
Вычислительные системы, сети и телекоммуникации (часть I) Лектор

 Лектор заведующий кафедрой компьютерных технологий")





 появились в результате эволюции миникомпьютеров при переходе элементной базы машин")


 модели")





 - это компьютеры, имеющие на текущий момент развития человечества максимальную производительность, максимальный")



")














 Cray-1 имел 12 функциональных устройств. Они были разделены на")



 синхронизации, среднего количества тактов")
 единиц измерения производительности процессора является MIPS")















 В ЗУ фоннеймановской архитектуры обращение происходит")





+c)+d) h = 3 Дерево а) Уменьшение высоты дерева")
+(c+d) h = 2 Дерево б)")



 в общем случае основана на разделении подлежащей")




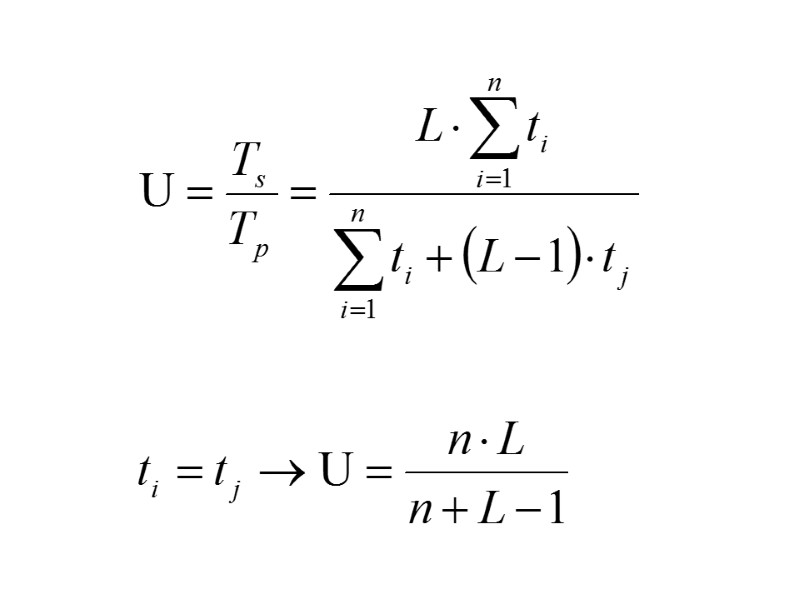














 Процессоры образуют конвейер, на")
 В системе SIMD используется несколько потоков")
 Базовой моделью вычислений на")




 ПАМЯТЬЮ И МНОГОМАШИННЫЕ СИСТЕМЫ")
 кэш-памяти состоит в необходимости гарантировать, что любое считывание")
. Информация")
.")


 и сетевого интерфейса контроллера блочных передач.")




 Рынок многопроцессорных векторных (векторно-параллельных) суперкомпьютеров")



 составляет 500 тыс. долл., а такой")
 Earth Simulator (ES) - мультипроцессорная компьютерная система с распределенной")

 был разработан как национальный проект Национальным агентством космического развития Японии, Научно-исследовательским")
")

. В АЗУ поиск идет")







 при обработке")
 вывода Маску вывода можно так же, как и регистр маски компаранда,")
 ввода-вывода АЗУ Эти регистры играют роль буфера при передаче данных")



")




, разряды")
 инициируется запрос к операционному коммутатору (ОК) на")








 для простейшего потока(то есть вероятность возникновения события в момент t) имеет экспоненциальный")
")




 того, что в момент t система")




); Вероятность третьего варианта равна")
![P0(t+Δt)= P0(t)[1- (λ1 + λ2)Δt] + μ1 Δt P1(t) +](https://present5.com/presentacii-2/20171208\19960-vsst_ch1_2012.ppt\19960-vsst_ch1_2012_159.jpg "P0(t+Δt)= P0(t)[1- (λ1 + λ2)Δt] + μ1 Δt P1(t) +")




 постоянны, то их производные равны нулю. Значит, чтобы найти финальные вероятности,")







")


=X(t)-Y(t) есть")




")




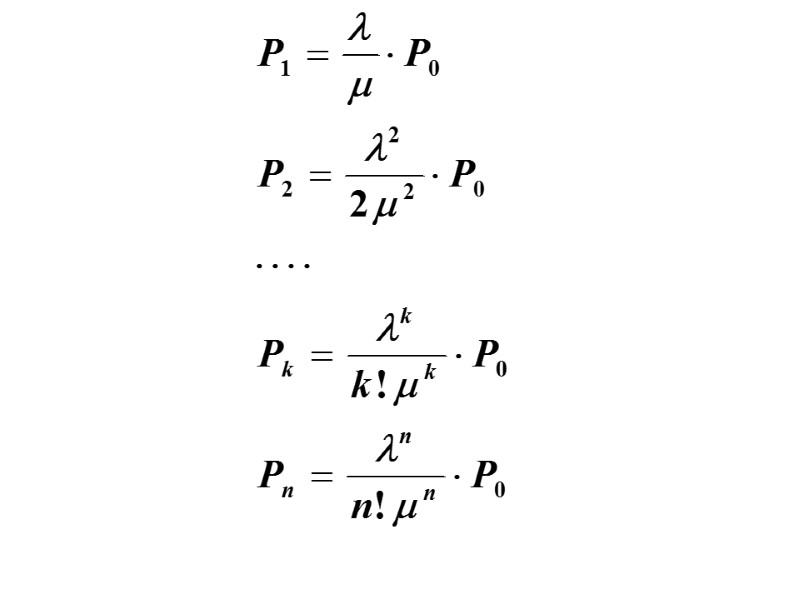

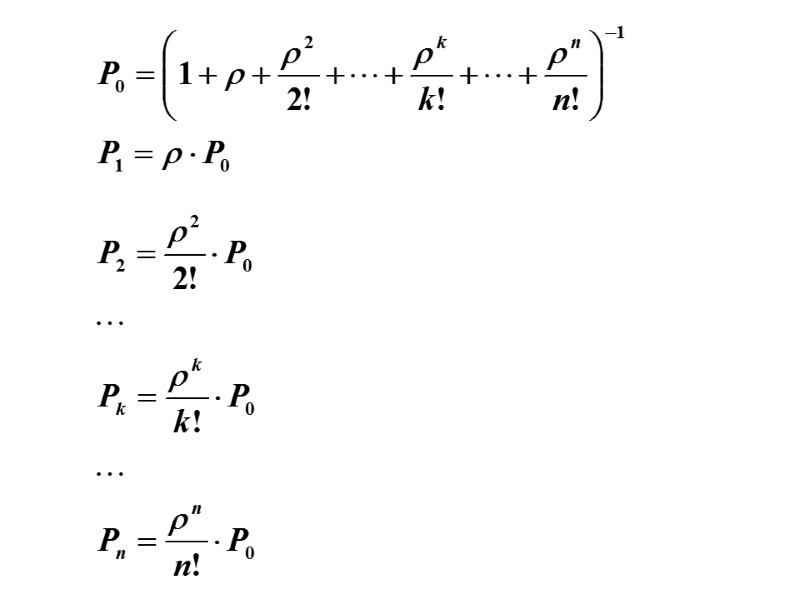




























 - это целое, составленное из частей. Другими словами система")








