194dee4cdfc572d05a567dc9c42f896d.ppt
- Количество слайдов: 159



第 6章 知识获取
知识获取的定义和基本原理; (2)主要的知识获取方法,包括:机器学习、数据挖掘与 知识发现; (3)知识获取在智能信息系统中的应用,包括领域知识的 获取、专家知识的获取、用户知识的获取等。")
本章主要内容 (1)知识获取的定义和基本原理; (2)主要的知识获取方法,包括:机器学习、数据挖掘与 知识发现; (3)知识获取在智能信息系统中的应用,包括领域知识的 获取、专家知识的获取、用户知识的获取等。

6. 1 知识获取概述 知识获取是人 智能和知识 程的核心技术。知识获取 和知识表示是建立、完善和扩展知识库的基础,是利用知识 进行推理求解问题的前提。智能信息系统中知识的质量和数 量直接影响其系统性能,知识获取成为智能信息系统开发的 关键。本章在概述知识获取的基础上,重点讨论机器学习、 数据挖掘与知识发现的基本原理与方法,并进一步论述知识 获取在智能信息系统中的应用。

6. 1. 1 知识获取定义 所谓知识获取,就是模拟人类学习知识的基本过程,从 信息源中抽取出所需知识,并将其转换成可被计算机程序利 用的表示形式。具体说,知识获取就是获得事实、规则及模 式的集合,并把它们转换为符合计算机知识表示的形式。信 息源主要是人类专家、书本、数据库和网络信息源等。 与信息收集的区别: 信息收集实现信息源浅层内容的获取; 知识获取实现信息源深层知识的获取。

6. 1. 2 知识获取的基本任务 这里通过类比人类学习知识的过程考察知识获取的基本任务。 人类学习知识的过程如下图所示。首先,了解基本的领域知识和 分析解决问题的方法,即对现有知识的固化记忆;然后,不断在 大量的实践活动中进行学习,即对实践数据进行分析、综合,并 从实践中总结经验,形成新知识;随后,将新知识与其已有的知 识进行融合,逐步精炼、完善和积累知识。
 (1)知识抽取。所谓知识抽取是指把蕴含于信息源中的 知识经过识别、理解、筛选、归纳等过程抽取出来,并存储 于知识库中。 (2)知识建模。知识建模即构建知识模型的过程。构建 知识模型的过程可以分为若干个阶段,其中主要的三个阶段 是:知识识别、知识规范说明和知识精化。 (3)知识转换。所谓知识转换是指把知识由一种表示形 式变换为另一种表示形式。如将从专家及文献资料那里抽取 的知识转换为产生式规则、框架等知识表示模式。")
知识获取的基本任务: (通过分析人类学习知识的基本过程) (1)知识抽取。所谓知识抽取是指把蕴含于信息源中的 知识经过识别、理解、筛选、归纳等过程抽取出来,并存储 于知识库中。 (2)知识建模。知识建模即构建知识模型的过程。构建 知识模型的过程可以分为若干个阶段,其中主要的三个阶段 是:知识识别、知识规范说明和知识精化。 (3)知识转换。所谓知识转换是指把知识由一种表示形 式变换为另一种表示形式。如将从专家及文献资料那里抽取 的知识转换为产生式规则、框架等知识表示模式。
 (4)知识存储。用适当方式表示知识,并经编辑、编译 后存入知识库。 (5)知识检测。为保证知识库中知识的一致性、完整性, 需要做好对知识的检测。 (6)知识库的重组。当系统经过一段时间运行后,由于 对知识库进行了多次的增、删、改,知识库的结构必然会发 生一些变化,需要对知识库中的知识重新进行组织。")
知识获取的基本任务(续) (4)知识存储。用适当方式表示知识,并经编辑、编译 后存入知识库。 (5)知识检测。为保证知识库中知识的一致性、完整性, 需要做好对知识的检测。 (6)知识库的重组。当系统经过一段时间运行后,由于 对知识库进行了多次的增、删、改,知识库的结构必然会发 生一些变化,需要对知识库中的知识重新进行组织。

6. 1. 3 知识获取方法 知识系统可用多种方法从多种信息源获取知识。如通过 与专家会谈、观察专家的问题求解过程、利用智能编辑系统、 应用机器学习中的归纳程序、使用文本理解系统等方式,获 取人类专家的知识或将其转换成所需要的形式,也可以从经 验数据、实例、出版物、数据库以及网络信息源中获取各种 知识。一般来说,按照知识获取的自动化程度,可以将知识 获取划分为非自动知识获取和自动知识获取两类基本方式。
非自动知识获取方式 在非自动的知识获取方式中,知识获取分两步进行,首先由知 识 程师从相应信息源获取知识;然后再由知识 程师通过某种 知识编辑软件将知识输入知识库。其 作方式如下图所示。 (1)知识 程师既懂得如何与领域专家打交道,能从领域专家及 有关文献中获得知识系统所需要的知识,又熟悉知识处理技术。 其主要任务是:获取知识系统所需要的原始知识;对其进行分析、 归纳、整理、升华,用自然语言描述之;然后由领域专家审查; 把最后确定的知识内容用知识表示语言表示出来,通过知识编辑 器进行编辑输入。")
(一)非自动知识获取方式 在非自动的知识获取方式中,知识获取分两步进行,首先由知 识 程师从相应信息源获取知识;然后再由知识 程师通过某种 知识编辑软件将知识输入知识库。其 作方式如下图所示。 (1)知识 程师既懂得如何与领域专家打交道,能从领域专家及 有关文献中获得知识系统所需要的知识,又熟悉知识处理技术。 其主要任务是:获取知识系统所需要的原始知识;对其进行分析、 归纳、整理、升华,用自然语言描述之;然后由领域专家审查; 把最后确定的知识内容用知识表示语言表示出来,通过知识编辑 器进行编辑输入。
知识编辑器是一种用于知识编辑和输入的软件,一般采 用交互 作方式,其主要功能是: ①将获取的知识转换成计算机可表示的内部形式,并输 入知识库。 ②检测知识的错误,包括内容错误和语法错误,例如, 知识的正确性、完整性和一致性等。并报告错误性质、原因 与部位,以便进行修正。")
(2)知识编辑器是一种用于知识编辑和输入的软件,一般采 用交互 作方式,其主要功能是: ①将获取的知识转换成计算机可表示的内部形式,并输 入知识库。 ②检测知识的错误,包括内容错误和语法错误,例如, 知识的正确性、完整性和一致性等。并报告错误性质、原因 与部位,以便进行修正。
知识 程师获取专家的知识,用英语描述后输入系统; (2)系统将其翻译为LISP语言的表示形式,然后再用英语的 描述形式显示出来,供知识 程师或领域专家检查; (3)如有错误,则由知识 程师与领域专家协商修改,再重 复(1)和(2)的")
实例:专家系统MYCIN的知识获取 非自动方式是知识库系统建造中用得较普遍的一种知识获取方 式。早期专家系统都是运用这种方式建造的,如DENDRAL、 MYCIN等。其中,专家系统MYCIN是最具代表性的一个,它用产 生式规则作为表示知识的模式,用LISP语言表示规则。其知识获 取步骤如下: (1)知识 程师获取专家的知识,用英语描述后输入系统; (2)系统将其翻译为LISP语言的表示形式,然后再用英语的 描述形式显示出来,供知识 程师或领域专家检查; (3)如有错误,则由知识 程师与领域专家协商修改,再重 复(1)和(2)的 作,直到被确认正确为止; (4)对于新规则,则需检查它与知识库中知识的一致性,有 错则修改; (5)将正确的规则送入知识库。
自动知识获取方式 手 获取知识建立知识库是一件相当困难且费时费力的 作,已构成知识 程的瓶颈。为了解决这个难题,人们尝 试运用各种理论和方法实现知识的自动化获取。 所谓自动知识获取是指系统采用相关的知识获取方法, 直接从信息源“学习”相关的基础知识,以及从系统自身的运 行实践中总结、归纳出新知识,不断自我完善,建立起性能 优良的知识库。其 作方式如图所示。")
(二)自动知识获取方式 手 获取知识建立知识库是一件相当困难且费时费力的 作,已构成知识 程的瓶颈。为了解决这个难题,人们尝 试运用各种理论和方法实现知识的自动化获取。 所谓自动知识获取是指系统采用相关的知识获取方法, 直接从信息源“学习”相关的基础知识,以及从系统自身的运 行实践中总结、归纳出新知识,不断自我完善,建立起性能 优良的知识库。其 作方式如图所示。
自然语言理解方式主要借助于自然语言处理技术,针对 文本类型的信息源,通过语法、语义分析,推导文本内容属 性,抽取与领域相关的语义实体及其关系,实现知识获取。 从本质上说,虽然自然语言理解是最理想的自动知识获取方 法,但由于自然语言处理中多项难点技术(如抽词技术、切 分词技术、短语识别技术等)尚未得到有效解决,因此,给 基于自然语言理解的知识自动获取利用带来一定困难。")
实现自动知识获取的主要方法: (1)自然语言理解方式主要借助于自然语言处理技术,针对 文本类型的信息源,通过语法、语义分析,推导文本内容属 性,抽取与领域相关的语义实体及其关系,实现知识获取。 从本质上说,虽然自然语言理解是最理想的自动知识获取方 法,但由于自然语言处理中多项难点技术(如抽词技术、切 分词技术、短语识别技术等)尚未得到有效解决,因此,给 基于自然语言理解的知识自动获取利用带来一定困难。
模式识别 基于模式识别的知识获取方法主要针对多媒体信息源( 如图片、语音波形、符号等),采用统计方法等对事物或现 象进行描述、辨认、分类和解释,从经数字化处理后的数据 中识别事物对象的特征。 (3)机器学习是系统利用各种学习方法来获取知识,是一种 高级的全自动化的知识获取方法。机器学习还具有从运行实 践中学习的能力,能纠正可能存在的错误,产生新的知识, 从而不断进行知识库的积累、修改和扩充。")
实现自动知识获取的主要方法: (2)模式识别 基于模式识别的知识获取方法主要针对多媒体信息源( 如图片、语音波形、符号等),采用统计方法等对事物或现 象进行描述、辨认、分类和解释,从经数字化处理后的数据 中识别事物对象的特征。 (3)机器学习是系统利用各种学习方法来获取知识,是一种 高级的全自动化的知识获取方法。机器学习还具有从运行实 践中学习的能力,能纠正可能存在的错误,产生新的知识, 从而不断进行知识库的积累、修改和扩充。
数据挖掘与知识发现 基于数据挖掘的知识获取是近几年发展起来的新方法, 它主要针对结构化的数据库,采用统计学习等定量化分析方 法,发现大量数据之间所存在的关联。虽然数据挖掘与机器 学习都是从数据中提取知识,但两者之间存在区别:机器学 习主要针对特定模式的数据进行学习;数据挖掘则是从实际 的海量数据源中发现、抽取知识。由于数据挖掘技术简单易 行,目前已逐步发展成为金融业、保险业、零售业、电信、 生物等领域中颇具影响力的知识获取 具。")
(4)数据挖掘与知识发现 基于数据挖掘的知识获取是近几年发展起来的新方法, 它主要针对结构化的数据库,采用统计学习等定量化分析方 法,发现大量数据之间所存在的关联。虽然数据挖掘与机器 学习都是从数据中提取知识,但两者之间存在区别:机器学 习主要针对特定模式的数据进行学习;数据挖掘则是从实际 的海量数据源中发现、抽取知识。由于数据挖掘技术简单易 行,目前已逐步发展成为金融业、保险业、零售业、电信、 生物等领域中颇具影响力的知识获取 具。
机器感知 基于机器感知的知识获取主要依靠机器的视觉、听觉、 触觉、味觉等传感器获取生理及行为特征信号,直接感知外 部世界。它需要采用人 智能方法和技术,观测、建模、识 别外界信息,从而创建感知能力。机器感知是一项高智能的 活动,比自然语言理解、模式识别具有更复杂的能力,目前 还只是处于探索中。 本章将主要论述机器学习和数据挖掘这两类方法。")
(5)机器感知 基于机器感知的知识获取主要依靠机器的视觉、听觉、 触觉、味觉等传感器获取生理及行为特征信号,直接感知外 部世界。它需要采用人 智能方法和技术,观测、建模、识 别外界信息,从而创建感知能力。机器感知是一项高智能的 活动,比自然语言理解、模式识别具有更复杂的能力,目前 还只是处于探索中。 本章将主要论述机器学习和数据挖掘这两类方法。

自动知识获取方式的展望 自动知识获取是一种理想的知识获取方式,它涉及到人 智能的多个研究领域,如模式识别、自然语言理解、机器 学习等,对硬件亦有较高的要求。而目前这些领域尚处于研 究阶段,有许多理论及技术上的问题需要做进一步的研究, 就目前已经取得的研究成果而言,尚不足以真正实现自动知 识获取。因此,知识的完全自动获取目前还只能作为人们为 之奋斗的目标。
增 长知识和改善其技能的方法。如果一个计算机系统 具有学习能力,它就可以自动改进自身的执行性能 而不需要重新进行程序设计。")
6. 2 机器学习是人 智能研究中的一个重要领域。 学习是一种自然的认识处理,是人(或计算机)增 长知识和改善其技能的方法。如果一个计算机系统 具有学习能力,它就可以自动改进自身的执行性能 而不需要重新进行程序设计。
研究及其学习的目的 (1)开发学习的理论,模拟人类学习处理的认知模型,进行理论分析和学 习方法的探索。 (2)构造学习机器和具有学习能力的知识系统,帮助人类解决困难的社会、 技术和科学问题。 (二)机器学习研究的主要内容 (1)学习机理的研究。这是对人类学习机制的研究,即人类获取知识、技 能和抽象概念的天赋能力。通过这一研究,可以指导机器学习,以便解决机器 学习中存在的相关问题。 (2)学习方法与技术的研究。研究人类的学习过程,探索各种可能的学习")
6. 2. 1 概述 (一)研究及其学习的目的 (1)开发学习的理论,模拟人类学习处理的认知模型,进行理论分析和学 习方法的探索。 (2)构造学习机器和具有学习能力的知识系统,帮助人类解决困难的社会、 技术和科学问题。 (二)机器学习研究的主要内容 (1)学习机理的研究。这是对人类学习机制的研究,即人类获取知识、技 能和抽象概念的天赋能力。通过这一研究,可以指导机器学习,以便解决机器 学习中存在的相关问题。 (2)学习方法与技术的研究。研究人类的学习过程,探索各种可能的学习 方法,建立起独立于具体应用领域的学习算法。 (3)机器学习系统及应用研究。根据特定任务要求,建立相应的学习系统。
机器学习的作用 (1)获取新知识。学习可看作一种创造活动,可以获取说明型知 识、经验知识和技能。机器学习可以归纳新知识,如发现人类未曾想到 过的新概念和模型,可以缩短从专家处获取知识的历程。 (2)精炼知识库。完全自动化的知识获取是困难的,利用机器学 习维护知识库的完整性和一致性是较容易实现的。通过学习不仅可以发 现知识库中的错误和缺陷,还可以优化和简化知识。例如,参数学习系 统中,当知识表示为函数,可用于发现好的参数或可信值集合。 (3)辅助查找处理。当查找空间很大,描述很多,就可能产生组 合爆炸问题。因此,需要学习有效的启发式知识引导查找,忽略大量与 目标无关的描述或概念,也就是将学习作为一种查找处理。 (4)形成新理论。探索新知识可被看作理论形成的处理。理论形 成的一个方面是归纳推理,从具体实例推导一般规律(假设)。理论形 成的另一方面是验证假设,寻找与一般理论的上下文有关的事实证据,")
(三)机器学习的作用 (1)获取新知识。学习可看作一种创造活动,可以获取说明型知 识、经验知识和技能。机器学习可以归纳新知识,如发现人类未曾想到 过的新概念和模型,可以缩短从专家处获取知识的历程。 (2)精炼知识库。完全自动化的知识获取是困难的,利用机器学 习维护知识库的完整性和一致性是较容易实现的。通过学习不仅可以发 现知识库中的错误和缺陷,还可以优化和简化知识。例如,参数学习系 统中,当知识表示为函数,可用于发现好的参数或可信值集合。 (3)辅助查找处理。当查找空间很大,描述很多,就可能产生组 合爆炸问题。因此,需要学习有效的启发式知识引导查找,忽略大量与 目标无关的描述或概念,也就是将学习作为一种查找处理。 (4)形成新理论。探索新知识可被看作理论形成的处理。理论形 成的一个方面是归纳推理,从具体实例推导一般规律(假设)。理论形 成的另一方面是验证假设,寻找与一般理论的上下文有关的事实证据, 并且比较多种可能的假设来选择较好的。
机器学习所用到的推理方法 目前机器学习所用到的推理方法可分为三大类: Ø基于演绎的保真性推理 Ø基于归纳的从个别到一般的推理 Ø基于类比的从个别到个别的推理 不同的学习系统采用不同的推理方法。早期的机器学习 系统一般采用单一的推理学习方法,而现在则趋于采用多种 推理技术支持的学习方法。学习中使用的推理越多,表明系 统的学习能力越强。")
(四)机器学习所用到的推理方法 目前机器学习所用到的推理方法可分为三大类: Ø基于演绎的保真性推理 Ø基于归纳的从个别到一般的推理 Ø基于类比的从个别到个别的推理 不同的学习系统采用不同的推理方法。早期的机器学习 系统一般采用单一的推理学习方法,而现在则趋于采用多种 推理技术支持的学习方法。学习中使用的推理越多,表明系 统的学习能力越强。
机器学习的类型 根据学习原理,机器学习类型如下: (1)机械学习(Rote Learning) 机械学习是最简单的学习策略。这种学习策略不需要任何推理 过程。通过提供人机接口,将外界的知识按照系统内部的知识表 示方法进行组织,由于所输入的知识的表示方式与内部完全一致, 不需要任何处理和转换就可以直接存储并提供给用户检索和使用。 机械学习中,环境所提供的知识与执行环节中使用的知识有着相 同的形式和水平。虽然机械学习在方法上看来简单,但由于计算 机的存储容量较大,检索速度较快,而且记忆准确,所以也产生 较好的效果。如Samuel西洋象棋程序就是采用了这种机械记忆策 略,它记忆每个棋局以便提高下棋水平。")
(五)机器学习的类型 根据学习原理,机器学习类型如下: (1)机械学习(Rote Learning) 机械学习是最简单的学习策略。这种学习策略不需要任何推理 过程。通过提供人机接口,将外界的知识按照系统内部的知识表 示方法进行组织,由于所输入的知识的表示方式与内部完全一致, 不需要任何处理和转换就可以直接存储并提供给用户检索和使用。 机械学习中,环境所提供的知识与执行环节中使用的知识有着相 同的形式和水平。虽然机械学习在方法上看来简单,但由于计算 机的存储容量较大,检索速度较快,而且记忆准确,所以也产生 较好的效果。如Samuel西洋象棋程序就是采用了这种机械记忆策 略,它记忆每个棋局以便提高下棋水平。
指导学习(Learning from Instruction) 就是对知识进行简单的语法转换,将它同化为已描述的知识结构 (模型、框架等)。对于使用传授学习策略的系统来说,外界所 输入知识的表示方式与内部知识的表示方式不完全一致,系统在 接受外部知识时需要一定的推理、翻译和转化 作。MYCIN、 DENDRAL等专家系统在获取知识上都采用这种学习策略。 (3)归纳学习(Inductive Learning) 归纳学习是研究最广的一种符号学习方法。归纳学习采用归纳 推理。归纳推理是从部分到全体,从特殊到一般的推理过程。在 进行归纳学习时,学习者从所提供的事实或观察到的假设进行归")
(2)指导学习(Learning from Instruction) 就是对知识进行简单的语法转换,将它同化为已描述的知识结构 (模型、框架等)。对于使用传授学习策略的系统来说,外界所 输入知识的表示方式与内部知识的表示方式不完全一致,系统在 接受外部知识时需要一定的推理、翻译和转化 作。MYCIN、 DENDRAL等专家系统在获取知识上都采用这种学习策略。 (3)归纳学习(Inductive Learning) 归纳学习是研究最广的一种符号学习方法。归纳学习采用归纳 推理。归纳推理是从部分到全体,从特殊到一般的推理过程。在 进行归纳学习时,学习者从所提供的事实或观察到的假设进行归 纳推理,获得某个概念。应用归纳推理,系统可从环境提供的具 体事实中获取知识。
演绎学习(Deductive Learning) 演绎学习中,学习系统进行演绎推理,从源信息和它的背景知 识中推导出所需要的知识。 (5)类比学习(Learning by Analogy) 类比是一种很有效的推理方法,它能够清晰简洁地描述对象间 的相似性。为了使类比系统能够获得类似任务的有关知识,要求类 比学习系统必须能够发现当前任务与已知任务的相似之处,并由此 制定完成当前任务的方案,可看作是归纳和演绎学习的综合方法。 (6)基于案例的学习(Case-Based Learning) 计算机系统在执行任务的过程中,常接受、处理和积累大量的")
(4)演绎学习(Deductive Learning) 演绎学习中,学习系统进行演绎推理,从源信息和它的背景知 识中推导出所需要的知识。 (5)类比学习(Learning by Analogy) 类比是一种很有效的推理方法,它能够清晰简洁地描述对象间 的相似性。为了使类比系统能够获得类似任务的有关知识,要求类 比学习系统必须能够发现当前任务与已知任务的相似之处,并由此 制定完成当前任务的方案,可看作是归纳和演绎学习的综合方法。 (6)基于案例的学习(Case-Based Learning) 计算机系统在执行任务的过程中,常接受、处理和积累大量的 具体案例及过程。要求系统通过案例进行学习,需要对这些例子的 作模式与经验进行分析、总结和推广,得到完成任务的一般性规 律,并在进一步的 作中验证或修改这些规律。
机器学习系统 根据人类学习的原理和方法,机器学习系统需要通过学习 增长其知识、改善其性能、提高其智能水平。机器学习系统在 不同的学习环境、不同的应用条件下,一般也存在差异。例如, 专家系统中的知识获取,主要是获取专家的知识。而对于博弈 系统,在与对手较量的过程中,需要了解对方的长处与弱势, 从失败与成功的案例中总结经验教训并将其转换为内在的知识。 机器学习系统在学习过程中,需要使用合适的学习方法,通过 与环境多次交互,逐步达到一定的知识水平和求解问题的能力, 从而改善系统的性能。在获取知识过程中,机器学习系统中应")
6. 2. 2 机器学习系统的原理、结构和功能 (一)机器学习系统 根据人类学习的原理和方法,机器学习系统需要通过学习 增长其知识、改善其性能、提高其智能水平。机器学习系统在 不同的学习环境、不同的应用条件下,一般也存在差异。例如, 专家系统中的知识获取,主要是获取专家的知识。而对于博弈 系统,在与对手较量的过程中,需要了解对方的长处与弱势, 从失败与成功的案例中总结经验教训并将其转换为内在的知识。 机器学习系统在学习过程中,需要使用合适的学习方法,通过 与环境多次交互,逐步达到一定的知识水平和求解问题的能力, 从而改善系统的性能。在获取知识过程中,机器学习系统中应 设置知识库、人机接口等功能。
机器学习系统的结构和功能 机器学习系统的类型很多,但它们具有一些共同的要素。 图中给出了学习系统的一般构架,它包含 5个主要部分:环境、 控制与评价、学习、知识库和执行机制。 系统各部分简要描述如下:")
(二)机器学习系统的结构和功能 机器学习系统的类型很多,但它们具有一些共同的要素。 图中给出了学习系统的一般构架,它包含 5个主要部分:环境、 控制与评价、学习、知识库和执行机制。 系统各部分简要描述如下:
知识库(Knowledge Base) 用于存储、积累系统的知识,它包括规则集合、参数值、符 号结构等,供执行机制使用。它还具有知识增删、修改、扩充等 功能。知识库可组织为两个级别:长期存储器(Long Term Memory)和短期存储器(Short Term Memory)。长期存储器存 储较永久性的知识,它们是系统必须具备的先验背景知识。短期 存储器存放学习过程中的初始数据、中间结果等。 (2)学习部分(Learner) 学习部分是系统的核心部件,必须具备以下2个主要功能: ①进行学习推理。利用输入信息、评价指导信息和多种学习策略,")
(1)知识库(Knowledge Base) 用于存储、积累系统的知识,它包括规则集合、参数值、符 号结构等,供执行机制使用。它还具有知识增删、修改、扩充等 功能。知识库可组织为两个级别:长期存储器(Long Term Memory)和短期存储器(Short Term Memory)。长期存储器存 储较永久性的知识,它们是系统必须具备的先验背景知识。短期 存储器存放学习过程中的初始数据、中间结果等。 (2)学习部分(Learner) 学习部分是系统的核心部件,必须具备以下2个主要功能: ①进行学习推理。利用输入信息、评价指导信息和多种学习策略, 进行学习过程的知识推理,获得有关问题的解答和结论。②学习 部分还应能修改知识库,纠正系统的错误执行,自动改进系统的 执行性能。
执行机制(Performer) 该部分使用已学习到的知识去完成所规定的任务。它以各种 方法运用知识库中的规则引导系统的活动。例如,当学习过程修 改了知识库中的知识,系统行为将要随之改变。 (4)控制与评价(Control and Critic) 该部分的首要任务是评价系统执行性能,通过将系统的实际 结果与先验理想模型相比较,找出误差,分析错误,检测系统执 行效果。然后,系统根据评价和检测结果,将信息反馈给学习部 分,对学习进行指导,并控制输入信息的改进。 (5)环境(Environment) 环境指获取信息和知识的来源,包括实例集合、已存在的实 例数据库、人类专家等信息源。")
(3)执行机制(Performer) 该部分使用已学习到的知识去完成所规定的任务。它以各种 方法运用知识库中的规则引导系统的活动。例如,当学习过程修 改了知识库中的知识,系统行为将要随之改变。 (4)控制与评价(Control and Critic) 该部分的首要任务是评价系统执行性能,通过将系统的实际 结果与先验理想模型相比较,找出误差,分析错误,检测系统执 行效果。然后,系统根据评价和检测结果,将信息反馈给学习部 分,对学习进行指导,并控制输入信息的改进。 (5)环境(Environment) 环境指获取信息和知识的来源,包括实例集合、已存在的实 例数据库、人类专家等信息源。
描述语言是系统知识的表达机制。描述语言必须适 用于知识获取,应能表达系统中的两类重要知识:一类是输 入实例;另一类是系统产生的规则。知识的表示形式应易理 解、易转换。 (2)实例集合的选取对于学习系统是很重要的。很显然, 系统需要一个训练实例集合,依据这些实例,系统推导与输 入描述相关的规则或规则集。但是,系统产生的规则必须被 检测。因此系统还必须有另一个检测实例集合,若规则能成 功地应用于这些新的实例,则会提高规则的可信度。")
除了以上5个主要部件之外,与学习系统有关的其它2个 元素是描述语言和实例集合的选择。 (1)描述语言是系统知识的表达机制。描述语言必须适 用于知识获取,应能表达系统中的两类重要知识:一类是输 入实例;另一类是系统产生的规则。知识的表示形式应易理 解、易转换。 (2)实例集合的选取对于学习系统是很重要的。很显然, 系统需要一个训练实例集合,依据这些实例,系统推导与输 入描述相关的规则或规则集。但是,系统产生的规则必须被 检测。因此系统还必须有另一个检测实例集合,若规则能成 功地应用于这些新的实例,则会提高规则的可信度。

