min ); vector ( VVW, VSUB, v_sub, v_max, v_min ); vector ( VVW, VCMV_LTZ, v_min, v_max, v_sub ); vector ( VVW, VCMV_LTZ, v_max, v_tmp, v_sub ); Human-written compare-and-swap vector ( VVW, VSUB, v_sub, v_input 1, v_input 2 ); vector ( VVW, VCMV_GTEZ, v_min, v_input 2, v_sub ); vector ( VVW, VCMV_LTZ, v_min, v_input 1, v_sub ); vector ( VVW, VCMV_GTEZ, v_min, v_input 1, v_sub ); vector ( VVW, VCMV_LTZ, v_max, v_input 2, v_sub ); Compiler-generated compare-and-swap
Performance Degradation on median int *v_min = v_input 1; int *v_max = v_input 2; vector ( VVW, VOR, v_tmp, v_min ); vector ( VVW, VSUB, v_sub, v_max, v_min ); vector ( VVW, VCMV_LTZ, v_min, v_max, v_sub ); vector ( VVW, VCMV_LTZ, v_max, v_tmp, v_sub ); Human-written compare-and-swap vector ( VVW, VSUB, v_sub, v_input 1, v_input 2 ); vector ( VVW, VCMV_GTEZ, v_min, v_input 2, v_sub ); vector ( VVW, VCMV_LTZ, v_min, v_input 1, v_sub ); vector ( VVW, VCMV_GTEZ, v_min, v_input 1, v_sub ); vector ( VVW, VCMV_LTZ, v_max, v_input 2, v_sub ); Compiler-generated compare-and-swap
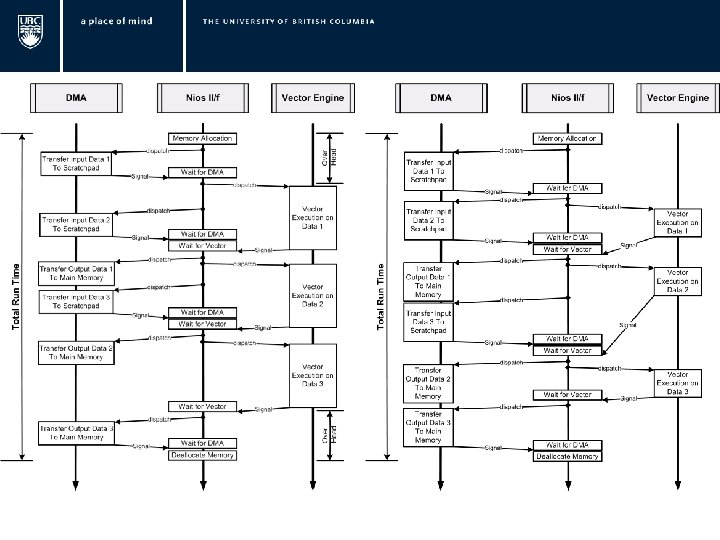
 Double Buffering
Double Buffering