19960-vsst_ch1_2012.ppt
- Количество слайдов: 224
Вычислительные системы, сети и телекоммуникации (часть I) Лектор заведующий кафедрой компьютерных технологий и систем КубГАУ, заслуженный деятель науки РФ, доктор технических наук, профессор Лойко Валерий Иванович
Основная литература Архитектура компьютерных систем и сетей: Учебное пособие. / Т.П. Барановская, В.И. Лойко, М.И. Семенов, А.И. Трубилин. Под ред. В.И. Лойко. - Москва: Финансы и статистика, 2003. - 290 с.: ил. Информационные системы и технологии в экономике: Учебник. – 2-е изд, перераб. и доп./ Т.П. Барановская, В.И. Лойко, М.И. Семенов, А.И. Трубилин. Под ред. В.И. Лойко. - Москва: Финансы и статистика, 2006. - 457 с.: ил. Вентцель Е.С. Исследование операций: задачи, принципы, методология. – Москва.: Наука, 2002. Дополнителная литература Воеводин В.В. Параллельная обработка данных. Курс лекций, 2008. http://www.citforum.ru/; http://www.parallel.ru Пятибратов А.П. и др. Вычислительные системы, сети и телекоммуникации: Учебник. – 2-е изд, перераб. и доп. Под ред. А.П. Пятибратова. - Москва : Финансы и статистика, 2007.-457с.: ил. Шварц М. Сети связи: протоколы, моделирование и анализ: В 2-х ч.: Пер. с англ. – Москва.: Наука. Гл. ред. Физ.-мат. лит., 1992.
Раздел 1. Компьютерные системы ВССТ
14 февраля — неофициальный, но широко отмечаемый в профессиональном мире День компьютерщика. 14 февраля 1946 года научному миру и всем заинтересованным был продемонстрирован первый реально работающий электронный компьютер ENIAC I (Electrical Numerical Integrator And Calculator). Интересно, что работы по разработке первой вычислительной машины спонсировались американской армией, которой компьютер был необходим для проведения военных расчетов, планирования и программирования. ENIAC I проработал до 23 часов 45 минут 2 октября 1955 года, а потом был разобран. Конечно, были и более ранние компьютеры, но это все прототипы и экспериментальные варианты. Если уж на то пошло, то первым компьютером вообще была аналитическая машина Бэббиджа... Но ENIAC был первым реально работающим на практических задачах компьютером. Между прочим, именно от ENIACа современные компьютеры унаследовали двоичную систему счисления. ENIAC был разработан для решения одной из серьезных и нужных задач того времени: для обсчета баллистических таблиц армии. В армии были отделы, занимающиеся обсчетом баллистических таблиц для нужд артиллерии и авиации. Работали в этих отделах люди на должности Армейского Калькулятора. Естественно, мощности и производительности этих «вычислительных ресурсов» армии не хватало. Именно поэтому кибернетики в начале 1943 года приступили к разработке концепции нового вычислительного устройства — компьютера ENIAC.
1.1. Классификация компьютеров по областям применения
Персональные компьютеры и рабочие станции Серверы Мейнфреймы Кластерные архитектуры Суперкомпьютеры
Персональные компьютеры (ПК) появились в результате эволюции миникомпьютеров при переходе элементной базы машин с малой и средней степенью интеграции на большие и сверхбольшие интегральные схемы. ПК в начале ориентировались на самого широкого потребителя непрофессионала.
Миникомпьютеры стали прародителями и другого направления развития современных систем – 32-разрядных машин. Создание RISC-процессоров и микросхем памяти емкостью более 1 Мбит привело к окончательному оформлению настольных систем высокой производительности, которые сегодня известны как рабочие станции. Рабочие станции ориентированы на профессиональных пользователей.
Это чаще всего компьютеры с RISC процессорами, с многопользовательскими операционными системами, относящимися к семейству ОС UNIX. Содержат от одного до четырех двух-, четырхядерных процессоров. Поддерживают удаленный доступ. Могут обслуживать вычислительные потребности небольшой группы пользователей. В настоящее время появилось понятие "персональной рабочей станции", которое объединяет оба направления.
В распределенной (сетевой) модели "клиент-сервер" часть работы выполняет сервер, а часть пользовательский компьютер (в общем случае клиентская и серверная части могут работать и на одном компьютере).
Классификация серверов по виду ресурса: файл-сервер; сервер баз данных; принт-сервер; вычислительный сервер; сервер приложений. Классификация серверов по масштабу сети: сервер рабочей группы; сервер отдела; сервер масштаба предприятия (корпоративный сервер).
Современные суперсерверы характеризуются: наличием двух и более центральных процессоров RISC, либо Pentium, двух- или четырехъядерных; многоуровневой шинной архитектурой, в которой запатентованная высокоскоростная системная шина связывает между собой несколько процессоров и оперативную память, а также множество стандартных шин ввода/вывода, размещенных в том же корпусе; поддержкой технологии дисковых массивов RAID; поддержкой режима симметричной многопроцессорной обработки, которая позволяет распределять задания по нескольким центральным процессорам или режима асимметричной многопроцессорной обработки, которая допускает выделение процессоров для выполнения конкретных задач. Как правило, суперсерверы работают под управлением операционных систем UNIX и Windows NT.
Мейнфрейм - это синоним понятия "большая универсальная ЭВМ". Мейнфреймы и до сегодняшнего дня остаются наиболее мощными (не считая суперкомпьютеров) вычислительными системами общего назначения, обеспечивающими непрерывный круглосуточный режим эксплуатации.
Кластерные архитектуры реализуют объединение машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей. Машины, кластеризованные вместе таким способом, могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера.
VAX-кластер обладает следующими свойствами: разделение ресурсов; высокая готовность; высокая пропускная способность; удобство обслуживания системы; расширяемость.
Супер-ЭВМ (суперкомпьютеры) - это компьютеры, имеющие на текущий момент развития человечества максимальную производительность, максимальный объем оперативной и дисковой памяти, а также специализированное ПО, с помощью которого можно эффективно управлять этими ресурсами.
Rank - порядковый номер в списке Top500 Site - организация, в которой установлен компьютер System/Year Vendor - название (тип) компьютера, указанное поставщиком/производитель Cores - количество вычислительных ядер Rmax - максимальная полученная производительность по LINPACK (TFlop/s) Rpeak - теоретическая пиковая производительность (TFlop/s) Power - электропотребление системы в КВ
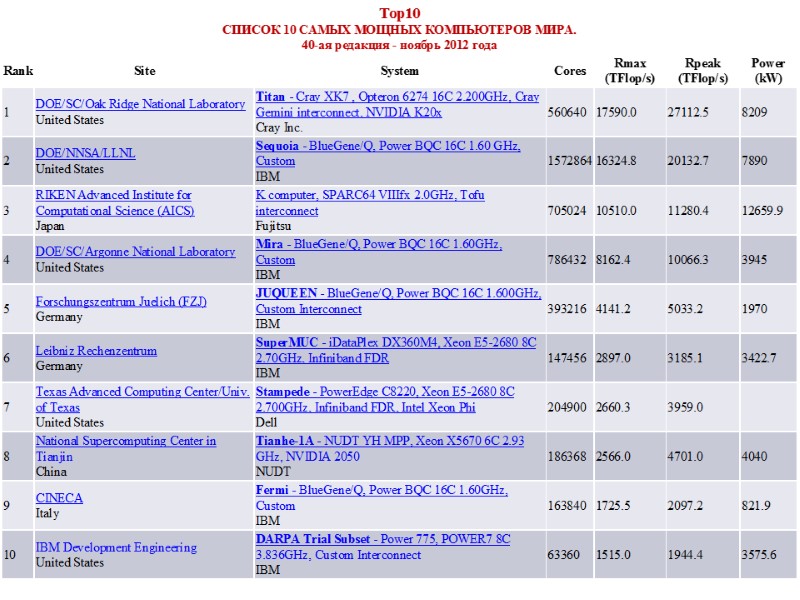
Список 10 самых мощных компьютеров мира. 37-ая редакция
Некоторая статистика 37-ой редакции списка мощнейших компьютеров мира 20 июня 2011 года была опубликована 37-ая редакция списка 500 наиболее мощных компьютеров мира Top500. На первом месте списка оказался новый суперкомпьютер K Computer, установленный в RIKEN Advanced Institute for Computational Science (Япония). Данный суперкомпьютер построен на базе 68544 8-ядерных процессоров SPARC64 VIIIfx, что суммарно составляет 548352 вычислительных ядер. Пиковая производительность K Computer составляет 8.77 PFlop/s, а производительность на тесте Linpack - 8.16 PFlop/s, что составляет рекордные для систем такого уровня 93% эффективности. На второе место списка опустился суперкомпьютер Tianhe-1A, установленный в National Supercomputer Center, Tianjin (Китай), с пиковой производительностью 4.7 PFlop/s и производительностью на тесте Linpack 2.57 PFlop/s. На третье место списка со второго опустился суперкомпьютер Jaguar Cray XT5, установленный в Oak Ridge National Laboratory. Его производительность на тесте Linpack составляет 1.759 PFlop/s. На четвёртое место с третьего опустился ещё один китайский суперкомпьютер Nebulae, построенный на базе процессоров Intel X5650 и ГПУ NVidia Tesla C2050, с пиковой производительностью 2.98 PFlop/s и производительностью на тесте Linpack 1.271 PFlop/s. Всего в списке оказалось 10 систем петафлопсного уровня производительности. Последняя, 500-ая система в новой редакции списка была бы полгода назад на 262-ом месте. Для того чтобы попасть в текущий список, потребовалась производительность на Linpack 40.1 TFlop/s против 31.1 TFlop/s в ноябре. Суммарная производительность систем в списке выросла за полгода с 43.7 PFlop/s до 58.88 PFlop/s.
TOP 10 суперкомпьютеров (39 редакция, июнь 2012)
Статистика 39 редакции
Titan — суперкомпьютер компании Cray Inc. установленный в национальной лаборатории Оук-Ридж (сокращенно ORNL, национальная лаборатория Министерства энергетики США, Теннесси) для использования в научных проектах. Является обновлением суперкомпьютера Jaguar, при котором было увеличено количество центральных процессоров и добавлены GPU Nvidia Tesla K20x