6. 2. 3 基于归纳的学习 所谓归纳学习,就是系统根据有关的数据或实例, 应用归纳推理推导出一般性规则或结论。系统可通过 实例学习,还可通过观察样品和通过发现而学习。归 纳学习可以迅速地产生知识库,是一种实验成功的、 有效的自动化学习方法。
归纳学习的原理 归纳学习是通过执行归纳推理来实现的。什么是归纳推 理呢?如图所示,归纳推理就是从已知事实和背景知识推导 出结论的处理过程,该结论描述已知事实。归纳推理是由特 殊到一般,若推导出的规则是正确的,那么不仅可将它用于 其它特例,还可用于一般情况。")
(一)归纳学习的原理 归纳学习是通过执行归纳推理来实现的。什么是归纳推 理呢?如图所示,归纳推理就是从已知事实和背景知识推导 出结论的处理过程,该结论描述已知事实。归纳推理是由特 殊到一般,若推导出的规则是正确的,那么不仅可将它用于 其它特例,还可用于一般情况。
选择归纳包括 : ①减少条件:就是从AND操作符连接的表达式中删掉一个或几个条件, 那么所得规则比原规则较一般化。例如, 原规则:如果 一个学生又聪明又很勤奋 那么 他的学习一定很好。 新规则:如果 一个学生很勤奋 那么 他的学习一定很好。 ②将常量转换为变量:将事实描述或规则条件中的常量代换为一个变")
适合于学习系统的归纳推理规则可分为以下两大类型: (1)选择归纳包括 : ①减少条件:就是从AND操作符连接的表达式中删掉一个或几个条件, 那么所得规则比原规则较一般化。例如, 原规则:如果 一个学生又聪明又很勤奋 那么 他的学习一定很好。 新规则:如果 一个学生很勤奋 那么 他的学习一定很好。 ②将常量转换为变量:将事实描述或规则条件中的常量代换为一个变 量。例如,likes(Liming, football)转为likes(X, football),则变量X可 代表任何一个人,即任何一个人都喜欢足球。
= Red,转为Flag(X)= Red OR Blue。 ④转换AND为OR:就是将条件中的AND操作符转为OR 操作符。例如A AND B,转为A OR B。 ⑤应用“相对扩展(Extend Against)”操作,扩展规则的")
③增加选择项:就是将可能的情形用OR操作符号连入规 则的条件中。例如Flag(X)= Red,转为Flag(X)= Red OR Blue。 ④转换AND为OR:就是将条件中的AND操作符转为OR 操作符。例如A AND B,转为A OR B。 ⑤应用“相对扩展(Extend Against)”操作,扩展规则的 条件。
构造归纳包括: ①计算参数满足一个条件,例如曲线拟合法,可从已存实例推导出新 规则。例如,对于(X, Y, Z)三元组有以下三个实例: 实例1:(0, 2, 7) 实例2:(6, ﹣ 1, 10) 实例3:(﹣ 1,")
(2)构造归纳包括: ①计算参数满足一个条件,例如曲线拟合法,可从已存实例推导出新 规则。例如,对于(X, Y, Z)三元组有以下三个实例: 实例1:(0, 2, 7) 实例2:(6, ﹣ 1, 10) 实例3:(﹣ 1, ﹣ 5, ﹣ 16) 其中X、Y是输入,Z是输出。采用最小平方回归分析,可推出规则: Z = 2 X+3 Y+1。 ②探索概念之间的从属关系,用较广义的概念代换较狭义的概念。例 如用“图书馆”代换“大学图书馆”。 ③用蕴含性质代换一个性质。例如,A蕴含B,则可用A代换B。
归纳学习的要素 归纳学习要求具有实例集合、规则集合和归纳学习算法 3 个基本元素。 (1)实例集合。实例集合形成归纳推理的基础。训练实例的 质量对学习系统的执行起着非常重要的作用。 (2)规则集合。归纳系统包含有不同的规则集合,如背景知 识规则集和假设规则集。整个规则空间通常用项和所执行的 各种运算来定义。 (3)归纳学习算法。学习系统要具备有效的归纳推理算法用 来从实例集合归纳出规则。从实例集合的查找、归纳能力及 处理输入中的错误与干扰等方面来看,有许多不同的归纳算法。")
(二)归纳学习的要素 归纳学习要求具有实例集合、规则集合和归纳学习算法 3 个基本元素。 (1)实例集合。实例集合形成归纳推理的基础。训练实例的 质量对学习系统的执行起着非常重要的作用。 (2)规则集合。归纳系统包含有不同的规则集合,如背景知 识规则集和假设规则集。整个规则空间通常用项和所执行的 各种运算来定义。 (3)归纳学习算法。学习系统要具备有效的归纳推理算法用 来从实例集合归纳出规则。从实例集合的查找、归纳能力及 处理输入中的错误与干扰等方面来看,有许多不同的归纳算法。
、当前的归纳命题、背景知识( Background Knowledge)、假设的选择标准。 寻找:一个归纳命题/假设(H),它蕴含观察描述(或事实),并满 足假设的选择标准。 例如: 前提:张华、李红和王刚都是中国人。 背景知识:他们都是哲学家。 哲学家都是人。 中国人都是人。 选择标准:产生的规则能确定哲学家的国籍。 推出结论:所有哲学家都是中国人。")
归纳学习的例子: 归纳学习的描述: 已知:观察描述或事实(F)、当前的归纳命题、背景知识( Background Knowledge)、假设的选择标准。 寻找:一个归纳命题/假设(H),它蕴含观察描述(或事实),并满 足假设的选择标准。 例如: 前提:张华、李红和王刚都是中国人。 背景知识:他们都是哲学家。 哲学家都是人。 中国人都是人。 选择标准:产生的规则能确定哲学家的国籍。 推出结论:所有哲学家都是中国人。 所有人都是中国人。 选择结论:所有哲学家都是中国人。
归纳学习方法 (1)根据是否有教师指导,归纳学习可分为通过实例学习和 通过观察与发现学习两类 通过实例学习,由教师提供正面实例和反面实例,由计 算机独立进行模型间的匹配,自动寻找差异,决定优先级别 和做出相应处理,完成模型的修改。通过实例学习,可从部 分信息推导整体规则,从实例信息推导类的特性。它还可从 离散的操作事件推导一般的问题求解步骤。 通过观察与发现学习,是根据环境提供的事例以及一些 规则,机器独立地发现正例和反例,并进行推理,发现新概 念,做出新猜想。例如概念聚类学习和BACON的发现学习。")
(三)归纳学习方法 (1)根据是否有教师指导,归纳学习可分为通过实例学习和 通过观察与发现学习两类 通过实例学习,由教师提供正面实例和反面实例,由计 算机独立进行模型间的匹配,自动寻找差异,决定优先级别 和做出相应处理,完成模型的修改。通过实例学习,可从部 分信息推导整体规则,从实例信息推导类的特性。它还可从 离散的操作事件推导一般的问题求解步骤。 通过观察与发现学习,是根据环境提供的事例以及一些 规则,机器独立地发现正例和反例,并进行推理,发现新概 念,做出新猜想。例如概念聚类学习和BACON的发现学习。
根据信息提供方式,归纳学习分为增量式和非增量式学习模式是:已知正、反实例集合和背景知识,学习 一般性的概念描述(规则),它覆盖所有的正面例子,不包括反 面实例。学习过程中,所有实例一次提供给程序。 增量式学习模式是:已知正面实例集合与反面实例集合、背景 知识和输入假设集合,实例分为若干组,逐次将每组实例加入输 入数据,同时,将前面程序运行的结果作为输入假设,逐渐修改 和精炼以前产生的规则和正在产生的规则。 著名的归纳学习算法有: ①TDIDT系列(Quinlan),采用决策树的自顶向下的归纳 方法; ②AQ系列(Michalski),采用决策树或规则的形式从训练 实例中归纳知识。 ③ASSISTANT学习系统")
(2)根据信息提供方式,归纳学习分为增量式和非增量式学习模式是:已知正、反实例集合和背景知识,学习 一般性的概念描述(规则),它覆盖所有的正面例子,不包括反 面实例。学习过程中,所有实例一次提供给程序。 增量式学习模式是:已知正面实例集合与反面实例集合、背景 知识和输入假设集合,实例分为若干组,逐次将每组实例加入输 入数据,同时,将前面程序运行的结果作为输入假设,逐渐修改 和精炼以前产生的规则和正在产生的规则。 著名的归纳学习算法有: ①TDIDT系列(Quinlan),采用决策树的自顶向下的归纳 方法; ②AQ系列(Michalski),采用决策树或规则的形式从训练 实例中归纳知识。 ③ASSISTANT学习系统
机器归纳学习系统:AQ 15 (1)系统概述 AQ 15是一个学习分类规则的归纳学习系统,是机器学习领域 中成功的典例。它由美国人 智能专家Michalski指导研制。 AQ 15是实例归纳学习方法,可执行增量或非增量式学习,从 基于属性描述的正、反实例中推导分类判断规则。学习过程中所 用的知识包括:①系统拥有的概念、规则和学习方法;②用户提 供的有关信息和规则;③选择标准,用于评估和优选假设。系统 的输入是实例集合和已知规则。系统的输出是一般、特殊等多种 形式的判断规则。AQl")
(四)机器归纳学习系统:AQ 15 (1)系统概述 AQ 15是一个学习分类规则的归纳学习系统,是机器学习领域 中成功的典例。它由美国人 智能专家Michalski指导研制。 AQ 15是实例归纳学习方法,可执行增量或非增量式学习,从 基于属性描述的正、反实例中推导分类判断规则。学习过程中所 用的知识包括:①系统拥有的概念、规则和学习方法;②用户提 供的有关信息和规则;③选择标准,用于评估和优选假设。系统 的输入是实例集合和已知规则。系统的输出是一般、特殊等多种 形式的判断规则。AQl 5应用谓词逻辑、规则、树等多种知识表示 方法;具有构造式学习能力来扩充和完善用户的输入数据;应用 AQ归纳学习方法产生判断规则;提供多种知识评价方法,对结果 假设进行检测和优化。
当存在输入事件时,输入假设用于增量 式学习的初始假设;若不需要增量式学习,可以不用它。ii)当 不存在输入事件时,输入假设被转换作为事件处理。AQl 5程序运 行的结果也可作为输入假设。")
系统输入信息主要包括以下三类: ①事件表:一个事件表描述一个对象类,包含一组训练实例,事 件表名就是类名。 ②背景知识:背景知识是由用户提供或系统已知的关于应用领域 的描述和如何构造规则的知识。它包括概念描述及其类型的定义、 定义结构描述的规则、构造新属性的规则以及评估候选假设的标 准。背景知识用于构造式学习功能,产生新的描述,以精炼输入 数据和简化结果假设。 ③输入假设:输入假设是关于事件类的描述,用于增量式学习。 输入假设有两种作用:i)当存在输入事件时,输入假设用于增量 式学习的初始假设;若不需要增量式学习,可以不用它。ii)当 不存在输入事件时,输入假设被转换作为事件处理。AQl 5程序运 行的结果也可作为输入假设。
系统结构和学习算法 AQ 15系统通过对输入的训练实例集合和背景知识执行归纳 推理,产生各类实例的判断规则,训练实例集合表示为属性向量 的合取范式。规则集合表示为析取范式。程序对逻辑表达式空间 执行启发式搜索,直至找到一个或一组判断规则,它们包含所有 的正面实例,不包含任何反面实例,并通过选择标准加以优选。 AQl 5系统包括以下5个子系统: ①装配。输入用户数据,检查错误,并将其转换为内部形式 ②预处理——构造式学习。程序应用用户输入的背景知识, 作用于输入的事件和假设,产生新的变量,系统进一步构造对应 新变量的表达式,然后利用确定的标准选择某些新变量,将其加 入到事件和假设中。构造式学习可以更精确地描述或完善输入数")
(2)系统结构和学习算法 AQ 15系统通过对输入的训练实例集合和背景知识执行归纳 推理,产生各类实例的判断规则,训练实例集合表示为属性向量 的合取范式。规则集合表示为析取范式。程序对逻辑表达式空间 执行启发式搜索,直至找到一个或一组判断规则,它们包含所有 的正面实例,不包含任何反面实例,并通过选择标准加以优选。 AQl 5系统包括以下5个子系统: ①装配。输入用户数据,检查错误,并将其转换为内部形式 ②预处理——构造式学习。程序应用用户输入的背景知识, 作用于输入的事件和假设,产生新的变量,系统进一步构造对应 新变量的表达式,然后利用确定的标准选择某些新变量,将其加 入到事件和假设中。构造式学习可以更精确地描述或完善输入数 据,以便产生和优化结果假设。
。 ⑤输出。该子程序输出结果关系表,在输出判断规则时,执 行附加计算,遍历结构的层次图,并用较高层次结点代换叶点的 值。")
③构造判断规则。程序应用广度优先方式搜索事件的分类结 构,为每个类产生判断规则。为了获得某类Ci的判断规则,它把 所有已知属于Ci类的实例作为正面实例,而按照某种方式构造Ci 的反面实例集,例如,把其余类中的所有实例作为反面实例,并 能处理模糊实例。 系统基于输入的实例集合和假设,应用AQ算法产生类的一 般性描述,它覆盖当前类的所有正面实例,不包含任何反面实例。 然后,根据用户选择的质量评估标准,选择最好的假设。最后, 简化整理所产生的判断规则,以关系表形式输出。 ④检测。应用检测实例集合检测系统产生的判断规则,方法 是测量每个检测实例与判断规则的概念隶属度(或匹配度)。 ⑤输出。该子程序输出结果关系表,在输出判断规则时,执 行附加计算,遍历结构的层次图,并用较高层次结点代换叶点的 值。

AQ 15系统的学习算法: AQ学习算法由Michalski于1969年提出,用于从给定的 正面实例集和反面实例集中归纳学习新的概念或规则,算法 步骤如下: ①从正面实例集中选择一个实例为种子; ②归纳产生一个Star,它一致地概括种子,排除所有反 面实例; ③依据给定的选择标准,从Star中选择最好的假设,必 要时进一步精炼假设; ④如果假设覆盖了所有正面实例,则停止;否则,选一 个尚未被假设覆盖的正例,转②。
e和一个反面实例集合 N={el,e 2,…,ek)。 寻找:一个集合G(e/N),它是一个极大概括实例e的 合取描述(Star),而不包含任何反面实例。")
为了产生一个Star,要相对于反面实例执行扩展操作。同 时为了获取最好的Star,要利用同化规则执行简化和整理 作,最后产生一个无冗余的合取描述。 首先给出Star算法的已知条件和要求: 已知:一个种子(正面实例)e和一个反面实例集合 N={el,e 2,…,ek)。 寻找:一个集合G(e/N),它是一个极大概括实例e的 合取描述(Star),而不包含任何反面实例。
PS = Extendagainst(e, ei),PS是变量的析取范式, 它覆盖正面实例e,即它的变量具有e的尽可能多的概括值, 该值不与ei的值重复; ii)Star = multiply(Star,")
Star算法: ①置Star的初始值为Φ; ②对每个反面实例ei,i = l,2,…,k,执行以下操作: i)PS = Extendagainst(e, ei),PS是变量的析取范式, 它覆盖正面实例e,即它的变量具有e的尽可能多的概括值, 该值不与ei的值重复; ii)Star = multiply(Star, PS),用i)的结果PS乘以前 面产生的初始假设(Star); iii)Star = best(Star, Max. Star, Pref. Crit),简化ii)产 生的结果:从Star中删除冗余部分,然后应用质量评估标准 选择最好的,解答个数小于“Max. Star”参数的元素。
 反面实例集N:el = (1,1,0);e 2 = (2,1,0)")
产生Star的例子描述如下: 实例空间:变量定义:X: 0,1,2;Y: 0,1;Z: 0,1 正面实例:e = (2,0,1) 反面实例集N:el = (1,1,0);e 2 = (2,1,0) 产生的部分Star: PSl:e ┫e 1={[X = 0 ∨ 2],[Y=0],[Z=1]} PS 2:e ┫e 2={[Y = 0]},[Z = 1]} 完整的Star: G(e/N)=PSl*PS 2={[X= 0∨ 2] & [Y=0],[X=0∨ 2]&[z =1], [Y=0]&[Y=0],[Y=0]&[Z=1],[Z=1}&[Y=0],[Z=1]&[Z=1]}={[Y=0], [Z=1])
样例和系统评价 以下样例是关于个人计算机的统计信息。假设有12台个 人计算机,每台计算机的特性用一组属性描述,例如它具有 的语言软件(Pascal, Fortran, Cobol),操作系统类型(OP -system),软盘驱动器个数(Floppies),硬盘的有无( Disk),处理器的类型(Processor),主存的大小( Memory),以及是否带有打印机(Printer)。所有的计算机 依据它们的价格分为三类:$1000以下,$1000至$4000和 $4000以上。12台计算机的信息描述于下:")
(3)样例和系统评价 以下样例是关于个人计算机的统计信息。假设有12台个 人计算机,每台计算机的特性用一组属性描述,例如它具有 的语言软件(Pascal, Fortran, Cobol),操作系统类型(OP -system),软盘驱动器个数(Floppies),硬盘的有无( Disk),处理器的类型(Processor),主存的大小( Memory),以及是否带有打印机(Printer)。所有的计算机 依据它们的价格分为三类:$1000以下,$1000至$4000和 $4000以上。12台计算机的信息描述于下:

![设用户选择的评估假设标准是,要求规则包含最简化的表达式。对于以上 的实例集合,AQ 15产生的确定计算机价格的判断规则如下: [cost=under 1000] if [Floppies=0] 意思是,如果一台计算机没有软盘驱动器则它的价格在 1000美元以下。 [cost=From 1000 to 4000] if](https://present5.com/presentation/194dee4cdfc572d05a567dc9c42f896d/image-49.jpg "设用户选择的评估假设标准是,要求规则包含最简化的表达式。对于以上 的实例集合,AQ 15产生的确定计算机价格的判断规则如下: [cost=under 1000] if [Floppies=0] 意思是,如果一台计算机没有软盘驱动器则它的价格在 1000美元以下。 [cost=From 1000 to 4000] if")
设用户选择的评估假设标准是,要求规则包含最简化的表达式。对于以上 的实例集合,AQ 15产生的确定计算机价格的判断规则如下: [cost=under 1000] if [Floppies=0] 意思是,如果一台计算机没有软盘驱动器则它的价格在 1000美元以下。 [cost=From 1000 to 4000] if [Floppies=1 V 2]&[Disk&Printer=no] 意思是,如果一台计算机有1至 2台软盘驱动器,没有硬盘和打印机,则它 的价格是 1000至 4000美元。 [cost = Over 4000] if [Disk=yes]V[Printer=yes] 意思是,如果一台计算机有硬盘或者有打印机,则它的价格在 4000美元 以上。 很明显,AQl 5程序产生的三条规则,可以正确地分类以上的计算机实例。
,这种严格要求不 适于大多数情况。对于大量的实例集合,系统有待改进。")
专家曾对于医学领域,将AQ 15系统、ASSISTANT学习系统 与医学专家进行比较,经 4次以上实验的平均值如下表所示。该 表说明AQ 15程序的诊断精确性接近人类专家的水平。 AQ 15程序还存在一些问题,例如,不能检查出输入数据 中的所有语法错误,执行中可能会出现死循环。另外,系统要 求教师提供准确的实例集合(正、反实例),这种严格要求不 适于大多数情况。对于大量的实例集合,系统有待改进。
。这里仅讨论智 能信息系统中的概念学习,研究领域对象(如文献、 专业术语、用户、提问等)及其关系的学习方法。 从应用的推理方式来看,有两种常用的概念学习 方法:归纳概念学习和演绎概念学习。")
6. 2. 4 基于概念的学习 在人 智能领域中,概念学习有着特殊的含义, 通常被认为是从环境中获取结构描述(这个描述就叫 做一个概念、一个模型或一个假设)。这里仅讨论智 能信息系统中的概念学习,研究领域对象(如文献、 专业术语、用户、提问等)及其关系的学习方法。 从应用的推理方式来看,有两种常用的概念学习 方法:归纳概念学习和演绎概念学习。
归纳概念学习就是从经验实例中推导出一般结论。给出 背景知识(BK)和概念的实例集合(E),当满足以下条件 可以推导出概念C: (a)BK ├→ E 实例不是背景知识的逻辑结论 (b)BK∪E ├→ ~C概念与实例、背景知识不矛盾 (c)BK∪C→E 实例是概念和背景知识的逻辑结论。")
(一)归纳概念学习就是从经验实例中推导出一般结论。给出 背景知识(BK)和概念的实例集合(E),当满足以下条件 可以推导出概念C: (a)BK ├→ E 实例不是背景知识的逻辑结论 (b)BK∪E ├→ ~C概念与实例、背景知识不矛盾 (c)BK∪C→E 实例是概念和背景知识的逻辑结论。
,而且可避免学习处理的错误导向。对于获取用 户分类模型的任务来说,用户的专业概念和系统经验是最重要的 属性,其描述了用户的领域知识水平和应用系统的技能。对每个 实例的属性赋予重要程度值后,应用归纳学习方法,可以判别哪 些用户是专家,哪些用户是无经验的新手,以建立用户分类模型, 并在查询过程中,逐步精炼,直到满足所期望的要求为止。")
归纳概念学习的应用实例 智能信息系统可根据用户提供的背景知识和查询实例,应用归 纳学习方法,建立用户分类模型。 假设每个用户实例包括用户名、职业、学历、使用的专业概 念、交互方式、系统经验等属性,在收集实例时,应识别重要的 属性,减少次要的属性个数,删除无用条件,并给每个属性赋予 重要程度值。如此处理,不仅提高了学习的经济性(减少了存储 空间与计算量),而且可避免学习处理的错误导向。对于获取用 户分类模型的任务来说,用户的专业概念和系统经验是最重要的 属性,其描述了用户的领域知识水平和应用系统的技能。对每个 实例的属性赋予重要程度值后,应用归纳学习方法,可以判别哪 些用户是专家,哪些用户是无经验的新手,以建立用户分类模型, 并在查询过程中,逐步精炼,直到满足所期望的要求为止。
 表示概念cl和c 2相似 sim(cl,c 3) 表示概念cl和c 3相似 和相似传递规则 if")
应用归纳概念学习获取新知识: 应用归纳学习方法,还可以根据概念之间的相似和相邻关系 推导出新的概念和新的关系。 例如,已知事实 sim(cl,c 2) 表示概念cl和c 2相似 sim(cl,c 3) 表示概念cl和c 3相似 和相似传递规则 if sim(X,Y)and sim(X,Z) then sim(Y,Z); 可以归纳推导出概念cl和c 3之间的相似关系。
演绎概念学习也称基于模型的学习。演绎概念学习应用抽象 的概念和领域模型等理论指导学习。模型(如框架、模式等)常 常描述问题领域的深层知识结构。它可被用于同化新知识,使学 习机制建立关于对象或未来事件的期望值。当有实例违背模型的 期望值,则学习机制将查找一个解释,从而扩展新知识。利用模 型可以执行定性模拟,自动产生任何可能概念或行为的实例,然 后应用这些实例进行归纳学习,产生可用的新概念或决策规则。 已知:抽象的概念描述;概念的实例;领域理论和操作标准; 确定:一个包含该实例的可用概念描述。 其中,实例可从领域理论中演绎出来,而归纳概念学习中的 实例不能从背景知识演绎出来。")
(二)演绎概念学习也称基于模型的学习。演绎概念学习应用抽象 的概念和领域模型等理论指导学习。模型(如框架、模式等)常 常描述问题领域的深层知识结构。它可被用于同化新知识,使学 习机制建立关于对象或未来事件的期望值。当有实例违背模型的 期望值,则学习机制将查找一个解释,从而扩展新知识。利用模 型可以执行定性模拟,自动产生任何可能概念或行为的实例,然 后应用这些实例进行归纳学习,产生可用的新概念或决策规则。 已知:抽象的概念描述;概念的实例;领域理论和操作标准; 确定:一个包含该实例的可用概念描述。 其中,实例可从领域理论中演绎出来,而归纳概念学习中的 实例不能从背景知识演绎出来。

两种概念学习方法的区别 这两种概念学习方法对应着概括和分析方法。两者都涉 及查找,但存在以下不同点: Ø归纳方法应用较一般的描述,而演绎方法应用推理语言表 达概念; Ø归纳方法用较复杂的顺序控制查找,而演绎达到目标则终 止; Ø归纳的结果是学习到的新概念,演绎结果是查找路径本身。
的概念 最初是由Illinois大学的De. Jong和Mooney于1986年提出 的,随后又经Mitchell、Van Harmelen和Bundy等人的 逐步完善,最终成为机器学习中的一个独立分支。解 释学习本质上是一种演绎学习,它通过对现有例子求 解过程的解释,得出一般性控制知识,用于以后类似 问题的求解。")
6. 2. 5 基于解释的学习 解释学习(Explanation-Based Learning)的概念 最初是由Illinois大学的De. Jong和Mooney于1986年提出 的,随后又经Mitchell、Van Harmelen和Bundy等人的 逐步完善,最终成为机器学习中的一个独立分支。解 释学习本质上是一种演绎学习,它通过对现有例子求 解过程的解释,得出一般性控制知识,用于以后类似 问题的求解。
学习算法描述 解释学习是由四个前件和一个后件构成。四个前件是: (1)领域理论(Domain theory):用一些规则和事实来描述 某一领域的知识,在算法中,这些规则和事实必须用符号抽象出 来。 (2)目标概念(Target concept):是对要学习概念的描述。 (3)操作性标准(Operationality criterion):用于衡量学习 系统对目标概念的描述是否准确,对学习过程起控制作用。 (4)训练例子(Training example):能用领域理论明确解释, 并充分说明目标概念的实例,它是解释学习的对象。")
(一)学习算法描述 解释学习是由四个前件和一个后件构成。四个前件是: (1)领域理论(Domain theory):用一些规则和事实来描述 某一领域的知识,在算法中,这些规则和事实必须用符号抽象出 来。 (2)目标概念(Target concept):是对要学习概念的描述。 (3)操作性标准(Operationality criterion):用于衡量学习 系统对目标概念的描述是否准确,对学习过程起控制作用。 (4)训练例子(Training example):能用领域理论明确解释, 并充分说明目标概念的实例,它是解释学习的对象。 解释学习的后件是:一个满足操作标准的关于目标概念的充 分概念描述。
 训练例子(是一些描述物体obj 1与obj 2的事实): On(obj 1,obj 2) 物体obj 1可以放在物体obj 2上面")
解释学习算法的实例说明 假如,要得出关于“一个物体x可以安全地放置在另一个 物体y的上面”的一般性控制知识,可以通过以下操作实现。 首先,用符号表示出解释学习的前件: 目标概念:Safe-to-stack(x,y) 训练例子(是一些描述物体obj 1与obj 2的事实): On(obj 1,obj 2) 物体obj 1可以放在物体obj 2上面 Is-a(obj 1,book) 物体obj 1是一本书 Is-a(obj 2,table) 物体obj 2是一张桌子 Volume(obj 1,1) 物体obj 1的数量为 1 Density(obj 1,0. 1) 物体obj 1的密度为 0. 1
→Safe-to-stack(x,y) 若y不是易碎物品,则x可以放在y上 Lighter(x,y)→Safe-to-stack(x,y) 若x比y轻,则x可以放在y上 Volume(p,v)^Density(p,d)^Product(v,d,w)→Weight(p,w) 给定物体p的重量参数 Is-a(p,table)→Weight(p,5) 桌子的重量参数为 5 Weight(p 1,w 1)^Weight(p 2,w")
领域理论: ┐Fragile(y)→Safe-to-stack(x,y) 若y不是易碎物品,则x可以放在y上 Lighter(x,y)→Safe-to-stack(x,y) 若x比y轻,则x可以放在y上 Volume(p,v)^Density(p,d)^Product(v,d,w)→Weight(p,w) 给定物体p的重量参数 Is-a(p,table)→Weight(p,5) 桌子的重量参数为 5 Weight(p 1,w 1)^Weight(p 2,w 2)^Smaller(w 1,w 2)→Lighter(p 1,p 2) 判别物体p 1和p 2轻重的准则 接着从目标概念出发,运用领域理论进行逆向推理,便可得到一个 实例求解的解释树,如下图所示。
的解释树 在得出训练例子的解释树之后,将解释树的所有叶子结点的合取作为前 件,根结点作为后件,便得到关于判断一个物体是否能放置到桌子上的一般 性控制知识: Volume (obj 1,1)^Density (obj 1,0. 1)^Product (1,0.")
Safe -to-stack(obj 1,obj 2)的解释树 在得出训练例子的解释树之后,将解释树的所有叶子结点的合取作为前 件,根结点作为后件,便得到关于判断一个物体是否能放置到桌子上的一般 性控制知识: Volume (obj 1,1)^Density (obj 1,0. 1)^Product (1,0. 1)^Is-a (obj 2, table)^Smaller (0. 1,5)→Safe-to-stack (obj 1,obj 2)
解释学习模型 在逻辑上,解释学习的求解是由四个前件经过推理得到 一个后件,由此我们可以得出解释学习的模型。下图比较简 洁地表达了解释学习的基本原理。事实上,解释学习的四个 前件在学习中并非处于同一层次,它们控制着学习过程的不 同环节。图中箭头的指向表示学习的流程:先由学习系统接 受一个不可操作的描述概念D 1(不能有效地用于识别相应概 念的例子),然后根据知识库中的领域理论对D 1进行不同描 述的转换,并由执行系统(包含操作性标准)对每个转换结 果进行测试,直到转换结果被执行系统所接受,才输出可操 作的概念描述D 2。")
(二)解释学习模型 在逻辑上,解释学习的求解是由四个前件经过推理得到 一个后件,由此我们可以得出解释学习的模型。下图比较简 洁地表达了解释学习的基本原理。事实上,解释学习的四个 前件在学习中并非处于同一层次,它们控制着学习过程的不 同环节。图中箭头的指向表示学习的流程:先由学习系统接 受一个不可操作的描述概念D 1(不能有效地用于识别相应概 念的例子),然后根据知识库中的领域理论对D 1进行不同描 述的转换,并由执行系统(包含操作性标准)对每个转换结 果进行测试,直到转换结果被执行系统所接受,才输出可操 作的概念描述D 2。