Система Titan - это обновленная версия ранее существовавшего суперкомпьютера Jaguar открытого в Национальной лаборатории Окридж в штате Теннесси. С учетом последнего рейтинга суперкомпьютеров, Titan - это один из двух мощнейших в мире суперкомпьютеров. В Минэнерго США говорят, что доступ к Titan получат американские ученые из университетской среды, правительственных лабораторий и различных коммерческих отраслей. Всего в проекте работы над Titan были задействованы около шести десятков подрядчиков, а бесплатный доступ к его ресурсам получат участники научной программы INCITE (Innovative and Novel Computational Impact on Theory and Experiment). В компании Nvidia, на базе решений которой были созданы дополнительные мощности Titan, рассказывают, что в первую очередь суперкомпьютер будет применяться для исследований в области изменения климата, материаловедения, ядерной энергетики, биотоплива и астрономии. "Все эти области требуют очень масштабных вычислений. Получив возможность быстро проводить необходимые расчеты, соответствующие исследовательские группы существенно продвинутся в работе", - говорит Стив Скотт, директор по технологиям Nvidia. Технически, Titan представляет собой новый тип системы, объединяющей в себе как традиционные процессоры, так и графические чипы Nvidia. В случае с Titan, в качестве x86-чипов применяются серверные процессоры AMD. Формально Titan потребляет 7 мегаватт мощности. Всего в Titan работают 560 640 процессоров, включая 300 000 процессоров AMD Opteron 6200 и 261 000 чипов Nvidia K20. Система разместилась в 200 серверных стойках и получила 710 терабайт памяти, необходимой для ее нормальной работы. Номинальная производительность Titan составляет 20 петафлоп/сек или 20 000 триллионов операций в секунду.
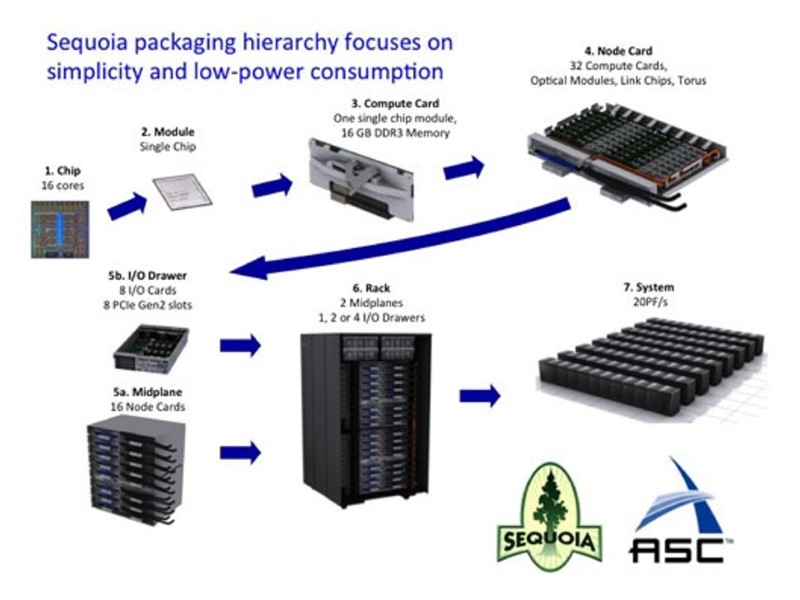
Характеристика Sequoia В основе комплекса Sequoia - суперкомпьютерная архитектура Blue Gene следующего поколения — Blue Gene/Q, использующая вычислительные ядра PowerPC A2. Процессоры для Sequoia имеют 18 ядер: 16 из них используются для расчётов, одно — для поддержания системных процессов Linux. Ещё одно ядро играет роль запасного: оно позволит поднять процент выхода годных изделий, а также в случае необходимости сможет подменить ядро, вышедшее из строя при эксплуатации комплекса. Чипы из состава BlueGene/Q имеют два контроллера памяти DDR3 и 32 Мб кеша второго уровня. Количество транзисторов составит около 1,47 млрд; при производстве чипов применяется 45-нанометровая технология. Тактовая частота — 1,6 ГГц. В системе Sequoia объединены мощности примерно 1,6 млн процессорных ядер. Объём оперативной памяти состаляет 1,6 петабайта, а для монтажа всего оборудования требуется 96 полноразмерных серверных стоек. Новый суперкомпьютер занимает площадь около 320 квадратных метров. Расчетная производительность Sequoia — до 20 петафлопсов (квадриллионов операций с плавающей запятой в секунду). Суперкомпьютер создан для Ливерморской национальной лабораторией имени Лоуренса Министерства энергетики США (LLNL). Использовать его учёные намерены в том числе при моделировании испытаний ядерного оружия. Монтаж комплекса произведен в первой половине 2012 года.
18-ядерная плата процессора Sequoia
Одна из плат стоек Sequoia
Стойка Sequoia
Sequoia
Sequoia
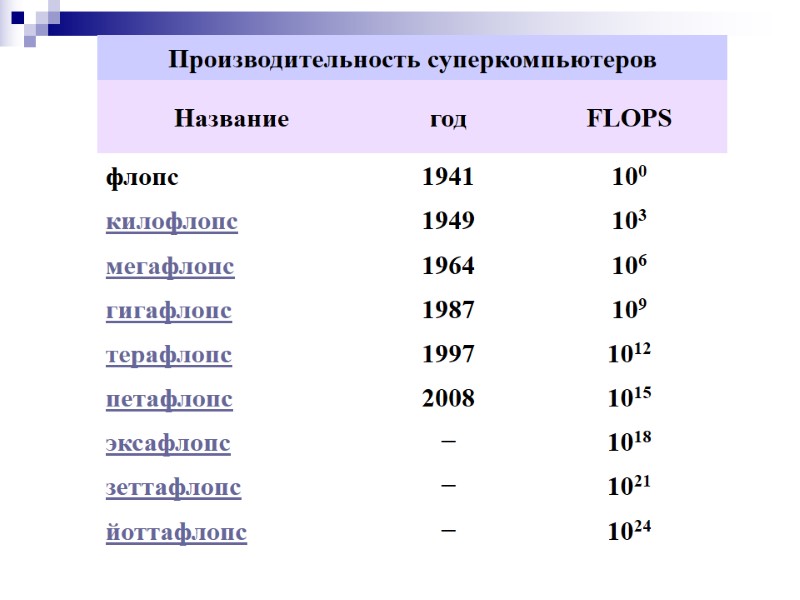
Производительность суперкомпьютеров Компьютер ЭНИАК, построенный в 1946 году, при массе 27 т и энергопотреблении 150 кВт, обеспечивал производительность в 300 флопс IBM 709 (1957) — 5 Кфлопс БЭСМ-6 (1968) — 1 Мфлопс (операций деления) Cray-1 (1974) — 100 Мфлопс БЭСМ-6 на базе Эльбрус-1К2 (1980-х) — 6 Мфлопс (операций деления) Эльбрус-2 (1984) — 125 Мфлопс Cray Y-MP (1988) — 2,3 Гфлопс Электроника СС БИС (1991) — 500 Мфлопс ASCI Red (1993) — 1 Тфлопс Blue Gene/L (2006) — 478,2 Тфлопс Jaguar (суперкомпьютер) (2008) — 1,059 Пфлопс IBM Roadrunner (2008) — 1,042 Пфлопс Jaguar Cray XT5-HE (2009) — 1,759 Пфлопс IBM Sequoia (2012) — 20 Пфлопс Cray Titan (2012) — 27 Пфлопс
Суперкомпьютер Cray-1 (1976 г.) Cray-1 имел 12 функциональных устройств. Они были разделены на группы в зависимости от типа выполняемых ими операций и адресуемых регистров. Выполняли вычисление адресов, логические, скалярные и векторные операции над целыми числами, операции с плавающей запятой над скалярами и векторами. Большинство простых операций центрального процессора выполняось за один такт, который составлял 12,5 нс. Производительность однопроцессорной машины Cray-1 составляла примерно 100 000 000 операций с плавающей точкой в секунду (100 Мфлопс).
Суперкомпьютер Cray-1
1.2. Оценка производительности вычислительных систем
Единицей измерения производительности компьютера является время: компьютер, выполняющий тот же объем работы за меньшее время является более быстрым. В большинстве современных процессоров скорость протекания процессов взаимодействия внутренних функциональных устройств определяется естественными задержками в этих устройствах и задается единой системой синхросигналов, вырабатываемых некоторым генератором тактовых импульсов, как правило, работающим с постоянной тактовой частотой.
Производительность ЦП зависит от трех параметров: такта (или частоты) синхронизации, среднего количества тактов на команду и количества выполняемых команд.
Одной из альтернативных (по отношению к времени выполнения) единиц измерения производительности процессора является MIPS - (миллион команд в секунду). При использовании этой единицы есть три проблемы. Во-первых, MIPS зависит от набора команд процессора, что затрудняет сравнение по MIPS компьютеров, имеющих разные системы команд. Во-вторых, MIPS даже на одном и том же компьютере меняется от программы к программе. В-третьих, MIPS может меняться по отношению к производительности в противоположенную сторону.
Для научно-технических задач производительность процессора оценивается в MFLOPS (миллионах чисел-результатов вычислений с плавающей точкой в секунду, или миллионах элементарных арифметических операций над числами с плавающей точкой, выполненных в секунду).
Соотношения между реальными и нормализованными операциями с плавающей точкой, которыми пользуются авторы "ливерморских циклов" для вычисления рейтинга MFLOPS
Ливерморские циклы - это набор фрагментов фортран-программ, каждый из которых взят из реальных программных систем. Обычно при проведении испытаний используется либо малый набор из 14 циклов, либо большой набор из 24 циклов. LINPACK - это пакет фортран-программ для решения систем линейных алгебраических уравнений.
1.3. Требования, предъявляемые к современным компьютерам
К современным компьютерам предъявляются требования по следующим общим показателям: Отношение стоимость/производительность Надежность и отказоустойчивость Масштабируемость Совместимость (мобильность) программного обеспечения
Надежность компьютера основана на предотвращении неисправностей путем снижения интенсивности отказов и сбоев его элементов. Отказоустойчивость - это такое свойство вычислительной системы, которое обеспечивает ей, как логической машине, возможность продолжения действий, заданных программой, после возникновения неисправностей.
Масштабируемость представляет собой возможность наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы. Концепция программной совместимости заключается в создании такой архитектуры, которая была бы одинаковой с точки зрения пользователя для всех моделей системы независимо от цены и производительности каждой из них.
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ 1. Проведите классификацию компьютеров по областям применения. 2. Каковы достоинства и недостатки существующих методов оценки производительности вычислительных систем? 3. Назовите общие требования, предъявляемые к современным компьютерам.
Раздел 2. Нетрадиционные архитектуры вычислительных систем ВССТ
В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера, как систему памяти и процессоров, структуру системной шины, организацию ввода/вывода и т.п.
2.1.Числовая и нечисловая обработка Компьютеры были созданы для реализации большого объема вычислений. Как правило, эти вычисления представляют собой длинные цепочки итераций и требуют сохранения высокой точности. Такие вычисления характерны для числовой обработки.
По мере распространения компьютеров и создания персональных ЭВМ появилась необходимость в обработке экономической информации, в создании информационных систем для различных организаций, автоматизации работ в учреждениях и т. д. Все эти применения требуют различных баз данных, которые могут хранить миллионы и миллиарды отдельных записей. Чтобы предварительно найти требуемую запись, обработать ее и определить форму ее вывода требуются такие операции, как поиск и сортировка. Эти процессы характеризует нечисловую обработку данных.