解释学习的模拟模型 虽然解释学习属于保真推理,但受领域知识完善程度的影响,并非总能 产生正确的解释描述。比如,解释学习的特点非常适合个性化信息检索,但 在引入解释学习之前,首先必须完善个性化信息检索的领域知识,用逻辑符 号抽象出个性化信息模型。
或源域;一个是当前尚未完全认识的领域, 可称为靶(Target)或目标域。一般来说,类比学习就是用类 比来比较源域和目标域,以发现目标域中的新属性、新结构、 新关系。")
6. 2. 6 基于类比的学习 所谓类比学习就是在几个对象之间检测相似性,根据一方 对象所具有的事实和知识推论出相识对象所具有的事实和知识。 类比是一种很有用的和有效的推理方法,借助这种相似性推理, 人们可以领会或表达出某些概念的内涵。 类比推理是在两个领域中进行的,一个是已认识的领域, 可称为基(Base)或源域;一个是当前尚未完全认识的领域, 可称为靶(Target)或目标域。一般来说,类比学习就是用类 比来比较源域和目标域,以发现目标域中的新属性、新结构、 新关系。
类比学习的用途 类比学习是人类认识事物的一个重要手段,它主要有两方面的用途: (1)通过类比学习,获得新的概念或新的技巧 利用类比学习方法学习新概念或新技巧时,它要把类似这些新概念 或新技巧的已知知识转换为适于新情况的形式。其学习的步骤是:首先 从记忆中(知识库中)找到类似的概念或技巧,然后把它们转换为新形 式以便用于新情况。例如人类的一种学习方式是先由老师教学生解例题, 再给学生留习题。学生寻找在例题和习题间的对应关系,利用解决例题 的知识去解决习题中的问题。学生经过一般化归纳,就可推出一些解题 原理,以便以后使用。 (2)通过类比来学习解决问题的方法 日常生活中这样的例子很多,例如,通过与鸟类飞行类比,人们发 明了飞机;通过与鱼类潜水类比,人们发明了潜艇。这种类比就是要机 器像人一样,从分析已有的解题方法中找到解决新的、类似问题的方法。")
(一)类比学习的用途 类比学习是人类认识事物的一个重要手段,它主要有两方面的用途: (1)通过类比学习,获得新的概念或新的技巧 利用类比学习方法学习新概念或新技巧时,它要把类似这些新概念 或新技巧的已知知识转换为适于新情况的形式。其学习的步骤是:首先 从记忆中(知识库中)找到类似的概念或技巧,然后把它们转换为新形 式以便用于新情况。例如人类的一种学习方式是先由老师教学生解例题, 再给学生留习题。学生寻找在例题和习题间的对应关系,利用解决例题 的知识去解决习题中的问题。学生经过一般化归纳,就可推出一些解题 原理,以便以后使用。 (2)通过类比来学习解决问题的方法 日常生活中这样的例子很多,例如,通过与鸟类飞行类比,人们发 明了飞机;通过与鱼类潜水类比,人们发明了潜艇。这种类比就是要机 器像人一样,从分析已有的解题方法中找到解决新的、类似问题的方法。
类比学习的类型 从不同的角度,根据不同的论域以及不同的相似“型”,可将类比学习 归结为如下4种类型:属性类比、射类比、结构类比、扩展类比。 (1)属性类比 对象是由一组属性所限定的。如果对象t的—组属性P(t)和对象b的— 组属性P’(b)相似,则称对象t与对象b类似。由此可见,属性类比学习推论 出来的结果并不是保真的。但是,属性类比类比学习增加了新的知识。 (2)射类比 射是借用范畴论的术语,它表示对象与对象之间的对应关系。设基 对象是一个二元组(Bi, BF),其中Bi为初态,BF为终态,从Bi到BF有一 个射α。靶对象也是一个二元组(Ti, TF)。若已知(Ti, TF)和(Bi,")
(二)类比学习的类型 从不同的角度,根据不同的论域以及不同的相似“型”,可将类比学习 归结为如下4种类型:属性类比、射类比、结构类比、扩展类比。 (1)属性类比 对象是由一组属性所限定的。如果对象t的—组属性P(t)和对象b的— 组属性P’(b)相似,则称对象t与对象b类似。由此可见,属性类比学习推论 出来的结果并不是保真的。但是,属性类比类比学习增加了新的知识。 (2)射类比 射是借用范畴论的术语,它表示对象与对象之间的对应关系。设基 对象是一个二元组(Bi, BF),其中Bi为初态,BF为终态,从Bi到BF有一 个射α。靶对象也是一个二元组(Ti, TF)。若已知(Ti, TF)和(Bi, BF) 相似,要求从Ti到TF的射β,则称为射类比。射类比可用于定理证明、问 题求解及故障诊断等方面。
结构类比 一个对象A可由若干子对象a 1,a 2,…,an及这些子对象 间的一些关系R组成,可用二元组刻画其结构:A=({a 1,a 2, …,an},R)。若已知基对象B的结构为({b 1,b 2,…,bn}, Rb)和靶对象T的部分结构({t 1,t 2,…,tm},Rt-),要求 对象T中的另一些关系,则称为结构类比,即找出对象集{b")
(3)结构类比 一个对象A可由若干子对象a 1,a 2,…,an及这些子对象 间的一些关系R组成,可用二元组刻画其结构:A=({a 1,a 2, …,an},R)。若已知基对象B的结构为({b 1,b 2,…,bn}, Rb)和靶对象T的部分结构({t 1,t 2,…,tm},Rt-),要求 对象T中的另一些关系,则称为结构类比,即找出对象集{b 1, b 2,…,bn}和{t 1,t 2,…,tm}上的对应,并将Rb中的某些关 系映射到中,成为Rt’。 (4)扩展类比是由一些元素之间的相似扩展为系统间的相似。
类比学习的过程 假若关于对象的知识表达为框架集,那么,属性类比学 习过程可描述为将一个框架(源框架)的槽值传送到另一框 架(目标框架)的槽,其过程可分为两个步骤: (1)利用源框架产生若干候选槽作为推荐槽,并将这些槽 的值传送到目标框架中。 (2)利用目标框架中已有的信息来筛选由第一步推荐的相 似性。")
(三)类比学习的过程 假若关于对象的知识表达为框架集,那么,属性类比学 习过程可描述为将一个框架(源框架)的槽值传送到另一框 架(目标框架)的槽,其过程可分为两个步骤: (1)利用源框架产生若干候选槽作为推荐槽,并将这些槽 的值传送到目标框架中。 (2)利用目标框架中已有的信息来筛选由第一步推荐的相 似性。
则是系统应执 行的长期的、动态的学习任务。文献的重描述对系统执行效率 影响较大,这里侧重讨论文献重描述的学习方法。 遗传算法GA(Genetic Algorithm)在机器学习研究中越来 越受欢迎。在检索咨询的反馈过程中,可根据用户对检索结果 文献的相关评价,利用GA算法概括出较好的文献描述。用户 下次再查找这些文献,就比较容易,且效率较高。其他用户的")
6. 2. 7 基于遗传算法的文献描述学习 在信息检索系统中,可利用用户提供的相关反馈信息来修 改相关文献的描述和提问,改进检索效率。修改提问是检索过 程中的短期学习,而文献描述的修改(重描述)则是系统应执 行的长期的、动态的学习任务。文献的重描述对系统执行效率 影响较大,这里侧重讨论文献重描述的学习方法。 遗传算法GA(Genetic Algorithm)在机器学习研究中越来 越受欢迎。在检索咨询的反馈过程中,可根据用户对检索结果 文献的相关评价,利用GA算法概括出较好的文献描述。用户 下次再查找这些文献,就比较容易,且效率较高。其他用户的 同类提问也可获得较好的检索效率。
遗传算法概述 GA算法的原理是模仿遗传,求得最多的合适元素。在遗传中,最佳 成员的基因(对象的特征)从上一代遗传给下一代。GA算法不仅选择好 的基因,还选择好的基因组合,引入新的变化,使得后代比父辈更好。 GA算法操作于对象集合,每次操作执行相似的任务。算法用另一个新对 象集合代换旧集合,反复进行这种操作,产生理想的对象集合。 GA算法的步骤如下: 首先随机产生对象集合,然后对于该集合重复执行以下操作,直到满 足给定标准: (1)测量固定集合中对象的执行值; (2)代换对象集合:①从当前对象集合中选择具有较高执行值的对象, 取它们的特征构造新对象集合,每个新对象与所有旧对象不同;②丢弃 旧对象集合。")
(一)遗传算法概述 GA算法的原理是模仿遗传,求得最多的合适元素。在遗传中,最佳 成员的基因(对象的特征)从上一代遗传给下一代。GA算法不仅选择好 的基因,还选择好的基因组合,引入新的变化,使得后代比父辈更好。 GA算法操作于对象集合,每次操作执行相似的任务。算法用另一个新对 象集合代换旧集合,反复进行这种操作,产生理想的对象集合。 GA算法的步骤如下: 首先随机产生对象集合,然后对于该集合重复执行以下操作,直到满 足给定标准: (1)测量固定集合中对象的执行值; (2)代换对象集合:①从当前对象集合中选择具有较高执行值的对象, 取它们的特征构造新对象集合,每个新对象与所有旧对象不同;②丢弃 旧对象集合。
文献描述的学习过程 假设给定M个与文献相关的提问,构成相关提问集合Q。 依据GA算法,系统重复执行以下操作: (1)测量对象的执行值 对象是指文献描述,对象执行的评估方法是,计算文献 描述与提问的相关程度。 (2)对象集合的代换 重产生和交换步骤。")
(二)文献描述的学习过程 假设给定M个与文献相关的提问,构成相关提问集合Q。 依据GA算法,系统重复执行以下操作: (1)测量对象的执行值 对象是指文献描述,对象执行的评估方法是,计算文献 描述与提问的相关程度。 (2)对象集合的代换 重产生和交换步骤。

一些实验证明,使用GA算法,可从已存文献描述中分离 出有用的信息,来形成更适于检索的新描述,这种描述具有 以下特点:使提问与其相关的文献有较高的匹配概率;使提 问与不相关的文献有较低的匹配概率,从而提高检索效率。 GA算法产生的文献描述,还提供了最好的词汇组合形式, 用户感兴趣的词或其组合形式,可加入主题词表,作为主题 词或检索入口词。 事实证明,GA算法是改进文献描述的有效 具。信息系 统可利用这种方法,根据相关反馈信息,不断学习文献的新 描述,改进系统执行性能。
(以下 简称神经网络)是对人类大脑系统的感知和思维功能的一种微 观模拟,它由一系列的神经元及其相应的联接构成,具有良好 的数学描述,并可以用计算机程序来模拟实现。人 神经网络 的研究涉及数学、计算机、思维科学、神经生理学、心理学、 模式识别、非线性动力学等众多学科,是一个正在迅速发展中")
6. 2. 8 基于神经网络的学习 人 神经网络(Artificial Neural Network,ANN)(以下 简称神经网络)是对人类大脑系统的感知和思维功能的一种微 观模拟,它由一系列的神经元及其相应的联接构成,具有良好 的数学描述,并可以用计算机程序来模拟实现。人 神经网络 的研究涉及数学、计算机、思维科学、神经生理学、心理学、 模式识别、非线性动力学等众多学科,是一个正在迅速发展中 的交叉性学科。人 神经网络具有类似人脑的信息处理方式, 是一种高度复杂的、非线性的、并行的信息系统,能被用于从 不确定、不完整、存在矛盾及假相的复杂环境中获取知识。
神经网络概述 神经网络是基于“连接主义 ”(Connectionism)理论而形成的。连接 主义是人 智能研究的主要途径之一。它不采用包含具体含义和蕴涵着 推理能力的显示符号表示方式模拟人类智能,而是试图通过神经元间的 并行协作来实现对人类智能的模拟,其主要特征是: (1)通过神经元之间的并行协同作用实现信息处理,处理过程具有 并行性、动态性、全局性。 (2)知识与信息储存于神经元的联系之中,因而可以实现联想功能, 对于带噪声、缺损、变形的信息能进行有效处理,取得比较满意的结果。 (3)它不通过编程而是通过学习直接改变神经元参数来获取特定问 题的知识。 (4)适合于模拟人类的形象思维过程。")
(一)神经网络概述 神经网络是基于“连接主义 ”(Connectionism)理论而形成的。连接 主义是人 智能研究的主要途径之一。它不采用包含具体含义和蕴涵着 推理能力的显示符号表示方式模拟人类智能,而是试图通过神经元间的 并行协作来实现对人类智能的模拟,其主要特征是: (1)通过神经元之间的并行协同作用实现信息处理,处理过程具有 并行性、动态性、全局性。 (2)知识与信息储存于神经元的联系之中,因而可以实现联想功能, 对于带噪声、缺损、变形的信息能进行有效处理,取得比较满意的结果。 (3)它不通过编程而是通过学习直接改变神经元参数来获取特定问 题的知识。 (4)适合于模拟人类的形象思维过程。
神经网络的结构 神经网络作为反映人脑某些特性的—种计算结构,需要采取一定的 连接方式将神经元节点相连。 (1)基本处理单元——神经元 ①输入和输出。处理单元有许多输入信息,这些信息同时输入神经 元,但是这些信息经神经元函数响应处理后,仅输出一个输出信息。如 图所示。")
(二)神经网络的结构 神经网络作为反映人脑某些特性的—种计算结构,需要采取一定的 连接方式将神经元节点相连。 (1)基本处理单元——神经元 ①输入和输出。处理单元有许多输入信息,这些信息同时输入神经 元,但是这些信息经神经元函数响应处理后,仅输出一个输出信息。如 图所示。

②加权系数。处理单元的每—个输入都有一个相对加权,用 于影响该输入的作用效果。在网络中,权值是可自适应调整 的系数,可被看成连接强度的一种测度。处理单元的初始权 值可以根据网络自身的规则进行改进修正、以响应不同的输 入。如图所示。
主要连接形式 基本处理单元中的函数只能实现简单的信息处理,单个 处理单元的信息处理能力并不强,只有把许多的神经元连接 起来,构成一个网络系统,才能完成复杂的信息处理任务, 呈现“智能”的特性。神经网络系统是一个高度互联的复杂的 非线性系统,其中每个神经元的输入可以与许多其他节点相 连,但只有一个输出。而这个输出也可以同时输入给许多其 他的神经元。神经网络的连接根据连接取向(或信息流向) 主要分为前馈网络和反馈网络两种形式。其中前馈连接形式 中任何一个神经元的输出不能作为同层或前几层节点的输入。 而反馈连接形式中节点的输出可以转向作为同—层或前几层 节点的输入。其中具有闭环的反馈网络称为回归(循环)神 经网络。")
(2)主要连接形式 基本处理单元中的函数只能实现简单的信息处理,单个 处理单元的信息处理能力并不强,只有把许多的神经元连接 起来,构成一个网络系统,才能完成复杂的信息处理任务, 呈现“智能”的特性。神经网络系统是一个高度互联的复杂的 非线性系统,其中每个神经元的输入可以与许多其他节点相 连,但只有一个输出。而这个输出也可以同时输入给许多其 他的神经元。神经网络的连接根据连接取向(或信息流向) 主要分为前馈网络和反馈网络两种形式。其中前馈连接形式 中任何一个神经元的输出不能作为同层或前几层节点的输入。 而反馈连接形式中节点的输出可以转向作为同—层或前几层 节点的输入。其中具有闭环的反馈网络称为回归(循环)神 经网络。

①前馈网络 在这种连接形式的网络中,神经元分层排列,各神经元接收前一层 输入并输出到下一层;神经元自身及神经元间无反馈,这种网络可用有 向无环图表示。其中的节点可分为两类,即输入节点和计算节点。由于 输入和输出节点与外界相联系,可直接接受环境的影响,所以称为可见 层,而其他的中间层则称为隐层。如图所示。
输出到输入有反馈的反馈网络。 此时,它的输入节点既可接受输入,也起计算单元的作用。如左图所示。 b)同一层内有反馈的反馈网络。这种网络的最大特点在于在各层中允许引 入神经元间的侧向作用,以实现各层神经元的自组织。如中图所示。c)相 互连接型网络。这种网络中任意两个神经元之间都可能有连接。如右图 所示。")
②反馈网络可细分为如下3种形式:a)输出到输入有反馈的反馈网络。 此时,它的输入节点既可接受输入,也起计算单元的作用。如左图所示。 b)同一层内有反馈的反馈网络。这种网络的最大特点在于在各层中允许引 入神经元间的侧向作用,以实现各层神经元的自组织。如中图所示。c)相 互连接型网络。这种网络中任意两个神经元之间都可能有连接。如右图 所示。
神经网络的学习 目前,神经网络的学习功能和联想记忆为机器学习提供了—条新的途径。 可学习性是神经网络的—个主要特征,神经网络通过对输入数据的学习、训 练来实现知识获取。 (1)基本学习机制 神经网络由许多简单的处理单元连接而成。对于一个给定处理单元,其 激活函数是固定的,它一般取决于网络设计,不能在运行过程中进行调节改 变。但是其中的权值是可变的,它们能进行动态调节以产生给定的输出。这 一可变权值的动态调节过程正是神经网络学习的本质。在单个处理单元层次, 这—调节是比较简单的,但是当大量单元集体进行调节时,就呈现类似“智 能”的特性,其中有意义的信息就存在于调节了的权值上。此外,近年来发 展起来的计算神经网络在调节权值的同时,还可根据环境自律地改变其系统 结构,使系统结构成为与环境相匹配的优化结构,实现计算智能目的。")
(三)神经网络的学习 目前,神经网络的学习功能和联想记忆为机器学习提供了—条新的途径。 可学习性是神经网络的—个主要特征,神经网络通过对输入数据的学习、训 练来实现知识获取。 (1)基本学习机制 神经网络由许多简单的处理单元连接而成。对于一个给定处理单元,其 激活函数是固定的,它一般取决于网络设计,不能在运行过程中进行调节改 变。但是其中的权值是可变的,它们能进行动态调节以产生给定的输出。这 一可变权值的动态调节过程正是神经网络学习的本质。在单个处理单元层次, 这—调节是比较简单的,但是当大量单元集体进行调节时,就呈现类似“智 能”的特性,其中有意义的信息就存在于调节了的权值上。此外,近年来发 展起来的计算神经网络在调节权值的同时,还可根据环境自律地改变其系统 结构,使系统结构成为与环境相匹配的优化结构,实现计算智能目的。
学习的模式 神经网络的学习方法很多,但总体上可划分为以下两种模式:有师学习 和无师学习。 ①有师学习。该模式中,需要有一个“教师”,这个“教师”既可以是一组 训练集,也可以是个观察者。学习原理如下:将实际输出与期望输出进行比 较,然后根据这一比较结果调节网络的权值,使得在下一个迭代循环中产生 一个更好的匹配。学习过程的目的是通过权值的连续调节,最终使得期望输 出与当前输出间的误差最小。对于有师学习,网络在能执行 作前必须进行“ 训练”。当网络对于给定的输入数据序列能产生所需要的输出时,就认为网络 的训练已经完成。有师学习是通过“加强”进行学习的,是一种强迫学习。 ②无师学习。有时也称它为无监督学习。该学习模式中,网络权值调节 没有受外来的“教师”影响。相反地,在其内部对性能实行监控,网络在输入 信息中寻找规律或趋势,并根据网络的功能进行自适应调节。尽管它没有外")
(2)学习的模式 神经网络的学习方法很多,但总体上可划分为以下两种模式:有师学习 和无师学习。 ①有师学习。该模式中,需要有一个“教师”,这个“教师”既可以是一组 训练集,也可以是个观察者。学习原理如下:将实际输出与期望输出进行比 较,然后根据这一比较结果调节网络的权值,使得在下一个迭代循环中产生 一个更好的匹配。学习过程的目的是通过权值的连续调节,最终使得期望输 出与当前输出间的误差最小。对于有师学习,网络在能执行 作前必须进行“ 训练”。当网络对于给定的输入数据序列能产生所需要的输出时,就认为网络 的训练已经完成。有师学习是通过“加强”进行学习的,是一种强迫学习。 ②无师学习。有时也称它为无监督学习。该学习模式中,网络权值调节 没有受外来的“教师”影响。相反地,在其内部对性能实行监控,网络在输入 信息中寻找规律或趋势,并根据网络的功能进行自适应调节。尽管它没有外 来“教师”,但是网络仍然需要有一些内部准则以进行系统的自我组织。无师 学习强调处理单元群集间的协调。如果外界输入激活处理单元群中的某一节 点,那么整个处理单元群的活性也就随之增加。
神经网络知识获取实例 神经网络是一种具有学习、联想和自组织能力的智能系 统,通过训练多个神经网络并将其结果进行合成,可以显著 地提高学习系统的泛化能力。在专家系统开发中,通过引入 神经网络功能模块,可使机器进行自组织、自学习,不断地 充实、丰富知识库。神经网络作为专家系统的知识获取机构 和推理 具已在智能决策支持、图形/图像识别、语音识别、 遥感信息处理、时序分析(如股市大盘走势)等领域得到广 泛应用。下面以图书馆领域的图书剔旧 作为例,介绍基于 神经网络的知识获取实现过程。")
(四)神经网络知识获取实例 神经网络是一种具有学习、联想和自组织能力的智能系 统,通过训练多个神经网络并将其结果进行合成,可以显著 地提高学习系统的泛化能力。在专家系统开发中,通过引入 神经网络功能模块,可使机器进行自组织、自学习,不断地 充实、丰富知识库。神经网络作为专家系统的知识获取机构 和推理 具已在智能决策支持、图形/图像识别、语音识别、 遥感信息处理、时序分析(如股市大盘走势)等领域得到广 泛应用。下面以图书馆领域的图书剔旧 作为例,介绍基于 神经网络的知识获取实现过程。
基于神经网络集成的图书剔旧专家系统简介 图书剔旧 作需要使用高效、科学的自动处理 具实现。由于专家系统具 有适应性强、可靠性高、成本低、响应快等优点,并具有持久性、复合性和解 释说明性等特性,十分切合图书剔旧 作的需要。但是,由于传统专家系统中 的知识是由知识 程师从专家处获取,而知识 程师很难从专家处获取剔旧所 需要的全部知识,而且专家系统还存在诸如知识面窄、学习能力差、处理复杂 问题的能力和效率较差等缺陷,因此单纯采用专家系统技术设计的图书剔旧系 统仍不能很好地满足图书剔旧 作的需要。而神经网络具有通过样本训练获取")
(1)基于神经网络集成的图书剔旧专家系统简介 图书剔旧 作需要使用高效、科学的自动处理 具实现。由于专家系统具 有适应性强、可靠性高、成本低、响应快等优点,并具有持久性、复合性和解 释说明性等特性,十分切合图书剔旧 作的需要。但是,由于传统专家系统中 的知识是由知识 程师从专家处获取,而知识 程师很难从专家处获取剔旧所 需要的全部知识,而且专家系统还存在诸如知识面窄、学习能力差、处理复杂 问题的能力和效率较差等缺陷,因此单纯采用专家系统技术设计的图书剔旧系 统仍不能很好地满足图书剔旧 作的需要。而神经网络具有通过样本训练获取 知识的学习能力,一旦网络训练成功,即可在较短执行时间内给出结果。神经 网络集成通过训练多个神经网络并将其结果进行合成,可显著提高神经网络系 统的泛化能力,但它不具备对自身行为解释的能力,对用户来说是一个“黑匣 子”。既然基于符号逻辑的专家系统擅长于推理解释 作,基于示例学习的神 经网络集成更适用于完成信息感知的功能,两者在功能上互补,可以考虑将神 经网络集成和专家系统结合起来,实现知识的自动获取和推理问题。
系统模型及其 作原理 系统模型如下图所示,主要组成部分: ①基本部件:人机接口、知识库管理系统、推理机、 数据库、解释机; ②核心部件:神经网络集成。")
(2)系统模型及其 作原理 系统模型如下图所示,主要组成部分: ①基本部件:人机接口、知识库管理系统、推理机、 数据库、解释机; ②核心部件:神经网络集成。
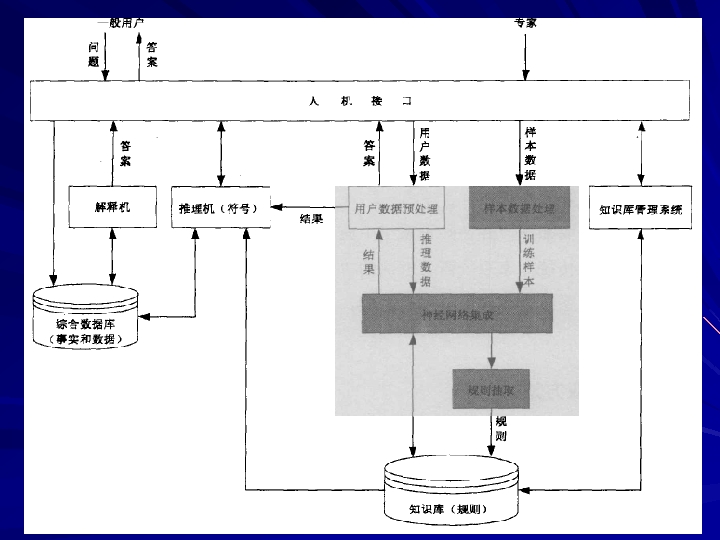