В понятие «данные» при числовой и нечисловой обработке вкладывается различное содержание. При числовой обработке используются такие объекты, как переменные, векторы, матрицы, многомерные массивы, константы и т.д. При нечисловой обработке объектами могут быть файлы, записи, поля, иерархии, сети, отношения и т. д. При числовой обработке нас не интересует текущее значение переменных. Даже в условном операторе мы обращаемся к элементу данных не по содержанию, а по имени (например, элемент матрицы A(I,J)). При нечисловой обработке, наоборот, нас интересуют непосредственные сведения об объектах (конкретный служащий или группа служащих), а не файл служащих как таковой.
В классических ЭВМ способы построения запоминающих устройств и способы обращения к ним центрального процессора ориентированы на числовую обработку. В ЭВМ фоннеймановской архитектуры обращение к данным организовано так, что для выборки объекта из памяти нужно сначала указать его адрес. Если же имена служащих выбираются из файла не по адресу, а по содержимому полей (например, ВОЗРАСТ и ЗАРПЛАТА), то этот способ адресации называется ассоциативным обращением или ассоциативной адресацией.
2.2.Ограничения фоннеймановской архитектуры ПРОЦЕССОР В фоннеймановской архитектуре для обработки огромного объема информации мы располагаем всего лишь одним процессором. При этом возникает ситуация, когда миллиарды байтов (символов) информации находятся в состоянии ожидания передачи через канал и обработки на устройстве весьма ограниченной мощности. Такая ситуация для процессора является тупиковой. Для выхода из тупика необходимо внести на этом уровне два изменения в архитектуру: а) использовать параллельные процессоры; б) приблизить процессоры к данным, чтобы устранить их постоянную передачу по каналу.
ЗАПОМИНАЮЩИЕ УСТРОЙСТВА (ЗУ) В ЗУ фоннеймановской архитектуры обращение происходит по адресу. Но при нечисловой обработке обращение должно осуществляться по содержанию. Поэтому используется способ эмуляции ассоциативной адресации с помощью основного адресного доступа. При этом создаются специальные таблицы (справочники) для перевода ассоциативного запроса в соответствующий адрес. Таблицы называются списками ссылок, или индексами. Один из выходов – ассоциативные запоминающие устройства (АЗУ)
2.3. Параллельная обработка Необходимость параллельной обработки может возникнуть по следующим причинам: 1.Велико время решения данной задачи. 2.Мала пропускная способность системы. 3.Необходимо улучшение использования системы. Для распараллеливания необходимо соответствующим образом организовать вычисления. Сюда входят: составление параллельных программ; автоматическое обнаружение параллелизма.
Граф процессов программы Рассмотрим граф, описывающий последовательность процессов большой программы.
Ускорение обработки данных
Условия параллельного выполнения процессов где - пустое множество
Для использования скрытой параллельной обработки требуются преобразования программных конструкций, такие как: уменьшение высоты деревьев арифметических выражений; преобразование линейных рекуррентных соотношений; замена операторов; преобразование блоков IF и DO к каноническому виду; распределение циклов.
(((a+b)+c)+d) h = 3 Дерево а) Уменьшение высоты дерева
(a+b)+(c+d) h = 2 Дерево б)
Для арифметического выражения с n переменными или константами уменьшение высоты дерева позволяет достигнуть ускорения обработки порядка O(n/log2 n) при использовании O(n) процессоров. В рассмотренном примере выражение может быть вычислено за два шага вместо трех первоначальных
Замена операторов Исходный блок операторов присваивания: X=BCD+E Y=AX Z=X+FG Ts = 6 при n = 1 Путем замены операторов можно получить следующий блок: X=BCD+E Y=ABCD+AE Z=BCD+E+FG Tm = 3 при n = 5 Этот блок может быть вычислен параллельно при использовании 5 процессоров за три шага с ускорением обработки U = Ts /Tm = 6/3 = 2 .
2.4. Конвейерная обработка Примером конвейерной организации является сборочный транспортер на производстве. Если транспортер несет аналогичные, но не тождественные изделия, то это – последовательный конвейер; если же все изделия одинаковы, то это – векторный конвейер.
Последовательные конвейеры Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями.
На следующем рисунке показано устройство обработки команд процессора, которое включает четыре ступени (впервые реализовано в машине ATLAS, разработанной в Манчестерском университете в 1963 г.): выборка команд из памяти; декодирование; определение адреса и выборка операнда; исполнение.
Последовательный конвейер
Диаграмма работы последовательного конвейера
tраз = Первый результат на выходе конвейера появляется спустя время: а последующие – с интервалами t j. называемое временем разгона конвейера, ,
Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых команд и операндов соответствует максимальной производительности конвейера
Задержки в работе конвейера могут возникать в результате появления конфликтных ситуаций. Существуют три класса конфликтов: Структурные конфликты, которые возникают из-за конфликтов по ресурсам. Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Векторные конвейеры В векторных машинах пары операндов, принадлежащие двум разным векторам, подаются на функциональное устройство (включающее множество одинаковых функциональных элементов) одновременно, и со всеми парами элементов векторов проводят одновременно функциональные преобразования.
Упрощенная схема векторной машины
Для предварительной подготовки преобразуемых векторов используются векторные регистры, на которые собираются подлежащие обработке вектора. Типичное использование векторного конвейера – это процесс, вырабатывающий по двум исходным векторам А и В результирующий вектор С для арифметической операции С = А + В. В этом случае на конвейер поступает множество одинаковых команд. Векторная команда реализуется с помощью управляющего вектора. Если i-й разряд управляющего вектора установлен в 1, то операция Ci = Аi + Вi выполняется и Сi записывается в результирующий вектор. По мере вычисления адресов, пары операндов могут непрерывно вводиться в арифметическое устройство. В такой конвейерной архитектуре требуются регистры (или управляющие векторы), хранящие необходимую информацию до тех пор, пока можно начать выполнение команды.
Необходимое для этого время называют временем подготовки ts. Время от момента декодирования векторной команды до появления на выходе конвейера первого элемента результирующего вектора называют временем разгона конвейера tf. Если длина обрабатываемого векторного поля равна l, а время обработки на самой медленной ступени равно tb, то общее время выполнения на конвейере векторной команды составляет tvp = ts + tf +(l - 1) tb
Для того чтобы выполнить ту же обработку на последовательном конвейере, потребовалось бы использовать его l раз. Эквивалентом оценки tvp в последовательном конвейере является величина tsq = tfs +(l - 1) tbs , где tsq, tfs и tbs — соответственно время обработки на последовательном конвейере, время его разгона и время обработки на самой медленной его ступени.
Сравнивая tvp и tsq, получаем, что эффективность векторного конвейера будет выше последовательного (время обработки на векторном конвейере будет меньше, чем на последовательном), то есть ts + tf +(l - 1) tb tfs +(l - 1) tbs , в случае, если l 1 + (ts + tf - tfs)/( tbs - tb). Установлено, что знаменатель дроби в правой части неравенства, как правило, составляет около одной десятой числителя, что соответствует значению l 10.
Условия для векторной обработки программ Для векторизации необходимы векторы-аргументы плюс независимые операции над ними. Кандидаты для векторизации - это самые внутренние циклы программы. Пример векторизуемого фрагмента, для которого выполнены все указанные условия: Do i = 1,n C(i) = A(i) + B(i) End Do Пример невекторизуемого фрагмента (очередная итерация не может начаться, пока не закончится предыдущая): Do i = 1,n C(i) = C(i-1)+ B(i) End Do
2.5. Закон Амдала и его следствия Предположим, что в программе доля операций, которые нужно выполнять последовательно, равна S, где 0 ≤ S ≤ 1. Крайние случаи в значениях S соответствуют полностью параллельным (S = 0) и полностью последовательным (S = 1) программам.
Для того, чтобы оценить, какое ускорение U может быть получено на компьютере из N процессоров при заданном значении S, можно воспользоваться законом Амдала: Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно.