系统 作原理如下: 在构建了完整的知识库的基础上,系统就可以进行 作: 一般的用户通过人机接口输入需要系统解决的图书剔旧问题, 系统根据用户的请求,调用神经网络集成进行计算推理,并 将推理结果处理后反馈给用户。若用户对神经网络集成推理 有疑问,系统通过传统的专家系统进行逻辑推理:首先将神 经网络集成的推理结果传送给逻辑推理机,并通过人机接口 将用于神经网络推理的事实数据传送到综合数据库,然后系 统逻辑推理机从知识库中调用知识与用户输入数据进行匹配 运算,并将推理的中间结果存放在综合数据库中。在推理过 程中,系统可以通过人机界面向用户索取更多的事实数据。 最终,系统解释机整理综合数据库中的推理链,并通过人机 接口向用户提供对系统推理过程的解释。

系统中知识获取的原理是: 用户向神经网络集成模块输入训练样本;系统对输入样本 进行预处理,并用处理好的数据训练神经网络集成;在训练 结束后系统保存神经网络集成模块中的权值以及结构信息; 接着,系统通过一定的规则抽取算法对已训练好的神经网络 集成进行规则抽取,并将抽取到的规则以一定的形式保存到 系统的规则知识库中。
知识获取步骤 基于神经网络集成的知识自动获取,不需要由知识 程师整理、总结、 消化领域专家知识,只需要用领域专家解决问题的实例训练神经网络集成。 具体步骤如下: ①设置初始的神经网络集成的结构; ②用负相关学习算法训练神经网络集成,动态地调整神经网络集成中成 员神经网络的结构; ③判别误差是否满足要求,如满足要求,则学习结束,保存权值等数值 知识。否则返回②继续训练; ④集成训练达到误差要求后,用集成生成一个示例集S,利用基于结构的 规则抽取算法或者基于功能的规则抽取算法等将神经网络所隐含的隐性知 识进行显示化表示; ⑤将抽取出来的规则存放到知识库中。")
(3)知识获取步骤 基于神经网络集成的知识自动获取,不需要由知识 程师整理、总结、 消化领域专家知识,只需要用领域专家解决问题的实例训练神经网络集成。 具体步骤如下: ①设置初始的神经网络集成的结构; ②用负相关学习算法训练神经网络集成,动态地调整神经网络集成中成 员神经网络的结构; ③判别误差是否满足要求,如满足要求,则学习结束,保存权值等数值 知识。否则返回②继续训练; ④集成训练达到误差要求后,用集成生成一个示例集S,利用基于结构的 规则抽取算法或者基于功能的规则抽取算法等将神经网络所隐含的隐性知 识进行显示化表示; ⑤将抽取出来的规则存放到知识库中。

6. 3 数据挖掘与知识发现 丰富的网络信息资源一方面给知识获取提供了广 阔的信息源;另一方面,海量的信息使得人们无法 辨别隐藏在其中的有用知识。数据挖掘技术是一种 自动的数据分析技术,能处理大量数据,能挖掘深 层有价值的潜在知识。
是一门交叉性新兴学科,涉及到数 据库、人 智能、数理统计、可视化、并行计算等领域,通过综合运用统计 学、机器学习和专家系统等多种学习手段和方法,从大量数据中提炼出抽象 的知识,揭示出蕴涵在这些数据背后的客观世界的内在联系和本质规律,实 现知识的自动获取。 知识发现(Knowledge Discovery in")
6. 3. 1 概述 数据挖掘(Data Mining,DM)是一门交叉性新兴学科,涉及到数 据库、人 智能、数理统计、可视化、并行计算等领域,通过综合运用统计 学、机器学习和专家系统等多种学习手段和方法,从大量数据中提炼出抽象 的知识,揭示出蕴涵在这些数据背后的客观世界的内在联系和本质规律,实 现知识的自动获取。 知识发现(Knowledge Discovery in Databases,KDD)是和数 据挖掘相关的另一个常用术语。“知识发现”是从大量数据中提取出可信的、 新颖的、有用的且可以被人理解的模式的高级处理过程。严格的说,KDD是 从数据中发现有用知识的整个过程,而数据挖掘特指KDD整个过程中的一个 特定步骤,是KDD中最核心的部分。但在 程领域,“数据挖掘”被视为 “KDD”的同义词。这主要是由于“知识发现”是一门受到来自各种不同领域的 研究者关注的交叉性学科,因此导致很多不同的相关术语名词,如“知识抽取 ”、“信息发现”、“智能数据分析” 等。其中,最常用的术语是“知识发现”和“ 数据挖掘”。

数据挖掘与知识发现的应用: 数据挖掘与知识发现既可对数字、符号等数据进行分析, 也可对图形、图像、声音等多媒体信息进行挖掘利用;其知识 发现过程既可在结构化、半结构化数据源中进行,也可以在文 本等非结构化数据源中开展;知识发现的结果可以表示成各种 形式,如规则、法则、科学规律、方程或概念网等。 目前,市场营销、银行业、生产销售、零售业、制造业、经 济业、保险业、医药业、电信业、公司经营管理等各个应用方 向都开始尝试将知识挖掘应用于超大型数据库。此外,数据挖 掘和知识发现系统的另一个重要的应用领域是作为专家系统、 决策支持系统等知识库系统的知识获取 具。

知识发现应用于知识获取中的好处: 数据挖掘与知识发现理论与技术在知识获取中的应用, 一方面可以在知识获取中引入数据预处理模块,以免大量噪 声数据影响知识获取的正确性;另一方面,数据挖掘研究的 成果,大大加深和拓宽了知识获取的深度与广度,有利于从 多方面、多层次、多渠道获取知识。此外,数据挖掘与统计 学的结合,可以使知识获取具备更多的统计科学性;数据挖 掘与可视化技术的结合,可增强知识的直观性和可理解性。
结构化数据为主的关系数据库、数据仓库; (2)半结构化、非结构化的复杂类型数据库; (3)图像、声音等多媒体数据库; (4)互联网资源。 这些不同的挖掘对象又关联到不同的技术,形成彼此相关又 相互独立的若干领域。")
6. 3. 2 知识发现的对象 网络环境下的知识发现对象范围广泛,涵盖了众多的信息 类型和内容。 数据挖掘技术的对象: (1)结构化数据为主的关系数据库、数据仓库; (2)半结构化、非结构化的复杂类型数据库; (3)图像、声音等多媒体数据库; (4)互联网资源。 这些不同的挖掘对象又关联到不同的技术,形成彼此相关又 相互独立的若干领域。
数据库与数据仓库挖掘 这里特指针对关系数据库、事务数据库和数据仓库等这些结构化的数据 挖掘对象而言的挖掘。 (2)Web挖掘 ①Web内容挖掘。Web内容挖掘指从Web文档中发现有用的信息。Web 内容挖掘又可进一步分为基于半结构化文档的Web内容挖掘和非结构化文档 的Web内容挖掘。非结构化Web文档挖掘主要针对Web上的自由文本,如新 闻、网络小说等,从统计的角度,根据词频、词汇出现位置等方法进行考察。 半结构化Web文档挖掘则指在加入了HTML、超链接等附加结构的信息上进 行挖掘,包括超链接文本的分类、文档关系的发现、半结构化文档中的模式 和规则的提取等,主要应用于Web权威页面的发现,如许多Web搜索引擎就 利用Web内容挖掘中的Web超链接分析来提高搜索的效率和准确性。Web内 容挖掘主要利用了自动文摘、文本分类与聚类等技术。")
(1)数据库与数据仓库挖掘 这里特指针对关系数据库、事务数据库和数据仓库等这些结构化的数据 挖掘对象而言的挖掘。 (2)Web挖掘 ①Web内容挖掘。Web内容挖掘指从Web文档中发现有用的信息。Web 内容挖掘又可进一步分为基于半结构化文档的Web内容挖掘和非结构化文档 的Web内容挖掘。非结构化Web文档挖掘主要针对Web上的自由文本,如新 闻、网络小说等,从统计的角度,根据词频、词汇出现位置等方法进行考察。 半结构化Web文档挖掘则指在加入了HTML、超链接等附加结构的信息上进 行挖掘,包括超链接文本的分类、文档关系的发现、半结构化文档中的模式 和规则的提取等,主要应用于Web权威页面的发现,如许多Web搜索引擎就 利用Web内容挖掘中的Web超链接分析来提高搜索的效率和准确性。Web内 容挖掘主要利用了自动文摘、文本分类与聚类等技术。

②Web结构挖掘。Web结构挖掘的对象是Web本身的超链接,即对Web文档的 结构进行挖掘。对于给定的Web文档集合,通过算法发现它们之间连接的有用 信息。Web结构挖掘的另一个尝试是在Web数据仓库环境下的挖掘,包括在不 同的Web数据仓库中检查副本以帮助定位镜像站点;通过发现针对某一特定领 域的超链接的层次属性,探索信息流动如何影响Web站点的设计。 ③Web用法挖掘。Web用法挖掘即Web使用记录挖掘,它在新兴的电子商务领 域中有着广泛用途。它通过挖掘相关的Web日志记录来发现用户访问Web页面 的模式;通过分析日志记录中的规律,识别用户的忠实度、喜好、满意度,发 现潜在用户,增强站点的服务竞争力。Web使用记录的数据类型与数据量是非 常大的,包括服务器日志记录、浏览器端日志、注册信息、用户会话信息、交 易信息、鼠标点击率等。根据对数据源的不同处理方法,Web用法挖掘又可以 分为两类:一类是将Web使用记录数据转换到传统的关系表里,再使用传统数 据库挖掘算法对关系表中的数据进行常规挖掘;另一类是将Web使用记录数据 直接进行预处理后再进行挖掘。
文本挖掘的对象是非结构化的文本数据。文本挖掘涵盖了 多学科领域,包括数据挖掘技术、信息抽取技术、机器学习 技术、自然语言处理技术、统计数据分析技术等多种技术, 利用神经网络、基于案例的推理智能算法,抽取非结构化文 本源中的概念和关系,从中发现隐含的、散布在文本文件中 的有价值的知识。按照文本挖掘对象的不同,文本挖掘又可 分为基于单文档的数据挖掘和基于文档集的数据挖掘:基于 单文档的数据挖掘对文档的分析并不涉及其他文档,主要采 用文本摘要、信息提取技术;基于文档集的数据挖掘是对大 规模的文档数据进行模式抽取,主要采用文本分类、文本聚 类、个性化文本过滤等技术。")
(3)文本挖掘的对象是非结构化的文本数据。文本挖掘涵盖了 多学科领域,包括数据挖掘技术、信息抽取技术、机器学习 技术、自然语言处理技术、统计数据分析技术等多种技术, 利用神经网络、基于案例的推理智能算法,抽取非结构化文 本源中的概念和关系,从中发现隐含的、散布在文本文件中 的有价值的知识。按照文本挖掘对象的不同,文本挖掘又可 分为基于单文档的数据挖掘和基于文档集的数据挖掘:基于 单文档的数据挖掘对文档的分析并不涉及其他文档,主要采 用文本摘要、信息提取技术;基于文档集的数据挖掘是对大 规模的文档数据进行模式抽取,主要采用文本分类、文本聚 类、个性化文本过滤等技术。
多媒体信息挖掘的对象主要指典型的多媒体数据,如图像、视频、音频等 类型的数据。多媒体信息中蕴含着大量的信息线索和具有潜在价值的知识。针 对多媒体信息的研究过去大都集中在基于内容的信息检索方面,这在某种程度 上解决了信息搜索和信息资源发现的问题,而不能从大量多媒体数据中发现和 分析出其中蕴含的有价值的知识。为此,需要研究比多媒体信息检索更高层次 的新方法,那就是多媒体信息挖掘。 多媒体信息挖掘就是从大量多媒体数据集中,通过综合分析视听特性和语 义,发现隐含的、有效的、有价值的、可理解的模式,得出事件的趋向和关联, 为用户提供问题求解层次的决策支持能力。多媒体信息挖掘主要涉及数据挖掘 和多媒体信息处理两个研究领域。如何把数据挖掘的基本理论和方法与对多媒 体特性的分析结合起来,从多媒体的内容着手,利用多媒体的时间、空间、视 觉特性、视听对象及运动特性,挖掘出有价值的隐含的信息线索和知识,是多 媒体信息挖掘研究所面临的挑战。")
(4)多媒体信息挖掘的对象主要指典型的多媒体数据,如图像、视频、音频等 类型的数据。多媒体信息中蕴含着大量的信息线索和具有潜在价值的知识。针 对多媒体信息的研究过去大都集中在基于内容的信息检索方面,这在某种程度 上解决了信息搜索和信息资源发现的问题,而不能从大量多媒体数据中发现和 分析出其中蕴含的有价值的知识。为此,需要研究比多媒体信息检索更高层次 的新方法,那就是多媒体信息挖掘。 多媒体信息挖掘就是从大量多媒体数据集中,通过综合分析视听特性和语 义,发现隐含的、有效的、有价值的、可理解的模式,得出事件的趋向和关联, 为用户提供问题求解层次的决策支持能力。多媒体信息挖掘主要涉及数据挖掘 和多媒体信息处理两个研究领域。如何把数据挖掘的基本理论和方法与对多媒 体特性的分析结合起来,从多媒体的内容着手,利用多媒体的时间、空间、视 觉特性、视听对象及运动特性,挖掘出有价值的隐含的信息线索和知识,是多 媒体信息挖掘研究所面临的挑战。
知识库挖掘主要研究如何从现有的知识库中进一步发现更多的深层次知识。 基于知识库的知识发现是目前国内外的一个新研究领域。知识库中的知识发现 与数据库中的知识发现有所不同,主要表现在: ①发现的基础不同。知识库中的知识发现针对的对象是知识库,一个真实 的知识库一般包含事实库和规则库,它们的结构与数据库有着明显的区别。 ②采用的手段不同。知识库中不仅包含着数据,而且包含着显性的关系。 如何针对关系得出更高层次的知识,将采用与数据挖掘不同的方法。 从定性的角度分析知识库挖掘的本质的话,可以认为它是一种机器学习过 程,其目的是获取知识,学习源是知识库,学习手段是用归纳结合演绎的方法, 其最终结果将既能够发现事实上的知识,也能够发现规则上的知识。因此,在 具体实现中应该采用两条发掘线路:其一是利用归纳方法发掘事实之上的规则; 另一条线路是通过高阶推理的方法从规则库中发现规则,即属性与关系之上的 关系。")
(5)知识库挖掘主要研究如何从现有的知识库中进一步发现更多的深层次知识。 基于知识库的知识发现是目前国内外的一个新研究领域。知识库中的知识发现 与数据库中的知识发现有所不同,主要表现在: ①发现的基础不同。知识库中的知识发现针对的对象是知识库,一个真实 的知识库一般包含事实库和规则库,它们的结构与数据库有着明显的区别。 ②采用的手段不同。知识库中不仅包含着数据,而且包含着显性的关系。 如何针对关系得出更高层次的知识,将采用与数据挖掘不同的方法。 从定性的角度分析知识库挖掘的本质的话,可以认为它是一种机器学习过 程,其目的是获取知识,学习源是知识库,学习手段是用归纳结合演绎的方法, 其最终结果将既能够发现事实上的知识,也能够发现规则上的知识。因此,在 具体实现中应该采用两条发掘线路:其一是利用归纳方法发掘事实之上的规则; 另一条线路是通过高阶推理的方法从规则库中发现规则,即属性与关系之上的 关系。

6. 3. 3 知识发现的过程 数据挖掘不仅是面向特定数据库的简单检索、查询和调 用,而且要对这些数据进行微观、中观乃至宏观的统计、分 析、综合和推理,以指导实际问题的求解,并试图发现事件 之间的关联性,甚至利用已有的数据对未来的活动进行预测。 通过数据选取、预处理、变换、模式提取、知识评估以及过 程优化,运用判别分析、聚类分析、探索性分析等统计方法 来发现和获取知识。知识发现的基本过程可大致分为三个模 块:数据准备、数据挖掘以及结果的解释评估,如下图所示。

数据准备又可分为三个子步骤:数据选取、数据预处理 和数据变换。数据选取的目的是确定发现任务的操作对象, 即目标数据,它是根据用户的需要从原始数据库中抽取的一 组数据。数据预处理一般可能包括消除噪声、推导计算缺值 数据、消除重复记录、完成数据类型转换(如把连续值数据 转换为离散型数据,以便于符号归纳,或是把离散型数据转 换为连续值型数据,以便于神经网络归纳)等。当数据开采 的对象是数据仓库时,一般来说,数据预处理已经在生成数 据仓库时完成了。数据变换的主要目的是消减数据维数或降 维,即从初始特征中找出真正有用的特征以减少数据开采时 要考虑的特征或变量个数。")
(1)数据准备又可分为三个子步骤:数据选取、数据预处理 和数据变换。数据选取的目的是确定发现任务的操作对象, 即目标数据,它是根据用户的需要从原始数据库中抽取的一 组数据。数据预处理一般可能包括消除噪声、推导计算缺值 数据、消除重复记录、完成数据类型转换(如把连续值数据 转换为离散型数据,以便于符号归纳,或是把离散型数据转 换为连续值型数据,以便于神经网络归纳)等。当数据开采 的对象是数据仓库时,一般来说,数据预处理已经在生成数 据仓库时完成了。数据变换的主要目的是消减数据维数或降 维,即从初始特征中找出真正有用的特征以减少数据开采时 要考虑的特征或变量个数。
数据挖掘阶段首先要确定开采的任务或目的是什么,如 数据总结、分类、聚类、关联规则发现或序列模式发现等。 确定了开采任务后,就要决定使用什么样的开采算法。同样 的任务可以用不同的算法来实现,选择实现算法有两个考虑 因素:一是不同的数据有不同的特点,因此需要用与之相关 的算法来开采;二是用户或实际运行系统的要求,有的用户 可能希望获取描述型的、容易理解的知识,而有的用户或系 统的目的是获取预测准确度尽可能高的预测型知识。完成了 上述准备 作后,就可以实施数据挖掘操作了。")
(2)数据挖掘阶段首先要确定开采的任务或目的是什么,如 数据总结、分类、聚类、关联规则发现或序列模式发现等。 确定了开采任务后,就要决定使用什么样的开采算法。同样 的任务可以用不同的算法来实现,选择实现算法有两个考虑 因素:一是不同的数据有不同的特点,因此需要用与之相关 的算法来开采;二是用户或实际运行系统的要求,有的用户 可能希望获取描述型的、容易理解的知识,而有的用户或系 统的目的是获取预测准确度尽可能高的预测型知识。完成了 上述准备 作后,就可以实施数据挖掘操作了。
结果解释和评价 数据挖掘阶段发现出来的结果,可能存在冗余或无关的 模式,经过用户或机器的评价,需要将其剔除;也有可能模 式不满足用户要求,这时则需要整个发现过程退回到发现阶 段之前,如重新选取数据、采用新的数据变换方法、设定新 的数据挖掘参数值,甚至换一种挖掘算法(如当发现任务是 分类时,有多种分类方法,不同的方法对不同的数据有不同 的效果)。另外,由于KDD最终是面向人类用户的,因此可 能要对发现的模式进行可视化,或者把结果转换为用户易懂 的另一种表示,如把分类决策树转换为“if…then…”规则。")
(3)结果解释和评价 数据挖掘阶段发现出来的结果,可能存在冗余或无关的 模式,经过用户或机器的评价,需要将其剔除;也有可能模 式不满足用户要求,这时则需要整个发现过程退回到发现阶 段之前,如重新选取数据、采用新的数据变换方法、设定新 的数据挖掘参数值,甚至换一种挖掘算法(如当发现任务是 分类时,有多种分类方法,不同的方法对不同的数据有不同 的效果)。另外,由于KDD最终是面向人类用户的,因此可 能要对发现的模式进行可视化,或者把结果转换为用户易懂 的另一种表示,如把分类决策树转换为“if…then…”规则。