Следствие из закона Амдала Для того чтобы ускорить выполнение программы в U раз необходимо ускорить не менее, чем в U раз не менее, чем (1-1/U)-ю часть программы. Таким образом, для эффективного использования мультипроцессорных систем (МПС) необходимо тщательное согласование структур алгоритмов и программ с особенностями архитектуры параллельных вычислительных систем.
2.6. Классификация архитектур вычислительных систем Структура типа ОКОД или SISD Структура типа МКОД или MISD Структура типа ОКМД или SIMD Структура типа МКМД или MIMD
ОДНОПРОЦЕССОРНАЯ СИСТЕМА Структура типа ОКОД или SISD Структура обыкновенной однопроцессорной ЭВМ архитектуры фон Неймана содержит одинарный поток команд и одинарный поток данных (структура ОКОД или SISD).
2. КОНВЕЙЕРНЫЕ МПС: последовательные конвейеры: структура типа МКОД (MISD) Процессоры образуют конвейер, на вход которого поступает одинарный поток данных. Информация на выходе одного процессора является входной информацией для следующего в конвейерной цепочке. Это обеспечивается подведением к каждому процессору своего потока команд, то есть имеется множественный поток команд.
2. КОНВЕЙЕРНЫЕ МПС: векторные конвейеры: структура ОКМД (SIMD) В системе SIMD используется несколько потоков данных и один общий поток команд. Если эти процессоры организованы так, что при выполнении заданных вычислений, инициированных контроллером, они работают параллельно, то система называется матричным процессором (задачи числовой обработки). Если соединить каждый процессор непосредственно с его памятью и работать в режиме поиска по всему массиву, то получим ассоциативный процессор (задачи нечисловой обработки). Процессорные ансамбли применимы как для числовой, так и нечисловой обработки.
4. ОБЩИЙ СЛУЧАЙ МПС структура типа: МКМД (или MIMD) Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс.
К классу MIMD могут быть отнесены, следующие конфигурации: - мультипроцессорные системы; - системы с мультиобработкой; - многомашинные системы; - локальные и глобальные компьютерные сети, в т.ч. Internet.
2.7. Мультипроцессорные системы Мультипроцессорные системы - это системы, имеющие два или более процессоров с общим управлением, совместно использующие ресурсы системы (память, информационные шины, команды, данные) и взаимодействующие между собой.
КЛАССИФИКАЦИЯ МУЛЬТИПРОЦЕССОРНЫХ СИСТЕМ 1.Конвейерные и векторные процессоры 2.Машины типа SIMD 3.Многопроцессорные машины с SIMD-процессорами (MSIMD) 4.Машины типа MIMD 4.1. Мультипроцессорные системы с общей памятью 4.2. Мультипроцессорные системы с локальной памятью и многомашинные системы
МУЛЬТИПРОЦЕССОРНЫЕ СИСТЕМЫ С ОБЩЕЙ ПАМЯТЬЮ
МУЛЬТИПРОЦЕССОРНЫЕ СИСТЕМЫ С ЛОКАЛЬНОЙ (ИНДИВИДУАЛЬНОЙ) ПАМЯТЬЮ И МНОГОМАШИННЫЕ СИСТЕМЫ
Мультипроцессорная когерентность кэш-памяти Проблема когерентности (согласованности) кэш-памяти состоит в необходимости гарантировать, что любое считывание элемента данных дает последнее по времени записанное в него значение.
Существуют два класса протоколов когерентности кэш-памяти. Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы). Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли кэши информацию об изменении сотояния соответствующего блока.
2.8. Базовые архитектуры суперкомпьютеров Архитектура массивно-параллельных компьютеров (на примере CRAY T3D). Эти машины еще называют компьютерами с массовым параллелизмом (Massively Parallel Processor - MPP). К ним относятся такие мощные компьютеры, как Intel Paragon, IBM SP2, CRAY T3D. Основные причины появления массивно-параллельных компьютеров - это, во-первых, необходимость построения компьютеров с гигантской производительностью, и, во-вторых, необходимость производства компьютеров в большом диапазоне как производительности, так и стоимости.
Для массивно-параллельного компьютера, в котором число процессоров может сильно меняться, всегда можно подобрать конфигурацию с заранее заданной производительностью и/или стоимостью. С некоторой степенью условности, массивно-параллельные компьютеры можно характеризовать следующими параметрами: используемые микропроцессоры: Intel Paragon - i860, IBM SP2 - PowerPC 604e или Power2 SC, CRAY T3D - DEC ALPHA; коммуникационная сеть: Intel Paragon - двумерная прямоугольная решетка, IBM SP2 - коммутатор, CRAY T3D - трехмерный тор; организация памяти: Intel Paragon, IBM SP2, CRAY T3D - распределенная память; наличие или отсутствие host-компьютера: Intel Paragon, IBM SP2 - нет, CRAY T3D - есть.
Общая структура компьютера CRAY T3D Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. CRAY T3D подключается к хост-компьютеру (главному или ведущему). Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с. Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основные компоненты: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода.
Вычислительный узел состоит из двух процессорных элементов (ПЭ) и сетевого интерфейса контроллера блочных передач. Оба процессорных элемента, входящие в состав вычислительного узла, идентичны и могут работать независимо друг от друга. Процессорный элемент. Каждый ПЭ содержит микропроцессор, локальную память и некоторые вспомогательные схемы. Микропроцессор - это 64-х разрядный RISC (Reduced Instruction Set Computer) процессор ALPHA фирмы DEC, работающий на тактовой частоте 150 MHz. Микропроцессор имеет внутреннюю кэш-память команд и кэш-память данных.
Объем локальной памяти ПЭ - 8 Mслов. Локальная память каждого процессорного элемента является частью физически распределенной, но логически разделяемой (или общей), памяти всего компьютера. Каждый ПЭ может обращаться к памяти любого другого ПЭ, не прерывая его работы. Сетевой интерфейс формирует передачи перед посылкой через коммуникационную сеть другим вычислительным узлам или узлам ввода/вывода, а также принимает приходящие сообщения и распределяет их между двумя процессорными элементами узла. Контроллер блочных передач - это контроллер асинхронного прямого доступа в память, который помогает перераспределять данные, расположенные в локальной памяти разных ПЭ компьютера CRAY T3D, без прерывания работы самих ПЭ.
Коммуникационная сеть обеспечивает передачу информации между вычислительными узлами и узлами ввода/вывода с максимальной скоростью в 140 Mбайт/с. Сеть образует трехмерную решетку, соединяя сетевые маршрутизаторы узлов в направлениях X, Y, Z. Каждая элементарная связь между двумя узлами - это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
Особенности синхронизации процессорных элементов Для поддержки синхронизации процессорных элементов предусмотрена аппаратная реализация одного из наиболее "тяжелых" видов синхронизации - барьеров синхронизации. Барьер - это точка в программе, при достижении которой каждый процессор должен ждать до тех пор, пока остальные также не дойдут до барьера, и лишь после этого момента все процессы могут продолжать работу дальше.
Табл. 2.1. Максимальное ускорение работы программы в зависимости от доли последовательных вычислений и числа используемых процессоров в CRAY T3D
Векторные конвейерные процессоры (на примере суперкомпьютера Cray SV1) Рынок многопроцессорных векторных (векторно-параллельных) суперкомпьютеров достаточно узок. Прежде всего это американская компания SGI, производящая компьютеры с маркой Cray, и японские NEC и Fujitsu. Векторные процессоры NEC SX-5 и Cray SV-1 по-прежнему опережают по производительности вычислений с плавающей запятой самые быстродействующие микропроцессоры.
Из обычных процессоров Cray SV1 можно сконфигурировать так называемые многопоточные процессоры путем объединения четырех стандартных двухконвейерных процессоров в один. SMP-система SV1 может масштабироваться до 32 двухконвейерных центральных процессоров. Общее число каналов GigaRing на систему может при этом достигать 8.
Внешний вид и архитектура суперЭВМ Сray SV1 с коммутатором 4х4
Кроме SMP-систем SV1, SGI предлагает также кластеры на их основе. Основным «строительным блоком» кластера являются четырехузловые системы. До восьми таких блоков можно объединить, доведя общее число процессоров до 1024 (192 многопоточных). Это позволяет иметь суперкомпьютерную систему с емкостью оперативной памяти свыше 1 Тбайт и производительностью свыше 1 TFLOPS.
Стоимость минимальной конфигурации SV1-1A (восемь двухконвейерных центральных процессоров) составляет 500 тыс. долл., а такой же, но с возможностью расширения SV1-1 — 1 млн. долл. Очевидно, что соотношение стоимость/производительность для таких систем выглядит весьма привлекательно.