6. 3. 4 知识发现的的主要方法 知识发现方法主要由人 智能、机器学习这两个 领域中的相关方法发展而来。它将信息论方法、统计 分析方法、模糊数学方法、知识处理方法相融合,形 成了由归纳学习方法、仿生物技术方法、公式发现方 法、统计分析方法、模糊数学方法以及基于知识的挖 掘这六大类方法所构成的方法体系。
归纳学习方法依据事物的特征,执行归纳推理,产生描述一类数据对 象的普遍特征的规则。归纳学习方法是目前重点研究的方向,研究成果较多。 从所采用的技术上看,又可细分为两类:信息论方法和集合论方法,每类方 法又包含多个具体实现方法。 (1)信息论方法。信息论方法是利用信息论的原理建立决策树。由于该 方法最后获得的知识表示形式是决策树,故一般文献中称它为决策树方法。 该类方法的实用效果好,影响较大。其中较有特色的实现方法有:ID 3方法 和IBLE方法。 (2)集合论方法。集合论方法是开展研究较早的方法。近年来,由于粗 集理论的发展使集合论方法得到了迅速的发展。这类方法包括:覆盖正例排 斥反例的方法(如AQ系列方法)、概念树方法和粗集(roush set)方法。")
(一)归纳学习方法依据事物的特征,执行归纳推理,产生描述一类数据对 象的普遍特征的规则。归纳学习方法是目前重点研究的方向,研究成果较多。 从所采用的技术上看,又可细分为两类:信息论方法和集合论方法,每类方 法又包含多个具体实现方法。 (1)信息论方法。信息论方法是利用信息论的原理建立决策树。由于该 方法最后获得的知识表示形式是决策树,故一般文献中称它为决策树方法。 该类方法的实用效果好,影响较大。其中较有特色的实现方法有:ID 3方法 和IBLE方法。 (2)集合论方法。集合论方法是开展研究较早的方法。近年来,由于粗 集理论的发展使集合论方法得到了迅速的发展。这类方法包括:覆盖正例排 斥反例的方法(如AQ系列方法)、概念树方法和粗集(roush set)方法。
仿生物技术方法 仿生物技术典型的方法是神经网络方法和遗传算法。这两类方法已经形 成了独立的研究体系,在数据挖掘中也发挥了巨大的作用。 (1)神经网络方法。它模拟了人脑神经元结构,以MP模型和Hebb学习规 则为基础的,建立了前馈式网络、反馈式网络、自组织网络三大类多种神经 网络模型。其中,前馈式网络用于预测、模式识别等方面;反馈式网络用于联 想记忆和优化计算;自组织网络用于聚类。 (2)遗传算法。这是模拟生物进化过程的算法。它由三个基本算子组成: ①繁殖(选择)。从一个旧种群(父代)选择出生命力强的个体产生新种群 (后代)的过程。②交叉(重组)。选择两个不同个体(染色体)的部分( 基因)进行交换,形成新个体。③变异(突变)。对某些个体的某些基因进 行变异(1变 0,0变 1)。遗传算法已在优化计算和分类机器学习方面显示了")
(二)仿生物技术方法 仿生物技术典型的方法是神经网络方法和遗传算法。这两类方法已经形 成了独立的研究体系,在数据挖掘中也发挥了巨大的作用。 (1)神经网络方法。它模拟了人脑神经元结构,以MP模型和Hebb学习规 则为基础的,建立了前馈式网络、反馈式网络、自组织网络三大类多种神经 网络模型。其中,前馈式网络用于预测、模式识别等方面;反馈式网络用于联 想记忆和优化计算;自组织网络用于聚类。 (2)遗传算法。这是模拟生物进化过程的算法。它由三个基本算子组成: ①繁殖(选择)。从一个旧种群(父代)选择出生命力强的个体产生新种群 (后代)的过程。②交叉(重组)。选择两个不同个体(染色体)的部分( 基因)进行交换,形成新个体。③变异(突变)。对某些个体的某些基因进 行变异(1变 0,0变 1)。遗传算法已在优化计算和分类机器学习方面显示了 显著的效果。
公式发现方法 在 程和科学数据库(由实验数据组成)中对若干数据项(变量)进 行一定的数学运算,求得相应的数学公式。 (1)物理定律发现系统BACON发现系统完成了物理学中大量定律的重新发现。它的基本思 想是对数据项进行初等数学运算(加、减、乘、除等)形成组合数据项, 若它的值为常数时,我们就得到了组合数据项等于常数的公式。 (2)经验公式发现系统FDD 基本思想是若对两个数据项交替取初等函数后与另一数据项的线性组 合为直线,就找到了数据项(变量)的初等函数的线性组合公式。该系统 所发现的公式比BACON系统发现的公式更宽些。")
(三)公式发现方法 在 程和科学数据库(由实验数据组成)中对若干数据项(变量)进 行一定的数学运算,求得相应的数学公式。 (1)物理定律发现系统BACON发现系统完成了物理学中大量定律的重新发现。它的基本思 想是对数据项进行初等数学运算(加、减、乘、除等)形成组合数据项, 若它的值为常数时,我们就得到了组合数据项等于常数的公式。 (2)经验公式发现系统FDD 基本思想是若对两个数据项交替取初等函数后与另一数据项的线性组 合为直线,就找到了数据项(变量)的初等函数的线性组合公式。该系统 所发现的公式比BACON系统发现的公式更宽些。
统计分析方法 利用统计学原理对数据库中的数据进行分析,如在 程和科学数据库中对 若干数据项进行一定的数学运算,求得相应的数学公式。主要分析方法如下: ①常用统计:求大量数据中的最大值、最小值、总和、平均值等。 ②相关分析:求相关系数,度量变量间的相关程度。 ③回归分析:求回归方程(线性或非线性)来表示变量间的数量关系。 ④差异分析:从样本统计量的值得出差异,确定总体参数之间是否存在差异( 假设检验)。 ⑤聚类分析:直接比较样本中各样本之间的距离,将距离较近的归为一类,而 将距离较远的分在不同类中。 ⑥判别分析:建立一个或多个判别函数,并确定一个判别标准。对未知对象利 用判别函数将它划归某一个类别。")
(四)统计分析方法 利用统计学原理对数据库中的数据进行分析,如在 程和科学数据库中对 若干数据项进行一定的数学运算,求得相应的数学公式。主要分析方法如下: ①常用统计:求大量数据中的最大值、最小值、总和、平均值等。 ②相关分析:求相关系数,度量变量间的相关程度。 ③回归分析:求回归方程(线性或非线性)来表示变量间的数量关系。 ④差异分析:从样本统计量的值得出差异,确定总体参数之间是否存在差异( 假设检验)。 ⑤聚类分析:直接比较样本中各样本之间的距离,将距离较近的归为一类,而 将距离较远的分在不同类中。 ⑥判别分析:建立一个或多个判别函数,并确定一个判别标准。对未知对象利 用判别函数将它划归某一个类别。
模糊数学方法 利用模糊集合理论对实际问题进行模糊评判、模糊决策、 模糊模式识别和模糊聚类分析。 (六)基于知识的挖掘方法 目前,数据挖掘中开始引入了本体、知识抽取和知识组 织等知识处理技术等,实现基于知识的挖掘。 具体方法如下:")
(五)模糊数学方法 利用模糊集合理论对实际问题进行模糊评判、模糊决策、 模糊模式识别和模糊聚类分析。 (六)基于知识的挖掘方法 目前,数据挖掘中开始引入了本体、知识抽取和知识组 织等知识处理技术等,实现基于知识的挖掘。 具体方法如下:
利用领域本体知识。数据挖掘所面临的对象是海量的数 据,这些数据具有非常复杂的属性和关系,需要花费较长的 处理时间探索并发现其中的规律知识。因此,需要根据问题 需要引入相关的领域知识,用于合理选择相关属性,进行多 抽象层次、不同知识层面的语义挖掘,减少数据处理量,降 低处理复杂属性关系时的难度,提高挖掘质量。本体作为领 域知识的一种先进的表示方法,可帮助机器理解概念,消除 数据的歧义性,实现概念的规范化和泛化,辅助挖掘进程从 不同层次获取隐含的关联知识。")
(1)利用领域本体知识。数据挖掘所面临的对象是海量的数 据,这些数据具有非常复杂的属性和关系,需要花费较长的 处理时间探索并发现其中的规律知识。因此,需要根据问题 需要引入相关的领域知识,用于合理选择相关属性,进行多 抽象层次、不同知识层面的语义挖掘,减少数据处理量,降 低处理复杂属性关系时的难度,提高挖掘质量。本体作为领 域知识的一种先进的表示方法,可帮助机器理解概念,消除 数据的歧义性,实现概念的规范化和泛化,辅助挖掘进程从 不同层次获取隐含的关联知识。
利用用户知识。有效的数据挖掘过程需要让用户真正参 与到挖掘过程中,将用户兴趣知识、背景知识、需求模型融 入到系统中,通过用户与系统之间的反复交互约束、聚焦数 据挖掘进程方向,并可以保证所发现的知识的有效性和利用 价值。 (3)利用专家知识。专家知识是执行专种任务的决策规则和 技能,是专家在长期的生产实践中积累起来的财富。作为领 域知识与具体问题解决方案相结合的产物,专家知识是系统 执行各种推理、评价、判断的基础。在数据挖掘过程中,通 过采用合适的知识表示方法将专家知识建模与组织,可以指 导数据挖掘系统的运作。")
(2)利用用户知识。有效的数据挖掘过程需要让用户真正参 与到挖掘过程中,将用户兴趣知识、背景知识、需求模型融 入到系统中,通过用户与系统之间的反复交互约束、聚焦数 据挖掘进程方向,并可以保证所发现的知识的有效性和利用 价值。 (3)利用专家知识。专家知识是执行专种任务的决策规则和 技能,是专家在长期的生产实践中积累起来的财富。作为领 域知识与具体问题解决方案相结合的产物,专家知识是系统 执行各种推理、评价、判断的基础。在数据挖掘过程中,通 过采用合适的知识表示方法将专家知识建模与组织,可以指 导数据挖掘系统的运作。
特征提取。特征提取不是数据的简单枚举,而是产生数据")
6. 3. 5 知识发现的主要技术 数据挖掘可以从海量数据中寻找数据关联和隐藏要素,建立 模型并预测未来的趋势及行为,自动探测以前未发现的模式,从 而提炼出决策知识。 数据挖掘技术主要包括:特征提取、关联分析 、分类分析 、 聚类分析、时序分析 、偏差检测 、预测。 (1)特征提取。特征提取不是数据的简单枚举,而是产生数据 的特征化和比较描述。其中的特征化提供给定数据集的简洁汇总, 而概念或类的比较则提供对两个或多个数据集的比较描述。
关联分析。关联分析的目的是抽取隐藏在数据或对象间的 关联规则。关联规则是描述事物之间关系的知识模式。关联分析 可以揭示数据间未知的依赖关系,并以置信度因子衡量依赖的程 度。例如,若两个或多个数据项的取值重复出现且概率很高时, 它们就存在某种关联。例如:在超市的商品销售数据库中,我们 可以找到以下信息:在购买面包和黄油的顾客中,大部分的人同 时也买了牛奶。那么面包与牛奶之间必定存在某种关联。 关联分析近几年研究较多,已经从单一概念层次关联规则的 发现发展到多概念层次的关联规则的发现,并把研究的重点放在 提高算法的效率和规模的可收缩性上。 常用的关联分析方法:数据立方体法、面向属性归纳法。")
(2)关联分析。关联分析的目的是抽取隐藏在数据或对象间的 关联规则。关联规则是描述事物之间关系的知识模式。关联分析 可以揭示数据间未知的依赖关系,并以置信度因子衡量依赖的程 度。例如,若两个或多个数据项的取值重复出现且概率很高时, 它们就存在某种关联。例如:在超市的商品销售数据库中,我们 可以找到以下信息:在购买面包和黄油的顾客中,大部分的人同 时也买了牛奶。那么面包与牛奶之间必定存在某种关联。 关联分析近几年研究较多,已经从单一概念层次关联规则的 发现发展到多概念层次的关联规则的发现,并把研究的重点放在 提高算法的效率和规模的可收缩性上。 常用的关联分析方法:数据立方体法、面向属性归纳法。
分类分析。分类分析就是通过学习构造一个分类函数或 分类模型(也常称作分类器),形成一个类别的概念描述,即 该类的内涵描述,包括共同特征描述和辨别性描述(与其它类 的区别)。类的描述可以是显式的,如用一组特征概念描述; 也可以是隐式的,如用一个数学公式或数学模型描述 分类分析方法:机器学习、神经网络、粗糙集 (Rough set )、决策树 、统计分析法等。")
(3)分类分析。分类分析就是通过学习构造一个分类函数或 分类模型(也常称作分类器),形成一个类别的概念描述,即 该类的内涵描述,包括共同特征描述和辨别性描述(与其它类 的区别)。类的描述可以是显式的,如用一组特征概念描述; 也可以是隐式的,如用一个数学公式或数学模型描述 分类分析方法:机器学习、神经网络、粗糙集 (Rough set )、决策树 、统计分析法等。
聚类分析。聚类分析是根据事物本身潜在的特性研究对象 分类的方法。通过聚类把一个数据集中的个体(对象)按照相 似性归约成若干类别,使其“物以类聚”。聚类分析的原则是使 同一类别中的对象之间具有尽可能大的相似性,而不同类别中 的对象之间具有尽可能大的差异性。与分类分析不同的是,聚 类结果主要基于当前所处理的数据,不依赖于预先定义好的类, 事先也不知道可分割的类的个数。 聚类分析方法包括基于划分的方法、基于密度的方法、基于 层次的方法、基于网格的方法、基于模型的方法等。")
(4)聚类分析。聚类分析是根据事物本身潜在的特性研究对象 分类的方法。通过聚类把一个数据集中的个体(对象)按照相 似性归约成若干类别,使其“物以类聚”。聚类分析的原则是使 同一类别中的对象之间具有尽可能大的相似性,而不同类别中 的对象之间具有尽可能大的差异性。与分类分析不同的是,聚 类结果主要基于当前所处理的数据,不依赖于预先定义好的类, 事先也不知道可分割的类的个数。 聚类分析方法包括基于划分的方法、基于密度的方法、基于 层次的方法、基于网格的方法、基于模型的方法等。
时序分析。时序分析把数据之间的关联性与时间性联系起 来,通过时间序列搜索出重复发生且概率较高的模式。它的目 的是为了挖掘数据之间的联系。序列模式可以看成是一种特定 的关联模型,增加了时间属性。时序分析强调时间序列的影响, 非常适于寻找事物的发生趋势或重复性模式。例如,在所有购 买了激光打印机的人中,半年后80%的人再购买新硒鼓,20% 的人用旧硒鼓装碳粉。 时序模式中,一个重要的方法是“相似时序”,即按时间顺序 查看时间事件数据库,从中找出另一个或多个相似的时序事件。 例如,在零售市场上,找到另一个有相似销售的部门,在股市 中找到有相似波动的股票。")
(5)时序分析。时序分析把数据之间的关联性与时间性联系起 来,通过时间序列搜索出重复发生且概率较高的模式。它的目 的是为了挖掘数据之间的联系。序列模式可以看成是一种特定 的关联模型,增加了时间属性。时序分析强调时间序列的影响, 非常适于寻找事物的发生趋势或重复性模式。例如,在所有购 买了激光打印机的人中,半年后80%的人再购买新硒鼓,20% 的人用旧硒鼓装碳粉。 时序模式中,一个重要的方法是“相似时序”,即按时间顺序 查看时间事件数据库,从中找出另一个或多个相似的时序事件。 例如,在零售市场上,找到另一个有相似销售的部门,在股市 中找到有相似波动的股票。
偏差分析。偏差分析用来发现数据集中与正常情况不同的异常和变化, 并进一步分析这种变化的原因。当某数据对象不符合大多数数据对象所构成 的规律时就会形成孤立点,就需要进行偏差分析。以前许多数据分析方法都 将孤立点作为嗓声或意外而将其排除在分析处理的范围之外。事实上在一些 商业应用中,小概率发生事件往往比经常发生的事件更有挖掘价值,如各种 商业欺诈行为的自动检测等。因此,偏差分析有助于滤掉知识发现引擎所抽 取的无关信息,也可滤掉那些不合适的数据,还可产生新的引人关注的事实。 偏差分析的主要算法包括基于统计的、基于距离的、基于密度的、基于偏离 的分析算法等。 (7)预测。预测是指利用从历史数据集中自动推导出的对给定数据的推广 描述,预测未知的数据值或变化趋势。例如根据客户的年龄、性别和收入来 预测他的大概支出。常用的预测技术包括线性和多项式回归、神经网络和决 策树预测等。")
(6)偏差分析。偏差分析用来发现数据集中与正常情况不同的异常和变化, 并进一步分析这种变化的原因。当某数据对象不符合大多数数据对象所构成 的规律时就会形成孤立点,就需要进行偏差分析。以前许多数据分析方法都 将孤立点作为嗓声或意外而将其排除在分析处理的范围之外。事实上在一些 商业应用中,小概率发生事件往往比经常发生的事件更有挖掘价值,如各种 商业欺诈行为的自动检测等。因此,偏差分析有助于滤掉知识发现引擎所抽 取的无关信息,也可滤掉那些不合适的数据,还可产生新的引人关注的事实。 偏差分析的主要算法包括基于统计的、基于距离的、基于密度的、基于偏离 的分析算法等。 (7)预测。预测是指利用从历史数据集中自动推导出的对给定数据的推广 描述,预测未知的数据值或变化趋势。例如根据客户的年龄、性别和收入来 预测他的大概支出。常用的预测技术包括线性和多项式回归、神经网络和决 策树预测等。
规则。规则知识由前提条件和结论两部分组成。前提条 件由字段项(属性)的取值的合取(与八)和析取(或V)组 合而成,结论为决策字段项(属性)的取值或者类别组成。 (2)决策树。基于信息论方法所挖掘到的知识一般表示为决 策树。如ID 3方法的决策树由信息量最大的字段(属性)作为 根结点,它的各个取值为分支,对各个分支所划分的数据元")
6. 3. 6 知识发现结果的表示 数据挖掘所获得的知识既可以以直观的图表形式展示给 用户,也可以以内部结构形式存储到知识库中,其表示形式 主要有四种:规则、决策树、浓缩数据、公式。 (1)规则。规则知识由前提条件和结论两部分组成。前提条 件由字段项(属性)的取值的合取(与八)和析取(或V)组 合而成,结论为决策字段项(属性)的取值或者类别组成。 (2)决策树。基于信息论方法所挖掘到的知识一般表示为决 策树。如ID 3方法的决策树由信息量最大的字段(属性)作为 根结点,它的各个取值为分支,对各个分支所划分的数据元 组(记录)子集,重复建树过程,扩展决策树,最后得到相 同类别的子集,以该类别作为叶结点。
浓缩数据。数据挖掘方法能计算出数据库中字段项(属 性)的重要程度,对于不重要的字段可以删除。对数据库中的 元组(记录)能按一定的原则合并。这样,就能大大压缩数据 库的元组和字段项,最后得到浓缩数据,它是原数据库的精华。 (4)公式。科学和 程数据库中存放了大量实验数据(数值) ,它们中蕴涵着一定的规律性,通过一定的数据挖掘算法,可 以找出各种变量间的相互关系,并可用公式表示。")
(3)浓缩数据。数据挖掘方法能计算出数据库中字段项(属 性)的重要程度,对于不重要的字段可以删除。对数据库中的 元组(记录)能按一定的原则合并。这样,就能大大压缩数据 库的元组和字段项,最后得到浓缩数据,它是原数据库的精华。 (4)公式。科学和 程数据库中存放了大量实验数据(数值) ,它们中蕴涵着一定的规律性,通过一定的数据挖掘算法,可 以找出各种变量间的相互关系,并可用公式表示。
:它主要包括四个模块:基 于知识库的约束生成模块、基于约束的知识发现模块、支持演化知识库的 知识库管理模块、以及激发整个知识发现与知识演化过程的知识应用模块。")
6. 3. 7 基于知识发现的知识获取模型 随着数据库、网络资源的发展,知识发现的对象不仅仅侧重于专家经 验,日益丰富的数据库信息、Web信息已成为大量而有用的知识来源。如 何从超大数量、动态变化的信息源中有效的抽取出特定的知识是知识获取 中的热点和难点。基于KDD的知识自动获取可以实现从变化的环境中学习、 发现新的知识,构建知识库,并进行一系列的检测和更新,丰富和完善知 识库系统。 基于KDD的知识自动获取模型(如下图):它主要包括四个模块:基 于知识库的约束生成模块、基于约束的知识发现模块、支持演化知识库的 知识库管理模块、以及激发整个知识发现与知识演化过程的知识应用模块。