Суперкомпьютер Earth Simulator (ES) Earth Simulator (ES) - мультипроцессорная компьютерная система с распределенной памятью, состоящая из 640 процессорных узлов (PNs), связанных через 640x640 одноступенчатых перекрестных переключателей, образующих внутреннюю высокоскоростную коммутирующую сеть. Каждый PN - система с общей памятью, состоящая из 8 арифметических процессоров векторного типа (APs), оперативной памяти на 16 Гбайт (MS), блока управления удаленного доступа (RCU) и процессора ввода - вывода. Пиковая производительность каждого арифметического процессора (AP) – 8 Gflops. ES в целом, таким образом, состоит из 5120 APs с 10 ТВ оперативной памяти и пиковой производительностью - 40 Tflop/s.
Конфигурация ES
Earth Simulator (ES) был разработан как национальный проект Национальным агентством космического развития Японии, Научно-исследовательским институтом атомной энергии Японии и Центром морской науки и технологии Японии. Установлен и введен в эксплуатацию к концу февраля 2002 в Центре моделирования Земли в Йокогаме. Суперкомпьютер размещен на площади 50x65 m.
Суперкомпьютер Earth Simulator (ES)
2.9. Ассоциативный процессор В ассоциативной памяти параллельный поиск идет сразу по большой группе ячеек и в итоге поисковому признаку может удовлетворять содержимое нескольких ячеек. Возможности выполнения различных видов поиска и разнообразие структур ассоциативной памяти объясняют, почему для обозначения этого устройства существует так много синонимов: память с параллельным поиском, запоминающее устройство с многозначным ответом, память с распределенной логикой, логико-запоминающее устройство и т.д.
Одновременность в работе —неотъемлемое свойство ассоциативного запоминающего устройства (АЗУ). В АЗУ поиск идет по всем элементам сразу. Ассоциативное запоминающее устройство, дополненное логикой и микропрограммным управлением, называют ассоциативным процессором (АП).
В основе архитектур ассоциативных процессоров с пословной организацией лежит параллелизм на уровне слов, и в большинстве конфигураций обработка слов выполняется последовательно по разрядам. Базовая структура пословно организованного ассоциативного процессора
Базовая структура пословно организованного ассоциативного процессора
Массив ассоциативной памяти Массив АП содержит т n-разрядных слов. При нечисловой обработке такая запоминающая матрица размером т x n является удобной средой для отображения двумерных логических структур, таких, как матрицы, файлы и отношения. Каждая строка матрицы, каждая запись файла или каждый кортеж отношения соответствует слову ассоциативного массива. Слова могут быть длиной 256, 1024 и даже 4096 бит.
Множество слов образует ассоциативный массив или ассоциативное запоминающее устройство пословно организованного ассоциативного процессора. Соответственно имеется по одному процессорному элементу (ПЭ) на каждое слово, так что весь разрядный срез может обрабатываться параллельно.
Регистр компаранда Компаранд должен быть сначала введен в регистр компаранда, чтобы выполнить массовое сравнение (или сравнение типа SIMD), в котором одно значение сравнивается параллельно со множеством значений. Длина регистра компаранда соответствует длине слова АЗУ.
Регистр маски Регистр маски можно рассматривать как простой фильтр или селектор разрядов регистра компаранда. С помощью регистра маски указывается поле регистра компаранда, которое служит действительным компарандом. Все разряды, не входящие в указанный компаранд, маскируются (т.е. соответствующие разряды регистра маски устанавливаются в 0), в то время как разряды, соответствующие полю компаранда, устанавливаются в 1.
Регистры хранения ответов Обычно каждый регистр хранения ответов представляет собой множество триггеров, образующих двоичный вектор вдоль всего массива АЗУ. Один из этих регистров называется регистром меток (тегов) или отклика и служит для индикации или хранения результатов операций над массивом.
Второй регистр памяти ответов используется как временная рабочая область (или сверхоперативная память) при обработке данных или реализации логических функций. Третий регистр памяти ответов служит для выбора слов. Он указывает для каждого слова АЗУ, участвует ли оно в подлежащей выполнению операции. Запрет обработки всех слов неучаствующего файла производится путем установки в 0 всех разрядов регистра выбора слов, соответствующих этому файлу.
Маска (буфер) вывода Маску вывода можно так же, как и регистр маски компаранда, рассматривать как фильтр разрядов найденных слов. Все невыводимые разряды маскируются (т.е. соответствующие разряды найденных слов устанавливаются в 0), в то время как разряды, соответствующие полю вывода, устанавливаются в 1.
Регистры (или буфер) ввода-вывода АЗУ Эти регистры играют роль буфера при передаче данных в АЗУ или из него.
Соединительная сеть Соединительная сеть используется для логических комбинаций полей в данной физической среде, чтобы можно было выполнить требуемые операции. Иначе говоря, соединительная сеть эмулирует на двумерном массиве АЗУ более сложные виды межпроцессорных соединений.
Контроллер Массив АЗУ и все рассмотренные выше схемы управляются контроллером. Контроллер имеет память для программ, реализующих базовые операции, различные регистры, логику управления шиной, механизмы прерываний и арифметико-логическое устройство для вычисления адресов и сдвига информации.
2.10. Концепция ВС с управлением потоком данных Существуют трудности, связанные с решением проблемы автоматизации параллельного программирования. Поэтому актуальны исследования новых методов построения высокопроизводительных ВС, одними из которых являются ВС с управлением потоком данных, или потоковые ВС.
В системах с управлением потоками данных предполагается наличие большого числа специализированных операционных устройств (ОУ) для определенных видов операций (сложения, умножения и т.п., отдельных для разных типов данных). Данные снабжаются указателями их готовности к обработке (тегами), на основании которых данные загружаются в соответствующие свободные операционные блоки. При достаточном количестве операционных блоков может быть достигнут высокий уровень распараллеливания вычислительного процесса.
Принципиальное отличие потоковых машин состоит в том, что команды выполняются не в порядке следования команд в тексте программы, а по мере готовности их операндов.
Процессор с управлением потоком данных
«Потоковая программа» размещается в массиве ячеек команд. Команда наряду с кодом операции содержит поля, куда заносятся готовые операнды, и поле, содержащее адреса команд, в которые должен быть направлен в качестве операнда результат операции.
Формат команды потоковой ВС КОП Оп1 Оп2 А1, А2, А3… 1 1 Управляющий тег
Кроме того, каждой команде поставлен в соответствие двухразрядный тег (располагаемый в управляющем устройстве), разряды которого устанавливаются «1» при занесении в тело команды соответствующих операндов.
В состоянии тега «11» (оба операнда готовы) инициируется запрос к операционному коммутатору (ОК) на передачу готовой команды в соответствующее коду операции операционное устройство (ОУ). Результат выполнения команды над ее непосредственно адресуемыми операндами направляется через командный коммутатор (КК) согласно указанным в команде адресам в ячейки команд и помещается в их поля операндов. И так далее.
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ В чем отличие числовой и нечисловой обработки данных? Перечислите ограничения фоннеймановской архитектуры. Поясните суть параллельной обработки данных. Поясните конвейерную обработку данных. Приведите примеры последовательных конвейеров. Что такое «время разгона» конвейера? Поясните суть организации векторных конвейеров. Поясните закон Амдала и его следствия.
Продолжение Проведите классификацию архитектур вычислительных систем. Расскажите о мультипроцессорных системах с общей памятью. Расскажите о мультипроцессорных системах с локальной памятью. Перечислите базовые архитектуры суперкомпьютеров. Расскажите об архитектуре современных векторных суперкомпьютеров. Что такое ассоциативная память и ассоциативный процессор? Изложите концепцию вычислительных систем с управлением потоком данных.
Раздел 3. Введение в теорию массового обслуживания и управления ресурсами вычислительных систем ВССТ
Понятие Марковского случайного процесса Случайный процесс, протекающий в системе, называется Марковским, если для любого момента времени t0 вероятностные характеристики процесса в будущем зависят только от его состояния S0 в данный момент t0 и не зависят от того, когда и как система пришла в это состояние.
К понятию Марковского случайного процесса
Марковские процессы с дискретными состояниями и непрерывным временем Процесс называется процессом с дискретными состояниями, если количество состояний конечно (можно пронумеровать), а переходы из состояния в состояние происходят скачкообразно. Процесс называется процессом с непрерывным временем, если моменты возможных переходов из состояния в состояние не фиксированы заранее, а неопределенны, случайны, если переход может осуществиться в любой момент.