模型说明: 该模型是一个演化循环的过程: ——约束生成模块:该模块一方面从知识库中获得先验知识输入,另一方面从 知识发现模块获得算法参数输入,结合两类输入和约束生成机制,该模块自动 生成约束集合,代表先验知识指导知识发现的全过程。 ——知识发现模块:应用知识发现技术从数据库发现、提炼新的知识。 ——知识库管理模块:结合生成的新知识与知识库中的原知识进行检测,融合 了原有知识和新环境特性,不断的动态更新知识库。 ——知识应用模块:不断运用更新后的知识执行当前应用任务,并根据真实值 反馈判断当前知识库能否满足应用需求。如果当前知识库中的知识已经过时, 知识应用模块将利用新的运行数据更新数据库,并激发约束生成模块开始新一 轮的知识获取过程,形成连续的知识演化循环,自动化地实现了动态环境下的 知识获取。这一螺旋上升的循环过程使模型获取的知识越来越丰富、越来越完 整。
约束生成模块 该模块从知识库自动产生对KDD过程的约束。它获得知识库中的先验 知识输入和KDD模块的参数输入,输出对KDD过程的约束。 该模块通过约束利用知识库中现有知识,其方法的基本思想是:根据 一定的约束生成机制,自动从知识库中产生约束,这些约束在一定程度上 反映了知识库中的现有知识;利用这些约束指导KDD过程的进行,实现基 于约束的数据挖掘,即相当于利用知识库中的现有知识指导了KDD过程的 进行。这样,整个约束生成和基于约束的KDD过程都可以自动化地进行, 减少了手 操作的任务量,极大地提高 作效率及其实时性。 指导KDD过程的约束的具体内容可以有:①数据约束。用户可以指定 对哪些数据进行挖掘,而不一定是全部的数据。②指定挖掘的维和层次。 用户可以指定对哪些维以及维上的哪些层次进行挖掘。③规则约束。可以")
(1)约束生成模块 该模块从知识库自动产生对KDD过程的约束。它获得知识库中的先验 知识输入和KDD模块的参数输入,输出对KDD过程的约束。 该模块通过约束利用知识库中现有知识,其方法的基本思想是:根据 一定的约束生成机制,自动从知识库中产生约束,这些约束在一定程度上 反映了知识库中的现有知识;利用这些约束指导KDD过程的进行,实现基 于约束的数据挖掘,即相当于利用知识库中的现有知识指导了KDD过程的 进行。这样,整个约束生成和基于约束的KDD过程都可以自动化地进行, 减少了手 操作的任务量,极大地提高 作效率及其实时性。 指导KDD过程的约束的具体内容可以有:①数据约束。用户可以指定 对哪些数据进行挖掘,而不一定是全部的数据。②指定挖掘的维和层次。 用户可以指定对哪些维以及维上的哪些层次进行挖掘。③规则约束。可以 指定哪些类型的规则是所需要的。
KDD模块 该模块的功能在于实现基于知识库指导的知识获取。如何有效地结合领 域知识进行数据挖掘是提高知识获取与发现效率和性能的关键之一。本模块 将用户知识和领域知识存储于知识库中,通过自动化的机制从知识库中生成 限制和指导KDD过程的约束,并在此约束的基础上进行知识发现。 KDD模块由数据选择、数据预处理、数据转换、数据挖掘与解释评价 这五个子步骤组成。其中,数据选择子步骤依据相应的约束选出相关的属性 和数据集;数据预处理子步骤筛选掉非法的记录并补齐缺失值;数据挖掘子 步骤实现基于约束的挖掘;在解释评价子步骤中,根据满足约束的程度对目 标集进行排序选优。这里以关联规则挖掘算法为例,说明基于约束的KDD 具体实现过程。 数据挖掘技术:包括概念描述、关联分析、分类分析、聚类分析、时序 分析、偏差检测分析、预测等。基于约束的关联规则挖掘是克服关联规则挖掘 产生大量无用规则的有效手段。它将约束规则内嵌到挖掘引擎里,来约束指")
(2)KDD模块 该模块的功能在于实现基于知识库指导的知识获取。如何有效地结合领 域知识进行数据挖掘是提高知识获取与发现效率和性能的关键之一。本模块 将用户知识和领域知识存储于知识库中,通过自动化的机制从知识库中生成 限制和指导KDD过程的约束,并在此约束的基础上进行知识发现。 KDD模块由数据选择、数据预处理、数据转换、数据挖掘与解释评价 这五个子步骤组成。其中,数据选择子步骤依据相应的约束选出相关的属性 和数据集;数据预处理子步骤筛选掉非法的记录并补齐缺失值;数据挖掘子 步骤实现基于约束的挖掘;在解释评价子步骤中,根据满足约束的程度对目 标集进行排序选优。这里以关联规则挖掘算法为例,说明基于约束的KDD 具体实现过程。 数据挖掘技术:包括概念描述、关联分析、分类分析、聚类分析、时序 分析、偏差检测分析、预测等。基于约束的关联规则挖掘是克服关联规则挖掘 产生大量无用规则的有效手段。它将约束规则内嵌到挖掘引擎里,来约束指 导挖掘过程,从而快速高效地实现定向的数据挖掘和知识发现。
知识库管理模块由知识转换、知识检测和知识融合这三个子模块组成。 该模块的功能在于对所发现的新知识与知识库中的原有知识进行正确性、 一致性、完整性检测,并对不一致和不完整的情况进行处理。经过检测和 消解后,两者融合为新的知识库,更新原有知识库,用于之后的知识应用 与新一轮的知识发现过程。 实现该模块功能的最直接的方法是由领域专家或用户从新发现的知识 中选择有用的知识,和知识 程师一起将其加入到系统知识库中,并对知 识库进行检测,实现知识库更新和完善。为了减轻领域专家和知识 程师 进行手 操作的负担,另一种方法是采用知识自动检测技术。通过知识自 动检测,可以有效地发现知识库中不一致和不完整的知识,再提供给领域 专家进行处理。遵循领域专家和用户指定的处理方法和相关参数,可以实")
(3)知识库管理模块由知识转换、知识检测和知识融合这三个子模块组成。 该模块的功能在于对所发现的新知识与知识库中的原有知识进行正确性、 一致性、完整性检测,并对不一致和不完整的情况进行处理。经过检测和 消解后,两者融合为新的知识库,更新原有知识库,用于之后的知识应用 与新一轮的知识发现过程。 实现该模块功能的最直接的方法是由领域专家或用户从新发现的知识 中选择有用的知识,和知识 程师一起将其加入到系统知识库中,并对知 识库进行检测,实现知识库更新和完善。为了减轻领域专家和知识 程师 进行手 操作的负担,另一种方法是采用知识自动检测技术。通过知识自 动检测,可以有效地发现知识库中不一致和不完整的知识,再提供给领域 专家进行处理。遵循领域专家和用户指定的处理方法和相关参数,可以实 现自动化的知识检测与知识融合,尤其当知识库中的知识需要随着环境的 变化而不断变化时,这种自动演化知识库可以有效提高 作效率。
知识应用模块 该模块由应用系统和运行监控子模块组成,可以将知识 库中的知识应用于实际的系统运行过程,并从外界获得反馈。 当反馈结果表明知识库应用系统处理结果与实际情况存在较 大误差时,运行监控模块判定应用系统运行环境已发生变化, 知识需要更新,于是激发新一轮的知识获取过程。")
(4)知识应用模块 该模块由应用系统和运行监控子模块组成,可以将知识 库中的知识应用于实际的系统运行过程,并从外界获得反馈。 当反馈结果表明知识库应用系统处理结果与实际情况存在较 大误差时,运行监控模块判定应用系统运行环境已发生变化, 知识需要更新,于是激发新一轮的知识获取过程。

6. 4 知识获取在智能信息系统中的应用 智能信息系统应具有知识表示、推理和学习的 能力。系统中,所有知识应被合理地表示,推理策 略必须能适应智能提问处理。系统还应能适应环境 的变化,不断动态地获取、精炼和扩展系统的知识, 来控制表示和推理从一种状态转换为另一种适应新 环境的状态,并不断地改进系统的执行性能。这种 具有学习能力的系统将能从行为信息中获取经验知 识,能探索领域中的新概念和新模型,还能综合数 据和实例,提供高质量的情报知识。

6. 4. 1 具有知识获取功能的智能信息系统模型 智能信息系统应包含知识获取子系统,使其具有从外界环境学习和从 系统本身学习的各种灵活策略。其模型如下图所示,主要包括知识获取、 知识库管理、知识利用和知识服务等部分。其中,知识获取部分利用各种 获取方法获得系统所需要的各类知识,建立、修改和扩展知识库。
综合利用各种信息源,也就是综合信息系统所需要的信 息源和学习任务所需要的信息源。例如将学习任务中的领域 知识和信息系统中的领域知识合为一体。 (2)对各种信息源的不同表示进行综合、一致地管理,例如, 领域概念的分类结构,属性的可能值,以及事实和规则的条件。 (3)将知识获取的各项任务适当综合于信息系统各部件的功 能任务中。 (4)能将外界知识获取和系统自身执行的反馈学习有机地结 合起来,提高系统的执行性能和效率。")
这种综合式信息系统具有以下特点: (1)综合利用各种信息源,也就是综合信息系统所需要的信 息源和学习任务所需要的信息源。例如将学习任务中的领域 知识和信息系统中的领域知识合为一体。 (2)对各种信息源的不同表示进行综合、一致地管理,例如, 领域概念的分类结构,属性的可能值,以及事实和规则的条件。 (3)将知识获取的各项任务适当综合于信息系统各部件的功 能任务中。 (4)能将外界知识获取和系统自身执行的反馈学习有机地结 合起来,提高系统的执行性能和效率。

智能信息系统中所包含的知识获取 作: 具有学习功能的智能信息系统中,知识获取的总任务是 建立、修改、扩展和重新组织知识库。它包括知识库的结构 与内容知识的获取、精炼和完善。其知识获取 作可概括为 以下四个方面: Ø领域知识的获取 Ø专家知识的获取 Ø用户知识的获取 Ø基于系统自学习的知识获取。基于系统自学习的知识获取是 从系统内部获取知识。

6. 4. 2 领域知识的获取 领域知识:指与主题相关的知识,包括专业知识、数据事 实知识等,用于描述专业领域中的各实体对象和对象之间的关 系。领域知识对于事实数据的标引和检索、用户查询式的扩展、 匹配算法的实现都具有重要的意义,是智能信息系统中不可缺 少的信息源。领域知识通常以概念的形式进行表示和描述。概 念可以是对具体实体对象的描述,也可以是对特征、行为、时 间、规则、策略的描述。 领域知识获取:其主要 作表现为获取基本概念及概念之间 的各种语义关系,即获取概念知识。概念可以描述实体对象, 也可以描述抽象对象。

领域知识的获取方法: ——人 获取 在传统的信息系统中,专业领域知识一般通过该领域的叙词表来描 述,其获取方法主要有以下几种:从现有叙词表中移植,然后加以精练、 修改和补充;当没有现成词表可用,则从那些专业词汇高度集中的参考 具书或文献原文获取;通过检索咨询交互,向用户和专家学习。 ——利用自然语言处理技术实现领域知识的自动获取 如CODER智能检索系统利用人机结合方法和自然语言处理技术,从 专业词汇高度密集的人 智能手册中获取人 智能领域的概念知识。但是, 受相关技术的影响,基于自然语言处理的领域知识获取实现难度较大,在 相关技术没有取得实质性突破之前,该方法只是一种理想的方法。

——采用机器学习和数据挖掘技术 获取领域知识的较易实现的、且较有效的自动化方法是,采用机器学习 和数据挖掘技术,从各专业文献中、从用户和专家的交互信息或检索实例中 获取概念知识。 此外,还可以通过概念相交、概念组配等概念逻辑方法获得新概念。 目前,领域知识获取中的研究难点与热点在于如何以机器可读的形式实 现对深层知识和隐性知识的表示,用于描述专业领域知识中的各层次的实体 对象和对象关系,从而支持复杂的相关度计算和推理。由于概念知识是一种 很复杂的结构化的信息集合,概念之间存在各种纵向和横向的关系,构成一 个网络形式,在人 智能领域,常用语义网络表示法作为概念本身的知识表 示形式,采用语义网络表示法时,相关知识还可以从相连的结点推导出来。 下面侧重介绍基于机器学习、数据库、本体的领域知识获 取方法。
基于语义网络的领域知识获取 概念知识是通过概念及其关系对客观事实进行抽象的、简化的描 述。概念既可以是对具体实体对象的描述,也可以是对特征、行为、 时间、规则、策略的描述。 概念知识的关键部分是概念之间的关系知识。在获取基本概念之 后,需要识别概念之间的各种语义关系。首先是评估、识别概念之 间的相关性,各种自动分类或聚类方法用来测量概念间的相似值。 经过聚类形成概念类以后,进一步获取类中概念之间的语义关系, 尤其是等级关系。此项 作较困难,通常通过统计分析、机器归纳 学习、利用专家启发式知识的逻辑推理来推导概念之间的等级关系。 由于同一概念可能拥有多个有同义关系的描述元,并且概念的描述 亦可随时空或学科领域等因素的改变而变化,故需要动态地评估和 识别概念之间的相关性。")
(一)基于语义网络的领域知识获取 概念知识是通过概念及其关系对客观事实进行抽象的、简化的描 述。概念既可以是对具体实体对象的描述,也可以是对特征、行为、 时间、规则、策略的描述。 概念知识的关键部分是概念之间的关系知识。在获取基本概念之 后,需要识别概念之间的各种语义关系。首先是评估、识别概念之 间的相关性,各种自动分类或聚类方法用来测量概念间的相似值。 经过聚类形成概念类以后,进一步获取类中概念之间的语义关系, 尤其是等级关系。此项 作较困难,通常通过统计分析、机器归纳 学习、利用专家启发式知识的逻辑推理来推导概念之间的等级关系。 由于同一概念可能拥有多个有同义关系的描述元,并且概念的描述 亦可随时空或学科领域等因素的改变而变化,故需要动态地评估和 识别概念之间的相关性。
基于机器学习的领域知识获取 这里采用面向对象的方法设计概念知识的逻辑结构。在 表示概念知识时,属分等级关系是概念之间诸关系中最本质 的关系,是组织概念库的核心元素。面向对象的方法很适合 表达这种具有等级关系的知识。由于概念的属分关系、等同 关系不是唯一的,也不是固定的,一个概念可能有一个或多 个属概念,可能有一个或多个等同概念,当然也存在没有属 概念和等同概念的情况。后图是采用面向对象方法表达概念 对象时的结构框架图。")
(二)基于机器学习的领域知识获取 这里采用面向对象的方法设计概念知识的逻辑结构。在 表示概念知识时,属分等级关系是概念之间诸关系中最本质 的关系,是组织概念库的核心元素。面向对象的方法很适合 表达这种具有等级关系的知识。由于概念的属分关系、等同 关系不是唯一的,也不是固定的,一个概念可能有一个或多 个属概念,可能有一个或多个等同概念,当然也存在没有属 概念和等同概念的情况。后图是采用面向对象方法表达概念 对象时的结构框架图。