Потоки событий Потоком событий называется последовательность однородных событий, следующих одно за другим в случайные моменты времени.
Важнейшей характеристикой потока событий является его интенсивность – среднее число событий, приходящихся на единицу времени. Интенсивность может быть как постоянной, так и переменной, зависящей от времени t. Поток событий называется простейшим (или стационарным пуассоновским), если он обладает сразу тремя свойствами: стационарен, ординарен и без последействия.
Вероятность P(t) для простейшего потока(то есть вероятность возникновения события в момент t) имеет экспоненциальный (показательный) вид:
Для простейшего потока с интенсивностью λ интервал τ между событиями (плотность вероятности) имеет так же показательное распределение. (τ>0)
Величина λ в приведенной формуле называется параметром показательного закона. Если интервал Т между событиями T = 1/ λ , то такой интервал называют коротким. Для простейшего потока характерно, что короткие интервалы между событиями более вероятны, чем длинные; ≈ 63 % промежутков времени между событиями имеют длину меньше короткой.
Элемент вероятности Рассмотрим на оси 0t простейший поток с интенсивностью λ и произвольно расположенный элементарный участок времени Δt. Элементом вероятности называется вероятность попадания на этот участок хотя бы одного события потока. Для простейшего потока элемент вероятности равен интенсивности потока, умноженной на длину элементарного участка.
Уравнения Колмогорова Уравнения Колмогорова - особого вида дифференциальные уравнения, в которых неизвестными функциями являются вероятности состояний. Пусть техническое устройство S состоит из двух узлов и является Марковской системой с дискретными состояниями и непрерывным временем. Изменение состояний происходит под воздействием простейших потоков случайных событий. Возможные состояния системы можно перечислить: S0 – оба узла исправны; S1 - первый узел ремонтируется, второй исправен; S2 - второй узел ремонтируется, первый исправен; S3 – оба узла ремонтируются.
Граф состояний системы S μi - интенсивность ремонтов i - го узла λi - интенсивность поломок i - го узла
Вероятностью i-го состояния называется вероятность Pi (t) того, что в момент t система будет находиться в состоянии Si . Имея в своем распоряжении размеченный граф состояний, можно с помощью уравнений Колмогорова найти все вероятности состояний Pi (t) как функции времени.
Составим уравнения Колмогорова для заданной системы S. Рассмотрим одну из вероятностей состояний, например P0 (t). Это вероятность того, что в момент t система будет в состоянии S0 . Придадим t малое приращение Δt и найдем P0 (t+Δt) – вероятность того, что в момент (t+Δt) система будет находится тоже в состоянии S0.
Произойти это может в трех случаях: либо в момент t система уже была в состоянии S0, а за время Δt не вышла из него; либо в момент t система была в состоянии S1, а за время Δt перешла из него в S0; либо в момент t система была в состоянии S2, а за время Δt перешла из него в S0.
Найдем вероятность первого варианта. Вероятность того, что в момент t система была в состоянии S0 , равна P0(t). Эту вероятность нужно умножить на вероятность того, что, находясь в момент t в состоянии S0, система за время Δt не перейдет из него в другое состояние. Суммарный поток событий, выводящий систему из состояния S0, будет простейший, с интенсивностью (λ1 + λ2).
Значит, вероятность того, что за время Δt система выйдет из состояния S0, равна (λ1 + λ2)Δt; вероятность того, что не выйдет: (1- (λ1 + λ2)Δt). Отсюда, вероятность первого варианта равна P0(t)(1- (λ1 + λ2)Δt).
Вероятность второго варианта равна (μ1 Δt P1(t)); Вероятность третьего варианта равна (μ2 Δt P2(t)). Складывая вероятности всех трех вариантов, получим:
P0(t+Δt)= P0(t)[1- (λ1 + λ2)Δt] + μ1 Δt P1(t) + + μ2 Δt P2(t) Раскроем квадратные скобки, перенесем P0(t) в левую часть и разделим обе части на Δt, получим:
Устремив Δt к нулю, получим: Таким образом, мы получили первое уравнение Колмогорова. Аналогично составляются и уравнения для P1(t), P2(t) и P3(t).
Правило составления дифференциальных уравнений Колмогорова В левой части каждого из уравнений стоит производная вероятности данного состояния. В правой части – сумма произведений вероятностей всех состояний, из которых идут стрелки в данное состояние, на интенсивности соответствующих потоков событий; минус суммарная интенсивность всех потоков, выводяших систему из данного состояния, умноженная на вероятность данного состояния.
Пользуясь этим правилом, получим уравнения Колмогорова для рассмотренной системы S: Чтобы решить эти уравнения и найти вероятности состояний, необходимо задать начальные условия.
Правомерен вопрос: что будет происходить с вероятностями состояний при t, стремящемся к бесконечности? Будут ли Pi(t) стремиться к каким-то пределам? Если эти пределы существуют и не зависят от начального состояния системы, то они называются финальными вероятностями состояний.
Если вероятности Pi(t) постоянны, то их производные равны нулю. Значит, чтобы найти финальные вероятности, нужно все левые части в уравнениях Колмогорова положить равными нулю, и решить полученную систему уже не дифференциальных, а линейных алгебраических уравнений. Для нашей системы они будут выглядеть следующим образом:
Уравнения Колмогорова для финальных вероятностей состояний Для решения этой системы необходимо воспользоваться нормировочным условием P0+P1+P2+P3 = 1.
Правило составления алгебраических уравнений Колмогорова В левой части каждого из уравнений стоит суммарная интенсивность всех потоков, выводящих систему из данного состояния, умноженная на вероятность данного состояния. В правой части – сумма произведений вероятностей всех состояний, из которых идут стрелки в данное состояние, на интенсивности соответствующих потоков событий.
Базовые соотношения систем массового обслуживания Схема гибели и размножения Граф состояний для схемы гибели и размножения
Особенность этого графа в том, что все состояния системы можно вытянуть в одну цепочку, в которой каждое из внутренних состояний (S1,S2,...,Sn-1) связано прямой и обратной стрелкой с каждым из соседних состояний – правым и левым, а крайние состояния (S0,Sn) – только с одним соседним состоянием. Термин «схема гибели и размножения» ведет начало от биологических задач, где подобной схемой описывается изменение численности популяции.
Пользуясь графом состояний системы, составим и решим алгебраические уравнения Колмогорова для финальных вероятностей состояний. Для состояния S0: P0 λ1 = P1 μ1 Для состояния S1: P1 (μ1 + λ2)=P0 λ1 +P2 μ2 Или, с учетом уравнения для S0, для состояния S1 окончательно: P1 λ2 = P2 μ2
Очевидно, для состояния S2 получим: P2 λ3 = P3 μ3 Из уравнения для состояния S0 выразим P1 через P0:
C учетом полученного для вероятности Р1, для вероятности Р2 будем иметь:
Для Р3: И вообще, для любого k (от 1 до n)
Таким образом, все вероятности состояний выражаются через P0. Подставив эти выражения в нормировочное условие и вынеся P0 за скобку, получим:
Формула Литтла Формула Литтла связывает среднее число заявок Lсист , находящихся в системе массового обслуживания, и среднее время пребывания заявки в системе Wсист. Рассмотрим любую СМО и связанные с нею два потока событий, определяемых как: x(t) – число заявок, прибывших в СМО до момента t ; y(t) – число заявок, покинувших СМО до момента t .
К выводу формулы Литтла Очевидно, что для любого момента t разность Z(t)=X(t)-Y(t) есть не что иное, как число заявок, находящихся в СМО.
Рассмотрим очень большой промежуток времени Т и вычислим для него среднее число заявок, находящихся в СМО. Среднее число заявок, находящихся в СМО будет равно интегралу от функции Z(t) на этом промежутке, деленному на длину интервала Т: Интеграл представляет собой не что иное, как площадь фигуры, заштрихованной на предыдущем рисунке, состоящей из прямоугольников высотой, равной единице и основанием ti. Поэтому
Разделим и умножим правую часть выражения для Lсист на интенсивность λ: Величина есть не что иное, как среднее число заявок, пришедших за время Т. Если мы разделим сумму всех времен ti на среднее число заявок, то получим среднее время пребывания заявки в системе Wсист. Следовательно,
Выражение для Wсист и есть формула Литтла - для любой СМО, при любом характере потока заявок, при любом распределении времени обслуживания, при любой дисциплине обслуживания среднее время пребывания заявки в системе равно среднему числу заявок в системе, деленному на интенсивность потока заявок.