概念对象框架图 概念对象图中包含 7个概念对 象:概念词表、族首词表、自由词 表、等同关系词表、上位类词表、 下位类词表和相关关系词表。其中 概念词表是主表,其它为子表。为 了解决概念对象之间的不确定关系, 设计过程中可利用对象类型扩展, 将用、代、属、族、分、参考等关 系设计成对象类型。然后利用这些 对象类型来创建嵌套表类型。嵌套 表类型可以表达概念实体的基本属 性,还可用来将子表的数据嵌入其 父表,动态实现不确定关系。
基于权值优先的方法精炼概念知识 基于权值优先的学习方法,就是依据用户的访问和反馈信 息学习。系统对每一个主题概念分配一个权值,表示用户对 它的满意程度和访问频率。系统通过观察记忆机制对用户经 常检索和访问的主题进行统计,并转换成权值。另一方面, 通过反馈学习算法根据用户反馈信息修改相关权值。系统依 据权值优先的原则,周期性地检查精炼概念知识。")
概念框架模型中的概念学习方法 采用上述的逻辑框架设计数据库表后,可以应用两种概念 学习方法:一种是基于权值优先的方法精炼概念知识;另一 种是基于自由词的方法学习新的概念。 (1)基于权值优先的方法精炼概念知识 基于权值优先的学习方法,就是依据用户的访问和反馈信 息学习。系统对每一个主题概念分配一个权值,表示用户对 它的满意程度和访问频率。系统通过观察记忆机制对用户经 常检索和访问的主题进行统计,并转换成权值。另一方面, 通过反馈学习算法根据用户反馈信息修改相关权值。系统依 据权值优先的原则,周期性地检查精炼概念知识。
基于自由词的方法学习新概念 基于自由词的学习是,在机器获取了自由词的情况下, 如何判断自由词是否能被提取出来作为备用的正式主题概念, 即正式主题词或非正式主题词。当然这些备用的主题概念还 需提交专家进一步审核。学习系统所起作用是记录自由词并 统计其使用频率,依据限定的条件将其转化为备用词,为专 家决策起辅助作用。系统基于概念知识库中的自由词表,在 用户进行检索时,自动将检索词与自由词表进行比较,如果 该检索词在自由词表中,则将其计数器加 1。计数器设定一阀 值,当自由词被查询的次数达到阀值时,系统则自动改变该 自由词标志,该标志供专家参考,以便修改该自由词自由词 的类别,或提升为正式主题概念。")
(2)基于自由词的方法学习新概念 基于自由词的学习是,在机器获取了自由词的情况下, 如何判断自由词是否能被提取出来作为备用的正式主题概念, 即正式主题词或非正式主题词。当然这些备用的主题概念还 需提交专家进一步审核。学习系统所起作用是记录自由词并 统计其使用频率,依据限定的条件将其转化为备用词,为专 家决策起辅助作用。系统基于概念知识库中的自由词表,在 用户进行检索时,自动将检索词与自由词表进行比较,如果 该检索词在自由词表中,则将其计数器加 1。计数器设定一阀 值,当自由词被查询的次数达到阀值时,系统则自动改变该 自由词标志,该标志供专家参考,以便修改该自由词自由词 的类别,或提升为正式主题概念。
基于本体的领域知识获取 领域概念知识是通过概念及其关系对客观事实进行抽象的、简化的描述。 概念知识非常适合应用本体方法来表达、获取。 本体方法:利用本体方法获取领域知识时,首要任务就是识别和获取概念 知识,包括识别兴趣领域的关键概念、识别概念间关系和识别与这些概念和 关系相关的词项,最终结果是形成一套概念集合。由于领域知识的获取过程 不是一步完成的,在建立其基本的类层次结构以后,还需要通过对各种类型 专业领域知识的学习,不断地对领域知识进行充实和丰富。 获取领域知识的过程主要分为二步:首先要根据知识信息的应用需求确 定概念集合的主题范围;其次是从主题范围中识别概念及其关系,形成概念 集合。要不断学习新的领域知识,以保证领域知识的时效性和新颖性。")
(三)基于本体的领域知识获取 领域概念知识是通过概念及其关系对客观事实进行抽象的、简化的描述。 概念知识非常适合应用本体方法来表达、获取。 本体方法:利用本体方法获取领域知识时,首要任务就是识别和获取概念 知识,包括识别兴趣领域的关键概念、识别概念间关系和识别与这些概念和 关系相关的词项,最终结果是形成一套概念集合。由于领域知识的获取过程 不是一步完成的,在建立其基本的类层次结构以后,还需要通过对各种类型 专业领域知识的学习,不断地对领域知识进行充实和丰富。 获取领域知识的过程主要分为二步:首先要根据知识信息的应用需求确 定概念集合的主题范围;其次是从主题范围中识别概念及其关系,形成概念 集合。要不断学习新的领域知识,以保证领域知识的时效性和新颖性。
确定主题范围 概念集合的主题范围是指概念所反映的知识信息的全部内容主题,也 是本体的知识主题范围。由于概念集合主要通过非形式化语言进行描述, 具有很大的不确定性和模糊性,在不同的时空、领域、语境中,同一概念 也可能会具有不同的语义内涵。因此概念集合的确定总是需要和具体的应 用需求相联系。只有通过考察本体论的应用目的、信息需求、用户特征和 运行环境,才能确定概念的内涵以及概念集合所涵盖的主题范围。 确定主题范围的方法主要有两个: Ø应用场景和能力问题法:应用场景是对实际应用中各种情况和应对措施 的假想,主要包括可能出现的问题、相关条件和问题可能的解答。 Ø头脑风暴法:在本体的应用环境不易确定的情况下,使用应用场景和能 力问题往往不足以覆盖所有的应用需求。这时,头脑风暴法就可以作为替 代或补充方法。头脑风暴法的实施方法是:利用头脑风暴产生一组与应用 需求潜在相关的词项,如果参与者的技术技能不够,则需要参考相关的知")
(1)确定主题范围 概念集合的主题范围是指概念所反映的知识信息的全部内容主题,也 是本体的知识主题范围。由于概念集合主要通过非形式化语言进行描述, 具有很大的不确定性和模糊性,在不同的时空、领域、语境中,同一概念 也可能会具有不同的语义内涵。因此概念集合的确定总是需要和具体的应 用需求相联系。只有通过考察本体论的应用目的、信息需求、用户特征和 运行环境,才能确定概念的内涵以及概念集合所涵盖的主题范围。 确定主题范围的方法主要有两个: Ø应用场景和能力问题法:应用场景是对实际应用中各种情况和应对措施 的假想,主要包括可能出现的问题、相关条件和问题可能的解答。 Ø头脑风暴法:在本体的应用环境不易确定的情况下,使用应用场景和能 力问题往往不足以覆盖所有的应用需求。这时,头脑风暴法就可以作为替 代或补充方法。头脑风暴法的实施方法是:利用头脑风暴产生一组与应用 需求潜在相关的词项,如果参与者的技术技能不够,则需要参考相关的知 识资料以保证对应用需求的充分覆盖。
识别和产生概念集合的主要任务是从上一步形成的术语表中识别概念和关系, 采用没有歧义的准确文本定义概念,描述概念关系,形成概念集合。这一 过程主要包括去重、分组、定义概念和描述关系四个步骤。 Ø去重:应用某种清理方法对术语表进行修整,去除某个词项的原则有两 个:一是该词项是重复词;二是该词项的相关性较低。 Ø分组:为了便于提取概念,可以根据术语表中词项的语义对其进行分组, 将语义相似的词项或者具有一定相关性的词项分到同一组。 Ø识别和定义概念:应用本体学习的方法,从词项分组中识别概念,并用 准确的自然语言定义概念。 Ø识别和描述关系:应用本体学习的方法识别两个概念间的关系,也就是 它们所属的两个组间的相互参照关系。概念关系的描述将加入到各个概念 的定义中,形成完整的概念集合。")
(2)识别和产生概念集合的主要任务是从上一步形成的术语表中识别概念和关系, 采用没有歧义的准确文本定义概念,描述概念关系,形成概念集合。这一 过程主要包括去重、分组、定义概念和描述关系四个步骤。 Ø去重:应用某种清理方法对术语表进行修整,去除某个词项的原则有两 个:一是该词项是重复词;二是该词项的相关性较低。 Ø分组:为了便于提取概念,可以根据术语表中词项的语义对其进行分组, 将语义相似的词项或者具有一定相关性的词项分到同一组。 Ø识别和定义概念:应用本体学习的方法,从词项分组中识别概念,并用 准确的自然语言定义概念。 Ø识别和描述关系:应用本体学习的方法识别两个概念间的关系,也就是 它们所属的两个组间的相互参照关系。概念关系的描述将加入到各个概念 的定义中,形成完整的概念集合。

基于本体的概念知识学习的基本原理: 领域知识的学习可以采用人 和自动两种方式,自动方式是学习的主要 方式,通过本体和知识提取 具的结合,可以实现持续的自动学习。 基于本体的概念知识学习的基本原理:首先依据语言知识库和专家知识 库提供的相关知识和学习规则,对事实数据进行解析,识别和提取与领域本 体中的分类结构相匹配的知识模式和元素。本体学习过程分为两步: Ø识别概念本体:从句法和语义两方面对自然语言的事实数据进行解析,将 其逐步分解为段、句、短语和词,将相关的词和短语组织在一起,作为语法 分析的结果。然后利用本体识别器和语言知识库对数据的段落和语句进行语 义检查,进而识别概念本体。 Ø识别概念本体之间的关系:这一步的主要任务是根据专业领域的专门语义 知识,提取被识别的概念本体间的二元关系,专门语义知识主要从领域本体 中推导而来。

6. 4. 3 专家知识的获取 专家知识是指专家执行专门任务的决策规则和技能,是领 域知识与具体问题的解决方案相结合的产物。专家知识是专家 在长期的生产实践中积累起来的财富,是系统执行各种推理的 基础。 具体说来,使用专家知识主要有这样一些好处: Ø系统能够在无人监督的情况下,高效、准确、迅速地 作; Ø使人类专家的领域知识突破时间和空间的限制,专家系统程 序可永久保存,并可复制任意多的副本或在网上供不同地区或 不同部门的人们使用; Ø能够带来巨大的经济效益和社会效益。
专家经验知识的特点 Ø专家经验知识的效用特点:在解决具体问题时,使用这些知识往往会得 到事半功倍的效果。 Ø专家经验知识与具体实例相结合的特点:专家的启发性知识都是从解决 具体的问题中总结出来的,因而它总是与具体的实例联系在一起的。使用 专家经验知识应该突破其针对具体实例的局限性,使其具有普遍意义。 Ø专家经验具有无正确性保障的特点:虽然专家经验知识非常有用,但它 只是领域专家给出的具有解决问题可能性的原始信息,并无正确性保障。 所以,专家经验必须经过验证和加 ,被转化为具有普遍意义的知识后才 能使用。 Ø专家经验知识具有难以表示的特点:领域专家所拥有的经验性、判断性 知识,实际上是一种直觉性和诀窍性的知识,它是专家在知识积累基础上 的本能反应,往往是可意会而不可言传。这正表明了专家经验知识难以获")
(一)专家经验知识的特点 Ø专家经验知识的效用特点:在解决具体问题时,使用这些知识往往会得 到事半功倍的效果。 Ø专家经验知识与具体实例相结合的特点:专家的启发性知识都是从解决 具体的问题中总结出来的,因而它总是与具体的实例联系在一起的。使用 专家经验知识应该突破其针对具体实例的局限性,使其具有普遍意义。 Ø专家经验具有无正确性保障的特点:虽然专家经验知识非常有用,但它 只是领域专家给出的具有解决问题可能性的原始信息,并无正确性保障。 所以,专家经验必须经过验证和加 ,被转化为具有普遍意义的知识后才 能使用。 Ø专家经验知识具有难以表示的特点:领域专家所拥有的经验性、判断性 知识,实际上是一种直觉性和诀窍性的知识,它是专家在知识积累基础上 的本能反应,往往是可意会而不可言传。这正表明了专家经验知识难以获 取的特点。
专家知识获取的途径与方法 在人 智能技术发展的初级阶段,人们企图通过专家访谈、发放调查表 等方式获取专家经验知识,但效果并不太理想,其主要原因是:①专家会谈 和发放调查表属于主观导向,难以收集到全面的专家经验信息;②人为因素 很难将隐含在专家经验中的虚假信息剔除;③脱离实情实景的经验描述,往 往难以同其要解决的具体问题发生联系;④在采集专家经验信息时,没有足 够地探索专家知识的范围和灵活性。随着人 智能、机器学习技术的发展和 应用,专家经验知识获取的效率和效果都有很大的改观,人们正致力于发挥 专家经验知识的最大效用。 专家经验知识获取方法: (1)机器归纳学习技术,从专家提供的 作实例或基本操作信息中归纳学")
(二)专家知识获取的途径与方法 在人 智能技术发展的初级阶段,人们企图通过专家访谈、发放调查表 等方式获取专家经验知识,但效果并不太理想,其主要原因是:①专家会谈 和发放调查表属于主观导向,难以收集到全面的专家经验信息;②人为因素 很难将隐含在专家经验中的虚假信息剔除;③脱离实情实景的经验描述,往 往难以同其要解决的具体问题发生联系;④在采集专家经验信息时,没有足 够地探索专家知识的范围和灵活性。随着人 智能、机器学习技术的发展和 应用,专家经验知识获取的效率和效果都有很大的改观,人们正致力于发挥 专家经验知识的最大效用。 专家经验知识获取方法: (1)机器归纳学习技术,从专家提供的 作实例或基本操作信息中归纳学 习专门知识。 (2)神经网络技术,使系统进行自组织、自学习,不断地充实、丰富专家 系统中原有的知识库。同时,可以采用归纳学习或者基于解释的机器学习方 法,对通过神经网络获取的知识进行处理,并对学习的效果进行检测。
专家知识获取模式 这里以智能检索系统为例,分析专家知识获取的模式。以 专家经验知识为基础的智能检索系统也可被看作一种专家系统, 但它又不同于一般的专家系统,主要因为信息检索是一个交叉 领域,涉及到计算机技术、信息管理等多领域的知识。专家智 能检索系统需要获取多学科领域的专家经验知识,需要应用多 种学习方法,从多种角度实现复合学习。这里给出以人 神经 网络为基础的专家知识获取模式,如下图所示。 专家智能检索系统功能的实现,依赖于检索专家的经验知 识与具体应用领域专家知识的结合,即在系统中要具有融合各 方专家经验知识的知识模型,然后针对具体的检索任务选择适 当的知识模型即可。")
(三)专家知识获取模式 这里以智能检索系统为例,分析专家知识获取的模式。以 专家经验知识为基础的智能检索系统也可被看作一种专家系统, 但它又不同于一般的专家系统,主要因为信息检索是一个交叉 领域,涉及到计算机技术、信息管理等多领域的知识。专家智 能检索系统需要获取多学科领域的专家经验知识,需要应用多 种学习方法,从多种角度实现复合学习。这里给出以人 神经 网络为基础的专家知识获取模式,如下图所示。 专家智能检索系统功能的实现,依赖于检索专家的经验知 识与具体应用领域专家知识的结合,即在系统中要具有融合各 方专家经验知识的知识模型,然后针对具体的检索任务选择适 当的知识模型即可。
,经人 神经网络 学习处理后,二者有机 地结合起来,形成专家 经验知识模型。")
专家知识获取模式 从给出的模式图可以 看出,系统从知识 程 师那里获取的临时知识 是零散的知识单元(学 科知识和检索知识相分 离),经人 神经网络 学习处理后,二者有机 地结合起来,形成专家 经验知识模型。

6. 4. 4 用户知识的获取 智能信息系统的一个策略是,允许用户建立他们自己的专门知识库。用户 知识包括专业背景知识、需求模型及喜爱的交互方式等。在知识获取中,可 使用特定知识获取方法识别和描述用户的各种特征,并通过建立用户模型来 描述用户的特点、背景知识和经验。 用户模型是对用户知识进行归纳抽象的产物,是实现个性化知识推理与检 索的重要部件。用户模型的设计主要基于这样一种思想:若系统能准确地生 成用户代表,那么它就能比较有把握地预言用户的行为和信息需求,从而使 知识推理和检索变得更为有效。 用户知识获取:主要从用户与系统的交互中或从用户使用记录中获取。例 如,系统可自动处理使用户不满意的系统状态,当这种状态再发生,则采用 新的交互方式。经过一段时间,用户在不同的系统状态下改变交互方式,学 习系统就可获得个人喜爱的交互模型。具体可参见“智能人机接口”一章中有 关内容。
基于系统运行实例的自学习。实例的运行过程是求解问题的过程,也 是系统积累经验、发现自身缺陷及错误的过程。适当记录运行实例,如记 录实例编号、提交人、提交时间、实例运行过程中出现的问题、运行后得 到的结论是否正确、运行时间等项目,并建立专用的实例库,就可以利用 这些实例进行归纳推理和实例推理获取提高系统运行性能的经验知识。 (2)基于系统运行史的自学习。系统是在使用过程中不断完善的,为了给 系统的进一步完善提供依据,除了记录系统的运行实例外,还需要记录系 统的运行史,记录的内容与知识的检测及求精方法有关,没有统一的标准。 一般来说应当记录:系统运行过程中激活的知识、产生的结论以及产生这")
6. 4. 5 基于系统自学习的知识获取 智能信息系统应拥有自学习功能,能从系统运行过程中学习到相关知识。 (1)基于系统运行实例的自学习。实例的运行过程是求解问题的过程,也 是系统积累经验、发现自身缺陷及错误的过程。适当记录运行实例,如记 录实例编号、提交人、提交时间、实例运行过程中出现的问题、运行后得 到的结论是否正确、运行时间等项目,并建立专用的实例库,就可以利用 这些实例进行归纳推理和实例推理获取提高系统运行性能的经验知识。 (2)基于系统运行史的自学习。系统是在使用过程中不断完善的,为了给 系统的进一步完善提供依据,除了记录系统的运行实例外,还需要记录系 统的运行史,记录的内容与知识的检测及求精方法有关,没有统一的标准。 一般来说应当记录:系统运行过程中激活的知识、产生的结论以及产生这 些结论的条件、推理步长、专家对结论的评价等。这些记录不仅可用来评 价系统的性能,而且对知识的维护以及系统向用户的解释都有重要作用。 通过记录系统运行史,可从中获取系统运行知识。
基于系统维护史的自学习。对系统知识库的增、删、改将使知识库 的内容发生变化,如果将其变化情况及知识的使用情况记录下来,将有利 于评价知识的性能、改善知识库的组织结构,增强知识库的主动维护功能。 为了记录知识库的发展变化情况,需要建立知识库发展史库,记录内容一 般包括:知识库设计者及建造者的姓名、初始建成的时间;每条知识的编 号以及它进入知识库的时间;如有知识被删除,则记录删除者的姓名、被 删除的知识以及删除的时间;如有知识被修改,则记录修改者的姓名、修 改前的知识及修改时间等;统计并记录各类知识的使用次数,如有可能还 可对各条知识的性能进行分析,一方面可对功能较弱的知识进行完善,另 一方面可把使用频率较高的知识放置在容易搜索的位置上,提高系统的运 行效率。")
(3)基于系统维护史的自学习。对系统知识库的增、删、改将使知识库 的内容发生变化,如果将其变化情况及知识的使用情况记录下来,将有利 于评价知识的性能、改善知识库的组织结构,增强知识库的主动维护功能。 为了记录知识库的发展变化情况,需要建立知识库发展史库,记录内容一 般包括:知识库设计者及建造者的姓名、初始建成的时间;每条知识的编 号以及它进入知识库的时间;如有知识被删除,则记录删除者的姓名、被 删除的知识以及删除的时间;如有知识被修改,则记录修改者的姓名、修 改前的知识及修改时间等;统计并记录各类知识的使用次数,如有可能还 可对各条知识的性能进行分析,一方面可对功能较弱的知识进行完善,另 一方面可把使用频率较高的知识放置在容易搜索的位置上,提高系统的运 行效率。

属性归纳方法实例: 思想: 首先查询关系数据库, 收集与任务相关的数据, , 然后考察其每个 属性的不同值的个数, 进行概括。它还可通过对属性值间概念的 层次结构进行归纳,获得相关数据的概括性知识。在实际情况中, 许多属性都可以进行数据归类,形成概念汇聚点。这些概念依抽 象程度的不同可构成描述它们层次结构的概念树。 概念层次树: 指某属性值所具有的从具体的概念值到概念类的层次关系 树。 一般由用户提供或从领域知识中得到该属性的概念层次树。 例:属性‘籍贯’的概念层次树,如下图所示。

籍 贯

归纳: 用属性概念层次树上高层的属性值去替代低层的属性值,又 称为概念提升。例如:用‘湖北’去代替‘武汉’,用‘江苏’去代 替‘南京’或‘苏州’等。 概括关系表 这是一张二维关系表,其属性是目标类中参与规则发现的属 性,其最终元组数不大于用户指定的值。该表中的元组被称 为宏元组。一个宏元组概括了多个基本元组,并附加上一个 COUNT属性,用以表示该宏元组所概括的基本元组数。 n 例子:有部分学生在图书馆借阅了《大趋势》这本书,想通 过数据挖掘技术发现这部分学生的特征和学科背景。其基本关 系表如下:

基本关系表: 学 号 姓 名 系 别 书 名 借阅日期 9932007 颜立 经济 大趋势 2000. 3. 16 9833090 王家卫 金融 大趋势 2000. 3. 16 9813105 王向东 医学院 大趋势 2000. 5. 8 9928073 朱小明 企管 大趋势 2000. 5. 20 9822041 刘伟 历史 大趋势 2000. 6. 30 9932056 陈立业 经济 大趋势 2000. 9. 19 9923143 刘英 新闻 大趋势 2000. 12. 3

概念层次树:系别 1 2 3 文科 – 商学院 -- 经济,金融,企管,会计,国贸 文科 – 文学院 -- 中文,新闻,信管,历史,哲学 理科 – 医学院 理科 – 理学院 -- 数学,天文,物理

概括关系表一 系 别 书 名 借阅次数 商学院 大趋势 4 文学院 大趋势 2 医学院 大趋势 1 概括关系表二 系 别 书 名 借阅次数 文科 大趋势 6 理科 大趋势 1 依据借阅次数来决定噪声数据的阀值

如果定义噪声数据的阀值是 1,则: 根据‘基本关系表’发现的特征规则是: 借阅《大趋势》一书的是‘经济系’的学生 根据‘概括关系表一’发现的特征规则是: 借阅《大趋势》一书的是‘商学院’的学生 借阅《大趋势》一书的是‘文学院’的学生 根据‘概括关系表二’发现的特征规则是: 借阅《大趋势》一书的是‘文科’的学生

如果定义噪声数据的阀值是 2,则: 根据‘基本关系表一’发现不到特征规则 根据‘概括关系表一’发现的特征规则是: 借阅《大趋势》一书的是‘商学院’的学生 根据‘概括关系表二’发现的特征规则是: 借阅《大趋势》一书的是‘文科’的学生 如果定义噪声数据的阀值是 5,则: 根据‘基本关系表一’发现不到特征规则 根据‘概括关系表二’发现的特征规则是: 借阅《大趋势》一书的是‘文科’的学生
掌握知识获取的主要方法:机器学习、数据挖掘与知识发现; (2)通过知识获取再IIS中的应用,为知识获取方法的学习、研究及 应用打下基础。")
小结 (1)掌握知识获取的主要方法:机器学习、数据挖掘与知识发现; (2)通过知识获取再IIS中的应用,为知识获取方法的学习、研究及 应用打下基础。
194dee4cdfc572d05a567dc9c42f896d.ppt