Таким же образом выводится вторая формулу Литтла, связывающая среднее время пребывания заявки в очереди Wоч и среднее число заявок в очереди Lоч:
Анализ базовых систем массового обслуживания Многоканальная СМО с отказами (задача Эрланга) Задача ставится так: имеется n каналов, на которые поступает поток заявок с интенсивностью . Поток обслуживания одним каналом имеет интенсивность (величина, обратная среднему времени обслуживания tob).
Требуется найти финальные вероятности состояний СМО, а также характеристики ее эффективности: А – абсолютную пропускную способность, то есть среднее число заявок, обслуживаемых в единицу времени; Q – относительную пропускную способность, то есть среднюю долю обслуженных системой заявок; Ротк - вероятность отказа, то есть вероятность того, что заявка покинет СМО необслуженной; – среднее число занятых каналов.
Состояние системы массового обслуживания S будем нумеровать по числу заявок, находящихся в системе (в данном случае оно совпадает с числом занятых каналов): S0 – в СМО нет ни одной заявки; S1 - в СМО находится одна заявка (один канал занят, остальные свободны); . . . . . Sk - в СМО находится k заявок (k каналов заняты, остальные свободны) Sn - в СМО находятся n заявок (все n каналов заняты).
Граф состояний многоканальной СМО с отказами Воспользуемся уже выведенными формулами для финальных вероятностей в схеме «гибели-размножения».
Получим для P0: где ! обозначает факториал. Члены разложения будут представлять собой коэффициенты при P0 в выражениях для P1, P2 ,...Pn:
Обозначим и будем называть величину ρ приведенной интенсивностью потока заявок. Ее смысл - среднее число заявок, приходящих за среднее время обслуживания одной заявки. Пользуясь этим обозначением, перепишем полученные формулы в виде
Полученные формулы для финальных вероятностей состояний анализируемой СМО называются формулами Эрланга - в честь основателя теории массового обслуживания. По финальным вероятностям можно вычислить характеристики эффективности СМО.
Показатели эффективности многоканальной СМО с отказами Сначала найдем Potk - вероятность того, что пришедшая в СМО заявка получит отказ. Для этого нужно, чтобы все n каналов были заняты, значит:
Отсюда находим относительную пропускную способность - вероятность того, что заявка будет обслужена: Абсолютную пропускную способность получим, умножая интенсивность потока заявок на Q:
Абсолютная пропускная способность есть не что иное, как интенсивность потока обслуженных системой заявок. Так как каждый занятый канал в единицу времени обслуживает в среднем μ заявок, то среднее число занятых каналов равно:
Одноканальная СМО с неограниченной очередью Пусть имеется одноканальная СМО с очередью, на которую не наложено никаких ограничений (ни по длине очереди, ни по времени ожидания). На эту СМО поступает поток заявок с интенсивностью λ; поток обслуживаний имеет интенсивность μ, обратную среднему времени обслуживания заявки tоб.
Требуется найти финальные вероятности состояний СМО, а также характеристики ее эффективности: Lсист- среднее число заявок в системе; Wсист- среднее время пребывания заявки в системе; Lоч- среднее число заявок в очереди; Wоч- среднее время пребывания заявки в очереди; Рзан- вероятность того, что канал занят (степень загрузки канала).
Что касается абсолютной пропускной способности А и относительной Q, то вычислять их нет надобности: в силу того, что очередь не ограничена, каждая заявка рано или поздно будет обслужена, поэтому А = λ , по той же причине Q=1. Решение. Состояния системы будем нумеровать по числу заявок, находящихся в СМО: S0- канал свободен; S1- канал занят, очереди нет; S2- канал занят, одна заявка стоит в очереди; и т.д. Теоретически число состояний ничем не ограничено.
Граф состояний имеет вид
Это - схема гибели и размножения, но с бесконечным числом состояний. По всем стрелкам слева направо поток заявок с интенсивностью λ переводит систему в состояния слева направо, а справа налево - поток обслуживаний с интенсивностью μ. Если ρ≥1, то канал с заявками не справляется, очередь растет до бесконечности. Если ρ <1, то задача вполне разрешима. Воспользуемся формулами для финальных вероятностей из схемы гибели и размножения, но для бесконечного числа состояний. Подсчитаем финальные вероятности :
Ряд в формуле представляет собой геометрическую прогрессию со знаменателем ρ. Известно, что при ρ 1 ряд расходится; при ρ < 1 ряд сходится. Теперь предположим, что это условие выполнено, и ρ < 1. Суммируя прогрессию в предыдущей формуле, получаем Тогда
вероятности P1, P2,...,Pk,... найдутся по формулам: откуда с учетом того, что найдем окончательно:
Найдем среднее число заявок в СМО как дискретную случайную величину – число заявок в системе. Эта величина имеет возможные значения 0,1,2,...,k,... с вероятностями P0, P1,..., Pk,... Ее математическое ожидание Lсист определяется как
Произведение есть ни что иное, как производная по от выражения ρ k; значит, Подставив в формулу для Lсист выражение для Pk, получим:
Но сумма в этом выражении есть не что иное, как сумма бесконечно убывающей геометрической прогрессии с первым членом ρ и знаменателем ρ ; эта сумма равна , а ее производная равна: Подставляя это выражение в предыдущую формулу, получим:
Теперь применим формулу Литтла и найдем среднее время пребывания заявки в системе:
Найдем среднее число заявок в очереди Lоч. Будем рассуждать так: число заявок в очереди равно числу заявок в системе минус число заявок, находящихся под обслуживанием. Число заявок под обслуживанием может быть либо нулем (канал свободен), либо единицей (канал занят). Математическое ожидание такой случайной величины равно вероятности того, что канал занят (Рзан). Очевидно, Рзан равно единице минус вероятность P0 того, что канал свободен:
Следовательно, среднее число заявок под обслуживанием равно отсюда и окончательно
По формуле Литтла найдем среднее время пребывания заявки в очереди: Таким образом, все характеристики эффективности этой СМО найдены.
Многоканальная СМО с неограниченной очередью Тот же подход, что и для одноканальной СМО, используется и для решения задачи для многоканальной СМО с неограниченной очередью. Состояния системы: S0- все каналы свободны; S1- один канал занят, очереди нет; S2- занято два канала; .................................... Sn- заняты все n каналов; Sn+1- заняты все n каналов, одна заявка стоит в очереди; ................................... Sn+r- заняты все n каналов, r заявок стоит в очереди; ..................................
Граф состояний многоканальной СМО с неограниченной очередью Естественное условие существования финальных вероятностей ρ/n < 1. Если ρ/n ≥ 1, очередь растет до бесконечности.
Пусть условие ρ/n < 1 выполнено. Применяя формулы для схемы гибели и размножения, найдем финальные вероятности. В выражении для P0 будет стоять ряд членов, содержащих факториалы, плюс сумма бесконечно убывающей геометрической прогрессии со знаменателем ρ/n . Суммируя ее, найдем
Теперь найдем характеристики эффективности СМО. Из них легче всего находится среднее число занятых каналов Найдем среднее число заявок в системе Lсист и среднее число заявок в очереди Lоч. Из них легче вычислить второе по формуле выполняя соответствующие преобразования по образцу одноканальной СМО с неограниченной очередью, получим:
Пусть Тогда
Поскольку то Так как то ,
а То есть Для Lоч получим
Деля, по формуле Литтла, выражение для Lсист и Lоч на λ , получим средние времена пребывания заявки в очереди и в системе: Прибавляя к Lоч среднее число заявок под обслуживанием (оно же - среднее число занятых каналов) , получаем:
1.1. СИСИТЕМЫ
По-гречески система (systêma) - это целое, составленное из частей. Другими словами система - есть совокупность элементов, взаимосвязанных друг с другом и таким образом образующих определённую целостность.
Свойства и понятия систем Элемент системы - часть системы выполняющая определённую функцию. Элемент системы может быть сложным, состоящим из взаимосвязанных частей, то есть тоже представлять собой систему. Такой сложный элемент называют подсистемой. Организация системы - внутренняя упорядоченность и согласованность взаимодействия элементов системы. Структура системы - совокупность внутренних устойчивых связей между элементами системы, определяющая её основные свойства. Целостность системы - принципиальная несводимость свойств системы к сумме свойств её элементов.
1.2. УПРАВЛЕНИЕ
Укрупнённая структурная схема системы управления
Упрощённая структурная схема замкнутой САУ
Структурная схема АСУ
1.3. ИНФОРМАЦИОННАЯ ТЕХНОЛОГИЯ
Основные технические достижения, обусловившие появление ИТ
Концептуальная модель базовой информационной технологии